【ES专题】ElasticSearch集群架构剖析
目录
- 前言
- 阅读对象
- 阅读导航
- 要点
- 笔记正文
- 一、ES集群架构
- 1.1 为什么要使用ES集群架构
- 1.2 ES集群核心概念
- 1.2.1 节点
- 1.2.1.1 Master Node主节点的功能
- 1.2.1.2 Data Node数据节点的功能
- 1.2.1.3 Coordinate Node协调节点的功能
- 1.2.1.4 Ingest Node协调节点的功能
- 1.2.1.5 其他节点功能
- 1.2.1.6 Master Node主节点选举流程
- 1.2.2 分片
- 1.3 搭建三节点ES集群
- 1.3.1 ES集群搭建步骤
- 1.3.2 安装客户端
- 二、生产环境最佳实践
- 2.1 一个节点只承担一个角色的配置
- 2.2 增加节点水平扩展场景
- 2.3 异地多活架构
- 2.4 Hot & Warm 架构
- 2.5 如何对集群的容量进行规划
- 2.6 如何设计和管理分片
前言
个人感觉集群架构其实都有点大同小异,看了这么多集群架构之后,感觉无非要考虑的地方就几点:
- 使用何种通信协议去同步数据,互相通信
- 采用何种策略同步数据(异步还是同步)
- 如何保证一致性,保证到什么程度(【最终一致性】 or【实时一致性 / 强一致性】)
- 使用何种算法去选举主次节点(感觉这个比较随意,通常为了快速恢复服务,选举流程是怎么快怎么来,但是不能出现【脑裂问题】)
阅读对象
有基本ES使用知识,需要使用集群架构
阅读导航
系列上一篇文章:《【ES专题】ElasticSearch搜索进阶》
系列下一篇文章:《【ES专题】ElasticSearch功能详解与原理剖析》
要点
ES要掌握什么:
- 使用:搜索和聚合操作语法,理解分词,倒排索引,相关性算分(文档匹配度)
- 优化: 数据预处理,文档建模,集群架构优化,读写性能优化
笔记正文
一、ES集群架构
1.1 为什么要使用ES集群架构
为什么需要使用集群架构?这就得提一下分布式系统的可用性与扩展性了。
- 高可用性:分为两个点考虑
- 服务高可用性:允许个别节点停止服务,个别节点停止服务不影响整体使用
- 数据可用性:部分节点丢失,不会丢失数据(需要有备份策略)
- 可扩展性:
- 请求量提升/数据的不断增长(将数据分布到所有节点上)
上面所说的正是集群架构的优势所在。对ES集群架构来说,则体现在:
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
- 存储的水平扩容
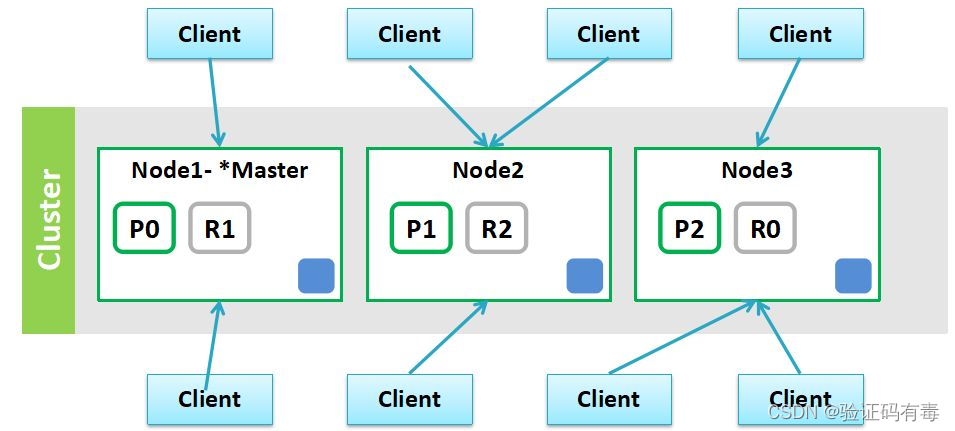
1.2 ES集群核心概念
ES集群中有2个比较核心的概念需要理解一下。分别是:节点、分片。在聊这些概念之前,我们先重新梳理一下,ES的集群是什么。
ES的集群,亦上图所示,它通常由如下特征:
- 集群中有一个或者多个节点
- 不同的集群通过不同的名字来区分,默认名字【elasticsearch】
注意:ES在实际生产环境中,还会部署多个集群一起工作
- 通过配置文件修改,或者在命令行中
-E cluster.name=es-cluster进行设定
1.2.1 节点
ES中的节点本质上是一个Elasticsearch的实例,一个Java进程。通常,我们建议生产环境中,一台机器只运行一个ES实例。(一台机器部署多个节点,其实是违背【高可用】原则的)
ES节点有如下特性:
- 每一个节点都有名字,通过配置文件配置,或者启动时候
-E node.name=node1指定 - 每一个节点在启动之后,会分配一个UID,保存在data目录下
- 节点有多种角色(类型),不同角色通常有不同的功能,它们分别是:
Master Node:主节点,负责索引的删除创建Master eligible nodes:【直译:符合条件的节点】。可以参与选举的合格节点Data Node:数据节点,负责文档的写入、读取。节点保存数据并执行与数据相关的操作,如CRUD、搜索和聚合Coordinating Node:协调节点- 其他节点
通过ES多角色定义可以看的出来,ES的集群架构非常成熟,它也是我目前见过的角色最丰富的架构。如此丰富的角色定义,肯定是为了拓展集群架构而生的,单一职责嘛。不过有一点我没想通的是,如果节点太多了,做一次CRUD的速度能快吗?会不会在通信上就花费了很多时间。
节点类型,可以通过如下配置参数禁用/启用
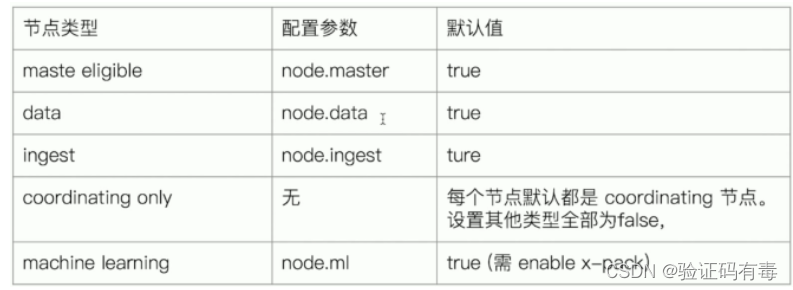
关于Master eligible nodes和Master Node
- 每个节点启动后,默认就是一个Master eligible节点,即都可以参与集群选举,成为Master节点。可以通过
node.mater=false禁止 - 当第一个节点启动时候,它会将自己选举成Master节点
- 每个节点上都保存了集群的状态,但是只有Master节点才能修改集群的状态信息。集群状态信息(Cluster State) 维护了一个集群中所有必要的信息。比如:
- 所有节点信息
- 所有的索引和其他相关的Mapping与Setting信息
- 分片的路由信息
关于Data Node 和 Coordinating Node
- Data Node:
- 可以保存数据的节点,叫做Data Node,负责保存分片数据。在数据扩展上起到了至关重要的作用
- 节点启动后,默认就是数据节点。可以设置
node.data: false禁止 - 由Master Node决定如何把分片分发到数据节点上
- 通过增加数据节点可以解决数据水平扩展和解决数据单点问题
- Coordinating Node:
- 负责接受Client的请求, 将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordinating Node的职责
其他节点类型
Hot & Warm Node:冷热节点。不同硬件配置 的Data Node,用来实现Hot & Warm架构,降低集群部署的成本
不同硬件配置,通常是CPU跟硬盘。硬盘根据冷热数据类型,可以选择固态或者机械硬盘
Ingest Node:数据前置处理转换节点,支持pipeline管道设置,可以使用ingest对数据进行过滤、转换等操作Machine Learning Node:负责跑机器学习的Job,用来做异常检测Tribe Node:Tribe Node连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理
以下是一个多集群业务架构图:

1.2.1.1 Master Node主节点的功能
Master节点主要功能::
- 管理索引和分片的创建、删除和重新分配
- 监测节点的状态,并在需要时进行重分配
- 协调节点之间的数据复制和同步工作
- 处理集群级别操作,如创建或删除索引、添加或删除节点等
- 维护集群的状态
1.2.1.2 Data Node数据节点的功能
Data Node数据节点的功能:
- 存储和索引数据:Data Node 节点会将索引分片存储在本地磁盘上,并对查询请求进行响应
- 复制和同步数据:为了确保数据的可靠性和高可用性,ElasticSearch 会将每个原始分片的多个副本存储在不同的 Data Node 节点上,并定期将各节点上的数据进行同步
- 参与搜索和聚合操作:当客户端提交搜索请求时,Data Node 节点会使用本地缓存和分片数据完成搜索和聚合操作
- 执行数据维护操作:例如,清理过期数据和压缩分片等
官方定义:
数据节点保存包含您已索引的文档的分片。数据节点处理数据相关操作,例如 CRUD、搜索和聚合。这些操作是 I/O、内存和 CPU 密集型操作。监视这些资源并在过载时添加更多数据节点非常重要。
拥有专用数据节点的主要好处是主角色和数据角色的分离。
要创建专用数据节点,请设置:node.roles: [ data ]
在多层部署体系结构中,您可以使用专门的数据角色将数据节点分配到特定层:data_content、data_hot、data_warm、data_cold或data_frozen。一个节点可以属于多个层,但具有专用数据角色之一的节点不能具有通用data角色。
1.2.1.3 Coordinate Node协调节点的功能
官方定义:
诸如搜索请求或批量索引请求之类的请求,它们可能涉及不同数据节点上保存的数据。例如,搜索请求分两个阶段执行,这两个阶段由接收客户端请求的节点(协调节点)协调。
- 在分散阶段,协调节点将请求转发到保存数据的数据节点。每个数据节点在本地执行请求并将其结果返回给协调节点
- 在收集阶段,协调节点将每个数据节点的结果缩减为单个全局结果集
每个节点都是隐式的协调节点。这意味着具有显式空角色列表的节点node.roles将仅充当协调节点,无法禁用。因此,这样的节点需要有足够的内存和 CPU 才能处理收集阶段。
1.2.1.4 Ingest Node协调节点的功能
官方定义:
在实际的文档索引发生之前,使用摄取节点对文档进行预处理。摄取节点拦截批量和索引请求,应用转换,然后将文档传递回索引或批量api。
默认情况下,所有节点都启用摄取,因此任何节点都可以处理摄取任务。您还可以创建专用的摄取节点。如果要禁用节点的摄取,请在elasticsearch. conf中配置以下配置。yml文件:node.ingest: false
要在索引之前对文档进行预处理,请定义一个指定一系列处理器的管道。每个处理器都以某种特定的方式转换文档。例如,管道可能有一个处理程序从文档中删除字段,然后有另一个处理程序重命名字段。然后,集群状态存储配置的管道。
要使用管道,只需在索引或批量请求上指定pipeline参数。这样,摄取节点就知道要使用哪个管道。例如:
PUT my-index/my-type/my-id?pipeline=my_pipeline_id
{"foo": "bar"
}
1.2.1.5 其他节点功能
其他节点相对来说使用的比较少,不做介绍了
1.2.1.6 Master Node主节点选举流程
ES的选举流程也很简单,如下:
- 通常集群启动时,第一个启动的节点会被选为主节点。当主节点挂了的时候,进行下一步
- 互相Ping对方,Node ld 低的会成为被选举的节点
- 其他节点会加入集群,但是不承担Master节点的角色。一旦发现被选中的主节点丢失,就会重新选举出新的Master节点
在我们的生产过程中,Master Node的最佳实践方案
- Master节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个Master节点,每个节点只承担Master 的单一角色
1.2.2 分片
分片是ES中一个比较重要的概念。ElasticSearch是一个分布式的搜索引擎,索引可以分成一份或多份,多份分布在不同节点的分片当中。ElasticSearch会自动管理分片,如果发现分片分布不均衡,就会自动迁移。
分片又有【主分片】、【副本分片】之分。它们的区别如下:
- 主分片(Primary Shard)
- 用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的Lucene的实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
- 副本分片
- 用以解决数据高可用的问题。 副本分片是主分片的拷贝(备份)
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
# 指定索引的主分片和副本分片数
PUT /csdn_blogs
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}
分片架构
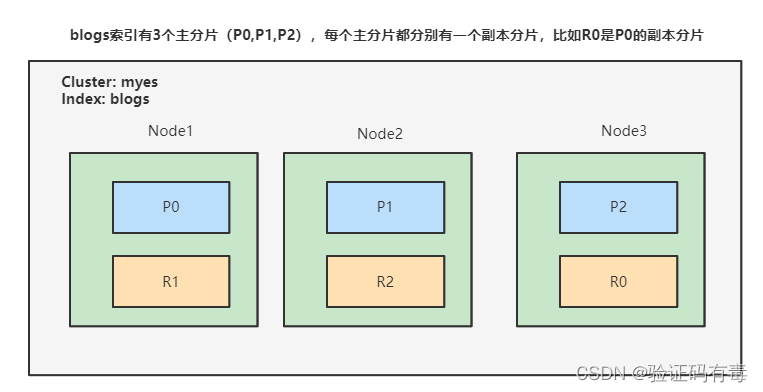
如上图是某个集群的分片架构,它有如下特征:
- 集群中有3个节点
