Accelerate 0.24.0文档 三:超大模型推理(内存估算、Sharded checkpoints、bitsandbytes量化、分布式推理)
文章目录
- 一、内存估算
- 1.1 Gradio Demos
- 1.2 The Command
- 二、使用Accelerate加载超大模型
- 2.1 模型加载的常规流程
- 2.2 加载空模型
- 2.3 分片检查点(Sharded checkpoints)
- 2.4 示例:使用Accelerate推理GPT2-1.5B
- 2.5 device_map
- 三、bitsandbytes量化
- 3.1 环境依赖
- 3.2 量化示例
- 3.3 保存和加载 8 位模型
- 3.4 微调量化模型
- 四、分布式推理
- 4.1 使用torch.distributed进行分布式推理
- 4.2 使用Accelerate进行分布式推理
- 《探索多种方案下 LLM 的预训练性能》
一、内存估算
参考《Understanding how big of a model can fit on your machine》、《Transformer 估算》
目前使用大模型一个非常困难的方面是了解当前显卡的内存可以容纳多大的模型(例如将模型加载到 CUDA 上)。为了帮助解决这个问题,Accelerate提供了accelerate estimate-memory 命令行界面,来进行估算。
1.1 Gradio Demos
打开Gradio Demos页面。输入Model Name or URL就可以进行估算。

- 该计算器将告诉您纯粹加载模型而不是执行推理需要多少内存
- 模型所需的最小内存建议 表示为“最大层”的大小,模型的训练大约是其大小的 4 倍(对于 Adam)
- 在执行推理时,预计会额外增加 20%。未来将进行更多测试,以获得每个模型更准确的基准。
- 目前此工具支持使用 transformers 和 timm 托管的所有模型
- 此计算的精确度在实际值的百分之几内,例如,当以全精度加载到 CUDA 上时,加载 bert-base-cased 实际上需要 413.68 MB ,计算器估计是 413.18 MB 。
1.2 The Command
你也可以使用命令行界面来获取结果,例如计算bert-base-cased 的内存占用量:
accelerate estimate-memory bert-base-cased
这将下载 bert-based-cased 的 config.json文件 ,在 meta 设备上加载模型,并报告它将使用多少空间:
| dtype | Largest Layer | Total Size | Training using Adam |
|---|---|---|---|
| float32 | 84.95 MB | 418.18 MB | 1.61 GB |
| float16 | 42.47 MB | 206.59 MB | 826.36 MB |
| int8 | 21.24 MB | 103.29 MB | 413.18 MB |
| int4 | 10.62 MB | 51.65 MB | 206.59 MB |
默认情况下,它将返回所有支持的数据类型( int4 到 float32 ),你也可以进行过滤:
accelerate estimate-memory bert-base-cased --dtypes float32 float16
| dtype | Largest Layer | Total Size | Training using Adam |
|---|---|---|---|
| float32 | 84.95 MB | 413.18 MB | 1.61 GB |
| float16 | 42.47 MB | 206.59 MB | 826.36 MB |
如果无法确定来自哪个库,可以传入库的名称:
HuggingFaceM4/idefics-80b-instruct:
accelerate estimate-memory HuggingFaceM4/idefics-80b-instruct --library_name transformers
| dtype | Largest Layer | Total Size | Training using Adam |
|---|---|---|---|
| float32 | 3.02 GB | 297.12 GB | 1.16 TB |
| float16 | 1.51 GB | 148.56 GB | 594.24 GB |
| int8 | 772.52 MB | 74.28 GB | 297.12 GB |
| int4 | 386.26 MB | 37.14 GB | 148.56 GB |
timm/resnet50.a1_in1k:
accelerate estimate-memory timm/resnet50.a1_in1k --library_name timm
| dtype | Largest Layer | Total Size | Training using Adam |
|---|---|---|---|
| float32 | 9.0 MB | 97.7 MB | 390.78 MB |
| float16 | 4.5 MB | 48.85 MB | 195.39 MB |
| int8 | 2.25 MB | 24.42 MB | 97.7 MB |
| int4 | 1.12 MB | 12.21 MB | 48.85 MB |
二、使用Accelerate加载超大模型
本章参考:
- 《Handling big models for inference》、《Distributed Inference with 🤗 Accelerate》
- 《使用HuggingFace的Accelerate库加载和运行超大模型》
- 有关本章用到的各种API和更多超大模型加载内容,可参考《Working with large models》

2.1 模型加载的常规流程
在 PyTorch 中加载预训练模型时,通常的工作流程如下所示:
import torchmy_model = ModelClass(...)
