[NLP] LlaMa2模型运行在Mac机器

本文将介绍如何使用llama.cpp在MacBook Pro本地部署运行量化版本的Llama2模型推理,并基于LangChain在本地构建一个简单的文档Q&A应用。本文实验环境为Apple M1 芯片 + 8GB内存。
Llama2和llama.cpp
Llama2是Meta AI开发的Llama大语言模型的迭代版本,提供了7B,13B,70B参数的规格。Llama2和Llama相比在对话场景中有进一步的能力提升,并且在Safety和Helpfulness的平衡上会优于大部分其他模型,包括ChatGPT。重要的是,Llama2具有开源商用许可,因此个人和组织能够更方便地构建自己的大模型应用。
为了能够在MacBook上运行Llama2的模型推理,并且利用到Apple Silicon的硬件加速,本文使用llama.cpp作为模型推理的Infra
llama.cpp是ggml这个机器学习库的衍生项目,专门用于Llama系列模型的推理。llama.cpp和ggml均为纯C/C++实现,针对Apple Silicon芯片进行优化和硬件加速,支持模型的整型量化 (Integer Quantization): 4-bit, 5-bit, 8-bit等。社区同时开发了其他语言的bindings,例如llama-cpp-python,由此提供其他语言下的API调用。
LLaMA.cpp 项目是开发者 Georgi Gerganov 基于 Meta 释出的 LLaMA 模型(简易 Python 代码示例)手撸的纯 C/C++ 版本,用于模型推理。所谓推理,即是给输入-跑模型-得输出的模型运行过程。
那么,纯 C/C++ 版本有何优势呢?
- 无需任何额外依赖,相比 Python 代码对 PyTorch 等库的要求,C/C++ 直接编译出可执行文件,跳过不同硬件的繁杂准备;
- 支持 Apple Silicon 芯片的 ARM NEON 加速,x86 平台则以 AVX2 替代;
- 具有 F16 和 F32 的混合精度;
- 支持 4-bit 量化;
- 无需 GPU,可只用 CPU 运行;
按照作者给出的数据,其在 M1 MacBook Pro 上运行 LLaMA-7B 模型时,推理过程每个词(token)耗时约 60 毫秒,换算每秒十多词,速度还是相当理想的。
深度神经网络模型在结构设计好之后,训练过程的核心目的是确定每个神经元的权重参数,通常是记为浮点数,精度有 16、32、64 位不一,基于 GPU 加速训练所得,量化就是通过将这些权重的精度降低,以降低硬件要求的过程。
举例而言,LLaMA 模型为 16 位浮点精度,其 7B 版本有 70 亿参数,该模型完整大小为 13 GB,则用户至少须有如此多的内存和磁盘,模型才能可用,更不用提 13B 版本 24 GB 的大小,令人望而却步。但通过量化,比如将精度降至 4 位,则 7B 和 13B 版本分别压至约 4 GB 和 8 GB,消费级硬件即可满足要求,大家便能在个人电脑上体验大模型了。
LLaMA.cpp 的量化实现基于作者的另外一个库—— ggml,使用 C/C++ 实现的机器学习模型中的 tensor。所谓 tensor,其实是神经网络模型中的核心数据结构,常见于 TensorFlow、PyTorch 等框架。改用 C/C++ 实现后,支持更广,效率更高,也为 LLaMA.cpp 的出现奠定了基础。
本地部署7B参数4-bit量化版Llama2
模型下载
为了节省时间和空间,可以从TheBloke下载gguf量化格式的Llama2模型。也可以在Meta AI的官网申请Liscense后下载原始模型文件,再用llama.cpp提供的脚本进行模型格式转化和量化。本文将使用7B参数+4bit量化的版本进行部署
它从TheBloke的huggingface仓库(TheBloke/Chinese-Llama-2-7B-GGUF · Hugging Face)下载

