NLP之多循环神经网络情感分析
文章目录
- 代码展示
- 代码意图
- 代码解读
- 知识点介绍
代码展示
import pandas as pd
import tensorflow as tf# 构建RNN神经网络
tf.random.set_seed(1)
df = pd.read_csv("../data/Clothing Reviews.csv")
print(df.info())df['Review Text'] = df['Review Text'].astype(str)
x_train = df['Review Text']
y_train = df['Rating']from tensorflow.keras.preprocessing.text import Tokenizer# 创建词典的索引,默认词典大小20000
dict_size = 14848
tokenizer = Tokenizer(num_words=dict_size)
# jieba: 停用词,标点符号,词性.....
tokenizer.fit_on_texts(x_train)
print(len(tokenizer.word_index), tokenizer.index_word)# # 把评论的文本转化序列编码
x_train_tokenized = tokenizer.texts_to_sequences(x_train)# # 通过指定长度,把不等长list转化为等长
from tensorflow.keras.preprocessing.sequence import pad_sequencesmax_comment_length = 120
x_train = pad_sequences(x_train_tokenized, maxlen=max_comment_length)for v in x_train[:10]:print(v, len(v))# 构建RNN神经网络
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN, Embedding
import tensorflow as tfrnn = Sequential()
# 对于rnn来说首先进行词向量的操作
rnn.add(Embedding(input_dim=dict_size, output_dim=60, input_length=max_comment_length))rnn.add(SimpleRNN(units=100)) # 第二层构建了100个RNN神经元rnn.add(Dense(units=10, activation=tf.nn.relu))rnn.add(Dense(units=6, activation=tf.nn.softmax)) # 输出分类的结果
rnn.compile(loss='sparse_categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
print(rnn.summary())
result = rnn.fit(x_train, y_train, batch_size=64, validation_split=0.3, epochs=1)
print(result)
print(result.history)
代码意图
代码的意图:
该代码的主要目的是构建一个简单的RNN(循环神经网络)来对"Clothing Reviews.csv"中的评论进行分类。评论文本被转换为数值序列,然后使用这些序列来训练RNN模型,以预测评论的评分。
流程描述:
-
设置随机种子:确保结果的可重复性。
tf.random.set_seed(1) -
读取数据:使用pandas读取"Clothing Reviews.csv"文件,并打印数据信息。
df = pd.read_csv("../data/Clothing Reviews.csv") print(df.info()) -
数据预处理:
- 将’Review Text’列转换为字符串类型。
- 从数据框中提取训练数据
x_train和标签y_train。df['Review Text'] = df['Review Text'].astype(str) x_train = df['Review Text'] y_train = df['Rating']
-
文本标记化:
-
使用
Tokenizer进行文本标记,创建一个字典来将每个词映射到一个整数值。 -
通过调用
fit_on_texts方法对评论文本进行学习。dict_size = 14848 tokenizer = Tokenizer(num_words=dict_size) tokenizer.fit_on_texts(x_train) -
将评论文本转换为整数序列。
x_train_tokenized = tokenizer.texts_to_sequences(x_train)
-
-
序列填充:为了确保所有序列长度相同,使用
pad_sequences对序列进行填充或截断。max_comment_length = 120 x_train = pad_sequences(x_train_tokenized, maxlen=max_comment_length) -
构建RNN模型:
- 初始化一个序贯模型
Sequential。 - 添加一个
Embedding层,将词汇转换为固定大小的向量。 - 添加一个
SimpleRNN层,含有100个神经元。 - 添加两个全连接层
Dense,用于分类任务。 - 编译模型,设置损失函数、优化器和评估标准。
rnn = Sequential() rnn.add(Embedding(input_dim=dict_size, output_dim=60, input_length=max_comment_length)) rnn.add(SimpleRNN(units=100)) rnn.add(Dense(units=10, activation=tf.nn.relu)) rnn.add(Dense(units=6, activation=tf.nn.softmax)) rnn.compile(loss='sparse_categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
模型结构
Model: "sequential" _________________________________________________________________Layer (type) Output Shape Param # =================================================================embedding (Embedding) (None, 120, 60) 890880 simple_rnn (SimpleRNN) (None, 100) 16100 dense (Dense) (None, 10) 1010 dense_1 (Dense) (None, 6) 66 - 初始化一个序贯模型
-
模型摘要:打印模型的摘要,显示各层的细节。
print(rnn.summary()) -
训练模型:使用提取的数据训练RNN模型,并将30%的数据用作验证集。训练1个epoch。
result = rnn.fit(x_train, y_train, batch_size=64, validation_split=0.3, epochs=1) -
打印结果:显示模型的训练历史。
print(result) print(result.history)
总之,这段代码首先进行数据预处理,然后构建和训练一个RNN模型来对评论进行分类。
代码解读
当然可以!下面是逐行解读的代码:
-
