数据结构基础之栈和队列
目录
前言
1、栈
2、队列
2.1、实现队列
2.2、循环队列
前言
上一篇中我们介绍了数据结构基础中的《动态数组》,本篇我们继续来学习两种基本的数据结构——栈和队列。
1、栈
特点:栈也是一种线性结构,相比数组,栈对应的操作是数组的子集,只能从一端添加元素,也只能从同一端取出元素,这一端称为栈顶。栈是一种后进先出的数据结构,即Last In First Out(LIFO)。
上面说到栈对应的操作是数组的子集,因此我们就基于上一篇中实现的动态数组来快速的实现一个栈。
首先定义一个接口,定义相关功能方法:

然后让栈来实现接口中的具体功能:
import arr.Array;public class ArrayStack<E> implements Stack<E> {Array<E> array;public ArrayStack(int capacity) {array = new Array<>(capacity);}public ArrayStack() {array = new Array<>();}public int getCapacity() {return array.getCapacity();}@Overridepublic int getSize() {return array.getSize();}@Overridepublic boolean isEmpty() {return array.isEmpty();}@Overridepublic void push(E e) {array.addLast(e);}@Overridepublic E pop() {return array.removeLast();}@Overridepublic E peek() {return array.getLast();}@Overridepublic String toString() {StringBuilder res = new StringBuilder();res.append("Stack").append("[");for (int i = 0; i < array.getSize(); i++) {res.append(array.get(i));if (i != array.getSize() - 1) {res.append(",");}}res.append("] Top");return res.toString();}
}写一个测试方法:

执行结果如下:

2、队列
2.1、实现队列
队列也是一种线性结构,相比数组,队列对应的操作也是数组的子集,队列只能从一端(队尾)添加元素,只能从另一端(队首)取出元素。队列是一种先进先出的数据结构(先到先得),即:First In First Out(FIFO)。
由于队列对应的操作同样是数组的子集,那么我们让然也是基于上一篇中实现的动态数组来快速的实现一个栈。
定义一个接口,定义相关功能方法:

然后让队列来实现接口中的具体功能:
import arr.Array;public class ArrayQueue<E> implements Queue<E> {private Array<E> array;public ArrayQueue(int capacity) {array = new Array<>(capacity);}public ArrayQueue(){array = new Array<>();}public int getCapacity(){return array.getCapacity();}@Overridepublic int getSize() {return array.getSize();}@Overridepublic boolean isEmpty() {return array.isEmpty();}@Overridepublic void enqueue(E e) {array.addLast(e);}@Overridepublic E dequeue() {return array.removeFirst();}@Overridepublic E getFront() {return array.getFirst();}@Overridepublic String toString() {StringBuilder res = new StringBuilder();res.append("Queue:").append("Front [");for (int i = 0; i < array.getSize(); i++) {res.append(array.get(i));if (i != array.getSize() - 1) {res.append(",");}}res.append("] tail");return res.toString();}
}同样的写一个测试类:

执行结果如下:

2.2、循环队列
初始时front和tail都是指向下标为0的位置,当有元素入队时,tail指向该元素的下一个位置((tail+1)%capacity),元素出队时,front向后移动一个位置,因此,循环队列有元素出队时,无需让所有的元素都移动一个位置,只需让front的指向移动一次即可,示意图如下:


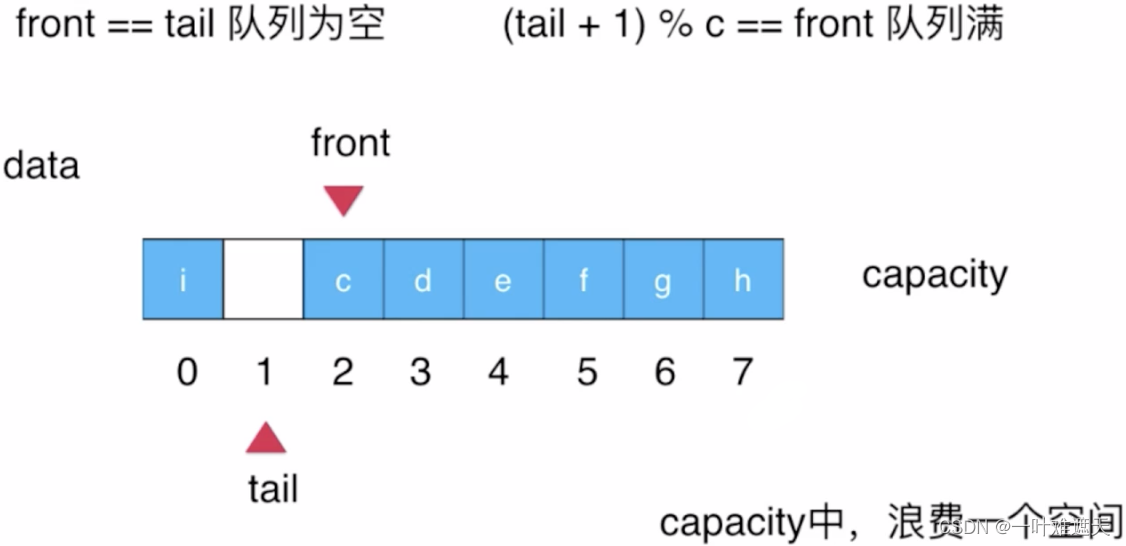
下面我们来通过代码看一下循环队列该怎么实现:
public class LoopQueue<E> implements Queue<E> {private E[] data;private int front, tail;private int size;public LoopQueue(int capacity) {data = (E[]) new Object[capacity + 1];front = 0;tail = 0;size = 0;}public LoopQueue() {this(10);}public int getCapacity() {return data.length - 1;}@Overridepublic int getSize() {return size;}@Overridepublic boolean isEmpty() {return front == tail;}@Overridepublic void enqueue(E e) {if ((tail + 1) % data.length == front) {resize(getCapacity() * 2);}data[tail] = e;tail = (tail + 1) % data.length;size++;}private void resize(int newCapacity) {E[] newdata = (E[]) new Object[newCapacity + 1];for (int i = 0; i < size; i++) {newdata[i] = data[(i + front) % data.length];}data = newdata;front = 0;tail = size;}@Overridepublic E dequeue() {if (isEmpty()) {throw new IllegalArgumentException("队列为空");}E ret = data[front];data[front] = null;front = (front + 1) % data.length;size--;if (size == getCapacity() / 4 && getCapacity() / 2 != 0) {resize(getCapacity() / 2);}return null;}@Overridepublic E getFront() {if (isEmpty()) {throw new IllegalArgumentException("队列为空");}return data[front];}@Overridepublic String toString() {StringBuilder res = new StringBuilder();res.append(String.format("Queue: size=%d,capacity=%d\n", size, getCapacity())).append("front [");for (int i = front; i != tail; i = (i + 1) % data.length) {res.append(data[i]);if ((i+1)%data.length != tail) {res.append(",");}}res.append("] tail");return res.toString();}
}同样的测试程序:
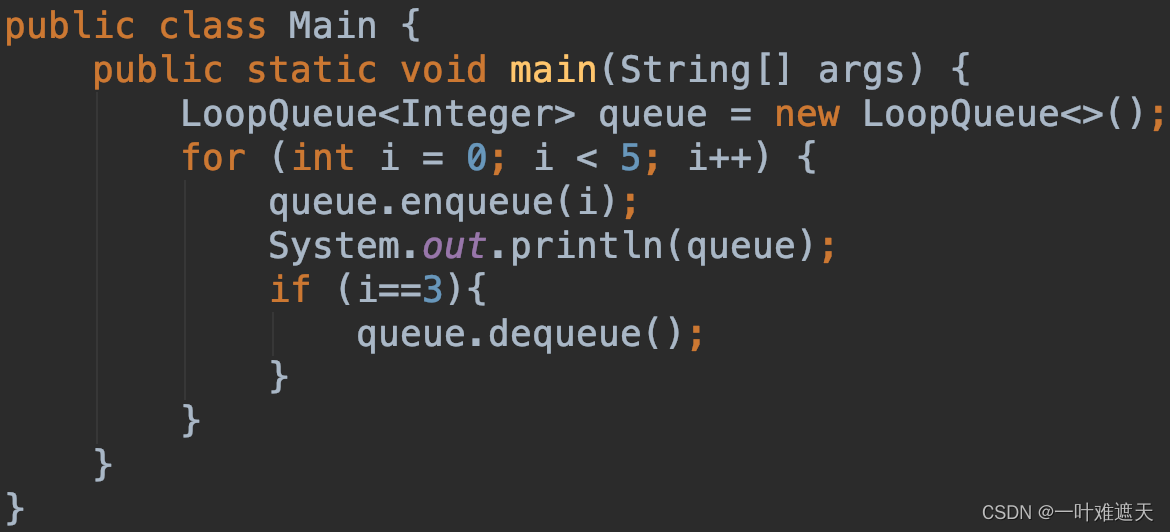
执行结果如下:
好了,关于栈和队列的内容就说这么多吧,咱们下期再会!
祝:工作顺利!
相关文章:
数据结构基础之栈和队列
目录 前言 1、栈 2、队列 2.1、实现队列 2.2、循环队列 前言 上一篇中我们介绍了数据结构基础中的《动态数组》,本篇我们继续来学习两种基本的数据结构——栈和队列。 1、栈 特点:栈也是一种线性结构,相比数组ÿ…...
【Spark分布式内存计算框架——Spark Streaming】3.入门案例(上)官方案例运行
2.1 官方案例运行 运行官方提供案例,使用【$SPARK_HOME/bin/run-example】命令运行,效果如下: 具体步骤如下: 第一步、准备数据源启动端口,准备数据 nc -lk 9999 spark spark hive hadoop spark hive 第二步、运行…...