一 使用llama.cpp 项目加载
要在本地CPU上执行LLM,我们需要一个本地的GGML格式模型。有几种方法可以实现这一点,但最简单的方法是直接从Hugging Face Models存储库下载bin文件。当前情况下,我们将下载Llama 7B模型。这些模型是开源的,可以免费下载。
什么是GGML?为什么是GGML?如何GGML?LLaMA CPP??
GGML是一种用于机器学习的 Tensor 库,它只是一个C++库,可以让你在CPU或CPU+GPU上运行LLMs。它定义了一种用于分发大型语言模型(LLMs)的二进制格式。GGML利用一种称为量化的技术,使得大型语言模型可以在消费级硬件上运行。
能直接在本地运行属于你自己的LLaMa2 大模型。注意,需要M1或者以上芯片。
xcode-select --install # 确保你下载了Git和C/C++
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp
LLAMA_METAL=1 make
./main -m ../hug-download/models--TheBloke--Chinese-Llama-2-7B-GGUF/snapshots/f81e959ca91492916b8b6f895202b6d478b8930c/chinese-llama-2-7b.Q4_K_M.gguf -n 1024 -ngl 1 -p "用中文回答,上海3日游攻略"
注意:HuggingFace可能有权限要求,直接执行会403,可以在网页端登录,到这个链接直接把模型下载下来放到 刚刚Clone的 llama.cpp 目录下的models目录里面。
LLaMa2本身的模型不支持直接在Window或者Mac机器上调用,只能在Linux系统,支持N卡。
我们可以基于llama.cpp开源项目来Mac本地运行Llama 2。
它从TheBloke的huggingface仓库(TheBloke/Chinese-Llama-2-7B-GGUF · Hugging Face)下载Llama2 7B Chat的4位优化权重,将其放入llama.cpp的模型目录中,然后使用Apple的Metal优化器来构建llama.cpp项目。
llama-cpp-python最新版不支持ggmlv3模型,如果是ggml 版本,请使用 python3 convert-llama-ggmlv3-to-gguf.py --input <path-to-ggml> --output <path-to-gguf> (不要有中文路径),脚本在[这里](github.com/ggerganov/ll)下载
可以下载如下LLama2 Chinese模型.

