机器学习-BM-FKNCN、BM-FKNN等分类器对比实验
目录
一、简介和环境准备
二、算法简介
2.1四种方法类:
2.1.1FKNN
2.1.2FKNCN
2.1.3BM-FKNN
2.1.3BM-FKNCN
2.2数据预处理
2.3输出视图
2.4调用各种方法看准确率
2.4.1BM-FKNCN
2.4.2BM-FKNN
2.4.3FKNCN
2.4.4FKNN
2.4.5KNN
一、简介和环境准备
knn一般指邻近算法。 K最近邻算法是一种常见的监督式学习算法,用于分类和回归问题。在K最近邻算法中,给定一个新的数据点,算法会找到训练数据集中离这个数据点最近的K个数据点,然后使用这K个数据点的标签或属性来预测新数据点的标签或属性。
主角是一种基于局部Bonferroni均值的模糊K-最近质心近邻(BM-FKNCN)分类器。下文会详细介绍BM-FKNCN。
本次实验环境需要用的是Google Colab和Google Drive(云盘),文件后缀是.ipynb可以直接用。首先登录谷歌云盘(网页),再打卡ipynb文件就可以跳转到谷歌colab了。再按以下点击顺序将colab和云盘链接。
输入依赖
from google.colab import drive
import pandas as pd
import numpy as np
import scipy.spatial
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import KFold
from sklearn.metrics import confusion_matrix
from sklearn.metrics import plot_confusion_matrix
import matplotlib.pyplot as plt
drive.mount('/content/drive')
二、算法简介
2.1四种方法类:
FKNN、FKNCN、BM_FKNN和BM_FKNCN(之后再调用,不用先运行)
2.1.1FKNN
FKNN是指Fuzzy K-Nearest Neighbor(模糊K最近邻)算法。它使用模糊逻辑来考虑数据点之间的相似性。在FKNN中,每个数据点都被赋予一个隶属度(membership degree),该隶属度表示数据点属于每个类别的可能性程度。与传统的K最近邻算法不同,FKNN不仅考虑最近的K个数据点,还考虑了与目标数据点在一定距离范围内的所有数据点。FKNN的主要优点是能够处理数据集中的噪声和模糊性,并且对于不平衡的数据集也表现良好。
#Methods##FKNNimport scipy.spatial
from collections import Counter
from operator import itemgetterclass FKNN:def __init__(self, k):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef getDistance(self, X1, X2):return scipy.spatial.distance.euclidean(X1, X2)def fuzzy(self, d, m):closestPoint = [ d[k][1] for k in range(len(d))]classes = np.unique(self.y_train[closestPoint])arrMembership = []for cls in classes:atas = 0bawah = 0for close in d: if(close[0] != 0):if(cls == self.y_train[close[1]]):atas += np.power((1/close[0]), (2/(m-1)))else:atas += np.power((0/close[0]), (2/(m-1)))bawah += np.power((1/close[0]), (2/(m-1)))else:atas += 0bawah += 1arrMembership.append([atas/bawah, cls])return arrMembershipdef predict(self, X_test):final_output = []for i in range(len(X_test)):d = []votes = []for j in range(len(X_train)):dist = self.getDistance(X_train[j] , X_test[i])d.append([dist, j])d.sort()d = d[0:self.k]membership = self.fuzzy(d, 2)predicted_class = sorted(membership, key=itemgetter(0), reverse=True)final_output.append(predicted_class[0][1]) return final_outputdef score(self, X_test, y_test):predictions = self.predict(X_test)value = 0for i in range(len(y_test)):if(predictions[i] == y_test[i]):value += 1return value / len(y_test)2.1.2FKNCN
模糊K-最近质心近邻(FKNCN)分类器是一种基于邻近性的模糊分类算法,是模糊K-最近邻(FKNN)算法的一种变体。与FKNN类似,FKNCN算法也使用模糊理论中的隶属度来度量样本之间的相似度。但是,与FKNN不同的是,FKNCN算法不仅考虑最近邻居的距离,还考虑了它们的质心。具体来说,对于每个测试样本,FKNCN算法首先使用K-最近邻算法来找到其K个最近的邻居。然后,对于每个类别,FKNCN算法计算其K个最近邻居的质心,并将测试样本与每个质心之间的距离作为该类别的隶属度。最后,FKNCN算法通过计算每个类别的隶属度之和,来确定测试样本所属的类别。
与FKNN相比,FKNCN具有以下优点:
-
对异常值和噪声更加鲁棒:FKNCN算法不仅考虑到每个邻居的距离,还考虑到它们的质心,因此对异常值和噪声更加鲁棒。
-
对于类别不平衡的数据集有更好的性能:FKNCN算法可以根据每个类别的质心来调整类别之间的权重,因此可以处理类别不平衡的数据集。
-
算法相对简单:FKNCN算法比一些更复杂的算法(如支持向量机)具有更简单的实现和计算。
##FKNCNimport scipy.spatial
from collections import Counter
from operator import itemgetterclass FKNCN:def __init__(self, k):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef getDistance(self, X1, X2):return scipy.spatial.distance.euclidean(X1, X2)def getFirstDistance(self, X_train, X_test):distance = []for i in range(len(X_train)):dist = scipy.spatial.distance.euclidean(X_train[i] , X_test)distance.append([i, dist, self.y_train[i]])return distancedef getCentroid(self, arrData):result=[]dataTran = np.array(arrData).Tfor i in range(len(dataTran)):result.append(np.mean(dataTran[i]))return resultdef kncn(self, X_test):myclass = list(set(self.y_train))closestPoint = []anothersPoint = []for indexK in range(0, self.k):if(indexK == 0):distance = self.getFirstDistance(self.X_train, X_test) distance_sorted = sorted(distance, key=itemgetter(1))closestPoint.append(distance_sorted[0])distance_sorted.pop(0)for anothers in (distance_sorted):anothersPoint.append(anothers[0]) else:arrDistance = []closestPointTemp = [self.X_train[r[0]] for r in closestPoint]for r in (anothersPoint):arrQ = closestPointTemp.copy()arrQ.append(self.X_train[r])arrDistance.append([r, self.getDistance(self.getCentroid(arrQ), X_test)])distance_sorted = sorted(arrDistance, key=itemgetter(1))closestPoint.append(distance_sorted[0])# anothersPoint = np.setdiff1d(anothersPoint, closestPoint)return closestPointdef fuzzy(self, d, m):closestPoint = [ d[k][1] for k in range(len(d))]classes = np.unique(self.y_train[closestPoint])arrMembership = []for cls in classes:atas = 0bawah = 0for close in d: if(close[0] != 0):if(cls == self.y_train[close[1]]):atas += np.power((1/close[0]), (2/(m-1)))else:atas += np.power((0/close[0]), (2/(m-1)))bawah += np.power((1/close[0]), (2/(m-1)))else:atas += 0bawah += 1arrMembership.append([atas/bawah, cls])return arrMembershipdef predict(self, X_test):final_output = []for i in range(len(X_test)):closestPoint = self.kncn(X_test[i])d = []votes = []for j in range(len(X_train)):dist = self.getDistance(X_train[j] , X_test[i])d.append([dist, j])d.sort()d = d[0:self.k]membership = self.fuzzy(d, 2)predicted_class = sorted(membership, key=itemgetter(0), reverse=True)final_output.append(predicted_class[0][1]) return final_outputdef score(self, X_test, y_test):predictions = self.predict(X_test)value = 0for i in range(len(y_test)):if(predictions[i] == y_test[i]):value += 1return value / len(y_test)2.1.3BM-FKNN
BM-FKNN是指一种基于贝叶斯模型的模糊K最近邻分类算法(Bayesian Model-based Fuzzy K-Nearest Neighbor)。BM-FKNN是对传统FKNN算法的改进,它通过引入贝叶斯模型来提高分类性能。具体地说,BM-FKNN使用贝叶斯分类器来计算每个类别的后验概率,并将其作为FKNN的权重,进而确定新数据点所属的类别。
BM-FKNN的主要优点是能够处理分类问题中的不确定性和噪声,同时具有高效性和灵活性。与传统的K最近邻算法相比,BM-FKNN能够更好地处理高维和大规模的数据集,并且对于不平衡的数据集也表现良好。BM-FKNN在模式识别、图像处理、生物信息学和金融等领域有广泛的应用。
##BM-FKNNimport scipy.spatial
from collections import Counter
from operator import itemgetterclass BM_FKNN:def __init__(self, k):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef getDistance(self, X1, X2):return scipy.spatial.distance.euclidean(X1, X2)def getFirstDistance(self, X_train, X_test):distance = []for i in range(len(X_train)):dist = scipy.spatial.distance.euclidean(X_train[i] , X_test)distance.append([i, dist, self.y_train[i]])return distancedef nearestPoint(self, X_test):allPoint = [ i for i in range(len(X_test))]distance = self.getFirstDistance(self.X_train, X_test) distance_sorted = sorted(distance, key=itemgetter(1))closest = distance_sorted[0:self.k]closestPoint = [ i[0] for i in closest]anothersPoint = np.setdiff1d(allPoint, closestPoint)return closestPoint, anothersPointdef bonferroniMean(self, c, closestPoint, p, q): arrInner = [self.X_train[e] for e in closestPoint if(self.y_train[e] != c)] # j bukan angggota i arrOuter = [self.X_train[q] for q in closestPoint if(self.y_train[q] == c)]n = len(closestPoint)if(n > 1):inner = [(sum(np.power(x, q)))/n for x in zip(*arrInner)]outer = [(sum(np.power(x, p)))/(n-1) for x in zip(*arrOuter)]else:inner = arrInner[0].copy()outer = arrOuter[0].copy()Br = [ np.power((inner[i]*outer[i]), (1/(p+q)) ) for i in range(len(inner))]return Brdef fuzzy(self, arrBr, closestPoint, m):arrMembership = []for localMean in arrBr:atas = 0bawah = 0for r in (closestPoint): if(localMean[1] == self.y_train[r]):atas += np.power((1/localMean[0]), (2/(m-1)))else:atas += np.power((0/localMean[0]), (2/(m-1)))bawah += np.power((1/localMean[0]), (2/(m-1)))arrMembership.append([atas/bawah, localMean[1]])return arrMembershipdef predict(self, X_test, p, q, m):final_output = []for i in range(len(X_test)):localMean = []closestPoint, anothersPoint = self.nearestPoint(X_test[i])classes = np.unique(self.y_train[closestPoint])if(len(classes) == 1):final_output.append(classes[0]) else:arrBr = []for j in classes:Br = self.bonferroniMean(j, closestPoint, p, q)distBr = self.getDistance(X_test[i], Br)arrBr.append([distBr, j])membership = self.fuzzy(arrBr, closestPoint, m )predicted_class = sorted(membership, key=itemgetter(0), reverse=True)final_output.append(predicted_class[0][1])return final_outputdef score(self, X_test, y_test, p, q, m):predictions = self.predict(X_test, p, q, m)value = 0for i in range(len(y_test)):if(predictions[i] == y_test[i]):value += 1# print(value)return value / len(y_test)2.1.3BM-FKNCN
一种基于局部Bonferroni均值的模糊K-最近质心近邻(BM-FKNCN)分类器,该分类器根据最近的局部质心均值向量分配查询样本的类标签,以更好地表示数据集的基础统计。由于最近中心邻域(NCN)概念还考虑了邻居的空间分布和对称位置,因此所提出的分类器对异常值具有鲁棒性。此外,所提出的分类器可以克服具有类不平衡的数据集中邻居的类支配,因为它平均每个类的所有质心向量,以充分解释类的分布。
##BM-FKNCNimport scipy.spatial
from collections import Counter
