MySQL EXPLAIN查看执行计划
MySQL 执⾏计划是 MySQL 查询优化器分析 SQL 查询时⽣成的⼀份详细计划,包括表如何连 接、是否⾛索引、表扫描⾏数等。通过这份执⾏计划,我们可以分析这条 SQL 查询中存在的 问题(如是否出现全表扫描),从⽽进⾏针对优化。
我们可以通过EXPLAIN来查询我们SQL的执行计划。
EXPLAIN
各字段的含义
Id
SELECT查询的序列号,表示执行SELECT 子句的顺序(
Id相同,从上往下执行,Id不同,值越大越先执行。)
select_type
查询类型,来区分简单查询、联合查询、⼦查询等。
常⻅的类型有:
- SIMPLE:简单查询,不包含表连接或⼦查询
- PRIMARY:主查询,外层的查询
- SUBQUERY:⼦查询中第⼀个
- SELECT UNION:UNION 后⾯的 SELECT 查询语句
- UNION RESULT:UNION 合并的结果
table
查询的表名(也可以是别名)
partitions
匹配的分区,没有分区的表为 NULL
type*
扫描表的方式。
常见的类型有:(性能从上到下,越来越差)
system
表中只有一行数据(系统表),这是const类型的特殊情况;
const
最多返回一条匹配的数据在查询的最开始读取。
因为是通过主键来查询的,然后我们的1也是常量级的,所以类型是const。

eq_ref
在连接查询中
被驱动表使用主键或者唯一键进行连接的时候。(被驱动表只返回一行数据),类似于外键查询。

ref
在连接查询中
被驱动表使用普通索引进行连接的时候,或者在普通查询的WHERE条件中使用索引,基于这个索引来匹配表中所有的行。(也就是在查询前就知道可能会返回多条数据)


fulltext
使用全文索引查询数据。
ref_of_null
在
ref的基础,额外添加了对NULL值的查找。
在join中也可使用


index_merge
索引合并在
key列中会显示所有使用到的索引。类似于有两个条件,这两个条件都有索引,用OR进行连接的话,最后会通过两个索引查询的所有主键值来进行合并(并集)。这个称之为`索引合并。

key列中,可以看见我们使用了两个索引
range
使用索引进行范围查找。
像between,>=,>,<,<=这种查询都是范围查询。
like前缀的模糊查询也是范围查找。


index
虽然用到了索引,但是是扫描了所有的索引。

ALL
全表扫描。(注意:全表扫描并不代表就是最差的方案,就比方你本身就需要全部表的数据,你使用全表扫描还能用什么呢?)

possible_keys
这一列显示查询可能使用那些索引来查找。
explain 中有可能possible_keys中有值,但是我们的key中显示NULL的情况,这种因为表中的数据不多,MySQL认为对此查询帮助不大,选择了全表查询。
key
实际采用了那个索引。
如果没有使用索引时,我们可以通过force index,ignore index,来强制使用某个索引或者忽略某个索引。
key_len
表示使用
key中索引的长度。
我们创建了一个b_c_d(三个字段的联合索引)。
这里可以用的b=4来进行查询。key列中存在我们的索引,但是注意key_len是5,代表我们使用到了部分索引。
当我们使用b=4 and c=4,这样里的key_len是10
当我们使用b = 4 and c = 4 and d = 4,这样里的key_len是15
这里的计算方式是,1个int类型的索引是4个字节,又因为这个字段是允许为空的,所有的加+1位,则是5个字节。所有可以通过观察key_len,来判断索引是否被充分使用。



