Java数据结构与算法——手撕LRULFU算法
LRU算法
力扣146:https://leetcode-cn.com/problems/lru-cache/
讲解视频:https://www.bilibili.com/video/BV1Hy4y1B78T?p=65&vd_source=6f347f8ae76e7f507cf6d661537966e8
LRU是Least Recently Used的缩写,是一种常用的页面置换算法,选择最近最久未使用的数据予以淘汰。(操作系统)
分析:
1 所谓缓存,必须要有读+写两个操作,按照命中率的思路考虑,写操作+读操作时间复杂度都需要为O(1)
2 特性要求分析
2.1 必须有顺序之分,以区分最近使用的和很久没用到的数据排序。
2.2 写和读操作 一次搞定。
2.3 如果容量(坑位)满了要删除最不长用的数据,每次新访问还要把新的数据插入到队头(按照业务你自己设定左右那一边是队头)
查找快,插入快,删除快,且还需要先后排序-------->什么样的数据结构满足这个问题?
你是否可以在O(1)时间复杂度内完成这两种操作?
如果一次就可以找到,你觉得什么数据结构最合适??
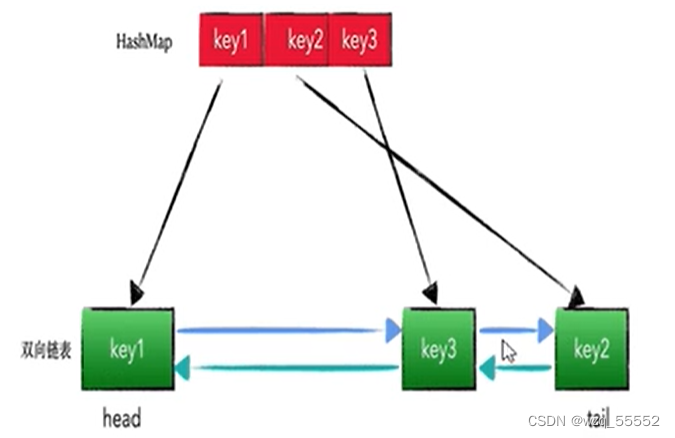
LRU的算法核心是哈希链表,本质就是HashMap+DoubleLinkedList 时间复杂度是O(1),哈希表+双向链表的结合体
利用JDK的LinkedHashMap实现:
LRU(The Least Recently Used,最近最久未使用算法)是一种常见的缓存算法,在很多分布式缓存系统(如Redis, Memcached)中都有广泛使用。
LRU算法的思想是:如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被置换(淘汰)。
LRU算法的描述: 设计一种缓存结构,该结构在构造时确定大小,假设大小为 K,并有两个功能:
- set(key,value):将记录(key,value)插入该结构。当缓存满时,将最久未使用的数据置换掉。
- get(key):返回key对应的value值。
实现:最朴素的思想就是用数组+时间戳的方式,不过这样做效率较低。因此,我们可以用双向链表(LinkedList)+哈希表(HashMap)实现(链表用来表示位置,哈希表用来存储和查找),在Java里有对应的数据结构LinkedHashMap。
利用Java的LinkedHashMap用非常简单的代码来实现基于LRU算法的Cache功能,代码如下:
import java.util.LinkedHashMap;
import java.util.Map;/*** Title:力扣146 - LRU 缓存机制* Description:最近最久未使用算法* 双向链表+Hash实现,LinkedHashMap* @author WZQ* @version 1.0.0* @date 2020/12/24*/
public class LRUCache{// 思路1 使用LinkedHashMap jdk自带public LinkedHashMap<Integer, Integer> map;public LRUCache(int capacity) {// true表示纪录访问的顺序,false的话,按第一次插入的顺序不变map = new LinkedHashMap(capacity, 0.75f, true){// 最近最久未使用删除@Overrideprotected boolean removeEldestEntry(Map.Entry eldest) {return this.size() > capacity;}};}public int get(int key) {return map.get(key) == null ? -1 : map.get(key);}public void put(int key, int value) {map.put(key, value);}public static void main(String[] args) {LRUCache lruCache = new LRUCache(3);lruCache.put(1,"a");lruCache.put(2,"b");lruCache.put(3,"c");System.out.println(lruCache.keySet());lruCache.put(4,"d");System.out.println(lruCache.keySet());lruCache.put(3,"c");System.out.println(lruCache.keySet());lruCache.put(3,"c");System.out.println(lruCache.keySet());lruCache.put(3,"c");System.out.println(lruCache.keySet());lruCache.put(5,"x");System.out.println(lruCache.keySet());}}/*** true* [1, 2, 3]* [2, 3, 4]* [2, 4, 3]* [2, 4, 3]* [2, 4, 3]* [4, 3, 5]* false* [1, 2, 3]* [2, 3, 4]* [2, 3, 4]* [2, 3, 4]* [2, 3, 4]* [3, 4, 5]*/
手写LRU:
import java.util.HashMap;
import java.util.Map;/*** Title:146. LRU 缓存* Description:LRU* @author WZQ* @version 1.0.0* @date 2023/2/26*/
