hive建分区表,分桶表,内部表,外部表
hive建分区表,分桶表,内部表,外部表
一、概念介绍
Hive是基于Hadoop的一个工具,用来帮助不熟悉 MapReduce的人使用SQL对存储在Hadoop中的大规模数据进行数据提取、转化、加载。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表(hive表对应着hdfs文件),并提供SQL查询功能,Hive能将SQL语句转变成MapReduce任务来执行。
分区表,分桶表,内部表,外部表的概念:
hive表由存储的数据和描述表数据形式的元数据组成。
内部表(默认):建表时没有用EXTERNAL关键字,状态下hive表会维护数据,将数据移入仓库目录(warehouse),表被删除时会同步删除元数据和数据
外部表(external table)建表时使用了EXTERNAL关键字,删除表时仅仅删除hive中的元数据,不会去删除数据。
内部表和外部表的区别表现在LOAD和DROP命令的不同上。LOAD 内部表会把数据移动到仓库目录(warehouse)外部表不会移动数据,只是记录数据路径信息,甚至不会检查路径是否存在DROP 内部表会将元数据和数据一起删除外部表只删除元数据
分区表:分区只是表目录下的子目录。比如按天分区,这样同一天的记录会被保存在同一分区(目录),优点在于查询特定日期的时候特别高效。分区是在创建表时使用 PARTITIONED BY子句定义的,分区列不在数据文件中。create table logs(ts INT,line STRING)PARTITIONED by(dt STRING);分区表加载数据时需要指定分区值load data local inpath ‘/home/public_train/part.txt’ into table logs PARTITION (dt=’2023-01-01’);使用show partitions logs;查看logs下的分区
分桶表:使用CLUSTERED BY子句指定划分通的列和桶的个数。每个桶是表(或分区)目录里的一个文件。create table bucketed_user(id INT,name STRING)CLUSTERED BY (id) into 4 BUCKETS;桶中的数据库可以进行排序:create table bucketed_users(id INT,name STRING)CLUSTERED BY (id) SORTED BY (id ASC) into 4 BUCKETS;查看分桶文件hdfs dfs -ls /user/hive/warehouse/bucketed_users分桶的优点在于快速取样和在表连接的时候提高效率。
下面我们使用hive建分区表,分桶表,内部表,外部表来熟悉hive的建表操作。
二、 hive建表实操
${HIVE_HOME}/bin/hive启动hive客户端