key_len 计算规则
字符串
如果是utf-8,则一个数字与一个字符占一个字节,一个汉字占3个字节
- char:如果存汉字就是3n字节
- varchar:如果存汉字则长度是3n+2字节,+2的2个字节用来存储字符串长度,因为字符串长度,
数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
注意:为空的字段,索引需要在额外+1,判断是否为NULL;
索引最大长度
索引最大长度是768字节,当字符串过长时,mysql,会做一个类似于左前缀索引的处理,将前前半部分的字符提取出来做索引。
ref
这一列显示了在key列记录的索引中,表查找值所用到的列或者常量。常见的有:
const常量,字段名
row
表示mysql大概扫描的行数,这个并不是真正的结果集行数。
filtered
基于
row扫描的行数,最后用到了百分之多少的数据,优化可以根据这个来做文章,因为如果说有大量扫描的数据没有被使用,那么会降低查询效率。
Extra*
字段通常回会显示更多的信息,可以帮助我们发现性能问题的所在。
Using where
使用
where语句来进行过滤,并且使用的**条件未被索引**覆盖。(表级的过滤)
Using index condition
查询的列
没有完全被索引覆盖,且使用where条件进行前置过滤。
Using index
表示直接通过索引即可返回所需的字段信息,不需要返回表。(
索引覆盖)
就比方,需要返回一个二级索引值与主键值,使用where条件查询二级索引时,因为二级索引的叶子节点中存储的是主键值,所有不需要进行回表了。
Using filesort
表示需要额外的执行排序操作。数据较小时从内存排序,否则需要在磁盘完成排序。
Using temporart
意味着需要创建临时表保存中间结果
EXPLAIN 扩展选项
EXPLAIN FORMAT = tree
按树状结构输出我们的执行计划。
缩进越深越先执行,如果缩进相同从上往下执行.
EXPLAIN format = tree
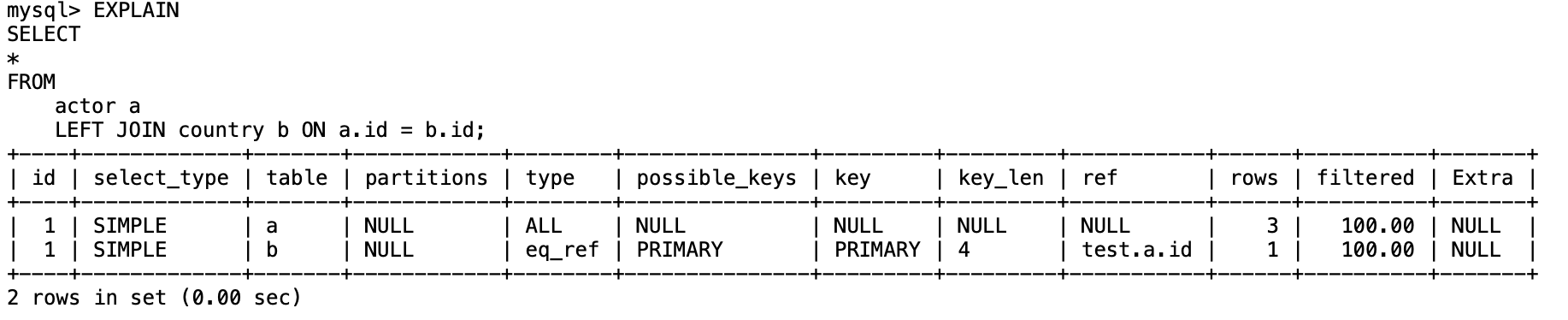
SELECT
*
FROMactor aLEFT JOIN country b ON a.id = b.id-> Nested loop left join (cost=1.60 rows=3)-> Table scan on a (cost=0.55 rows=3)-> Single-row index lookup on b using PRIMARY (Id=a.id) (cost=0.28 rows=1)
EXPLAIN FORMAT = json
EXPLAIN format = json
SELECT
*
FROMactor aLEFT JOIN country b ON a.id = b.id{"query_block": {"select_id": 1,"cost_info": {"query_cost": "1.60"},"nested_loop": [{"table": {"table_name": "a","access_type": "ALL","rows_examined_per_scan": 3,"rows_produced_per_join": 3,"filtered": "100.00","cost_info": {"read_cost": "0.25","eval_cost": "0.30","prefix_cost": "0.55","data_read_per_join": "456"},"used_columns": ["id","name","update_time"]}},{"table": {"table_name": "b","access_type": "eq_ref","possible_keys": ["PRIMARY"],"key": "PRIMARY","used_key_parts": ["Id"],"key_length": "4","ref": ["test.a.id"],"rows_examined_per_scan": 1,"rows_produced_per_join": 3,"filtered": "100.00","cost_info": {"read_cost": "0.75","eval_cost": "0.30","prefix_cost": "1.60","data_read_per_join": "4K"},"used_columns": ["Id","countryname","countrycode"]}}]}