state_dict = torch.load(checkpoint_file)
my_model.load_state_dict(state_dict)
简而言之,这些步骤是:
- 使用随机初始化的权重创建模型
- 从磁盘加载模型权重(通常称为state_dict)
- 将这些权重加载到模型中
- 将模型加载到相应设备上(比如GPU)进行模型推理
如果模型不是很大的话,使用上面的代码加载权重是可以的。但当我们处理大型模型时,此工作流程有一些明显的局限性。
- 在第一步中,需要在RAM中加载一个完整版本的模型,并花费一些时间对权重进行随机初始化(在第三步将被丢弃)。
- 在第二步中,需要再次在RAM中加载一个完整版本的模型,其中包含预训练的权重。
对于包含60亿参数的模型,这意味每一步都需要需要24GB的RAM(float32每个占四字节),总共需要48GB(其中一半用于在FP16中加载模型)。如果加载更大的模型,比如BLOOM或OPT-176B(1760亿个参数),需要大概1.4TB的内存空间。这样内存肯定是不够的,因此我们需要做一些技巧性的改变。
2.2 加载空模型
PyTorch 1.9版本提供了一个叫做meta的新设备。使用该设备,可以创建非常大的张量,而无需考虑内存或显存的大小。同样的,也可以方便创建模型,而无需加载权重。例如,下面的代码如果在Colab上或kaggle的kernel运行,会报错OOM,因为默认使用精度为32位的情况下,创建下述张量需要40G内存。
import torch
large_tensor = torch.randn(100000, 100000)
而如果与meta设备来创建,即可只定义张量形状,而不消耗内存。
import torch
large_tensor = torch.randn(100000, 100000, device="meta")
large_tensor
# 张量只有形状,并没有数据(不占据内存或显存)。
tensor(..., device='meta', size=(100000, 100000))
Accelerate 引入的第一个帮助处理大型模型的工具是上下文管理器 init_empty_weights(),可以使用meta初始化一个空模型(只有shape,没有数据)。
from accelerate import init_empty_weightswith init_empty_weights():model = nn.Sequential(*[nn.Linear(10000, 10000) for _ in range(1000)])
这可以初始化一个略大于100亿参数的空模型,在init_empty_weights()下的初始化过程中,每当创建一个参数,它会立即被移到meta设备上。定义好上述模型后,可以喂输入,然后得到一个meta设备的输出张量(同样,只有形状,没有数据,其实就是进行了shape计算)。
2.3 分片检查点(Sharded checkpoints)
当模型过大,无法将其整体加载到内存中时,仍可通过分片方式加载,尤其在有一个或多个GPU的情况下,因为GPU提供了更多内存。
检查点分片:将检查点分割成多个较小的文件,称为检查点分片。Accelerate库能够处理这种检查点分片,前提是遵循特定的格式:
- 检查点应该存储在一个文件夹中。
- 文件夹中包含多个具有部分状态字典的文件,每个文件对应模型的不同部分。
- 有一个JSON格式的索引文件,该文件包含一个字典,将参数名称映射到包含其权重的文件。
使用 save_model() 可以轻松地将模型分片:
accelerator.wait_for_everyone() # 确保所有进程训练完成
accelerator.save_model(model, save_directory, max_shard_size="1GB", safe_serialization=True)
得到的结果类似于:
first_state_dict.bin
index.json
second_state_dict.bin
其中index.json是以下文件:
{"linear1.weight": "first_state_dict.bin","linear1.bias": "first_state_dict.bin","linear2.weight": "second_state_dict.bin","linear2.bias": "second_state_dict.bin"
}
加载时,你可以使用 load_checkpoint_in_model() 函数将其加载在特定设备上。
load_checkpoint_in_model(unwrapped_model, save_directory, device_map={"": device})
也可以使用load_checkpoint_and_dispatch() 函数在空模型中加载完整检查点或分片检查点,它还会自动在您可用的设备(GPU、CPU RAM)上分配这些权重。完整的模型分片推理过程见此YouTube视频。
load_checkpoint_and_dispatch函数常用参数为model、checkpoint、device_map、max_memory、no_split_module_classes,后两个参数将在后面讲到。
2.4 示例:使用Accelerate推理GPT2-1.5B
- 使用 minGPT库的默认配置初始化模型
git clone https://github.com/karpathy/minGPT.git
pip install minGPT/
from accelerate import init_empty_weights
from mingpt.model import GPTmodel_config = GPT.get_default_config()
model_config.model_type = 'gpt2-xl'
model_config.vocab_size = 50257
model_config.block_size = 1024with init_empty_weights():model = GPT(model_config)
- 下载模型权重并加载
pip install huggingface_hubfrom huggingface_hub import snapshot_download
from accelerate import load_checkpoint_and_dispatchcheckpoint = "marcsun13/gpt2-xl-linear-sharded"
