Intel oneAPI笔记(2)--jupyter官方文档(oneAPI_Intro)学习笔记
前言
本文是对jupyterlab中oneAPI_Essentials/01_oneAPI_Intro文档的学习记录,包含对SYCL、DPC++ extends SYCL、oneAPI Programming models等介绍和SYCL代码的初步演示等内容
oneAPI编程模型综述
oneAPI编程模型提供了一个全面而统一的开发人员工具组合,可以跨硬件目标使用,包括一系列跨越多个工作负载域的性能库,这些库包括针对每个目标体系结构定制编码的函数,因此相同的函数调用可以在支持的体系结构中提供优化性能
多体系结构编程挑战
目前,在以数据为中心的领域,专用工作负载正在增长。每种以数据为中心的硬件通常需要使用不同的语言和库进行编程,因为没有通用的编程语言或 API,这需要维护单独的代码库。开发人员必须学习一整套不同的工具,因为跨平台的工具支持不一致。为每个硬件平台开发软件需要单独的投资,并且几乎无法重用该工作以针对不同的体系结构。
oneAPI的引入
oneAPI作为一种统一编程模型,包括表达并行性的统一和简化的语言和库,它有着很好的开放性,可以与现有的HPC编程模型相互操作
一个简单的例子
%%writefile lab/simple.cpp
//==============================================================
// Copyright © Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include <sycl/sycl.hpp>
using namespace sycl;
static const int N = 16;
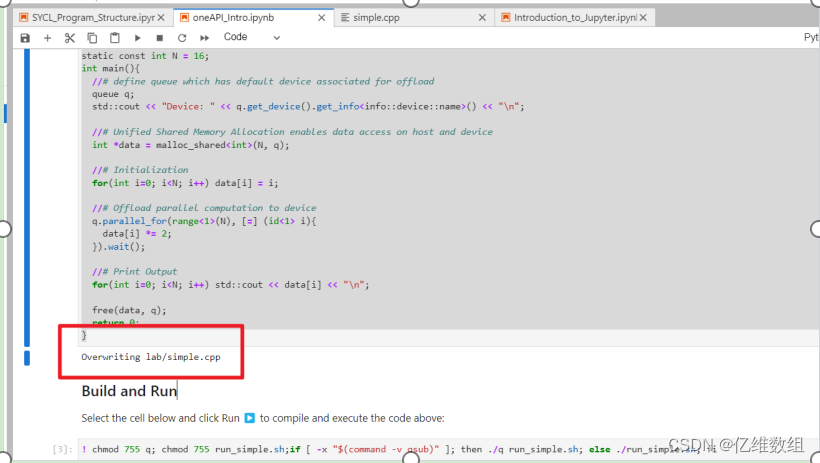
int main(){//# define queue which has default device associated for offloadqueue q;std::cout << "Device: " << q.get_device().get_info<info::device::name>() << "\n";//# Unified Shared Memory Allocation enables data access on host and deviceint *data = malloc_shared<int>(N, q);//# Initializationfor(int i=0; i<N; i++) data[i] = i;//# Offload parallel computation to deviceq.parallel_for(range<1>(N), [=] (id<1> i){data[i] *= 2;}).wait();//# Print Outputfor(int i=0; i<N; i++) std::cout << data[i] << "\n";free(data, q);return 0;
}这是一个简单的SYCL编程例子,第一行%%writefile lab/simple.cpp的作用是,当将这个代码在jupyter lab中的一个cell中点运行时,将会把除了这一行的代码之外的所有代码保存在jupyterlab的/lab(相对路径)的位置的simple.cpp文件当中
也就是说,运行这个之后只会把代码保存在一个文件中:
之后,在下一个cell中运行这段代码,才是对上面的代码的真正运行:
! chmod 755 q; chmod 755 run_simple.sh;if [ -x "$(command -v qsub)" ]; then ./q run_simple.sh; else ./run_simple.sh; fi
运行结果

