【Spark分布式内存计算框架——Spark Streaming】3.入门案例(上)官方案例运行
2.1 官方案例运行
运行官方提供案例,使用【$SPARK_HOME/bin/run-example】命令运行,效果如下:
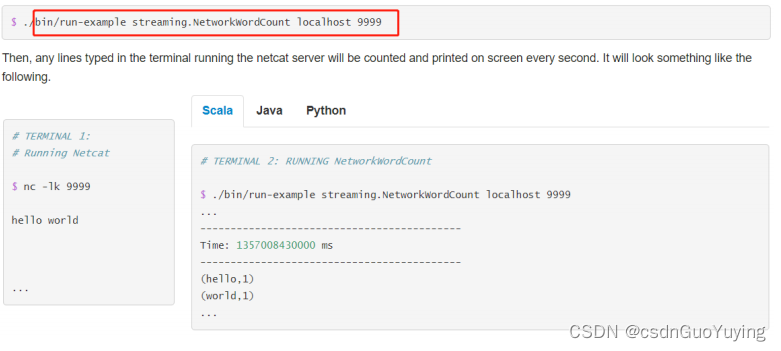
具体步骤如下:
第一步、准备数据源启动端口,准备数据
nc -lk 9999
spark spark hive hadoop spark hive
第二步、运行官方案例
- 使用官方提供命令行运行案例
# 官方入门案例运行:词频统计
/export/server/spark/bin/run-example --master local[2] streaming.NetworkWordCount node1.itcast.cn 9999
第三步、运行结果

