【巨人的肩膀】JAVA面试总结(二)
1、💪
目录
- 1、💪
- 1.0、什么是面向对象
- 1.1、JDK、JRE、JVM之间的区别
- 1.2、什么是字节码
- 1.3、hashCode()与equals()之间的联系
- 1.4、String、StringBuffer、StringBuilder的区别
- 1.5、==和equals方法的区别
- 1.6、重载和重写的区别
- 1.7、List和Set的区别
- 1.8、ArrayList和LinkedList的区别
- 1.9、ArrayList的优缺点?
- 1.10、Array和ArrayList有何区别?什么时候更适合用Array?
- 1.11、遍历一个List有哪些不同的方式?
- 1.12、ArrayList的扩容机制
- 1.13、ConcurrentHashMap的实现原理是什么?
- 1.14、JDK1.8 中为什么使用内置锁 synchronized替换 可重入锁 ReentrantLock?
- 1.15、ConcurrentHashMap的扩容机制
- 1.16、HashMap 与 ConcurrentHashMap 的区别是什么?
- 1.17、JDK1.7和JDK1.8的ConcurrentHashMap实现有什么不同
- 1.18、ConcurrentHashMap的put方法执行逻辑是什么
- 1.19、ConcurrentHashMap的get方法执行逻辑是什么
- 1.20、ConcurrentHashMap 的 get 方法是否要加锁,为什么?
- 1.21、get 方法不需要加锁与 volatile 修饰的哈希桶数组有关吗?
- 1.22、ConcurrentHashMap 不支持 key 或者 value 为 null 的原因?
- 1.23、ConcurrentHashMap 和 Hashtable 的效率哪个更高?为什么?
- 1.24、具体说一下Hashtable的锁机制
- 1.25、jdk1.7到jdk1.8HashMap发生了什么变化
- 1.26、解决hash冲突的办法有哪些?HashMap用的哪种?
- 1.27、为什么在解决hash冲突的时候,不直接用红黑树?而选择先用链表,再转为红黑树?
- 1.28、HashMap默认加载因子是多少?为什么是0.75
- 1.29、HashMap的Put方法
- 1.30、HashMap为什么线程不安全
- 1.31、深拷贝和浅拷贝
- 1.32、HashMap的扩容机制
- 1.33、Java中的异常体系是怎样的
- 1.34、什么时候应该抛出异常,什么时候捕获异常
- 1.35、了解ReentrantLock吗
- 1.36、ReentrantLock中tryLock()和lock()方法的区别
- 1.37、ReentrantLock中的公平锁和非公平锁的底层实现
- 1.38、ReadWriteLock是什么
- 1.39、Sychronized的偏向锁、轻量级锁、重量级锁
- 1.40、synchronized为什么是非公平锁?非公平体现在哪些地方
- 1.41、Sychronized和ReentrantLock的区别
- 1.42、谈谈你对AQS的理解,AQS如何实现可重入锁
- 1.43、什么是泛型?有什么作用
- 1.44、泛型的使用方式有哪几种
- 1.45、Java泛型的原理是什么?什么是类型擦除
- 1.46、什么是泛型中的限定通配符和非限定通配符
- 1.47、Array中可以用泛型吗
- 1.48、项目中哪里用到了泛型
- 1.49、反射
- 1.50、如何获取反射中的Class对象
- 1.51、Java反射API有几类?
- 1.52、反射机制的应用有哪些?
- 1.53、什么是注解?
- 1.54、注解的解析方法有哪几种
- 1.55、序列化和反序列化
- 1.56、如果有些字段不想进行序列化怎么办
- 1.57、为什么不推荐使用JDK自带的序列化
- 1.58、静态变量会被序列化吗
- 1.56、如果有些字段不想进行序列化怎么办
- 1.57、为什么不推荐使用JDK自带的序列化
- 1.58、静态变量会被序列化吗
1.0、什么是面向对象
对比面向过程,面向对象是不同的处理问题的角度。面向过程更注重事情的每一个步骤及顺序,面向对象更注重事情有哪些参与者,及各自需要做什么。
比如:洗衣机洗衣服。面向过程就会将任务拆解成一系列的函数:1.打开洗衣机 2.放衣服 3.放洗衣粉 4.清洗
面向对象会拆出人和洗衣机两个对象,人:打开洗衣机、放衣服、放洗衣粉,洗衣机只需要清洗即可。
面向过程比较直接高效,面向对象更易于维护、扩展和复用。
面向对象有三大特性:封装、继承和多态
-
封装的意义在于明确标识出允许外部使用的所有成员函数和数据项,内部细节对外部调用透明,外部调用无需关心内部的实现,Java中有两个比较经典的场景
-
Javabean 的属性私有,对外提供 get、set 方法访问
private String name; public void setName(String name){this.name = name; } -
orm 框架:操作数据库,我们不需要关心链接是如何建立的、sql是如何执行的,只需要引入 mybatis,调相应的方法即可
-
-
继承:继承父类的方法,并作出自己的改变和扩展
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
-
多态:比如都是动物类型的对象,执行 run 方法,cat 猫类和 dog 狗类会表现出不同的行为特征。
- 多态的使用前提:必须存在继承或者实现关系、必须存在父类类型的变量引用(指向)子类类型的对象、需要存在方法重写
- 多态本质上分为两种:编译时多态(又称静态多态)、运行时多态(又称动态多态)。**我们通常所说的多态指的都是运行时多态,也就是编译时不确定究竟调用哪个具体方法,一直延迟到运行时才能确定。**这也是为什么有时候多态方法又被称为延迟方法的原因。
1.1、JDK、JRE、JVM之间的区别
- JDK:Java SE Development Kit,Java标准开发包,它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
- JRE:Java Runtime Environment,它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序
- JVM:Java Virtual Mechinal,Java 虚拟机,它是整个 Java 实现跨平台的最核心的部分,负责运行字节码文件。
我们写出来的 Java 代码,想要运行,需要先编译成字节码,那就需要编译器,而 JDK 中就包含了编译器 javac,编译之后的字节码,想要运行,就需要一个可以执行字节码的程序,这个程序就是 JVM Java虚拟机,专门用来执行 Java 字节码的。
JDK包含JRE,JRE包含JVM。
1.2、什么是字节码
Java之所以可以“一次编译,到处运行”,一是因为JVM针对各种操作系统、平台都进行了定制,二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class文件)供JVM使用。因此,也可以看出字节码对于Java生态的重要性。
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
1.3、hashCode()与equals()之间的联系
在Java中,每个对象都可以调用自己的hashCode()方法得到自己的哈希值(hashCode),我们可以利用hashCode来做一些提前的判断,比如:
- 如果两个对象的hashCode不相同,那么这两个对象肯定不同的两个对象
- 如果两个对象的hashCode相同,不代表这两个对象一定是同一个对象,也可能是两个对象
- 如果两个对象相等,那么他们的hashCode就一定相同
在Java的集合类的实现中,在比较两个对象是否相等时,会先调用对象的hashCode()方法得到哈希值进行比较,如果hashCode不相同,就可以直接认为这两个对象不相同。如果hashCode相同,那么就会进一步调用equals()方法进行比较,可以用来最终确定两个对象是不是相等的。所以如果我们重写了equals()方法,一般也要重写 hashCode() 方法。
1.4、String、StringBuffer、StringBuilder的区别
-
String是不可变的,如果尝试去修改,会新生成一个字符串对象,StringBuffer和StringBuilder是可变的【补充:String 不是基本数据类型,是引用类型,底层用 char 数组实现的】,String类利用了 final 修饰的 char 类型数组存储字符,它里面的对象是不可变的,也就可以理解为常量,显然线程安全。
private final char value[]; -
StringBuffer是线程安全的,StringBuffer 属于可变类,对方法加了同步锁,线程安全【说明:StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的】
-
StringBuilder是线程不安全的
执行效率:StringBuilder > StringBuffer > String
线程安全:当多个线程访问某一个类(对象或方法)时,对象对应的公共数据区始终都能表现正确,那么这个类(对象或方法)就是线程安全的
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
String 为什么要设计为不可变类?不可变对象的好处是什么?
主要的原因主要有以下三点:
- 字符串常量池的需要:字符串常量池是 Java 堆内存中一个特殊的存储区域, 当创建一个 String 对象时,假如此字符串值已经存在于常量池中,则不会创建一个新的对象,而是引用已经存在的对象
- 允许 String 对象缓存 HashCode:Java 中 String 对象的哈希码被频繁地使用, 比如在 HashMap 等容器中。字符串不变性保证了 hash 码的唯一性,因此可以放心地进行缓存。这也是一种性能优化手段,意味着不必每次都去计算新的哈希码;
- String 被许多的 Java 类(库)用来当做参数,例如:网络连接地址 URL、文件路径 path、还有反射机制所需要的 String 参数等, 假若 String 不是固定不变的,将会引起各种安全隐患
不可变对象指对象一旦被创建,状态就不能再改变,任何修改都会创建一个新的对象,如 String、Integer及其它包装类.不可变对象最大的好处是线程安全.
String 字符串修改实现的原理?
当用 String 类型来对字符串进行修改时,其实现方法是首先创建一个 StringBuilder,其次调用 StringBuilder 的 append() 方法,最后调用 StringBuilder 的 toString() 方法把结果返回。
String str = “i” 和 String str = new String(“i”) 一样吗?
