2023年亚太杯数学建模思路 - 复盘:校园消费行为分析
文章目录
- 0 赛题思路
- 1 赛题背景
- 2 分析目标
- 3 数据说明
- 4 数据预处理
- 5 数据分析
- 5.1 食堂就餐行为分析
- 5.2 学生消费行为分析
- 建模资料
0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到 11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3 数据说明
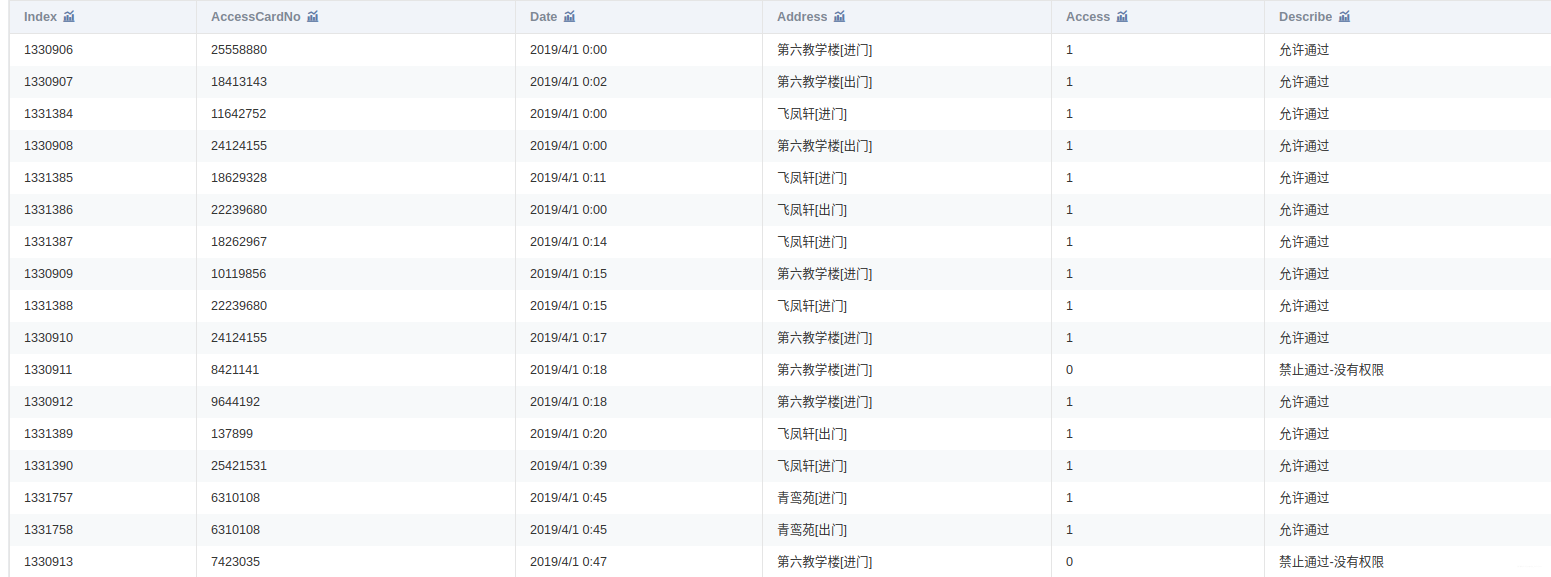
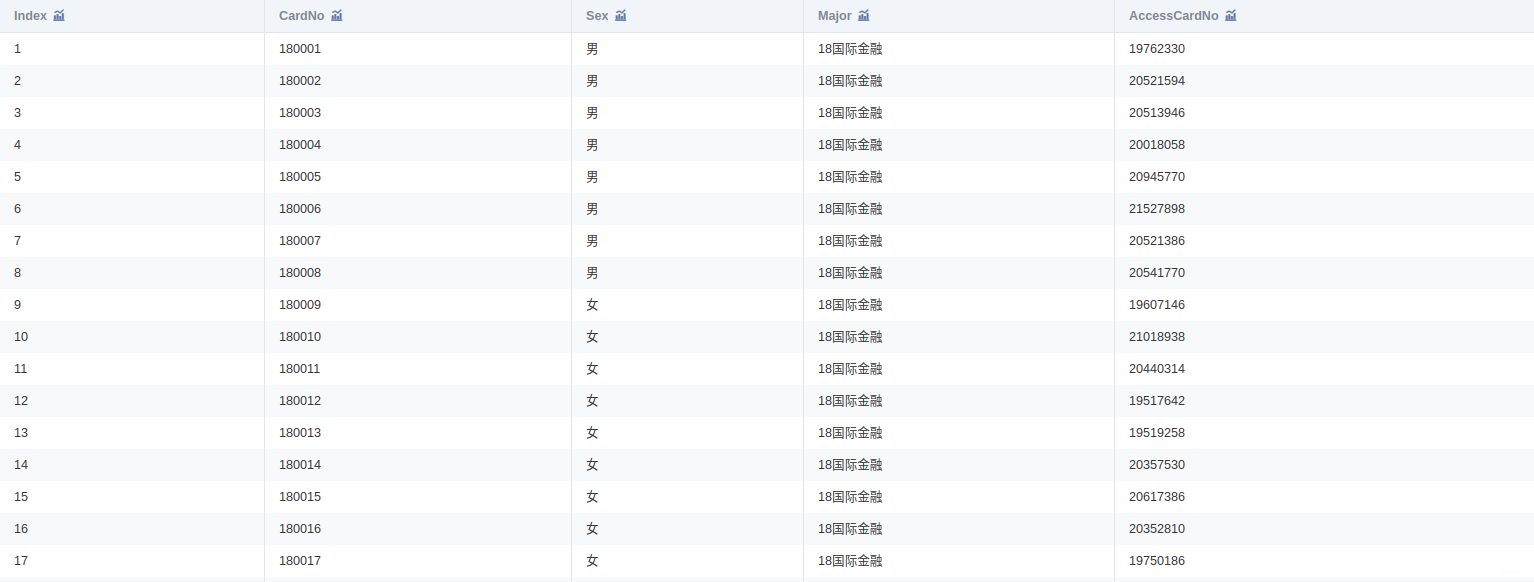
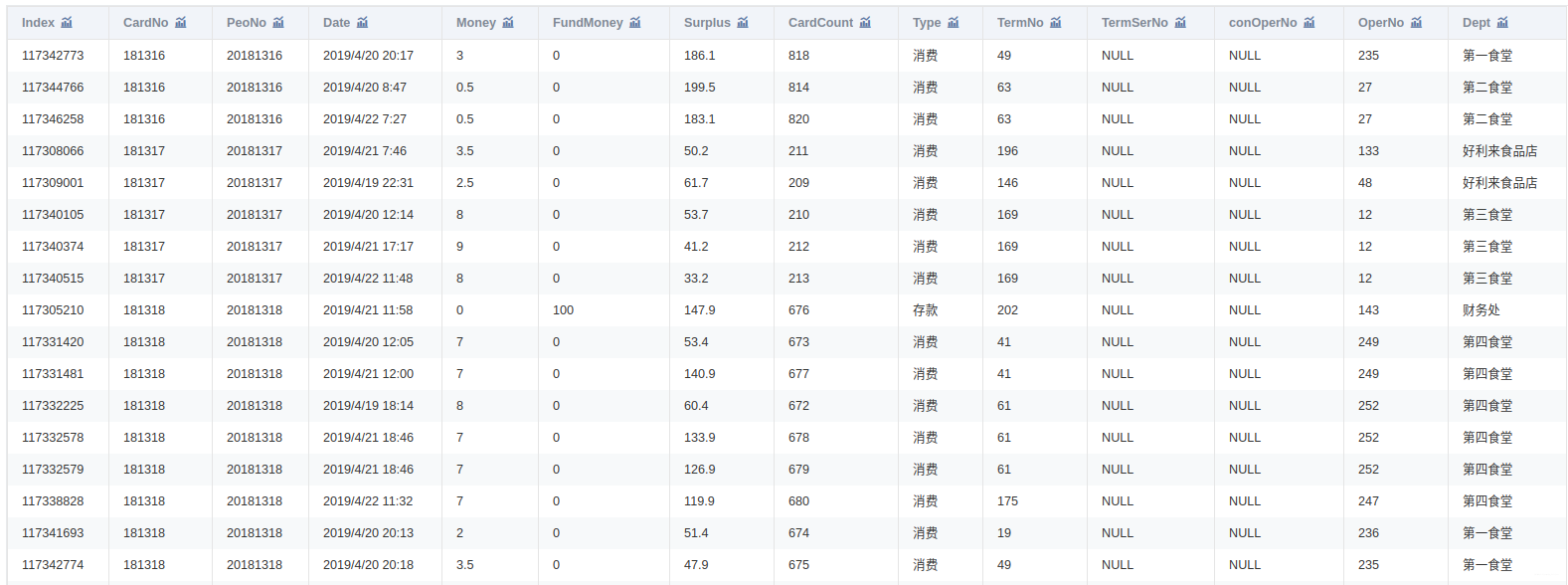
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
4 数据预处理
将附件中的 data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从 1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
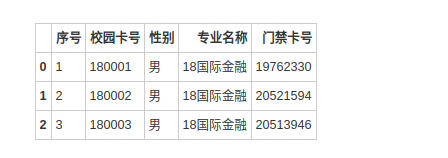
data1.head(3)
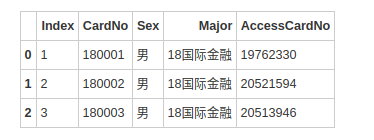
data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']
data1.dtypes