class LRUCache {/*** 数据结点* @param <K>* @param <V>*/class Node<K, V>{K key;V value;Node<K, V> prev;Node<K, V> next;public Node() {this.prev = this.next = null;}public Node(K key, V value){this.prev = this.next = null;this.key = key;this.value = value;}}/*** 双端链表* @param <K>* @param <V>*/class DoubleLinkedList<K, V>{Node<K, V> head;Node<K, V> tail;public DoubleLinkedList() {// 头结点不删head = new Node<>();tail = new Node<>();head.next = tail;tail.prev = head;}// 头放最久未使用,尾放最新访问// 删除节点public void removeNode(Node<K, V> node){node.next.prev = node.prev;node.prev.next = node.next;node.prev = null;node.next = null;}// 添加到尾public void addTail(Node<K, V> node){node.prev = tail.prev;node.next = tail;tail.prev.next = node;tail.prev = node;}// 获取最久未使用节点public Node<K, V> getLast() {return head.next;}}private int capacity;private DoubleLinkedList<Integer, Integer> doubleLinkedList;private HashMap<Integer, Node<Integer, Integer>> map;// 思路2 手写 双端链表+哈希 时间复杂度: put O(1) get O(1) public LRUCache(int capacity) {this.capacity = capacity;doubleLinkedList = new DoubleLinkedList();map = new HashMap<>();}public int get(int key) {if (!map.containsKey(key)) {return -1;}Node<Integer, Integer> node = map.get(key);doubleLinkedList.removeNode(node);doubleLinkedList.addTail(node);return node.value;}public void put(int key, int value) {if (map.containsKey(key)){// 已存在节点// 删除节点,放到尾部Node<Integer, Integer> node = map.get(key);node.value = value;doubleLinkedList.removeNode(node);doubleLinkedList.addTail(node);}else {// 未存在节点if (capacity == map.size()){// 缓存数已满,需删除最久未使用Node<Integer, Integer> last = doubleLinkedList.getLast();doubleLinkedList.removeNode(last);map.remove(last.key);}Node<Integer, Integer> node = new Node<Integer, Integer>(key, value);doubleLinkedList.addTail(node);map.put(key, node);}}public static void main(String[] args) {LRUCache lruCacheDemo = new LRUCache(3);lruCacheDemo.put(1, 1);lruCacheDemo.put(2, 2);lruCacheDemo.put(3, 3);System.out.println(lruCacheDemo.map.keySet());lruCacheDemo.put(4, 1);System.out.println(lruCacheDemo.map.keySet());lruCacheDemo.put(3, 1);System.out.println(lruCacheDemo.map.keySet());lruCacheDemo.put(3, 1);System.out.println(lruCacheDemo.map.keySet());lruCacheDemo.put(3, 1);System.out.println(lruCacheDemo.map.keySet());lruCacheDemo.put(5, 1);System.out.println(lruCacheDemo.map.keySet());}
}/**[1, 2, 3][2, 3, 4][2, 3, 4][2, 3, 4][2, 3, 4][3, 4, 5]*/
LFU算法
力扣:https://leetcode.cn/problems/lfu-cache/description/
LFU(Least Frequently Used ,最近最少使用算法)也是一种常见的缓存算法。
顾名思义,LFU算法的思想是:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。如果访问频率相同,则淘汰最久未访问的。
LFU 算法的描述:
设计一种缓存结构,该结构在构造时确定大小,假设大小为 K,并有两个功能:
- set(key,value):将记录(key,value)插入该结构。当缓存满时,将访问频率最低的数据置换掉。
- get(key):返回key对应的value值。
