hadoop03-MapReduce【尚硅谷】
大数据学习笔记
MapReduce
一、MapReduce概述
- MapReduce是一个分布式运算程序的编程框架,是基于Hadoop的数据分析计算的核心框架。
MapReduce处理过程为两个阶段:Map和Reduce。
- Map负责把一个任务分解成多个任务;
- Reduce负责把分解后多任务处理的结果汇总。
- MapReduce优点
- MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。 - 良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。 - 高容错性
-MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。 - 适合PB级以上海量数据的离线处理
可以实现上千台服务器集群开发工作,提供数据处理能力。
- MapReduce缺点
- 不擅长实时计算
- 不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。 - 不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
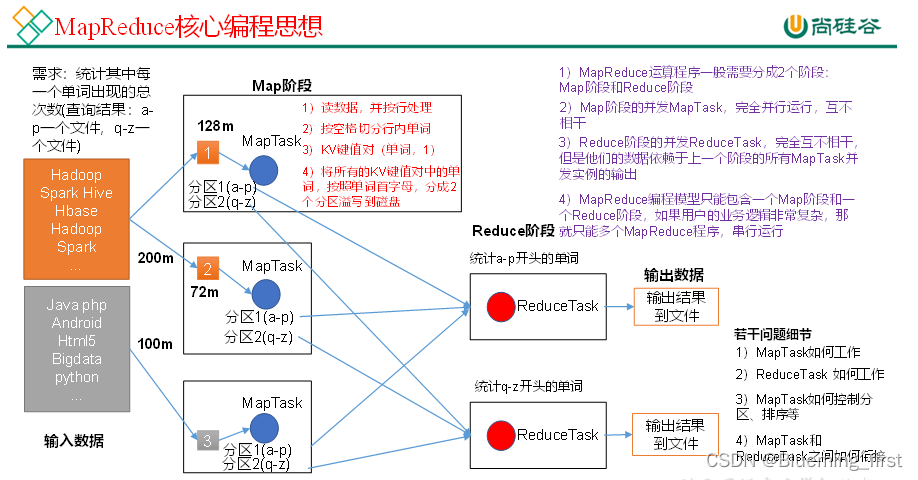
MapReduce核心编程思想
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
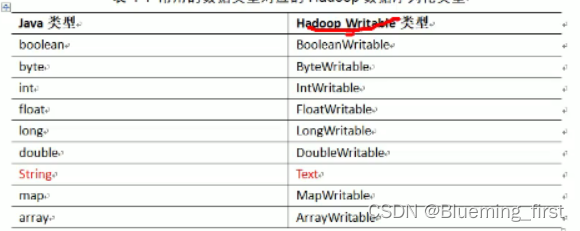
- 常用序列化类型
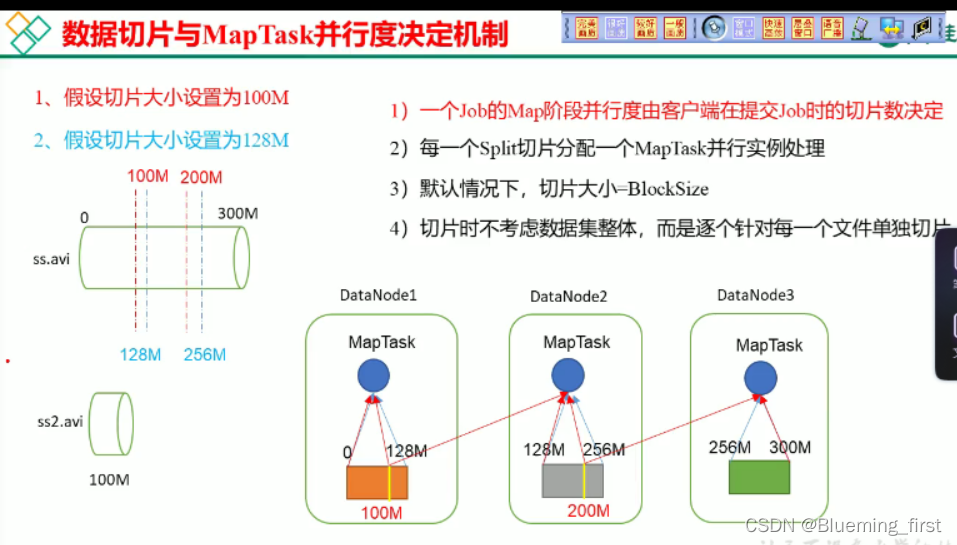
- MapTask的并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切分:数据切分只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。(只是在切分时默认按照块大小来切分)
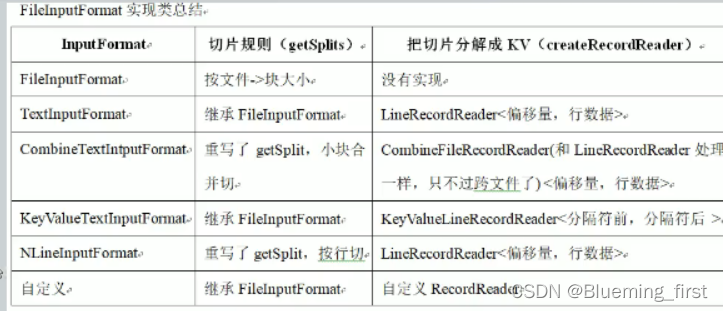
- FileInputFormat切片源码解析
1) 程序先找到你数据存储的目录。
2)开始遍历处理(规划切片)目录下的每一个文件
3)遍历第一个文件ss.txt
a) 获取文件大小fs.sizeOf(ss.txt)
b) 计算切片大小
computeSplitSize(Math.max(minSize.Math.min(maxSize,blocksize)))=blocksize=128M
c) 默认情况下,切片大小=blocksize
d)开始切,形成第一个切片:ss.txt–0:128M 第二个切片ss.txt–128:256M 第三个切片ss.txt–256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片)
e)将切片信息写到一个切片规划文件中
f)整个切片的核心过程在getSplit()方法中完成
g) InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
4)提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。 - FileInputFormat切片机制
1)简单地按照文件的内容长度进行切片
2)切片大小,默认等于Block大小
3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片

