pt02-list-tuple-dir
容器类型
通用操作
数学运算符
(1) + 用于拼接两个容器
(2) += 用原容器与右侧容器拼接,并重新绑定变量
(3) * 重复生成容器元素
(4) *= 用原容器生成重复元素, 并重新绑定变量
(5) == !=:依次比较两个容器中元素,一但不同则返回比较结果。< <= > >= 意义不大
//输入整数,打印出正方形
number = int(input("请输入边长:"))
print("*" * number)
for item in range(number-2): #用不到的item,一般写成__print("*%s*"%(" " * (number-2)))
print("*" * number)
number = int(input("请输入边长:"))
for item in range(number):if item == 0 or item == number-1:print("*" * number)else:print("*%s*"%(" " * (number-2)))
成员运算符
(1) 语法:数据 in 序列, 数据 not in 序列
(2) 作用:如果在指定的序列中找到值,返回bool类型。
练习:注意下else的位置
如果账号qwe,密码123,输入账户密码验证。提示剩余输入次数,错误3次·提示锁定账户。
for count in range(3):login_id = input("请输入账号:")password = input("请输入密码:")if login_id == "qwe" and password == "123":print("登录成功")breakelse:print("登录失败")print("还可以登录%d次"%(2-count))print(f"还可以登录{2-count}次") #f-string,python3.6以上支持
else:print("锁定了")
索引index
(1) 作用:定位单个容器元素。
(2) 语法:容器[整数]
正向索引从0开始,第二个索引为1,最后一个为len(s)-1。
反向索引从-1开始,-1代表最后一个,-2代表倒数第二个,以此类推,第一个是 -len(s)。
message = "我是花果山齐天大圣"
print(message[2]) # 花
print(message[-2]) # 大
print(len(message)) # 9
切片slice
(1) 作用:定位多个容器元素。 语法:容器[开始索引:结束索引:步长]
结束索引不包含该位置元素,步长是切片每次获取完当前元素后移动的偏移量,开始、结束和步长都可以省略。
message = "我是花果山齐天大圣"
print(message[2:5:1]) # 花果山
print(message[2:5:1][1]) # 果
print(message[1:5]) # 是花果山
print(message[2:-4]) # 花果山
print(message[:-4]) # 我是花果山
print(message[:]) # 我是花果山齐天大圣
print(message[-3:]) # 天大圣
print(message[:2]) # 我是
print(message[-2:]) # 大圣
print(message[-2:3:-1]) # 大天齐山
print(message[1:1]) # 空
print(message[2:5:-1]) # 空
# 特殊:翻转
print(message[::-1]) # 圣大天齐山果花是我
内建函数
(1) len(x) 返回序列的长度
(2) max(x) 返回序列的最大值元素
(3) min(x) 返回序列的最小值元素
(4) sum(x) 返回序列中所有元素的和(元素必须是数值类型)
字符串 str
由一系列字符组成的不可变序列容器,存储的是字符的编码值。
基础知识
(1) 字节byte:计算机最小存储单位,等于8 位bit.
(2) 字符:单个的数字,文字与符号。
(3) 字符集(码表):存储字符与二进制序列的对应关系。
(4) 编码:将字符转换为对应的二进制序列的过程。
(5) 解码:将二进制序列转换为对应的字符的过程。
编码方式
(1) ASCII编码:包含英文、数字等字符,每个字符1个字节。
(2) GBK编码:兼容ASCII编码,包含21003个中文;英文1个字节,汉字2个字节。
(3) Unicode字符集:国际统一编码,旧字符集每个字符2字节,新字符集4字节。
(4) UTF-8编码:Unicode的存储与传输方式,英文1字节,中文3字节。
number =ord("我")
print(number)
25105
char =chr(25105)
print(char)
我
将输入的内容打印每个文字的编码值
for item in input("请输入"):print(ord(item))
循环输入编码值,打印出文字,为空时退出
while True:code_value = input("请输入编码值")if code_value == "":breakprint(chr(int(code_value)))
字面值
单引和双引号一样,推荐使用双引号
三引号作用:作为文档字符串,输入的什么,打印出的就是什么,会自动转换\n换行
转义字符&取消全部转义
(1) 定义:改变字符的原始含义。
\' \" \n \\ \t
原始字符串:取消转义。字符前加 r 取消字符串所有转移
a = r"C:\newfile\test.py"
b = "C:\newfile\test.py"
print(a)
print(b)C:\newfile\test.py
C:
ewfile est.py
字符串格式化
(1) 定义:生成一定格式的字符串。
(2) 语法:字符串%(变量)
name="tom"
age="18"
print("我的名字是%s,年龄是%s"%(name,age))
(3) 类型码:
%s 字符串 %d整数 %f 浮点数
print("%.2d:%.2d"%(2,3)) # 时间 02:03
print("治愈比例为%d%%" % 5) # 治愈比例为5% %%打印出了%
print("价格%.2f元" % (5 / 3)) # 价格1.67元
"""练习:根据下列文字,提取变量,使用字符串格式化打印信息湖北确诊67802人,治愈63326人,治愈率0.9970秒是01分零10秒
"""
region = "湖北"
confirmed = 67802
cure = 63326
print("%s确诊%s人,治愈%s人,治愈率%.2f" % (region, confirmed, cure, cure / confirmed))
print("%s确诊%s人,治愈%s人,治愈率%.2f%%" % (region, confirmed, cure, cure / confirmed * 100))
//python3.6以上支持
print(f"{region}确诊{confirmed}人,治愈{cure}人,治愈率{(cure / confirmed * 100):.2f}%%")
second = 70
print("%s秒是%.2d分零%.2d秒" % (second, second // 60, second % 60))
print(f"{}")
f-srting 学习 高版本python支持
jin = 2
liang = 3
print("结果为:" + str(jin) + "斤" + str(liang) + "两")
print("结果为:%s斤%s两" % (jin, liang))
print(f"结果为:{jin}斤{liang}两")
""" 赌大小游戏玩家的身家初始10000,实现下列效果:少侠请下注: 30000超出了你的身家,请重新投注。少侠请下注: 8000你摇出了5点,庄家摇出了3点恭喜啦,你赢了,继续赌下去早晚会输光的,身家还剩18000少侠请下注: 18000你摇出了6点,庄家摇出了6点打平了,少侠,在来一局?少侠请下注: 18000你摇出了4点,庄家摇出了6点少侠,你输了,身家还剩 0哈哈哈,少侠你已经破产,无资格进行游戏
"""
import randommoney = 10000
while money > 0:bet = int(input("少侠请下注: "))if bet > money:print("超出了你的身家,请重新投注。")continuedealer = random.randint(1, 6)player = random.randint(1, 6)# print("你摇出了%s点,庄家摇出了%s点" % (player, dealer))print(f"你摇出了{player}点,庄家摇出了{dealer}点")if dealer > player:money -= betprint("少侠,你输了,身家还剩" + str(money))elif dealer < player:money += betprint("恭喜啦,你赢了,继续赌下去早晚会输光的,身家还剩" + str(money))else:print("打平了,少侠,在来一局?")
print("哈哈哈,少侠你已经破产,无资格进行游戏")一个小球从100米高度落下,每次弹回原高的一半计算,最小的弹回高度0.01米
--总共弹起多少次?(最小弹起高度0.--全过程总共移动多少米?
height =100
count=0
distance =height
while height/2 > 0.01: #弹起高度height/=2count+=1distance+=height*2print(f"第{count}次弹起的高度是{height/2}")
print(f"一共弹起{count}次")
print(f"移动的总长度是{distance:.2f}米")
列表list[] 可变
由一系列变量组成的可变序列容器。预留空间,自动扩容。可排序
基础操作
(1) 创建列表:
列表名 = []
列表名 = list(可迭代对象)
list_ages = [26, 23, 25, 16]
list_name = list("孙悟空")
print(list_name) # ['孙', '悟', '空']
(2) 添加元素:
列表名.append(元素)
列表名.insert(索引,元素)
list_names.append("小白龙")
list_names.insert(2, "哪吒")
print(list_names) # ['悟空', '唐三藏', '哪吒', '八戒', '沙僧', '小白龙']
(3) 定位元素:
列表名[索引] = 元素
变量 = 列表名[索引]
变量 = 列表名[切片] # 赋值给变量的是切片所创建的新列表
列表名[切片] = 容器 # 右侧必须是可迭代对象,左侧切片没有创建新列表。
element = list_names[-1]
print(element) # 小白龙
list_names[-1] = "二郎神" #修改
print(list_names) # ['悟空', '唐三藏', '哪吒', '八戒', '沙僧', '二郎神']
(4) 遍历:
正向:for 变量名 in 列表名:变量名就是元素反向:for 索引名 in range(len(列表名)-1,-1,-1):列表名[索引名]就是元素
list_names=['悟空', '唐三藏', '哪吒', '八戒', '沙僧', '二郎神']
for i in range(len(list_names) - 1, -1, -1):print(list_names[i]) #反向打出来了
list_names=['悟空', '唐三藏', '哪吒', '八戒', '沙僧', '二郎神']
for i in range(len(list_names)):#if xxxx:list_names[i] = "xxx"
print(list_names) #['xxx', 'xxx', 'xxx', 'xxx', 'xxx', 'xxx']
(5) 删除元素:
列表名.remove(元素)
del 列表名[索引或切片]
list_names.remove("八戒") #
根据定位删除 del 容器名[索引或者切片]
del list_names[0]
del list_names[-2:] 倒数第二个开始,全删