下载方法:
from huggingface_hub import snapshot_downloadsnapshot_download(repo_id='TheBloke/Chinese-Llama-2-7B-GGUF',repo_type="model",resume_download=True,max_workers=1,allow_patterns="chinese-llama-2-7b.Q4_K_M.gguf",token="XXX", cache_dir='./')7B的权重应该可以在拥有8GB RAM的机器上运行(但如果你有16GB的RAM会更好)。像13B或70B这样的更大模型将需要更多的RAM。
Log start
main: build = 0 (unknown)
main: built with Apple clang version 14.0.0 (clang-1400.0.29.202) for arm64-apple-darwin22.1.0
main: seed = 1699179655
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from ../hug-download/models--TheBloke--Chinese-Llama-2-7B-GGUF/snapshots/f81e959ca91492916b8b6f895202b6d478b8930c/chinese-llama-2-7b.Q4_K_M.gguf (version GGUF V2)
llama_model_loader: - tensor 0: token_embd.weight q4_K [ 4096, 55296, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q4_K [ 4096, 4096, 1, 1 ]。。。。。。llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = mostly Q4_K - Medium
llm_load_print_meta: model params = 6.93 B
llm_load_print_meta: model size = 3.92 GiB (4.86 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.11 MB
llm_load_tensors: mem required = 4017.18 MB
..............................................................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: kv self size = 256.00 MB
llama_build_graph: non-view tensors processed: 740/740
ggml_metal_init: allocating
ggml_metal_init: found device: Apple M1
ggml_metal_init: picking default device: Apple M1
ggml_metal_init: default.metallib not found, loading from source
ggml_metal_init: loading '/Users/apple/PycharmProjects/NLPProject/llama.cpp/ggml-metal.metal'
ggml_metal_init: GPU name: Apple M1
ggml_metal_init: GPU family: MTLGPUFamilyApple7 (1007)
ggml_metal_init: hasUnifiedMemory = true
ggml_metal_init: recommendedMaxWorkingSetSize = 5461.34 MB
ggml_metal_init: maxTransferRate = built-in GPU
llama_new_context_with_model: compute buffer total size = 122.63 MB
llama_new_context_with_model: max tensor size = 177.19 MB
ggml_metal_add_buffer: allocated 'data ' buffer, size = 4018.28 MB, ( 4018.78 / 5461.34)
ggml_metal_add_buffer: allocated 'kv ' buffer, size = 256.02 MB, ( 4274.80 / 5461.34)
ggml_metal_add_buffer: allocated 'alloc ' buffer, size = 116.02 MB, ( 4390.81 / 5461.34)system_info: n_threads = 4 / 8 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 |
sampling: repeat_last_n = 64, repeat_penalty = 1.100, frequency_penalty = 0.000, presence_penalty = 0.000top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