不一样,因为内存的分配方式不一样。String str = “i” 的方式,Java 虚拟机会将其分配到常量池中。
String str = new String(“i”) 则会被分到堆内存中。
public class StringTest { public static void main(String[] args) {String str1 = "abc";String str2 = "abc";String str3 = new String("abc");String str4 = new String("abc");System.out.println(str1 == str2); // trueSystem.out.println(str1 == str3); // falseSystem.out.println(str3 == str4); // falseSystem.out.println(str3.equals(str4)); // true}
}在执行 String str1 = “abc” 的时候,JVM 会首先检查字符串常量池中是否已经存在该字符串对象,如果已经存在,那么就不会再创建了,直接返回该字符串在字符串常量池中的内存地址;如果该字符串还不存在字符串常量池中,那么就会在字符串常量池中创建该字符串对象,然后再返回。所以在执行 String str2 = “abc” 的时候,因为字符串常量池中已经存在“abc”字符串对象了,就不会在字符串常量池中再次创建了,所以栈内存中 str1 和 str2 的内存地址都是指向 “abc” 在字符串常量池中的位置,所以 str1 = str2 的运行结果为 true
而在执行 String str3 = new String(“abc”) 的时候,JVM 会首先检查字符串常量池中是否已经存在“abc”字符串,如果已经存在,则不会在字符串常量池中再创建了;如果不存在,则就会在字符串常量池中创建 “abc” 字符串对象,然后再到堆内存中再创建一份字符串对象
String类的常用方法都有哪些?
- indexOf():返回指定字符的索引
- charAt():返回指定索引处的字符
- replace():字符串替换
- trim():去除字符串两端空白
- split():分割字符串,返回一个分割后的字符串数组
- length():返回字符串长度
- substring():截取字符串
- equals():字符串比较
String 有哪些特性?
- 不变性
- 常量池优化:String 对象创建之后,会在字符串常量池中进行缓存,如果下次创建同样的对象时,会直接返回缓存的引用
- final:使用 final 来定义 String 类,表示 String 类不能被继承,提高了系统的安全性
在使用HashMap的时候,用 String 做 key 有什么好处?
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
1.5、==和equals方法的区别
- ==:如果是基本数据类型,比较是值,如果是引用类型,比较的是引用地址
- equals:具体看各个类重写equals方法的比较逻辑,比如String类,虽然是引用类型,但是String类中重写了equals方法,方法内部比较的是字符串中的各个字符是否全部相等。
1.6、重载和重写的区别
- 重载:方法重载发生在同一个类中,方法名称必须相同,参数类型不同、个数不同、顺序不同也是方法重载,方法返回值和访问修饰符可以不同,如果只是方法返回值不同就不是重载,在编译时就会报错。
- 重写:方法重写发生在父子类中,子类重写父类的方法,方法名称、参数列表必须相同
- 返回值范围 ≤ 父类返回值范围
- 抛出异常范围 ≤ 父类抛出异常范围
- 访问修饰符范围 ≥ 父类访问修饰符范围
- 如果父类方法访问修饰符为 private ,则子类就不能重写该方法(子类不能重写父类的私有方法)
public int add(int a,String b)
public String add(int a,String b)
// 上方不是重载,重载与返回值和访问修饰符无关,只看方法名称和参数
构造器是否可被重写?
构造器不能被继承,因此不能被重写,但可以被重载。每一个类必须有自己的构造函数,负责构造自己这部分的构造。子类不会覆盖父类的构造函数,相反必须一开始调用父类的构造函数。
1.7、List和Set的区别
- List:有序,可重复,按对象插入的顺序保存对象,允许多个Null元素对象。可以使用迭代器 Iterator 取出所有元素,再逐一遍历各个元素。或者使用 get(int index) 方法获取指定下标的元素。
- Set:无序,不可重复。最多只允许一个 NULL 元素对象,取元素只能用迭代器 Iterator 取得所有元素,再逐一遍历各个元素。
1.8、ArrayList和LinkedList的区别
- 首先,他们的底层数据结构不同,ArrayList底层是基于数组实现的,LinkedList底层是基于链表实现的
- ArrayList更适合随机查找,LinkedList更适合删除和添加(不要下意识地认为
LinkedList作为链表就最适合元素增删的场景,LinkedList仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的时间复杂度都是 O(n) ) - ArrayList和LinkedList都实现了List接口,但是LinkedList还额外实现了Deque接口,所以LinkedList还可以当做队列来使用
- 两个都不保证线程安全。
- 我们在项目中一般是不会使用到
LinkedList的,需要用到LinkedList的场景几乎都可以使用ArrayList来代替,并且,性能通常会更好!就连LinkedList的作者都说他自己几乎从来不会使用LinkedList
1.9、ArrayList的优缺点?
ArrayList的优点如下:
- ArrayList 底层以数组实现,ArrayList 实现了 RandomAccess 接口,根据索引进行随机访问的时候速度非常快。
- ArrayList 在尾部添加一个元素的时候非常方便。
ArrayList 的缺点如下:
- 在非尾部的增加和删除操作,影响数组内的其他数据的下标,需要进行数据搬移,比较消耗性能
ArrayList 比较适合顺序添加、随机访问的场景。
1.10、Array和ArrayList有何区别?什么时候更适合用Array?
- Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型
- Array 大小是固定的,ArrayList 的大小是动态变化的
- ArrayList 提供了更多的方法和特性,比如:addAll(),removeAll(),iterator() 等等
1.11、遍历一个List有哪些不同的方式?
遍历方式有以下几种:
- for 循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后停止
- 迭代器遍历,Iterator。Iterator 是面向对象的一个设计模式,目的是屏蔽不同数据集合的差异,提供统一遍历集合的接口。Java 在 Collections 集合都支持了 Iterator 遍历
- foreach 循环遍历。foreach 内部也是采用了 Iterator 的方式实现,使用时不需要显式声明 Iterator 或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中不能对集合进行增删操作
Java Collections 框架中提供了一个 RandomAccess 接口,用来标记 List 实现是否支持 Random Access。
- 如果一个数据集合实现了该接口,最好使用for 循环遍历
- 如果没有实现该接口,则推荐使用 Iterator 或 foreach 遍历。
1.12、ArrayList的扩容机制
ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。默认情况下,新的容量会是原容量的1.5倍。
1.13、ConcurrentHashMap的实现原理是什么?
先来看下JDK1.7:
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
如下图所示,首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一段数据时,其他段的数据也能被其他线程访问,实现了真正的并发访问。

Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。Segment 默认为 16,也就是并发度为 16。
再来看下JDK1.8:
在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加细粒度的锁。
将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点(红黑树的根节点),就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。

1.14、JDK1.8 中为什么使用内置锁 synchronized替换 可重入锁 ReentrantLock?
- 在 JDK1.6 中,对 synchronized 锁的实现引入了大量的优化,并且 synchronized 有多种锁状态,会从无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁一步步转换
- 减少内存开销 。假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承 AQS 来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。
1.15、ConcurrentHashMap的扩容机制
1.7版本
- 1.7版本的ConcurrentHashMap是基于Segment分段实现的
- 每个Segment相对于一个小型的HashMap
- 每个Segment内部会进行扩容,和HashMap的扩容逻辑类似
- 先生成新的数组,然后转移元素到新数组中
- 扩容的判断也是每个Segment内部单独判断的,判断是否超过阈值
1.8版本
- 1.8版本的ConcurrentHashMap不再基于Segment实现
- 当某个线程进行put时,如果发现ConcurrentHashMap正在进行扩容那么该线程一起进行扩容
- 如果某个线程put时,发现没有正在进行扩容,则将key-value添加到ConcurrentHashMap中,然后判断是否超过阈值,超过了则进行扩容
- ConcurrentHashMap是支持多个线程同时扩容的
- 扩容之前也先生成一个新的数组
- 在转移元素时,先将原数组分组,将每组分给不同的线程来进行元素的转移,每个线程负责一组或多组的元素转移工作
1.16、HashMap 与 ConcurrentHashMap 的区别是什么?