"""八大行星:"水星" "金星" "地球" "火星" "木星" "土星" "天王星" "海王星"-- 创建列表存储4个行星:“水星” "金星" "火星" "木星"-- 第三个位置插入"地球"、追加"土星" "天王星" "海王星"-- 打印第一个和最后一个元素-- 打印太阳到地球之间的行星(前两个行星)-- 删除"海王星",删除第四个行星-- 倒序打印所有行星(一行一个)
"""
list_planet = ["水星", "金星", "火星", "木星"]
list_planet.insert(2, "地球")
list_planet += ["土星", "天王星", "海王星"]
print(list_planet[0])
print(list_planet[-1])
print(list_planet[:2])
list_planet.remove("海王星")
del list_planet[3]
for i in range(len(list_planet)-1,-1,-1):print(list_planet[i])
深拷贝和浅拷贝了解
浅拷贝:复制过程中,只复制一层变量,不会复制深层变量绑定的对象的复制过程。
只备份一层,如果深层数据被修改将被影响。
深拷贝:复制整个依懒的变量。复制了整块内存,多画画内存图
复制所有数据,占用内存较多。
适用性:没有深层数据时,使用浅拷贝
list01 = ["北京", "上海"]
list02 = list01 # 列表1个,变量2个。 #赋值,没有产生列表复制
print(list02) #['北京', '上海']
list01[0] = "广东"
print(list02) #['广东', '上海'] #list02指向list01的内存数据
list03 = list01[:] #切片,创建新列表
print(list03) #['广东', '上海']
list03[-1] = "深圳" # 新列表被修改,不影响原列表
print(list03) #['广东', '深圳']
print(list01) #['广东', '上海']
print(list02) #['广东', '上海']
import copylist01 = ["北京",["上海","深圳"]]
list02 = list01
list03 = list01[:]
list03[0] = "北京03" #浅拷贝,修改浅拷贝的第一层数据,互不影响list01[0]仍是北京
list03[1][1] = "深圳03" #修改浅拷贝的第二层,将会影响,list01[1][1]的深圳将变化为深圳03
print(list01) # ['北京', ['上海', '深圳03']]
list02[0] = "北京02"
list02[1][1] = "深圳02"
print(list01) # ['北京02', ['上海', '深圳02']]list04 = copy.deepcopy(list01) # ['北京02', ['上海', '深圳02']] #深拷贝
list04[0] = "北京04"
print(list04) #['北京04', ['上海', '深圳02']]
list04[1][1] = "深圳04" #修改深拷贝的数据,互补影响,list01不会变化
print(list04) #['北京04', ['上海', '深圳04']]
print(list01) # ['北京02', ['上海', '深圳02']]
列表与字符串转换
(1) 列表转换为字符串: result = “连接符”.join(列表)
list01 = ["a", "b", "c"]
result = "-".join(list01) #-可替换,如“”为空 将输出abc
print(result) #a-b-c
result = []
for number in range(10):result.append(str(number))
result="".join(result)
print(result) #0123456789
输入内容,对内容进行拼接,当输入为空时,结束输入并打印出结果
result = []
while True:content =input("请输入内容")if content == "":breakresult.append(content)
result = "".join(result)
print(result)
练习
根据列表中的数字,重复生成*.list01 = [1, 2, 3, 4, 5, 4, 3, 2, 1]效果:*************************
list01 = [1, 2, 3, 4, 5, 4, 3, 2, 1]
for number in list01:print("*"*number)
根据列表中的数字,重复生成*.list02 = [1, 2, 3, 4, 5]效果:***************list02 = [1, 2, 3, 4, 5]
for i in range(len(list02)-1,-1,-1):print("*"*list02[i])
将列表中的数字累乘 list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5] 结果:806400list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
result =1
for item in list02:result*=item
print(result)
(2) 字符串转换为列表:列表 = “a-b-c-d”.split(“分隔符”)
场景:使用一个字符串存储多个信息时
list_result = "唐僧,孙悟空,八戒".split(",")[0]
print(list_result) #取出了唐僧
将下列英文语句按照单词进行翻转.
转换前:To have a government that is of people by people for people
转换后:people for people by people of is that government a have Tocontent = "To have a government that is of people by people for people"
list_temp = content.split(" ")
#print(list_temp[::-1])
result = " ".join(list_temp[::-1])
print(result)
列表推导式
(1) 定义:使用简易方法,将可迭代对象转换为列表。
(2) 语法:
变量 = [表达式 for 变量 in 可迭代对象]
变量 = [表达式 for 变量 in 可迭代对象 if 条件]
(3) 说明: 如果if真值表达式的布尔值为False,则可迭代对象生成的数据将被丢弃。
list01 = [9, 15, 65, 6, 78, 89]
# 需求:在list01中挑出能被3整除的数字存入list02 #
list02 = []
#for item in list01:
# if item % 3 == 0:
# list02.append(item)
list02 = [item for item in list01 if item % 3 == 0]
print(list02)
# 需求:在list01中所有数字的个位存储list03
# list03 = []
# for item in list01:
# list03.append(item % 10)
list03 = [item % 10 for item in list01]
print(list03)
生成10--30之间能被3或者5整除的数字
# list_result = []
# for number in range(10, 31):
# if number % 3 == 0 or number % 5 == 0:
# list_result.append(number)
# print(list_result)list_result = [number for number in range(10, 31) if number % 3 == 0 or number % 5 == 0]
print(list_result)
生成5 -- 20之间的数字平方
list_result = [item ** 2 for item in range(5, 21)]
print(list_result)
元组 tuple()不可变
(1) 由一系列变量组成的不可变序列容器,按需分配。节省内存,优先选择
(2) 不可变是指一但创建,不可以再添加/删除/修改元素。
基础操作
(1) 创建空元组:
元组名 = ()
元组名 = tuple()
(2) 创建非空元组:
元组名 = (20,)
元组名 = (1, 2, 3)
元组名 = 100,200,300
元组名 = tuple(可迭代对象)
(3) 获取元素:
变量 = 元组名[索引]
变量 = 元组名[切片] # 赋值给变量的是切片所创建的新列表
(4) 遍历元组:
正向:for 变量名 in 列表名:变量名就是元素反向:for 索引名 in range(len(列表名)-1,-1,-1):元组名[索引名]就是元素
# 1. 创建
# -- 元组名 = (元素1, 元素2, 元素3)
tuple01 = (10, 20, 30)
# -- 元组名 = tuple( 可迭代对象 )
list01 = ["a", "b", "c"]
tuple02 = tuple(list01) //场景:结算出结果存储时用元组
list02 = list(tuple02)# 2. 定位 # -- 读取(索引/切片)
print(tuple01[0]) # 10
print(tuple01[:2]) # (10, 20)# 3. 遍历
for item in tuple01: print(item) for i in range(len(tuple01) -1, -1, -1): print(tuple01[i])
# 4. 特殊
# 注意1:小括号可以省略
tuple03 = 10, 20, 30 # 注意2:如果元组中只有一个元素,必须有逗号
tuple04 = (10,) # 拆包: 多个变量 = 容器
a,b,c = tuple03 #print(a,b,c) 10 20 30
a,b,c = ["A","B","C"] #print(a,b,c) A B C
a,b,c = "孙悟空" # print(a,b,c) 孙 悟 空
*a,b = "孙悟空" # print(a,b) ['孙', '悟'] 空 # *收集剩余的变量
作用
(1) 元组与列表都可以存储一系列变量,由于列表会预留内存空间,所以可以增加元素。
(2) 元组会按需分配内存,所以**如果变量数量固定,建议使用元组,因为占用空间更小。
(3) 应用:
变量交换的本质就是创建元组:x, y = (y, x )
格式化字符串的本质就是创建元祖:"姓名:%s, 年龄:%d" % ("tarena", 15)
"""根据月日,计算是这一年的第几天.公式:前几个月总天数 + 当月天数例如:5月10日计算:31 29 31 30 + 10
"""
month = int(input("请输入月份:")) # 5
day = int(input("请输入日:")) # 10
tuple_days = (31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31)
# total_day = 0
# for i in range(month - 1):
# total_day += tuple_days[i]
total_day = sum( tuple_days[:month - 1] )
total_day += day
print("累计%s天" % total_day)
name = "张无忌"
names = ["赵敏", "周芷若"]
tuple01 = ("张翠山", name, names)
name = "无忌哥哥" #内存新址,元组指向仍是旧址张无忌
tuple01[2][0] = "敏儿" #指向列表names,names[0]改变
print(tuple01) # ('张翠山', '张无忌', ['敏儿', '周芷若'])
字典 **dict **{}
方便查找,不能排序
(1) 由一系列 键值对 组成的可变散列容器。
(2) 散列:对键进行哈希运算,确定在内存中的存储位置,每条数据存储无先后顺序。