通常都是奇数,所谓【集群奇数法则】。但其实只是名字很唬人,本质上也没那么神奇。你自己想想,如果是偶数的话,是不是很有可能出现选举平票的时候?根据我的经验,选举算法通常都希望快速选举一个master或者leader出来,以便能够快速提供服务,所以没空扯皮
- 每个节点各有一个主副分片
高可用之——故障转移
- 主副分片之间交叉存储(
node1的副本放在node3,node2放在node1,node3放在node2)
使用【cat API查看集群信息】
- GET /_cat/nodes?v #查看节点信息
- GET /_cat/health?v #查看集群当前状态:红、黄、绿
- GET /_cat/shards?v #查看各shard的详细情况
- GET /_cat/shards/{index}?v #查看指定分片的详细情况
- GET /_cat/master?v #查看master节点信息
- GET /_cat/indices?v #查看集群中所有index的详细信息
- GET /_cat/indices/{index}?v #查看集群中指定index的详细信息 `
1.3 搭建三节点ES集群
1.3.1 ES集群搭建步骤
下面是在Linux环境,centos7下面的集群搭建步骤:
1)系统环境准备
首先创建用户,因为es不允许root账号启动
adduser es
passwd es
安装版本:elasticsearch-7.17.3。接着切换到root用户,修改/etc/hosts:
vim /etc/hosts
192.168.66.150 es-node1
192.168.66.151 es-node2
192.168.66.152 es-node3
2)修改elasticsearch.yml
注意配置里面的注释,里面有一些细节。比如:
- 注意集群的名字,3个节点的集群名称必须一直
- 给每个节点指定名字,比如这里是node1/2/3
- 是否要开启外网访问,跟redis的配置差不多
# 指定集群名称3个节点必须一致
cluster.name: es-cluster
#指定节点名称,每个节点名字唯一
node.name: node-1
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#用于节点发现
discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
三个节点配置很简单,按照上面的模板,依次修改node.name就行了
3) 启动每个节点的ES服务
# 注意:如果运行过单节点模式,需要删除data目录, 否则会导致无法加入集群
rm -rf data
# 启动ES服务
bin/elasticsearch -d
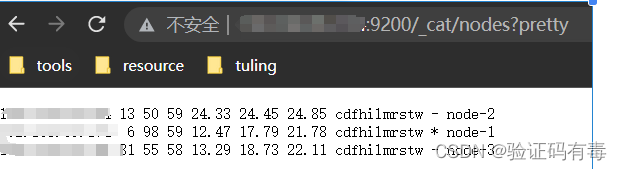
4)验证集群
正常来说,如果我们先启动了192.168.66.150,那么它就是这个集群当中的主节点,所以我们验证集群的话,只需要访问http://192.168.66.150:9200即可看到如下界面:
1.3.2 安装客户端
介绍完了ES的集群部署,我们再来看看ES客户端的部署。这里有两个可选方案,它们分别是Cerebro和Kibana,它们的区别与联系如下:
Cerebro和Kibana都是用于Elasticsearch的开源工具,但它们在功能和使用场景上存在一些区别。
功能:
- Cerebro:Cerebro是Elasticsearch的图形管理工具,可以查看分片分配和执行常见的索引操作,功能集中管理alias和index template,十分快捷。此外,Cerebro还具有实时监控数据的功能。
- Kibana:Kibana是一个强大的可视化工具,可以用于Elasticsearch数据的探索、分析和展示。它提供了丰富的图表类型,包括折线图、直方图、饼图等,可以方便地展示基于时间序列的数据。此外,Kibana还提供了日志管理、分析和展示的功能
使用场景:
- Cerebro:Cerebro适合用于生产和测试环境的Elasticsearch集群管理,尤其适用于需要快速查看和执行索引操作的情况。由于Cerebro轻量且适用于实时监控,它可能更适用于较小的集群和实时监控的场景。
- Kibana:Kibana适合对Elasticsearch数据进行深入的分析和探索,以及对日志进行管理和分析。它提供了丰富的可视化功能和灵活的数据展示方式,适用于各种规模的数据分析和监控场景。
Cerebro安装
Cerebro 可以查看分片分配和通过图形界面执行常见的索引操作,完全开源,并且它允许添加用户,密码或 LDAP 身份验证问网络界面。Cerebro 基于 Scala 的Play 框架编写,用于后端 REST 和 Elasticsearch 通信。 它使用通过 AngularJS 编写的单页应用程序(SPA)前端。
安装包下载地址如下:https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.zip
下载安装之后,用以下命令启动即可:
cerebro-0.9.4/bin/cerebro#后台启动
nohup bin/cerebro > cerebro.log &
访问:http://192.168.66.150:9000/
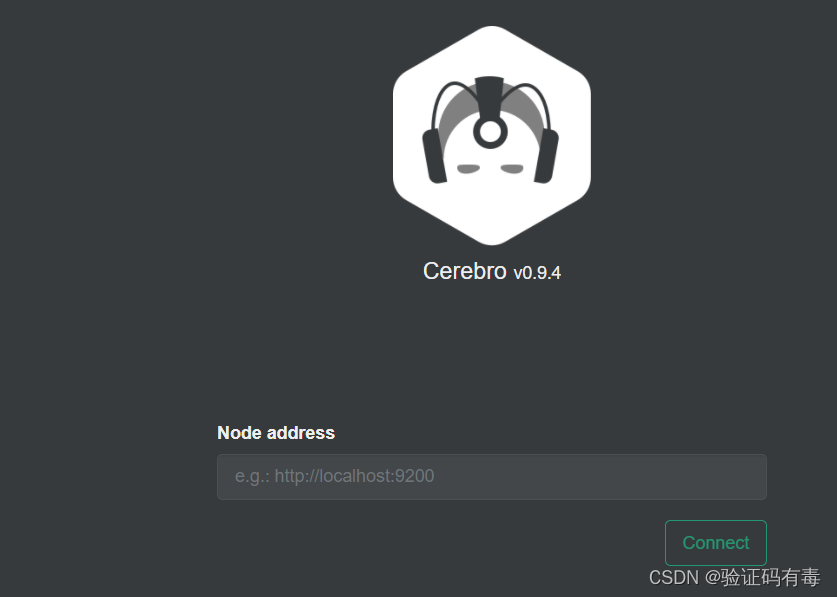
