时间序列预测实战(十六)PyTorch实现GRU-FCN模型长期预测并可视化结果

往期回顾:时间序列预测专栏——包含上百种时间序列模型带你从入门到精通时间序列预测
一、本文介绍
本文讲解的实战内容是GRU-FCN(门控循环单元-全卷积网络),这是一种结合了GRU(用于处理时间序列数据)和FCN(全卷积网络)的深度学习模型,这种融合模型在处理时间序列预测的时候是十分经典且效果很好的组合方式。它的优势在于能够同时捕捉时间序列数据中的时间动态和空间特征,从而提高模型的准确度和效率,本文给大家讲解的就是这个模型,本文的实战内容通过时间序列领域最经典的数据集——电力负荷数据集为例,带大家深入的了解GRU和FCN的基本原理和融合思想。
预测类型->单元预测、长期预测,(多元预测的功能我目前没有做这个模型大家有兴趣可以自己尝试有不会的可以在评论区问我)
代码地址->文末提供复制粘贴即可运行的代码块
目录
一、本文介绍
二、框架原理介绍
1.GRU的基本原理
1.1GRU的基本框架
2.FCN的基本原理
3.模型融合思想
三、数据集介绍
四、项目的全部代码
五、模型代码的详细讲解
六、模型的训练和预测
6.1模型的训练
6.2模型的评估
6.2.1结果展示
6.2.2结果分析
全文总结
二、框架原理介绍
1.GRU的基本原理
GRU(门控循环单元)是一种循环神经网络(RNN)的变体,主要用于处理序列数据,它的基本原理可以概括如下:
门控机制:GRU的核心是门控机制,包括更新门(update gate)和重置门(reset gate)。这些门控制着信息的流动,即决定哪些信息应该被保留,哪些应该被遗忘。
更新门:更新门帮助模型决定过去的信息有多少需要保留到当前状态。它是通过当前输入和前一个隐状态计算得出的,用于调节隐状态的更新程度。
重置门:重置门决定了多少过去的信息需要被忘记。它同样依赖于当前输入和前一个隐状态的信息。当重置门接近0时,模型会“忘记”过去的隐状态,只依赖于当前输入。
当前隐状态的计算:利用更新门和重置门的输出,结合前一隐状态和当前输入,GRU计算出当前的隐状态。这个隐状态包含了序列到目前为止的重要信息。
输出:GRU的最终输出通常是在序列的每个时间步上产生的,或者在序列的最后一个时间步产生,取决于具体的应用场景。
总结:GRU相较于传统的RNN,其优势在于能够更有效地处理长序列数据,减轻了梯度消失的问题。同时,它通常比LSTM(长短期记忆网络)更简单,因为它有更少的参数。
1.1GRU的基本框架