weights_location = snapshot_download(repo_id=checkpoint)
model = load_checkpoint_and_dispatch(model, checkpoint=weights_location, device_map="auto", no_split_module_classes=['Block']
)
上述代码中:
- 使用load_checkpoint_and_dispatch()加载检查点到空模型。
- 设置device_map="auto"会让Accelerate自动判断把模型的每个层放在哪里:
- 优先尽量放在GPU上
- 如果GPU空间不够,将剩余层放在CPU RAM上
- 如果CPU RAM也不够,将剩余层存储在硬盘上,以memory-mapped tensors的形式。
- 通过
no_split_module_classes参数可以指定某些层不被分割(比如包含残差连接的Block等模块)。
memory-mapped tensors简称 mmap tensors,是PyTorch提供的一种特殊的tensors,它允许将数据存储在磁盘文件中,而不占用宝贵的RAM内存,CPU可以直接对磁盘文件中的数据进行读写操作,就像操作RAM中的tensors一样。mmap tensors既可以享受性能接近RAM的缓存系统带来的读写速度,同时也不会耗尽宝贵的RAM空间,从而使Accelerate支持超大模型的训练
- 推理
现在我们的模型位于多个设备上,也许还有在硬盘上的部分,但它仍然可以用作常规 PyTorch 模型进行推理:
from mingpt.bpe import BPETokenizer
tokenizer = BPETokenizer()
inputs = tokenizer("Hello, my name is").to(0)outputs = model.generate(x1, max_new_tokens=10, do_sample=False)[0]
tokenizer.decode(outputs.cpu().squeeze())
在幕后, Accelerate 添加了钩子(hook)到模型,以便:
- 在每一层,输入被放在正确的设备上,因此,即使您的模型分布在多个GPU上,它也能正常工作。
- 对于卸载到CPU上的权重,在前向传播之前将它们放在GPU上,然后在之后清理
- 对于卸载到硬盘上的权重,在前向传播之前将其加载到RAM中,然后放在GPU上,之后再清理
这样,即使您的模型在GPU或CPU上装不下,也可以进行推理!同时需要注意的是,Accelerate 通过 hook 仅支持推理而不支持训练,这是因为:
- 内存限制:在训练过程中,我们需要在每一层保留激活值来计算梯度,这会大大增加内存需求。但在推理时我们可以在每一层后立即释放激活,所以内存需求较小。
- 计算复杂性:训练需要频繁的反向传播,权重需要频繁更新。反向传播涉及到复杂的计算图跟踪,这在分布式环境下变得非常困难,特别是当layer分布在不同设备时,实现反向传播会变得极具挑战性,高效的分布式权重更新也非常困难。
- 精度要求:训练中需要精确计算梯度的值,但在这种分布式环境下很难保证,最终会影响模型的训练质量。相比之下,在推理过程中,不需要计算梯度。
当我们谈到深度学习中的 “hook” 时,我们指的是一种机制,允许在神经网络的不同部分插入自定义代码,以便在训练或推断的过程中执行一些额外的操作。这些操作可能包括记录中间激活值、梯度、权重等,或者进行某种修改,以适应特定需求。
hook一般包括Forward Hook(前向钩子)和Backward Hook(反向钩子)。上面的讲解中,hooks 的作用是确保输入被正确放置在合适的设备上。下面是一段关于hook的伪代码:
def forward_hook(module, input, output):# 在前向传播中执行的自定义操作
def backward_hook(module, grad_input, grad_output):# 在反向传播中执行的自定义操作# 注册前向和反向 hook
hook_handle = model.fc.register_forward_hook(forward_hook)
hook_handle_backward = model.fc.register_backward_hook(backward_hook)# 运行前向传播和反向传播
output = model(input_data)
output.backward(torch.randn_like(output))# 移除 hook
hook_handle.remove()
hook_handle_backward.remove()
2.5 device_map
-
查看和设置device_map
您可以通过访问模型的 hf_device_map 属性来查看 Accelerate 选择的 device_map(一个字典,包含模型模块、权重以及对应的设备) ,比如对于上述GPT2-1.5B模型:model.hf_device_map{'transformer.wte': 0,'transformer.wpe': 0,'transformer.drop': 0,'transformer.h.0': 0,...'transformer.h.21': 0, 'transformer.h.22': 1, 'transformer.h.23': 1, 'transformer.h.24': 1,...'transformer.h.47': 1, 'transformer.ln_f': 1, 'lm_head': 1}你也可以自定义设备映射,指定要使用的 GPU 设备(数字)、 “cpu” 或 “disk” 并将其传入:
device_map = {"transformer.wte": "cpu","transformer.wpe": 0,"transformer.drop": "cpu","transformer.h.0": "disk" }model = load_checkpoint_and_dispatch(model, checkpoint=weights_location, device_map=device_map) -
device_map选项
device_map有四个可选参数。当GPU不足以容纳整个模型时,所有选项都会产生相同的结果(即优先加载在GPU上,而后分别是 CPU和磁盘)。当 GPU显存大于模型大小时,每个选项会有如下差异:"auto"或"balanced"::Accelerate将会根据所有GPU均衡切分权重,尽量均匀的切分到各个GPU上;"balanced_low_0"::在第一个GPU上(序号为0)会尽量节省显存,其它个GPU均匀分割权重。这种模式可以有效节省第一个GPU的显存用于模型生成等计算操作(generate函数);"sequential":Accelerate按照GPU的顺序占用显存,因此排序靠后的GPU显存占用会少一些。