-- 准备工作, 创建数据文件,这里字段分割符是Tab键,对应着表定义中的'\t'
vi stu.txt
1 xiapi
2 xiaoxue
3 qingqin
4 lisi
--上传文件到hdfs
hdfs dfs -mkdir -p /hive/stu
hdfs dfs -put -f stu.txt hdfs://192.168.129.130:8020/hive/stu/stu.txt
下面使用${HIVE_HOME}/bin/hive启动hive客户端进行演示:
1. 创建表并将数据文件导入表中
建hive表(默认为内部表)会在数据仓库(hdfs默认/user/hive/warehouse)中创建同名表目录,load数据文件会将文件移动到表目录下。
-- drop table test;
-- 建hive表对应的是数据仓库warehouse中的hdfs文件,所以需要指定文件中的字段分隔符和行分隔符
create table test (
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';-- 查看表字段
desc test;
-- 查看建表语句
show create table test;
show tables;
-- 查看表文件
$ hdfs dfs -ls hdfs://192.168.129.130:8020/user/hive/warehouse/public_train.db/test-- 导入数据的语法为
-- LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
-- INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]-- 导入本地数据,需要加上LOCAL
load data LOCAL inpath '/home/public_train/stu.txt' INTO TABLE test;
select * from test;-- 导入HDFS数据, 会将HDFS文件移动到hive数据仓库
load data inpath 'hdfs://192.168.129.130:8020/hive/stu/stu.txt' INTO TABLE test;
select * from test;
-- 查看表文件,增加了1个文件
$ hdfs dfs -ls hdfs://192.168.129.130:8020/user/hive/warehouse/public_train.db/test
-- hdfs文件已经不见了(被移动到hive数据仓库了)
$ hdfs dfs -ls hdfs://192.168.129.130:8020/hive/stu/stu.txt-- OVERWRITE覆盖导入HDFS数据