- HashMap 不是线程安全的,而 ConcurrentHashMap 是线程安全的。
- ConcurrentHashMap 采用锁分段技术,将整个Hash桶进行了分段segment,也就是将这个大的数组分成了几个小的片段 segment,而且每个小的片段 segment 上面都有锁存在,那么在插入元素的时候就需要先找到应该插入到哪一个片段 segment,然后再在这个片段上面进行插入,而且这里还需要获取 segment 锁,这样做明显减小了锁的粒度。
1.17、JDK1.7和JDK1.8的ConcurrentHashMap实现有什么不同
- 线程安全实现方式 :JDK 1.7 采用
Segment分段锁来保证安全,Segment是继承自ReentrantLock。JDK1.8 放弃了Segment分段锁的设计,采用Node + CAS + synchronized保证线程安全,锁粒度更细,synchronized只锁定当前链表或红黑二叉树的首节点 - Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)
- 并发度 :JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
1.18、ConcurrentHashMap的put方法执行逻辑是什么
先来看JDK1.7:
首先,会尝试获取锁,如果获取失败,利用自旋获取锁;如果自旋重试的次数超过 64 次,则改为阻塞获取锁
获取到锁后:
- 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
- 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
- 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
- 释放 Segment 的锁。
再来看JDK1.8:
- 根据 key 计算出 hash值。
- 判断是否需要进行初始化。
- 定位到 Node,拿到首节点 f,判断首节点 f:
- 如果为 null ,则通过cas的方式尝试添加。
- 如果为
f.hash = MOVED = -1,说明其他线程在扩容,参与一起扩容。 - 如果都不满足 ,synchronized 锁住 f 节点,判断是链表还是红黑树,遍历插入。
- 当在链表长度达到8的时候,数组扩容或者将链表转换为红黑树。
1.19、ConcurrentHashMap的get方法执行逻辑是什么
先来看JDK1.7:
首先,根据 key 计算出 hash 值定位到具体的 Segment ,再根据 hash 值获取定位 HashEntry 对象,并对 HashEntry 对象进行链表遍历,找到对应元素。
由于 HashEntry 涉及到的共享变量都使用 volatile 修饰,volatile 可以保证内存可见性,所以每次获取时都是最新值。
再来看JDK1.8:
- 根据 key 计算出 hash 值,判断数组是否为空;
- 如果是首节点,就直接返回;
- 如果是红黑树结构,就从红黑树里面查询;
- 如果是链表结构,循环遍历判断。
1.20、ConcurrentHashMap 的 get 方法是否要加锁,为什么?
get 方法不需要加锁。因为 Node 的元素 value 和指针 next 是用 volatile 修饰的,在多线程环境下线程A修改节点的 value 或者新增节点的时候是对线程B可见的。这也是它比其他并发集合比如 Hashtable、HashMap效率高的原因。
1.21、get 方法不需要加锁与 volatile 修饰的哈希桶数组有关吗?
没有关系。哈希桶数组table用 volatile 修饰主要是保证在数组扩容的时候保证可见性
1.22、ConcurrentHashMap 不支持 key 或者 value 为 null 的原因?
我们先来说value 为什么不能为 null。因为 ConcurrentHashMap 是用于多线程的 ,如果ConcurrentHashMap.get(key)得到了 null ,这就无法判断,是映射的value是 null ,还是没有找到对应的key而为 null ,就有了二义性。
而用于单线程状态的 HashMap 却可以用containsKey(key) 去判断到底是否包含了这个 null 。
1.23、ConcurrentHashMap 和 Hashtable 的效率哪个更高?为什么?
ConcurrentHashMap 的效率要高于 Hashtable,因为 Hashtable 给整个哈希表加了一把大锁从而实现线程安全。而ConcurrentHashMap 的锁粒度更低,在 JDK1.7 中采用分段锁实现线程安全,在 JDK1.8 中采用CAS+synchronized实现线程安全。
1.24、具体说一下Hashtable的锁机制
Hashtable 是使用 synchronized来实现线程安全的,给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞等待需要的锁被释放,在竞争激烈的多线程场景中性能就会非常差!
1.25、jdk1.7到jdk1.8HashMap发生了什么变化
- jdk1.7中底层是数组+链表,jdk1.8中底层是数组+链表+红黑树,加红黑树的目的是提高HashMap插入和查询整体效率
- jdk1.7链表插入使用的是头插法,jdk1.8中链表插入使用的是尾插法,因为jdk1.8中插入 key 和 value 时需要判断链表元素个数,当链表个数达到8个,需要将链表转化为红黑树,所以每次插入都需要遍历统计链表中元素个数,所以正好直接使用尾插法
- jdk1.7中哈希算法比较复杂,存在各种右移与异或运算,jdk1.8中进行了简化,jdk1.8中新增了红黑树,所以可以适当的简化哈希算法,节省CPU资源
1.26、解决hash冲突的办法有哪些?HashMap用的哪种?
解决Hash冲突方法有:开放定址法、再哈希法、链地址法(拉链法)。HashMap中采用的是 链地址法 :将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
1.27、为什么在解决hash冲突的时候,不直接用红黑树?而选择先用链表,再转为红黑树?
因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。当元素小于 8 个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于 8 个的时候, 红黑树搜索时间复杂度是 O(logn),而链表是 O(n),此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
不用红黑树,用二叉查找树可以吗?
可以。但是二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢。
1.28、HashMap默认加载因子是多少?为什么是0.75
0.75是对空间和时间效率的一个平衡选择,一般不要修改,除非在时间和空间比较特殊的情况下 :
- 如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值
- 相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1
1.29、HashMap的Put方法
HashMap的Put方法的流程:
- 根据 put 进来的 key 通过哈希算法得出数组下标
- 如果数组下标位置元素为空,则直接将 key 和 value 封装为 Entry 对象(jdk1.7中是 Entry 对象,jdk1.8中是 Node 对象),并将对象放入该位置
- 如果数组下标位置元素不为空,则要分情况讨论:
- 如果是jdk1.7,则先判断是否需要扩容 HashMap,如果要扩容就扩容,如果不用扩容就生成 Entry 对象,并使用头插法将对象插入到当前位置的链表中
- 如果是jdk1.8,则会先判断当前位置上的 Node 类型,看是红黑树的 Node,还是链表的 Node
- 如果是红黑树的 Node,则将 key 和 value 封装为一个红黑树结点并添加到红黑树中去
- 如果是链表的 Node,则将 key 和 value 封装为一个链表 Node 并通过 尾插法插入到链表的最后位置,因为是尾插法,所以需要遍历链表,当发现链表结点个数大于等于8,那么就会将该链表转成红黑树
- 将 key 和 value 封装为 Node 插入到链表或者红黑树中后,再判断是否需要进行扩容,如果需要就扩容,如果不需要就结束 put 方法。
jdk1.7是先判断需要需要扩容,再进行插入。jdk1.8是先插入,然后再判断是否需要扩容
1.30、HashMap为什么线程不安全
- 多线程下扩容死循环。JDK1.7中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表的问题。
- 多线程的put可能导致元素的丢失。多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在JDK 1.7和 JDK 1.8 中都存在。
- put和get并发时,可能导致get为null。线程1执行put时,因为元素个数超出threshold而导致rehash,线程2此时执行get,有可能导致这个问题。此问题在JDK 1.7和 JDK 1.8 中都存在。
1.31、深拷贝和浅拷贝
java当中的克隆跟生物上所说的克隆类似,就是复制出一个一模一样的个体,当然迁移到java当中,那就是复制出一个一模一样对象。
克隆的作用:对象克隆主要是为了解决引用类型在进行等号赋值时使得两个引用同时指向同一个对象实例,从而导致通过两个引用去操作对象时,会直接更改实例中的属性破坏对象的相互独立性
//例如一下代码段
public class Test {public static void main(String[] args) {// TODO Student s1 = new Student("Tom", 12);Student s2 = s1;//s2的引用指向s1System.out.println(s1); // name = Tom,age = 12System.out.println(s2); // name = Tom,age = 12s2.setName("Jerry");//修改s2的值时s1的属性System.out.println(s1); // name = Jerry,age = 12System.out.println(s2); // name = Jerry,age = 12}
由上述运行结果可知,在引用类型当中,由于都是指向同一个对象实例,当我们用引用类型去修改对象实例的值时,原来对象的属性也会跟着改变,从而导致了数据的不一致性。对象的克隆就能解决上述问题,防止发生此类情况。
- 浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址,也就是在进行修改的时候同样会修改原来的属性
- 深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。深度克隆就是把对象的所有属性都统统复制一份新的到目标对象里面去,使他成为一个独立的对象,当修改新的对象实例的属性时,原来对象中的属性任然不变。
- 基本数据类型就是 int、double等,实例对象就是 User 类、 Student类等
如何实现对象的克隆?
