字节前端经典面试题(附答案)
有哪些可能引起前端安全的问题?
- 跨站脚本 (Cross-Site Scripting, XSS): ⼀种代码注⼊⽅式, 为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简单包括但不限于 JavaScript / CSS / Flash 等;
- iframe的滥⽤: iframe中的内容是由第三⽅来提供的,默认情况下他们不受控制,他们可以在iframe中运⾏JavaScirpt脚本、Flash插件、弹出对话框等等,这可能会破坏前端⽤户体验;
- 跨站点请求伪造(Cross-Site Request Forgeries,CSRF): 指攻击者通过设置好的陷阱,强制对已完成认证的⽤户进⾏⾮预期的个⼈信息或设定信息等某些状态更新,属于被动攻击
- 恶意第三⽅库: ⽆论是后端服务器应⽤还是前端应⽤开发,绝⼤多数时候都是在借助开发框架和各种类库进⾏快速开发,⼀旦第三⽅库被植⼊恶意代码很容易引起安全问题。
写代码:实现函数能够深度克隆基本类型
浅克隆:
function shallowClone(obj) {let cloneObj = {};for (let i in obj) {cloneObj[i] = obj[i];}return cloneObj;
}深克隆:
- 考虑基础类型
- 引用类型
- RegExp、Date、函数 不是 JSON 安全的
- 会丢失 constructor,所有的构造函数都指向 Object
- 破解循环引用
function deepCopy(obj) {if (typeof obj === 'object') {var result = obj.constructor === Array ? [] : {};for (var i in obj) {result[i] = typeof obj[i] === 'object' ? deepCopy(obj[i]) : obj[i];}} else {var result = obj;}return result;
}<script src=’xxx’ ’xxx’/>外部js文件先加载还是onload先执行,为什么?
onload 是所以加载完成之后执行的
了解 this 嘛,bind,call,apply 具体指什么
它们都是函数的方法
call: Array.prototype.call(this, args1, args2]) apply: Array.prototype.apply(this, [args1, args2]) :ES6 之前用来展开数组调用, foo.appy(null, []),ES6 之后使用 … 操作符
- New 绑定 > 显示绑定 > 隐式绑定 > 默认绑定
- 如果需要使用 bind 的柯里化和 apply 的数组解构,绑定到 null,尽可能使用 Object.create(null) 创建一个 DMZ 对象
四条规则:
- 默认绑定,没有其他修饰(bind、apply、call),在非严格模式下定义指向全局对象,在严格模式下定义指向 undefined
function foo() {console.log(this.a);
}var a = 2;
foo();- 隐式绑定:调用位置是否有上下文对象,或者是否被某个对象拥有或者包含,那么隐式绑定规则会把函数调用中的 this 绑定到这个上下文对象。而且,对象属性链只有上一层或者说最后一层在调用位置中起作用
function foo() {console.log(this.a);
}var obj = {a: 2,foo: foo,
}obj.foo(); // 2- 显示绑定:通过在函数上运行 call 和 apply ,来显示的绑定 this
function foo() {console.log(this.a);
}var obj = {a: 2
};foo.call(obj);显示绑定之硬绑定
function foo(something) {console.log(this.a, something);return this.a + something;
}function bind(fn, obj) {return function() {return fn.apply(obj, arguments);};
}var obj = {a: 2
}var bar = bind(foo, obj);New 绑定,new 调用函数会创建一个全新的对象,并将这个对象绑定到函数调用的 this。
- New 绑定时,如果是 new 一个硬绑定函数,那么会用 new 新建的对象替换这个硬绑定 this,
function foo(a) {this.a = a;
}var bar = new foo(2);
console.log(bar.a)代码输出结果
// a
function Foo () {getName = function () {console.log(1);}return this;
}
// b
Foo.getName = function () {console.log(2);
}
// c
Foo.prototype.getName = function () {console.log(3);
}
// d
var getName = function () {console.log(4);
}
// e
function getName () {console.log(5);
}Foo.getName(); // 2
getName(); // 4
Foo().getName(); // 1
getName(); // 1
new Foo.getName(); // 2
new Foo().getName(); // 3
new new Foo().getName(); // 3输出结果:2 4 1 1 2 3 3
解析:
- Foo.getName(), Foo为一个函数对象,对象都可以有属性,b 处定义Foo的getName属性为函数,输出2;
- getName(), 这里看d、e处,d为函数表达式,e为函数声明,两者区别在于变量提升,函数声明的 5 会被后边函数表达式的 4 覆盖;
- ** Foo().getName(),** 这里要看a处,在Foo内部将全局的getName重新赋值为 console.log(1) 的函数,执行Foo()返回 this,这个this指向window,Foo().getName() 即为window.getName(),输出 1;
- getName(), 上面3中,全局的getName已经被重新赋值,所以这里依然输出 1;
- new Foo.getName(), 这里等价于 new (Foo.getName()),先执行 Foo.getName(),输出 2,然后new一个实例;
- new Foo().getName(), 这 里等价于 (new Foo()).getName(), 先new一个Foo的实例,再执行这个实例的getName方法,但是这个实例本身没有这个方法,所以去原型链__protot__上边找,实例.protot === Foo.prototype,所以输出 3;
- new new Foo().getName(), 这里等价于new (new Foo().getName()),如上述6,先输出 3,然后new 一个 new Foo().getName() 的实例。
一个 tcp 连接能发几个 http 请求?