算法实现策略:考虑到 LFU 会淘汰访问频率最小的数据,我们需要一种合适的方法按大小顺序维护数据访问的频率。LFU 算法本质上可以看做是一个 top K 问题(K = 1),即选出频率最小的元素,因此我们很容易想到可以用二项堆来选择频率最小的元素,这样的实现比较高效。最终实现策略为小顶堆+哈希表,时间复杂度O(logn),代码如下:
import java.util.Arrays;
import java.util.HashMap;
import java.util.PriorityQueue;
import java.util.TreeSet;/*** Title:leetcode --> 460. LFU 缓存* Description:LFU** 方法1:哈希表 + 最小堆/平衡二叉树TreeSet * 时间复杂度:put O(logn) get O(logn) 堆运算** @author WZQ* @version 1.0.0* @date 2023/2/26*/
class LFUCache {PriorityQueue<Node<Integer, Integer>> minHeap;HashMap<Integer, Node<Integer, Integer>> map;// 访问时间int visitTime;int capacity;/*** 数据结点* @param <K>* @param <V>*/class Node<K, V> implements Comparable<Node>{K key;V value;// 访问次数int count;// 最新的时间,越小表示越久未访问int lastTime;public Node(K key, V value){this.key = key;this.value = value;this.count = 1;}public Node(){}@Overridepublic int compareTo(Node node) {// 访问次数一样,则取最久未访问的return count == node.count ? lastTime - node.lastTime : count - node.count;}}public LFUCache(int capacity) {visitTime = 0;this.capacity = capacity;map = new HashMap<>();minHeap = new PriorityQueue<>();}public int get(int key) {if (!map.containsKey(key)){return -1;}Node<Integer, Integer> node = map.get(key);// 删除元素,重新入堆排序minHeap.remove(node);node.count ++;node.lastTime = ++ visitTime;minHeap.offer(node);return node.value;}public void put(int key, int value) {if (map.containsKey(key)){// 访问+1,置成最新Node<Integer, Integer> node = map.get(key);minHeap.remove(node);node.value = value;node.count++;node.lastTime = ++ visitTime;minHeap.offer(node);}else {// 容量已满,剔除最小元素(最久未访问)if (capacity == map.size()){Node<Integer, Integer> minNode = minHeap.poll();map.remove(minNode.key);}Node<Integer, Integer> node = new Node<>(key, value);node.lastTime = ++ visitTime;map.put(key, node);minHeap.offer(node);}}}
双hash表思路,详细可见leetcode讲解视频:https://leetcode.cn/problems/lfu-cache/solutions/186348/lfuhuan-cun-by-leetcode-solution/
时间复杂度O(1),代码如下:
import java.util.HashMap;
import java.util.Map;/*** Title:leetcode --> 460. LFU 缓存* Description:LFU** 双Hash表 时间复杂度 O(1)** @author WZQ* @version 1.0.0* @date 2023/2/26*/
class LFUCache2 {/*** 数据结点* @param <K>* @param <V>*/class Node<K, V>{K key;V value;// 访问次数int count;Node<K, V> prev;Node<K, V> next;public Node() {this.prev = this.next = null;}public Node(K key, V value){this.prev = this.next = null;this.key = key;this.value = value;count = 1;}}/*** 双端链表* @param <K>* @param <V>*/class DoubleLinkedList<K, V>{Node<K, V> head;Node<K, V> tail;int size;public DoubleLinkedList() {// 头结点不删head = new Node<>();tail = new Node<>();head.next = tail;tail.prev = head;size = 0;}// 头放最久未使用,尾放最新访问// 删除节点public void