浅克隆:实现 Cloneable 接口并重写 clone() 方法(浅克隆)
//实现Cloneable接口
public class Product implements Cloneable{private String name;private Integer price;public String getName() {return name;} public void setName(String name) {this.name = name;}public Integer getPrice() {return price;}public void setPrice(Integer price) {this.price = price;}public Product(String name, Integer price) {super();this.name = name;this.price = price;}@Overridepublic String toString() {return "Product [name=" + name + ", price=" + price + "]";}//重写clone的方法@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}
}
测试:
public class Test {public static void main(String[] args) {// TODO 对象的克隆Product product1 = new Product("篮球", 189);// 1.在Product实现CoCloneable接口// 2.重写clone方法Product product2 = product1.clone();System.out.println(product2);product2.setPrice(200);//篮球涨价了System.out.println(product1);//此时修改product2不会影响product1的值System.out.println(product2);}
}
深克隆:实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深克隆
1.32、HashMap的扩容机制
HashMap 在容量超过负载因子所定义的容量之后,就会扩容。Java 里的数组是无法自动扩容的,方法是将 HashMap 的大小扩大为原来数组的两倍,并将原来的对象放入新的数组中。
jdk1.7版本:
- 先生成新数组
- 遍历老数组中的每个位置上的链表上的每个元素
- 取每个元素的key,计算出每个元素在新数组中的下标
- 将元素添加到新数组中去
- 所有元素转移完了之后,将新数组赋值给HashMap对象的table属性
jdk1.8版本:
- 先生成新数组
- 遍历老数组中的每个位置上的链表或红黑树
- 如果是链表,则直接将链表中的每个元素重新计算下标,并添加到新数组中去
- 如果是红黑树,则先遍历红黑树,先计算出红黑树中每个元素对应在新数组中的下标位置
- 统计每个下标位置的元素个数
- 如果该位置下的元素个数超过了8,则生成一个新的红黑树,并将根节点添加到新数组的对应位置
- 如果该位置下的元素个数没有超过8,则生成一个链表,并将链表的头节点添加到新数组的对应位置
- 所有元素转移完了之后,将新数组赋值给HashMap对象的table属性
1.33、Java中的异常体系是怎样的
-
Java中的所有异常都来自顶级父类Throwable。Throwable下有两个子类Exception和Error。
-
Error表示非常严重的错误,比如java.lang.StackOverFlowError 栈溢出和Java.lang.OutOfMemoryError 内存溢出,通常这些错误出现时,仅仅想靠程序自己是解决不了的,可能是虚拟机、磁盘、操作系统层面出现的问题了,所以通常也不建议在代码中去捕获这些Error,因为捕获的意义不大,因为程序可能已经根本运行不了了。
-
Exception表示异常,表示程序出现Exception时,是可以靠程序自己来解决的,比如NullPointerException空指针异常IllegalAccessException违法访问异常等,我们可以捕获这些异常来做特殊处理。
-
Exception的子类通常又可以分为RuntimeException运行时异常和非RuntimeException非运行时异常两类
- RunTimeException表示运行期异常,表示这个异常是在代码运行过程中抛出的,这些异常在写代码时可能发现不了。比如NullPointerException空指针异常、IndexOutOfBoundsException数组下标越界异常等。
- 非RuntimeException表示非运行期异常,比如 IO异常、SQL异常,是编译器认为这块读文件可能会读不到
- 二者区别:是否强制要求调用者必须处理此异常,如果强制要求调用者必须进行处理,那么就使用非运行时异常,否则就选择运行异常。
throw 和 throws 的区别
- throw:在方法体内部,表示抛出异常,由方法体内部的语句处理;throw 是具体向外抛出异常的动作,所以它抛出的是一个异常实例
- throws:在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理;表示出现异常的可能性,并不一定会发生这种异常。
1.34、什么时候应该抛出异常,什么时候捕获异常
异常相当于一种提示,如果我们抛出异常,就相当于告诉上层方法,我抛了一个异常,我处理不了这个异常,交给你来处理,而对于上层方法来说,它也需要决定自己能不能处理这个异常,是否也需要交给它的上层。
所以我们在写一个方法时,我们需要考虑的就是,本方法能否合理的处理该异常,如果处理不了就继续向上抛出异常,包括本方法中在调用另外一个方法时,发现出现了异常,如果这个异常应该由自己来处理,那就捕获该异常并进行处理。
本方法能处理异常则捕获异常,不能处理异常则向上抛出。
常见的异常类有哪些?
- NullPointerException:当应用程序试图访问空对象时,则抛出该异常。
- SQLException:提供关于数据库访问错误或其他错误信息的异常
- IndexOutOfBoundsException:指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出
- FileNotFoundException:当试图打开指定路径名表示的文件失败时,抛出此异常。
- OException:当发生某种 I/O 异常时,抛出此异常。此类是失败或中断的 I/O 操作生成的异常的通用类。
- ClassCastException:当试图将对象强制转换为不是实例的子类时,抛出该异常
- IllegalArgumentException:抛出的异常表明向方法传递了一个不合法或不正确的参数
主线程可以捕获到子线程的异常吗?
线程设计的理念:“线程的问题应该线程自己本身来解决,而不要委托到外部”。
正常情况下,如果不做特殊的处理,在主线程中是不能够捕获到子线程中的异常的。如果想要在主线程中捕获子线程的异常,我们可以用如下的方式进行处理,使用 Thread 的静态方法。
Thread.setDefaultUncaughtExceptionHandler(new MyUncaughtExceptionHandle());
1.35、了解ReentrantLock吗
ReetrantLock是一个可重入的独占锁,主要有两个特性,一个是支持公平锁和非公平锁,一个是可重入。
ReetrantLock实现依赖于AQS,ReetrantLock主要依靠AQS维护一个阻塞队列,多个线程对加锁时,失败则会进入阻塞队列。等待唤醒,重新尝试加锁。
1.36、ReentrantLock中tryLock()和lock()方法的区别
- lock() 方法是阻塞加锁,没有返回值,如果有线程在调用这个方法,如果线程没有加到锁,那么线程就会停在
reentrantLock.lock()这行代码,后续代码不会执行。直到这个线程获得锁之后,才会解阻塞 - tryLock() 是尝试加锁,不一定能加到,是非阻塞加锁,返回值是 Boolean
- 还有一种锁是很多框架都会用到的,是自旋锁,比较灵活,性能会很高,但是比较消耗CPU
public class Hello {static ReentrantLock reentrantLock = new ReentrantLock();public static void main(String[] args) {reentrantLock.lock(); // 阻塞加锁// 若没有加锁后续代码不会执行boolean result = reentrantLock.tryLock(); //尝试加锁,非阻塞加锁// 自旋锁while(!reentrantLock.tryLock()){// 其他事情}}
}
1.37、ReentrantLock中的公平锁和非公平锁的底层实现
首先不管是公平锁还是非公平锁,它们的底层实现都会使用 AQS 来进行排队,它们的区别在于:线程在使用 lock() 方法加锁时:
- 如果是公平锁,会先检查 AQS 队列中是否存在线程在排队,如果有线程在排队,则当前线程也进行排队
- 如果是非公丕锁,则不会去检查是否有线程在排队,而是直接竞争锁
不管是公平锁还是非公平锁,一旦没竞争到锁,都会进行排队,当锁释放时,都是唤醒排在最前面的线程,所以非公平锁只是体现在了线程加锁阶段,而没有体现在线程被唤醒阶段。
另外, ReentrantLock 是可重入锁(同一个线程不停的加锁都可以),不管是公平锁还是非公平锁都是可重入的。默认情况下我们 new ReentrantLock() 底层是非公平锁,因为非公平性能会更高。但是解锁时候也得不停解锁,加锁两次,解锁也得两次。
public class Hello {static ReentrantLock reentrantLock = new ReentrantLock();public static void main(String[] args) {reentrantLock.lock(); // 阻塞加锁reentrantLock.lock(); // 阻塞加锁reentrantLock.unlock();reentrantLock.unlock();}
}
1.38、ReadWriteLock是什么
首先ReentrantLock某些时候有局限,如果使用ReentrantLock,可能本身是为了防止线程A在写数据、线程B在读数据造成的数据不一致,但这样,如果线程C在读数据、线程D也在读数据,读数据是不会改变数据的,没有必要加锁,但是还是加锁了,降低了程序的性能。
因为这个,才诞生了读写锁ReadWriteLock。ReadWriteLock是一个读写锁接口,ReentrantReadWriteLock是ReadWriteLock接口的一个具体实现,实现了读写的分离,读锁是共享的,写锁是独占的,读和读之间不会互斥,读和写、写和读、写和写之间才会互斥,提升了读写的性能
1.39、Sychronized的偏向锁、轻量级锁、重量级锁
-
偏向锁:在锁对象的对象头中记录一下当前获取到该锁的线程ID,该线程下次如果又来获取该锁就可以直接获取到了。也就是这把锁偏向于这个线程,所以称为 偏向锁
-
轻量级锁:由偏向锁升级而来,当一个线程获取到锁后,此时这把锁是偏向锁,此时如果有第二个线程来竞争这把锁,偏向锁就会升级为轻量级锁,之所以叫轻量级锁,是为了和重量级锁区分,轻量级锁底层是通过自旋来实现的,并不会阻塞线程。如果自旋次数过多仍然没有获取到锁,则会升级为重量级锁,重量级锁会导致线程阻塞。
-
自旋锁:自旋锁就是线程在获取锁的过程中,不会去阻塞线程,也就无所谓唤醒线程,阻塞和唤醒这两个步骤都需要操作系统去进行的,比较消耗时间,自旋锁就是一直循环获取锁。
说一说自己对于 synchronized 关键字的了解
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized 关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。另外,在 Java 早期版本中,synchronized 属于重量级锁,效率低下,JDK6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
说说 jdk1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗?