【博学谷学习记录】超强总结,用心分享 | 架构师 Tomcat源码学习总结
文章目录TomcatTomcat功能需求分析Tomcat两个非常重要的功能(身份)Tomcat的架构(设计实现)连接器的设计连接器架构分析核心功能ProtocolHandler 组件1.EndPoint组件EndPoint类结构图2.Processor组件Processor类结构图3.Adapter组件…...
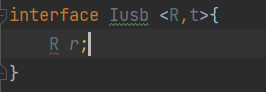
泛型<E>
泛型 案例引出泛型 按要求写出代码: 在ArrayList中添加3个Dog对象,Dog对象有name和age两个属性,且输出name和age public class test1 {public static void main(String[] args) {ArrayList list new ArrayList();list.add(new Dog(10,&quo…...

你对MANIFEST.MF这个文件知道多少?
前言我们在读源码过程中,经常看到每个jar包的METE-INF目录下有个MANIFEST.MF文件,这个文件到底是做什么的呢?在计算机领域中,"manifest" 通常指的是一份清单或概要文件,用于描述一组文件或资源的内容和属性。…...

史上最经典垃圾回收器(CMS,G1)详解、适用场景及特点、使用命令
文章目录垃圾收集器介绍总结各个垃圾收集器之间的关系垃圾收集器使用命令及默认值详解各个垃圾收集器SerialParNewParallel ScavengeSerial OldParallel OldCMS(Concurrent Mark Sweep)G1(Garbage First)适用场景及推荐垃圾收集器介绍总结 垃圾收集器可以帮助我们进行具体的垃…...

Hive查询中的优化
目录前言优化策略推荐使用group by代替distinct去重前言 优化策略 推荐使用group by代替distinct去重 参考: hive中groupby和distinct区别以及性能比较 - cnblogs数据倾斜之count(distinct) - cnblogs 重要结论: 两者都会在map阶段count,…...

【开发规范】go项目开发中的[流程,git,代码,目录,微服务仓库管理,静态检查]
文章目录前言一、有哪些规范我们应该遵循二、项目开发流程三、git的代码分支管理1. 分支管理2. commit规范三、go的代码规范四、go项目目录规范五、微服务该采用multi-repo还是mono-repo?1. 引言2. Repos 是什么?3. 什么是 Mono-repo?4. Mono-repo 的劣势5. 什么是…...