SparkStreaming模块对流式数据处理,介于Batch批处理和RealTime实时处理之间处理数据方式。
2.2 编程实现
基于IDEA集成开发环境,编程实现:从TCP Socket实时读取流式数据,对每批次中数据进行词频统计WordCount。
StreamingContext
回顾SparkCore和SparkSQL及SparkStreaming处理数据时编程:
1)、SparkCore
- 数据结构:RDD
- SparkContext:上下文实例对象
2)、SparkSQL
- 数据结构:Dataset/DataFrame = RDD + Schema
- SparkSession:会话实例对象, 在Spark 1.x中SQLContext/HiveContext
3)、SparkStreaming
- 数据结构:DStream = Seq[RDD]
- StreamingContext:流式上下文实例对象,底层还是SparkContext
- 参数:划分流式数据时间间隔BatchInterval:1s,5s(演示)
文档:http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#initializing-streamingcontext
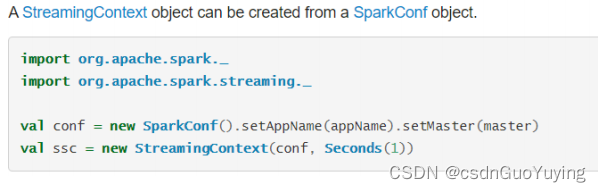
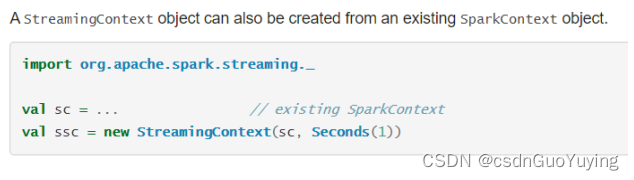
从官方文档可知,提供两种方式构建StreamingContext实例对象,截图如下:
第一种方式:构建SparkConf对象
第二种方式:构建SparkContext对象
编写代码
针对SparkStreaming流式应用来说,代码逻辑大致如下五个步骤:
1、Define the input sources by creating input DStreams.
定义从哪个数据源接收流式数据,封装到DStream中
2、Define the streaming computations by applying transformation and output operations to DStreams.
针对业务调用DStream中函数,进行数据处理和输出
3、Start receiving data and processing it using streamingContext.start().
4 、 Wait for the processing to be stopped (manually or due to any error) using streamingContext.awaitTermination().
5、The processing can be manually stopped using streamingContext.stop().
启动流式应用,并且一直等待程序终止(人为或异常),最后停止运行
完整StreamingWordCount代码如下所示:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object StreamingWordCount {
def main(args: Array[String]): Unit = {
// TODO: 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// TODO: 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(
"node1.itcast.cn", 9999
)
// TODO: 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = inputDStream
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
// TODO: 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
运行结果监控截图:
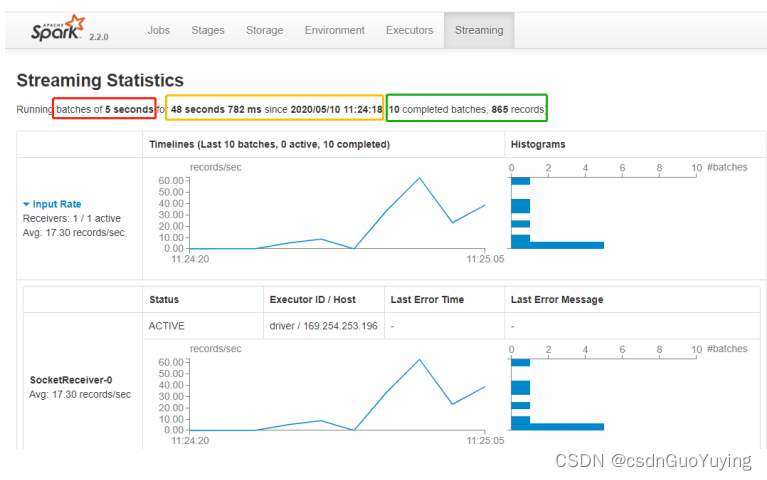
Streaming 应用监控
运行上述词频统计案例,登录到WEB UI监控页面:http://localhost:4040,查看相关监控信息。
其一、Streaming流式应用概要信息
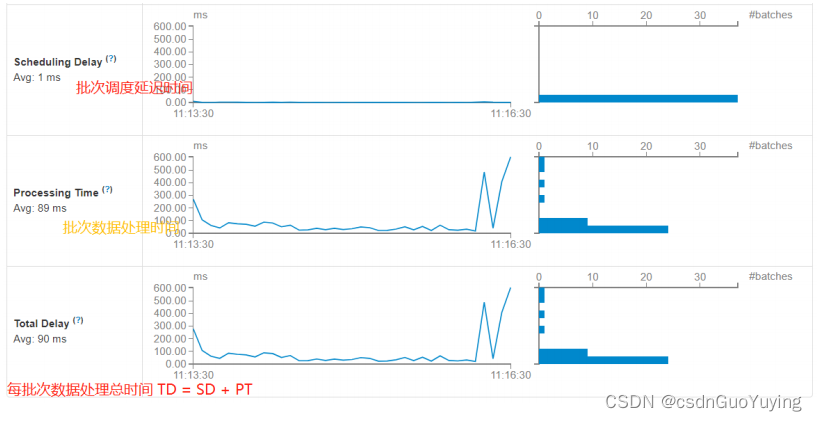
每批次Batch数据处理总时间TD = 批次调度延迟时间SD + 批次数据处理时间PT。
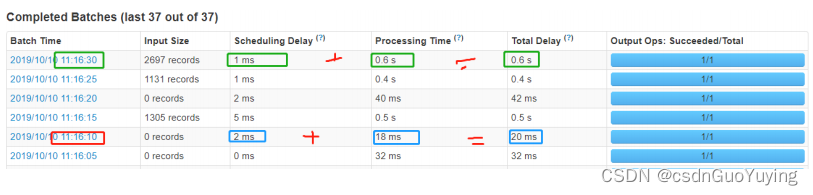
其二、性能衡量标准
SparkStreaming实时处理数据性能如何(是否可以实时处理数据)??如何衡量的呢??
每批次数据处理时间TD <= BatchInterval每批次时间间隔
相关文章:
【Spark分布式内存计算框架——Spark Streaming】3.入门案例(上)官方案例运行
2.1 官方案例运行 运行官方提供案例,使用【$SPARK_HOME/bin/run-example】命令运行,效果如下: 具体步骤如下: 第一步、准备数据源启动端口,准备数据 nc -lk 9999 spark spark hive hadoop spark hive 第二步、运行…...