from operator import itemgetterclass BM_FKNCN:def __init__(self, k):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef getDistance(self, X1, X2):return scipy.spatial.distance.euclidean(X1, X2)def getFirstDistance(self, X_train, X_test):distance = []for i in range(len(X_train)):dist = scipy.spatial.distance.euclidean(X_train[i] , X_test)distance.append([i, dist, self.y_train[i]])return distancedef getCentroid(self, arrData):result=[]dataTran = np.array(arrData).Tfor i in range(len(dataTran)):result.append(np.mean(dataTran[i]))return resultdef kncn(self, X_test):myclass = list(set(self.y_train))closestPoint = []anothersPoint = []for indexK in range(0, self.k):if(indexK == 0):distance = self.getFirstDistance(self.X_train, X_test) distance_sorted = sorted(distance, key=itemgetter(1))closestPoint.append(distance_sorted[0][0])distance_sorted.pop(0)for anothers in (distance_sorted):anothersPoint.append(anothers[0]) else:arrDistance = []closestPointTemp = [self.X_train[r] for r in closestPoint]for r in (anothersPoint):arrQ = closestPointTemp.copy()arrQ.append(self.X_train[r])arrDistance.append([r, self.getDistance(self.getCentroid(arrQ), X_test)])distance_sorted = sorted(arrDistance, key=itemgetter(1))closestPoint.append(distance_sorted[0][0])anothersPoint = np.setdiff1d(anothersPoint, closestPoint)return closestPoint, anothersPointdef bonferroniMean(self, c, closestPoint, p, q): arrInner = [self.X_train[e] for e in closestPoint if(self.y_train[e] != c)] # j bukan angggota i arrOuter = [self.X_train[q] for q in closestPoint if(self.y_train[q] == c)]n = len(closestPoint)if(n > 1):inner = [(sum(np.power(x, q)))/n for x in zip(*arrInner)]outer = [(sum(np.power(x, p)))/(n-1) for x in zip(*arrOuter)]else:inner = arrInner[0].copy()outer = arrOuter[0].copy()Br = [ np.power((inner[i]*outer[i]), (1/(p+q)) ) for i in range(len(inner))]return Brdef fuzzy(self, arrBr, closestPoint, m):arrMembership = []for localMean in arrBr:atas = 0bawah = 0for r in (closestPoint):if(localMean[1] == self.y_train[r]):atas += np.power((1/localMean[0]), (2/(m-1)))else:atas += np.power((0/localMean[0]), (2/(m-1)))bawah += np.power((1/localMean[0]), (2/(m-1)))arrMembership.append([atas/bawah, localMean[1]])return arrMembershipdef predict(self, X_test, p, q, m):final_output = []for i in range(len(X_test)):localMean = []closestPoint, anothersPoint = self.kncn(X_test[i])classes = np.unique(self.y_train[closestPoint])if(len(classes) == 1):final_output.append(classes[0]) else:arrBr = []for j in classes:Br = self.bonferroniMean(j, closestPoint, p, q)distBr = self.getDistance(X_test[i], Br)arrBr.append([distBr, j])membership = self.fuzzy(arrBr, closestPoint, m ) #Membership Degreepredicted_class = sorted(membership, key=itemgetter(0), reverse=True)final_output.append(predicted_class[0][1])return final_outputdef score(self, X_test, y_test, p, q, m):predictions = self.predict(X_test, p, q, m)value = 0for i in range(len(y_test)):if(predictions[i] == y_test[i]):value += 1return value / len(y_test)2.2数据预处理
乳房X光检查数据集
train_path = r'drive/MyDrive/BM-FKNCN-main/Dataset/mammographic_masses.xlsx'
data_train = pd.read_excel(train_path)
data_train.head()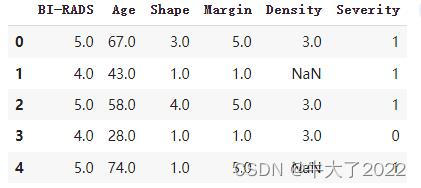
输出数据集详细信息
data_train.info()
输出一个比重,我不太清楚是什么,应该是丢失数据集率?
for col in data_train.columns:print(col, str(round(100* data_train[col].isnull().sum() / len(data_train), 2)) + '%')
data_train.loc[(data_train['BI-RADS'].isnull()==True), 'BI-RADS'] = data_train['BI-RADS'].mean()
data_train.loc[(data_train['Age'].isnull()==True), 'Age'] = data_train['Age'].mean()
data_train.loc[(data_train['Shape'].isnull()==True), 'Shape'] = data_train['Shape'].mean()
data_train.loc[(data_train['Margin'].isnull()==True), 'Margin'] = data_train['Margin'].mean()
data_train.loc[(data_train['Density'].isnull()==True), 'Density'] = data_train['Density'].mean()for col in data_train.columns:print(col, str(round(100* data_train[col].isnull().sum() / len(data_train), 2)) + '%')
2.3输出视图
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
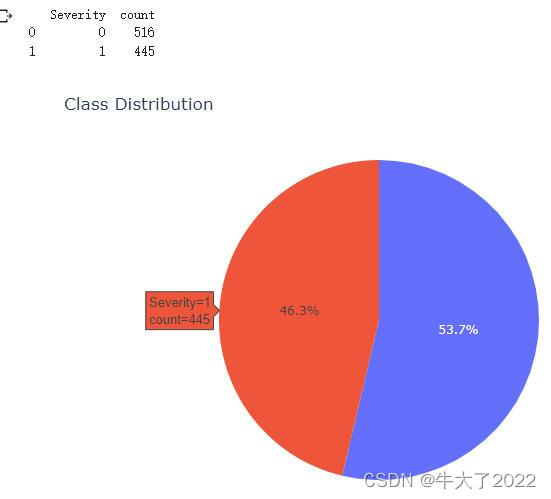
from matplotlib.colors import LinearSegmentedColormapcountClass = data_train['Severity'].value_counts().reset_index()
countClass.columns = ['Severity', 'count']