针对不同的文件类型FileInputFormat有不同的文件接口。 - CombineTextInputFormat切片机制
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。 - NLineInputFormat
NLineInputFormat每个map进程处理的InputSplit不再按Block块去划分,而是按NLineInputFormat指定的行数N来划分。 - NLineInputFormat
可指定分片数。
二、自定义inputformat案例
- 需求

- 自定义一个类继承FileInputFormat
1)重写isSplitable()方法,返回false不可分割
2)重写createRecordReader(),创建自定义的RecordReader对象,并初始化- 改写RecordReader,实现一次读取一个完整文件封装为KV
1)采用IO流一次读取一个文件输出到value中,因为设置了不可切片,最终把所有文件都封装到了value中
2)获取文件路径信息+名称,并设置key- 设置Driver
1)设置输入的inputFormat
2)设置输出的outputFormat

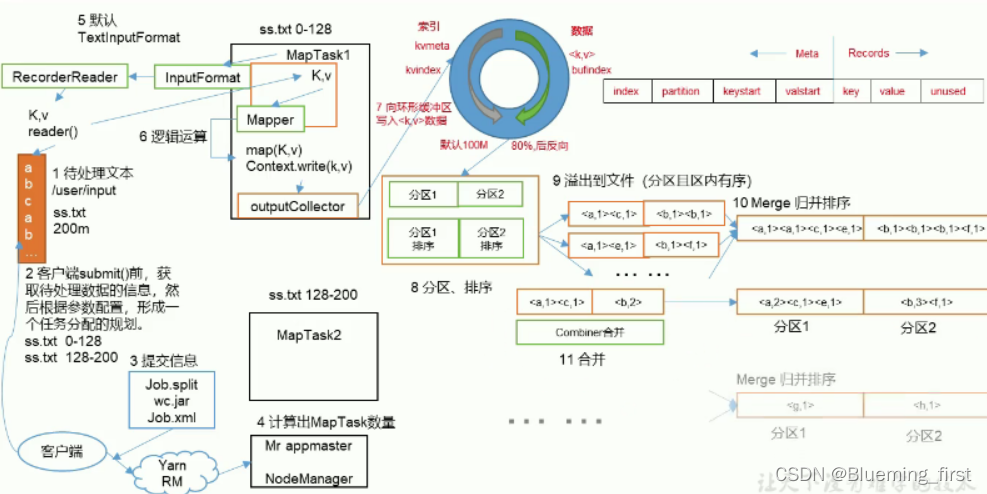
二、MapReduce详细工作流程
- MapReduce详细工作流程(一)
- 待处理文本 xx.txt
- 提交前要获取参数信息,形成一个任务分配的规划
- 提交信息 job(看是yarn 还是本地)
- APPmaster接收请求,根据切片来计算出开多少个MapTask
- 按照默认切片方式128M为一块,默认按照TextInputFormat读数据
- 将kv内容交给Mapper(逻辑运算内容) 业务逻辑
- 将数据写到环形缓冲区,包含元数据信息和真实输入的kv,元数据中包含索引、分区信息、key起始、value起始等信息。
- 分区、排序。
- 将缓冲区文件,溢写到文件,并分区且区内有序。
- Merge 归并,将溢写出的文件合并并排序
- 合并
- MapReduce详细工作流程(二)
- reduce根据当前分区的个数(MapTask数目)开启reduce Task进程
