duboo+zookeeper分布式架构入门
分布式 dubbo + Zookeeper
分布式系统就是若干独立计算机的集合(并且这些计算机之间相互有关联,就像是一台计算机中的C盘F盘等),这些计算对于用户来说就是一个独立的系统。
zookeeper安装
下载地址:Index of /dist/zookeeper/zookeeper-3.4.14 (apache.org)
这里选择3.4.14版本安装
下载完成得到一个压缩包,解压到我们安装的位置,打开解压之后的文件夹中的conf目录,把zoo_sample.cfg这个文件复制一份副本,将副本改名为zoo.cfg任何返回上一级目录,打开bin运行服务端zkServer.cmd,等待服务端运行成功之后运行客户端zkCli.cmd,服务端运行成功可以看见这一段信息 - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181,客户端运行成功看到WATCHER::WatchedEvent state:SyncConnected type:None path:null之后回车会显示[zk: localhost:2181(CONNECTED) 0]表示安装成功
安装dubbo-admin
dubbo-admin是一个监控管理后台,可以查看我们注册了哪些服务和查看哪些服务被消费了
github下载地址:apache/dubbo-admin at master (github.com)
下载之后是源码,这是一个maven项目,我们可以打包之后使用。进入文件夹dubbo-admin-master,执行打包命令
mvn clean package -Dmaven.test.skip=true等待cmd显示build success。打包成功之后开启zookeeper服务端后,进入dubbo-admin-master中的dubbo-admin-service目录,进入target文件夹cmd执行jar包。执行成功之后浏览器输入localhost:8080可以进入dubbo-admin的ui界面。初始密码和初始账号是root
测试分布式架构
新建两个springboot项目模块,一个服务提供商,一个使用者都导入dubbo和zookeeper依赖
<!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-spring-boot-starter -->
<dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo-spring-boot-starter</artifactId><version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.sgroschupf/zkclient -->
<dependency><groupId>com.github.sgroschupf</groupId><artifactId>zkclient</artifactId><version>0.1</version>
</dependency>
<!--zookeeper和springboot会有日志冲突需要排除一个日志的jar包;并且zookeeper需要依赖其他的jar包才能够正常运行-->
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>2.12.0</version>
</dependency>
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>2.12.0</version>
</dependency>
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.4.14</version><!--这里写排除包--><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions>
</dependency>
服务提供商配置
server:port: 8001# 当前服务应用的名字
dubbo:application:name: provider-server
# 注册中心地址registry:address: zookeeper://127.0.0.1:2181
# 配置需要被注册的服务的包地址scan:base-packages: com.zhong.service
这里可能会存在一个问题就是20880端口被占用了,于是项目于启动失败。如果出现这个问题就修改dubbo端口
# 修改端口为20881
dubbo:protocol:name: dubboport: 20881
服务端测试
package com.zhong.service;import org.apache.dubbo.config.annotation.Service;
import org.springframework.stereotype.Component;@Service //因为dubbo的@service注解和springboot的注解名字一样,不容易区分,特别要注意导入的包名
@Component //或者使用组件注解@Component
//使用了注解以后,会自动的注册服务到服务中心(zookeeper)
public class TicketServiceImpl implements TicketService {@Overridepublic String getTicket() {return "hello";}
}
测试服务注册,首先开启zookeeper,然后开启dubbo-admin,再开启项目。正常启动应该能够看到这两个服务被注册

用户配置
server:port: 8002
dubbo:
# 暴露消费者名字application:name: consumer-server
# 配置注册中心地址registry:address: zookeeper://127.0.0.1:2181
用户端这里有两种方式调用远程的接口,一是使用POM坐标(实际开发常用),二是使用新建一个相同的路径名的接口。
package com.zhong.service;import org.apache.dubbo.config.annotation.Reference;
import org.springframework.stereotype.Service;@Service//注意用户端这里的服务需要注入到容器中调用,所以这里是springboot的注解
public class UserService {@Reference//这里是指注入远程的接口,必须新建一个与远程接口包路径相同的接口来接收private TicketService ticketService;public void getTicket() {String ticket = ticketService.getTicket();System.out.println(ticket);}}
之后从容器中拿到注入的本地对象直接调用就可以了
相关文章:
duboo+zookeeper分布式架构入门
分布式 dubbo Zookeeper 分布式系统就是若干独立计算机的集合(并且这些计算机之间相互有关联,就像是一台计算机中的C盘F盘等),这些计算对于用户来说就是一个独立的系统。 zookeeper安装 下载地址:Index of /dist/z…...

黑盒测试用例设计方法-等价类划分法
目录 一、等价类的作用 二、等价类的分类 三、等价类的方法 四、等价类的原则 五、按照测试用例的完整性划分等价类 六、等价类步骤 七、案例 一、等价类的作用 为穷举测试设计测试点。 穷举:列出所有的可能情况,对其一一判断。 测试点&#x…...