如果是 HTTP 1.0 版本协议,一般情况下,不支持长连接,因此在每次请求发送完毕之后,TCP 连接即会断开,因此一个 TCP 发送一个 HTTP 请求,但是有一种情况可以将一条 TCP 连接保持在活跃状态,那就是通过 Connection 和 Keep-Alive 首部,在请求头带上 Connection: Keep-Alive,并且可以通过 Keep-Alive 通用首部中指定的,用逗号分隔的选项调节 keep-alive 的行为,如果客户端和服务端都支持,那么其实也可以发送多条,不过此方式也有限制,可以关注《HTTP 权威指南》4.5.5 节对于 Keep-Alive 连接的限制和规则。
而如果是 HTTP 1.1 版本协议,支持了长连接,因此只要 TCP 连接不断开,便可以一直发送 HTTP 请求,持续不断,没有上限; 同样,如果是 HTTP 2.0 版本协议,支持多用复用,一个 TCP 连接是可以并发多个 HTTP 请求的,同样也是支持长连接,因此只要不断开 TCP 的连接,HTTP 请求数也是可以没有上限地持续发送
参考 前端进阶面试题详细解答
什么是同源策略
跨域问题其实就是浏览器的同源策略造成的。
同源策略限制了从同一个源加载的文档或脚本如何与另一个源的资源进行交互。这是浏览器的一个用于隔离潜在恶意文件的重要的安全机制。同源指的是:协议、端口号、域名必须一致。
同源策略:protocol(协议)、domain(域名)、port(端口)三者必须一致。
同源政策主要限制了三个方面:
- 当前域下的 js 脚本不能够访问其他域下的 cookie、localStorage 和 indexDB。
- 当前域下的 js 脚本不能够操作访问操作其他域下的 DOM。
- 当前域下 ajax 无法发送跨域请求。
同源政策的目的主要是为了保证用户的信息安全,它只是对 js 脚本的一种限制,并不是对浏览器的限制,对于一般的 img、或者script 脚本请求都不会有跨域的限制,这是因为这些操作都不会通过响应结果来进行可能出现安全问题的操作。
说下对 JS 的了解吧
是基于原型的动态语言,主要独特特性有 this、原型和原型链。
JS 严格意义上来说分为:语言标准部分(ECMAScript)+ 宿主环境部分
语言标准部分
2015 年发布 ES6,引入诸多新特性使得能够编写大型项目变成可能,标准自 2015 之后以年号代号,每年一更
宿主环境部分
- 在浏览器宿主环境包括 DOM + BOM 等
- 在 Node,宿主环境包括一些文件、数据库、网络、与操作系统的交互等
React 17 带来了哪些改变
最重要的是以下三点:
- 新的
JSX转换逻辑 - 事件系统重构
Lane 模型的引入
1. 重构 JSX 转换逻辑
在过去,如果我们在 React 项目中写入下面这样的代码:
function MyComponent() {return <p>这是我的组件</p>
}
React 是会报错的,原因是 React 中对 JSX 代码的转换依赖的是 React.createElement 这个函数。因此但凡我们在代码中包含了 JSX,那么就必须在文件中引入 React,像下面这样:
import React from 'react';
function MyComponent() {return <p>这是我的组件</p>
}
而 React 17 则允许我们在不引入 React 的情况下直接使用 JSX。这是因为在 React 17 中,编译器会自动帮我们引入 JSX 的解析器,也就是说像下面这样一段逻辑:
function MyComponent() {return <p>这是我的组件</p>
}
会被编译器转换成这个样子:
import {jsx as _jsx} from 'react/jsx-runtime';
function MyComponent() {return _jsx('p', { children: '这是我的组件' });
}
react/jsx-runtime 中的 JSX 解析器将取代 React.createElement 完成 JSX 的编译工作,这个过程对开发者而言是自动化、无感知的。因此,新的 JSX 转换逻辑带来的最显著的改变就是降低了开发者的学习成本。
react/jsx-runtime 中的 JSX 解析器看上去似乎在调用姿势上和 React.createElement 区别不大,那么它是否只是 React.createElement 换了个马甲呢?当然不是,它在内部实现了 React.createElement 无法做到的性能优化和简化。在一定情况下,它可能会略微改善编译输出内容的大小
2. 事件系统重构
事件系统在 React 17 中的重构要从以下两个方面来看:
- 卸掉历史包袱
- 拥抱新的潮流
2.1 卸掉历史包袱:放弃利用 document 来做事件的中心化管控
React 16.13.x 版本中的事件系统会通过将所有事件冒泡到 document 来实现对事件的中心化管控
这样的做法虽然看上去已经足够巧妙,但仍然有它不聪明的地方——document 是整个文档树的根节点,操作 document 带来的影响范围实在是太大了,这将会使事情变得更加不可控
在 React 17 中,React 团队终于正面解决了这个问题:事件的中心化管控不会再全部依赖
document,管控相关的逻辑被转移到了每个 React 组件自己的容器 DOM 节点中。比如说我们在 ID 为 root 的 DOM 节点下挂载了一个 React 组件,像下面代码这样:
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
那么事件管控相关的逻辑就会被安装到 root 节点上去。这样一来, React 组件就能够自己玩自己的,再也无法对全局的事件流构成威胁了
2.2 拥抱新的潮流:放弃事件池
在 React 17 之前,合成事件对象会被放进一个叫作“事件池”的地方统一管理。这样做的目的是能够实现事件对象的复用,进而提高性能:每当事件处理函数执行完毕后,其对应的合成事件对象内部的所有属性都会被置空,意在为下一次被复用做准备。这也就意味着事件逻辑一旦执行完毕,我们就拿不到事件对象了,React 官方给出的这个例子就很能说明问题,请看下面这个代码
function handleChange(e) {// This won't work because the event object gets reused.setTimeout(() => {console.log(e.target.value); // Too late!}, 100);
}
异步执行的
setTimeout回调会在handleChange这个事件处理函数执行完毕后执行,因此它拿不到想要的那个事件对象e。
要想拿到目标事件对象,必须显式地告诉 React——我永远需要它,也就是调用 e.persist() 函数,像下面这样:
function handleChange(e) {// Prevents React from resetting its properties:e.persist();setTimeout(() => {console.log(e.target.value); // Works}, 100);
}
在 React 17 中,我们不需要 e.persist(),也可以随时随地访问我们想要的事件对象。
3. Lane 模型的引入
初学 React 源码的同学由此可能会很自然地认为:优先级就应该是用 Lane 来处理的。但事实上,React 16 中处理优先级采用的是 expirationTime 模型。
expirationTime模型使用expirationTime(一个时间长度) 来描述任务的优先级;而Lane 模型则使用二进制数来表示任务的优先级:
lane 模型通过将不同优先级赋值给一个位,通过 31 位的位运算来操作优先级。
Lane 模型提供了一个新的优先级排序的思路,相对于 expirationTime 来说,它对优先级的处理会更细腻,能够覆盖更多的边界条件。
浏览器的渲染过程
浏览器渲染主要有以下步骤:
- 首先解析收到的文档,根据文档定义构建一棵 DOM 树,DOM 树是由 DOM 元素及属性节点组成的。
- 然后对 CSS 进行解析,生成 CSSOM 规则树。
- 根据 DOM 树和 CSSOM 规则树构建渲染树。渲染树的节点被称为渲染对象,渲染对象是一个包含有颜色和大小等属性的矩形,渲染对象和 DOM 元素相对应,但这种对应关系不是一对一的,不可见的 DOM 元素不会被插入渲染树。还有一些 DOM元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。
- 当渲染对象被创建并添加到树中,它们并没有位置和大小,所以当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)。这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。
- 布局阶段结束后是绘制阶段,遍历渲染树并调用渲染对象的 paint 方法将它们的内容显示在屏幕上,绘制使用 UI 基础组件。
大致过程如图所示:
注意: 这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html 都解析完成之后再去构建和布局 render 树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
进程与线程的概念
从本质上说,进程和线程都是 CPU 工作时间片的一个描述:
- 进程描述了 CPU 在运行指令及加载和保存上下文所需的时间,放在应用上来说就代表了一个程序。
- 线程是进程中的更小单位,描述了执行一段指令所需的时间。
进程是资源分配的最小单位,线程是CPU调度的最小单位。
一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。进程是运行在虚拟内存上的,虚拟内存是用来解决用户对硬件资源的无限需求和有限的硬件资源之间的矛盾的。从操作系统角度来看,虚拟内存即交换文件;从处理器角度看,虚拟内存即虚拟地址空间。
如果程序很多时,内存可能会不够,操作系统为每个进程提供一套独立的虚拟地址空间,从而使得同一块物理内存在不同的进程中可以对应到不同或相同的虚拟地址,变相的增加了程序可以使用的内存。
进程和线程之间的关系有以下四个特点:
(1)进程中的任意一线程执行出错,都会导致整个进程的崩溃。
(2)线程之间共享进程中的数据。
(3)当一个进程关闭之后,操作系统会回收进程所占用的内存, 当一个进程退出时,操作系统会回收该进程所申请的所有资源;即使其中任意线程因为操作不当导致内存泄漏,当进程退出时,这些内存也会被正确回收。
(4)进程之间的内容相互隔离。 进程隔离就是为了使操作系统中的进程互不干扰,每一个进程只能访问自己占有的数据,也就避免出现进程 A 写入数据到进程 B 的情况。正是因为进程之间的数据是严格隔离的,所以一个进程如果崩溃了,或者挂起了,是不会影响到其他进程的。如果进程之间需要进行数据的通信,这时候,就需要使用用于进程间通信的机制了。
Chrome浏览器的架构图: 从图中可以看出,最新的 Chrome 浏览器包括:
- 1 个浏览器主进程
- 1 个 GPU 进程
- 1 个网络进程
- 多个渲染进程
- 多个插件进程
这些进程的功能:
- 浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
- 渲染进程:核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
- GPU 进程:其实, GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
- 网络进程:主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
- 插件进程:主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
所以,打开一个网页,最少需要四个进程:1 个网络进程、1 个浏览器进程、1 个 GPU 进程以及 1 个渲染进程。如果打开的页面有运行插件的话,还需要再加上 1 个插件进程。
虽然多进程模型提升了浏览器的稳定性、流畅性和安全性,但同样不可避免地带来了一些问题:
- 更高的资源占用:因为每个进程都会包含公共基础结构的副本(如 JavaScript 运行环境),这就意味着浏览器会消耗更多的内存资源。
- 更复杂的体系架构:浏览器各模块之间耦合性高、扩展性差等问题,会导致现在的架构已经很难适应新的需求了。
对对象与数组的解构的理解
解构是 ES6 提供的一种新的提取数据的模式,这种模式能够从对象或数组里有针对性地拿到想要的数值。 1)数组的解构 在解构数组时,以元素的位置为匹配条件来提取想要的数据的:
const [a, b, c] = [1, 2, 3]最终,a、b、c分别被赋予了数组第0、1、2个索引位的值:
数组里的0、1、2索引位的元素值,精准地被映射到了左侧的第0、1、2个变量里去,这就是数组解构的工作模式。还可以通过给左侧变量数组设置空占位的方式,实现对数组中某几个元素的精准提取:
const [a,,c] = [1,2,3]通过把中间位留空,可以顺利地把数组第一位和最后一位的值赋给 a、c 两个变量:
2)对象的解构 对象解构比数组结构稍微复杂一些,也更显强大。在解构对象时,是以属性的名称为匹配条件,来提取想要的数据的。现在定义一个对象:
const stu = {name: 'Bob',age: 24
}假如想要解构它的两个自有属性,可以这样:
const { name, age } = stu这样就得到了 name 和 age 两个和 stu 平级的变量:
注意,对象解构严格以属性名作为定位依据,所以就算调换了 name 和 age 的位置,结果也是一样的:
const { age, name } = stu什么是 XSS 攻击?