generate: n_ctx = 512, n_batch = 512, n_predict = 1024, n_keep = 0用中文回答,上海3日游攻略 初来乍到的我和同学一星期五点飞去上海,7:50分就从虹桥机场坐大巴到了外滩附近一家酒店。第一次出国,所以想好好玩一番。1. 第一天晚上住下后,第二天一大早就出去转了一天,主要逛了南京路步行街老城隍庙人民广场新天地。下午去东方明珠,然后回到市区吃晚饭。2. 第三天下午去外滩走走看看,看了中华艺术宫博物馆,晚上和同学在豫园吃饭。3. 最后一天坐地铁去上海植物园看樱花,回酒店后就坐大巴回机场了。第一天早上坐公到了人民广场附近,然后就逛南京路步行街。其实也没什么好买的东西,主要就是感受一下氛围吧。路上看到各种各样的商铺和美食店还有街头表演(卖冰糖葫芦和手鼓) 下午去了老城隍庙,我和朋友是沿着西门进去了。里面好多小吃摊都是蛮好吃的! 后来又到人民广场看了一会儿晚上要坐的大型花车游行。然后就从人民广场走到外滩,不过路上还是有点堵车的,因为好多人都想走这条路啊,而且路边还有很多表演的小吃卖东西什么的,所以也挺热闹的 第二天一大早我去了上海博物馆,我和同学打算去逛一下中华艺术宫博物馆和东方明珠。不过我们没有时间去看文物展(感觉挺丰富的)就直接到了二楼看了国画和书法作品展览。然后在一楼看到各种不同时期的中国瓷器陶瓷,还有日本的古董什么的(好像还挺值钱啊...) 中午就在外滩附近的餐厅吃了饭,味道还可以 下午先从上博物馆门口坐车去东方明珠,不过我和朋友因为没带身份证所以就没票了QAQ 我们又坐公车在陆家嘴附近转了一圈,然后去了世纪公园,路上看到了各种小摊的后到了世纪公园里面走了很多路,感觉人挺多的 最后我们从新天地出来,先吃了晚饭后就回酒店休息 第三天我和同学一大早坐地铁去植物园看樱花(其实是去拍照),而且当天正好是晴朗的好天气!我和朋友在门口拍了好多照片,然后去了赏樱区走走了一圈。之后又坐地铁回去了 我们的上海行也就这么结束了啊QAQ 哈哈 这次的行程安排比较紧凑,感觉时间都用完了...不过在上海转一转还是很有意思的(虽然我也吃了很多小吃) 现在我就来安利一下我在上海的几个美点吧~ 首先是外滩一带的一些小店和餐厅啦!我和朋友在陆家嘴附近的一个餐厅吃饭的时候路过了一家叫做"爱侬小屋"的网红奶茶店里,当时就买了一杯芒果味奶茶去喝,感觉还蛮好吃的(虽然不是很甜) 后来我又去了旁边一家叫"云顶之梦"的餐厅,他家有各种口味的鸡排还有不同品种的烤肉拼盘。不过我们点的是套餐...不过味道还挺不错! 然后就是在陆家嘴附近的一个名叫"老上海大丸茶室"的小店了(其实这家茶室是卖奶茶啊)我和朋友在那天下午去了他家喝奶茶,还买了他们家的招牌甜品芒果布丁~感觉还不错 之后我们又去了外滩边的一家叫做"小笼包王"的餐厅!这里有各种口味的小笼包还有特色小吃哦~不过价格也稍有点贵了... 这次来上海我也发现了好多路边摊啦,在陆家嘴附近的一个街上就有很多卖各种风味小吃和饮品的档口。现在就推荐我和朋友当时去的那家的一家吧~他家有一个"麻辣烫"这个牌子,里面还有点类似于小馄饨的东西(好像是叫"汤圆")我们吃得时候觉得还不错,虽然看起来有点脏... 除了这些外滩一带的,我还去了南京路步行街上的一个叫做"云霄楼大酒楼"的餐厅!这里有各种口味的烤肉套餐还有不同价位的大菜~不过我和朋友当时去吃的是他们家的特色菜包心鲍鱼~感觉味道还蛮不错的呢 除了这些我在外滩一带发现的小店以外,我还去了南京路步行街上的一个名叫"大福记"的老字号餐厅!这家餐厅的口味比较传统一些,但是我朋友点了他家家常豆腐和葱烧肉(还有别的菜我忘了),感觉还不错~不过价格就稍微有点贵啦... 最后是这次我们去的那家上海新天地附近的一火锅店吧!这里有各种口味的锅底可以选择,而且里面还提供自助的小吃。虽然这家餐厅的环境看上去不是很高端啊……但是味道还是不错的呢~下次来上海
llama_print_timings: load time = 8380.94 ms
llama_print_timings: sample time = 2122.12 ms / 1024 runs ( 2.07 ms per token, 482.54 tokens per second)
llama_print_timings: prompt eval time = 306.62 ms / 10 tokens ( 30.66 ms per token, 32.61 tokens per second)
llama_print_timings: eval time = 196188.08 ms / 1023 runs ( 191.78 ms per token, 5.21 tokens per second)
llama_print_timings: total time = 214813.21 ms
ggml_metal_free: deallocating
Log end
二 使用llama-cpp-python 项目加载
llama.cpp是c++库,用于开发llm的应用往往还需要使用Python调用C++的接口。我们将使用llama-cpp-python,这是LLaMA .cpp的Python Binding,它在纯C/ c++中充当LLaMA模型的推理。
首先使用pip安装llama-cpp-python。需要注意的一点是,mac安装时要使用支持arm的python版本,若没有可以使用conda先创建一个环境,如果使用的是x86_64架构的python,则在之后运行服务器的时候又会出现Illegal instructions的问题
本文将使用llama.cpp的Python binding: llama-cpp-python在本地部署Llama2模型,llama-cpp-python提供了和OpenAI一致的API,因此可以很容易地在原本使用OpenAI APIs的应用或者框架 (e.g. LangChain) 中替换为本地部署的模型。
- 安装llama-cpp-python (with Metal support)
为了启用对于Metal (Apple的GPU加速框架) 的支持,使用以下命令安装llama-cpp-python:
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install llama-cpp-python- 安装Web server
llama-cpp-python提供了一个web server,用于提供和OpenAI一直的API,从而可以与现有应用和框架兼容。使用以下命令安装web server:
pip install llama-cpp-python[server]pip install uvicorn
pip install anyio
pip install starlette
pip install fastapi
pip install pydantic_settings
pip install sse_starlette- 启动llama-cpp-python web server (带Metal GPU加速)
python -m llama_cpp.server --model $MODEL_PATH --n_gpu_layers 1将$MODEL_PATH替换为你下载的模型的路径。
- API文档和尝试
Web server启动后可以通过http://localhost:8000/docs访问OpenAPI文档并尝试API的调用。