load data inpath 'hdfs://192.168.129.130:8020/hive/stu/stu.txt' OVERWRITE INTO TABLE test;
select * from test;
-- 查看表文件,只剩下一个文件
$ hdfs dfs -ls hdfs://192.168.129.130:8020/user/hive/warehouse/public_train.db/test2. 基于现有表,创建新表
create table test_copy as select * from test;
3. 创建内部表和外部表,分别load和drop后查看数据文件观察区别。
内部表会维护数据文件即load时移动文件,drop时删除数据文件;
外部表hive不会维护数据文件, drop时不会删除数据文件,仅仅删除表定义;
-- 内部表使用上面的test表即可-- 建外部表使用external关键字
create external table stu (
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
location 'hdfs://192.168.129.130:8020/hive/stu' ;-- 查看建表语句
show create table stu;
select * from stu;$ hdfs dfs -put -f stu.txt hdfs://192.168.129.130:8020/hive/stu/stu.txt
$ hdfs dfs -ls hdfs://192.168.129.130:8020/hive/stu;
select * from stu;
-- 删除外部表后,数据文件还在
drop table stu;
$ hdfs dfs -ls hdfs://192.168.129.130:8020/hive/stu;create external table stu (
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
location 'hdfs://192.168.129.130:8020/hive/stu' ;
select * from stu;4. 创建分区表,并导入分区数据
分区是表目录下的子目录。分区字段值就是子目录名,分区字段不存在于数据文件中。
分区是表的水平拆分,查询特定分区的时候特别高效,只需要读取分区子目录下的文件。
-- PARTITIONED by指定分区字段
create table logs(ts INT,line STRING)
PARTITIONED by(dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';-- 加载数据
load data local inpath '/home/public_train/stu.txt' into table logs PARTITION (dt='2023-01-01');