"auto"和"balanced"目前会产生相同的结果,但如果我们找到更有意义的策略,"auto"的行为将来可能会发生变化,而"balanced"将保持不变。 -
accelerate.infer_auto_device_map:此函数用于为给定的模型生成设备映射,优先使用 GPU,然后是 CPU,最后是硬盘。因为所有计算都是通过分析模型参数的大小和数据类型来完成的,所以可以是meta上的空模型。以下是具体参数:
model(torch.nn.Module):要分析的模型。max_memory(可选):设备标识符到最大内存的字典。如果未设置,将默认为可用的最大内存。no_split_module_classes(可选):不应在设备之间分割的层类名称列表(例如,任何具有残差连接的层)。dtype(可选):如果提供,加载权重时将其转换为该类型。例如:from accelerate import infer_auto_device_map, init_empty_weights from transformers import AutoConfig, AutoModelForCausalLM config = AutoConfig.from_pretrained("facebook/opt-13b") with init_empty_weights():model = AutoModelForCausalLM.from_config(config) device_map = infer_auto_device_map(model, no_split_module_classes=["OPTDecoderLayer"], dtype="float16")special_dtypes(可选):如果提供,考虑某些特定权重的特殊数据类型(将覆盖作为所有权重默认值的 dtype)。verbose(可选,默认为 False):是否在函数构建设备映射时提供调试语句。
-
max_memory 参数
您可以使用 max_memory 参数来限制每个 GPU 和CPU上使用的内存,赋予GPU应该传递标识符(例如 0,1),内存值可以是整数(以字节为单位),也可以是表示数字及其单位的字符串,例如 “10GiB” 或 “10GB” 。
需要注意的是,当 PyTorch 中发生第一次分配时,它会加载 CUDA 内核,该内核大约需要 1-2GB 内存,具体取决于 GPU。因此,可用内存总是小于 GPU 的实际大小。要查看实际使用了多少内存,请执行torch.ones(1).cuda()并查看内存使用情况。-
示例一:GPU 内存不超过10GiB,CPU内存不超过30GiB:
from accelerate import infer_auto_device_mapdevice_map = infer_auto_device_map(my_model, max_memory={0: "10GiB", 1: "10GiB", "cpu": "30GiB"}) -
对于一些生成任务的模型,如果想您有许多 GPU且想使用更大的batch size进行推理,第一个GPU应该分配较少的内存。例如,在 8x80 A100 上使用 BLOOM-176B,接近理想的分配为:
max_memory = {0: "30GIB", 1: "46GIB", 2: "46GIB", 3: "46GIB", 4: "46GIB", 5: "46GIB", 6: "46GIB", 7: "46GIB"}
-
三、bitsandbytes量化
参考:《Quantization(Accelerate)》、《大规模 Transformer 模型 8 比特矩阵乘简介 - 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes》
Accelerate库集成了bitsandbytes 量化功能,几行代码就可以实现4位量化和8位量化。要了解有关 bitsandbytes 量化工作原理的更多信息,请查看8 位量化和 4 位量化的博客文章。transformers中也集成了bitsandbytes 量化功能,相关内容可查看量化文档,或者我的另一篇博客《Hugging Face高性能技术五:Transformer高效推断(bitsandbytes、FlashAttention、 BetterTransformer)》
3.1 环境依赖
使用前,安装相关依赖:
pip install bitsandbytes
pip install git+https://github.com/huggingface/accelerate.git
3.2 量化示例
安装 minGPT 和 huggingface_hub 以运行示例:
git clone https://github.com/karpathy/minGPT.git
pip install minGPT/
pip install huggingface_hub
从 minGPT 库中获取 GPT2 模型配置,然后使用 init_empty_weights().初始化一个空模型:
from accelerate import init_empty_weights
from mingpt.model import GPTmodel_config = GPT.get_default_config()
model_config.model_type = 'gpt2-xl'
model_config.vocab_size = 50257
model_config.block_size = 1024with init_empty_weights():empty_model = GPT(model_config)
需要获取模型权重的路径。该路径可以是 state_dict 文件(例如“pytorch_model.bin”)或包含分片检查点的文件夹。
from huggingface_hub import snapshot_download
weights_location = snapshot_download(repo_id="marcsun13/gpt2-xl-linear-sharded")
使用 BnbQuantizationConfig 设置量化配置
from accelerate.utils import BnbQuantizationConfig