SYCL
sycl代表了一项行业标准化工作,包括对c++数据并行编程的支持,被概括为“面向opencl的c++单源异构编程”。sycl是一个基于opencl的跨平台的抽象层,它使异构处理器的代码能够使用c++以“单一源”风格编写,使编译器能够分析和优化整个程序,而不管代码要在哪个设备上运行
与opencl不同,sycl包含模板和lambda函数,使高级应用程序软件能够清晰地编码,并优化内核代码的加速。
数据并行c++(dpc++)是一个api实现的sycl编译器。利用了现代c++的生产力优势和熟悉的结构,并结合了数据并行性和异构编程的sycl标准
sycl是一种单源语言,其中主机代码和异构加速器内核可以混合在同一源文件中。程序员可以使用熟悉的c++和代用附加功能的库结构,如用于工作定位的队列,用于数据管理的缓冲区,以及用于并行性的parallel_for来指示应该卸载哪部分的计算和数据
oneAPI编程模型
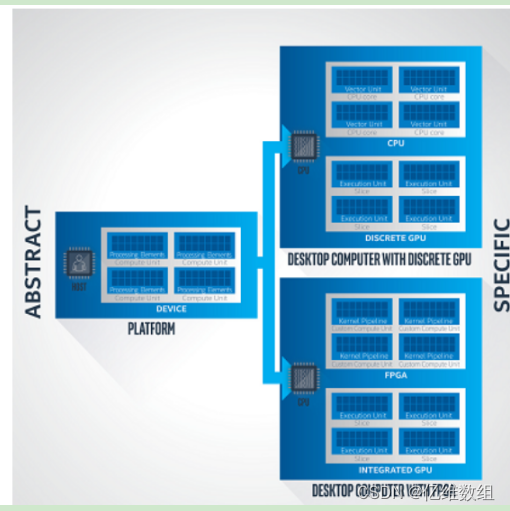
·平台模型
oneAPI的平台模型基于SYCL平台模型,指定一个主机控制一个或多个设备。主机是计算机,通常是基于cpu的系统,执行程序主要部分
每个设备是一个加速器,一个包含计算资源的专用组件,它可以快速执行操作的子集,通常比cpu更快。每个设备包含一个或多个计算单元,每个计算单元包含一个或处理单元,处理单元是单独的计算引擎
·执行模型
执行模型基于SYCL执行模型,它定义并指定代码(称为内核)如何在设备上执行并于控制主机交互,主机执行模型通过命令组在主机和设备之间协调执行和数据管理。命令组是像内核调用和访问器这样的命令的分组,被提交到队列中执行
执行模型指定了如何在访问器上完成计算,从小的一维数据到大的多维数据集的计算分布在nd范围、工作组、子组的层次结构中,都是在工作提交到命令队列时指定的
需要注意的是,实际的内核代码代表一个工作项执行的工作,内核之外的代码控制的是执行多少并行性,工作的数量和分配时由nd范围和工作组的规格来控制
下图描述nd范围、工作组、子组和工作项之间的关系,总工作量是由工作组大小指定,该实例显示了x*y*z的nd范围大小,x’*y’*z’的工作组大小和x’的子组大小。因此有(x*y*z)/(x’*y’*z’)大小的工作组和(x*y*z)/x’大小的子组