- 下载到ReduceTask本地磁盘,对每个分区做合并并进行归并排序
14.使用reduce方法 读文件数据- 分组
- 默认TextOutputFormat
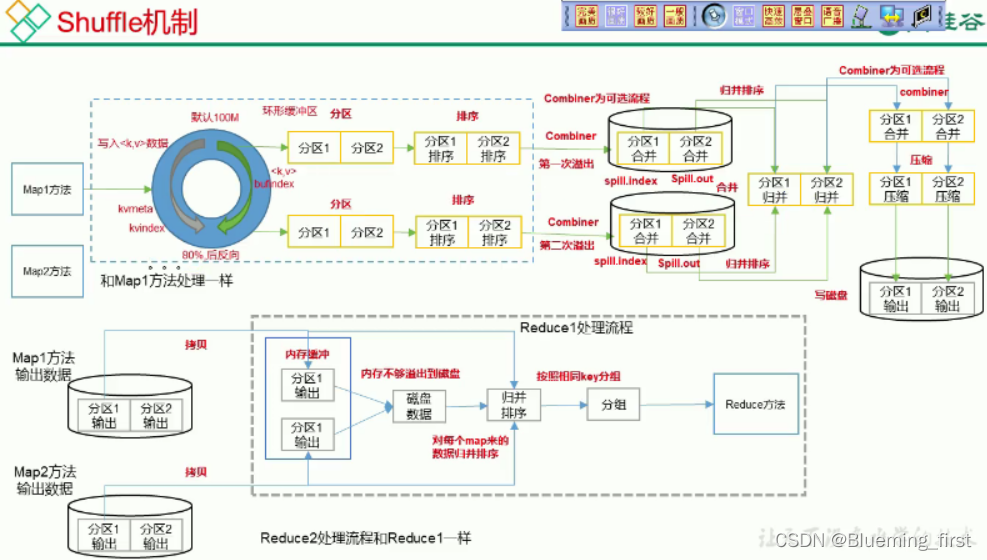
三、Shuffle机制
- Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。 - Map方法将 kv数据写入环形缓冲区,默认100M 当达到80%时会向磁盘溢写,(可选流程)将溢写到磁盘的分区进行合并排序
- reduce 拷贝maptask处理的分区数据放入内存,如果内存不够写入磁盘,对每一个map来的数据归并排序,按照相同的key执行reduce方法。
四、Partition分区
要求将统计结果按照条件输出到不同文件(分区)中去。
分区总结:

五、排序
指定排序规则。
- 概述
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对应MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它会从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以上传一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
2. 排序分类
1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
3)辅助排序
在reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
4)二次排序
自定义排序,如果compareTo中的判断条件为两个即为二次排序。
相关文章:
hadoop03-MapReduce【尚硅谷】
大数据学习笔记 MapReduce 一、MapReduce概述 MapReduce是一个分布式运算程序的编程框架,是基于Hadoop的数据分析计算的核心框架。 MapReduce处理过程为两个阶段:Map和Reduce。 Map负责把一个任务分解成多个任务;Reduce负责把分解后多任务处…...