(3) 键必须惟一且不可变(字符串/数字/元组),值没有限制。
基础操作
(1) 创建字典:
字典名 = {键1:值1,键2:值2}
字典名 = dict (可迭代对象)
(2) 添加/修改元素:
字典名[键] = 数据 #说明: 键不存在,创建记录。键存在,修改值。
(3) 获取元素:
变量 = 字典名[键] # 没有键则错误
(4) 遍历字典:
for 键名 in 字典名:字典名[键名]
for 键名,值名 in 字典名.items():语句
(5) 删除元素:
del 字典名[键]
1. 创建
# -- { 键1:值1, 键2:值2 }
dict_wk = {"name": "悟空", "age": 25, "sex": "女"}
# -- dict( [( , ),( , )] )
# 列表转换为字典的格式要求:列表元素必须能够"一分为二"
list01 = ["八戒", ("ts", "唐僧"), [1001, "齐天大圣"]]
dict01 = dict(list01) 2. 添加 字典名[键] = 值
dict_wk["money"] = 100000
print(dict_wk) # {'name': '悟空', 'age': 25, 'sex': '女', 'money': 100000} 3. 定位:字典名[键] # 字典不能使用 索引 切片
# -- 读取
print(dict_wk["name"])
# 注意:如果没有键则报错,解决:读取数据前,通过in判断.
if "money" in dict_wk: print(dict_wk["money"])# -- 修改 (与添加数据语法相同) 具有key为修改,没有key为添加
dict_wk["name"] = "空空"4. 删除 del 字典名[键]
del dict_wk["sex"]
print(dict_wk) # {'name': '空空', 'age': 25, 'money': 100000}5. 遍历
# 方式1:for 键 in 字典名称
for key in dict_wk: print(key)
# 方式2:for 值 in 字典名称.values()
for value in dict_wk.values(): print(value)
# 方式3:for 键,值 in 字典名称.items()
for key,value in dict_wk.items(): print(key) print(value)
数据类型转换
字典转列表
print(list(dict_wk.items())) # [('name','空空'), ('age', 25)] #键值都要
列表转字典
print(dict([(1,2),(3,4)])) # {1: 2, 3: 4}
字典推导式
使用简易方法,将可迭代对象转换为字典。
{键:值 for 变量 in 可迭代对象}
{键:值 for 变量 in 可迭代对象 if 条件}
# 需求:range(10)
new_dict = {}
for number in range(10):# 0~9new_dict[number] = number ** 2
print(new_dict)
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}new_dict = {number: number ** 2 for number in range(10) }
print(new_dict)
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
new_dict = {}
for number in range(10):# 0~9if number % 2 !=0:new_dict[number] = number ** 2
print(new_dict)
{1: 1, 3: 9, 5: 25, 7: 49, 9: 81}new_dict = {number: number ** 2 for number in range(10) if number % 2 != 0}
print(new_dict)
{1: 1, 3: 9, 5: 25, 7: 49, 9: 81}
练习1:
将两个列表,合并为一个字典
姓名列表["张无忌","赵敏","周芷若"],房间列表[101,102,103]
list_name = ["张无忌", "赵敏", "周芷若"]
list_room = [101, 102, 103]
dict_new = {list_name[i]: list_room[i] for i in range(len(list_name))}
print(dict_new)
{'张无忌': 101, '赵敏': 102, '周芷若': 103}
练习2:
颠倒练习1字典键值.如果存在一样的值,翻转过来也就是键重复了,将会覆盖掉之前的数据
new_dict = {value: key for key, value in dict_new.items()}
print(new_dict)
{101: '张无忌', 102: '赵敏', 103: '周芷若'}
集合set{} 使用较少
相当于只有键没有值的字典,不可重复,可用于列表去重
集合名={元素1,元素2,...}
list01=[1,2,3,1,5,5,6]
set01=set(list01)
print(set01) #{1, 2, 3, 5, 6} 去重
基础操作
添加
set01.add("666")
print(set01) //{1, 2, 3, '666', 5, 6}
5.6.3定位 不能定位
遍历
for item in set01:print(item)
删除
集合名.remove(元素名)
set01.remove("666")
运算
交集 & 返回共同值
并集 | 返回不重复的值
补集 ^ 返回不同的元素
子集 < 判断集合1是否属于集合2
超集 > ...
s1={1,2,3}
s2={2,3,4}
s3=s1 & s2 //{2, 3}
s4=s1 | s2 //{1, 2, 3, 4}
s5=s1 ^ s2 //{1, 4}
print(s1 < s2) //False
print(s1 > s2) //False
练习∶
一家公司有如下岗位∶
"经理”:“曹操","刘备”,"孙权“
"技术”:"曹操","刘备”,“张飞”,“关羽”
1.定义数据结构,存储以上信息 2.是经理也是技术的都有谁?
3.是经理不是技术的都有谁? 4.不是经理是技术的都有谁?
5.身兼一职的都有谁 6.公司总共有多少人数?dict_persons={"经理": {"曹操","刘备","孙权"},"技术": {"曹操","刘备","张飞","关羽"}
}
print(dict_persons["经理"] & dict_persons["技术"]) //{'刘备', '曹操'}
print(dict_persons["经理"] - dict_persons["技术"]) //{'孙权'}
print(dict_persons["技术"] - dict_persons["经理"])
print(dict_persons["经理"] ^ dict_persons["技术"]) //{'张飞', '孙权', '关羽'}
print(dict_persons["经理"] | dict_persons["技术"])
print(len(dict_persons["经理"] | dict_persons["技术"])) //5
综合练习
"""将列表中的数字累减list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
"""
list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
result = list02[0]
for i in range(1, len(list02)):result -= list02[i]
print(result) // -36
"""在列表中查找最大值(不使用max,自定义算法实现)思路:假设第一个元素就是最大值依次与后面元素进行比较如果发现更大值,则替换
"""
list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
max_value = list02[0]
for i in range(1, len(list02)):# 1 2 3 4 .. 总数-1if max_value < list02[i]:max_value = list02[i]
print(max_value) //8
"""取出十位上不是3,7,8的数字
"""
list03=[ 135,63,227, 675,470]
result = []
for item in list03:unit = str(item)[ -2]if unit in ( "3","7","8"):continueresult.append(item)
print (result) [63, 227]
"""在终端中获取颜色(RGBA),打印描述信息,否则提示颜色不存在"R" -> "红色""G" -> "绿色""B" -> "蓝色""A" -> "透明度"
"""
color = input("请输入颜色(RGBA):")
dict_color_info = {"R": "红色","G": "绿色","B": "蓝色","A": "透明度"
}
# print(dict_color_info[color])
if color in dict_color_info:print(dict_color_info[color])
else:print("颜色不存在")
"""彩票:双色球红色:6个 1--33之间的整数 不能重复蓝色:1个 1--16之间的整数1) 随机产生一注彩票(列表(前六个是红色,最后一个蓝色))2) 在终端中录入一支彩票要求:满足彩票的规则.
"""
import random# 1) 随机产生一注彩票(列表(前六个是红色,最后一个蓝色))
list_ticket = []
# 前六个红球
while len(list_ticket) < 6:number = random.randint(1, 33)if number not in list_ticket:list_ticket.append(number)
# 第七个蓝球
list_ticket.append(random.randint(1, 16))
print(list_ticket)# 2) 在终端中录入一支彩票
list_ticket = []
while len(list_ticket) < 6:# number = int(input("请输入第%d个红球号码:" % (len(list_ticket) + 1)))number = int(input(f"请输入第{len(list_ticket) + 1}个红球号码:"))if number in list_ticket:print("号码已经存在")elif number < 1 or number > 33:print("号码不在范围内")else:list_ticket.append(number)while len(list_ticket) < 7:number = int(input("请输入蓝球号码:"))if number < 1 or number > 16:print("号码不在范围内")else:list_ticket.append(number)
print(list_ticket)
种类与特点总结
字符串∶存储字符的编码,不可变,序列
列表∶存储变量,可变,序列!
元组∶存储变量,不可变,序列
字典∶存储键值对,可变,散列,键的限制∶唯一且不变(字符串、元组、数值)
集合︰存储键,可变,散列序列与散列
序列: 有顺序,空间连续(省地),定位单个元素慢
散列: 无顺序,数据分布松散(费地),定位单个元素最快
练习汇总
循环嵌套
"""两层for循环嵌套
""""""
for c in range(5):print("$", end=" ")
print() # 换行
for c in range(5):print("$", end=" ")
print() # 换行
for c in range(5):print("$", end=" ")
print() # 换行
"""# 外层循环执行一次,内层循环执行多次