tf.random.set_seed(1):
- 设置全局随机种子为1,确保随机过程的可重复性。
-
df = pd.read_csv(“…/data/Clothing Reviews.csv”):
- 使用pandas读取CSV文件,并将其内容赋值给
df。
- 使用pandas读取CSV文件,并将其内容赋值给
-
print(df.info()):
- 打印
df的简要摘要,包括每列的非空值数量、数据类型等信息。
- 打印
-
df[‘Review Text’] = df[‘Review Text’].astype(str):
- 将DataFrame中的’Review Text’列转换为字符串类型。
-
x_train = df[‘Review Text’]:
- 从
df中提取’Review Text’列的内容,并将其赋值给x_train。
- 从
-
y_train = df[‘Rating’]:
- 从
df中提取’Rating’列的内容,并将其赋值给y_train。
- 从
-
from tensorflow.keras.preprocessing.text import Tokenizer:
- 从TensorFlow库中导入文本标记化工具。
-
dict_size = 14848:
- 设置词汇表的大小为14848。
-
tokenizer = Tokenizer(num_words=dict_size):
- 初始化一个Tokenizer对象,其最大词汇数为
dict_size。
- 初始化一个Tokenizer对象,其最大词汇数为
-
tokenizer.fit_on_texts(x_train):
- 根据
x_train中的文本内容为tokenizer对象构建词汇表。
- print(len(tokenizer.word_index), tokenizer.index_word):
- 打印词汇表的大小和具体的词-索引映射。
- x_train_tokenized = tokenizer.texts_to_sequences(x_train):
- 将
x_train中的文本转换为整数序列,并赋值给x_train_tokenized。
- from tensorflow.keras.preprocessing.sequence import pad_sequences:
- 从TensorFlow库中导入序列填充工具。
- max_comment_length = 120:
- 设置评论的最大长度为120。
- x_train = pad_sequences(x_train_tokenized, maxlen=max_comment_length):
- 将
x_train_tokenized中的序列填充或截断为统一的长度(120)。
- for v in x_train[:10]: print(v, len(v)):
- 打印
x_train中前10个序列及其长度。
- from tensorflow.keras.models import Sequential 和其他导入语句:
- 从TensorFlow库中导入所需的模型和层。
- rnn = Sequential():
- 初始化一个Sequential模型对象,并赋值给
rnn。
- rnn.add(Embedding(…)):
- 向模型中添加一个Embedding层。
- rnn.add(SimpleRNN(units=100)):
- 添加一个包含100个神经元的SimpleRNN层。
- rnn.add(Dense(units=10, activation=tf.nn.relu)):
- 添加一个全连接层,包含10个神经元并使用ReLU激活函数。
- rnn.add(Dense(units=6, activation=tf.nn.softmax)):
- 添加输出层,包含6个神经元,并使用Softmax激活函数。
- rnn.compile(…):
- 编译模型,指定损失函数、优化器和评估标准。
- print(rnn.summary()):
- 打印模型的摘要,展示每层的参数数量。
- result = rnn.fit(…):
- 使用指定的训练数据和验证数据集进行模型训练,并将训练结果赋值给
result。
- print(result):
- 打印训练过程的结果。
- print(result.history):
- 打印训练过程中的历史数据,如每个周期的损失和准确率。
该代码的主要目的是使用Recurrent Neural Network (RNN)来对"Clothing Reviews.csv"中的评论进行分类。
知识点介绍
当然可以!以下是对每个重要函数的详细介绍:
-
tf.random.set_seed(1):
- 功能:设置全局随机种子,确保随机过程的可重复性。
-
pd.read_csv(“…/data/Clothing Reviews.csv”):
- 功能:使用pandas库读取CSV文件,并返回一个DataFrame对象。
-
df[‘Review Text’].astype(str):
- 功能:将DataFrame中的’Review Text’列转换为字符串类型。
-
Tokenizer(num_words=dict_size):
- 功能:初始化一个Tokenizer对象,该对象可以将文本转换为整数序列。
- 参数:num_words表示Tokenizer对象将使用的最大单词数。这意味着只有出现频率最高的
dict_size个词将被考虑。
-
tokenizer.fit_on_texts(x_train):
- 功能:根据提供的文本数据,为Tokenizer对象构建词汇表。
-
tokenizer.texts_to_sequences(x_train):
- 功能:将文本列表转换为整数序列列表,其中整数是词汇表中词的索引。
-
pad_sequences(x_train_tokenized, maxlen=max_comment_length):
- 功能:将整数序列列表转换为2D Numpy数组,长度不足的序列将被填充,长度超出的序列将被截断。
- 参数:maxlen定义了序列的最大长度。
-
Sequential():
- 功能:初始化一个线性堆叠模型,允许按顺序添加层。
-
Embedding(input_dim=dict_size, output_dim=60, input_length=max_comment_length):
- 功能:将整数标记转换为密集向量。
- 参数:input_dim是词汇表的大小,output_dim是嵌入向量的维度,input_length是输入序列的长度。
-
SimpleRNN(units=100):
- 功能:添加一个SimpleRNN层,它是RNN的一个简化版本。
- 参数:units定义了RNN单元的数量。
- Dense(units=10, activation=tf.nn.relu) 和 Dense(units=6, activation=tf.nn.softmax):
- 功能:添加一个全连接层。
- 参数:units定义了层中神经元的数量,activation是激活函数。
- rnn.compile(…):
- 功能:编译模型,准备进行训练。
- 参数:loss定义了损失函数,optimizer定义了优化算法,metrics定义了模型评估的标准。
- rnn.fit(x_train, y_train, batch_size=64, validation_split=0.3, epochs=1):
- 功能:训练模型。
- 参数:batch_size定义了每次梯度更新使用的样本数量,validation_split定义了用于验证的数据的比例,epochs定义了训练周期的数量。
这些函数共同完成了数据处理、模型构建和训练的过程。希望这些详细的介绍能够帮助您更好地理解代码!
相关文章:

NLP之多循环神经网络情感分析
文章目录 代码展示代码意图代码解读知识点介绍 代码展示 import pandas as pd import tensorflow as tf# 构建RNN神经网络 tf.random.set_seed(1) df pd.read_csv("../data/Clothing Reviews.csv") print(df.info())df[Review Text] df[Review Text].astype(str) …...
)
【AutoML】AutoKeras 的安装和环境配置(VSCode)
本地环境中已经有太多的工作配置了(Python、Java、Maven、Docker 等等),为了不影响其他环境运行,我选择直接在 VSCode 中创建工作空间并配置好 AutoKeras(反正最后也是要在 VSCode 中进行开发的)。 打开 V…...
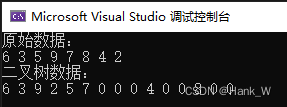
树结构及其算法-用数组来实现二叉树
目录 树结构及其算法-用数组来实现二叉树 C代码 树结构及其算法-用数组来实现二叉树 使用有序的一维数组来表示二叉树,首先可将此二叉树假想成一棵满二叉树,而且第层具有个节点,按序存放在一维数组中。首先来看看使用一维数组建立二叉树的…...
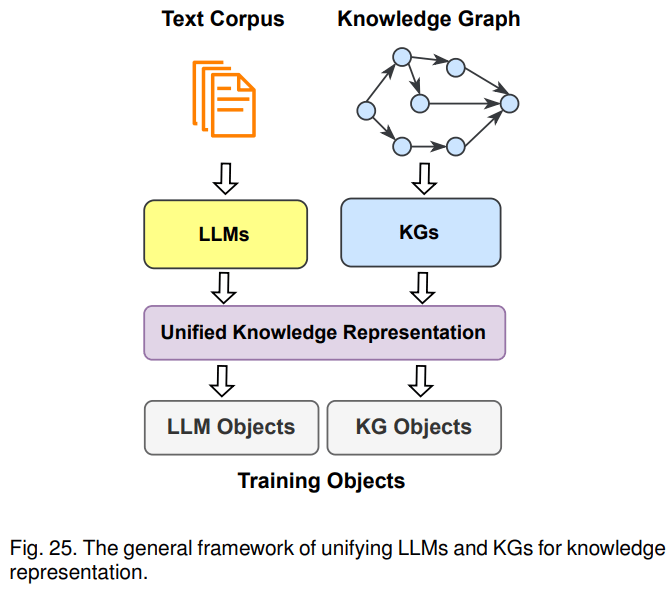
知识图谱与大模型结合方法概述
《Unifying Large Language Models and Knowledge Graphs: A Roadmap》总结了大语言模型和知识图谱融合的三种路线:1)KG增强的LLM,可在LLMs的预训练和推理阶段引入KGs;2)LLM增强KG,LLM可用于KG构建、KG emb…...