上面的图片为一个GRU的基本结构图,解释如下->
- 更新门(z) 在决定是否用新的隐藏状态更新当前隐藏状态时扮演重要角色。
- 重置门(r) 决定是否忽略之前的隐藏状态。
这些部分是GRU的核心组成,它们共同决定了网络如何在序列数据中传递和更新信息,这对于时间序列分析至关重要。
2.FCN的基本原理
全卷积网络(FCN, Fully Convolutional Network)FCN 完全由卷积层构成CN 通过在时间序列数据上应用一系列卷积和池化操作,有效地提取时间序列中的局部特征和模式。这对于理解数据中的复杂模式和趋势非常有用。卷积层可以捕捉时间序列数据中的局部依赖性和时间动态,不同的卷积核可以学习到数据的不同方面,例如趋势、周期性和异常(这一点在我定义的模型中也有体现)。
3.模型融合思想
将门控循环单元(GRU)和全卷积网络(FCN)结合起来的思想是为了利用这两种神经网络结构的优势,以更有效地处理时间序列数据->
特征提取与时间依赖性的结合:FCN 强于从时间序列数据中提取局部特征和模式,而 GRU 擅长捕捉时间序列的长期依赖性。将这两者结合,可以同时利用这两种能力。
FCN 部分的作用:在组合模型中,FCN 通常作为前端,用于从原始时间序列数据中提取重要的特征。FCN 的卷积层可以有效地识别出时间序列中的关键局部模式和结构特点。
GRU 部分的作用:GRU 作为模型的后端,用于处理 FCN 提取的特征。由于 GRU 的门控机制,它能够有效地捕捉和利用时间序列数据中的长期依赖关系。
最后将结果进行组合拼接从而融合了两种模型的各自优势和特点
三、数据集介绍
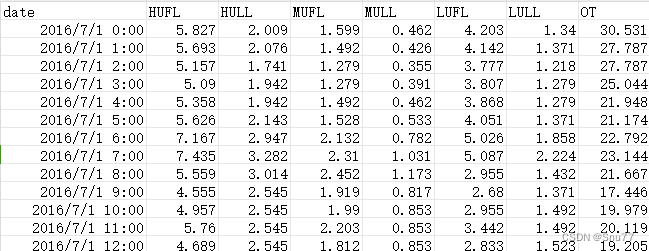
我们本文用到的数据集是官方的ETTh1.csv ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、项目的全部代码
"""
作者:CSDN Snu77 时间序列预测专栏
"""
import time
import numpy as np
import pandas as pd
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset
import torch.nn.functional as F# 随机数种子
np.random.seed(0)class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return mae"""
数据定义部分
"""
true_data = pd.read_csv('ETTh1-Test.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列target = 'OT' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 4 # 预测未来数据的长度
train_window = 32 # 观测窗口# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)def create_inout_sequences(input_data, tw, pre_len):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + 4) > len(input_data):breaktrain_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seq# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)# 创建 DataLoader
batch_size = 64 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)class GRUConvNet(nn.Module):def __init__(self, input_size, hidden_size, num_layers, pre_len, output_size=1):super(GRUConvNet, self).__init__()# 可以外部定义的参数self.pre_len = pre_lenself.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.output_size = output_size# GRU层self.gru = nn.GRU(input_size=self.input_size, hidden_size=hidden_size, num_layers=self.num_layers,batch_first=True)self.gru_dropout = nn.Dropout(0.05)# 卷积层self.conv1 = nn.Conv1d(in_channels=self.input_size, out_channels=hidden_size, kernel_size=9, padding='same')self.bn1 = nn.BatchNorm1d(hidden_size)self.conv2 = nn.Conv1d(in_channels=hidden_size, out_channels=hidden_size * 2, kernel_size=6, padding='same')self.bn2 = nn.BatchNorm1d(hidden_size * 2)self.conv3 = nn.Conv1d(in_channels=hidden_size * 2, out_channels=hidden_size, kernel_size=3, padding='same')self.bn3 = nn.BatchNorm1d(hidden_size)self.global_avg_pool = nn.AdaptiveAvgPool1d(1)# 输出层self.fc1 = nn.Linear(self.hidden_size, self.output_size)self.fc1 = nn.Linear(self.hidden_size, self.output_size)def forward(self, x):# GRU层x_, _ = self.gru(x)x_ = self.gru_dropout(x_[:, :, :]) # 使用序列的最后一个输出# 卷积层y = x.permute(0, 2, 1)y = F.relu(self.bn1(self.conv1(y)))y = F.relu(self.bn2(self.conv2(y)))y = F.relu(self.bn3(self.conv3(y)))y = self.global_avg_pool(y)y = y.permute(0, 2, 1)# 合并GRU和卷积层的输出combined = torch.cat([x_, y], dim=1)# 输出层output = self.fc1(combined)return output[:, -self.pre_len:, :]lstm_model = GRUConvNet(input_size=1, output_size=1, num_layers=2, hidden_size=32, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测if Train:losss = []lstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")else:# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式results = []reals = []losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)for j in range(batch_size):for i in range(pre_len):reals.append(labels[j][i][0].detach().numpy())results.append(pred[j][i][0].detach().numpy())reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]print("模型预测结果:", results)print("预测误差MAE:", losss)plt.figure()plt.style.use('ggplot')# 创建折线图plt.plot(reals, label='real', color='blue') # 实际值plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值# 增强视觉效果plt.grid(True)plt.title('real vs forecast')plt.xlabel('time')plt.ylabel('value')plt.legend()plt.savefig('test——results.png')
五、模型代码的详细讲解
下面我来仔细的讲解其中的每一行代码的具体含义,我们首先来看程序的入口再看调用方法内的代码->这段代码就是我们的模型内部,
整个代码的流程我会从模型的入口参数定义开始进行讲解, 然后顺序讲解在直到模型的结束。
true_data = pd.read_csv('ETTh1.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列这一步就是读取你的数据了~不给大家讲了主要是csv的格式数据。
target = 'OT' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 4 # 预测未来数据的长度
train_window = 32 # 观测窗口这一步就是参数定义的部分,讲解我已经再代码里标注了出来,需要说说的就是,pre_len和train_window这两个参数,
其中pre_len就是你预测未来数据的长度,假设你有一百条数据你想知道未来多少条数据的信息就填多少。
train_window是数据的观测窗口,就是你利用多少条数据去预测你定义的pre_len长度。
# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])这是提取出特征列,根据前面你定义的target。
# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)这部分是定义优化器,我们的深度学习模型输入一般都是-1到1(虽然这不是必须的,但是如果你不进行标准化处理效果真是天差地别),然后是测试集和训练集的划分,和根据数据进行标准化处理的操作,并且将数据转化为tensor的格式(tensor是我们深度学习特有的数据格式)。
# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)这一部分是重点!!!!!
时间序列的数据和其他领域的不一样他需要滑窗的数据形式,假设我有100条数据,前面定义的滑窗大小是32预测未来数据的长度是4那么他就会用32和4去滑动数据,
所以我们的到数据是多少呢就是100 - 32 - 4 =54条数据(每条数据包含32条观测数据和4个标签数据),这里必须理解大家这是时间序列的基础,他是不能够直接用Dataloader进行数据加载的。
# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)# 创建 DataLoader
batch_size = 32 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
这部分是创建数据集和Dataloader数据加载器,利用Dataloader的好处是可以避免内存爆炸,但是我们时间序列的数据一般都不大不会有这种情况。
class GRUConvNet(nn.Module):def __init__(self, input_size, hidden_size, num_layers, pre_len, output_size=1):super(GRUConvNet, self).__init__()# 可以外部定义的参数self.pre_len = pre_lenself.