说明:这道题答案有点长,但是回答的详细面试会很加分。
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,它们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
重量级锁
我们知道,我们要进入一个同步、线程安全的方法时,是需要先获得这个方法的锁的,退出这个方法时,则会释放锁。如果获取不到这个锁的话,意味着有别的线程在执行这个方法,这时我们就会马上进入阻塞的状态,等待那个持有锁的线程释放锁,然后再把我们从阻塞的状态唤醒,我们再去获取这个方法的锁。这种获取不到锁就马上进入阻塞状态的锁,我们称之为重量级锁。
-
自旋锁和自适应自旋锁
我们知道,线程从运行态进入阻塞态这个过程,是非常耗时的,因为不仅需要保存线程此时的执行状态,上下文等数据,还涉及到用户态到内核态的转换。当然,把线程从阻塞态唤醒也是一样,也是非常消耗时间的。
刚才我说线程拿不到锁,就会马上进入阻塞状态,然而现实是,它虽然这一刻拿不到锁,可能在下 0.0001 秒,就有其他线程把这个锁释放了。如果它慢0.0001秒来拿这个锁的话,可能就可以顺利拿到了,不需要经历阻塞/唤醒这个花时间的过程了。
然而重量级锁就是这么坑,它就是不肯等待一下,一拿不到就是要马上进入阻塞状态。为了解决这个问题,我们引入了另外一种愿意等待一段时间的锁 — 自旋锁。
自旋锁就是,如果此时拿不到锁,它不马上进入阻塞状态,而是等待一段时间,看看这段时间有没其他人把这锁给释放了。怎么等呢?这个就类似于线程在那里做空循环,如果循环一定的次数还拿不到锁,那么它才会进入阻塞的状态
至于是循环等待几次,这个是可以人为指定一个数字的。
上面我们说的自旋锁,每个线程循环等待的次数都是一样的,例如我设置为 100次的话,那么线程在空循环 100 次之后还没拿到锁,就会进入阻塞状态了。而自适应自旋锁就牛逼了,它不需要我们人为指定循环几次,它自己本身会进行判断要循环几次,而且每个线程可能循环的次数也是不一样的。而之所以这样做,主要是我们觉得,如果一个线程在不久前拿到过这个锁,或者它之前经常拿到过这个锁,那么我们认为它再次拿到锁的几率非常大,所以循环的次数会多一些。
而如果有些线程从来就没有拿到过这个锁,或者说,平时很少拿到,那么我们认为,它再次拿到的概率是比较小的,所以我们就让它循环的次数少一些。因为你在那里做空循环是很消耗 CPU 的。
所以这种能够根据线程最近获得锁的状态来调整循环次数的自旋锁,我们称之为自适应自旋锁。
-
轻量级锁
上面我们介绍的三种锁:重量级、自旋锁和自适应自旋锁,他们都有一个特点,就是进入一个方法的时候,就会加上锁,退出一个方法的时候,也就释放对应的锁。
轻量级锁认为,当你在方法里面执行的时候,其实是很少刚好有人也来执行这个方法的,所以,当我们进入一个方法的时候根本就不用加锁,我们只需要做一个标记就可以了,也就是说,我们可以用一个变量来记录此时该方法是否有人在执行。也就是说,如果这个方法没人在执行,当我们进入这个方法的时候,采用CAS机制,把这个方法的状态标记为已经有人在执行,退出这个方法时,在把这个状态改为了没有人在执行了。
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(JDK1.6 之后加入的)。轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了 CAS 操作。
如果没有竞争,轻量级锁使用 CAS 操作避免了使用互斥操作的开销。但如果存在锁竞争,除了互斥量开销外,还会额外发生 CAS 操作,因此在有锁竞争的情况下,轻量级锁比传统的重量级锁更慢!如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁!所以轻量级锁适合用在那种,很少出现多个线程竞争一个锁的情况,也就是说,适合那种多个线程总是错开时间来获取锁的情况。
-
偏向锁:
偏向锁就更加牛逼了,我们已经觉得轻量级锁已经够轻,然而偏向锁更加省事,偏向锁认为,你轻量级锁每次进入一个方法都需要用CAS来改变状态,退出也需要改变,多麻烦。
偏向锁进入一个方法的时候是这样处理的:如果这个方法没有人进来过,那么一个线程首次进入这个方法的时候,会采用CAS机制,把这个方法标记为有人在执行了,和轻量级锁加锁有点类似,并且也会把该线程的 ID 也记录进去,相当于记录了哪个线程在执行。
然后,但这个线程退出这个方法的时候,它不会改变这个方法的状态,而是直接退出来,懒的去改,因为它认为除了自己这个线程之外,其他线程并不会来执行这个方法。
然后当这个线程想要再次进入这个方法的时候,会判断一下这个方法的状态,如果这个方法已经被标记为有人在执行了,并且线程的ID是自己,那么它就直接进入这个方法执行,啥也不用做
你看,多方便,第一次进入需要CAS机制来设置,以后进出就啥也不用干了,直接进入退出。
然而,现实总是残酷的,毕竟实际情况还是多线程,所以万一有其他线程来进入这个方法呢?如果真的出现这种情况,其他线程一看这个方法的ID不是自己,这个时候说明,至少有两个线程要来执行这个方法论,这意味着偏向锁已经不适用了,这个时候就会从偏向锁升级为轻量级锁。所以呢,偏向锁适用于那种,始终只有一个线程在执行一个方法的情况哦。
但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
好文推荐:https://mp.weixin.qq.com/s/9zRmjH5Bgzo-EDIzZ5C7Hg
最开始我们说的三种锁,重量级锁、自旋锁和自适应自旋锁,进入方法之前,就一定要先加一个锁,这种我们为称之为悲观锁。悲观锁总认为,如果不事先加锁的话,就会出事,这种想法确实悲观了点,这估计就是悲观锁的来源了。
而乐观锁却相反,认为不加锁也没事,我们可以先不加锁,如果出现了冲突,我们在想办法解决,例如 CAS 机制,上面说的轻量级锁,就是乐观锁的。不会马上加锁,而是等待真的出现了冲突,在想办法解决。
1.40、synchronized为什么是非公平锁?非公平体现在哪些地方
synchronized 的非公平其实在源码中应该有不少地方,因为设计者就没按公平锁来设计,核心有以下几个点:
-
当持有锁的线程释放锁时,该线程会执行以下两个重要操作
- 先将锁的持有者 owner 属性赋值为 null
- 唤醒等待链表中的一个线程
-
当线程尝试获取锁失败,进入阻塞时,放入链表的顺序,和最终被唤醒的顺序是不一致的,也就是说你先进入链表,不代表你就会先被唤醒
1.41、Sychronized和ReentrantLock的区别
- sychronized是一个关键字,ReentrantLock是一个类。这是二者的本质区别。
- synchronized 依赖于 JVM 而 ReenTrantLock 依赖于 API。sychronized会自动的加锁与释放锁,ReentrantLock需要程序员手动加锁与释放锁(也就是 API 层面,需要 lock() 和 unlock 方法配合 try/finally 语句块来完成)
- ReentrantLock 比 synchronized 增加了一些高级功能
- 等待可中断:也就是说正在等待的线程可以选择放弃等待,改为处理其他事情
- ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。 ReentrantLock默认情况是非公平的
1.42、谈谈你对AQS的理解,AQS如何实现可重入锁
- AQS是一个JAVA线程同步的框架。是JDK中很多锁工具的核心实现框架。AQS是同步队列
- 在AQS中,维护了一个信号量state和一个线程组成的双向链表队列。其中,这个线程队列,就是用来给线程排队的,而state就像是一个红绿灯,用来控制线程排队或者放行的。 在不同的场景下,有不用的意义。
- 在可重入锁这个场景下,state就用来表示加锁的次数。0标识没有线程加锁,每加一次锁,state就加1。释放锁state就减1。
1.43、什么是泛型?有什么作用
**泛型就是将类型参数化,其在编译时才确定具体的参数。**这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。使用泛型参数,可以增强代码的可读性以及稳定性。
ArrayList<Persion> persons = new ArrayList<Persion>();
// 这行代码就指明了该 ArrayList对象只能传入 Persion 对象
使用泛型的好处有以下几点:
- 类型安全:译时期就可以检查出因 Java 类型不正确导致的异常,符合越早出错代价越小原则
- 消除强制类型转换:使用时直接得到目标类型,消除许多强制类型转换
- 性能收益:所有工作都在编译器中完成,支持泛型(几乎)不需要 JVM 或类文件更改
1.44、泛型的使用方式有哪几种
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
- 泛型类
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{private T key;public Generic(T key) {this.key = key;}public T getKey(){return key;}
}如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);
- 泛型接口
public interface Generator<T> {public T method();
}
实现泛型接口,不指定类型:
class GeneratorImpl<T> implements Generator<T>{@Overridepublic T method() {return null;}
}
实现泛型接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{@Overridepublic String method() {return "hello";}
}
- 泛型方法
public static < E > void printArray( E[] inputArray )
{for ( E element : inputArray ){System.out.printf( "%s ", element );}System.out.println();
}
使用:
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray(intArray);
printArray(stringArray);
注意: public static < E > void printArray( E[] inputArray ) 一般被称为静态泛型方法,在 java 中泛型只是一个占位符,必须在传递类型后才能使用。
类在实例化时才能真正的传递类型参数,由于静态方法的加载先于类的实例化,就是说类中的泛型还没有传递真正的类型参数,静态的方法的加载就已经完成了,所以静态泛型方法是没有办法使用类上声明的泛型的。只能使用自己声明的 <E>
1.45、Java泛型的原理是什么?什么是类型擦除
泛型是一种语法糖,泛型这种语法糖的基本原理是类型擦除。也就是说:**泛型只存在于编译阶段,而不存在于运行阶段。**在编译后的 class 文件中,是没有泛型这个概念的。
类型擦除:使用泛型的时候加上的类型参数,编译器在编译的时候去掉类型参数。
public class Caculate<T> {private T num;
}// 反编译一下上面的 Caculate 类
public class Caculate{public Caculate(){}private Object num;
}
发现编译器擦除 Caculate 类后面的两个尖括号,并且将 num 的类型定义为 Object 类型。大部分情况下,泛型类型都会以 Object 进行替换,而有一种情况则不是。那就是使用到了extends和super语法的有界类型
public class Caculate<T extends String> {private T num;
}
这种情况的泛型类型,num 会被替换为 String 而不再是 Object。它限定 T 是 String 或者 String 的子类
1.46、什么是泛型中的限定通配符和非限定通配符
有两种限定通配符:
- <? extends T> 表示包括T在内的任何T的子类来设定类型的上界
- <? super T> 表示包括T在内的任何T的父类来设定类型的下界(很少用)
public class People<E extends Number> {}
? 表示非限定通配符,因为 ? 可以用任意类型来替代
例如 List< ? extends Number > 可以接受 List< Integer > 或 List< Float > 。
1.47、Array中可以用泛型吗
不可以。因为 List 可以提供编译期的类型安全保证,而 Array 却不能。
1.48、项目中哪里用到了泛型
- 自定义接口通用返回结果
CommonResult<T>通过参数T可根据具体的返回类型动态指定结果的数据类型 - 构建集合工具类
1.49、反射
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。反射的核心思想和关键就是得到:编译后的class文件对象。
像是使用 Spring 的时候,一个@Component注解就声明了一个类为 Spring Bean ,通过一个 @Value注解就读取到配置文件中的值,这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
- Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段
- Method :可以使用 invoke() 方法调用与 Method 对象关联的方法
- Constructor :可以用 Constructor 创建新的对象
应用举例:工厂模式,使用反射机制,根据全限定类名获得某个类的 Class 实例
反射的优缺点:
- 优点:运行期类型的判断,class.forName() 动态加载类,提高代码的灵活度
- 缺点:反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。由于反射允许代码执行一些在正常情况下不被允许的操作(比如:访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。
1.50、如何获取反射中的Class对象
-
Class.forName(“类的路径”);当你知道该类的全路径名时,你可以使用该方法获取 Class 类对象
Class clz = Class.forName("java.lang.String"); -
类名.class。这种方法只适合在编译前就知道操作的 Class。
Class clz = String.class; -
对象名.getClass()
String str = new String("Hello"); Class clz = str.getClass(); -
如果是基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象
1.51、Java反射API有几类?