【博学谷学习记录】超强总结,用心分享 | 架构师 Tomcat源码学习总结
文章目录TomcatTomcat功能需求分析Tomcat两个非常重要的功能(身份)Tomcat的架构(设计实现)连接器的设计连接器架构分析核心功能ProtocolHandler 组件1.EndPoint组件EndPoint类结构图2.Processor组件Processor类结构图3.Adapter组件…...
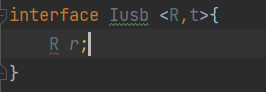
泛型<E>
泛型 案例引出泛型 按要求写出代码: 在ArrayList中添加3个Dog对象,Dog对象有name和age两个属性,且输出name和age public class test1 {public static void main(String[] args) {ArrayList list new ArrayList();list.add(new Dog(10,&quo…...

你对MANIFEST.MF这个文件知道多少?
前言我们在读源码过程中,经常看到每个jar包的METE-INF目录下有个MANIFEST.MF文件,这个文件到底是做什么的呢?在计算机领域中,"manifest" 通常指的是一份清单或概要文件,用于描述一组文件或资源的内容和属性。…...

史上最经典垃圾回收器(CMS,G1)详解、适用场景及特点、使用命令
文章目录垃圾收集器介绍总结各个垃圾收集器之间的关系垃圾收集器使用命令及默认值详解各个垃圾收集器SerialParNewParallel ScavengeSerial OldParallel OldCMS(Concurrent Mark Sweep)G1(Garbage First)适用场景及推荐垃圾收集器介绍总结 垃圾收集器可以帮助我们进行具体的垃…...

Hive查询中的优化
目录前言优化策略推荐使用group by代替distinct去重前言 优化策略 推荐使用group by代替distinct去重 参考: hive中groupby和distinct区别以及性能比较 - cnblogs数据倾斜之count(distinct) - cnblogs 重要结论: 两者都会在map阶段count,…...

【开发规范】go项目开发中的[流程,git,代码,目录,微服务仓库管理,静态检查]
文章目录前言一、有哪些规范我们应该遵循二、项目开发流程三、git的代码分支管理1. 分支管理2. commit规范三、go的代码规范四、go项目目录规范五、微服务该采用multi-repo还是mono-repo?1. 引言2. Repos 是什么?3. 什么是 Mono-repo?4. Mono-repo 的劣势5. 什么是…...

数组初始化方式与decimal.InvalidOperation
数组初始化方式与decimal.InvalidOperation调用函数主函数: 数组声明不同带来的报错与否1. 报错decimal.InvalidOperation的数组初始化版本2. 可行的初始化版本输出结果1. 报错时的内容2. 正常的输出计算结果原因(是否是数组与列表不同引起(?…...
【Opencv-python】之入门安装
目录 一、安装Python 1. 登录官网https://www.python.org/downloads/ 2. 任选一个版本,下载Python 3. 安装Python 记得勾选下图的Add Python 3.6 PATH, 添加python到环境变量的路径,然后选择Install now编辑 4. 验证是否安装成功 5.退出 二、安装…...