4.OCR文本识别Connectionist Temporal Classification(CTC)算法
文章目录1.基础介绍2.Connectionist Temporal Classification(CTC)算法2.1 什么是Temporal Classification2.2 CTC问题描述2.2关于对齐2.3 前向后向算法2.4 推理时3.pytorch中的CTCLOSS参考资料欢迎访问个人网络日志🌹🌹知行空间🌹dz…...

误删了Ubuntu/Linux的一些默认用户目录怎么办?
用户目录:指位于 $HOME 下的一系列常用目录,例如 Documents,Downloads,Music,还有 Desktop等。本文不是讲如何恢复原有目录及其重要文件,适用于仅恢复目录功能一:仅恢复个别目录如误删了Desktop…...
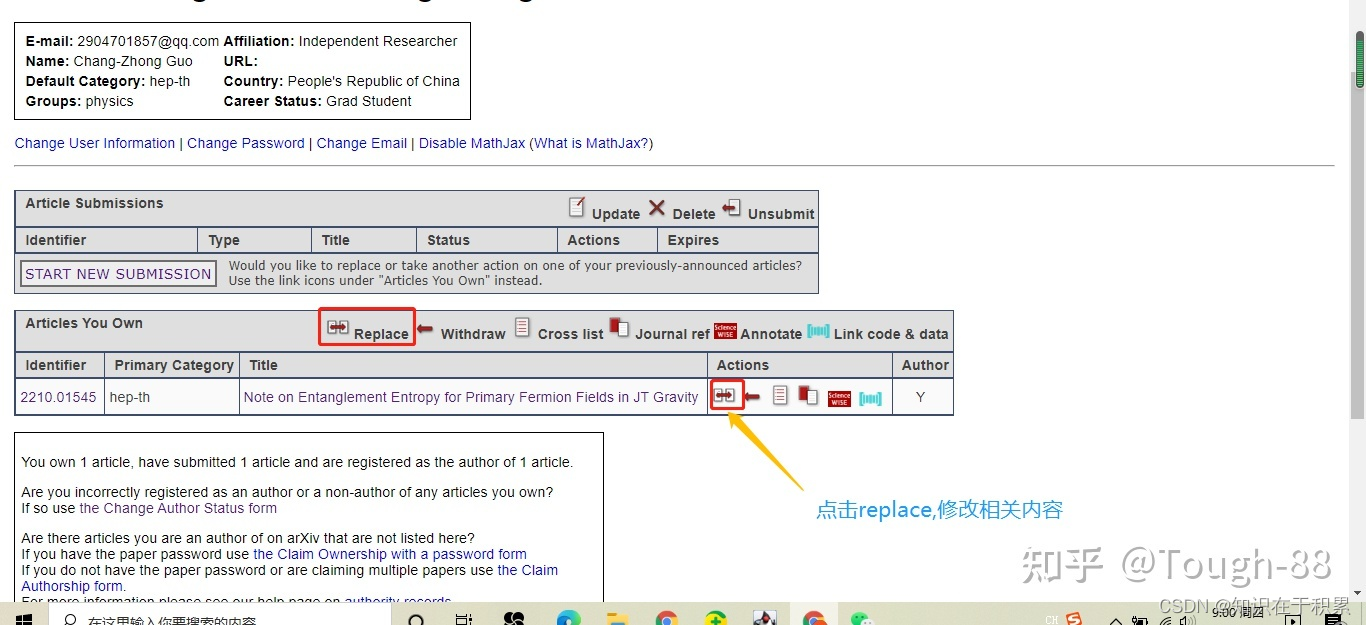
ArXiv简介以及论文提交
arXiv网站简介 arXiv是一个收集物理学、数学、计算机科学、生物学与数理经济学的论文预印本的网站。其中arXiv发音同“archive”,因为“X”代表希腊字母 ,国际音标为[kai]。它于1991年8月14日成立,现由美国康奈尔大学维护。 ——维基百科 对…...