removeNode(Node<K, V> node){node.next.prev = node.prev;node.prev.next = node.next;node.prev = null;node.next = null;size --;}// 添加到尾public void addTail(Node<K, V> node){node.prev = tail.prev;node.next = tail;tail.prev.next = node;tail.prev = node;size ++;}// 获取最久未使用节点public Node<K, V> getLast() {return head.next;}}// key:key, value:Node节点Map<Integer, Node<Integer, Integer>> keyTable;// key:访问次数, value:访问次数相同的组成链表,头是最久未访问的,新的插到尾部Map<Integer, DoubleLinkedList<Integer, Integer>> countTable;int capacity;int minCount;public LFUCache2(int capacity) {this.capacity = capacity;keyTable = new HashMap<>();countTable = new HashMap<>();}public int get(int key) {if (!keyTable.containsKey(key)){return -1;}Node<Integer, Integer> node = keyTable.get(key);resetNode(node);return node.value;}public void put(int key, int value) {if (keyTable.containsKey(key)){// 存在,则改变值,访问次数+1, 重置节点Node<Integer, Integer> node = keyTable.get(key);resetNode(node);node.value = value;}else {// 容量已满,剔除最少访问节点if (capacity == keyTable.size()){// 通过minCount拿到最小访问的头节点(最久未访问)Node<Integer, Integer> node = countTable.get(minCount).getLast();keyTable.remove(node.key);countTable.get(minCount).removeNode(node);if (countTable.get(minCount).size == 0) {countTable.remove(minCount);}}// 新节点添加DoubleLinkedList<Integer,Integer> linkedList = countTable.getOrDefault(1, new DoubleLinkedList());Node<Integer, Integer> node = new Node<>(key, value);linkedList.addTail(node);countTable.put(1, linkedList);keyTable.put(key, node);minCount = 1;}}/*** 访问次数+1,重置节点在countTable的位置* @param node*/public void resetNode(Node<Integer, Integer> node){// 1. 原位置删除该节点,原位置链表为空,则删除int count = node.count;countTable.get(count).removeNode(node);if (countTable.get(count).size == 0){countTable.remove(count);if (count == minCount) {minCount ++;}}// 2. 访问次数+1node.count ++;count++;// 3. 新位置为空,则创建链表,节点添加进去DoubleLinkedList<Integer, Integer> nextLinkedList = countTable.getOrDefault(count, new DoubleLinkedList<>());nextLinkedList.addTail(node);countTable.put(count, nextLinkedList);}}
相关文章:
Java数据结构与算法——手撕LRULFU算法
LRU算法 力扣146:https://leetcode-cn.com/problems/lru-cache/ 讲解视频:https://www.bilibili.com/video/BV1Hy4y1B78T?p65&vd_source6f347f8ae76e7f507cf6d661537966e8 LRU是Least Recently Used的缩写,是一种常用的页面置换算法&…...

20230227英语学习
Can Clay Capture Carbon Dioxide? 低碳新思路:粘土也能吸收二氧化碳! The atmospheric level of carbon dioxide — a gas that is great at trapping heat, contributing to climate change — is almost double what it was prior to the Industria…...

校招前端高频react面试题合集
了解redux吗? redux 是一个应用数据流框架,主要解决了组件之间状态共享问题,原理是集中式管理,主要有三个核心方法:action store reduce 工作流程 view 调用store的dispatch 接受action传入的store,reduce…...