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.output_size = output_size# GRU层self.gru = nn.GRU(input_size=self.input_size, hidden_size=hidden_size, num_layers=self.num_layers,batch_first=True)self.gru_dropout = nn.Dropout(0.05)# 卷积层self.conv1 = nn.Conv1d(in_channels=self.input_size, out_channels=hidden_size, kernel_size=9, padding='same')self.bn1 = nn.BatchNorm1d(hidden_size)self.conv2 = nn.Conv1d(in_channels=hidden_size, out_channels=hidden_size * 2, kernel_size=6, padding='same')self.bn2 = nn.BatchNorm1d(hidden_size * 2)self.conv3 = nn.Conv1d(in_channels=hidden_size * 2, out_channels=hidden_size, kernel_size=3, padding='same')self.bn3 = nn.BatchNorm1d(hidden_size)self.global_avg_pool = nn.AdaptiveAvgPool1d(1)# 输出层self.fc1 = nn.Linear(self.hidden_size, self.output_size)self.fc1 = nn.Linear(self.hidden_size, self.output_size)def forward(self, x):# GRU层x_, _ = self.gru(x)x_ = self.gru_dropout(x_[:, :, :]) # 使用序列的最后一个输出# 卷积层y = x.permute(0, 2, 1)y = F.relu(self.bn1(self.conv1(y)))y = F.relu(self.bn2(self.conv2(y)))y = F.relu(self.bn3(self.conv3(y)))y = self.global_avg_pool(y)y = y.permute(0, 2, 1)# 合并GRU和卷积层的输出combined = torch.cat([x_, y], dim=1)# 输出层output = self.fc1(combined)return output[:, -self.pre_len:, :]讲完了初始化操作->我们再来看看正向传播里面的代码,里面的代码就是我们将输入先经过gru经过一个处理,然后取出它最后的一个时间步为预测值,然后我们将输入进去的值在输如给FCN里面里面进行处理经过三个不同大小的卷积处理以后输入到一个全局池化的操作(这个是现在常用的操作用全局池化代替全连接层进行输出),最后我们将GRU和FCN的输入经过拼接在输入给一个全连接层进行输出得到我们的预测值,大家有兴趣建议还是debug一下我这么讲你是不能理解的,最好还是实际动手debug看一下其中的通道数变化情况,我相信debug一遍你会收获非常多。
lstm_model = GRU(input_dim=1, output_dim=1, num_layers=2, hidden_dim=train_window, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测
这里实例化了我们的模型,定义了MSE损失函数,和优化器Adam和训练轮次,其中的Train是来判断是否进行训练。
if Train:losss = []lstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")如果Train为True则开始训练执行上面的代码,这是一个标准pytorch框架下的训练过程就不给大家 说了,如果不能理解的话大家可以去补补基础,或者评论区问我我在给大家讲讲。
else:# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式results = []reals = []losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)for j in range(batch_size):for i in range(pre_len):reals.append(labels[j][i][0].detach().numpy())results.append(pred[j][i][0].detach().numpy())如果Train为False时候则开始进行评估模式我们利用test的数据集进行测试评估训练模型,
reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]print("模型预测结果:", results)print("预测误差MAE:", losss)plt.figure()plt.style.use('ggplot')# 创建折线图plt.plot(reals, label='real', color='blue') # 实际值plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值# 增强视觉效果plt.grid(True)plt.title('real vs forecast')plt.xlabel('time')plt.ylabel('value')plt.legend()plt.savefig('test——results.png')这一部分是我们预测值和真实值之间的对比,来确定我们预测的好坏,后面的结果分析会有展示。
六、模型的训练和预测
上面我把大多数的代码都讲了一便大家应该对整个过程有一个大致的了解下面来大家进行训练看看模型的结果。
6.1模型的训练
我们将我前面提供的全部代码块复制粘贴到随便一个.py的文件内然后将数据集和特征数填写进去,就可以开始训练模型了。
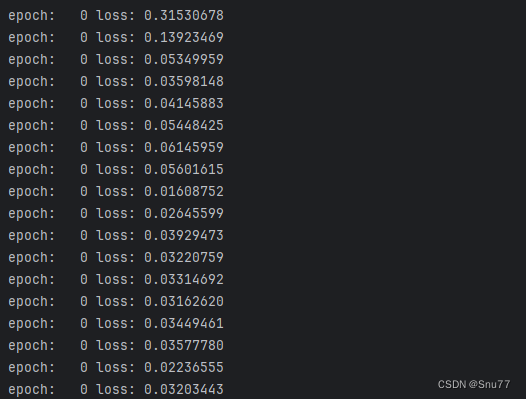
训练的过程中控制台会输出训练结果和损失,可以看到刚开始我们的损失非常的大,到训练结束之后我们的损失如下会变的非常小。
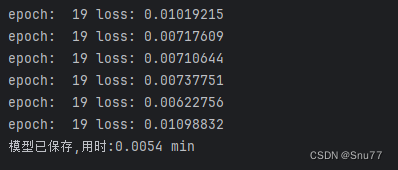
可以看到我们的模型损失只有0.01一个批次下可以说模型的拟合效果是非常的好,我们下面来看一下模型的损失图像,可以看到我们模型拟合速度比较一般在20个epoch左右在完全拟合,模型训练完成之后我们会在本地保存模型方便用于以后加载进行预测。
6.2模型的评估
经过训练之后我们可以开始进行模型的评估了。
6.2.1结果展示
下面的图片是模型的评估结果,其中评估数据大概有500条左右,可以看到这个模型的的效果只能说一般,和我上一个发的单层GRU的效果差不多。