-- 查看分区
show partitions logs;
-- 查看表文件(子目录名称即是分区)
dfs -ls /user/hive/warehouse/public_train.db/logs
select * from logs where dt='2023-01-01';-- 动态分区, 根据分区字段的值自动创建分区set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nonstrict;insert into logs partition (dt) values (8,'auto','2024-01-01');dfs -ls /user/hive/warehouse/public_train.db/logsshow partitions logs;
5. 建表分桶
单个分桶是表或分区下的单个表文件。
分桶可以将原本的单个表文件拆分为多个表文件,好处在于快速取样和表jion时的效率提升。
-- 强制分区及设置reduces数目为分区数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;create table bucketed_users (id INT,name STRING) CLUSTERED BY (id) into 4 BUCKETSROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';insert into table bucketed_users select ts, line from logs;dfs -ls /user/hive/warehouse/public_train.db/bucketed_users;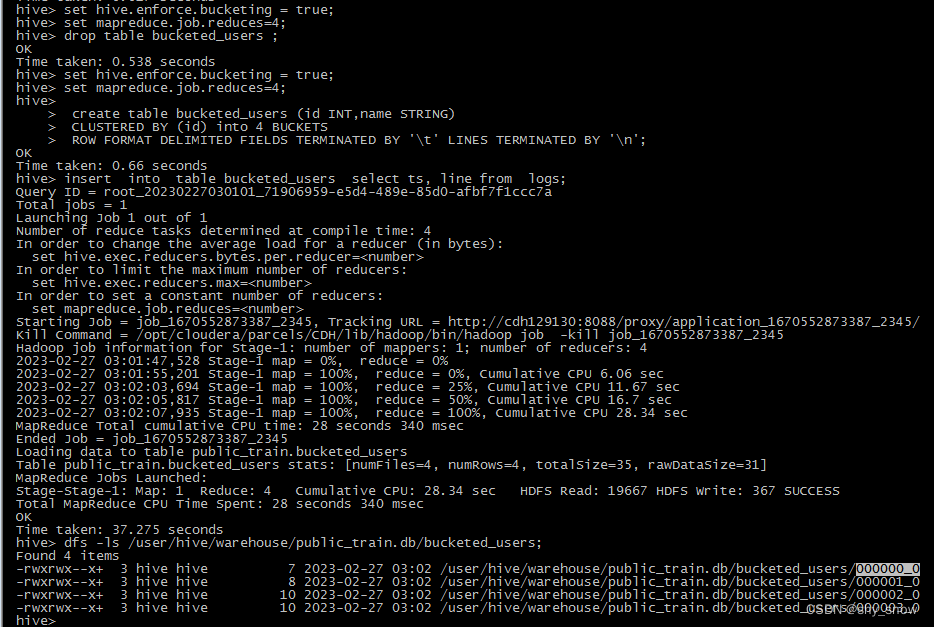
三、hive原理及架构
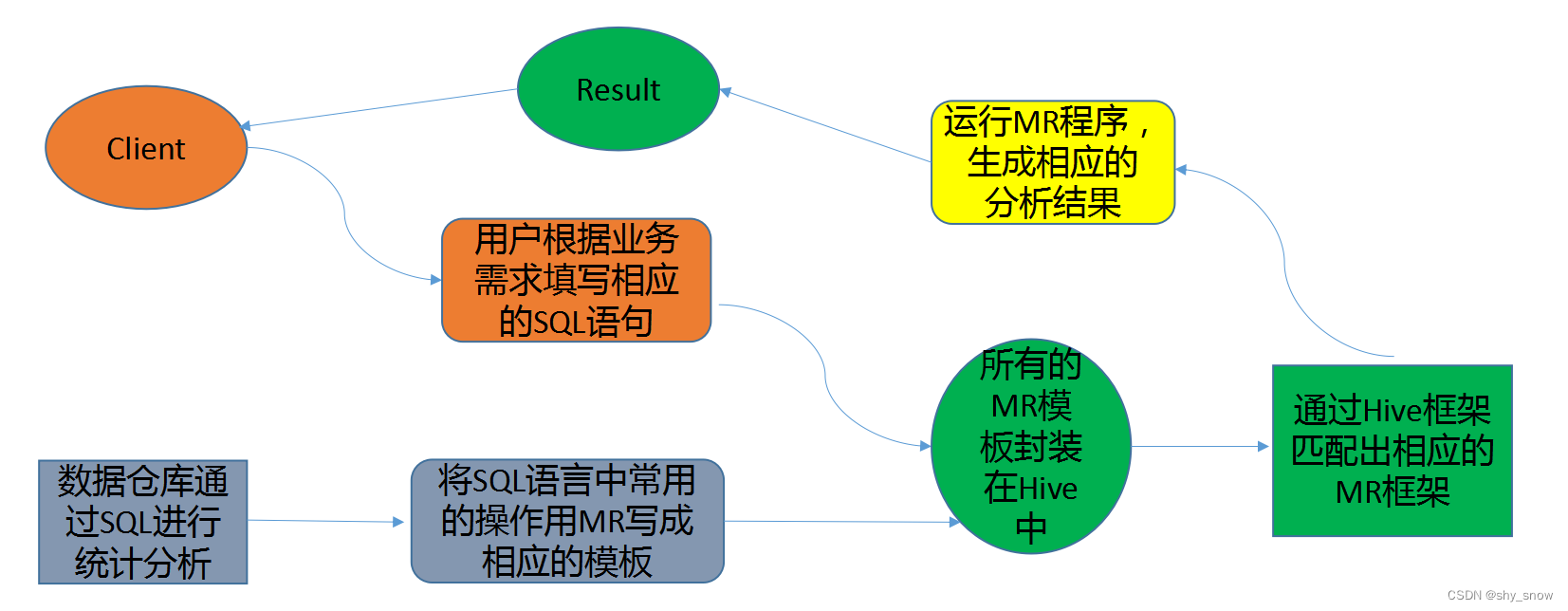
Hive 实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。下图简要说明Hive如何将SQL语句转换成MapReduce的实现原理。
基本概念:
底层数据是存储在 HDFS 上
元数据存储在元数据库中
Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
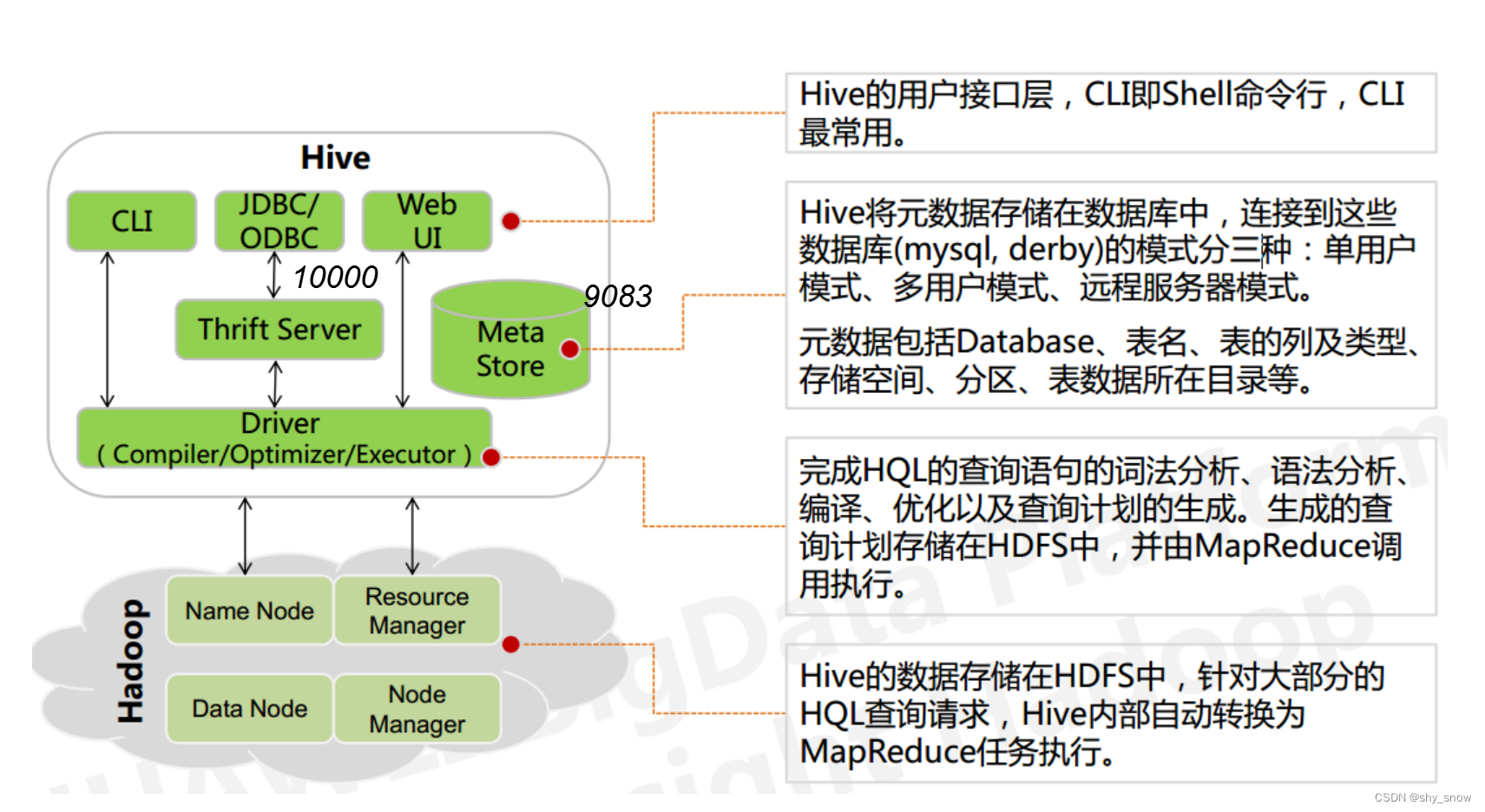
Hive的架构及常用端口
相关文章:
hive建分区表,分桶表,内部表,外部表
hive建分区表,分桶表,内部表,外部表 一、概念介绍 Hive是基于Hadoop的一个工具,用来帮助不熟悉 MapReduce的人使用SQL对存储在Hadoop中的大规模数据进行数据提取、转化、加载。Hive数据仓库工具能将结构化的数据文件映射为一张数…...