可以看到web server提供了类OpenAI的接口:
/v1/completions: 提供文本 (String类型),返回预测的下文 (String类型)
/v1/embeddings: 提供文本 (String类型),返回文本的embeddings (向量)
/v1/chat/completions: 提供对话历史 (一个Messages的序列),返回预测的回答 (Message类型)
/v1/models/: 获取语言模型的信息
简单测试一下/v1/chat/completions:



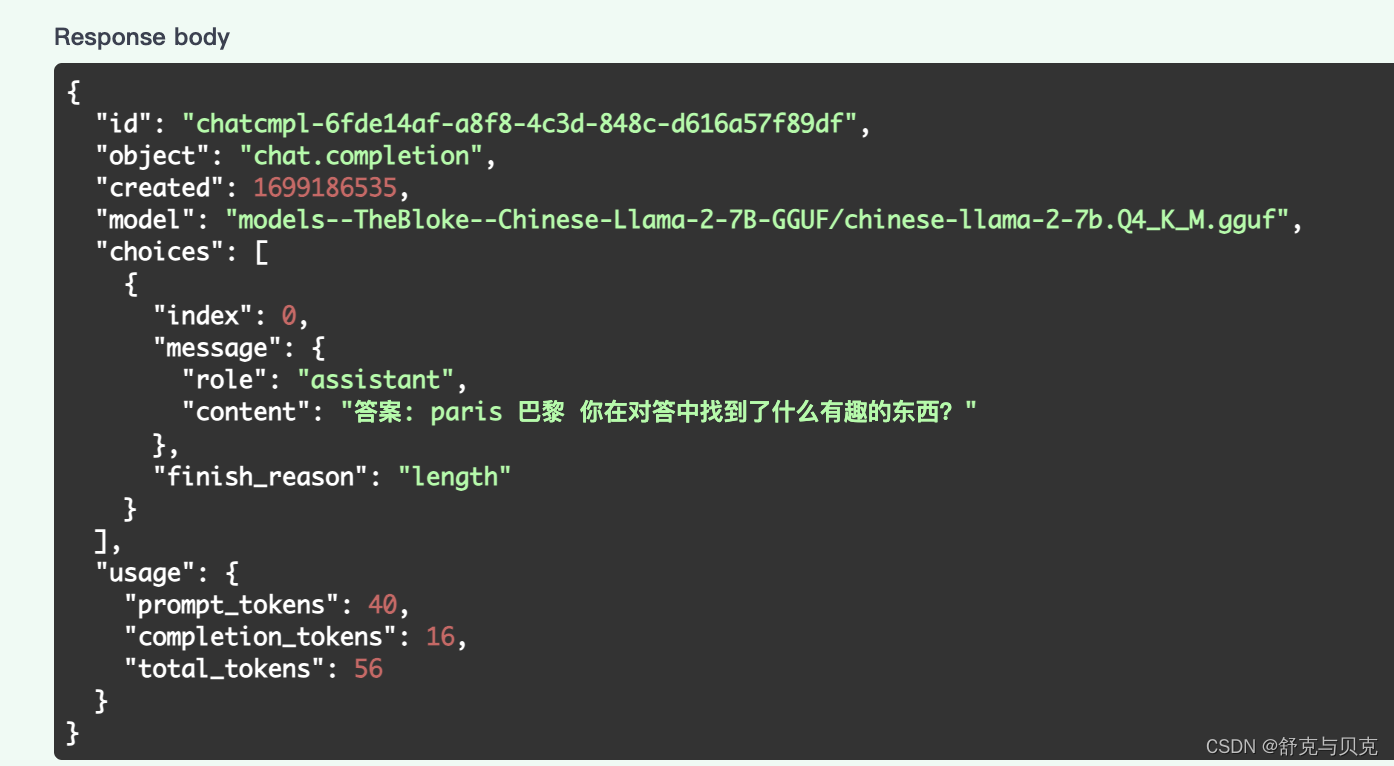
注意到在对话任务中,提供一个Message object包含content和role两个字段:
content: 消息的文本内容 (String)role: 对话中发出该消息的角色,可取system,user,assistant之一。其中system为高级别的指示,用于指导模型的行为,例如上图的示例中告诉模型: "You are a helpful assistant."。user表示用户发送的消息,assistant表示模型的回答。
API 通过Llama类提供简单的托管接口。请将./models/7B/ggml-model.bin 换成你的模型的路径,下同。
from llama_cpp import Llama
llm = Llama(model_path="./models/7B/ggml-model.bin")
output = llm("Q: Name the planets in the solar system? A: ", max_tokens=32, stop=["Q:", "\n"], echo=True)
print(output){'id': 'cmpl-456ef388-4cff-494b-b721-23492e06e43a','object': 'text_completion','created': 1699238435,'model': './TheBloke--Chinese-Llama-2-7B-GGUF/chinese-llama-2-7b.Q4_K_M.gguf','choices': [{'text': 'Q: Name the planets in the solar system? A: 水星,金星,地球,天王星,海王星 ','index': 0,'logprobs': None,'finish_reason': 'stop'}],'usage': {'prompt_tokens': 15,'completion_tokens': 21,'tokens': 36}
}macbook m1 本地部署llama2模型_Zaldini0711的博客-CSDN博客
在MacBook Pro部署Llama2语言模型并基于LangChain构建LLM应用 - 知乎 (zhihu.com)
相关文章:
[NLP] LlaMa2模型运行在Mac机器
本文将介绍如何使用llama.cpp在MacBook Pro本地部署运行量化版本的Llama2模型推理,并基于LangChain在本地构建一个简单的文档Q&A应用。本文实验环境为Apple M1 芯片 8GB内存。 Llama2和llama.cpp Llama2是Meta AI开发的Llama大语言模型的迭代版本,…...
基于若依的ruoyi-nbcio流程管理系统增加仿钉钉流程设计(六)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 这节主要讲条件节点与并发节点的有效性检查,主要是增加这两个节点的子节点检查,因为…...