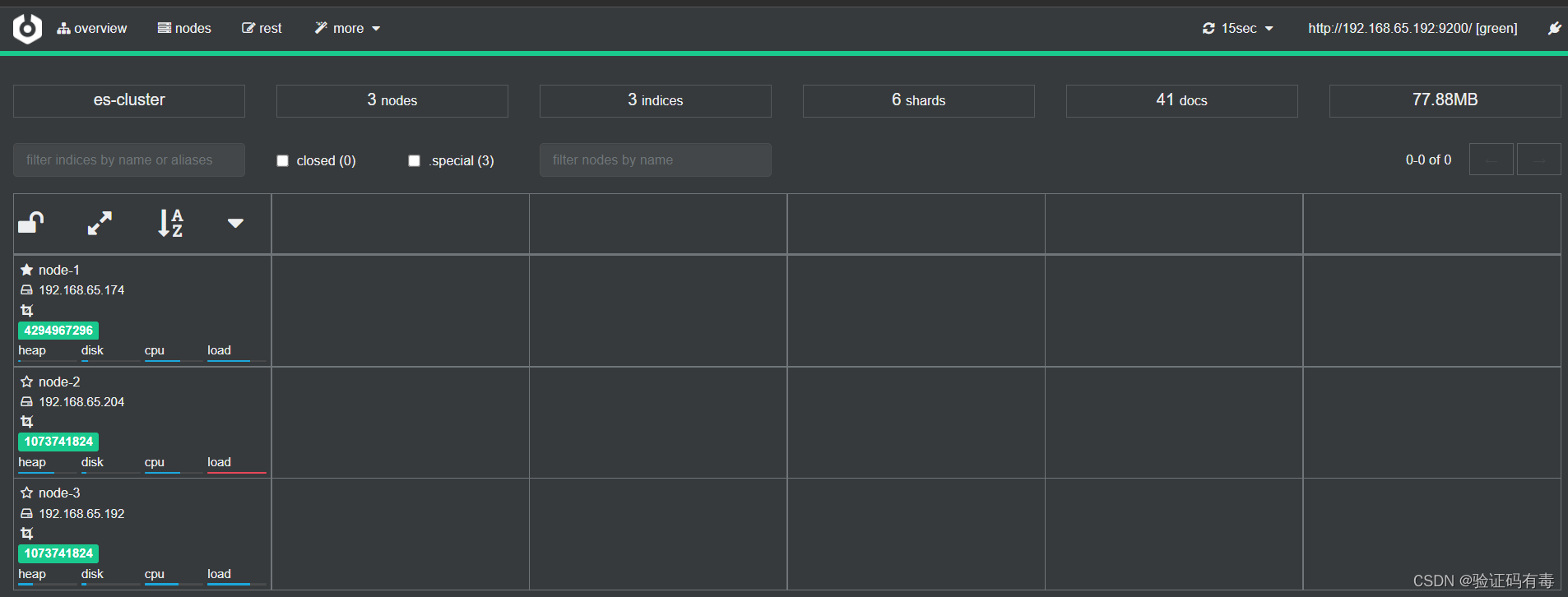
输入ES集群节点:http://192.168.66.150:9200,建立连接。然后会出现以下界面:
kibana安装
1)修改kibana配置
vim config/kibana.ymlserver.port: 5601
server.host: "192.168.66.150"
elasticsearch.hosts: ["http://192.168.66.150:9200","http://192.168.66.151:9200","http://192.168.66.152:9200"]
i18n.locale: "zh-CN"
2)运行Kibana
#后台启动
nohup bin/kibana &
3)访问
访问http://192.168.66.150:5601/验证
二、生产环境最佳实践
2.1 一个节点只承担一个角色的配置
我们在上面的介绍中知道,节点有多种不同的类型(角色),有:Master eligible / Data / Ingest / Coordinating /Machine Learning等。不过跟之前学习的各种集群架构不同的是,ES一个节点可承担多种角色。
不过,在生产环境中尽量还是一个节点一种角色比较好,优点是:极致的高可用;缺点是:可能有点费钱
想要一个节点只承担一个角色,只需要修改如下配置:
#Master节点
node.master: true
node.ingest: false
node.data: false#data节点
node.master: false
node.ingest: false
node.data: true#ingest 节点
node.master: false
node.ingest: true
node.data: false#coordinate节点
node.master: false
node.ingest: false
node.data: false
2.2 增加节点水平扩展场景
在实际生产中,我们可能会遇到需要水平扩展容量的场景,通常来说,以下是几个常见的场景:
- 当磁盘容量无法满足需求时,可以增加数据节点
- 磁盘读写压力大时,增加数据节点
- 当系统中有大量的复杂查询及聚合时候,增加Coordinating节点,增加查询的性能
2.3 异地多活架构
下面是一个多集群架构。集群处在三个数据中心,数据三写,使用GTM分发读请求
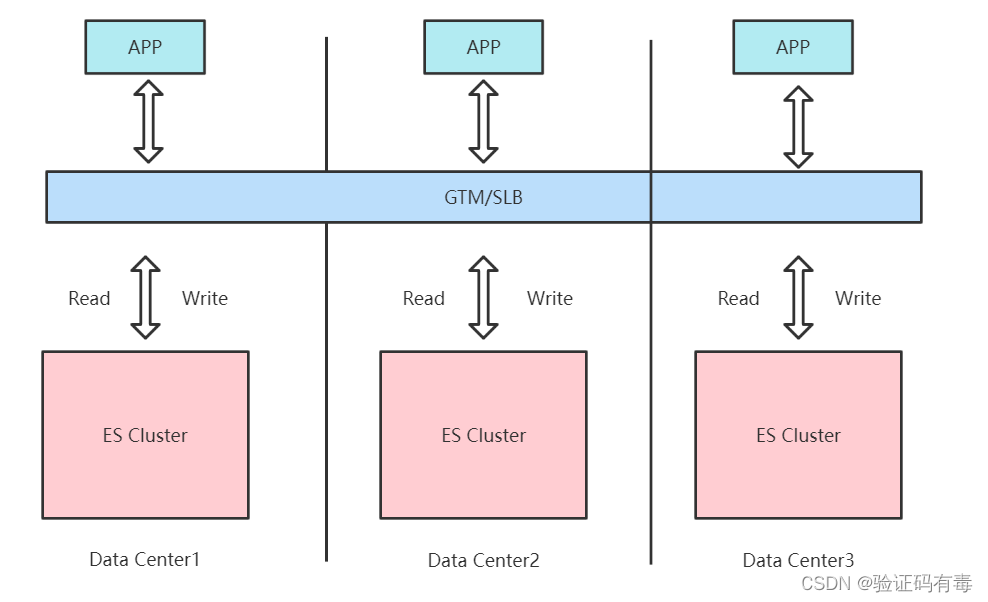
全局流量管理(GTM)和负载均衡(SLB)的区别:
GTM 是通过DNS将域名解析到多个IP地址,不同用户访问不同的IP地址,来实现应用服务流量的分配。同时通过健康检查动态更新DNS解析IP列表,实现故障隔离以及故障切换。最终用户的访问直接连接服务的IP地址,并不通过GTM。
而 SLB 是通过代理用户访问请求的形式将用户访问请求实时分发到不同的服务器,最终用户的访问流量必须要经过SLB。 一般来说,相同Region使用SLB进行负载均衡,不同region的多个SLB地址时,则可以使用GTM进行负载均衡。
2.4 Hot & Warm 架构
热节点存放用户最关心的热数据;温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。
它的典型的应用场景如下:
在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离,最大化解决客户反应的响应时间慢的问题。业务场景描述:每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
- ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储热数据,提升查询效率。
- 若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
ES为什么要设计Hot & Warm 架构呢?
- ES数据通常不会有 Update操作;
- 适用于Time based索引数据,同时数据量比较大的场景。
- 引入 Warm节点,低配置大容量的机器存放老数据,以降低部署成本
两类数据节点,不同的硬件配置:
- Hot节点(通常使用SSD)︰索引不断有新文档写入。
- Warm 节点(通常使用HDD)︰索引不存在新数据的写入,同时也不存在大量的数据查询
Hot Nodes:用于数据的写入
- lndexing 对 CPU和IO都有很高的要求,所以需要使用高配置的机器
- 存储的性能要好,建议使用SSD
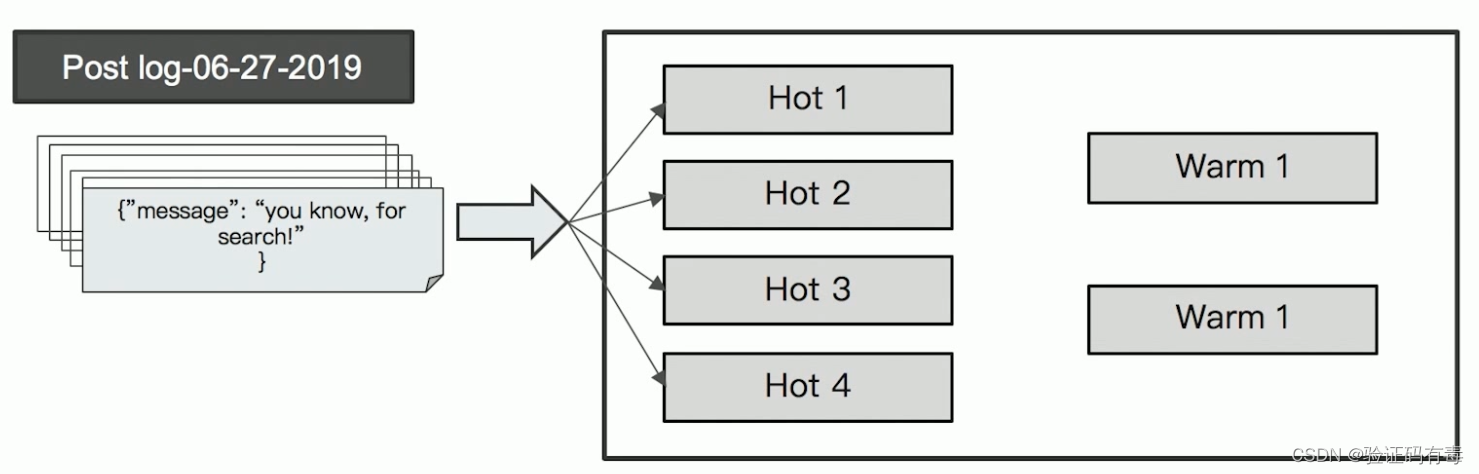
Warm Nodes
用于保存只读的索引,比较旧的数据。通常使用大容量的磁盘
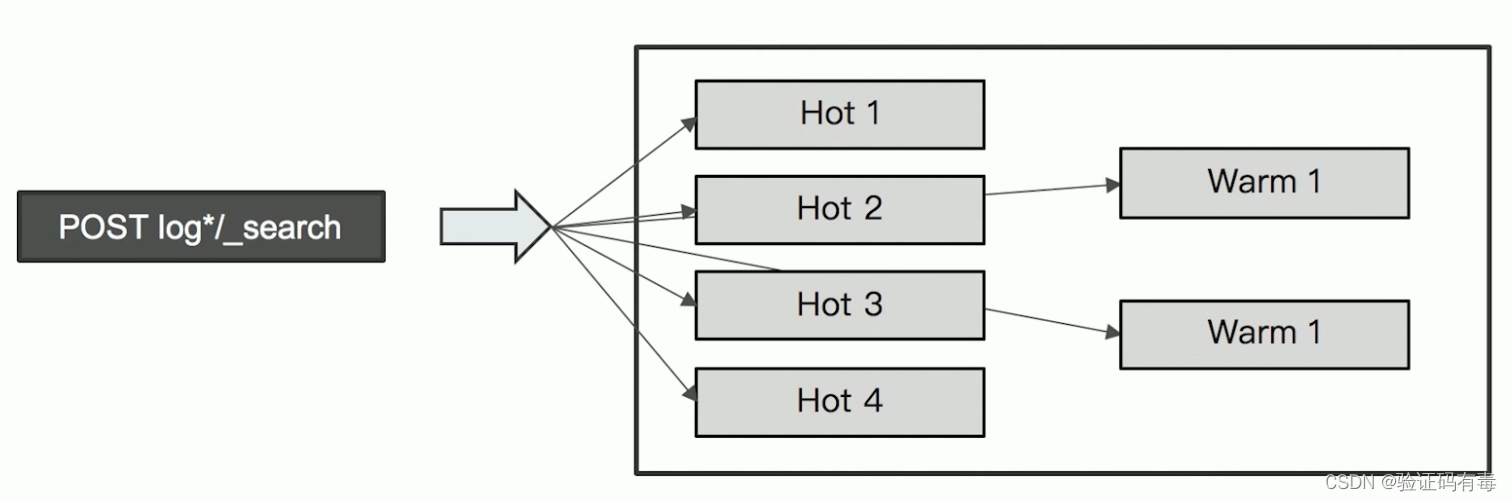
配置Hot & Warm 架构
使用Shard Filtering实现Hot&Warm node间的数据迁移
- node.attr来指定node属性:hot或是warm。
- 在index的settings里通过index.routing.allocation来指定索引(index)到一个满足要求的node