data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)

将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5 数据分析
5.1 食堂就餐行为分析
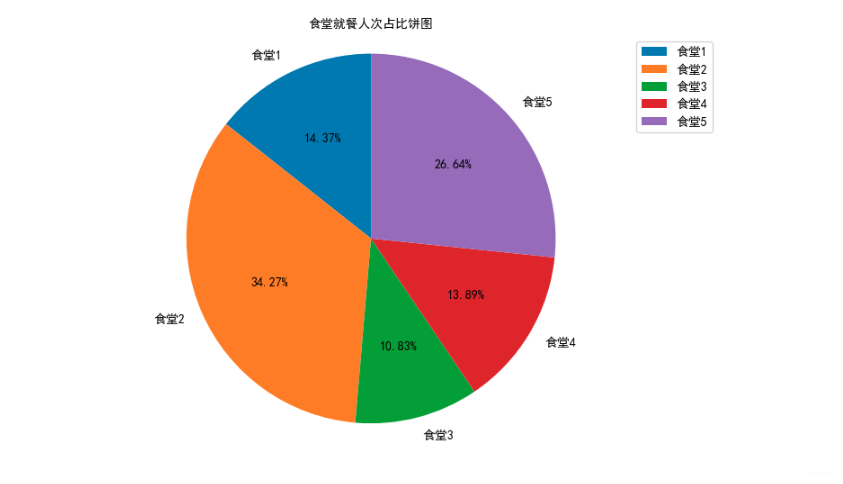
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消费地点'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消费地点'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消费地点'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消费地点'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消费地点'].apply(str).str.contains('第五食堂').sum()
# 绘制饼图
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
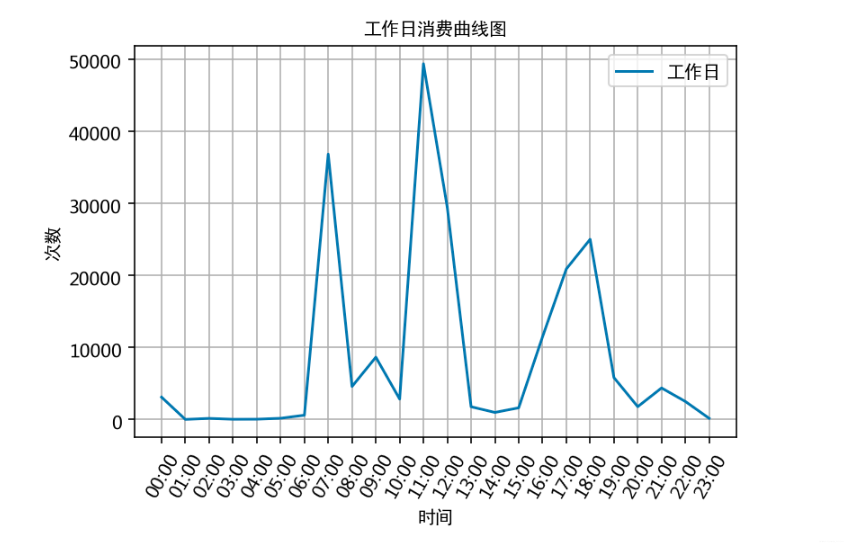
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。

# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,'消费时间'] = pd.to_datetime(data.loc[:,'消费时间'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data['消费星期'] = data['消费时间'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,'消费星期'] <= 5
unwork_day_query = data.loc[:,'消费星期'] > 5work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):work_day_times.append(work_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):x.append('{:02d}:00'.format(i))
# 绘图
plt.plot(x, work_day_times, label='工作日')
# x,y轴标签
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
# 标题
plt.title('工作日消费曲线图', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):unwork_day_times.append(unwork_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24): x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
plt.title('非工作日消费曲线图', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
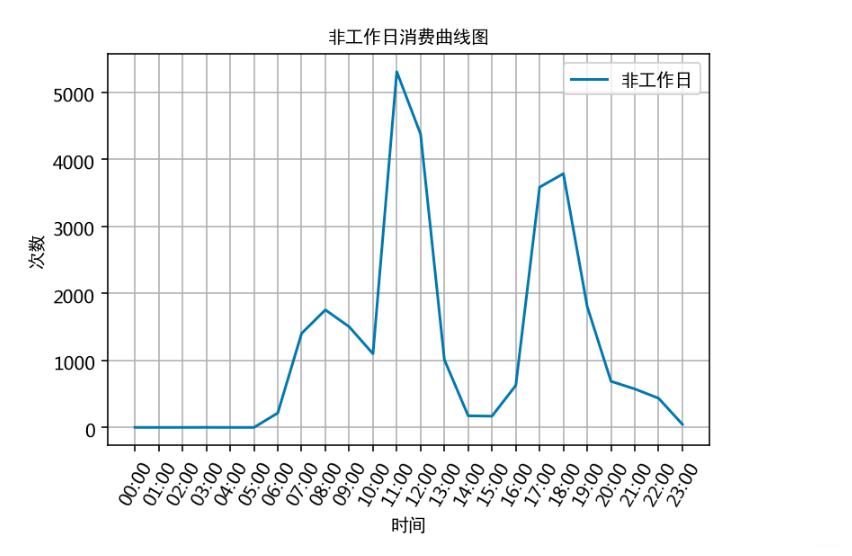
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data['消费时间'].count()
student_count = data['校园卡号'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data['消费金额'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money# 选择消费次数最多的3个专业进行分析
data['专业名称'].value_counts(dropna=False)
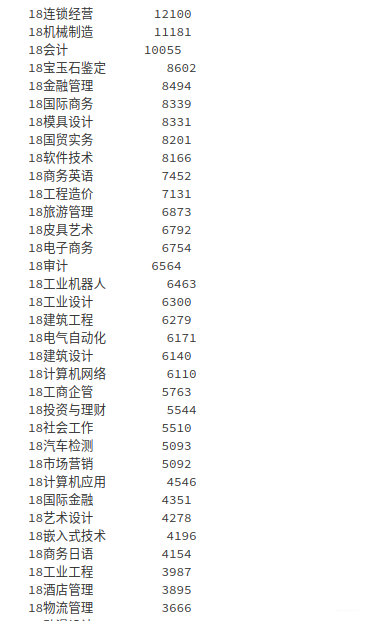
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data['专业名称'].apply(str).str.contains('18连锁经营')
major2 = data['专业名称'].apply(str).str.contains('18机械制造')
major3 = data['专业名称'].apply(str).str.contains('18会计')
major4 = data['专业名称'].apply(str).str.contains('18机械制造(学徒)')data_new = data[(major1 | major2 | major3) ^ major4]
data_new['专业名称'].value_counts(dropna=False)分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new['性别'] == '男']
data_female = data_new[data_new['性别'] == '女']
data_female.head()
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data['专业名称'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[['校园卡号','性别']].drop_duplicates().reset_index(drop=True)
data_1['性别'] = data_1['性别'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校园卡号'], inplace=True)
data_2 = data.groupby('校园卡号').sum()[['消费金额']]
data_2.columns = ['总消费金额']
data_3 = data.groupby('校园卡号').count()[['消费时间']]
data_3.columns = ['总消费次数']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + ['类别数目']# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby('校园卡号').sum()[['消费金额']]
data_500.sort_values(by=['消费金额'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校园卡号'].isin(data_500_index)]
data_500.head(10)
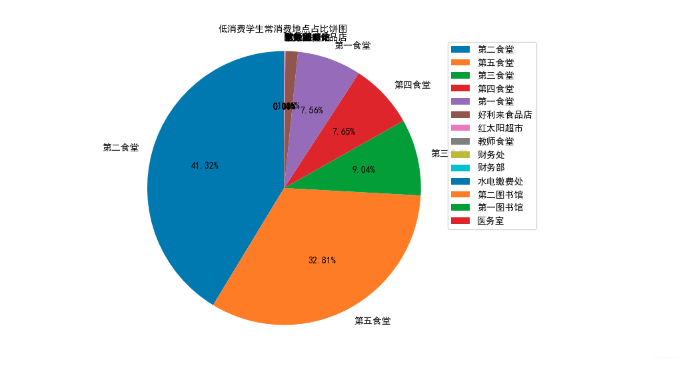
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
建模资料
资料分享: 最强建模资料