数组初始化方式与decimal.InvalidOperation
数组初始化方式与decimal.InvalidOperation调用函数主函数: 数组声明不同带来的报错与否1. 报错decimal.InvalidOperation的数组初始化版本2. 可行的初始化版本输出结果1. 报错时的内容2. 正常的输出计算结果原因(是否是数组与列表不同引起(?…...
【Opencv-python】之入门安装
目录 一、安装Python 1. 登录官网https://www.python.org/downloads/ 2. 任选一个版本,下载Python 3. 安装Python 记得勾选下图的Add Python 3.6 PATH, 添加python到环境变量的路径,然后选择Install now编辑 4. 验证是否安装成功 5.退出 二、安装…...

MySQL进阶(二)
目录 1、视图 1、检查选项 2、视图的更新 3、视图作用 2、存储过程 1、语法 2、变量 1、系统变量 2、用户定义变量 3、局部变量 3、if 4、参数 5、case 6、循环 1、while 2、repeat 3、loop 7、游标、条件处理程序 8、存储函数 3、触发器 4、锁 1、全局锁 2、表级锁 …...
热爱所有热爱
想成为这样的一个人,在工作中是一名充满极客精神的Programmer,处理遇到的问题能够游刃有余,能够做出优雅的设计,写出一手优秀的代码,还有着充分的学习能力和业务能力,做一名职场中的佼佼者。 在工作之余还能…...
)
Redis学习之数据删除与淘汰策略(七)
这里写目录标题一、Redis数据特征二、过期数据三、过期数据删除策略3.1 数据删除策略的目标3.2 定时删除3.3 惰性删除3.4 定期删除3.5 删除策略对比3.6 实际应用四、数据淘汰策略4.1 淘汰策略概述4.2 策略配置一、Redis数据特征 Redis是一种内存级数据库,所有的数据…...

HashMap 面试专题
1、HashMap 的底层结构 ①JDK1.8 以前 JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的hashCode 函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度…...
域组策略自动更新实验报告
域组策略自动更新实验报告 域组策略自动更新实验报告 作者: 高兴源 1要求、我公司为了完善员工的安全性和系统正常漏洞的维护,所以采用域组策略自动更新的方法来提高账户安全性,减少了用户的错误。 1.实验环境如下1台2008r2一台创建域,一台wi…...

Java自定义生成二维码(兼容你所有的需求)
1、概述作为Java开发人员,说到生成二维码就会想到zxing开源二维码图像处理库,不可否认的是zxing确实很强大,但是实际需求中会遇到各种各样的需求是zxing满足不了的,于是就有了想法自己扩展zxing满足历史遇到的各种需求,…...

Spring事务的隔离级别
事务隔离级别解决的是多个事务同时调⽤⼀个数据库的问题 事务传播机制解决的是⼀个事务在多个节点(⽅法)中传递的问题 事务的特性: 隔离性:多个事务在并发执行的时候,多个事务执行的一个行为模式,当一个事务执行的时候,另一个事务执行的一个行…...

JVM系统优化实践(4):以支付系统为例
您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~前面说过,JVM会将堆内存划分为年轻代、老年代两个区域。年轻代会将创建和使用完之后马上就要回收的对象放在里面,而老年代则将创建之后需要…...

16- TensorFlow实现线性回归和逻辑回归 (TensorFlow系列) (深度学习)
知识要点 线性回归要点: 生成线性数据: x np.linspace(0, 10, 20) np.random.rand(20)画点图: plt.scatter(x, y)TensorFlow定义变量: w tf.Variable(np.random.randn() * 0.02)tensor 转换为 numpy数组: b.numpy()定义优化器: optimizer tf.optimizers.SGD()定义损失: …...