测牛学堂:软件测试python学习之异常处理
python的捕获异常 程序在运行时,如果python解释器遇到一个错误,则会停止程序的执行,并且提示一些错误信息,这就是异常。 程序停止执行并且提示错误信息,称之为抛出异常。 因为程序遇到错误会停止执行,有时…...

图神经网络--图神经网络
图神经网络 图神经网络图神经网络一、PageRank简介1.1互联网的图表示1.2PageRank算法概述1.3求解PageRank二、代码实战2.1引入库2.2加载数据,并构建图2.3计算每个节点PageRank重要度2.4用节点尺寸可视化PageRank值一、PageRank简介 PageRank是Google最早的搜索引擎…...

React useCallback如何使其性能最大化?
前言 React中最让人畅谈的就是其带来的灵活性,可以说写起来非常的舒服。但是也就是它的灵活性太强,往往让我们忽略了很多细节的地方,而就是这些细节的东西能进行优化,减小我们的性能开销。可以说刚学React和工作几年后写React的代…...
长尾关键词使用方法,通过什么方式挖掘长尾关键词?
当你在搜索引擎的搜索栏中输入有关如何使用长尾关键词的查询时,你可能希望有简单快捷的方式出现在搜索结果中,可以帮助你更好地应用seo。 不过,这里要记住一件事:SEO 策略只会为你的网站带来流量;在你的产品良好之前&a…...

【网络编程套接字(一)】
网络编程套接字(一)理解源IP地址和目的IP地址理解源MAC地址和目的MAC地址理解源端口号和目的端口号PORT VS PID认识TCP协议和UDP协议网络字节序socket编程接口socket常见APIsockaddr结构简单的UDP网络程序服务端创建套接字服务端绑定字符串IP VS 整数IP客…...
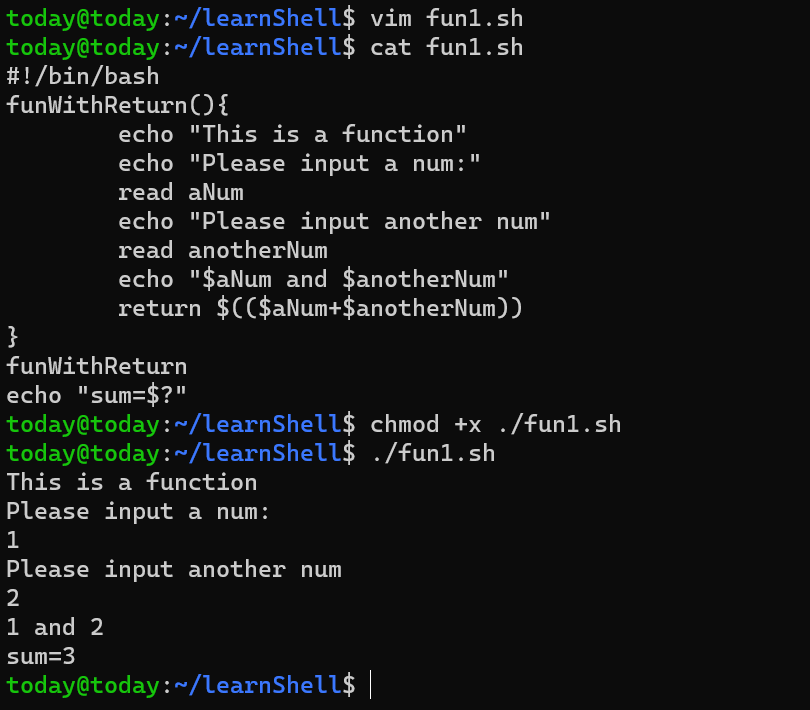
shell脚本入门
实习的时候第一个月的考核就是如何部署一个云资源,当时走的捷径(杠杠的搜索能力hhhh)找到了一个shell脚本一键部署,后来被leader问起来就如实说了,leader问有没有看懂shell脚本中的逻辑……(没有࿰…...
【经典蓝牙】 蓝牙HFP层协议分析
HFP 概述 HFP概念介绍 HFP(Hands-Free Profile), 是蓝牙免提协议, 可以让蓝牙设备对对端蓝牙设备的通话进行控制,例如蓝牙耳机控制手机通话的接听、 挂断、 拒接、 语音拨号等。HFP中蓝牙两端的数据交互是通过定义好的AT指令来通讯的。 &am…...
)
互联网摸鱼日报(2023-02-26)
互联网摸鱼日报(2023-02-26) InfoQ 热门话题 迁移工具 Air2phin 宣布开源,2 步迁移 Airflow 至 Dolphinscheduler 专访奇安信董国伟博士:目前开源安全的现状并不乐观,但其重要性已成各方共识 专访Brian Behlendorf&…...