其中预测的误差MAE大概在0.11和0.13之间。

6.2.2结果分析
这个模型结果我是没想到的本来以为会比上一个好一点,但是实际结果差不多,后续的工作呢差不多主要是解决数据滞后性的问题,(大家看其中的图像可以看到明显的数据滞后性),这一问题我在前面利用过ARIMA-LSTM进行解决进行了完美的解决,大家有兴趣可以去回去评估一下。
全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。
概念理解
15种时间序列预测方法总结(包含多种方法代码实现)
数据分析
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
机器学习——难度等级(⭐⭐)
时间序列预测实战(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
深度学习——难度等级(⭐⭐⭐⭐)
时间序列预测实战(五)基于Bi-LSTM横向搭配LSTM进行回归问题解决
时间序列预测实战(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测实战(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
时间序列预测实战(十一)用SCINet实现滚动预测功能(附代码+数据集+原理介绍)
时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
Transformer——难度等级(⭐⭐⭐⭐)
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(一)深度学习华为MTS-Mixers模型
时间序列预测实战(十三)定制化数据集FNet模型实现滚动长期预测并可视化结果
时间序列预测实战(十四)Transformer模型实现长期预测并可视化结果(附代码+数据集+原理介绍)
个人创新模型——难度等级(⭐⭐⭐⭐⭐)
时间序列预测实战(十)(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测
传统的时间序列预测模型(⭐⭐)
时间序列预测实战(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
时间序列预测实战(六)深入理解ARIMA包括差分和相关性分析
融合模型——难度等级(⭐⭐⭐)
时间序列预测实战(九)PyTorch实现融合移动平均和LSTM-ARIMA进行长期预测

相关文章:
时间序列预测实战(十六)PyTorch实现GRU-FCN模型长期预测并可视化结果
往期回顾:时间序列预测专栏——包含上百种时间序列模型带你从入门到精通时间序列预测 一、本文介绍 本文讲解的实战内容是GRU-FCN(门控循环单元-全卷积网络),这是一种结合了GRU(用于处理时间序列数据)和FCN(全卷积网络…...
如何提升软件测试效率?本文为你揭示秘密
在软件开发中,测试是至关重要的一个环节。它能帮助我们发现并修复问题,从而确保我们提供的软件具有高质量。然而,测试过程往往费时费力。那么,有没有方法可以提升我们的软件测试效率呢?答案是肯定的。下面,…...

参数估计和非参数估计
一、参数估计 参数估计是统计学中的一个重要概念,它涉及到使用样本数据来估计总体参数的过程。在统计学中,总体是指研究对象的整体集合,而样本是从总体中抽取的部分元素。 参数估计有两种主要方法:点估计和区间估计。 点估计&am…...
Apache Airflow (八) :DAG任务依赖设置
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...

使用 com.jacob.activeX 库实现 Word 到 PDF
使用 com.jacob.activeX 库实现 Word 到 PDF 的转换涉及到使用 Java 和 Microsoft Office 的 COM 自动化。JACOB(Java COM Bridge)库提供了一个桥接器,允许 Java 代码通过 COM(组件对象模型)与 Windows 应用程序&#…...

2023亚太杯数学建模思路 - 案例:FPTree-频繁模式树算法
文章目录 算法介绍FP树表示法构建FP树实现代码 建模资料 ## 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模式树算法,…...

Dart利用私有构造函数_()创建单例模式
文章目录 类的构造函数_()函数dart中构造函数定义 类的构造函数 类的构造函数有两种: 1)默认构造函数: 当实例化对象的时候,会自动调用的函数,构造函数的名称和类的名称相同,在一个类中默认构造函数只能由…...