}
EXPLAIN ANALYZE (MySQL8.0以上)
帮我们实际去执行一遍,并帮我们拿到实际的执行计划,及实际的值。
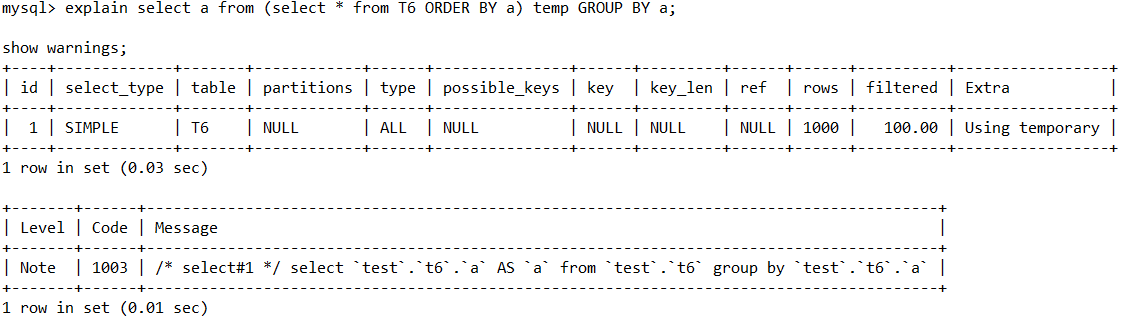
explain ANALYZE select * from T1 join T2 on T1.a = T2.a;-> Nested loop inner join (cost=1.15 rows=2) (actual time=0.048..0.073 rows=3 loops=1)-> Covering index scan on T1 using index_b (cost=0.45 rows=2) (actual time=0.034..0.043 rows=3 loops=1)-> Single-row index lookup on T2 using PRIMARY (a=t1.a) (cost=0.30 rows=1) (actual time=0.009..0.009 rows=1 loops=3)SHOW WARNINGS
可以拿到实际上被MySQL优化器,优化过后的SQL。
很经典的样例就是,子查询中的Order By被优化掉了。
因为我们这把排序放到了子查询内部,执行后发现我们的数据并没有按a来进行排序。
通过show warnings可以看见实际执行的SQL中并没有Order by
方案一:在Order by 后面加个limit ,limit的数量比你原有的结果集大就行,
方案二:Order by放最外面。
MySQL针对子查询的优化,必须不是一个包含了limit和order by才会进行优化。
相关文章:
MySQL EXPLAIN查看执行计划
MySQL 执⾏计划是 MySQL 查询优化器分析 SQL 查询时⽣成的⼀份详细计划,包括表如何连 接、是否⾛索引、表扫描⾏数等。通过这份执⾏计划,我们可以分析这条 SQL 查询中存在的 问题(如是否出现全表扫描),从⽽进⾏针对优化…...
)
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(最终篇)
目录 知识储备 杂散光 结构光 ■ 被动测距 ■ 主动结构光 图像分类技巧 增强...
redis教程 二 redis客户端Jedis使用
文章目录 Redis的Java客户端-JedisJedis快速入门创建工程:引入依赖:建立连接测试:释放资源Jedis连接池创建Jedis的连接池改造原始代码 Redis的Java客户端-SpringDataRedis快速入门导入pom坐标配置文件测试代码 数据序列化器StringRedisTempla…...
【数据开发】大数据平台架构,Hive / THive介绍
1、大数据引擎 大数据引擎是用于处理大规模数据的软件系统, 常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。 其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提…...
)
SOEM源码解析——ecx_init_context(初始化句柄)
0 工具准备 1.SOEM-master-1.4.0源码1 ecx_init_context函数总览 /*** @brief 初始化句柄* @param context 句柄*/ void ecx_init_context(ecx_contextt *context) {int lp;*(context->slavecount) = 0;/* clean ec_slave array */...