关于程序员中年危机的一个真实案例
关于中年危机,网上已经有了各种各样的解读。但是,这两天一个学员跟我简单几句聊天,却触发了对于中年危机的另一种思考。如果你曾经也有点迷茫,或许你可以稍微花几分钟看下这个故事。 一、无奈的故事 39岁还出来面试&#x…...
【fly-iot飞凡物联】(2):如何从0打造自己的物联网平台,使用开源的技术栈搭建一个高性能的物联网平台,目前在设计阶段。
目录前言1,fly-iot 飞凡物联2,mqtt-broker 服务3, 管理后台产品/设备设计4,数据存储目前使用mysql,消息存储到influxdb中5,规则引擎使用 ekuiper6, 总结和其他的想法前言 本文的原文连接是: https://blog.csdn.net/freewebsys/article/detail…...
Hadoop MapReduce
目录1.1 MapReduce介绍1.2 MapReduce优缺点MapReduce实例进程阶段组成1.3 Hadoop MapReduce官方示例案例:评估圆周率π(PI)的值案例:wordcount单词词频统计1.4 Map阶段执行流程1.5 Reduce阶段执行流程1.6 Shuffle机制1.1 MapReduc…...
时间复杂度和空间复杂度详解
有一堆数据需要排序,A要使用快速排序,B要使用堆排序,A认为自己的代码更高效,B也认为自己的代码更高效,在这种情况下,怎么来判断谁的代码更好一点呢?这时候就有了时间复杂度和空间复杂度。 目录 …...

【C++】面向对象---封装
【C】面向对象—封装 1.封装的意义 封装是C面向对象三大特性之一 封装的意义: 将属性和行为作为一个整体,表现生活的事物将属性和行为加以权限控制 封装意义一: 在设计类的时候,属性和行为写在一起,表现事物 语…...

Docker简介
一、介绍容器虚拟化技术(带环境安装的一种解决方案)打破程序即应用的观念,透过镜像image将作业系统核心除外,运用应用程序所需要的运行环境,由上而下打包,达到应用程序跨平台间的无缝接轨运作。Docker是基于…...
量化学习(一)数据获取
试验环境 windows10 AnacondaPyCharm(小白参考文章:https://coderx.com.cn/?p14) VM中安装MySQL5.7(设置utf8及相应配置优化) 关于复权 小白参考文章:https://zhuanlan.zhihu.com/p/469820288 数据来源 AK…...

java并发编程讨论:锁的选择
java并发编程 线程堆栈大小 单线程的堆栈大小默认为1M,1000个线程内存就占了1G。所以,受制于内存上限,单纯依靠多线程难以支持大量任务并发。 上下文切换开销 ReentrantLock 2个线程交替自增一个共享变量,使用ReentrantLock&…...