ASO优化之如何制作Google Play的长短描述
应用的描述以及标题和图标是元数据中最关键的元素,可以影响用户是否决定下载我们的应用程序。简短描述的长度限制为80个字符,它提供了更多的有关应用背景信息的机会。 1、简短描述帮助用户快速了解我们应用。 确保内容丰富的同时,保持简洁和…...

Python-platform模块
platform目录 前言一、platform.system()二、platform.release()三、platform.python_version()四、platform.machine()五、platform.python_implementation()六、其他代码示例七、help总结前言 Python platform模块是一个用于获取和操作操作系统相关信息的内置模块。它提供了…...
检测自己的数据集,附带代码模型可以收敛)
Yolov5旋转框(斜框)检测自己的数据集,附带代码模型可以收敛
文章目录 1. 制作数据集1.1 标注数据集1.2标签转换1.3 数据集划分2. 环境搭建1.安装nms_rotated2.安装DOTA_devkit3. 代码讲解3.1坐标表示3.2 损失函数4.训练+测试链接后面附上百度网盘链接,内部包含数据集。 下一篇介绍tensorRT部署yolov5-obb 1. 制作数据集 标注软件为…...
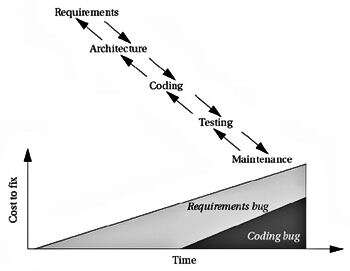
嵌入式应用选择正确的系统设计方法:第三部分
产品质量低下的原因有很多,例如,产品制造粗糙,组件设计不当,架构不佳以及对产品的要求了解不多。点击领取嵌入式物联网学习路线 必须设计质量。 您不能测试出足够的错误来交付高质量的产品。的质量保证(QA)…...

pthread_attr_getstacksize 问题
最近公司里遇到一个线程栈大小的问题,借此机会刚好学习一下这个线程栈大小相关的函数。如果公司里用的还是比较老的代码的话,都是用的 pthread 库支持线程的,而不是 c11 里的线程类。主要有两个相关函数:pthread_attr_setstacksiz…...

anaconda常见语法
anaconda常见语法 一、镜像 1.添加镜像channel conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/2.删除镜像channel conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/3.展示目前已有的镜像…...

reactive与ref VCA
简介 Vue3 最大的一个变动应该就是推出了 CompositionAPI,可以说它受ReactHook 启发而来;它我们编写逻辑更灵活,便于提取公共逻辑,代码的复用率得到了提高,也不用再使用 mixin 担心命名冲突的问题。 ref 与 reactive…...

小程序day01
简介: 小程序项目的基本结构 页面的组成部分 一个页面对应一个文件夹,所有有关的内容都放在一起。 JSON配置文件 2.app.json文件 3.project.config.json文件 4.sitemap.json文件 5.页面的.json配置文件 6. 新建小程序页面 7.修改项目首页 小程序代码构成 小程序的宿…...

redis主要支持的数据类型有哪些?—— 筑梦之路
Redis支持的主要数据类型: 1、字符串(String):字符串是最简单的数据结构,可以存储文本或二进制数据。常用操作:设置值、获取值、追加、自增自减等。 2、列表(List):列表是…...