(1)概念
XSS 攻击指的是跨站脚本攻击,是一种代码注入攻击。攻击者通过在网站注入恶意脚本,使之在用户的浏览器上运行,从而盗取用户的信息如 cookie 等。
XSS 的本质是因为网站没有对恶意代码进行过滤,与正常的代码混合在一起了,浏览器没有办法分辨哪些脚本是可信的,从而导致了恶意代码的执行。
攻击者可以通过这种攻击方式可以进行以下操作:
- 获取页面的数据,如DOM、cookie、localStorage;
- DOS攻击,发送合理请求,占用服务器资源,从而使用户无法访问服务器;
- 破坏页面结构;
- 流量劫持(将链接指向某网站);
(2)攻击类型
XSS 可以分为存储型、反射型和 DOM 型:
- 存储型指的是恶意脚本会存储在目标服务器上,当浏览器请求数据时,脚本从服务器传回并执行。
- 反射型指的是攻击者诱导用户访问一个带有恶意代码的 URL 后,服务器端接收数据后处理,然后把带有恶意代码的数据发送到浏览器端,浏览器端解析这段带有 XSS 代码的数据后当做脚本执行,最终完成 XSS 攻击。
- DOM 型指的通过修改页面的 DOM 节点形成的 XSS。
1)存储型 XSS 的攻击步骤:
- 攻击者将恶意代码提交到⽬标⽹站的数据库中。
- ⽤户打开⽬标⽹站时,⽹站服务端将恶意代码从数据库取出,拼接在 HTML 中返回给浏览器。
- ⽤户浏览器接收到响应后解析执⾏,混在其中的恶意代码也被执⾏。
- 恶意代码窃取⽤户数据并发送到攻击者的⽹站,或者冒充⽤户的⾏为,调⽤⽬标⽹站接⼝执⾏攻击者指定的操作。
这种攻击常⻅于带有⽤户保存数据的⽹站功能,如论坛发帖、商品评论、⽤户私信等。
2)反射型 XSS 的攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- ⽤户打开带有恶意代码的 URL 时,⽹站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。
- ⽤户浏览器接收到响应后解析执⾏,混在其中的恶意代码也被执⾏。
- 恶意代码窃取⽤户数据并发送到攻击者的⽹站,或者冒充⽤户的⾏为,调⽤⽬标⽹站接⼝执⾏攻击者指定的操作。
反射型 XSS 跟存储型 XSS 的区别是:存储型 XSS 的恶意代码存在数据库⾥,反射型 XSS 的恶意代码存在 URL ⾥。
反射型 XSS 漏洞常⻅于通过 URL 传递参数的功能,如⽹站搜索、跳转等。 由于需要⽤户主动打开恶意的 URL 才能⽣效,攻击者往往会结合多种⼿段诱导⽤户点击。
3)DOM 型 XSS 的攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- ⽤户打开带有恶意代码的 URL。
- ⽤户浏览器接收到响应后解析执⾏,前端 JavaScript 取出 URL 中的恶意代码并执⾏。
- 恶意代码窃取⽤户数据并发送到攻击者的⽹站,或者冒充⽤户的⾏为,调⽤⽬标⽹站接⼝执⾏攻击者指定的操作。
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执⾏恶意代码由浏览器端完成,属于前端JavaScript ⾃身的安全漏洞,⽽其他两种 XSS 都属于服务端的安全漏洞。
对节流与防抖的理解
- 函数防抖是指在事件被触发 n 秒后再执行回调,如果在这 n 秒内事件又被触发,则重新计时。这可以使用在一些点击请求的事件上,避免因为用户的多次点击向后端发送多次请求。
- 函数节流是指规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。节流可以使用在 scroll 函数的事件监听上,通过事件节流来降低事件调用的频率。
防抖函数的应用场景:
- 按钮提交场景:防⽌多次提交按钮,只执⾏最后提交的⼀次
- 服务端验证场景:表单验证需要服务端配合,只执⾏⼀段连续的输⼊事件的最后⼀次,还有搜索联想词功能类似⽣存环境请⽤lodash.debounce
节流函数的适⽤场景:
- 拖拽场景:固定时间内只执⾏⼀次,防⽌超⾼频次触发位置变动
- 缩放场景:监控浏览器resize
- 动画场景:避免短时间内多次触发动画引起性能问题
Number() 的存储空间是多大?如果后台发送了一个超过最大自己的数字怎么办
Math.pow(2, 53) ,53 为有效数字,会发生截断,等于 JS 能支持的最大数字。
死锁产生的原因? 如果解决死锁的问题?