反射 API 用来生成 JVM 中的类、接口或则对象的信息
- Class 类:反射的核心类,可以获取类的属性,方法等信息
- Field 类:表示类的成员变量,可以用来获取和设置类之中的属性值
- Method 类:表示类的方法,它可以用来获取类中的方法信息或者执行方法
- Constructor 类:表示类的构造方法
反射的使用步骤?
- 获取想要操作的类的Class对象,这是反射的核心,通过Class对象我们可以任意调用类的方法
- 调用 Class 类中的方法,即就是反射的使用阶段
- 使用反射 API 来操作这些信息
1.52、反射机制的应用有哪些?
Oracle 希望开发者将反射作为一个工具,用来帮助程序员实现本不可能实现的功能。举两个最常见使用反射的例子,来说明反射机制的强大之处:
第一种:JDBC 的数据库的连接:在JDBC 的操作中,如果要想进行数据库的连接,则必须按照以下的几步完成
- 通过Class.forName()加载数据库的驱动程序
- 通过 DriverManager 类进行数据库的连接,连接的时候要输入数据库的连接地址、用户名、密码
- 通过Connection 接口接收连接
第二种:Spring 框架的使用,最经典的就是xml的配置模式
Spring 通过 XML 配置模式装载 Bean 的过程:
- 将程序内所有 XML 或 Properties 配置文件加载入内存中
- Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息
- 使用反射机制,根据这个字符串获得某个类的Class实例
- 动态配置实例的属性
Spring这样做的好处是:
- 不用每一次都要在代码里面去new或者做其他的事情;
- 以后要改的话直接改配置文件,代码维护起来就很方便了;
- 有时为了适应某些需求,Java类里面不一定能直接调用另外的方法,可以通过反射机制来实现。
1.53、什么是注解?
注解 Annotation 可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。注解本质是一个继承了Annotation 的特殊接口,JDK 提供了很多内置的注解(比如 @Override 、@Deprecated),同时,我们还可以自定义注解。
1.54、注解的解析方法有哪几种
注解只有被解析之后才会生效,常见的解析方法有两种:
- 编译期直接扫描 :编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 - 运行期通过反射处理 :像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的
1.55、序列化和反序列化
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
- 序列化: 将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
下面是序列化和反序列化常见应用场景:
-
对象在进行网络传输之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化
-
将对象存储到文件之前需要进行序列化,将对象从文件中读取出来需要进行反序列化
-
将对象存储到数据库(如 Redis)之前需要用到序列化,将对象从缓存数据库中读取出来需要反序列化
-
将对象存储到内存之前需要进行序列化,从内存中读取出来之后需要进行反序列化
序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。

OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。所以序列化协议对应于 TCP/IP 模型的表示层。
序列化的实现:需要被序列化的类实现 Serializable 接口,用于标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个 ObjectOutputStream 对象,接着使用 ObjectOutputStream 对象的 writeObject(Object obj) 方法可以将参数为 obj 的对象写出,要恢复的话则使用输入流构造一个 ObjectInputStream 对象,接着使用 ObjectInputStream 对象的 readObject () 方法读取对象。
1.56、如果有些字段不想进行序列化怎么办
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化
1.57、为什么不推荐使用JDK自带的序列化
- 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了
- 性能差 :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大
- 存在安全问题 :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
1.58、静态变量会被序列化吗
不会。因为序列化是针对对象而言的, 而静态变量优先于对象存在, 随着类的加载而加载, 所以不会被序列化.
的对象之后需要再进行反序列化
-
将对象存储到文件之前需要进行序列化,将对象从文件中读取出来需要进行反序列化
-
将对象存储到数据库(如 Redis)之前需要用到序列化,将对象从缓存数据库中读取出来需要反序列化
-
将对象存储到内存之前需要进行序列化,从内存中读取出来之后需要进行反序列化
序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。所以序列化协议对应于 TCP/IP 模型的表示层。
序列化的实现:需要被序列化的类实现 Serializable 接口,用于标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个 ObjectOutputStream 对象,接着使用 ObjectOutputStream 对象的 writeObject(Object obj) 方法可以将参数为 obj 的对象写出,要恢复的话则使用输入流构造一个 ObjectInputStream 对象,接着使用 ObjectInputStream 对象的 readObject () 方法读取对象。
1.56、如果有些字段不想进行序列化怎么办
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化
1.57、为什么不推荐使用JDK自带的序列化
- 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了
- 性能差 :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大
- 存在安全问题 :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
1.58、静态变量会被序列化吗
不会。因为序列化是针对对象而言的, 而静态变量优先于对象存在, 随着类的加载而加载, 所以不会被序列化.
相关文章:
【巨人的肩膀】JAVA面试总结(二)
1、💪 目录1、💪1.0、什么是面向对象1.1、JDK、JRE、JVM之间的区别1.2、什么是字节码1.3、hashCode()与equals()之间的联系1.4、String、StringBuffer、StringBuilder的区别1.5、和equals方法的区别1.6、重载和重写的区别1.7、List和Set的区别1.8、Array…...

【网络安全入门】零基础小白必看!!!
看到很多小伙伴都想学习 网络安全 ,让自己掌握更多的 技能,但是学习兴趣有了,却发现自己不知道哪里有 学习资源◇瞬间兴致全无!◇ 😄在线找人要资料太卑微,自己上网下载又发现要收费0 🙃差点当…...
)
字节前端经典面试题(附答案)
有哪些可能引起前端安全的问题? 跨站脚本 (Cross-Site Scripting, XSS): ⼀种代码注⼊⽅式, 为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简…...
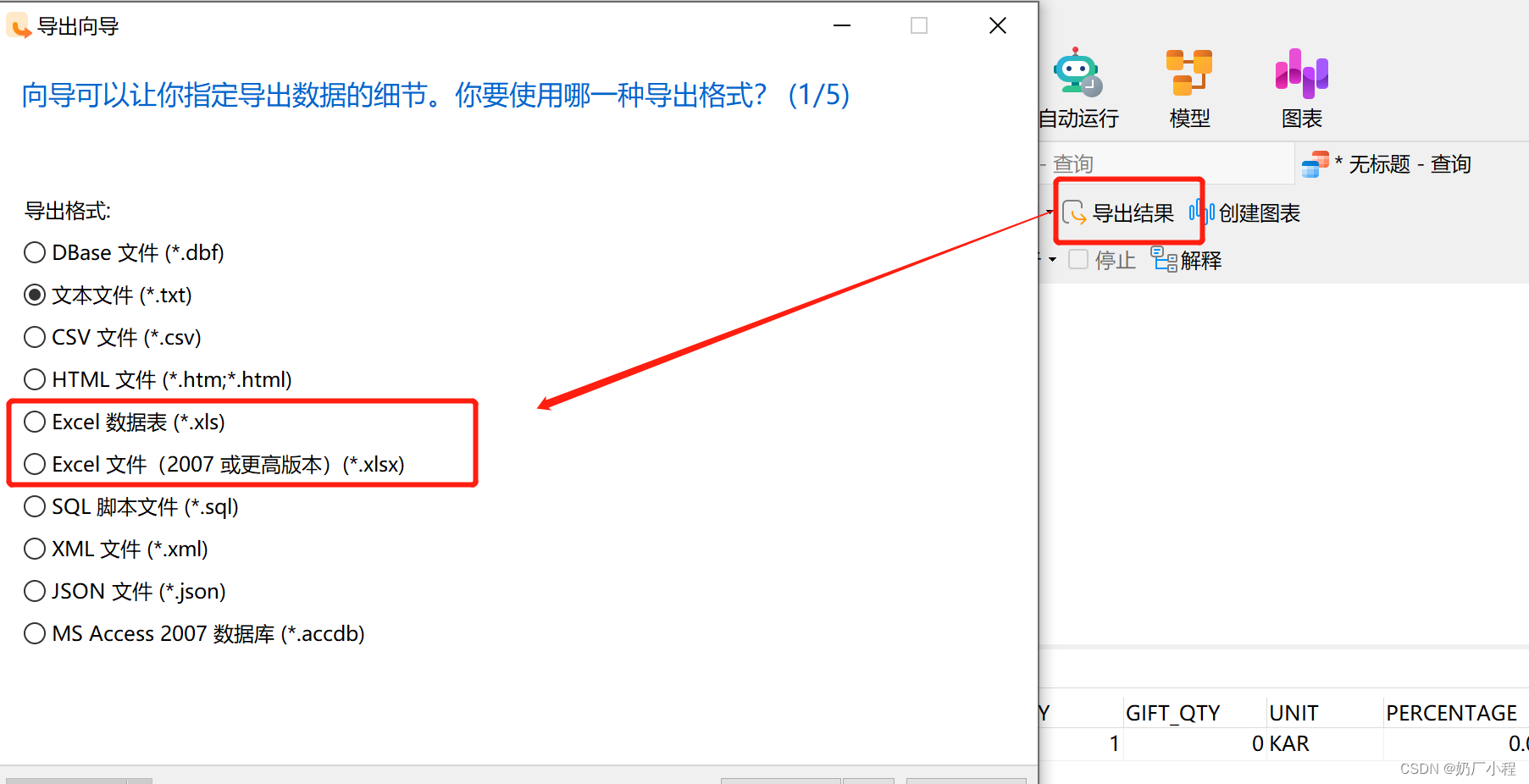
数据库管理工具的使用
目录 摘要 一、Navicat是什么? 二、使用步骤 1.如何下载与安装 2.如何连接远程数据库 总结 摘要 本文主要介绍数据库管理工具的使用 一、Navicat是什么? 它是一款数据库管理工具,将此工具连接数据库,你可以从中看到各种数据库的详细…...