# 8位量化
bnb_quantization_config = BnbQuantizationConfig(load_in_8bit=True, llm_int8_threshold = 6)
# 4位量化
bnb_quantization_config = BnbQuantizationConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4")
使用 load_and_quantize_model()量化所选配置的空模型:
from accelerate.utils import load_and_quantize_model
quantized_model = load_and_quantize_model(empty_model, weights_location=weights_location, bnb_quantization_config=bnb_quantization_config, device_map = "auto")
量化操作的具体实现,都集成在bitsandbytes 库的Linear8bitLt 模块中,它是torch.nn.modules 的子类。与 nn.Linear 模块略有不同,其参数属于 bnb.nn.Int8Params 类而不是 nn.Parameter 类。然后我们会调用replace_8bit_linear函数,将所有 nn.Linear 模块替换为 bitsandbytes.nn.Linear8bitLt模块。
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):for name, module in model.named_children():if len(list(module.children())) > 0:replace_8bit_linear(module, threshold, module_to_not_convert)if isinstance(module, nn.Linear) and name != module_to_not_convert:with init_empty_weights():model._modules[name] = bnb.nn.Linear8bitLt(module.in_features,module.out_features,module.bias is not None,has_fp16_weights=False,threshold=threshold,)return model
此函数递归地将 meta 设备上初始化的给定模型的所有 nn.Linear 层替换为 Linear8bitLt 模块。这里,必须将 has_fp16_weights 属性设置为 False,以便直接将权重加载为 Int8,并同时加载其量化统计信息。另外我们放弃了对某些模块 (这里是 lm_head) 进行替换,因为我们希望保持输出层的原始精度以获得更精确、更稳定的结果。也就是说, bitsandbytes只会量化transformer结构中除首层之外的全连接层。
3.3 保存和加载 8 位模型
使用accelerate.save_model保存8位模型,至于 4 位模型序列化,目前还不支持。
from accelerate import Accelerator
accelerate = Accelerator()
new_weights_location = "path/to/save_directory"
accelerate.save_model(quantized_model, new_weights_location)quantized_model_from_saved = load_and_quantize_model(empty_model, weights_location=new_weights_location, bnb_quantization_config=bnb_quantization_config, device_map = "auto")
如果 GPU 不足以存储整个模型,您可以通过传递自定义 device_map 将某些模块卸载到 cpu/磁盘。对于 8 位量化,所选模块将转换为 8 位精度。以下是一个示例:
device_map = {"transformer.wte": 0,"transformer.wpe": 0,"transformer.drop": 0,"transformer.h": "cpu","transformer.ln_f": "disk","lm_head": "disk",
}
完整量化代码可查看colab notebook示例《Accelerate quantization.ipynb》,示例中将GPT2模型量化为4位模型和8位模型并进行推理。
3.4 微调量化模型
参考《Quantize 🤗 Transformers models》
8 位或 4 位量化模型无法执行全量训练。但是,您可以利用参数高效微调方法 (PEFT) 来微调这些模型,详见peft Github示例:
- Colab notebook《Finetune-opt-bnb-peft.ipynb》:使用peft库的LoRa功能微调量化后的OPT-6.7b模型
- 《Finetuning Whisper-large-V2 on Colab using PEFT-Lora + BNB INT8 training + Streaming dataset》
- 《Finetuning Whisper-large-V2 on Colab using PEFT-Lora + BNB INT8 training》
请注意,device_map=auto 仅用于推理。这是因为推理过程通常不需要进行梯度计算,而且模型参数已经在训练期间被优化,因此在推理时可以更灵活地选择设备。
加载模型进行训练时,不需要显式传递device_map参数。系统会自动将模型加载到GPU上进行训练。如果需要,您可以将设备映射设置为特定设备,例如cuda:0, 0, torch.device('cuda:0')。
四、分布式推理
参考《Distributed Inference with 🤗 Accelerate》
4.1 使用torch.distributed进行分布式推理
分布式推理是一种常见的用例,尤其是自然语言处理 (NLP) 模型。用户通常希望发送多个不同的提示,每个提示发送到不同的 GPU,然后返回结果。下面是一个普通示例:
import torch
import torch.distributed as dist