解决国际阿里云服务器挂载云盘的问题!!
跟着云计算技术的开展,越来越多的企业和个人挑选运用云服务器。然而,在运用过程中,可能会遇到一些问题,比如云服务器无法挂载云盘。这篇文章将详细说明如何处理这个问题。 一、云服务器无法挂载云盘的原因 云服务器无法挂载云盘可…...

基于吉萨金字塔建造算法的无人机航迹规划-附代码
基于吉萨金字塔建造算法的无人机航迹规划 文章目录 基于吉萨金字塔建造算法的无人机航迹规划1.吉萨金字塔建造搜索算法2.无人机飞行环境建模3.无人机航迹规划建模4.实验结果4.1地图创建4.2 航迹规划 5.参考文献6.Matlab代码 摘要:本文主要介绍利用吉萨金字塔建造算法…...

高频SQL50题(基础版)-1
文章目录 主要内容一.SQL练习题1.1757-可回收且抵制的产品代码如下(示例): 2.584-寻找用户推荐人代码如下(示例): 3.595-大的国家代码如下(示例): 4.1148-文章浏览代码如下(示例): 5…...

RecyclerView自定义LayoutManager从0到1实践
此前大部分涉及到 RecyclerView 页面的 LayoutManager基本上用系统提供的 LinearLayoutManager 、GridLayoutManager 就能解决,但在一些特殊场景上还是需要我们自定义 LayoutManager。之前基本上没有自己写过,在网上看各种源码各种文章,刚开始…...

【虹科干货】5个关于微服务的误解
你认为微服务架构能为你带来什么?难道微服务真的是一劳永逸的吗?又或者,难道微服务的威力并不如传闻所言?微服务架构应当如何设计才能真正彰显它作为一种解决方案的好处呢? 文章速览: 误解一:…...

利用卷影拷贝服务攻击域控五大绝招
点击星标,即时接收最新推文 在微软Active Directory(活动目录)中,所有的数据都被保存在ntds.dit中, NTDS.DIT是一个二进制文件, 它存在于域控制器中的 %SystemRoot%\ntds\NTDS.DIT。ntds.dit包括但不限于Us…...
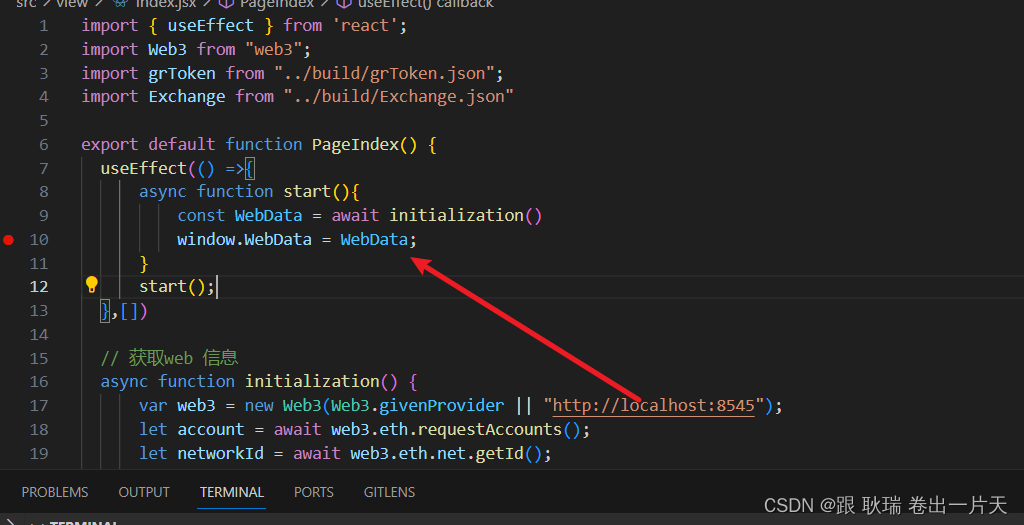
web3 在React dapp中全局管理web3当前登录用户/智能合约等信息
上文 Web3 React项目Dapp获取智能合约对象我们在自己的前端dapp项目中链接获取到了 自己的智能合约 我们继续 我们还是先启动ganache环境 终端输入 ganache -d然后发布一下我们的智能合约 打开我们的合约项目 终端输入 truffle migrate --reset这样 我们的智能合约就部署到区…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...