使用 Shard Filtering,步骤分为以下几步: - 标记节点(Tagging)
- 配置索引到Hot Node
- 配置索引到 Warm节点
1)标记节点
需要通过“node.attr”来标记一个节点
- 节点的attribute可以是任何的key/value
- 可以通过elasticsearch.yml 或者通过-E命令指定
# 标记一个 Hot 节点
elasticsearch.bat -E node.name=hotnode -E cluster.name=tulingESCluster -E http.port=9200 -E path.data=hot_data -E node.attr.my_node_type=hot# 标记一个 warm 节点
elasticsearch.bat -E node.name=warmnode -E cluster.name=tulingESCluster -E http.port=9201 -E path.data=warm_data -E node.attr.my_node_type=warm# 查看节点
GET /_cat/nodeattrs?v
2)配置Hot数据
创建索引时候,指定将其创建在hot节点上
# 配置到 Hot节点
PUT /index-2022-05
{"settings":{"number_of_shards":2,"number_of_replicas":0,"index.routing.allocation.require.my_node_type":"hot"}
}POST /index-2022-05/_doc
{"create_time":"2022-05-27"
}#查看索引文档的分布
GET _cat/shards/index-2022-05?v
3)旧数据移动到Warm节点
Index.routing.allocation是一个索引级的dynamic setting,可以通过API在后期进行设定
# 配置到 warm 节点
PUT /index-2022-05/_settings
{ "index.routing.allocation.require.my_node_type":"warm"
}
GET _cat/shards/index-2022-05?v
2.5 如何对集群的容量进行规划
一个集群总共需要多少个节点?一个索引需要设置几个分片?规划上需要保持一定的余量,当负载出现波动,节点出现丢失时,还能正常运行。做容量规划时,一些需要考虑的因素:
- 机器的软硬件配置
- 单条文档的大小│文档的总数据量│索引的总数据量((Time base数据保留的时间)|副本分片数
- 文档是如何写入的(Bulk的大小)
- 文档的复杂度,文档是如何进行读取的(怎么样的查询和聚合)
评估业务的性能需求:
- 数据吞吐及性能需求
- 数据写入的吞吐量,每秒要求写入多少数据?
- 查询的吞吐量?
- 单条查询可接受的最大返回时间?
- 了解你的数据
- 数据的格式和数据的Mapping
- 实际的查询和聚合长的是什么样的
ES集群常见应用场景:
- 搜索: 固定大小的数据集
- 搜索的数据集增长相对比较缓慢
- 日志: 基于时间序列的数据
- 使用ES存放日志与性能指标。数据每天不断写入,增长速度较快
- 结合Warm Node 做数据的老化处理
硬件配置:
- 选择合理的硬件,数据节点尽可能使用SSD
- 搜索等性能要求高的场景,建议SSD
- 按照1∶10-20的比例配置内存和硬盘
- 日志类和查询并发低的场景,可以考虑使用机械硬盘存储
- 按照1:50的比例配置内存和硬盘
- 单节点数据建议控制在2TB以内,最大不建议超过5TB
- JVM配置机器内存的一半,JVM内存配置不建议超过32G
- 不建议在一台服务器上运行多个节点
内存大小要根据Node 需要存储的数据来进行估算
- 搜索类的比例建议: 1:16
- 日志类: 1:48——1:96之间
假设总数据量1T,设置一个副本就是2T总数据量
- 如果搜索类的项目,每个节点31*16 = 496 G,加上预留空间。所以每个节点最多400G数据,至少需要5个数据节点
- 如果是日志类项目,每个节点31*50= 1550 GB,2个数据节点即可
部署方式:
- 按需选择合理的部署方式
- 如果需要考虑可靠性高可用,建议部署3台单一的Master节点
- 如果有复杂的查询和聚合,建议设置Coordinating节点
集群扩容:
- 增加Coordinating / Ingest Node
- 解决CPU和内存开销的问题
- 增加数据节点
- 解决存储的容量的问题
- 为避免分片分布不均的问题,要提前监控磁盘空间,提前清理数据或增加节点
2.6 如何设计和管理分片
单个分片
- 7.0开始,新创建一个索引时,默认只有一个主分片。单个分片,查询算分,聚合不准的问题都可以得以避免
- 单个索引,单个分片时候,集群无法实现水平扩展。即使增加新的节点,无法实现水平扩展
两个分片
集群增加一个节点后,Elasticsearch 会自动进行分片的移动,也叫 Shard Rebalancing