相关文章:
2023年亚太杯数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

ceph集群移除物理节点
1. 概述 ceph分布式存储在生产或者实验环境,经常涉及到物理节点加入或者删除,本文仅对移除物理节点的相关步骤做了操作记录,以方便需要时查阅。 2. 移除物理节点 2.1 out掉相应osd 操作之前通过ceph -s确保整个集群状态是OK的,…...
(八)Spring源码解析:Spring MVC
一、Servlet及上下文的初始化 1.1> DispatcherServlet的初始化 对于Spring MVC来说,最核心的一个类就是DispatcherServlet,它负责请求的行为流转。那么在Servlet的初始化阶段,会调用init()方法进行初始化操作,在DispatcherSe…...

maven或者gradle打完jar,jekins启动提示找不到问题
1、记录下遇到的一个问题,maven或者gradle打完jar,然后jekins发布,启动提示找不到实体类,mapper,xml问题 2、首先排查jar包中这些文件是否存在 3、然后排查每层的包名或者文件名是否能对应上 我这次遇到的问题就是本地…...

浏览器缓存sessionStorage、localStorage、Cookie
一、sessionStorage 1、简介 sessionStorage用于在浏览器会话期间存储数据,数据仅在当前会话期间有效。 存储的数据在用户关闭浏览器标签页或窗口后会被清除。 2、方法 使用sessionStorage.setItem(key, value)方法将数据存储在sessionStorage中。使用sessionSt…...

易点易动固定资产管理系统场景应用一:集成ERP/财务系统
在企业的日常运营中,固定资产管理是一个重要而繁琐的任务。传统的手工管理方式往往效率低下且容易出错,给企业带来不必要的成本和风险。为了解决这一问题,易点易动固定资产管理系统应运而生。本文将重点介绍易点易动固定资产管理系统在集成ER…...

k8s部署elk8 直接通过logstash获取日志文件方式