MySQL进阶(二)
目录 1、视图 1、检查选项 2、视图的更新 3、视图作用 2、存储过程 1、语法 2、变量 1、系统变量 2、用户定义变量 3、局部变量 3、if 4、参数 5、case 6、循环 1、while 2、repeat 3、loop 7、游标、条件处理程序 8、存储函数 3、触发器 4、锁 1、全局锁 2、表级锁 …...
热爱所有热爱
想成为这样的一个人,在工作中是一名充满极客精神的Programmer,处理遇到的问题能够游刃有余,能够做出优雅的设计,写出一手优秀的代码,还有着充分的学习能力和业务能力,做一名职场中的佼佼者。 在工作之余还能…...
)
Redis学习之数据删除与淘汰策略(七)
这里写目录标题一、Redis数据特征二、过期数据三、过期数据删除策略3.1 数据删除策略的目标3.2 定时删除3.3 惰性删除3.4 定期删除3.5 删除策略对比3.6 实际应用四、数据淘汰策略4.1 淘汰策略概述4.2 策略配置一、Redis数据特征 Redis是一种内存级数据库,所有的数据…...

HashMap 面试专题
1、HashMap 的底层结构 ①JDK1.8 以前 JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的hashCode 函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度…...
域组策略自动更新实验报告
域组策略自动更新实验报告 域组策略自动更新实验报告 作者: 高兴源 1要求、我公司为了完善员工的安全性和系统正常漏洞的维护,所以采用域组策略自动更新的方法来提高账户安全性,减少了用户的错误。 1.实验环境如下1台2008r2一台创建域,一台wi…...

Java自定义生成二维码(兼容你所有的需求)
1、概述作为Java开发人员,说到生成二维码就会想到zxing开源二维码图像处理库,不可否认的是zxing确实很强大,但是实际需求中会遇到各种各样的需求是zxing满足不了的,于是就有了想法自己扩展zxing满足历史遇到的各种需求,…...

Spring事务的隔离级别
事务隔离级别解决的是多个事务同时调⽤⼀个数据库的问题 事务传播机制解决的是⼀个事务在多个节点(⽅法)中传递的问题 事务的特性: 隔离性:多个事务在并发执行的时候,多个事务执行的一个行为模式,当一个事务执行的时候,另一个事务执行的一个行…...

JVM系统优化实践(4):以支付系统为例
您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~前面说过,JVM会将堆内存划分为年轻代、老年代两个区域。年轻代会将创建和使用完之后马上就要回收的对象放在里面,而老年代则将创建之后需要…...

16- TensorFlow实现线性回归和逻辑回归 (TensorFlow系列) (深度学习)
知识要点 线性回归要点: 生成线性数据: x np.linspace(0, 10, 20) np.random.rand(20)画点图: plt.scatter(x, y)TensorFlow定义变量: w tf.Variable(np.random.randn() * 0.02)tensor 转换为 numpy数组: b.numpy()定义优化器: optimizer tf.optimizers.SGD()定义损失: …...

无自动化测试系统设计方法论
灵活 敏捷 迭代。 自动化测试 辩思 测试必不可少 想想看没有充分测试的代码, 哪一次是一次过的? 哪一次不需要经历下测试的鞭挞? 不要以为软件代码容易改, 就对于质量不切实际的自信—那是自大! 不适用自动化测试的case 遗留系统。太多的依赖方, 不想用过多的mock > …...
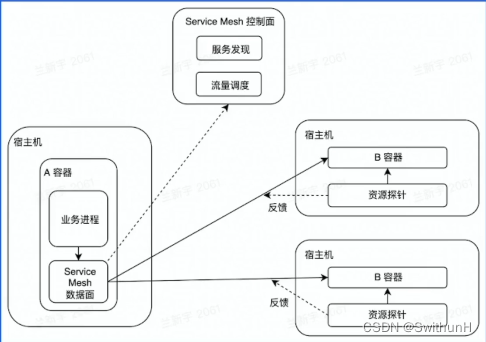
架构初探-学习笔记
1 什么是架构 有关软件整体结构与组件的抽象描述,用于指导软件系统各个方面的设计。 1.1 单机架构 所有功能都实现在一个进程里,并部署在一台机器上。 1.2 单体架构 分布式部署单机架构 1.3 垂直应用架构 按应用垂直切分的单体架构 1.4 SOA架构 将…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...