算分不准的原因
相关性算分在分片之间是相互独立的,每个分片都基于自己的分片上的数据进行相关度计算。这会导致打分偏离的情况,特别是数据量很少时。当文档总数很少的情况下,如果主分片大于1,主分片数越多,相关性算分会越不准
一个示例如下:
PUT /blogs
{"settings":{"number_of_shards" : "3"}
}POST /blogs/_doc/1?routing=fox
{"content":"Cross Cluster elasticsearch Search"
}POST /blogs/_doc/2?routing=fox2
{"content":"elasticsearch Search"
}POST /blogs/_doc/3?routing=fox3
{"content":"elasticsearch"
}GET /blogs/_search
{"query": {"match": {"content": "elasticsearch"}}
}#解决算分不准的问题
GET /blogs/_search?search_type=dfs_query_then_fetch
{"query": {"match": {"content": "elasticsearch"}}
}
解决算分不准的方法:
- 数据量不大的时候,可以将主分片数设置为1。当数据量足够大时候,只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差
- 使用DFS Query Then Fetch
- 搜索的URL中指定参数“_search?search_type=dfs_query_then_fetch"
- 到每个分片把各分片的词频和文档频率进行搜集,然后完整的进行一次相关性算分
但是这样耗费更加多的CPU和内存,执行性能低下,一般不建议使用
如何设计分片数
当分片数>节点数时
- 一旦集群中有新的数据节点加入,分片就可以自动进行分配
- 分片在重新分配时,系统不会有downtime
多分片的好处: 一个索引如果分布在不同的节点,多个节点可以并行执行
- 查询可以并行执行
- 数据写入可以分散到多个机器
分片过多所带来的副作用
Shard是Elasticsearch 实现集群水平扩展的最小单位。过多设置分片数会带来一些潜在的问题:
- 每个分片是一个Lucene的索引,会使用机器的资源。过多的分片会导致额外的性能开销。
- 每次搜索的请求,需要从每个分片上获取数据
- 分片的Meta 信息由Master节点维护。过多,会增加管理的负担。经验值,控制分片总数在10W以内
如何确定主分片数
从存储的物理角度看:
- 搜索类应用,单个分片不要超过20 GB
- 日志类应用,单个分片不要大于50 GB
为什么要控制分片存储大小:
- 提高Update 的性能
- 进行Merge 时,减少所需的资源
- 丢失节点后,具备更快的恢复速度
- 便于分片在集群内 Rebalancing
如何确定副本分片数
副本是主分片的拷贝:
- 提高系统可用性︰响应查询请求,防止数据丢失
- 需要占用和主分片一样的资源
对性能的影响:
- 副本会降低数据的索引速度: 有几份副本就会有几倍的CPU资源消耗在索引上
- 会减缓对主分片的查询压力,但是会消耗同样的内存资源。如果机器资源充分,提高副本数,可以提高整体的查询QPS
ES的分片策略会尽量保证节点上的分片数大致相同,但是有些场景下会导致分配不均匀:
- 扩容的新节点没有数据,导致新索引集中在新的节点
- 热点数据过于集中,可能会产生性能问题
可以通过调整分片总数,避免分配不均衡
index.routing.allocation.total_shards_per_node,index级别的,表示这个index每个Node总共允许存在多少个shard,默认值是-1表示无穷多个;cluster.routing.allocation.total_shards_per_node,cluster级别,表示集群范围内每个Node允许存在有多少个shard。默认值是-1表示无穷多个。
如果目标Node的Shard数超过了配置的上限,则不允许分配Shard到该Node上。注意:index级别的配置会覆盖cluster级别的配置
相关文章:
【ES专题】ElasticSearch集群架构剖析
目录 前言阅读对象阅读导航要点笔记正文一、ES集群架构1.1 为什么要使用ES集群架构1.2 ES集群核心概念1.2.1 节点1.2.1.1 Master Node主节点的功能1.2.1.2 Data Node数据节点的功能1.2.1.3 Coordinate Node协调节点的功能1.2.1.4 Ingest Node协调节点的功能1.2.1.5 其他节点功能…...