【分享】灌溉制度设计小程序VB源代码
说明 根据作物需水特性和当地气候、土壤、农业技术及灌水技术等因素制定的灌水方案。主要内容包括灌水次数、灌水时间、灌水定额和灌溉定额。灌溉制度是规划、设计灌溉工程和进行灌区运行管理的基本资料,是编制和执行灌区用水计划的重要依据。 1—计划湿润土层允…...

PR9268/300-000库存现货振动传感器 雄霸工控
PR9268/300-000库存现货振动传感器 雄霸工控PR9268/300-000库存现货振动传感器 雄霸工控SDM010PR9670/110-100PR9670/010-100PR9670/003-000PR9670/002-000PR9670/001-000PR9670/000-000PR9600/014-000PR9600/011-000PR9376/010-021PR9376/010-011PR9376/010-011PR9376/010-001…...
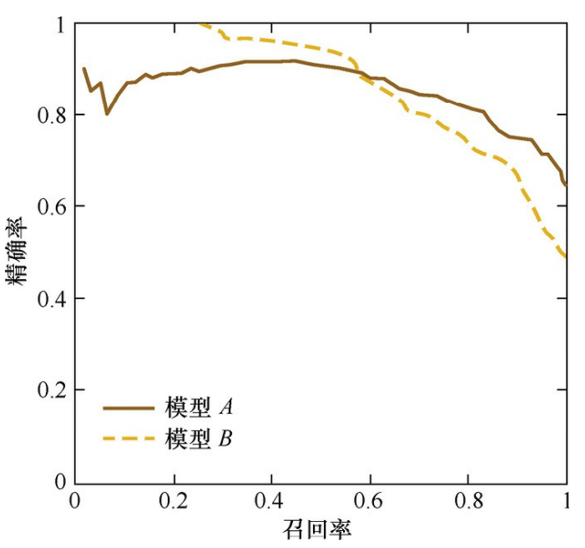
浅谈模型评估选择及重要性
作者:王同学 来源:投稿 编辑:学姐 模型评估作为机器学习领域一项不可分割的部分,却常常被大家忽略,其实在机器学习领域中重要的不仅仅是模型结构和参数量,对模型的评估也是至关重要的,只有选择那…...
多线程的初识和创建
✨个人主页:bit me👇 ✨当前专栏:Java EE初阶👇 ✨每日一语:知不足而奋进,望远山而前行。 目 录💤一. 认识线程(Thread)🍎1. 线程的引入🍏2. 线程…...

一句话设计模式3:工厂模式
工厂模式:new多种对象的简单方式。 文章目录 工厂模式:new多种对象的简单方式。前言一、两种工厂模式二、如何实现工厂模式1. 简单工厂2. 抽象工厂总结前言 工厂模式可以说比较常见的设计模式,仔细观察在很多源码中都有此种模式的应用;用来解决创建对象的创建问题; 一、两种工…...
】C. Serval and Toxel‘s Arrays【题解】)
【Codeforces Round #853 (Div. 2)】C. Serval and Toxel‘s Arrays【题解】
题目 Toxel likes arrays. Before traveling to the Paldea region, Serval gave him an array aaa as a gift. This array has nnn pairwise distinct elements. In order to get more arrays, Toxel performed mmm operations with the initial array. In the iii-th opera…...