无自动化测试系统设计方法论
灵活 敏捷 迭代。 自动化测试 辩思 测试必不可少 想想看没有充分测试的代码, 哪一次是一次过的? 哪一次不需要经历下测试的鞭挞? 不要以为软件代码容易改, 就对于质量不切实际的自信—那是自大! 不适用自动化测试的case 遗留系统。太多的依赖方, 不想用过多的mock > …...

亚洲美女-造相Z-Turbo效果对比:Z-Image-Turbo基模 vs LoRA微调版实测分析
亚洲美女-造相Z-Turbo效果对比:Z-Image-Turbo基模 vs LoRA微调版实测分析 想用AI画出好看的亚洲美女图片,但总觉得生成的图片风格不对味,或者细节不够精致?今天,我们就来实测一个专门针对亚洲美女形象进行优化的AI绘画…...

AI开发实战:从Cursor配置到Unity-MCP部署,打通AI自动化游戏开发链路
1. 为什么你需要AI自动化游戏开发工具 作为一个独立游戏开发者,我深知从零开始制作一款游戏有多难。光是写代码就要耗费大量时间,更别提还要处理Unity引擎里各种复杂的资源管理。直到我发现了Cursor和Unity-MCP这对黄金组合,开发效率直接提升…...

Mi-Create:3步打造个性化小米手表表盘的开源神器
Mi-Create:3步打造个性化小米手表表盘的开源神器 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 厌倦了千篇一律的智能手表表盘?想让你…...

创新屏幕色温调节技术:LightBulb如何通过智能伽马控制告别数字眼疲劳
创新屏幕色温调节技术:LightBulb如何通过智能伽马控制告别数字眼疲劳 【免费下载链接】LightBulb Reduces eye strain by adjusting gamma based on the current time 项目地址: https://gitcode.com/gh_mirrors/li/LightBulb 在数字时代,屏幕色温…...

语音识别SDK全平台集成指南:从技术原理到性能优化
语音识别SDK全平台集成指南:从技术原理到性能优化 【免费下载链接】wenet Production First and Production Ready End-to-End Speech Recognition Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wenet 在移动应用智能化浪潮中,语音交互已…...

C++20 Concepts 完全实战指南:告别 SFINAE,让模板约束更清晰
从「编译期报错 wall of text」到「简洁直观的约束表达式」,Concepts 是 C20 送给模板元编程开发者的最佳礼物。 引言:模板编程的痛点 作为 C 开发者,你一定经历过这样的绝望时刻: template<typename T> void process(T&a…...

SolidWorks模型渲染图测试:cv_resnet101_face-detection对3D合成人脸的检测能力
SolidWorks模型渲染图测试:cv_resnet101_face-detection对3D合成人脸的检测能力 最近在做一个挺有意思的小实验,想看看现在的人脸检测模型,在面对那些“看起来像真人,但其实是电脑画出来”的3D人脸时,到底能不能认出来…...

2026企业云盘/文件管理软件推荐:14款热门工具横评
本文将深入对比14款企业文件管理备份软件:亿方云、Worktile、蓝奏云、金山文档、傲梅轻松备份、Zoho WorkDrive、一粒云、联想企业网盘、百度网盘、阿里云盘、腾讯微云、Dropbox Business、坚果云、天翼企业云盘 在数字化程度高度发达的 2026 年,数据已成…...

基于庞特里亚金极小值原理PMP的燃料电池混合动力系统能量管理方法探索
基于庞特里亚金极小值原理PMP的燃料电池混合动力系统能量管理方法 注:1、该方法基于matlab的.m文件编写 2、采用等效氢耗和变载衰变作为损失函数 3、可作为对比,和扩展使用。在当今追求可持续能源的时代,燃料电池混合动力系统的能量管理显得尤为重要。今…...

MATLAB里给二自由度机械臂装上‘智能大脑’:手把手实现模糊PID轨迹跟踪仿真
为二自由度机械臂注入智能:模糊PID控制的MATLAB实战解析 在机器人控制领域,让机械臂精准跟踪预定轨迹一直是个令人着迷的挑战。传统PID控制器虽然结构简单,但在面对复杂非线性系统时往往力不从心。想象一下,如果给机械臂装上能够&…...