配置文件 kibana [rootnode101 config]# cat kibana.yml # # ** THIS IS AN AUTO-GENERATED FILE ** ## Default Kibana configuration for docker target server.host: "0.0.0.0" server.shutdownTimeout: "5s" elasticsearch.hosts: [ "http:/…...

git 本地多个账号错乱问题解决
当我们在本地有多个git账号时,例如公司的gitlab有一个git账号,自己的开源项目有一个GitHub账号,我们可能会出现账号错乱的情况,例如提交到公司gitlab的代码是github账号 这种情况通常是由于您的git config配置文件中的用户信息未…...

wu-ui-uniapp 多平台快速开发的UI框架
WU-UI 多平台快速开发的UI框架(无论平台,一致体验) 官方群 wu-ui官方1群: 767943089 说明 wu-ui(如虎添翼) 是 全面兼容多端的uniapp生态框架,基于vue2、vue3和nvue开发。丰富组件库,便捷工具库,简单高效。无论平台&#x…...
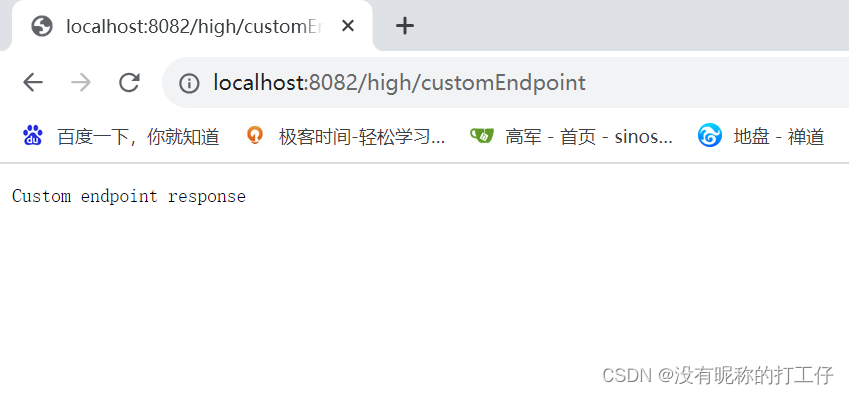
Spring Boot Actuator:自定义端点
要在Spring Boot Actuator中实现自定义端点,可以按照以下步骤进行操作: 1.创建一个自定义端点类 该类需要使用Endpoint注解进行标记,并使用Component注解将其作为Spring Bean进行管理。 package com.example.highactuator.point;import lo…...
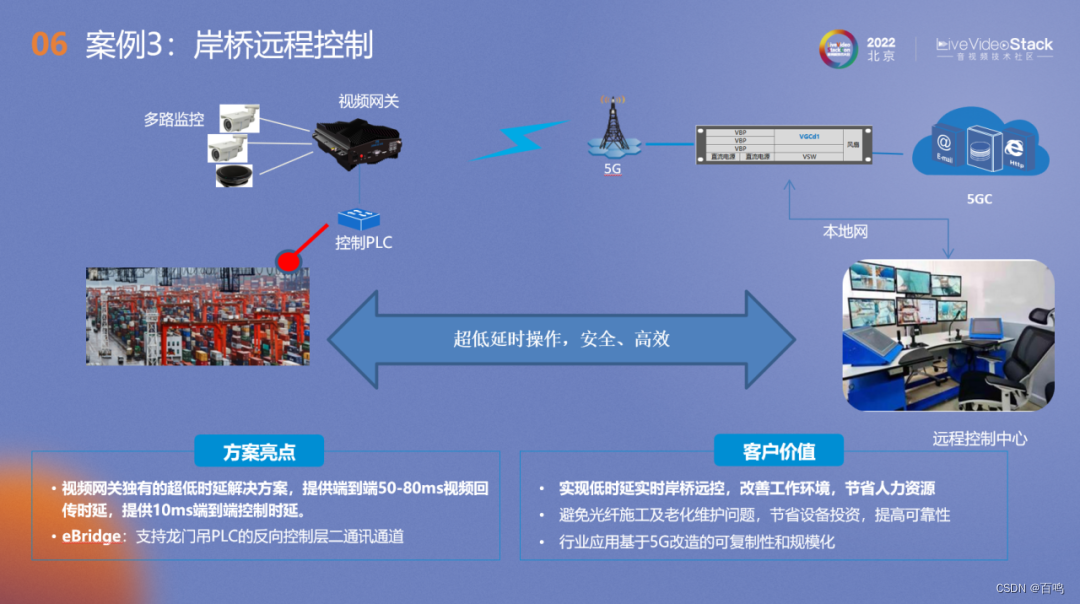
实时音视频方案汇总
若有好的方案欢迎留言讨论,非常感谢,汇总了一些,从市面上了解的一些低时延的端到端的方案,仅供参照,若有问题,也欢迎留言更正! 方案 方案描述 时延 备注 1大华同轴高清电缆200米电缆…...