100天精通Python(数据可视化篇)——第77天:数据可视化入门基础大全(万字总结+含常用图表动图展示)
文章目录1. 什么是数据可视化?2. 为什么会用数据可视化?3. 数据可视化的好处?4. 如何使用数据可视化?5. Python数据可视化常用工具1)Matplotlib绘图2)Seaborn绘图3)Bokeh绘图6. 常用图表介绍及其…...

PMP考前冲刺2.27 | 2023新征程,一举拿证
题目1-2:1.在产品开发过程中,项目发起人向项目团队推荐了一种新材料,新材料比现有的材料更便宜而且性能更好。如果团队采用新材料,不但有利于提升产品质量,而且可以显著降低成本。项目经理应该怎么办?A.采用新材料&am…...
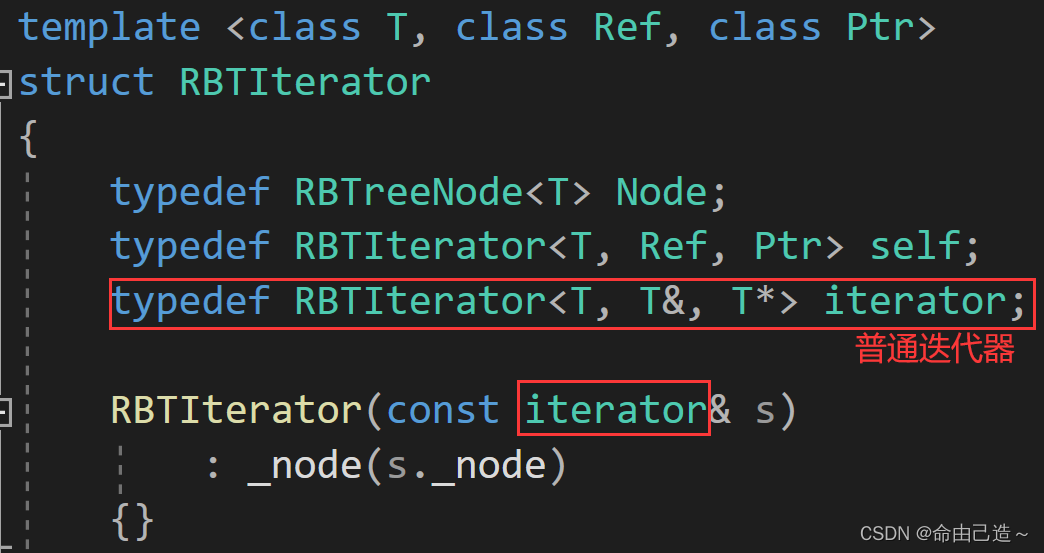
【C++】map和set的封装(红黑树)
map和set的封装一、介绍二、stl源码剖析三、仿函数获取数值四、红黑树的迭代器五、map的[]5.1 普通迭代器转const迭代器六、set源码七、map源码八、红黑树源码一、介绍 首先要知道map和set的底层都是用红黑树实现的 【数据结构】红黑树 set只需要一个key,但是map既…...
命令move)
【批处理脚本】-1.14-移动文件(夹)命令move
"><--点击返回「批处理BAT从入门到精通」总目录--> 共10页精讲(列举了所有move的用法,图文并茂,通俗易懂) 在从事“嵌入式软件开发”和“Autosar工具开发软件”过程中,经常会在其集成开发环境IDE(CodeWarrior,S32K DS,Davinci,EB Tresos,ETAS…)中,…...
逻辑地址和物理地址转换
在操作系统的学习中,很多抵挡都会涉及虚拟地址转换为物理地址的计算,本篇就简单介绍一下在分页存储管理、分段存储管理、磁盘存储管理中涉及的地址转换问题。 虚拟地址与物理地址 编程一般只有可能和逻辑地址打交道,比如在 C 语言中&#x…...