from diffusers import DiffusionPipelinepipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
使用使用torch.distributed模块进行分布式推理:
def run_inference(rank, world_size):dist.init_process_group("nccl", rank=rank, world_size=world_size)pipe.to(rank)if torch.distributed.get_rank() == 0:prompt = "a dog"elif torch.distributed.get_rank() == 1:prompt = "a cat"result = pipe(prompt).images[0]result.save(f"result_{rank}.png")
可以看到,我们需要根据进程的rank选择不同的提示进行推理,这种方式需要手动管理每个进程的提示,显得有些繁琐。
4.2 使用Accelerate进行分布式推理
通过🤗 Accelerate,我们可以通过使用Accelerator.split_between_processes()上下文管理器(也存在于PartialState和AcceleratorState中)来简化这个过程。此函数会自动将您传递给它的任何数据(无论是提示,一组张量,先前数据的字典等)在所有进程之间进行分割(可能进行填充),以便您立即使用。让我们使用上下文管理器重写上面的示例:
from accelerate import PartialState # Can also be Accelerator or AcceleratorState
from diffusers import DiffusionPipelinepipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
distributed_state = PartialState()
pipe.to(distributed_state.device)# Assume two processes
with distributed_state.split_between_processes(["a dog", "a cat"]) as prompt:result = pipe(prompt).images[0]result.save(f"result_{distributed_state.process_index}.png")
然后使用accelerate launch启动代码(已生成配置文件):
accelerate launch distributed_inference.py
使用的特定配置文件启动:
accelerate launch --config_file my_config.json distributed_inference.py
不使用配置文件进行启动:(会受到一些警告,可以执行 accelerate config default来解决)
accelerate launch --num_processes 2 distributed_inference.py
现在我们不需要写分布式推理的样板代码了,Accelerate会自动分配数据到各个GPU上。如果碰到数据分割不均的情况,比如我们有 3 个提示,但只有 2 个 GPU。在上下文管理器下,第一个 GPU 将接收前两个提示,第二个 GPU 将接收第三个提示,确保所有提示都被拆分并且不需要任何开销。
如果需要对所有 GPU 的结果执行一些操作(例如聚合它们并执行一些后处理),可以在 split_between_processes 中传递 apply_padding=True,以确保提示列表被填充到相同的长度,多余的数据从最后一个样本中获取。这样,所有 GPU 将具有相同数量的提示,然后可以收集结果。
from accelerate import PartialState # Can also be Accelerator or AcceleratorState
from diffusers import DiffusionPipelinepipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
distributed_state = PartialState()
pipe.to(distributed_state.device)# Assume two processes
with distributed_state.split_between_processes(["a dog", "a cat", "a chicken"], apply_padding=True) as prompt:result = pipe(prompt).images
此时,第一个 GPU提示列表五 [“a dog”, “a cat”],第二个 GPU提示列表为 [“a chicken”, “a chicken”]。
相关文章:
Accelerate 0.24.0文档 三:超大模型推理(内存估算、Sharded checkpoints、bitsandbytes量化、分布式推理)
文章目录 一、内存估算1.1 Gradio Demos1.2 The Command 二、使用Accelerate加载超大模型2.1 模型加载的常规流程2.2 加载空模型2.3 分片检查点(Sharded checkpoints)2.4 示例:使用Accelerate推理GPT2-1.5B2.5 device_map 三、bitsandbytes量…...
HackTheBox-Starting Point--Tier 2---Markup
文章目录 一 Markup测试过程1.1 打点1.2 权限获取1.3 权限升级 二 题目 一 Markup测试过程 1.1 打点 1.端口扫描 nmap -A -Pn -sC 10.129.95.1922.访问web网站,登录口爆破发现存在弱口令admin:password 3.抓包,发现请求体是XML格式 4.尝试使…...
android studio导入eclipse项目
网上下载一个老工程,.project文件里有eclipse。 android studio导入eclipse项目 eclipse项目结构 Android studio文件结构 下面是导入步骤: 第一步,打开一个项目。 选择File->New->Import Project 第二步,选择Eclipse项目根…...

如何利用AI实现银行存量客户的营销?