vue3.0中实现excel文件的预览
最近开发了一个需求,要求实现预览图片、pdf、excel、word、txt等格式的文件; 每种格式的文件想要实现预览的效果需要使用对应的插件,如果要实现excel格式文件的预览,要用到哪种插件呢? 答案:xlsx.full.min…...

信息学奥赛一本通 1435:【例题3】曲线 | 洛谷 洛谷 P1883 函数
【题目链接】 ybt 1435:【例题3】曲线 洛谷 P1883 函数 【题目考点】 1. 三分 【解题思路】 每个 S i ( x ) S_i(x) Si(x)是一个二次函数, F ( x ) m a x ( S i ( x ) ) F(x) max(S_i(x)) F(x)max(Si(x)),即为所有二次函数当自变量…...

OpenCV入门2——图像视频的加载与展示一些API
文章目录 题目OpenCV创建显示窗口OpenCV加载显示图片题目 OpenCV保存文件利用OpenCV从摄像头采集视频从多媒体文件中读取视频帧将视频数据录制成多媒体文件OpenCV控制鼠标关于[np.uint8](https://stackoverflow.com/questions/68387192/what-is-np-uint8) OpenCV中的TrackBar控…...

「校园 Pie」 系列活动正式启航,首站走进南方科技大学!
PieCloudDB 社区校园行系列活动「校园 Pie」已正式启动。「校园 Pie」旨在促进数据库领域的学术交流,提供一个平台让学生们了解最新的数据库发展趋势和相关技术应用。 在「校园 Pie」系列活动中,PieCloudDB 社区将携拓数派技术专家,社区大咖…...
【PyQt小知识 - 3】: QComboBox下拉框内容的设置和更新、默认值的设置、值和下标的获取
QComboBox 内容的设置和更新 from PyQt5.QtWidgets import * import sysapp QApplication(sys.argv)mainwindow QMainWindow() mainwindow.resize(200, 200) # 设置下拉框 comboBox QComboBox(mainwindow) comboBox.addItems([上, 中, 下])button QPushButton(更新, main…...