for r in range(3): # 0 1 2for c in range(5): # 01234 01234 01234print("$", end=" ")print() # 换行
for r in range(4):for c in range(r+1):print("$", end=" ")print()$
$ $
$ $ $
$ $ $ $
# 外层循环4次 内层循环
"""二维列表定位元素语法列表名[行索引][列索引]
"""
list01 = [[1, 2, 3, 4, 5],[6, 7, 8, 9, 10],[11, 12, 13, 14, 15],
]print(list01[0][0]) #1
print(list01[0][4]) #5
print(list01[2][1]) #12#将第一行从左到右逐行打印
for item in list01[0]:print(item)
for c in range(len(list01[0])):print(list01[0][c]) # 1 2 3 4 5#将第二行从右到左逐行打印
for c in range(4,-1,-1):print(list01[1][c])
for c in range(len(list01[1])-1,-1,-1):print(list01[1][c])#将第三列行从上到下逐个打印
for r in range(len(list01)):print(list01[r][2])#将第四列行从下到上逐个打印
for r in range(len(list01)-1,-1,-1):print(list01[r][3])#将二维列表以表格状打印
for r in range(len(list01)):for c in range(len(list01[r])):print(list01[r][c],end = "\t")print()for line in list01:for item in line:print(item,end="\t")print()
字典的修改
dict_hobbies = {
"于谦":["抽烟","喝酒","烫头"],
"郭德纲":["说","学","逗","唱"]
}
#打印于谦的所有爱好(一行一个)
for item in dict_hobbies["于谦"]:print(item)#计算郭德纲所有爱好数量
print(len(dict_hobbies["郭德纲"]))#打印所有人(一行一个)
for key1 in dict_hobbies:print(key1)#打印所有爱好(一行一个)
for value1 in dict_hobbies.values():for item in value1:print(item)
#修改
dict_hobbies["于谦"][0] = "唱歌"
dict_travel_info = {
"北京":{
"景区":["长城","故宫"],
"美食":["烤鸭","豆汁焦圈","面"]
},
"四川": {
"景区":["九寨沟","峨眉山"],"美食":["火锅","兔头"]
}
}打印北京的第一个景区∶长城
print(dict_travel_info["北京"]["景区"][0])所有城市(一行一个)效果∶北京四川
for key in dict_travel_info:print(key)北京所有美食(一行一个)效果∶
for item in dict_travel_info["北京"]["美食"]:print(item)打印所有城市的所有美食(一行一个)效果
for value in dict_travel_info.values():for item in value["美食"]:print(item)
自定义排序
"""交换算法a,b = b,a最值算法max_value = list01[0]for i in range(1, len(list01)):if max_value < list01[i]:max_value = list01[i]print(max_value)累计运算初始值 list01[0]循环while for初始值+=?结果排序算法升序排列:小->大在整个范围内,让第一个为最小值,降序排列:大->小"""
"""升序排列小 大
"""
思想:
把最小的放最第一位,拿list01[0]与后面的对比
list01 = [5, 56, 67, 78, 8, 9]
for i in range(1,len(list01)):if list01[0]>list01[i]:list01[0],list01[i]=list01[i],list01[0]
print(list01)
处理第二位为最小的,list01[1]与后面的对比
for i in range(2,len(list01)):if list01[1]>list01[i]:list01[1],list01[i]=list01[i],list01[1]
print(list01)
#整合重复的数据
list01 = [5, 56, 67, 78, 8, 9]
#取出数据,最后一位9不需要比了,下面-1
for r in range(len(list01) - 1):#作比较,不用和list01[0]自己比了,下面+1for c in range(r + 1, len(list01)):if list01[r] > list01[c]:list01[r], list01[c] = list01[c], list01[r]
print(list01)
"""降序排列
"""
list01 = [5, 56, 67, 78, 8, 9]
for i in range(1,len(list01)):if list01[0]<list01[i]:list01[0],list01[i]=list01[i],list01[0]
print(list01) [78, 5, 56, 67, 8, 9]for i in range(2,len(list01)):if list01[1]<list01[i]:list01[1],list01[i]=list01[i],list01[1]
print(list01)for r in range(len(list01) - 1):for c in range(r + 1, len(list01)):if list01[r] < list01[c]:list01[r], list01[c] = list01[c], list01[r]
print(list01)
#商品字典
dict_commodity_infos = {1001:{ "name":"屠龙刀","price":10000},1002:{ "name":"倚天剑","price":10000},1003:{ "name":"金箍棒","price":52100},1004:{"name":"口罩","price":20},1005:{"name":"酒精","price":30},
}打印所有的商品信息
for key,value in dict_commodity_infos.items():print("商品号%s,商品名%s,商品价格%s"%(key,value["name"],value["price"]))print(f"商品号{key},商品名{value['name']},商品价格{value['price']}")list orders = [
{ "cid": 1001,"count": 1},
{ "cid": 1002, "count": 3},'
{"cid": 1005, "count": 2},'
]打印所有订单中的信息 商品号,数量
for item in list_orders:print(f'商品号{item["cid"]},数量{item["count"]}')打印所有订单中的商品信息,格式:商品名称xx,商品单价:xx,数量xx.
for item in list_orders:#cid = item["cid"]#info = dict_commodity_infos[cid]info = dict_commodity_infos[item["cid"]]print(f'商品名称{info["name"]},商品单价{info["price"]},数量{item["count"]}')查找数量最多的订单
max_value=list_orders[0]
for i in range(1,len(list_orders)):if max_value["count"] < list_orders[i]["count"]:max_value=list_orders[i]
print(max_value)根据购买数量对订单列表降序(大->小)排
for r in range(len(list_orders)-1):for c in range(r+1,len(list_orders)):if list_orders[r]["count"] < list_orders[c]["count"]:list_orders[r],list_orders[c]=list_orders[c],list_orders[r]
print(list_orders)
[{'cid': 1002, 'count': 3}, {'cid': 1005, 'count': 2}, {'cid': 1001, 'count': 1}]
#字典优点∶定位单个元素最方便,最快捷
#列表优点:定位灵活(切片),有顺序,内存占有量较小
#员工列表(员工编号部门编号姓名工资)
# 员工列表(员工编号 部门编号 姓名 工资)
dict_employees = {1001: {"did": 9002, "name": "师父", "money": 60000},1002: {"did": 9001, "name": "孙悟空", "money": 50000},1003: {"did": 9002, "name": "猪八戒", "money": 20000},1004: {"did": 9001, "name": "沙僧", "money": 30000},1005: {"did": 9001, "name": "小白龙", "money": 15000},
}# 部门列表
list_departments = [{"did": 9001, "title": "教学部"},{"did": 9002, "title": "销售部"},{"did": 9003, "title": "品保部"},
]
# 1. 打印所有员工信息, 格式:xx的员工编号是xx,部门编号是xx,月薪xx元.
for eid, emp in dict_employees.items():print(f"{emp['name']}的员工编号是{eid},部门编号是{emp['did']},月薪{emp['money']}元.")# 2. 打印所有月薪大于2w的员工信息,
# 格式:xx的员工编号是xx,部门编号是xx,月薪xx元.
for eid, emp in dict_employees.items():if emp['money'] > 20000:print(f"{emp['name']}的员工编号是{eid},部门编号是{emp['did']},月薪{emp['money']}元.")# 3. 在部门列表中查找编号最小的部门
min_value = list_departments[0]
for i in range(1, len(list_departments)):if min_value["did"] > list_departments[i]["did"]:min_value = list_departments[i]
print(min_value)# 4. 根据部门编号对部门列表降序排列
# (1)取
for r in range(len(list_departments) - 1): # 0# (2)比for c in range(r + 1, len(list_departments)): # 1234# (3) 发现更小if list_departments[r]["did"] < list_departments[c]["did"]:# (4) 交换list_departments[r], list_departments[c] = list_departments[c], list_departments[r]
print(list_departments)
相关文章:

pt02-list-tuple-dir
容器类型 通用操作 数学运算符 (1) 用于拼接两个容器 (2) 用原容器与右侧容器拼接,并重新绑定变量 (3) * 重复生成容器元素 (4) * 用原容器生成重复元素, 并重新绑定变量 (5) !:依次比较两个容器中元素,一但不同则返回比较结果。< < > > 意…...

高端电器新十年,求解「竞速突围」
竞争激烈的高端电器品牌们,平时王不见王,但也有例外。海尔、博西、海信、创维、方太、老板等等近乎中国电器行业所有一线品牌副总裁级别以上高层,2月22日都现身于上海,来参加一场由红星美凯龙攒起来的高端电器局,2023中…...

[Android Studio] Android Studio使用keytool工具读取Debug 调试版数字证书以及release 发布版数字证书
🟧🟨🟩🟦🟪 Android Debug🟧🟨🟩🟦🟪 Topic 发布安卓学习过程中遇到问题解决过程,希望我的解决方案可以对小伙伴们有帮助。 📋笔记目…...

2023年金三银四必备软件测试常见面试题1500问!!!【测试思维篇】
五、测试思维5.1 打电话功能怎么去测?我们会从几个方面去测试:界面、功能、兼容性、易用性、安全、性能、异常。1)界面我们会测试下是否跟界面原型图一致,考虑浏览器不同显示比例,屏幕分辨率。2)功能&#…...
推荐四款自用的电脑神器
作为一个经常鼓捣电脑的小编来说,无论是写文章、截图、办公方面都缺少不了一些好用的软件,今天就给大家盘点一些我推荐用的办公效率工具,让你的效率事半功倍。 写文章神器 以前写文章一直是在公众号编辑上直接写的,缺点就是格式有…...