11.Z-Stack协议栈使用
f8wConfig.cfg文件 选择信道、设置PAN ID 选择信道 #define DEFAULT_CHANLIST 0x00000800 DEFAULT_CHANLIST 表明Zigbee模块要工作的网络,当有多个信道参数值进行或操作之后,把结果作为 DEFAULT_CHANLIST值 对于路由器、终端、协调器的意义࿱…...
设计模式—结构型模式之适配器模式
设计模式—结构型模式之适配器模式 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,适配器模式分为类结构型模式(继承)和对象结构型模式(组合)两种,前者&a…...

【LeetCode】187. 重复的DNA序列
187. 重复的DNA序列 难度:中等 题目 DNA序列 由一系列核苷酸组成,缩写为 A, C, G 和 T.。 例如,"ACGAATTCCG" 是一个 DNA序列 。 在研究 DNA 时,识别 DNA 中的重复序列非常有用。 给定一个表示 DNA序列 的字符串 …...

C++17中std::any的使用
类sdk:any提供类型安全的容器来存储任何类型的单个值。通俗地说,std::any是一个容器,可以在其中存储任何值(或用户数据),而无需担心类型安全。void*的功能有限,仅存储指针类型,被视为不安全模式。std::any可以被视为vo…...

携手ChainGPT 人工智能基础设施 波场TRON革新 Web3 版图
近日,波场TRON与 Web3 人工智能基础设施服务商 ChainGPT 正式达成合作。通过本次合作,双方将进一步推动人工智能和区块链技术的融合,在实现优势互补的同时,真正惠及日常生活。 作为一站式的加密AI中心,ChainGPT 的人工智能工具需要进行大量计算,能耗高,而波场TRON采用的创新型…...

pdfH5实现pdf预览功能
1.引入 npm install pdfh5 2.使用 <view id"pdfBox" class""></view> showPdf(url) {this.pdfh5 new Pdfh5("", {URIenable: false,zoomEnanle: true,maxZoom: 2,pdfurl: url})this.pdfh5.on("complete", function(st…...

Redis的持久化机制
多级缓存使用到了一个装饰设计模式:相当于我不影响我之前缓存本身的代码,但是我可以对我的缓存去做增强,因此多级缓存就是采用装饰模式去实现的~! 多级缓存可以采用装饰模式去重构~! Redis当中的持久化机制ÿ…...
mac装不了python3.7.6
今天发现一个很奇怪的问题 但是我一换成 conda create -n DCA python3.8.12就是成功的 这个就很奇怪...

仿写知乎日报第三周
新学到的 本周新学习了FMDB数据库,并对Masonry的使用有了更近一步的了解,还了解了cell的自适应高度 FMDB数据库的介绍和使用:iOS——FMDB的介绍与使用 cell自适应高度和Mansonry自动布局 本周写了评论区,在写评论区的时候&…...

Godot Best practices
Get Forward Vector transform.x # 等价手算 var rad node.rotation var forward Vector2(cos(rad), sin(rad))Await and Unity Style Coroutine func coroutine(on_update: Callable, duration: float 1):var elapse_time 0while elapse_time < 1:elapse_time get_p…...

win10 + cmake3.17 编译 giflib5.2.1
所有源文件已经打包上传csdn,大家可自行下载。 1. 下载giflib5.2.1,解压。 下载地址:GIFLIB - Browse Files at SourceForge.net 2. 下载CMakeLists.txt 及其他依赖的文件 从github上的osg-3rdparty-cmake项目: https://github.…...