Oracle OCM考试(史上最详细的介绍,需要19c OCP的证书)
Oracle 19c OCM考试和之前版本的OCM考试差不多,对于考生来说最大的难点是题量大,每场3小时,一共4场,敲键盘敲得手抽筋。姚远老师(v:dataace)的很多Oracle OCP学员都对19c OCM考试很有兴趣,这里给…...

广州华锐互动VRAR:VR教学楼地震模拟体验增强学生防震减灾意识
在当今社会,地震作为一种自然灾害,给人们的生活带来了巨大的威胁。特别是在学校这样的集体场所,一旦发生地震,后果将不堪设想。因此,加强校园安全教育,提高师生的防震减灾意识和能力,已经成为了…...

?. 语法报错
报错 Syntax Error: SyntaxError: E:xxx\src\views\xxx.vue: Support for the experimental syntax ‘optionalChaining’ isn’t currently enabled (173:27): 171 | label: node.label, 172 | style: { 173 | fill: colorSet?.mainFill || ‘#DEE9FF’, | ^ 174 | stroke: …...
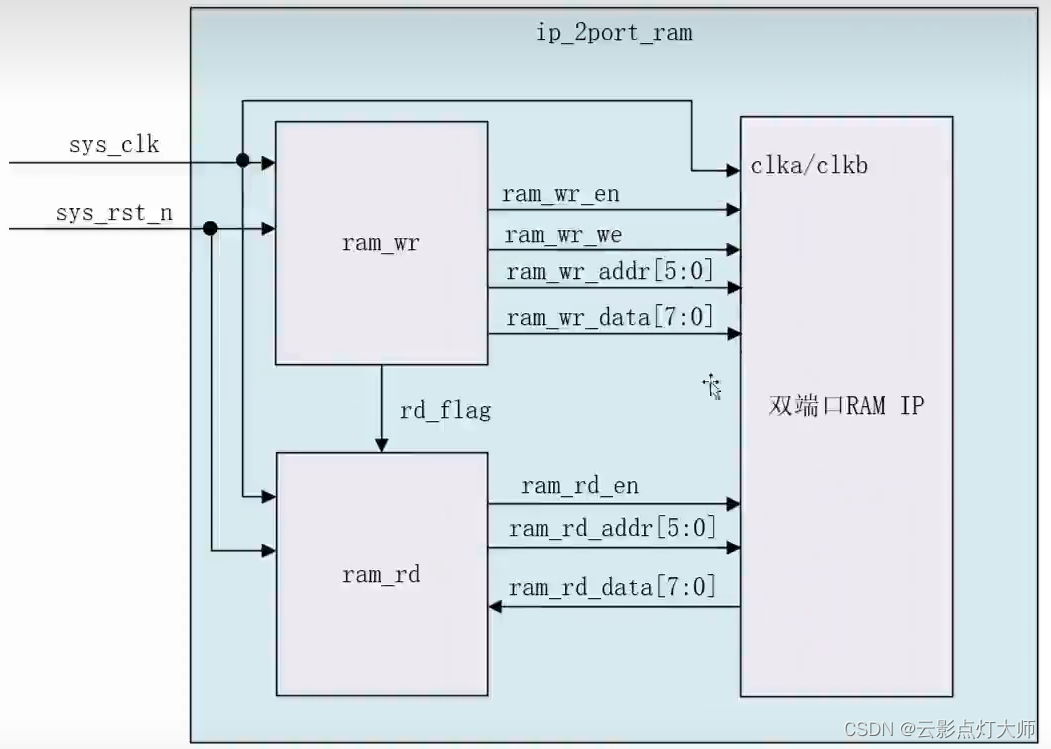
FPGA——IP核 基础操作
FPGA——IP核 基础操作 IP核例化模块时钟IP核RAM IP核 IP核例化模块 找到模版 加入代码中 时钟IP核 配置模式功能 配置输入时钟 输出配置 RAM IP核...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...