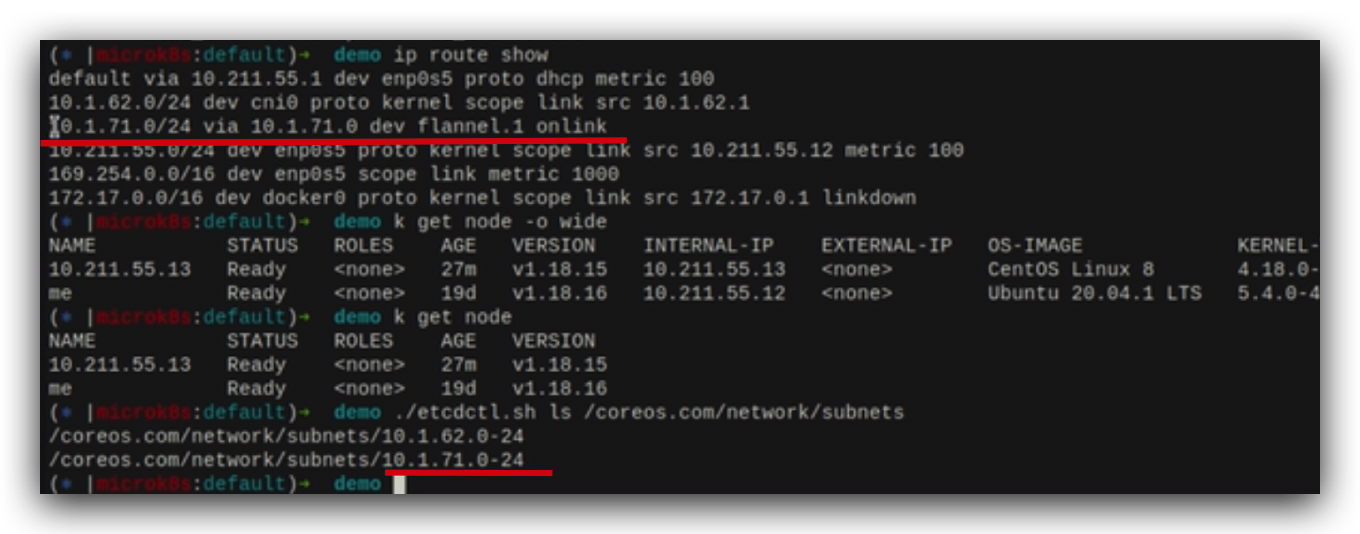
k8s node之间是如何通信的?
承接上文同一个node中pod之间如何通信?单一Pod上的容器是怎么共享网络命名空间的?每个node上的pod ip和cni0网桥ip和flannel ip都是在同一个网段10.1.71.x上。cni0网桥会把报文发送flannel这个网络设备上,flannel其实是node上的一个后台进程&…...
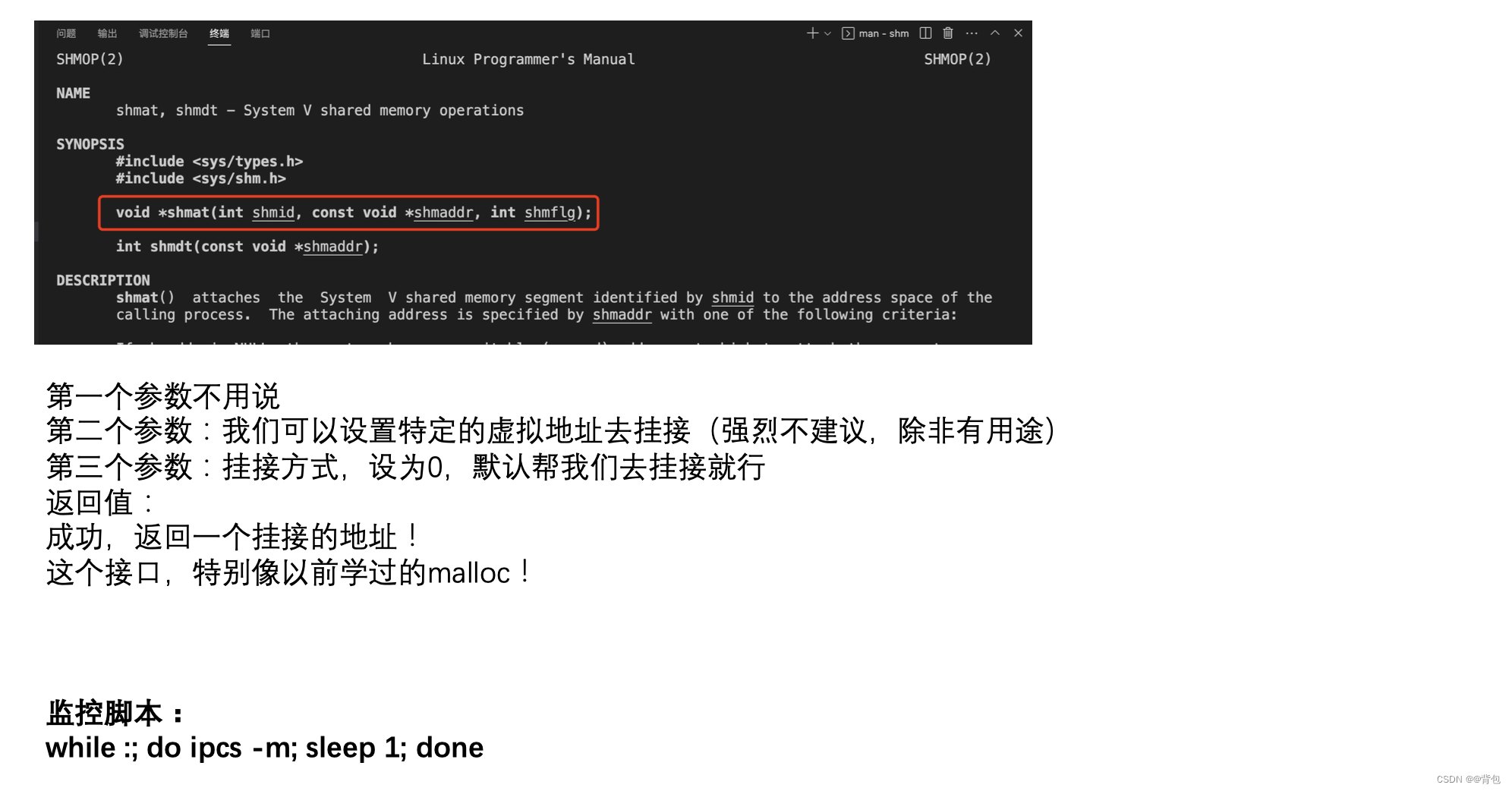
System V|共享内存基本通信框架搭建|【超详细的代码解释和注释】
前言 那么这里博主先安利一下一些干货满满的专栏啦! 手撕数据结构https://blog.csdn.net/yu_cblog/category_11490888.html?spm1001.2014.3001.5482这里包含了博主很多的数据结构学习上的总结,每一篇都是超级用心编写的,有兴趣的伙伴们都支…...
魔兽世界WoW注册网站搭建——-Liunx
问题背景哎 搭建了一个魔兽3.35(纯洁版)每当同学朋友要玩的时候我都直接worldserver上面打一个命令随之出现朋友的朋友也要玩想了想还是要有一个网站原本以为吧单机版里面网页的IP数据库改下可以了结果PHP报错了Unknown column sha_pass_hash in field l…...

OSG三维渲染引擎编程学习之六十八:“第六章:OSG场景工作机制” 之 “6.8 OSG内存管理”