print(countClass)fig = px.pie(countClass, values='count', names="Severity", title='Class Distribution', width=700, height=500
)fig.show()统计了患病人数和比例
np.unique(np.array(data_train['Severity']))症状这个变量矩阵,肯定是0-1,得与没得的差别
array([0, 1])
输出患者和未患者的受每种影响因素及是否患病的两两关系图
features = data_train.iloc[:,:5].columns.tolist()
plt.figure(figsize=(18, 27))for i, col in enumerate(features):plt.subplot(6, 4, i*2+1)plt.subplots_adjust(hspace =.25, wspace=.3)plt.grid(True)plt.title(col)sns.kdeplot(data_train.loc[data_train["Severity"]==0, col], label="alive", color = "blue", shade=True, cut=0)sns.kdeplot(data_train.loc[data_train["Severity"]==1, col], label="dead", color = "yellow", shade=True, cut=0)plt.subplot(6, 4, i*2+2) sns.boxplot(y = col, data = data_train, x="Severity", palette = ["blue", "yellow"]) 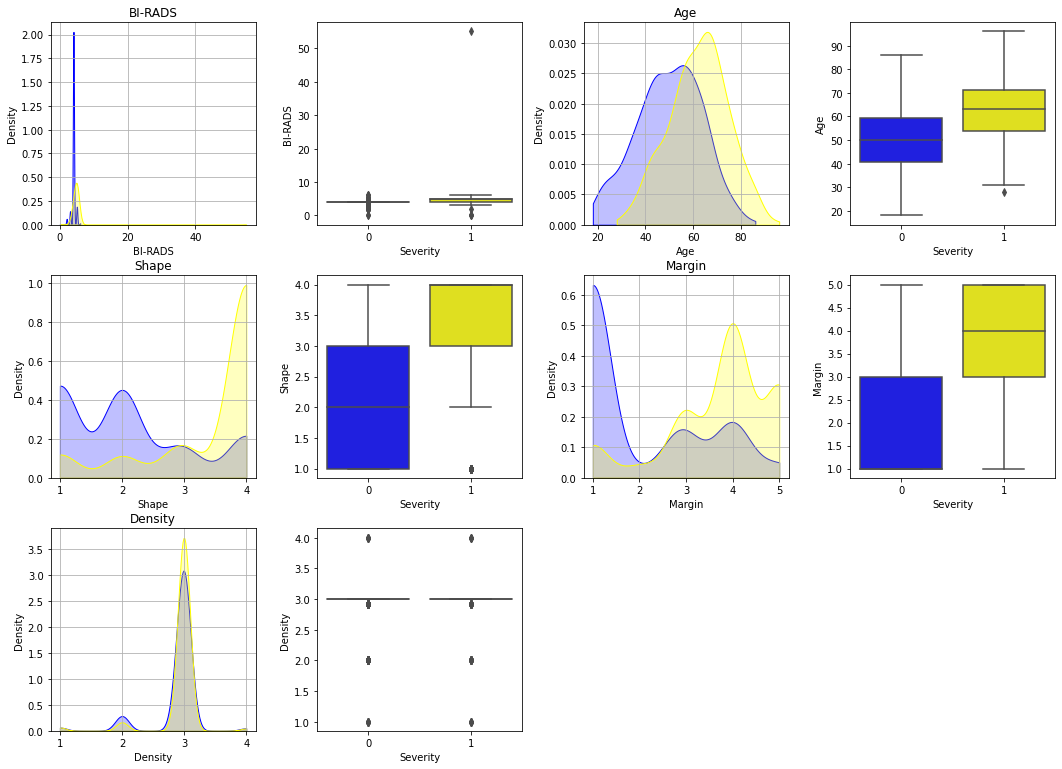
数据处理:
label_train = data_train.iloc[:,-1].to_numpy()
fitur_train = data_train.iloc[:,:5].to_numpy()
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(fitur_train)
fitur_train_normalize = scaler.transform(fitur_train)2.4调用各种方法看准确率
2.4.1BM-FKNCN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)rataBMFKNCN=[]
for train_index, test_index in kf.split(fitur_train_normalize):X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]y_train, y_test = label_train[train_index], label_train[test_index]bmfkncn = BM_FKNCN(9)bmfkncn.fit(X_train, y_train)prediction = bmfkncn.score(X_test, y_test, 1, 1, 2)rataBMFKNCN.append(prediction)print('Mean Accuracy: ', np.mean(rataBMFKNCN))Mean Accuracy: 0.7960481099656358
(不知道为啥跑了8分钟……几个数为按理说不应该那么长)
2.4.2BM-FKNN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)rataBMFKNN = []
for train_index, test_index in kf.split(fitur_train_normalize):X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]y_train, y_test = label_train[train_index], label_train[test_index]bmfknn = BM_FKNN(9)bmfknn.fit(X_train, y_train)prediction = bmfknn.score(X_test, y_test, 1, 1, 2)rataBMFKNN.append(prediction)print('Mean Accuracy: ', np.mean(rataBMFKNN))Mean Accuracy: 0.7981421821305843
2.4.3FKNCN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)rataFKNCN = []
for train_index, test_index in kf.split(fitur_train_normalize):X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]y_train, y_test = label_train[train_index], label_train[test_index]fkncn = FKNCN(9)fkncn.fit(X_train, y_train)prediction = fkncn.score(X_test, y_test)rataFKNCN.append(prediction)print('Mean Accuracy: ', np.mean(rataFKNCN))Mean Accuracy: 0.7783290378006873
这也跑了8分钟……看了FKNCN确实慢
2.4.4FKNN
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)accuracyFKNN = []for train_index, test_index in kf.split(fitur_train_normalize):X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]y_train, y_test = label_train[train_index], label_train[test_index]fknn = FKNN(9)fknn.fit(X_train, y_train)prediction = fknn.score(X_test, y_test)accuracyFKNN.append(prediction)print('Mean Accuracy: ', np.mean(accuracyFKNN))Mean Accuracy: 0.7783290378006873
2.4.5KNN
from sklearn.neighbors import KNeighborsClassifier
kf = KFold(n_splits=10, random_state=1, shuffle=True)
kf.get_n_splits(fitur_train_normalize)
rata = []for train_index, test_index in kf.split(fitur_train_normalize):X_train, X_test = fitur_train_normalize[train_index], fitur_train_normalize[test_index]y_train, y_test = label_train[train_index], label_train[test_index]neigh = KNeighborsClassifier(n_neighbors=9)neigh.fit(X_train, y_train)prediction = neigh.score(X_test, y_test)rata.append(prediction)print('Mean Accuracy: ', np.mean(rata))Mean Accuracy: 0.7981421821305843
柱状图看一下
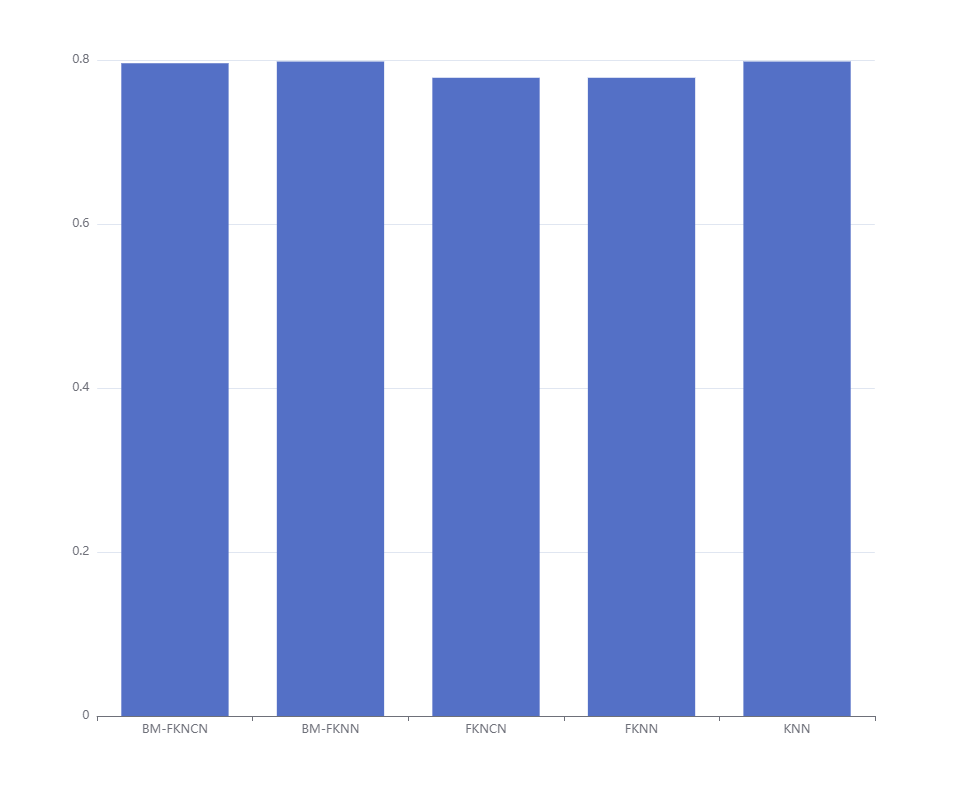
简单看,对于这组数据,BM-FKNN和KNN表现最好。
来源有更多数据集供分析,这里不再列举。
多组实验最后平均准确率:
Average of Accuracy
KNN = 0,8630
FKNN = 0,8666
FKNCN = 0,8637
BM-FKNN = 0,8634
BM-FKNCN = 0,8986
实验结果表明,与其他四个分类器相比,BM-FKNCN实现了89.86%的最高总体平均分类精度。
来源:GitHub - baguspurnama98/BM-FKNCN: A Bonferroni Mean Based Fuzzy K-Nearest Centroid Neighbor (BM-FKNCN), BM-FKNN, FKNCN, FKNN, KNN Classifier
相关文章:
机器学习-BM-FKNCN、BM-FKNN等分类器对比实验
目录 一、简介和环境准备 二、算法简介 2.1四种方法类: 2.1.1FKNN 2.1.2FKNCN 2.1.3BM-FKNN 2.1.3BM-FKNCN 2.2数据预处理 2.3输出视图 2.4调用各种方法看准确率 2.4.1BM-FKNCN 2.4.2BM-FKNN 2.4.3FKNCN 2.4.4FKNN 2.4.5KNN 一、简介和环境准备 k…...