CSDN 竞赛 32 期
CSDN 竞赛 32 期1、题目名称:传奇霸业2、题目名称:严查枪火3、题目名称:蚂蚁家族4、题目名称:运输石油小结1、题目名称:传奇霸业 传奇霸业,是兄弟就来干。 小春(HP a)遇到了一只黄金哥布林(HP x)。 小春每…...
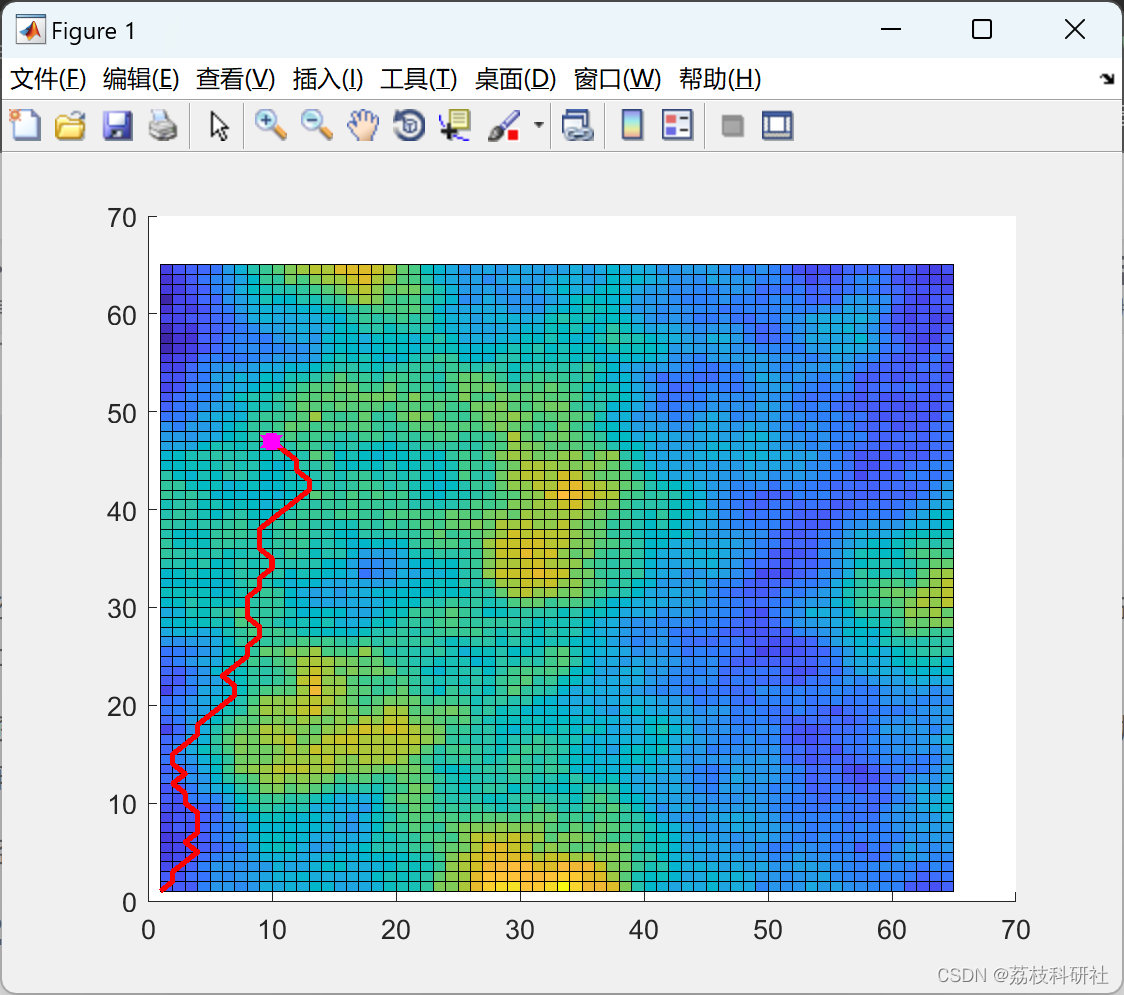
【路径规划】基于前向动态规划算法在地形上找到最佳路径(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
spring boot maven打包jar包太大,怎么办?这个方法解决你的烦恼
在springboot maven项目中,有两种打包方式,一种是war包,一种是jar,今天我们讲一下jar的打包方式。但是在jar包打包只要我们发现,我们的项目jar太大了,每次上传到服务器的时候非常的慢,接下来我们…...
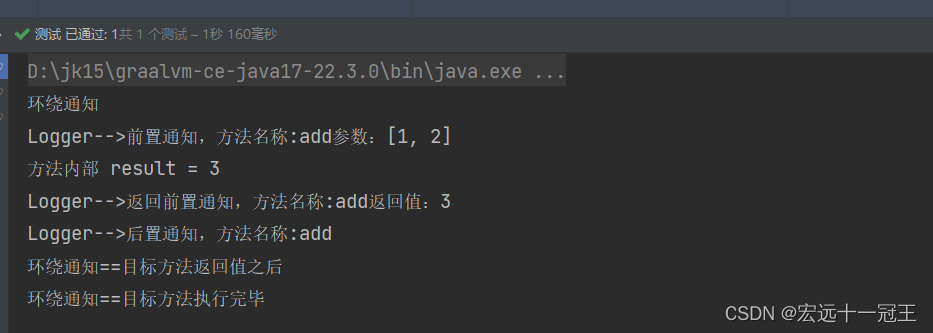
Spring之AOP理解及使用
文章目录AOP是什么AOPSpring的通知类型1.Before通知2. AfterReturning通知3.AfterThrowing通知4. After通知5. Around通知动态代理JDK动态代理CGLib动态代理动态代理的代码展示AOP使用切面类的配置最后大家好,我是Leo!今天给大家带来的是关于Spring AOP的…...
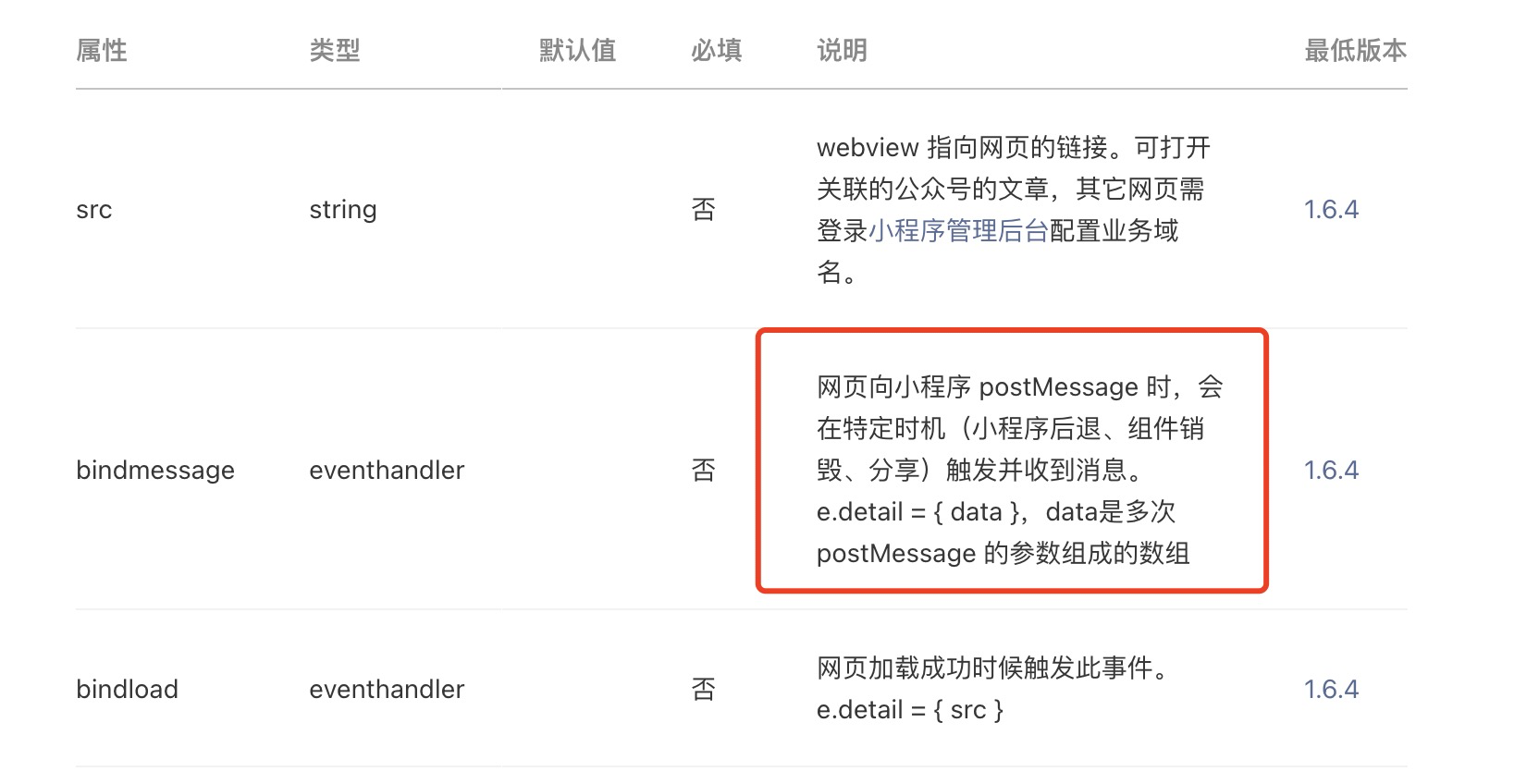
微信小程序和webview使用postMessage交互
小程序和webview能交互,但是没有你想的那个完美小程序向webview传递参数只能使用url携带参数webview向小程序传递参数可以使用postMessage, 但是注意了,postMessage只会在特定的时机执行,请看官方文档由此可见,如果你想点击webvie…...