近年来,大数据、人工智能等热门关键字多次被写入中央文件与国务院政府工作报告,目前已上升为国家战略,并将深刻地改变现有行业的游戏规则。 金融行业是当今大数据、人工智能应用最广、最深的领域之一。随着数据仓库和数据科学的发展ÿ…...
springboot327基于Java的医院急诊系统
交流学习: 更多项目: 全网最全的Java成品项目列表 https://docs.qq.com/doc/DUXdsVlhIdVlsemdX 演示 项目功能演示: ————————————————...

Unity3d 导入中文字体转TMPtext asset
外部字体放入unity仓库以后呢,需要把这个字体转成用立体的字体文件才可以被使用! 要想转换的话呢先放入仓库对字体点右键上面有一个Create创建里面有一个TEXT Asset,创建好就可以使用了...

云积万相,焕发电商店铺新活力
数字化时代,电商店铺的运营和营销策略越来越受到重视。如何让店铺在众多的竞争中脱颖而出,吸引更多的顾客,提高销售额,是每个电商品牌都需要思考的问题。云积天赫最近推出的云积万相为电商店铺带来全新的活力和更多的可能性。 …...
字典管理怎么使用,vue3项目使用若依的的字典管理模块
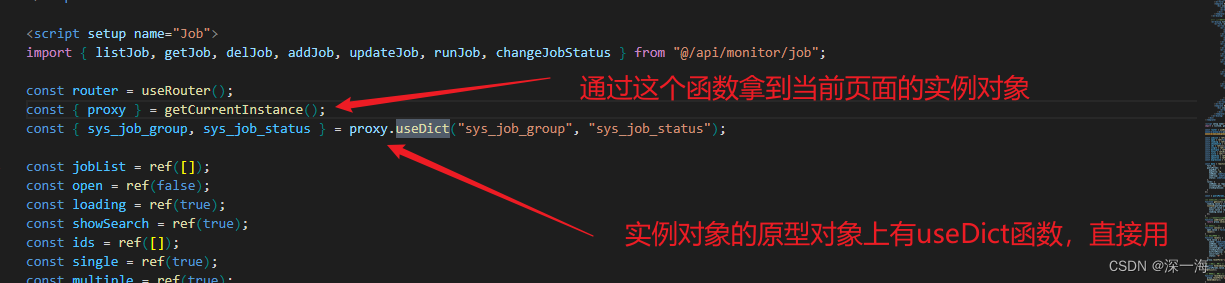
若依框架数据字典的使用_若依数据字典_哈哈水水水水的博客-CSDN博客 【精选】关于数据字典的理解与设计_数据字典怎么设计-CSDN博客 若依的字典值如何使用(超详细图文教程)_若依字典管理_丿BAIKAL巛的博客-CSDN博客 Vue3组合式API:getCurr…...

【汇编】内存中字的存储、用DS和[address]实现字的传送、DS与数据段
文章目录 前言一、内存中字的存储1.1 8086cpu字的概念1.2 16位的字存储在一个16位的寄存器中,如何存储?1.3 字单元 二、用DS和[address]实现字的传送2.1 字的传送是什么意思?2.2 要求原理解决方案:DS和[address]配合8086传送16字节…...

数据分析 - 分散性与变异的量度
全距 - 极差 处理变异性 方差度量 数值与均值的距离,也就是数据的差异性 标准差描述:典型值 和 均值的距离的方法,数据与均值的分散情况...
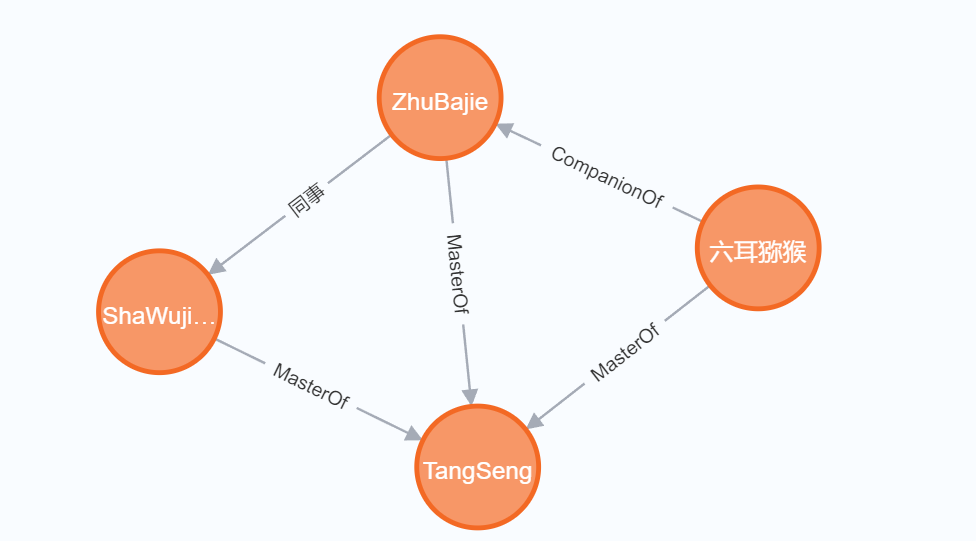
Neo4j数据库介绍及简单使用
图数据库介绍 图数据库是一种专门设计用于存储和管理图形数据的数据库类型。在图数据库中,数据以图的形式表示,其中节点表示实体,边表示实体之间的关系。这种表示方式非常适合处理具有复杂关系的数据,如社交网络、推荐系统、网络…...