ChatGPT火了,对话式人工智能还能干嘛?
身兼数职的ChatGPT 从2022火到了2023 连日来一直是各大平台的热议对象 其实除了写诗、敲代码、处理文档 以ChatGPT为代表的 对话式人工智能 还有更重要的工作要做 对话式AI与聊天机器人 相信大多数人…...
)
十一、操作数栈的特点(Operand Sstack)
1.每一个独立的栈帧中除了包含局部变量表以外,还包含一个后进先出的操作数栈,也可以称之为表达式栈。 2.操作数栈,在方法执行过程中,根据字节码指令,往栈中写入数据,或提取数据,即入栈ÿ…...

拆解瑞幸新用户激活流程,如何让用户“动”起来?
Aha时刻 一个产品的拉新环节,是多种方式并存的;新用户可能来自于商务搭建了新的渠道,运营策划了新的活动,企划发布了新的广告,销售谈下了新的客户,市场推广了新的群体,以及产品本身的口碑传播,功能更新带来的自然流量。 这是一个群策群力的环节,不同的团队背负不同的K…...
tkinter界面的TCP通信/开启线程等待接收数据
前言 用简洁的语言写一个可以与TCP客户端实时通信的界面。之前做了一个项目是要与PLC进行信息交互的界面,在测试的时候就利用TCP客户端来实验,文末会附上TCP客户端。本文分为三部分,第一部分是在界面向TCP发送数据,第二部分是接收…...