·存储模型
基于SYCl*内存模式,它定义了主机和设备如何与内存交互,它协调主机和设备之间的内存分配和管理。内存模型是一种抽象,其目的是概括和适应不同的主机和设备配置。
在这个模型中,内存驻留在主机或设备上,由主机或设备拥有,并通过声明一个内存对象来指定。有两种不同类型的内存对象,缓冲器和镜像。这些内存对象再主机和设备之间的交互通过访问器(accessor)完成,访问器传达了期望的访问设置,例如主机和设备,以及特定的访问模式,例如读和写
考虑这样一种情况,内存通过传统的malloc调用在主机上分配,一旦在主机上分配了内存,就会创建一个缓冲区对象,它使主机分配的内存能够和设备通信,缓冲区类将该类型的项的类型和数量通信给设备进行计算,一旦主机上创建了缓冲区,设备上运行的访问类型就通过访问器accessor对象进行通信。
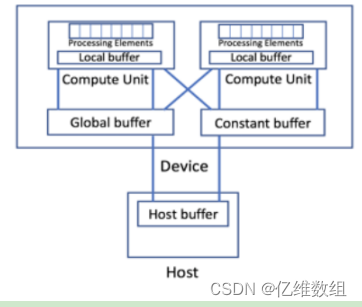
内核编程模型
支持主机和设备之间的显示并行性,这种并行性之所以显式,是因为程序员决定哪些代码在主机和设备上执行,它不是自动的,内核代码在加速器上执行。
采用oneAPI编程模型的程序支持单一源,这意味着主机代码和设备代码可以在同一个源文件中,但是,在语言一致性和语言特性方面,主机代码和设备代码中接受的源代码存在差异
相关文章:
Intel oneAPI笔记(2)--jupyter官方文档(oneAPI_Intro)学习笔记
前言 本文是对jupyterlab中oneAPI_Essentials/01_oneAPI_Intro文档的学习记录,包含对SYCL、DPC extends SYCL、oneAPI Programming models等介绍和SYCL代码的初步演示等内容 oneAPI编程模型综述 oneAPI编程模型提供了一个全面而统一的开发人员工具组合࿰…...
用 QT 开发软件会吃官司吗?
之前我写过我们现在使用 QT 开发跨平台软件,有朋友留言,QT 虽好,当心收到律师函。今天就来聊聊这个话题。 在开始这个话题之前,我们先把使用盗版 QT 排除在外,只讨论在合法且遵从版权协议的前提下,能否使用…...

远程运维用什么软件?可以保障更安全?
远程运维顾名思义就是通过远程的方式IT设备等运行、维护。远程运维适用场景包含因疫情居家办公,包含放假期间出现运维故障远程解决,包含项目太远需要远程操作等等。但远程运维过程存在一定风险,安全性无法保障,所以一定要选择靠谱…...

数据结构与算法C语言版学习笔记(2)-线性表、顺序存储结构的线性表
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 数据结构部分的知识框架一、线性表的定义和特点1.定义2.特点 二、线性表的实际案例引入1.案例一:多项式的加减乘除2.案例二:当多项式是稀疏多…...
【vite】vite.defineConfig is not a function/npm无法安装第三方包问题
当使用vite命令 npm init vite-app 项目名称时配置 import vue from vitejs/plugin-vueexport default defineConfig({plugins: [vue()] })会报错vite.defineConfig is not a function 还有就是npm下载的时候也会报错 原因vite插件vitejs/plugin-vue和vite版本问题 解决 调…...

234. 回文链表 --力扣 --JAVA
题目 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 解题思路 判断链表是否为回文链表取决于链表中各个节点的值,所以可以通过存储各节点的值进行对比判断&…...
【JAVA学习笔记】65 - 文件类,IO流--节点流、处理流、对象流、转换流、打印流
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter19/src/com/yinhai 文件 一、文件,流 文件,对我们并不陌生,文件是保存数据的地方,比如大家经常使用的word文档,txt文件,excel文件..都是文件。它既可以保存一张图片…...

R语言 复习 习题图片
这是日天土申哥不知道从哪淘来的R语言复习知识点图片,大部分内容都是课后习题的答案 加油吧,骚年,考个好分数...
c语言 结构体 简单实例
结构体 简单例子 要求: 结构体保存学生信息操作 代码 #include <stdio.h>//定义结构体 struct student{int ID;char name[20];char sex;char birthday[8];int grade; };int main(){int number;printf("请输入学生个数:");scanf(&quo…...

【ChatGPT】ChatGPT的自定义指令
ChatGPT的自定义指令 关于ChatGPT自定义指令的常见问题解答概述可用性如何使用您的数据自定义指令设置将应用于所有新聊天。启动新聊天可查看更改iOS & AndroidWeb 示例常见问题使用自定义指令的好处字符限制我的ChatGPT数据导出中是否包含自定义指令?当我删除我…...

《哥德尔、艾舍尔、巴赫——集异璧之大成》阅读笔记1
1、谁也不知道非智能行为和智能行为之间的界限在哪里。事实上,认为存在明显界限也许是愚蠢的。但是智能的基本能力还是确定的,它们是: 对于情境有很灵活的反应充分利用机遇弄懂含糊不清或彼此矛盾的信息认识到一个情境中什么是重要的因素&am…...