目录 第六章 OSG场景工作机制 6.8 OSG内存管理 6.8.1 Referenced类 6.8.2 ref_ptr<>模板类 6.8.3 智能指针...

字节前端必会面试题(持续更新中)
事件传播机制(事件流) 冒泡和捕获 谈一谈HTTP数据传输 大概遇到的情况就分为定长数据 与 不定长数据的处理吧。 定长数据 对于定长的数据包而言,发送端在发送数据的过程中,需要设置Content-Length,来指明发送数据的长度。 当…...

内存数据库-4-[redis]在ubuntu中离线安装
Ubuntu20.04(linux)离线安装redis 官网redis下载地址 下载安装包redis-6.0.9.tar.gz。 1 下载安装 (1)解压 sudo tar -xzvf redis-6.0.9.tar.gz -C /usr/local/ cd /usr/local/redis-6.0.9/(2)编译 sudo make(3)测试 sudo dpkg -i libtcl8.6_8.6.10dfsg-1_amd64.deb sudo d…...
并非从0开始的c++ day8
并非从0开始的c day8结构体结构体嵌套二级指针练习结构体偏移量内存对齐内存对齐的原因如何内存对齐文件操作文件的概念流的概念文本流二进制流文件缓冲区文件打开关闭文件关闭fclose文件读写函数回顾按格式化读写文件文件读写注意事项结构体 结构体嵌套二级指针练习 需求&am…...