Kafka与Flink的整合 -- sink、source
1、首先导入依赖: <dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.15.2</version></dependency> 2、 source:Flink从Kafka中读取数据 p…...

小鱼ROS
git clone git clone https://ghproxy.com/https://github.com/stilleshan/ServerStatus git clone 私有仓库 Clone 私有仓库需要用户在 Personal access tokens 申请 Token 配合使用.git clone https://user:your_tokenghproxy.com/https://github.com/your_name/your_priv…...
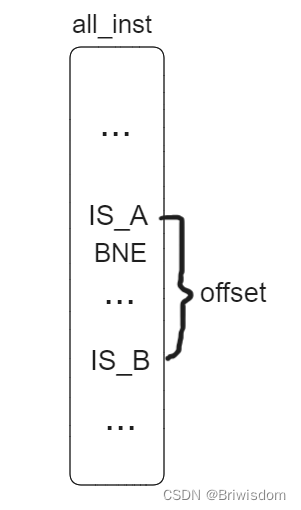
简单讲讲RISC-V跳转指令基于具体场景的实现
背景 在 RISC-V指令集中,一共有 6 条有条件跳转指令,分别是 beq、bne、blt、bltu、bge、bgeu。如下是它们的定义与接口 BEQ rs1, rs2, imm ≠ BNE rs1, rs2, imm < BLT rs1, rs2, imm ≥ BGE rs1, rs2, imm < unsigned BLTU rs1…...
 File类)
第13章 Java IO流处理(一) File类
目录 内容说明 章节内容 一、 File类 内容说明 结合章节内容重点难点,会对重要知识点进行扩展,以及做示例说明等,以便更好理解重点难点 章节内容 一、 File类 1、文件与目录的描述类——File ✔️ File类并不用来进行文件的读/写操作,并未涉及到写入或读取文件内容的…...