让马斯克反悔的毫米波雷达,被国产雷达头部厂商木牛科技迭代到了5D时代
近日,特斯拉或将在其HW4.0硬件系统配置一枚高精度4D毫米波雷达的消息在外网刷屏。据分析,“纯视觉”信仰者马斯克之所以做出这样的决定,一方面是减配了雷达的特斯拉自动驾驶,表现不尽如人意;另一方面也跟毫米波雷达的技…...
MaxWell原理概述
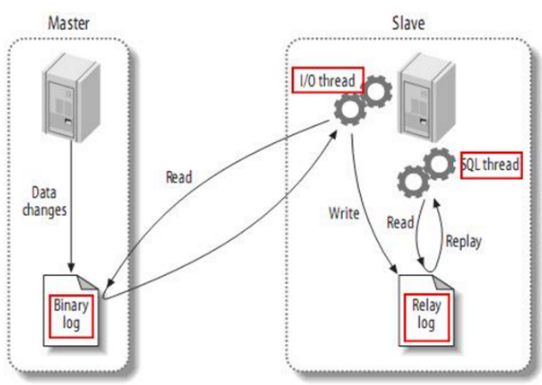
文章目录1.MaxWell概述2.Maxwell输出数据格式3.Maxwell原理3.1 MySQL二进制日志3.2 MySQL主从复制1.MaxWell概述 Maxwell 是由美国Zendesk公司开源,用Java编写的MySQL变更数据抓取软件。它会实时监控Mysql数据库的数据变更操作(包括insert、update、dele…...
电子技术——AB类输出阶
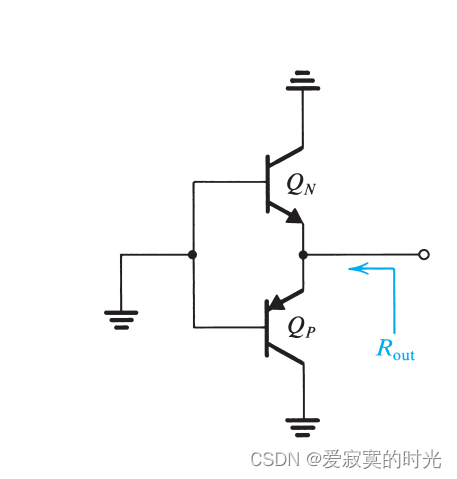
电子技术——AB类输出阶 原理 交越失真可以通过通过一个较小的偏置电流解除,如下图: QNQ_NQN 和 QPQ_PQP 的基极之间存在偏置电压 VBBV_{BB}VBB 。对于完美匹配的晶体管,当 vI0v_I 0vI0 的时候,此时 vO0v_O 0vO0 。每…...

Archlinux个人安装流程
操作环境: 时间:2023-02-17 电脑型号:联想拯救者R720 cpu:Intel Core i5-7300HQ 4x 3.5GHz gpu:NVIDIA GeForce GTX 1050 Ti 安装系统: 1.下载镜像: 请访问https://archlinux.org/查找镜…...
【Autoware】2小时安装Autoware1.13(保姆级教程)
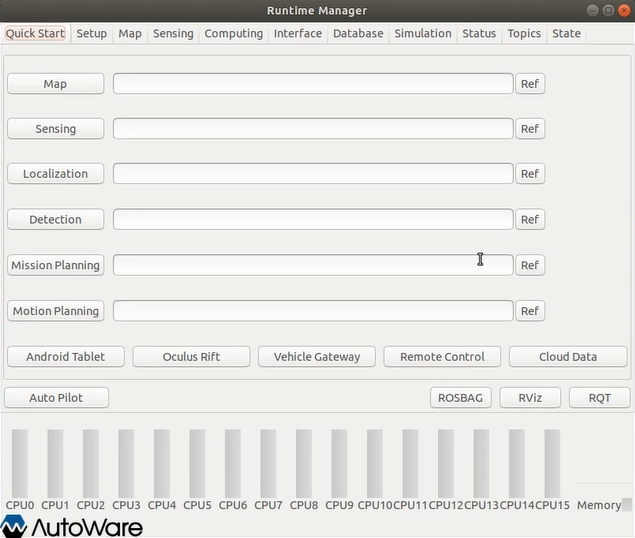
前言:ROS的出现使得机器人软件开发更加快速和模块化,在此基础上,Autoware.ai开源项目可以让我们很容易地将一套完整的自动驾驶软件部署到我们的测试车辆上,并见证它跑起来! 文章目录1.Autoware简介2.电脑软硬件配置要求…...
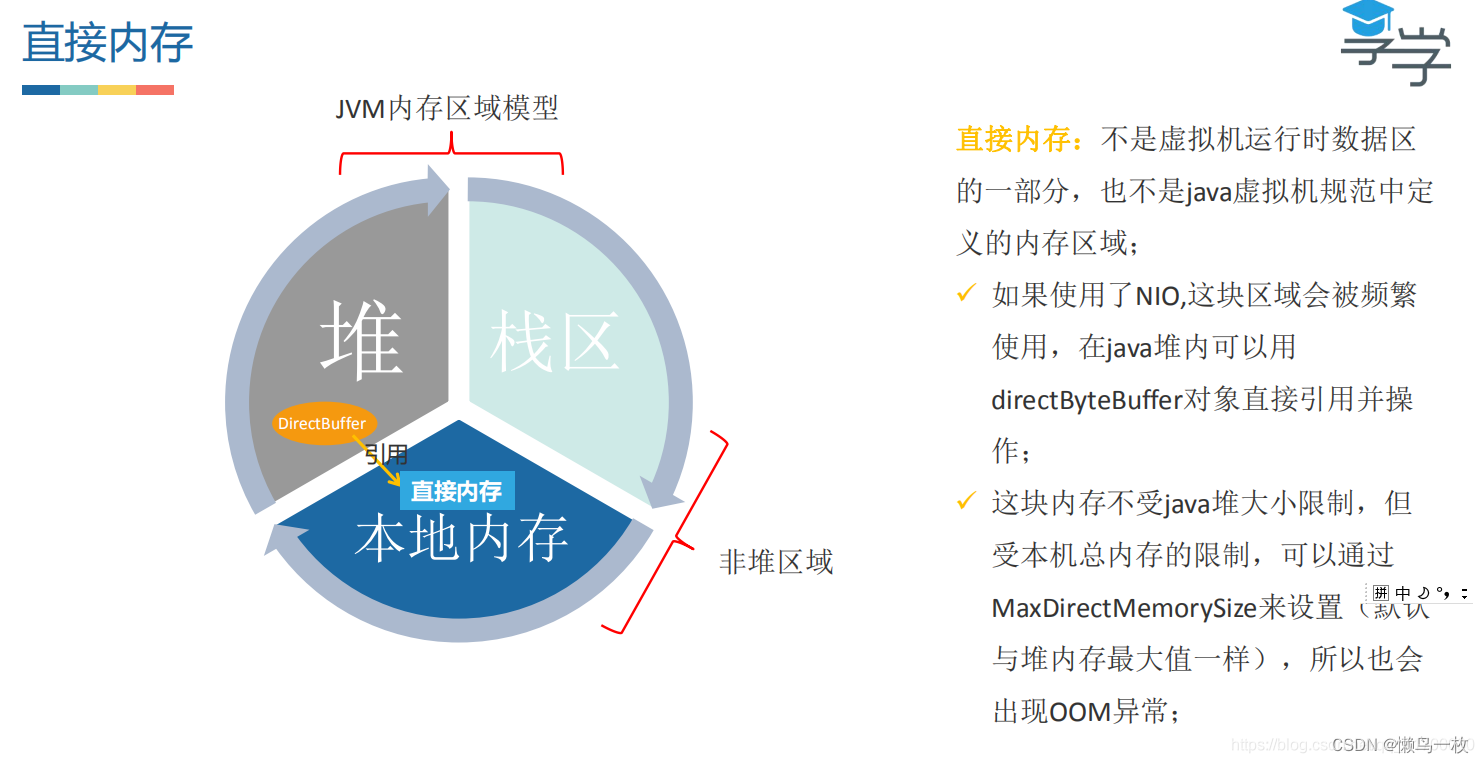
JVM 堆内存模型
方法区和永久代的关系 方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 N…...