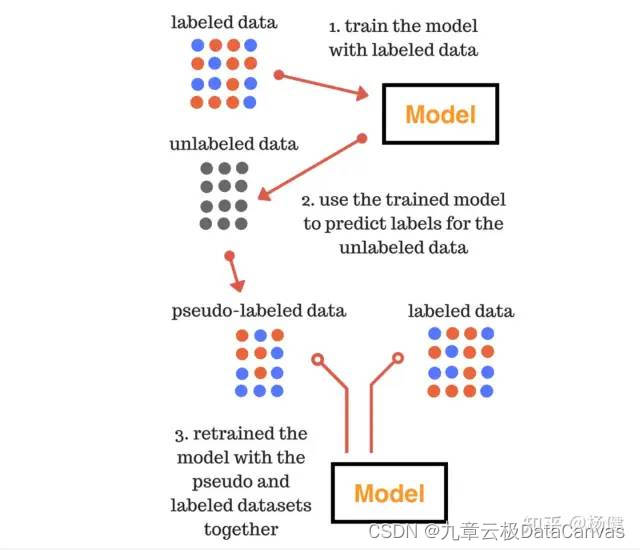
HyperGBM用4记组合拳提升AutoML模型泛化能力
本文作者:杨健,九章云极 DataCanvas 主任架构师 如何有效提高模型的泛化能力,始终是机器学习领域的重要课题。经过大量的实践证明比较有效的方式包括: 利用Early Stopping防止过拟合通过正则化降低模型的复杂度使用更多的训练数…...

P6软件中的前锋线设置
卷首语 所谓前锋线,是指从评估时刻的时标点出发,用点划线一次连接各项活动的实际进展位置所形成的的线段,其通常为折线。 关键路径法 前锋线比较法,是通过在进度计划中绘制实际进度前锋线以判断活动实际进度与计划进度的偏差&a…...

Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<二>---后端架构完善与接口开发
数据库准备: 在上一次Spring Boot Vue3 前后端分离 实战 wiki 知识库系统<一>---Spring Boot项目搭建已经将SpringBoot相关的配置环境给搭建好了,接下来则需要为咱们的项目创建一个数据库。 1、mysql的安装: 关于mysql的安装这里就…...
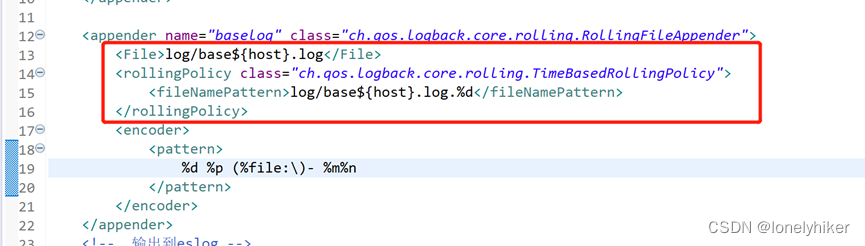
如何在logback.xml中自定义动态属性
原文地址:http://blog.jboost.cn/trick-logback-prop.html 当使用logback来记录Web应用的日志时,我们通过在logback.xml中配置appender来指定日志输出格式及输出文件路径,这在一台主机或一个文件系统上部署单个实例没有问题,但是…...
嵌入式系统硬件设计与实践(第一步下载eda软件)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 现实生活中,我们经常发现有的人定了很多的目标,但是到最后一个都没有实现。这听上去有点奇怪,但确实是实实在在…...
Portraiture4免费磨皮插件支持PS/LR
Portraiture 4免去了繁琐的手工劳动,选择性的屏蔽和由像素的平滑,以帮助您实现卓越的肖像润色。智能平滑,并删除不完善之处,同时保持皮肤的纹理和其他重要肖像的细节,如头发,眉毛,睫毛等。 一键…...