华为OD机试题,用 Java 解【任务混部】问题
最近更新的博客 华为OD机试题,用 Java 解【停车场车辆统计】问题华为OD机试题,用 Java 解【字符串变换最小字符串】问题华为OD机试题,用 Java 解【计算最大乘积】问题华为OD机试题,用 Java 解【DNA 序列】问题华为OD机试 - 组成最大数(Java) | 机试题算法思路 【2023】使…...

看linux内核启动流程需要的汇编指令解释
一、指令 0.MRS 和MSR MRS 指令: 对状态寄存器CPSR和SPSR进行读操作。 MSR指令: 对状态寄存器CPSR和SPSR进行写操作。 1.adrp adrp x0, boot_args把boot_args的页基地址提取出来,放到x0中。 2.stp stp x21, x1, [x0]将 x21, x1 的值存入 x0寄存器记录的地址中…...

【巨人的肩膀】JAVA面试总结(二)
1、💪 目录1、💪1.0、什么是面向对象1.1、JDK、JRE、JVM之间的区别1.2、什么是字节码1.3、hashCode()与equals()之间的联系1.4、String、StringBuffer、StringBuilder的区别1.5、和equals方法的区别1.6、重载和重写的区别1.7、List和Set的区别1.8、Array…...

【网络安全入门】零基础小白必看!!!
看到很多小伙伴都想学习 网络安全 ,让自己掌握更多的 技能,但是学习兴趣有了,却发现自己不知道哪里有 学习资源◇瞬间兴致全无!◇ 😄在线找人要资料太卑微,自己上网下载又发现要收费0 🙃差点当…...
)
字节前端经典面试题(附答案)
有哪些可能引起前端安全的问题? 跨站脚本 (Cross-Site Scripting, XSS): ⼀种代码注⼊⽅式, 为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简…...
数据库管理工具的使用
目录 摘要 一、Navicat是什么? 二、使用步骤 1.如何下载与安装 2.如何连接远程数据库 总结 摘要 本文主要介绍数据库管理工具的使用 一、Navicat是什么? 它是一款数据库管理工具,将此工具连接数据库,你可以从中看到各种数据库的详细…...

让马斯克反悔的毫米波雷达,被国产雷达头部厂商木牛科技迭代到了5D时代
近日,特斯拉或将在其HW4.0硬件系统配置一枚高精度4D毫米波雷达的消息在外网刷屏。据分析,“纯视觉”信仰者马斯克之所以做出这样的决定,一方面是减配了雷达的特斯拉自动驾驶,表现不尽如人意;另一方面也跟毫米波雷达的技…...
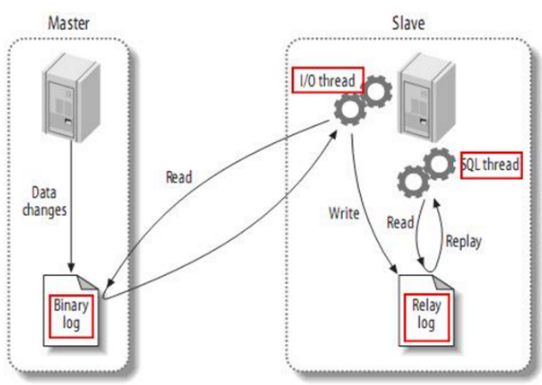
MaxWell原理概述
文章目录1.MaxWell概述2.Maxwell输出数据格式3.Maxwell原理3.1 MySQL二进制日志3.2 MySQL主从复制1.MaxWell概述 Maxwell 是由美国Zendesk公司开源,用Java编写的MySQL变更数据抓取软件。它会实时监控Mysql数据库的数据变更操作(包括insert、update、dele…...
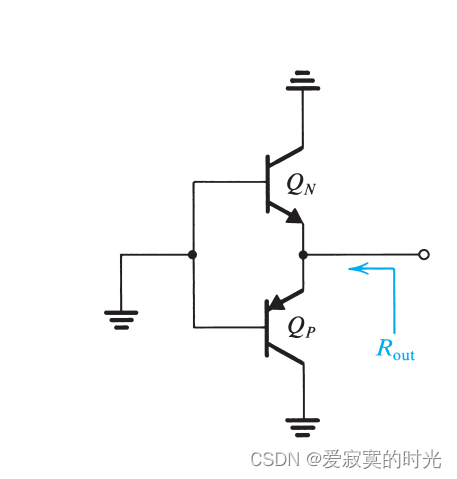
电子技术——AB类输出阶
电子技术——AB类输出阶 原理 交越失真可以通过通过一个较小的偏置电流解除,如下图: QNQ_NQN 和 QPQ_PQP 的基极之间存在偏置电压 VBBV_{BB}VBB 。对于完美匹配的晶体管,当 vI0v_I 0vI0 的时候,此时 vO0v_O 0vO0 。每…...