pytorch-自动求导机制,构建计算图进行反向传播,需要注意inplace操作导致的报错,梯度属性变化
PyTorch 作为一个深度学习平台,在深度学习任务中比 NumPy 这个科学计算库强在哪里呢?一是 PyTorch 提供了自动求导机制,二是对 GPU 的支持。由此可见,自动求导 (autograd) 是 PyTorch,乃至其他大部分深度学习框架中的重…...
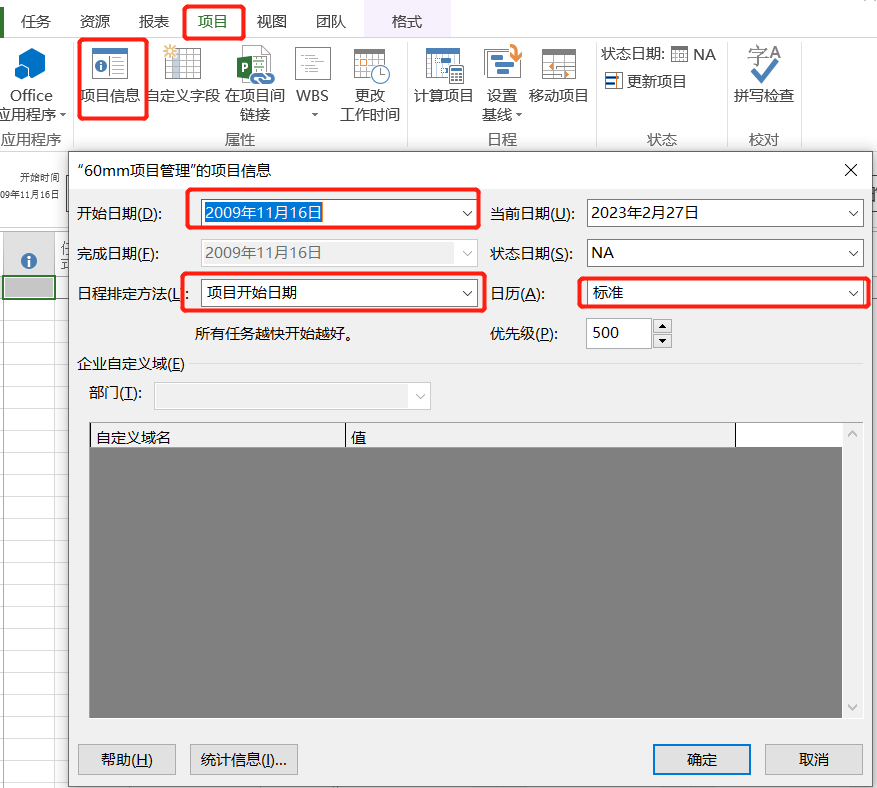
【Project】项目管理软件学习笔记
一、前言使用Project制定项目计划步骤大致如下:以Project2013为例,按照上图步骤指定项目计划。二、实施2.1 创建空白项目点击文件——新建——空白项目,即完成了空白项目的创建,在此我把该项目保存为60mm项目管理.mpp,…...

【算法设计-分治思想】快速幂与龟速乘
文章目录1. 快速幂2. 龟速乘3. 快速幂取模4. 龟速乘取模5. 快速幂取模优化1. 快速幂 算法原理: 计算 311: 311 (35)2 x 335 (32)2 x 332 3 x 3仅需计算 3 次,而非 11 次 计算 310: 310 (35)235 (32)2 x 332 3 x 3仅需计算…...
 如何保证数据的不重复和不丢失)
Kafka(十一) 如何保证数据的不重复和不丢失
数据不丢失 1)从生产端:acks -1,(ack应答机制)从生产端到节点端,当所有isr集合里的节点备份完毕后返回成功; 2)从节点端:每个partition至少需要一个isr节点࿰…...
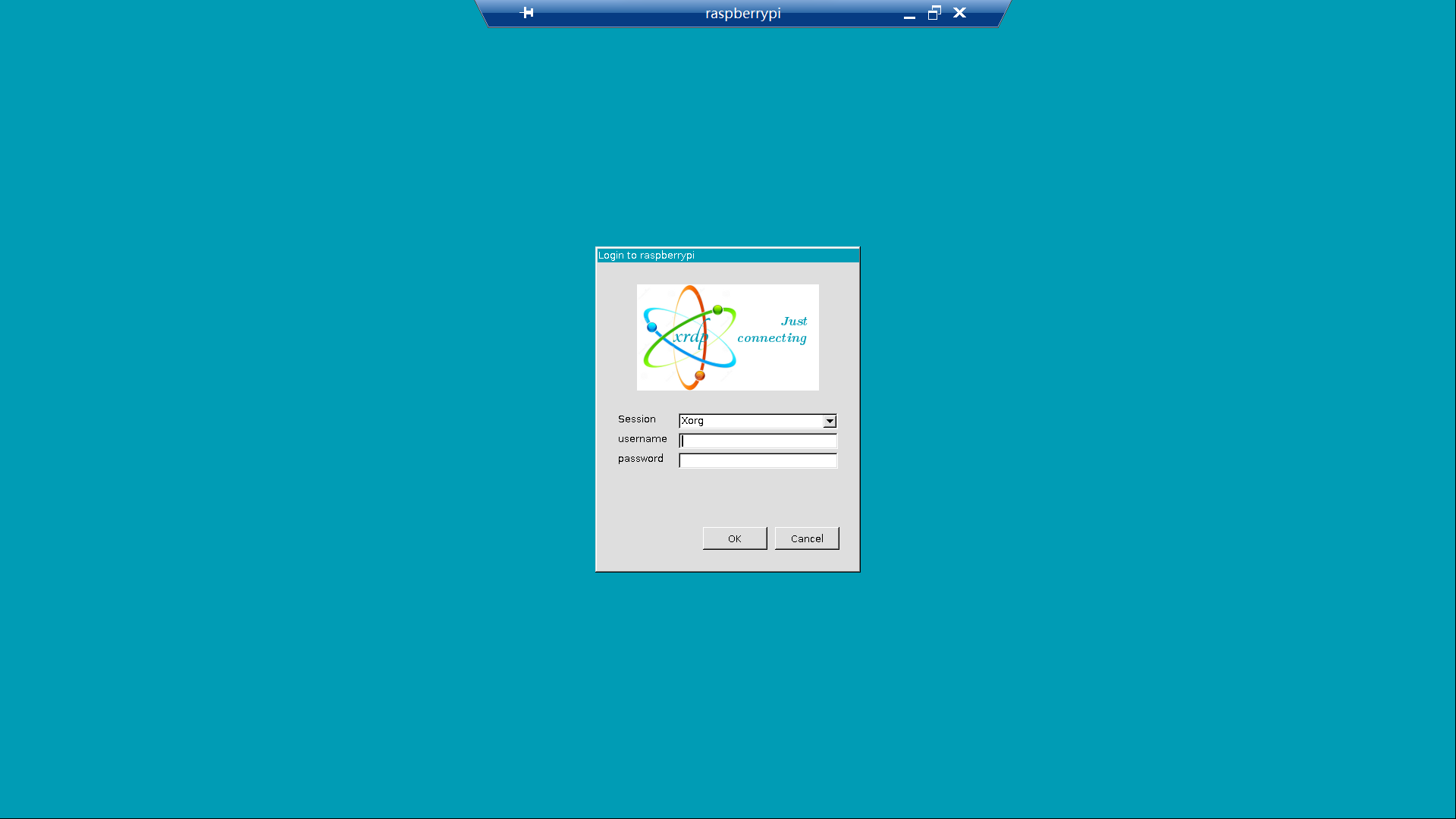
解决树莓派 bullseye (11) 系统无法通过 xrdp 远程连接的问题
我手上有一台树莓派 4B,使用官方镜像烧录器烧录老版本操作系统 buster (10) 时可以正常通过 Windows 远程桌面连接上,但换成最新的 bullseye (11) 系统后却无法正常连接远程桌面。 问题复现: 使用官方镜像烧录器烧录,配置用户名为…...
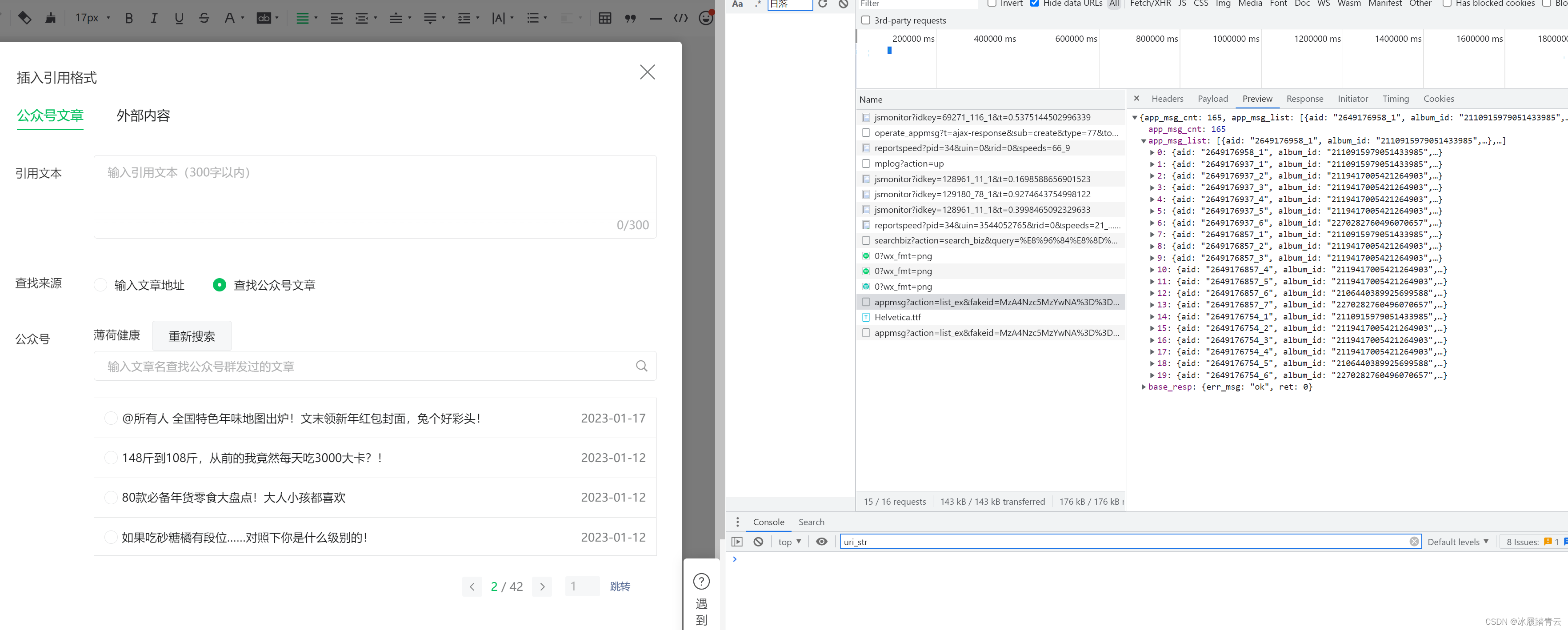
微信公众号历史作品定向采集
最近有遇到微信公众号历史作品采集的需求,这里做一下记录, 登录自己注册好的的微信公众号后台进入创作界面,点击右上角的引用: 弹出如下界面: 选择查找公众号文章,输入要查找的公众号: 回车: 同时就可以打开F12开始抓包,选择公众号点击进入: appmsg?action=li…...
)
Vue学习笔记(3)
3.1 计算属性和监视属性 3.1.1 计算属性 计算属性是一种计算值的方式,可以根据其他属性的值来动态地计算新的属性值。计算属性可以缓存计算结果,当依赖的属性发生改变时,才会重新计算。在Vue中,可以使用computed选项来定义计算属…...