pytorch学习
目录如下: pytorch常用操作 pytorch 常用操作 pytorch 的 detach()函数 1. 什么是detach()函数 我们在将输出特征矩阵进行存储的时候,经常需要将torch.Tensor类型的数据转换成别的如numpy类型的数据,但是Tensor类型的数据是会自动计算梯度…...
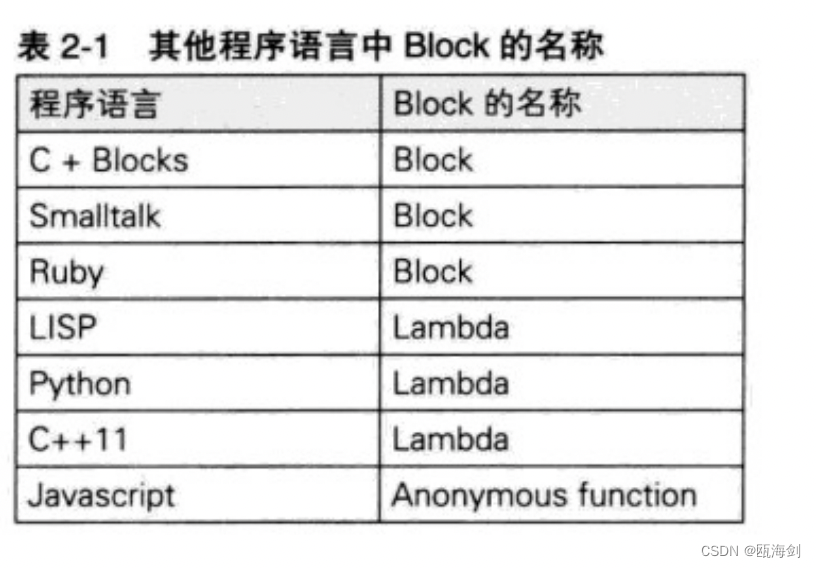
【OC】块初识
Block简介 Blocks是C语言的扩充功能。可以用一句话来表示Blocks的扩充功能:带有自动变量的匿名函数。 匿名函数 所谓匿名函数就是不带有名称的函数。C语言的标准不允许存在这样的函数。例: int func(int count);它声明了名称为func的函数。下面的源代…...
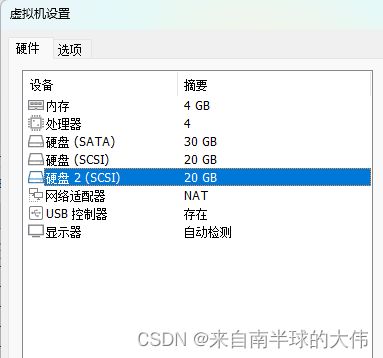
3-2 创建一个至少有两个PV组成的大小为20G的名为testvg的VG
文章目录1. 在vmware添加多块20G的硬盘,并创建分区2. 创建一个至少有两个PV组成的大小为20G的名为testvg的VG,要求PE大小为16M,而后在卷组中创建大小为5G的逻辑卷testlv;挂载至/users目录3. 新建用户archlinux,要求其家目录为/users/archlinu…...

【密码学】 一篇文章讲透数字证书
【密码学】 一篇文章讲透数字证书 数字证书介绍 数字证书是一种用于认证网络通信中参与者身份和加密通信的证书,人们可以在网上用它来识别对方的身份。 我们在上一篇博客中介绍了数字签名的作用和原理,数字签名可以防止消息被否认。有了公钥算法和数字签…...
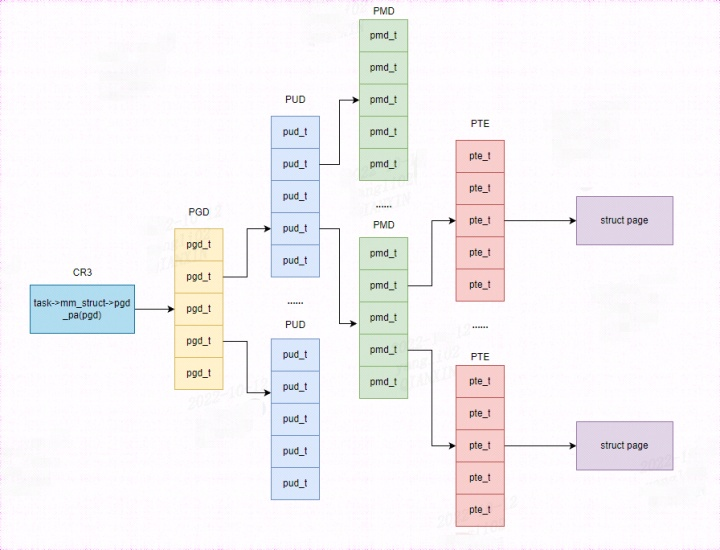
Linux 操作系统原理 — 内存管理 — 虚拟地址空间(x86 64bit 系统)
目录 文章目录目录虚拟地址格式与内核页表(四级页表)虚拟地址格式与内核页表(四级页表) 在 x86 64bit 系统中,可以描述的最长地址空间为 2^64(16EB),远远超过了目前主流内存卡的规格…...
指针的深入理解)
C语言深入知识——(2)指针的深入理解
1、字符指针 (1)字符指针的普通用法 char a A; char* pa &a;但是一般来说字符指针很少这么用……更多是拿来存储一个字符串 (2)字符串的两种存储以及区别 现在有了两种存储数组的方法 ①一个是使用char类型数组存储②另外…...
Git使用笔记
分支branch切换到另一个分支git checkout 你要切换到的分支的名字git checkout master将本地的这个分支branch1和gitee上的branch1进行合并(本地的branch1有的,gitee上branch1没有的增加上去)git merge branch1git merge 分支的名字查看本地是…...