Archlinux个人安装流程
操作环境: 时间:2023-02-17 电脑型号:联想拯救者R720 cpu:Intel Core i5-7300HQ 4x 3.5GHz gpu:NVIDIA GeForce GTX 1050 Ti 安装系统: 1.下载镜像: 请访问https://archlinux.org/查找镜…...
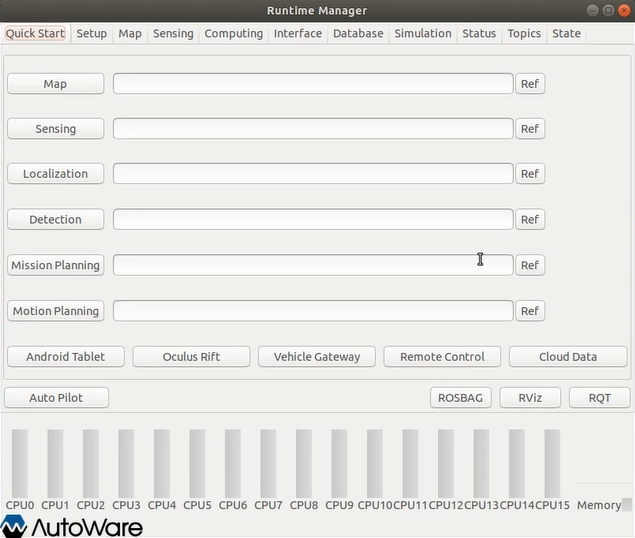
【Autoware】2小时安装Autoware1.13(保姆级教程)
前言:ROS的出现使得机器人软件开发更加快速和模块化,在此基础上,Autoware.ai开源项目可以让我们很容易地将一套完整的自动驾驶软件部署到我们的测试车辆上,并见证它跑起来! 文章目录1.Autoware简介2.电脑软硬件配置要求…...
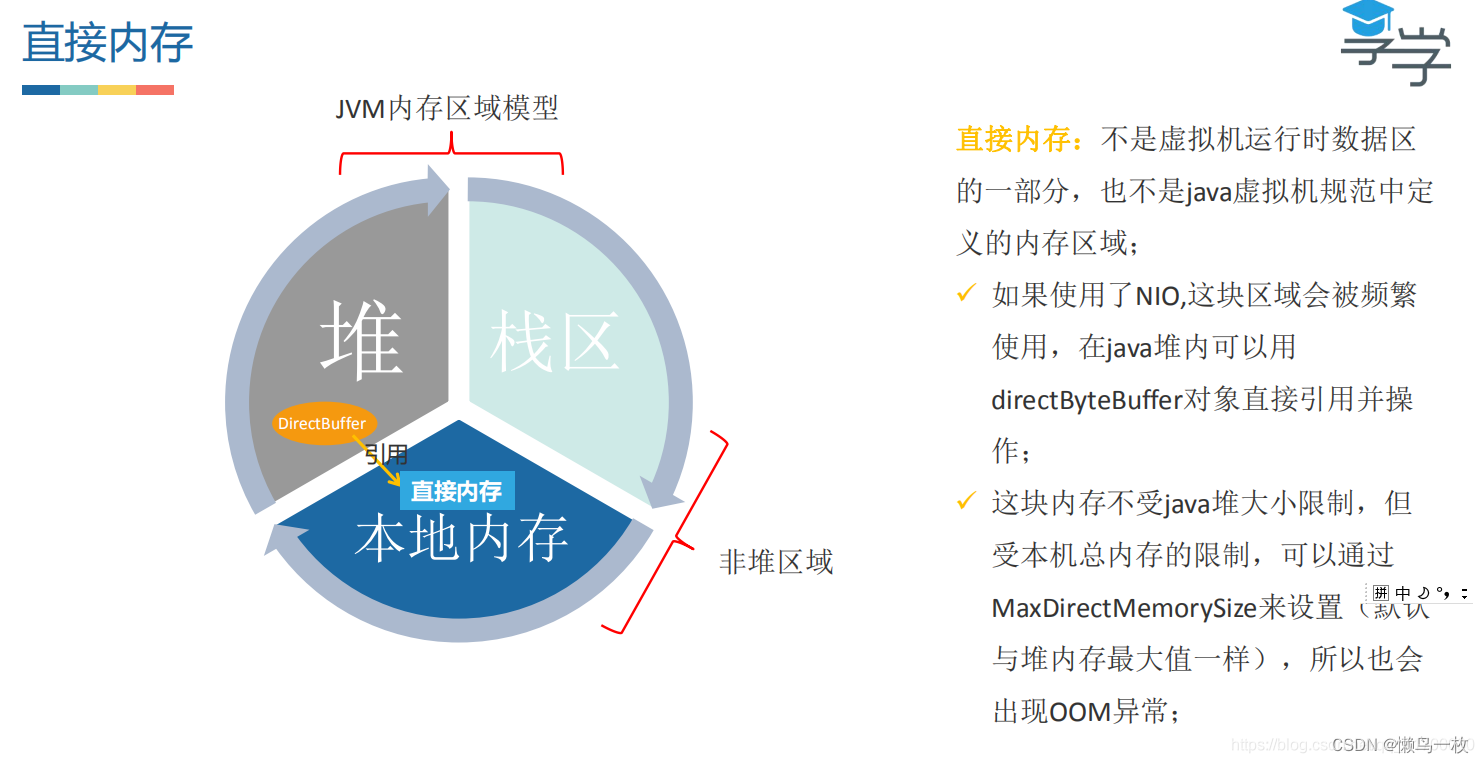
JVM 堆内存模型
方法区和永久代的关系 方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 N…...
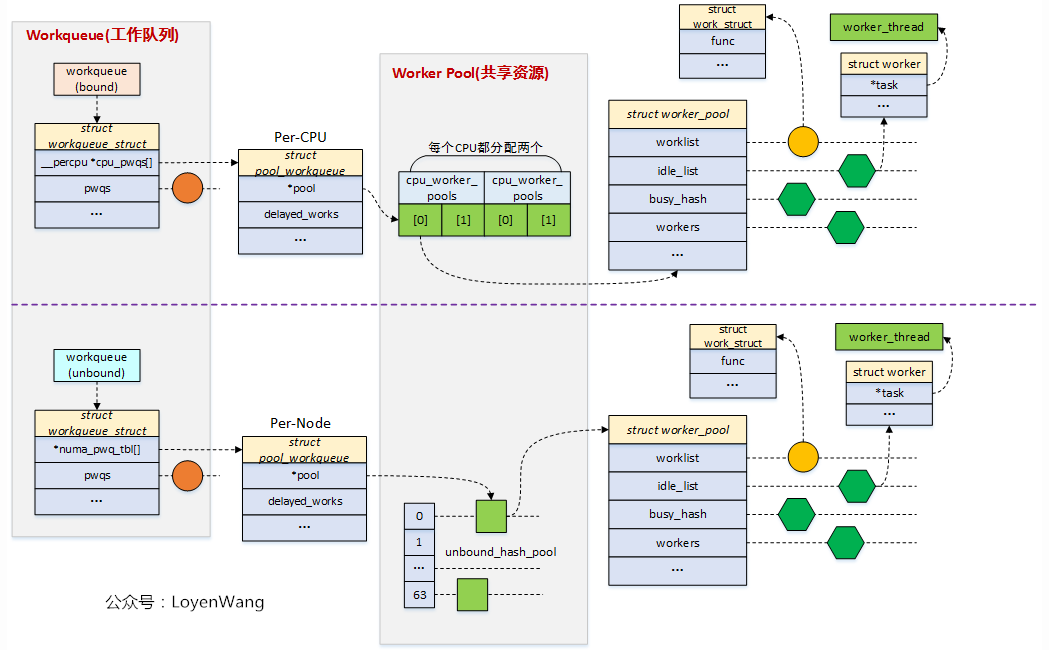
linux-中断下半部
引用preempt宋宝华: 是谁关闭了Linux抢占,而抢占又关闭了谁?Linux用户抢占和内核抢占详解(概念, 实现和触发时机)--Linux进程的管理与调度(二十)内核抢占实现(preempt)Linux中的preempt_count - 知乎 (zhihu.com)linux 中断子系统…...
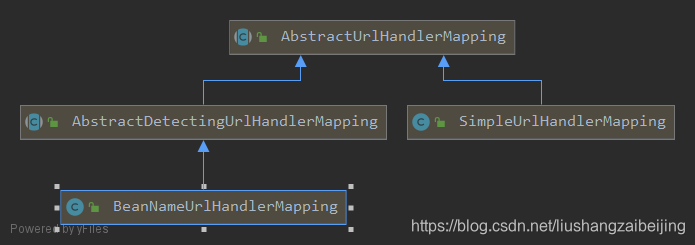
SpringMVC源码:HandlerMapping加载1
参考资料: 《SpringMVC源码解析系列》 《SpringMVC源码分析》 《Spring MVC源码》 写在开头:本文为个人学习笔记,内容比较随意,夹杂个人理解,如有错误,欢迎指正。 前文: 《SpringMVC源码&a…...