Python学习笔记202302
1、numpy.empty 作用:根据给定的维度和数值类型返回一个新的数组,其元素不进行初始化。 用法:numpy.empty(shape, dtypefloat, order‘C’) 2、logging.debug 作用:Python 的日志记录工具,这个模块为应用与库实现了灵…...

2023年大数据面试开胃菜
1、kafka的message包括哪些信息一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成,header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。当magic的值为1的时候,会在magic和crc32之间多一个字节…...

YOLO26惊艳效果:基于官方镜像的目标检测案例分享
YOLO26惊艳效果:基于官方镜像的目标检测案例分享 1. 引言:当YOLO26遇上官方镜像,效果有多惊艳? 想象一下,你手头有一堆图片或视频,需要快速、准确地找出里面的汽车、行人、动物,甚至更精细的物…...

LongCat-Image-Editn实用教程:如何用中文指令精准编辑图片
LongCat-Image-Editn实用教程:如何用中文指令精准编辑图片 1. 快速上手:从部署到第一张编辑图 你是不是也遇到过这样的烦恼?拍了一张不错的照片,但总觉得哪里差点意思——背景太乱、颜色不对,或者想给照片里的物品换…...

Flask Session 安全攻防实战:从密钥泄露到防御加固
1. Flask Session 安全威胁全景扫描 Flask 的客户端 Session 机制就像把家门钥匙藏在门口的垫子下面——虽然方便了自己,但也给小偷留了机会。我见过太多开发者直接照搬官方文档的示例代码,结果把整个系统的安全防线变成了纸糊的城墙。先带大家看看攻击者…...

AIGlasses_for_navigation资源管理:Win11系统优化与右键菜单定制提升开发效率
Win11开发者效率优化:从右键菜单到Python环境,打造AI开发工作站 如果你在Windows 11上做AI开发,特别是跑一些需要命令行和脚本的项目,可能会觉得有些地方用起来不太顺手。比如,那个新的右键菜单,找个“打开…...

Llama-3.2V-11B-cot部署教程:使用vLLM优化推理吞吐量的实操步骤
Llama-3.2V-11B-cot部署教程:使用vLLM优化推理吞吐量的实操步骤 1. 项目介绍 Llama-3.2V-11B-cot是一个强大的视觉语言模型,它不仅能理解图片内容,还能像人类一样进行逐步推理。这个模型基于Meta的Llama 3.2 Vision架构,拥有110…...
)
基于VSG控制的MMC并网逆变器仿真模型(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
【2026年拼多多春招- 3月15日 -第三题- 多多的配送轨迹】(题目+思路+JavaC++Python解析+在线测试)
题目内容 多多正在检查一段配送轨迹日志。日志长度为nnn,从起点(0,0)(0,0)(0,0)出发,按顺序记录了每一步移动指令。日志是一个长度为...
)
【UE4】GamePlay框架核心组件解析(蓝图篇)
1. GamePlay框架基础认知 第一次打开UE4编辑器时,很多人会被GamePlay框架里那些相似的类名搞晕。GameMode、GameState、PlayerController...这些看起来差不多的组件到底有什么区别?我在做第一个射击游戏时就犯过错误——把玩家分数存在了GameMode里&…...

基于springboot企业车辆管理系统
一、系统核心定位 基于 SpringBoot 的企业车辆管理系统,是专为企业(尤其是拥有多辆公务车、货运车的中大型企业)打造的 “车辆调度 - 使用 - 维护 - 成本” 全流程数字化平台。该系统解决传统车辆管理中 “调度混乱、用车申请繁琐、维护不及时…...

计算无人机巡逻覆盖地块数Java题解
问题描述 一块地用一个从 0 开始索引的二维二进制矩阵 block 表示,其中 0 表示空闲地块,1 表示放有障碍物的地块。在每个测试用例中,地的左上角永远是空闲的。一架无人机面向右侧,从左上角开始巡逻。无人机将一直前进,直到抵达的边界或遇到障碍物地块时,无人机将会顺时针…...