所谓死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。
系统中的资源可以分为两类:
- 可剥夺资源,是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU和主存均属于可剥夺性资源;
- 不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
产生死锁的原因:
(1)竞争资源
- 产生死锁中的竞争资源之一指的是竞争不可剥夺资源(例如:系统中只有一台打印机,可供进程P1使用,假定P1已占用了打印机,若P2继续要求打印机打印将阻塞)
- 产生死锁中的竞争资源另外一种资源指的是竞争临时资源(临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
(2)进程间推进顺序非法
若P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁。例如,当P1运行到P1:Request(R2)时,将因R2已被P2占用而阻塞;当P2运行到P2:Request(R1)时,也将因R1已被P1占用而阻塞,于是发生进程死锁
产生死锁的必要条件:
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程——资源的环形链。
预防死锁的方法:
- 资源一次性分配:一次性分配所有资源,这样就不会再有请求了(破坏请求条件)
- 只要有一个资源得不到分配,也不给这个进程分配其他的资源(破坏请保持条件)
- 可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
- 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
代码输出结果
const async1 = async () => {console.log('async1');setTimeout(() => {console.log('timer1')}, 2000)await new Promise(resolve => {console.log('promise1')})console.log('async1 end')return 'async1 success'
}
console.log('script start');
async1().then(res => console.log(res));
console.log('script end');
Promise.resolve(1).then(2).then(Promise.resolve(3)).catch(4).then(res => console.log(res))
setTimeout(() => {console.log('timer2')
}, 1000)输出结果如下:
script start
async1
promise1
script end
1
timer2
timer1代码的执行过程如下:
- 首先执行同步带吗,打印出script start;
- 遇到定时器timer1将其加入宏任务队列;
- 之后是执行Promise,打印出promise1,由于Promise没有返回值,所以后面的代码不会执行;
- 然后执行同步代码,打印出script end;
- 继续执行下面的Promise,.then和.catch期望参数是一个函数,这里传入的是一个数字,因此就会发生值渗透,将resolve(1)的值传到最后一个then,直接打印出1;
- 遇到第二个定时器,将其加入到微任务队列,执行微任务队列,按顺序依次执行两个定时器,但是由于定时器时间的原因,会在两秒后先打印出timer2,在四秒后打印出timer1。
判断数组的方式有哪些
- 通过Object.prototype.toString.call()做判断
Object.prototype.toString.call(obj).slice(8,-1) === 'Array';- 通过原型链做判断
obj.__proto__ === Array.prototype;- 通过ES6的Array.isArray()做判断
Array.isArrray(obj);- 通过instanceof做判断
obj instanceof Array- 通过Array.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(obj)JS 隐式转换,显示转换
一般非基础类型进行转换时会先调用 valueOf,如果 valueOf 无法返回基本类型值,就会调用 toString
字符串和数字
- “+” 操作符,如果有一个为字符串,那么都转化到字符串然后执行字符串拼接
- “-” 操作符,转换为数字,相减 (-a, a * 1 a/1) 都能进行隐式强制类型转换
[] + {} 和 {} + []布尔值到数字
- 1 + true = 2
- 1 + false = 1
转换为布尔值
- for 中第二个
- while
- if
- 三元表达式
- || (逻辑或) && (逻辑与)左边的操作数
符号
- 不能被转换为数字
- 能被转换为布尔值(都是 true)
- 可以被转换成字符串 “Symbol(cool)”
宽松相等和严格相等
宽松相等允许进行强制类型转换,而严格相等不允许
字符串与数字
转换为数字然后比较
其他类型与布尔类型
- 先把布尔类型转换为数字,然后继续进行比较
对象与非对象
- 执行对象的 ToPrimitive(对象)然后继续进行比较
假值列表
- undefined
- null
- false
- +0, -0, NaN
- “”
什么是物理像素,逻辑像素和像素密度,为什么在移动端开发时需要用到@3x, @2x这种图片?