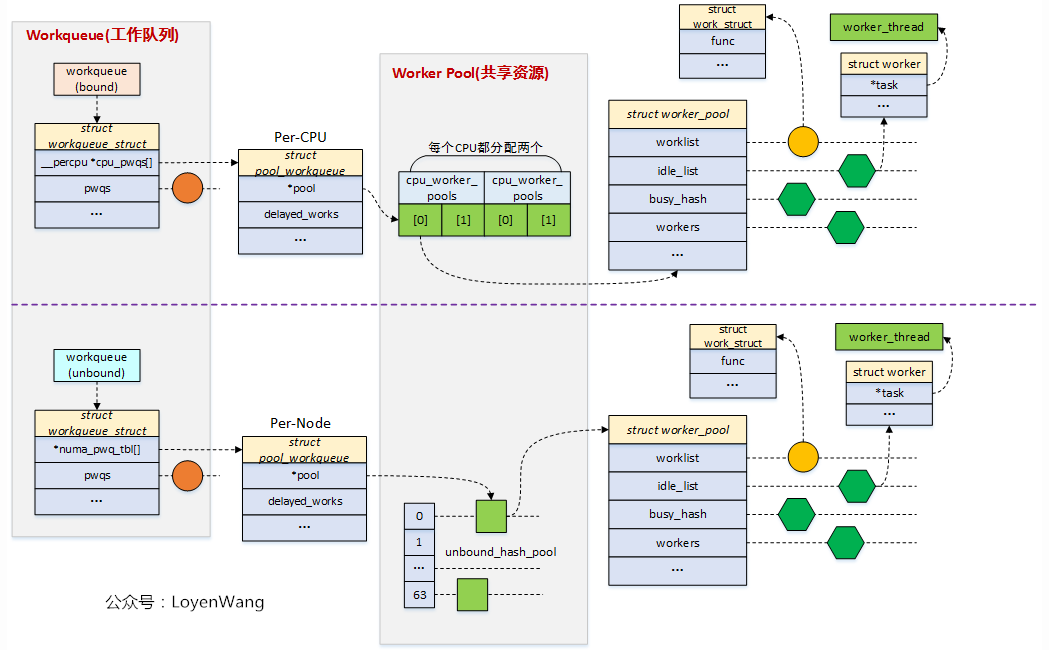
linux-中断下半部
引用preempt宋宝华: 是谁关闭了Linux抢占,而抢占又关闭了谁?Linux用户抢占和内核抢占详解(概念, 实现和触发时机)--Linux进程的管理与调度(二十)内核抢占实现(preempt)Linux中的preempt_count - 知乎 (zhihu.com)linux 中断子系统…...
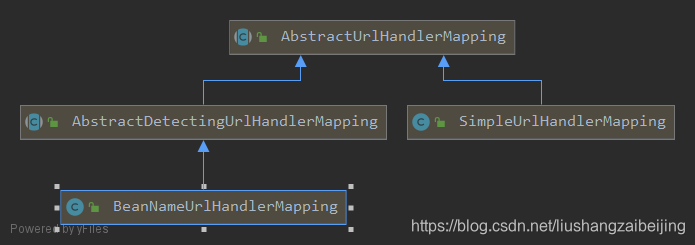
SpringMVC源码:HandlerMapping加载1
参考资料: 《SpringMVC源码解析系列》 《SpringMVC源码分析》 《Spring MVC源码》 写在开头:本文为个人学习笔记,内容比较随意,夹杂个人理解,如有错误,欢迎指正。 前文: 《SpringMVC源码&a…...

【ArcGIS】12 投影
问题描述 在处理地理数据时,可能会遇到以下关于投影的问题: DEM缺少投影,提取流域会报错图层只有地理坐标系,没有投影坐标系,无法测量距离、计算面积等要素图层投影偏移量错误,与实际位置有偏差总之,投影对各种地理操作影响很大,有必要深入理解。 投影说明 在ArcGIS…...

【微信小程序-原生开发+TDesign】通用功能页封装——地点搜索(含腾讯地图开发key 的申请方法)
效果预览 核心技能点 调用腾讯地图官方的关键字地点搜索功能,详见官方文档 https://lbs.qq.com/miniProgram/jsSdk/jsSdkGuide/methodGetsuggestion 完整代码实现 地点输入框 <t-input value"{{placeInfo.title}}" bindtap"searchPlace" dis…...

h5: 打开手机上的某个app
1、android端:直接通过URL Scheme方式打开。2、ios端(2种):(1)使用URL Scheme方式打开。(2)使用Universal link方式打开。3、Universal link方式使用注意事项:࿰…...

Hot Chocolate 构建 GraphQL .Net Core 服务
Hot Chocolate 是 .NET 平台下的一个开源组件库, 您可以使用它创建 GraphQL 服务, 它消除了构建成熟的 GraphQL 服务的复杂性, Hot Chocolate 可以连接任何服务或数据源,并创建一个有凝聚力的服务,为您的消费者提供统一的 API。 我会在 .NET 应用中使用…...

linux shell 入门学习笔记16 流程控制开发
shell的流程控制一般包括if、for、while、case/esac、until、break、continue语句构成。 if语句开发 单分支if //方式1 if <条件表达式> then 代码。。。 fi //方式2 if <条件表达式>;then 代码。。。 fi 双分支if if <条件表达式> then 代码1 if <条件表…...
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞…...

给VivoBook扩容重装系统
现在笔记本重装系统都这么复杂吗?原谅我还是10年前的装机水平,折腾了一天终于把系统重新安装好了。 笔记本: ASUS VivoBook 安装系统: Win10 1、扩容 电脑配的512G硬盘满了要换个大的,后盖严丝合缝,不…...

vue 依赖注入使用教程
vue 中的依赖注入,官网文档已经非常详细,笔者在这里总结一份 目录 1、背景介绍 2、代码实现 2.1、依赖注入固定值 2.2、 依赖注入响应式数据 3、注入别名 4、注入默认值 5、应用层 Provide 6、使用 Symbol 作注入名 1、背景介绍 为什么会出现依…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...
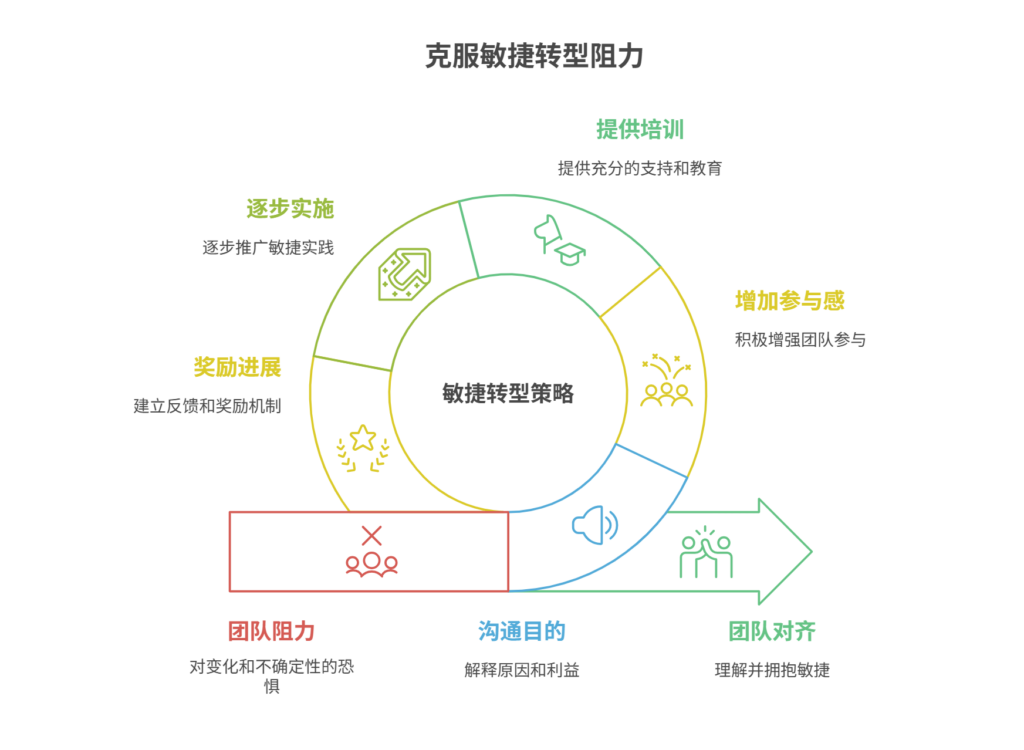
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...