测试面试题集锦(四)| Linux 与 Python 编程篇(附答案)
本系列文章总结归纳了一些软件测试工程师常见的面试题,主要来源于个人面试遇到的、网络搜集(完善)、工作日常讨论等,分为以下十个部分,供大家参考。如有错误的地方,欢迎指正。有更多的面试题或面试中遇到的…...

pytorch中的矩阵乘法
1. 运算符介绍 关于运算,*运算,torch.mul(), torch.mm(), torch.mv(), tensor.t() 和 *代表矩阵的两种相乘方式: 表示常规的数学上定义的矩阵相乘; *表示两个矩阵对应位置处的两个元素相乘。 1.1 矩阵点乘 *和torch.mul()等同…...

Java--Stream流详解
Stream是Java 8 API添加的一个新的抽象,称为流Stream,以一种声明性方式处理数据集合(侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式) Stream流是从支持数据处理操作的源生成的元素序列,源可…...

[PHP]ShopXO企业级B2C免费开源商城系统 v2.3.1
ShopXO 企业级B2C免费开源电商系统! 求实进取、创新专注、自主研发、国内领先企业级B2C电商系统解决方案。 遵循Apache2开源协议发布,无需授权、可商用、可二次开发、满足99%的电商运营需求。 PCH5、支付宝小程序、微信小程序、百度小程序、头条&抖音…...

Python基础入门系列详解20篇
Python基础入门(1)----Python简介 Python基础入门(2)----安装Python环境(Windows、MacOS、CentOS、Ubuntu) Python基础入门(3)----Python基础语法:解释器、标识符、关键…...
P02项目(学习)
★ P02项目 项目描述:安全操作项目旨在提高医疗设备的安全性,特别是在医生离开操作屏幕时,以减少非授权人员的误操作风险。为实现这一目标,我们采用多层次的保护措施,包括人脸识别、姿势检测以及二维码识别等技术。这些…...

pandas 笔记:get_dummies分类变量one-hot化
1 函数介绍 pandas.get_dummies 是 pandas 库中的一个函数,它用于将分类变量转换为哑变量/指示变量。所谓的哑变量,就是将分类变量的每一个不同的值转换为一个新的0/1变量。在输出的DataFrame中,每一列都以该值的名称命名 pandas.get_dummi…...

PTE作文练习(一)
目录 65分备考建议 WE模版 范文 Supporting ideas: SWT 65分备考建议 RA重在多听标准的正确的示范,RS重在抓大放小,WFD重在整理错题,以及反反复复的车轮战,FIBRW重在“以对代记” 就是直接看答案,节约时间&#…...

如何做到一套FPGA工程无缝兼容两款不同的板卡?
试想这样一种场景,有两款不同的FPGA板卡,它们的功能代码90%都是一样的,但是两个板卡的管脚分配完全不同,一般情况下,我们需要设计两个工程,两套代码,之后还需要一直维护两个版本。 那么有没有一种自动化的方式,实现一个工程,编译出一个程序文件,下载到这两个不同的板…...
VSCode修改主题为Eclipse 绿色护眼模式
前言 从参加开发以来,一直使用eclipse进行开发,基本官方出新版本,我都会更新。后来出来很多其他的IDE工具,我也尝试了,但他们的主题都把我劝退了,黑色主题是谁想出来?😂 字体小的时…...

conan和cmake编译器版本不匹配问题解决
conan和cmake编译器版本不匹配问题解决 1 问题现象2 解决方法2.1 在CMakeLists.txt禁止编译器检查2.1.1 修改方式 2.2 探查问题出现的根本原因2.2.1 安装升级gcc2.2.2 安装升级g 注 执行环境:ubuntu 1 问题现象 conan要求的编译器版本和cmake检测到的当前的编译器…...

float单精度浮点数如何在计算机中存储
文章目录 1 float型数据组成2 实际举例3 代码测试4 写在最后 1 float型数据组成 按照IEEE浮点标准存储浮点数时,一个float型的值由1个符号位(最左边的位或最高有效位)、8个指数位以及23个小数位依次组成: 符号位为0时表示正数,为1…...

机器视觉在虚拟现实与增强现实中的作用
机器视觉在虚拟现实(VR)和增强现实(AR)中发挥着至关重要的作用。这些技术的核心是计算机视觉领域,重点是让计算机具有“看到”和理解周围世界的能力。 在虚拟现实中,计算机视觉用于创建和处理用户所见的虚…...

红黑数原理及存在原因
我红黑树那么牛,你们为什么不用?_哔哩哔哩_bilibili 面试时经常会被问到红黑树,它到底有什么优点呢? 对于查找数据,数组二分查询速度最快,时间复杂度为O(logN)。但是如果增加和删除数据,数组就…...
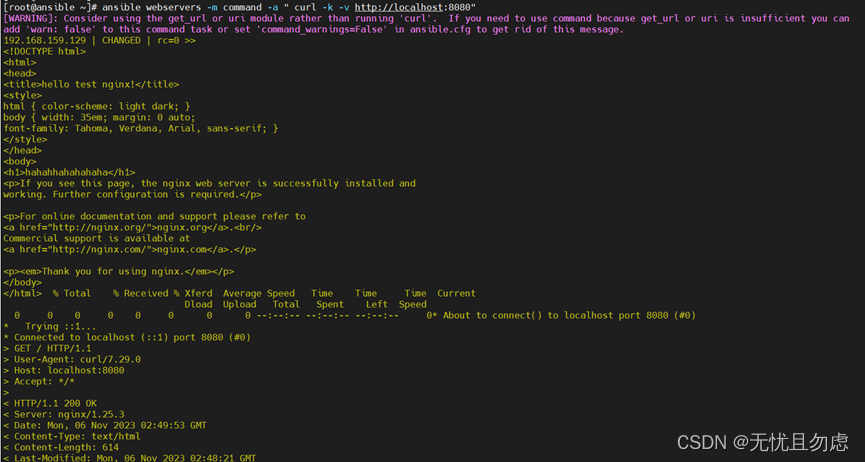
Ansible入门—安装部署及各个模块应用案例(超详细)
目录 前言 一、环境概况 修改主机名(可选项) 二、安装部署 1.安装epel扩展源 2.安装Ansible 3.修改Ansible的hosts文件 4.生成密钥 三、Ansible模块使用介绍 Command模块 Shell模块 User模块 Copy模块 File模块 Hostname模块 Yum模块 Se…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...