以 iPhone XS 为例,当写 CSS 代码时,针对于单位 px,其宽度为 414px & 896px,也就是说当赋予一个 DIV元素宽度为 414px,这个 DIV 就会填满手机的宽度;
而如果有一把尺子来实际测量这部手机的物理像素,实际为 1242*2688 物理像素;经过计算可知,1242/414=3,也就是说,在单边上,一个逻辑像素=3个物理像素,就说这个屏幕的像素密度为 3,也就是常说的 3 倍屏。
对于图片来说,为了保证其不失真,1 个图片像素至少要对应一个物理像素,假如原始图片是 500300 像素,那么在 3 倍屏上就要放一个 1500900 像素的图片才能保证 1 个物理像素至少对应一个图片像素,才能不失真。 当然,也可以针对所有屏幕,都只提供最高清图片。虽然低密度屏幕用不到那么多图片像素,而且会因为下载多余的像素造成带宽浪费和下载延迟,但从结果上说能保证图片在所有屏幕上都不会失真。
还可以使用 CSS 媒体查询来判断不同的像素密度,从而选择不同的图片:
my-image { background: (low.png); }
@media only screen and (min-device-pixel-ratio: 1.5) {#my-image { background: (high.png); }
}相关文章:
)
字节前端经典面试题(附答案)
有哪些可能引起前端安全的问题? 跨站脚本 (Cross-Site Scripting, XSS): ⼀种代码注⼊⽅式, 为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简…...
数据库管理工具的使用
目录 摘要 一、Navicat是什么? 二、使用步骤 1.如何下载与安装 2.如何连接远程数据库 总结 摘要 本文主要介绍数据库管理工具的使用 一、Navicat是什么? 它是一款数据库管理工具,将此工具连接数据库,你可以从中看到各种数据库的详细…...

让马斯克反悔的毫米波雷达,被国产雷达头部厂商木牛科技迭代到了5D时代
近日,特斯拉或将在其HW4.0硬件系统配置一枚高精度4D毫米波雷达的消息在外网刷屏。据分析,“纯视觉”信仰者马斯克之所以做出这样的决定,一方面是减配了雷达的特斯拉自动驾驶,表现不尽如人意;另一方面也跟毫米波雷达的技…...
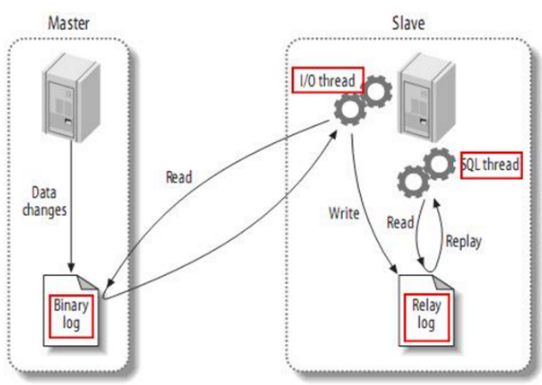
MaxWell原理概述
文章目录1.MaxWell概述2.Maxwell输出数据格式3.Maxwell原理3.1 MySQL二进制日志3.2 MySQL主从复制1.MaxWell概述 Maxwell 是由美国Zendesk公司开源,用Java编写的MySQL变更数据抓取软件。它会实时监控Mysql数据库的数据变更操作(包括insert、update、dele…...
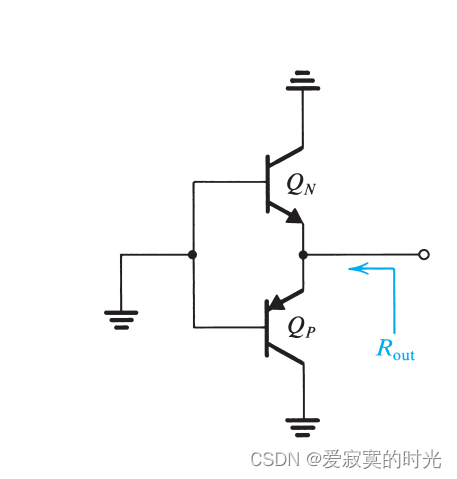
电子技术——AB类输出阶
电子技术——AB类输出阶 原理 交越失真可以通过通过一个较小的偏置电流解除,如下图: QNQ_NQN 和 QPQ_PQP 的基极之间存在偏置电压 VBBV_{BB}VBB 。对于完美匹配的晶体管,当 vI0v_I 0vI0 的时候,此时 vO0v_O 0vO0 。每…...

Archlinux个人安装流程
操作环境: 时间:2023-02-17 电脑型号:联想拯救者R720 cpu:Intel Core i5-7300HQ 4x 3.5GHz gpu:NVIDIA GeForce GTX 1050 Ti 安装系统: 1.下载镜像: 请访问https://archlinux.org/查找镜…...
【Autoware】2小时安装Autoware1.13(保姆级教程)
前言:ROS的出现使得机器人软件开发更加快速和模块化,在此基础上,Autoware.ai开源项目可以让我们很容易地将一套完整的自动驾驶软件部署到我们的测试车辆上,并见证它跑起来! 文章目录1.Autoware简介2.电脑软硬件配置要求…...