简述如何使用Androidstudio对文件进行保存和获取文件中的数据
在 Android Studio 中,可以使用以下方法对文件进行保存和获取文件中的数据: 保存文件: 创建一个 File 对象,指定要保存的文件路径和文件名。使用 FileOutputStream 类创建一个文件输出流对象。将需要保存的数据写入文件输出流中…...
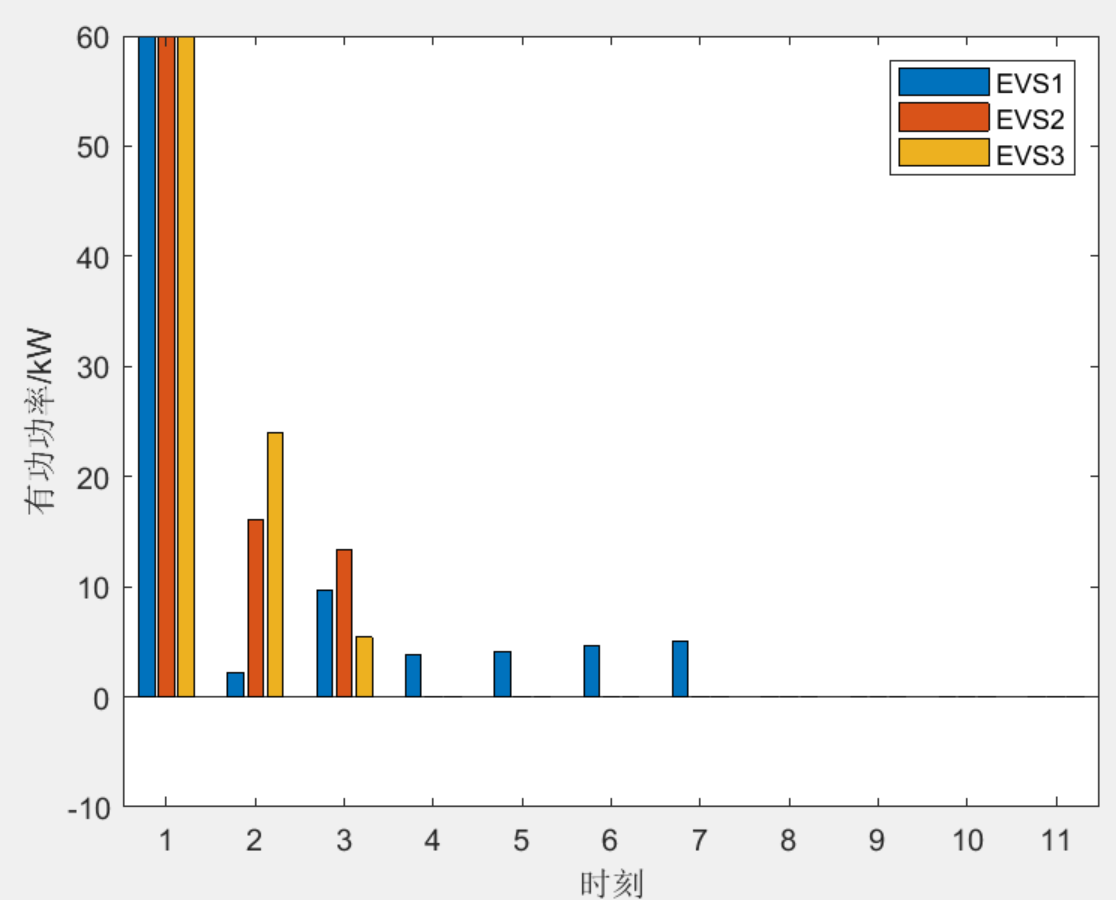
面向配电网韧性提升的移动储能预布局与动态调度策略(matlab代码)
欢迎关注威♥“电击小子程高兴的MATLAB小屋”获取更多资料 该程序复现《面向配电网韧性提升的移动储能预布局与动态调度策略》,具体摘要内容见下图,程序主要分为两大模块,第一部分是灾前预防代码,该部分采用两阶段优化算法&#…...
内网信息收集
目录 本机信息收集 查看系统配置信息 查看系统服务信息 查看系统登录信息 自动信息收集 域内信息收集 判断是否存在域 探测域内存主机&端口 powershell arp扫描 小工具 telnet 查看用户&机器&会话相关信息 查看机器相关信息 查看用户相关信息 免费领…...