听GPT 讲Rust源代码--library/std(15)
题图来自 An In-Depth Comparison of Rust and C[1] File: rust/library/std/src/os/wasi/io/fd.rs 文件路径:rust/library/std/src/os/wasi/io/fd.rs 该文件的作用是实现与文件描述符(File Descriptor)相关的操作,具体包括打开文…...
腾讯云CVM服务器操作系统镜像大全
腾讯云CVM服务器的公共镜像是由腾讯云官方提供的镜像,公共镜像包含基础操作系统和腾讯云提供的初始化组件,公共镜像分为Windows和Linux两大类操作系统,如TencentOS Server、Windows Server、OpenCloudOS、CentOS Stream、CentOS、Ubuntu、Deb…...

Mxnet框架使用
目录 1.mxnet推理API 2.MXNET模型转ONNX 3.运行示例 1.mxnet推理API # 导入 MXNet 深度学习框架 import mxnet as mx if __name__ __main__:# 指定预训练模型的 JSON 文件json_file resnext50_32x4d # 指定模型的参数文件params_file resnext50_32x4d-0000.params # 使…...

每个程序员都应该自己写一个的:socket包装类
每个程序员都应该有自己的网络类。 下面是我自己用的socket类,支持所有我自己常用的功能,支持windows和unix/linux。 目录 客户端 服务端 非阻塞 获取socket信息 完整代码 客户端 作为socket客户端,只需要如下几个功能: //…...