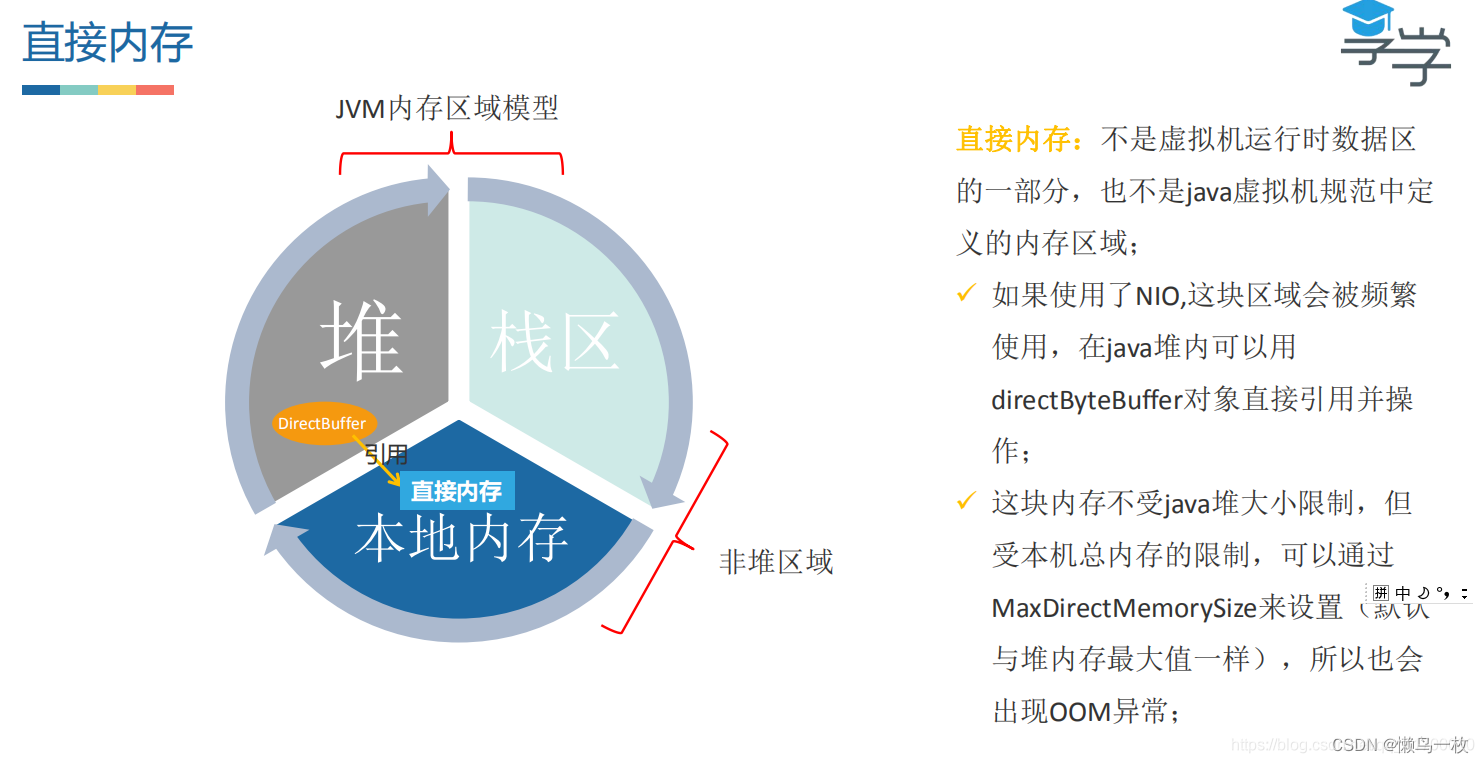
JVM 堆内存模型
方法区和永久代的关系 方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 N…...
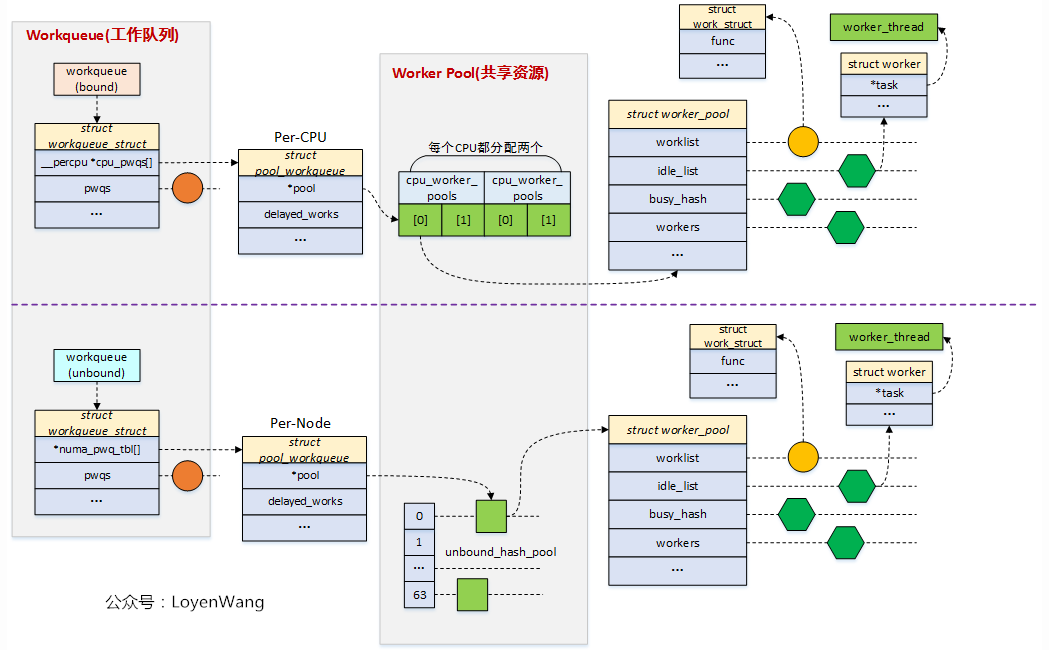
linux-中断下半部
引用preempt宋宝华: 是谁关闭了Linux抢占,而抢占又关闭了谁?Linux用户抢占和内核抢占详解(概念, 实现和触发时机)--Linux进程的管理与调度(二十)内核抢占实现(preempt)Linux中的preempt_count - 知乎 (zhihu.com)linux 中断子系统…...