【rust/esp32】初识slint ui框架并在st7789 lcd上显示
文章目录 说在前面关于slint关于no-std关于dma准备工作相关依赖代码结果参考 说在前面 esp32版本:s3运行环境:no-std开发环境:wsl2LCD模块:ST7789V2 240*280 LCDSlint版本:master分支github地址:这里 关于s…...
-http工作机制、指令和内置变量)
精通Nginx(05)-http工作机制、指令和内置变量
http服务是Nginx最原始的服务,搞清楚其工作机制非常有利于弄懂nginx是如何工作的。 Nginx核心模块为ngx_http_core_module。 目录 http工作机制 配置结构 工作机制 http常用指令 http server listen server_name location 优先级 "/"的特殊用法 root/a…...
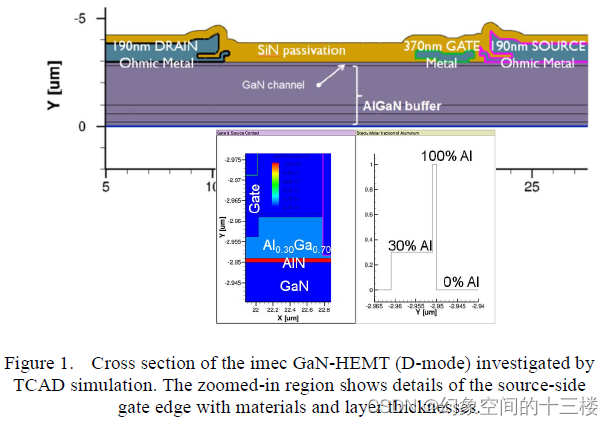
用于 GaN-HEMT 功率器件仿真的 TCAD 方法论
目录 标题:TCAD Methodology for Simulation of GaN-HEMT Power Devices来源:Proceedings of the 26th International Symposium on Power Semiconductor Devices & ICs(14年 ISPSD)GaN-HEMT仿真面临的挑战文章研究了什么文章的创新点文章的研究方法…...
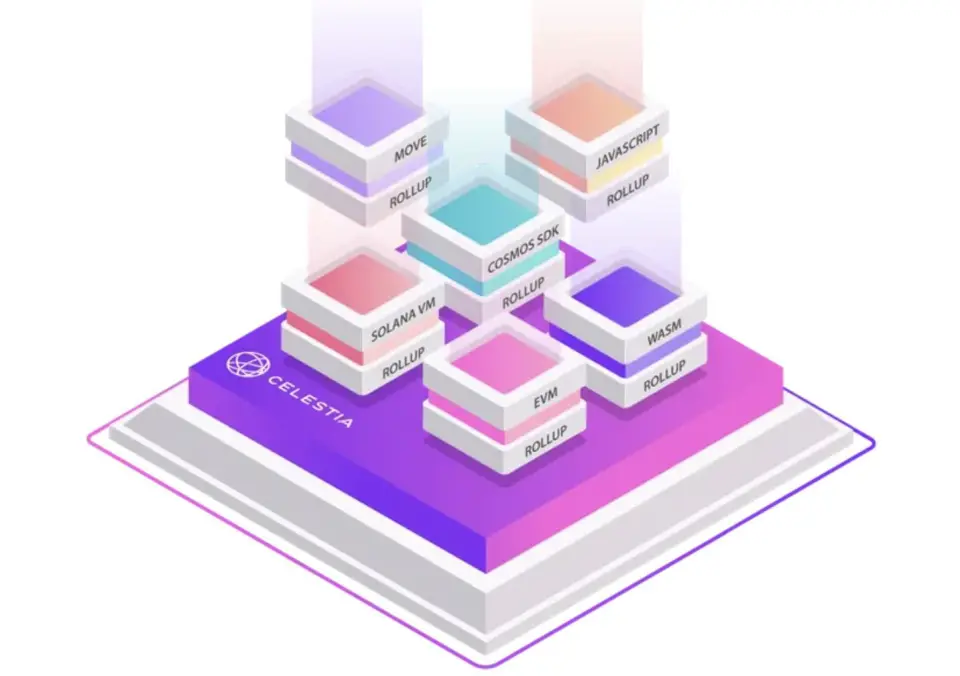
Web3公链之Cosmos生态的项目Celestia
文章目录 Web3公链之Cosmos生态的项目:模块化区块链Celestia什么是CelestiaCelestia网络架构数据可用性问题有哪些可用的解决方案? 发展历史运行节点参考 Web3公链之Cosmos生态的项目:模块化区块链Celestia 什么是Celestia 官网:…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...