windows cmd设置代理
https://blog.csdn.net/SHERLOCKSALVATORE/article/details/123599042...
)
English:small classified word(continuously update)
Distant family members(远亲) grandparents (外)祖父母 grandpa grandma grandchildren (外)孙女 aunt 姑姑 / 婶婶 / 姨 / 舅妈 uncle 叔叔 / 姑父 / 姨父/ 舅舅 niece 侄女 / 外甥女 nephew 侄子 / 外甥 cousin 堂 / 表兄弟姐妹 Appearance(外貌) …...
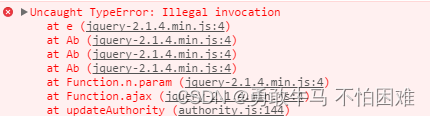
JQuery ajax 提交数据提示:Uncaught TypeError:Illegal invocation
JQuery ajax 提交数据提示:Uncaught TypeError:Illegal invocation 1 问题描述 用jQuery Ajax向DRF接口提交数据的时候,console提示:Uncaught TypeError:Illegal invocation(未捕获的异常:非法调用)。 这个问题可能有两种原因导…...
java实现选择排序
算法步骤 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。重复第二步,直到所有元素均排序完毕。 动图演…...

蓝桥杯 大小写转换
islower/isupper函数 islower和issupper是C标准库中的字符分类函数,用于检查一个字符是否为小写字母或大写字母 需要头文件< cctype>,也可用万能头包含 函数的返回值为bool类型 char ch1A; char ch2b; //使用islower函数判断字符是否为小写字母 if(islower(…...

在誉天学习华为认证,有真机吗
通过培训机构学习华为认证,特别是在HCIE的课程学习中,很多人关心的就是培训机构是否有真机能够进行华为认证的相关实验,今天我们一起来看看,在誉天学习华为认证,有真机吗? 誉天总部数据中心机房和誉天总部一…...
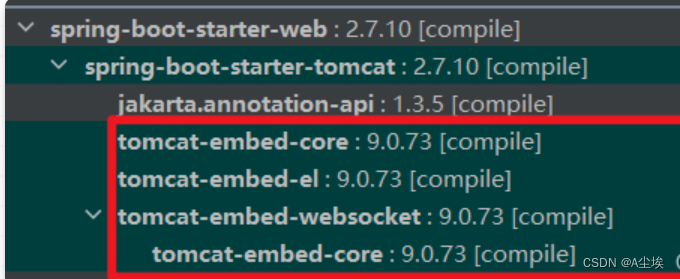
SpringBoot-配置文件properties/yml分析+tomcat最大连接数及最大并发数
SpringBoot配置文件 yaml 中的数据是有序的,properties 中的数据是无序的,在一些需要路径匹配的配置中,顺序就显得尤为重要(例如在 Spring Cloud Zuul 中的配置),此时一般采用 yaml。 Properties ①、位…...

07.智慧商城——商品详情页、加入购物车、拦截器封装token
01. 商品详情 - 静态布局 静态结构 和 样式 <template><div class"prodetail"><van-nav-bar fixed title"商品详情页" left-arrow click-left"$router.go(-1)" /><van-swipe :autoplay"3000" change"onCha…...

查看libc版本
查看libc库版本 查看系统libc版本 $ ldd --version ldd (Ubuntu GLIBC 2.27-3ubuntu1.2) 2.27 Copyright (C) 2018 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or …...

【电路笔记】-快速了解无源器件
快速了解无源器件 文章目录 快速了解无源器件1、概述2、电阻器作为无源器件3、电感器作为无源器件4、电容器作为无源器件5、总结 无源器件是电子电路的主要构建模块,没有它们,这些电路要么根本无法工作,要么变得不稳定。 1、概述 那么什么是…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...