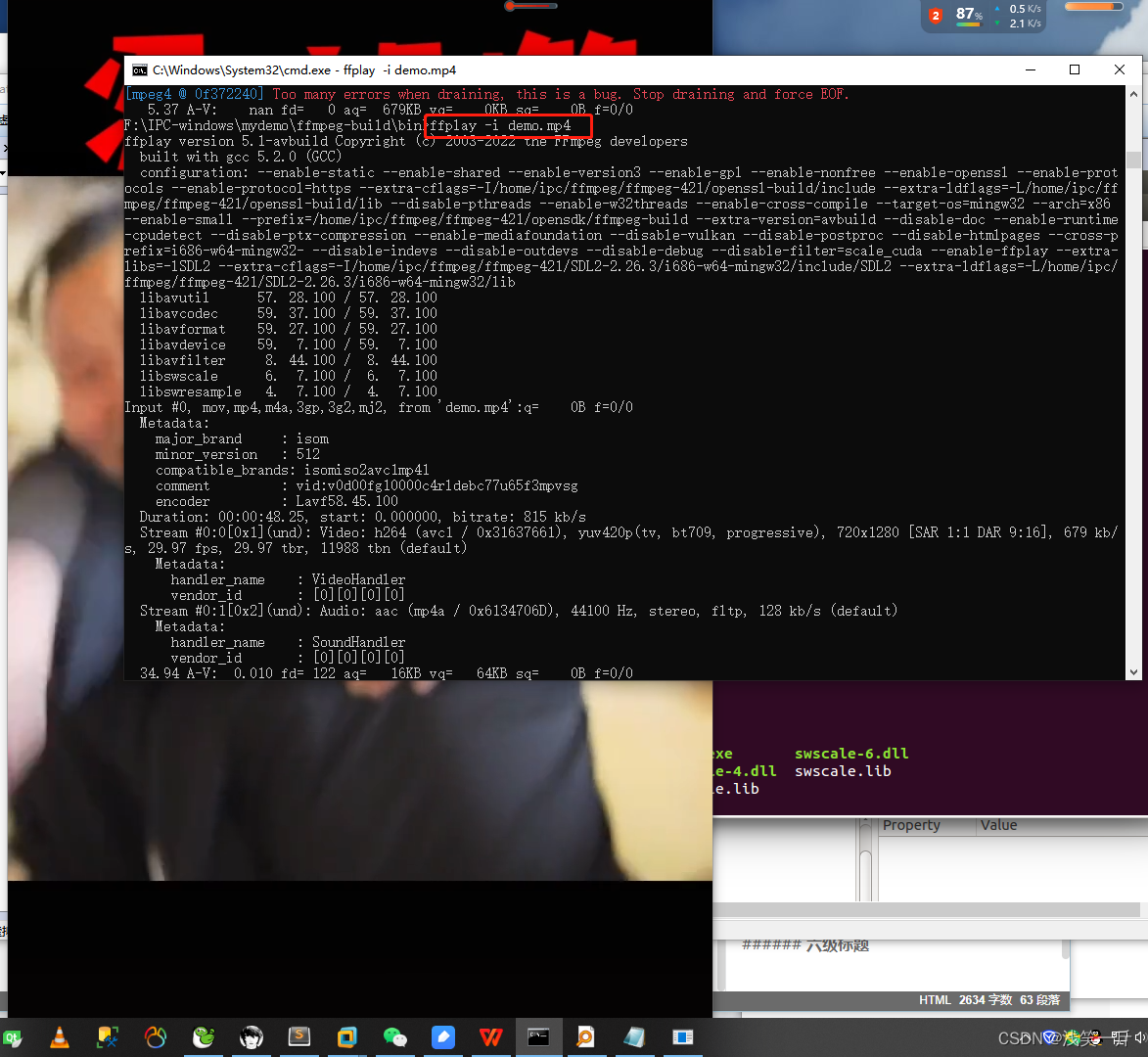
ubuntu下用i686-w64-mingw32交叉编译支持SDL、Openssl的ffmpeg库
前言 本篇博客是基于前两篇关于ffmpeg交叉编译下,进行再次编译操作。ubuntu下ffmpeg的交叉编译环境搭建可以参看以下我的这篇博客:https://blog.csdn.net/linyibin_123/article/details/108759367 ; ubuntu下交叉编译openssl及交叉编译支持o…...