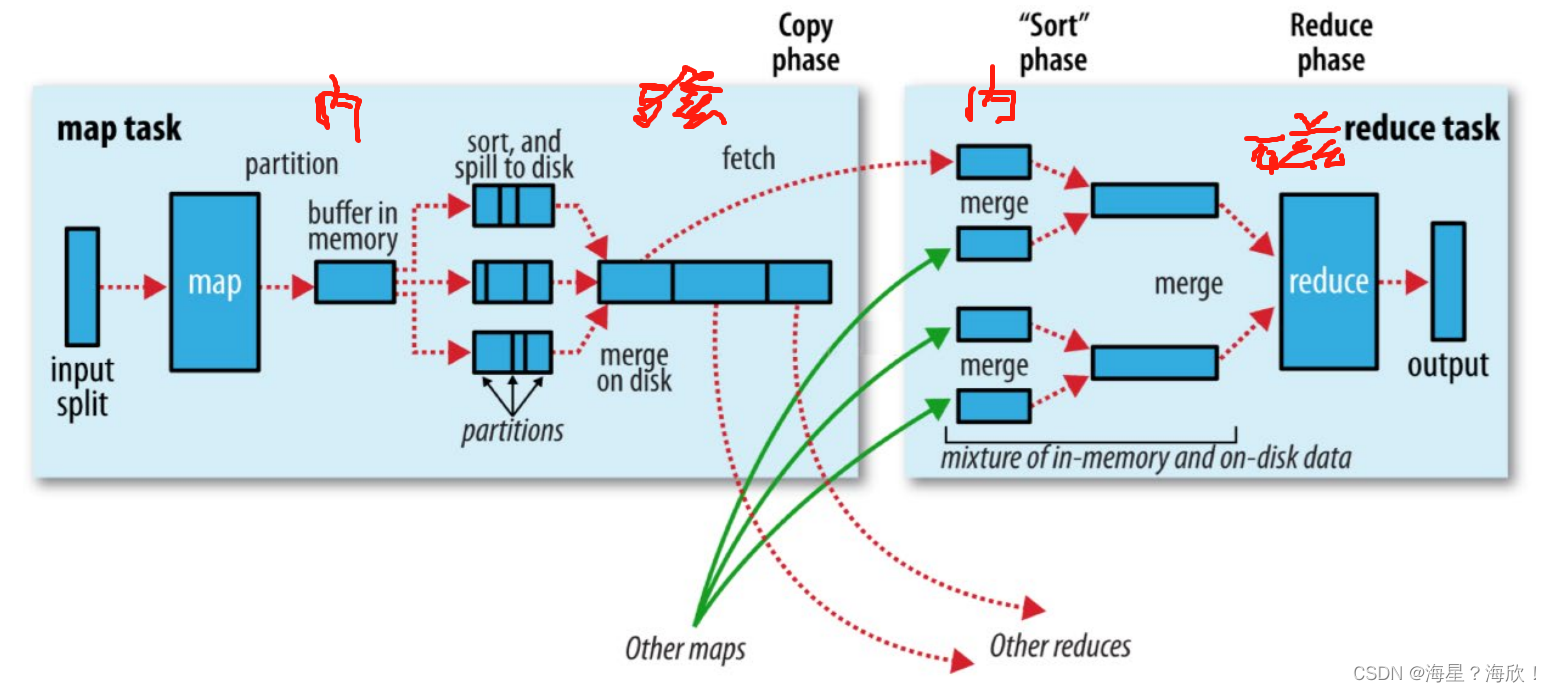
大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——ReduceTask工作机制
1、ReduceTask工作机制 ReduceTask工作机制,如下图所示。 (1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直…...

Nginx的介绍、安装与常用命令
前言:传统结构上(如下图所示)我们只会部署一台服务器用来跑服务,在并发量小,用户访问少的情况下基本够用但随着用户访问的越来越多,并发量慢慢增多了,这时候一台服务器已经不能满足我们了,需要我们增加服务…...

less基础
一、less介绍 1、介绍 是css预处理语言,让css更强大,可以实现在less里面定义变量函数运算等 2、less默认浏览器不识别 less转成csS (框架: less/sass 框架的内置了转码less-css) 3、使用语法 1.创建less文件xxx.less 后缀.less 2. less编译成css 再引入…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...