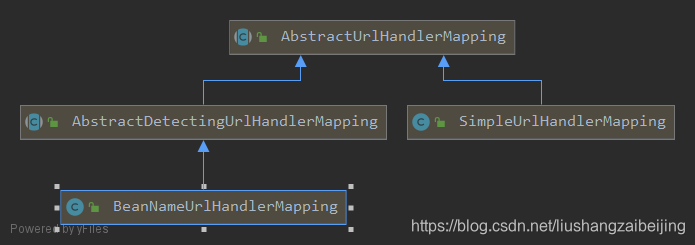
SpringMVC源码:HandlerMapping加载1
参考资料: 《SpringMVC源码解析系列》 《SpringMVC源码分析》 《Spring MVC源码》 写在开头:本文为个人学习笔记,内容比较随意,夹杂个人理解,如有错误,欢迎指正。 前文: 《SpringMVC源码&a…...

【ArcGIS】12 投影
问题描述 在处理地理数据时,可能会遇到以下关于投影的问题: DEM缺少投影,提取流域会报错图层只有地理坐标系,没有投影坐标系,无法测量距离、计算面积等要素图层投影偏移量错误,与实际位置有偏差总之,投影对各种地理操作影响很大,有必要深入理解。 投影说明 在ArcGIS…...

【微信小程序-原生开发+TDesign】通用功能页封装——地点搜索(含腾讯地图开发key 的申请方法)
效果预览 核心技能点 调用腾讯地图官方的关键字地点搜索功能,详见官方文档 https://lbs.qq.com/miniProgram/jsSdk/jsSdkGuide/methodGetsuggestion 完整代码实现 地点输入框 <t-input value"{{placeInfo.title}}" bindtap"searchPlace" dis…...

h5: 打开手机上的某个app
1、android端:直接通过URL Scheme方式打开。2、ios端(2种):(1)使用URL Scheme方式打开。(2)使用Universal link方式打开。3、Universal link方式使用注意事项:࿰…...

Hot Chocolate 构建 GraphQL .Net Core 服务
Hot Chocolate 是 .NET 平台下的一个开源组件库, 您可以使用它创建 GraphQL 服务, 它消除了构建成熟的 GraphQL 服务的复杂性, Hot Chocolate 可以连接任何服务或数据源,并创建一个有凝聚力的服务,为您的消费者提供统一的 API。 我会在 .NET 应用中使用…...

linux shell 入门学习笔记16 流程控制开发
shell的流程控制一般包括if、for、while、case/esac、until、break、continue语句构成。 if语句开发 单分支if //方式1 if <条件表达式> then 代码。。。 fi //方式2 if <条件表达式>;then 代码。。。 fi 双分支if if <条件表达式> then 代码1 if <条件表…...
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞…...

给VivoBook扩容重装系统
现在笔记本重装系统都这么复杂吗?原谅我还是10年前的装机水平,折腾了一天终于把系统重新安装好了。 笔记本: ASUS VivoBook 安装系统: Win10 1、扩容 电脑配的512G硬盘满了要换个大的,后盖严丝合缝,不…...

vue 依赖注入使用教程
vue 中的依赖注入,官网文档已经非常详细,笔者在这里总结一份 目录 1、背景介绍 2、代码实现 2.1、依赖注入固定值 2.2、 依赖注入响应式数据 3、注入别名 4、注入默认值 5、应用层 Provide 6、使用 Symbol 作注入名 1、背景介绍 为什么会出现依…...
【再临数据结构】Day1. 稀疏数组
前言 这不单单是稀疏数组的开始,也是我重学数据结构的开始。因此,在开始说稀疏数组的具体内容之前,我想先说一下作为一个有着十余年“学龄”的学生,所一直沿用的一个学习方法:3W法。我认为,只有掌握了正确的…...
)
二十四、MongoDB 聚合运算( aggregate )
MongoDB 聚合( aggregate ) 用于处理数据,比如统计平均值,求和等。然后返回计算后的数据结果 MongoDB 聚合有点类似 SQL 语句中的 COUNT( * ) aggregate() 方法 MongoDB aggregate() 为 MongoDB 数据库提供了聚合运算 语法 aggregate() 方法的语法如下 > d…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...

Java中栈的多种实现类详解
Java中栈的多种实现类详解:Stack、LinkedList与ArrayDeque全方位对比 前言一、Stack类——Java最早的栈实现1.1 Stack类简介1.2 常用方法1.3 优缺点分析 二、LinkedList类——灵活的双端链表2.1 LinkedList类简介2.2 常用方法2.3 优缺点分析 三、ArrayDeque类——高…...

Spring是如何实现无代理对象的循环依赖
无代理对象的循环依赖 什么是循环依赖解决方案实现方式测试验证 引入代理对象的影响创建代理对象问题分析 源码见:mini-spring 什么是循环依赖 循环依赖是指在对象创建过程中,两个或多个对象相互依赖,导致创建过程陷入死循环。以下通过一个简…...