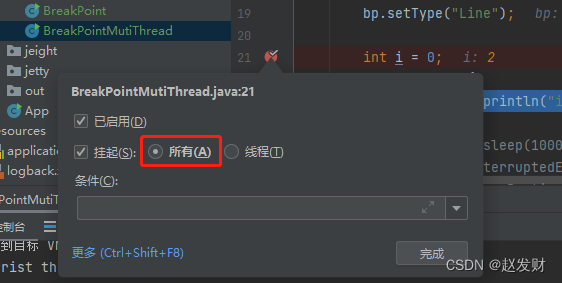
对IDEA中断点Suspend 属性理解
suspend的类型分为 1、ALL:有线程进入该断点时,暂停所有线程 2、Thread:有线程进入该断点时,只暂停该线程 讨论下不同线程在同一时间段都遇到断点时,idea的处理方法。假如在执行时间上,thread1会先进入断…...

IM即时通讯开发如何解决大量离线消息导致客户端卡顿的
大部分做后端开发的朋友,都在开发接口。客户端或浏览器h5通过HTTP请求到我们后端的Controller接口,后端查数据库等返回JSON给客户端。大家都知道,HTTP协议有短连接、无状态、三次握手四次挥手等特点。而像游戏、实时通信等业务反而很不适合用…...
【软件测试】测试老鸟的迷途,进军高级自动化测试测试......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 很多从业几年的选手…...
HMM(隐马尔科夫模型)-理论补充2
目录 一.大数定理 二.监督学习方法 1.初始概率 2.转移概率 3.观测概率 三.Baum-Welch算法 1.EM算法整体框架 2. Baum-Welch算法 3.EM过程 4.极大化 5.初始状态概率 6.转移概率和观测概率 四.预测算法 1.预测的近似算法 2.Viterbi算法 1.定义 2. 递推࿱…...
【分布式系统】MinIO之Multi-Node Multi-Drive架构分析
文章目录架构分析节点资源硬盘资源服务安装安装步骤创建系统服务新建用户和用户组创建环境变量启动服务负载均衡代码集成注意最近打算使用MinIO替代原来使用的FastDFS,所以一直在学习MinIO的知识。这篇文章是基于MinIO多节点多驱动的部署进行研究。 架构分析 节点资…...
【无标题】(2019)NOC编程猫创新编程复赛小学组真题含参考
(2019)NOC编程猫创新编程复赛小学组最后6道大题。前10道是选择填空题 略。 这道题是绘图题,没什么难度,大家绘制这2个正十边形要注意:一是不要超出舞台;二是这2个正十边形不要相交。 这里就不给出具体程序了…...
【尚硅谷MySQL入门到高级-宋红康】数据库概述
1、为什么要使用数据库 数据的持久化 2、数据库与数据库管理系统 2.1 数据库的相关概念 2.2 数据库与数据库管理系统的关系 3、 MySQL介绍 MySQL从5.7版本直接跳跃发布了8.0版本 ,可见这是一个令人兴奋的里程碑版本。MySQL 8版本在功能上做了显著的改进与增强&a…...
SpringBoot集成Redis并实现数据缓存
应用场景 存放Token、存放用户信息或字典等需要频繁访问数据库获取但不希望频繁访问增加数据库压力且变化不频繁的数据。 集成步骤 1. 新建 Maven 项目并引入 redis 依赖【部分框架有可能已经集成,会导致依赖文件有差异】 <dependency><groupId>org…...
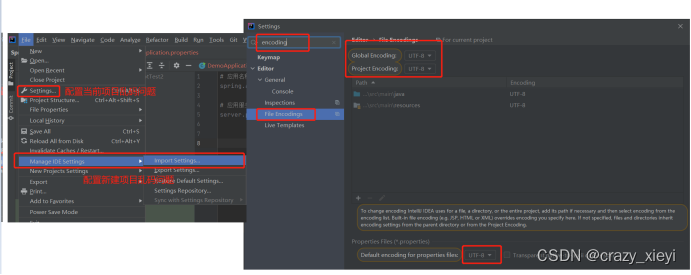
SpringBoot配置文件(properties yml)
查看官网更多系统配置项:https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.html#application-properties 1.配置⽂件作⽤ 整个项⽬中所有重要的数据都是在配置⽂件中配置的,⽐如:数据库的连接信息&am…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...