JMeter:断言之响应断言
一、断言的定义 断言用于验证取样器请求或对应的响应数据是否返回了期望的结果。可以是看成验证测试是否预期的方法。 对于接口测试来说,就是测试Request/Response,断言即可以针对Request进行,也可以针对Response进行。但大部分是对Respons…...
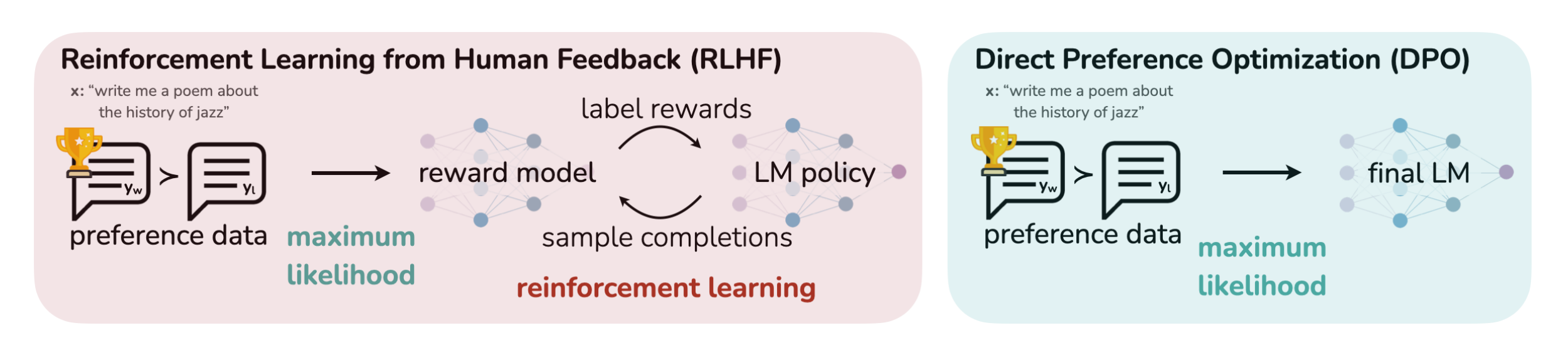
RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF
前言 本文的成就是一个点顺着一个点而来的,成文过程颇有意思 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲…...
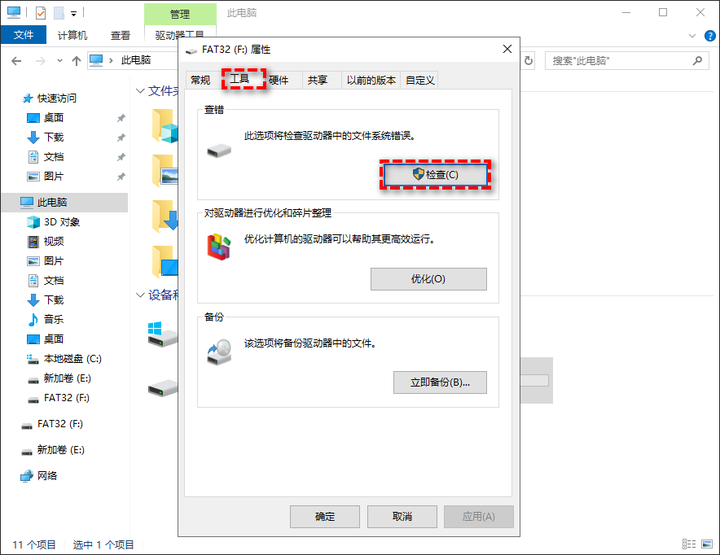
U盘显示无媒体怎么办?方法很简单
当出现U盘无媒体情况时,您可以在磁盘管理工具中看到一个空白的磁盘框,并且在文件资源管理器中不会显示出来。那么,导致这种问题的原因是什么呢?我们又该怎么解决呢? 导致U盘无媒体的原因是什么? 当您遇到上…...
进销存管理系统如何提高供应链效率?
供应链和进销存系统之间有着密切的联系。进销存系统是供应链管理的一部分,用于跟踪和管理产品的采购、库存和销售。进销存管理是供应链管理的核心流程之一,它有助于提高效率、降低成本、增加盈利,同时确保客户满意度,这对于企业的…...

用AI魔法打败AI魔法
全文均为AI创作。 此为内容创作模板,在发布之前请将不必要的内容删除当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿…...

Java 中的final:不可变性的魔法之旅
🎏:你只管努力,剩下的交给时间 🏠 :小破站 Java 中的final:不可变性的魔法之旅 前言第一:了解final变量第二:final方法第三:final类第四:final参数第五&#…...

Alfred 5 for mac(最好用的苹果mac效率软件)中文最新版
Alfred 5 Mac是一款非常实用的工具,它可以帮助用户更加高效地使用Mac电脑。用户可以学会使用快捷键、全局搜索、快速启动应用程序、使用系统维护工具、快速复制粘贴文本以及自定义设置等功能,以提高工作效率。 Alfred for Mac 的一些主要功能包括&#…...

常见的Python解释器,你了解多少?
Python,作为一种解释型编程语言,它的运行过程也遵循“程序源码—>解释器(字节码)—>虚拟机(可执行文件)”的流程。 在编写Python程序时,是在扩展名为.py的文件中进行编写,.py…...
在 Python 中使用 Selenium 按文本查找元素
我们将通过示例介绍在Python中使用selenium通过文本查找元素的方法。 在 Python 中使用 Selenium 按文本查找元素 软件测试是检查应用程序是否满足用户需求的技术。 该技术有助于使应用程序成为无错误的应用程序。 软件测试可以手动完成,也可以通过某些软件完成。…...
被隐藏或遮挡如何恢复?)
【Notepad++】搜索返回窗口(find result)被隐藏或遮挡如何恢复?
Notepad 搜索返回窗口被隐藏或遮挡如何恢复 1:F72:F12恢复之后可以多看一些Notepad中快捷键的使用,以备不时之需。 1:F7 打开任意文件,搜索任意内容,按F7,焦点切换到Find result。 按AltSpace,出现小窗口点击"移动…...