数据库管理-第五十八期 倒腾PDB(20230226)
数据库管理 2023-02-26第五十八期 倒腾PDB1 克隆本地PDB2 没开归档总结第五十八期 倒腾PDB 其实本周过的不大好,连着两天熬夜,一次是割接一次是处理ADG备库的异常,其实本周有些内容是以前处理过的问题,到了周末还肚子痛。哎… 1…...

我看谁还敢说不懂git
文章目录一、Git介绍1.1、Git的作用1.2、Git的理念1.3、Git的特点1.4、Git对比SVN二、Git的概念2.1、Git基础概念三、Git的基本操作3.1、使用Git管理一个代码仓库的流程3.2、Git常用命令介绍四、Git状态的变化五、Git安装和配置5.1、Git的安装5.2、Git的配置六、Git的高级操作6…...

Scratch少儿编程案例-算法练习-实现加减乘除练习题
专栏分享 点击跳转=>Unity3D特效百例点击跳转=>案例项目实战源码点击跳转=>游戏脚本-辅助自动化点击跳转=>Android控件全解手册点击跳转=>Scratch编程案例👉关于作者...
【离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计】
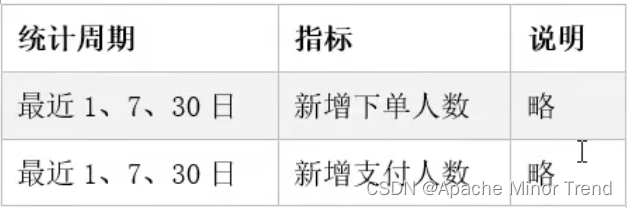
离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计一、DWS层设计要点二、DWS层设计分析 - 1d/nd1.DWS层设计一:不考虑用户维度2.DWS层设计二:考虑用户维度2.DWS层设计三 :考虑用户商…...

python网络数据获取
文章目录1网络爬虫2网络爬虫的类型2.1通用网络爬虫2.1.12.1.22.2聚焦网络爬虫2.2.1 基于内容评价的爬行策略2.2.2 基于链接结构的爬行策略2.2.3基于增强学习的爬行策略2.2.4基于语境图的爬行策略2.3增量式网络爬虫深层网页爬虫3网络爬虫基本架构3.1URL管理模块3.2网页下载模块3…...
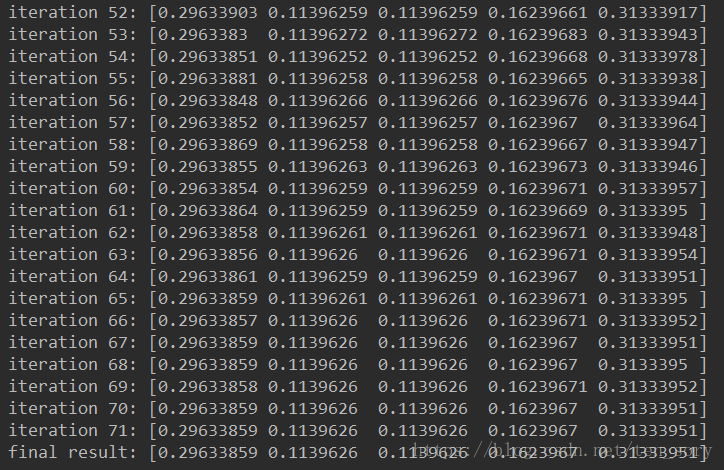
[Datawhale][CS224W]图机器学习(六)
目录一、简介二、概述三、算法四、PageRank的缺点五、Python实现迭代法参考文献一、简介 PageRank,又称网页排名、谷歌左侧排名、PR,是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法。 佩奇排名本质上是一种以网页之间的超链接个…...

aws ecr 使用golang实现的简单镜像转换工具
https://pkg.go.dev/github.com/docker/docker/client#section-readme 通过golang实现一个简单的镜像下载工具 总体步骤 启动一台海外区域的ec2实例安装docker和awscli配置凭证访问国内ecr仓库编写web服务实现镜像转换和自动推送 安装docker和awscli sudo yum remove awsc…...

【20230225】【剑指1】分治算法(中等)
1.重建二叉树class Solution { public:TreeNode* traversal(vector<int>& preorder,vector<int>& inorder){if(preorder.size()0) return NULL;int rootValuepreorder.front();TreeNode* rootnew TreeNode(rootValue);//int rootValuepreorder[0];if(preo…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...