稳定细胞系构建技术介绍
抗体药物的开发是一个非常复杂的过程,构建适用于工业生产的高表达的稳定细胞株是抗体药工艺开发的起点和基础。一株稳定高产的工程细胞株不仅能显著增加单位体积产量,降低生产成本,还可以降低下游纯化工艺复杂度,确保获得安全&…...
k8s部署srs服务
k8s部署srs服务 项目需要把srs纳入k8s进行管理,需要通过k8s来部署srs服务然后原本的srs可以支持rtmp与webrtc两种,官网查了部署方式,k8s只有最基本的部署方式于是开始研究k8s部署能够正常推拉流的webrtc版本的srs 首先肯定是去官网查有无相关…...

使用Java分割PDF文件
在Java中,我们可以使用iText库来处理PDF文件。iText是一个流行的Java库,用于创建和处理PDF文件。在本篇博客中,我们将介绍如何使用Java分割一个PDF文件为多个小的PDF文件。 1. 引入iText依赖 首先,我们需要在项目中引入iText库的…...

LLM时代中的分布式AI
深度学习相较传统机器学习模型,对算力有更高的要求。尤其是随着深度学习的飞速发展,模型体量也不断增长。于是,前几年,我们看到了芯片行业的百家争鸣和性能指标的快速提升。正当大家觉得算力问题已经得到较大程度的缓解时…...
Zinx框架-游戏服务器开发003:架构搭建-需求分析及TCP通信方式的实现
文章目录 1 项目总体架构2 项目需求2.1 服务器职责2.2 消息的格式和定义 3 基于Tcp连接的通信方式3.1 通道层实现GameChannel类3.1.1 TcpChannel类3.1.2 Tcp工厂类3.1.3 创建主函数,添加Tcp的监听套接字3.1.4 代码测试 3.2 协议层与消息类3.2.1 消息的定义3.2.2 消息…...

如何使用Pyarmor保护你的Python脚本
目录 一、Pyarmor简介 二、使用Pyarmor保护Python脚本 1、安装Pyarmor 2、创建Pyarmor项目 3、添加Python脚本 4、配置执行环境 5、生成保护后的脚本 三、注意事项与未来发展 四、未来发展 五、总结 本文深入探讨了如何使用Pyarmor工具保护Python脚本。Pyarmor是一个…...

【c++】搜索二叉树的模拟实现
搜索二叉树的模拟实现 k模型完整代码 #pragma once namespace hqj1 {template<class K>struct SBTreeNode{public://这里直接用匿名对象作为缺省参数SBTreeNode(const K& key K()):_key(key), _cleft(nullptr), _cright(nullptr){}public:K _key;SBTreeNode* _cle…...
)
Kubeadm - K8S1.20 - 高可用集群部署(博客)
这里写目录标题 Kubeadm - K8S1.20 - 高可用集群部署一.环境准备1.系统设置 二.所有节点安装docker三.所有节点安装kubeadm,kubelet和kubectl1.定义kubernetes源2.高可用组件安装、配置 四.部署K8S集群五.问题解决1.加入集群的 Token 过期2.master节点 无法部署非系…...
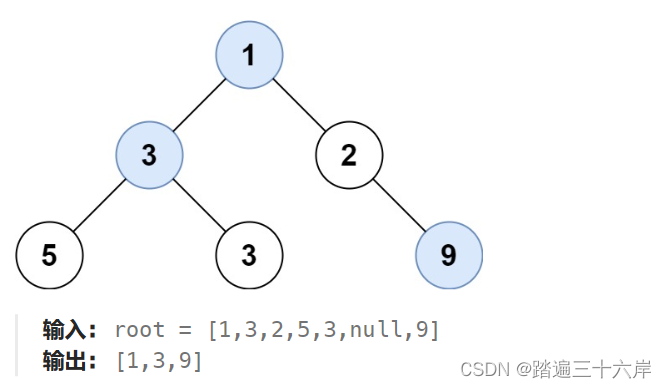
515. 在每个树行中找最大值
描述 : 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 题目 : LeetCode 在每个树行中找最大值 : 515. 在每个树行中找最大值 分析 : 这里其实就是在得到一层之后使用一个变量来记录当前得到的最大值 , 懂了前面的几道这就是小菜 解析 : /…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...