ubuntu 20.04安装 Anaconda教程
在安装Anaconda之前需要先安装ros(防止跟conda冲突,先装ros)。提前安装好cuda 和cudnn。 本博客参考:ubuntu20.04配置ros noetic和cuda,cudnn,anaconda,pytorch深度学习的环境 安装完conda后,输入: pyth…...
iframe渲染后端接口文件和实现下载功能
一:什么是iframe? 1、介绍 iframe 是HTML 中的一种标签,全称为 Inline Frame,即内联框架。它可以在网页中嵌入其他页面或文档,将其他页面的内容以框架的形式展示在当前页面中。iframe的使用方式是通过在HTML文档中插入…...

广西建筑工地模板:支模九层桉木模板
广西作为中国西南地区的重要建筑市场,建设工地的模板需求量一直居高不下。在众多建筑模板中,支模九层桉木模板以其强度高、使用寿命长的特点而备受关注。本文将介绍广西建筑工地常用的支模九层桉木模板,并探讨其在建筑施工中的应用优势。支模…...

java集合,栈
只有栈是类 列表是个接口 栈是个类 队列 接口有双链表,优先队列(堆) add会报错 offer是一个满了不会报错 set集合 有两个类实现了这个接口...

Ubuntu 20.04 LTS ffmpeg gif mp4 互转 许编译安装ffmpeg ;解决gif转mp4转换后无法播放问题
安装ffmpeg apt install ffmpeg -y gif转mp4 ffmpeg -f gif -i ldh.gif ldh.mp4 故障:生成没报错,但mp4无法播放,体积也不正常 尝试编译安装最新版 sudo apt install -y yasm axel -n 100 https://ffmpeg.org/releases/ffmpeg-6.0.1.tar.x…...
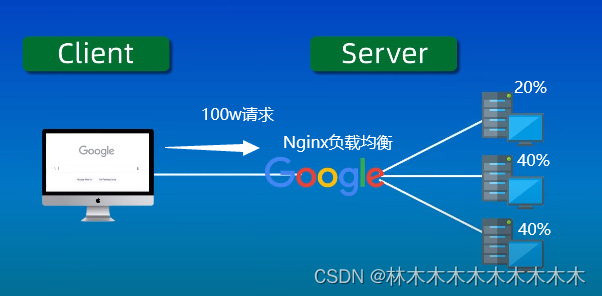
【Nginx】使用nginx进行反向代理与负载均衡
使用场景 反向代理:一个网站由许多服务器承载的,网站只暴露一个域名,那么这个域名指向一个代理服务器ip,然后由这台代理服务器转发请求到网站负载的多台服务器中的一台处理。这就需要用到Nginx的反向代理实现了 负载均衡…...
基于IDEA 进行Maven依赖管理
1. 依赖管理概念 Maven 依赖管理是 Maven 软件中最重要的功能之一。Maven 的依赖管理能够帮助开发人员自动解决软件包依赖问题,使得开发人员能够轻松地将其他开发人员开发的模块或第三方框架集成到自己的应用程序或模块中,避免出现版本冲突和依赖缺失等…...
瑞萨RZ/G2L平台 初起动(SD卡启动)
文章目录 一 准备条件1 工具2 硬件3 镜像 二 烧录SD卡启动盘三 写Bootloader1 烧录文件2 启动烧录3 烧录 四 启动设置 一 准备条件 1 工具 ** BalenaEtcher(俗称“ Etcher”),是一款快速将系统镜像文件( .iso 或 .img 或 .zip或…...

chkconfig及服务脚本
运行级别 linux启动之后处于某个状态 linux运行级别 0:关机 #设置即重启 1:单用户,为root权限,禁止远程登录 2:无网络文本模式 3:多用户文本模式 4:未使用 5:图形化…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...