【ArcGIS】12 投影
问题描述 在处理地理数据时,可能会遇到以下关于投影的问题: DEM缺少投影,提取流域会报错图层只有地理坐标系,没有投影坐标系,无法测量距离、计算面积等要素图层投影偏移量错误,与实际位置有偏差总之,投影对各种地理操作影响很大,有必要深入理解。 投影说明 在ArcGIS…...

告别输入法乱码!ArchLinux + GNOME 桌面下 Fcitx5 的保姆级配置与美化全攻略
ArchLinux GNOME 桌面下 Fcitx5 输入法的终极配置与视觉优化指南 在 Linux 桌面环境中配置中文输入法一直是许多用户的痛点,尤其是对于 ArchLinux 这样需要手动配置的发行版。本文将带你从零开始,在 GNOME 桌面环境下打造一个既稳定又美观的 Fcitx5 输入…...

Vue3中的reactive转换:Naive Ui Admin普通对象响应式处理指南
Vue3中的reactive转换:Naive Ui Admin普通对象响应式处理指南 【免费下载链接】naive-ui-admin Naive Ui Admin 是一个基于 vue3,vite2,TypeScript 的中后台解决方案,它使用了最新的前端技术栈,并提炼了典型的业务模型,页面&#…...

OpenClaw技能市场探索:GLM-4.7-Flash的扩展应用案例
OpenClaw技能市场探索:GLM-4.7-Flash的扩展应用案例 1. 为什么需要关注OpenClaw技能市场? 第一次接触OpenClaw时,我被它的"技能市场"概念深深吸引。作为一个长期被重复性工作困扰的技术写作者,我一直在寻找能够真正理…...

3步构建专业级虚拟海洋测试环境:ASV波浪模拟器实战指南
3步构建专业级虚拟海洋测试环境:ASV波浪模拟器实战指南 【免费下载链接】asv_wave_sim This package contains plugins that support the simulation of waves and surface vessels in Gazebo. 项目地址: https://gitcode.com/gh_mirrors/as/asv_wave_sim 定…...

Chord基于Qwen2.5-VL的视觉定位服务一文详解:支持多目标+属性描述+位置词
Chord基于Qwen2.5-VL的视觉定位服务一文详解:支持多目标属性描述位置词 1. 项目简介 1.1 什么是Chord视觉定位服务? Chord是一个基于Qwen2.5-VL多模态大模型的智能视觉定位服务。它能够理解自然语言描述,并在图像中精确找到并标注出对应的…...

FreeACS技术指南:构建企业级TR-069设备管理系统
FreeACS技术指南:构建企业级TR-069设备管理系统 【免费下载链接】freeacs Free TR-069 ACS that can run (mostly) anywhere. 项目地址: https://gitcode.com/gh_mirrors/fr/freeacs 一、问题:传统设备管理的困境与挑战 在网络设备管理领域&…...

PPTAgent:智能文档转演示文稿的全流程解决方案
PPTAgent:智能文档转演示文稿的全流程解决方案 【免费下载链接】PPTAgent PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides 项目地址: https://gitcode.com/gh_mirrors/pp/PPTAgent 1. 价值定位:重新定义演示文稿创作效…...

重塑社区体验:打造无广告干扰的第三方酷安客户端
重塑社区体验:打造无广告干扰的第三方酷安客户端 【免费下载链接】c001apk fake coolapk 项目地址: https://gitcode.com/gh_mirrors/c0/c001apk c001apk作为一款基于官方客户端二次开发的第三方应用,采用Jetpack Compose框架与MVI架构模式&#…...

Zed IDE新大招:Git 三合一 Picker,告别“找功能“焦虑症!
推荐阅读 Zed IDE 又整新活:确实比 VS Code 优雅丝滑! Zed IDE 又扔出了一个新玩具,确实比 VS Code 清新优雅! Zed 推出分栏 Diff :比 VSCode 更快、更智能的Git体验! Zed IDE 官宣ACP:一…...
)
机器学习个人笔记(第一节)
第一章:什么是机器学习定义:计算机程序从经验E中学习,解决某一任务T,进行某一性能P,通过P测定在T上的表现因经验E而提高 eg:跳棋程序 E: 程序自身下的上万盘棋局 T: 下跳棋 P&#x…...