Marshmallow 库
文章目录Marshmallow 库介绍使用序列化反序列化参数介绍schema参数fields 参数钩子函数内置验证器Meta 属性Marshmallow 库 介绍 marshmallow是一个用来将复杂的orm对象与python原生数据类型之间相互转换的库,简而言之,就是实现object -> dict&#…...

【BN层的作用】论文阅读 | How Does Batch Normalization Help Optimization?
前言:15年Google提出Batch Normalization,成为深度学习最成功的设计之一,18年MIT团队将原论文中提出的BN层的作用进行了一一反驳,重新揭示BN层的意义 2015年Google团队论文:【here】 2018年MIT团队论文:【h…...
用法的详细介绍)
re.sub()用法的详细介绍
一、前言 在字符串数据处理的过程中,正则表达式是我们经常使用到的,python中使用的则是re模块。下面会通过实际案例介绍 re.sub() 的详细用法,该函数主要用于替换字符串中的匹配项。 二、函数原型 首先从源代码来看一下该函数原型…...
)
从钓鱼邮件看防御:用DMARC报告分析攻击手法(含真实案例拆解)
从钓鱼邮件看防御:用DMARC报告分析攻击手法(含真实案例拆解) 邮件安全防护体系中,DMARC报告常被视为"事后审计工具",但安全团队往往低估了它在攻击溯源中的战略价值。去年某金融企业遭遇的定向钓鱼攻击中&am…...

n8n自动化实战:用AI老师带你6周搞定电商订单处理系统
n8n自动化实战:用AI老师带你6周搞定电商订单处理系统 电商行业的快速发展对订单处理效率提出了更高要求。传统人工操作不仅耗时耗力,还容易出错。n8n作为一款开源自动化工具,能够帮助企业快速搭建高效的订单处理系统。本文将带你用6周时间&am…...

Agent 记忆终于有救了!5 款开源框架横评,附落地架构选型指南
做 AI Agent 的朋友,你有没有遇到过这个让人崩溃的场景—— 用户昨天告诉 Agent:“我是素食主义者,别给我推荐含肉的食谱。” 今天 Agent 回来了,热情洋溢地推荐了:红烧肉。 用户已经把你拉黑了。这就是没有记忆的 Age…...

OpenClaw稳定性提升:Qwen3-14B长时运行的内存泄漏排查
OpenClaw稳定性提升:Qwen3-14B长时运行的内存泄漏排查 1. 问题背景:72小时无人值守的意外崩溃 上周我尝试用OpenClawQwen3-14B搭建一个自动化内容处理流水线,期望它能724小时不间断工作。前48小时运行良好,但在第72小时突然发现…...

2025年大模型年度复盘:RL、Agent与Omni的技术趋势解读
一、项目介绍准备 项目 1:基于 RAG 的大语言模型关系抽取 1、为什么不用传统语义相似度检索,改用关系原型检索? 传统相似度检索易召回伪近邻样本(语义相近、头尾实体不同→关系不同),干扰模型判断。 我先把…...

Linux内存监控工具与实战技巧
1. Linux 内存监控概述作为一名运维工程师,我每天都要和服务器内存打交道。内存就像系统的血液,一旦出现异常,整个系统就会变得迟缓甚至崩溃。在Linux系统中,我们可以通过多种方式来监控内存使用情况,每种方法都有其独…...

终极指南:揭秘LIEF二进制格式识别算法的实现原理 [特殊字符]
终极指南:揭秘LIEF二进制格式识别算法的实现原理 🔍 【免费下载链接】LIEF LIEF - Library to Instrument Executable Formats (C, Python, Rust) 项目地址: https://gitcode.com/gh_mirrors/li/LIEF LIEF(Library to Instrument Exec…...

私有化视频会议系统/私有化视频会议解决方案EasyDSS技术架构解析与应用实践
在数字化转型的浪潮中,视频会议已成为政企日常协作的核心纽带,但公有云会议平台的数据安全隐患、合规性短板,始终是政务、金融、军工等涉密领域的心头之患。EasyDSS私有化视频会议系统,以数据自主可控为核心,融合全场景…...

3分钟掌握DeepLabV3+语义分割:从零开始训练你的第一个图像分割模型 [特殊字符]
3分钟掌握DeepLabV3语义分割:从零开始训练你的第一个图像分割模型 🚀 【免费下载链接】deeplabv3-plus-pytorch 这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。 项目地址: https://gitcode.com/gh_mirrors/de/deeplabv3-p…...

新手福音:在ubuntu上用快马ai生成你的第一个python猜数字游戏
作为一个刚接触Ubuntu和Python编程的新手,第一次在命令行里跑起自己写的程序时那种成就感,相信很多人都有共鸣。今天就用InsCode(快马)平台的AI辅助功能,带大家零基础实现一个经典的数字猜谜游戏。整个过程完全在Ubuntu终端完成,不…...