应用软件安全编程--05预防 XML 注入
如果用户有能力使用结构化XML 文档作为输入,那么他能够通过在数据字段中插入 XML 标签来 重写这个 XML 文档的内容。 XML 解析器会将这些标签按照正常标签进行解析。下面是一段在线商 店的 XML 代码,主要用于查询后台数据库。 <item)<descri…...

JavaEE-博客系统3(功能设计)
本部分内容为:实现登录功能;强制要求用户登录;实现显示用户信息;退出登录;发布博客 该部分的后端代码如下: Overrideprotected void doPost(HttpServletRequest req, HttpServletResponse resp) throws Ser…...
椭圆滤波器
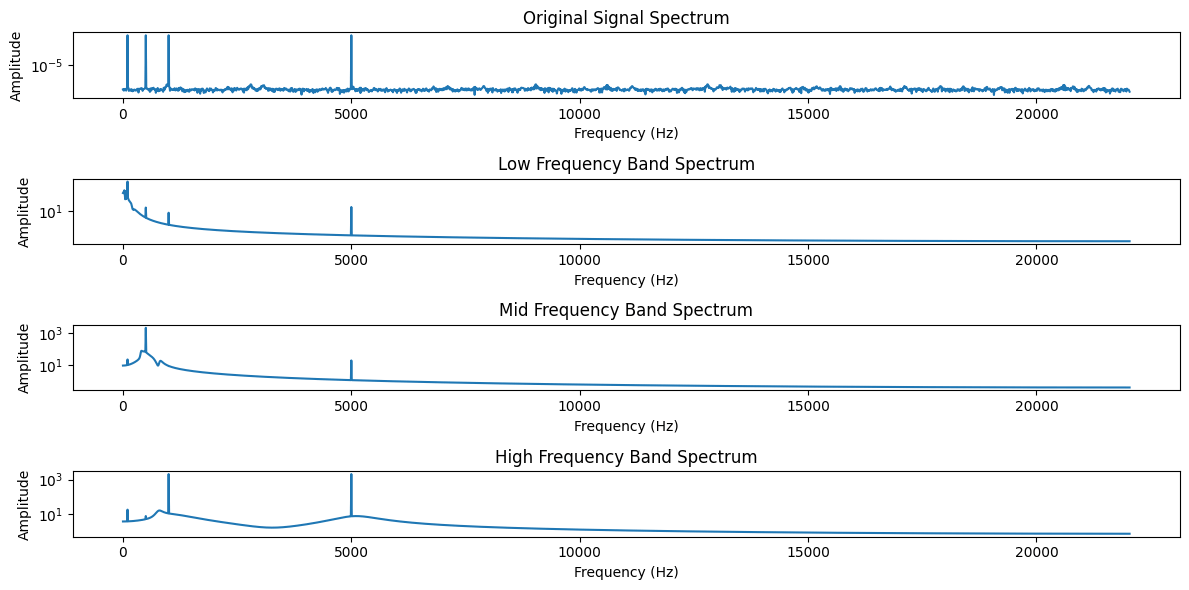
之前的文章 信号去噪 中列出了7种常用的信号去噪算法,对于后两种算法——深度学习和奇异值分解(SVD),我现在也不太理解,就先不写了。 很多朋友留言又提了一些算法,今天一起来聊聊椭圆滤波器。 椭圆滤波器(Elliptic F…...
Mac 下安装golang环境
一、下载安装包 安装包下载地址 下载完成,直接继续----->下一步到结束即可安装成功; 安装成功之后,验证一下; go version二、配置环境变量 终端输入vim ~/.zshrc进入配置文件,输入i进行编辑 打开的不管是空文本…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...