大数据基础设施搭建 - Hadoop
文章目录
- 一、下载安装包
- 二、上传压缩包
- 三、解压压缩包
- 四、配置环境变量
- 五、测试Hadoop
- 5.1 测试hadoop命令
- 5.2 测试wordcount案例
- 5.2.1 创建wordcount输入文本信息
- 5.2.2 执行程序
- 5.2.3 查看结果
- 六、分发压缩包到集群中其他机器
- 6.1 分发压缩包
- 6.2 解压压缩包
- 6.3 配置环境变量
- 七、配置集群
- 7.1 核心配置文件
- 7.2 HDFS配置文件
- 7.3 YARN配置文件
- 7.4 MapReduce配置文件
- 7.5 分发配置文件
- 八、启动集群
- 8.1 编辑workers文件确定数据节点
- 8.2 启动集群
- 步骤1: 格式化NameNode(首次启动集群时)
- 步骤2:启动HDFS
- 步骤3:启动YARN
- 步骤4:测试WEB访问
- (1)配置阿里云安全组
- (2)浏览器访问
- 九、测试集群
- 9.1 上传文件
- 9.2 查看文件
- 9.3 下载文件
- 9.4 执行程序
- 十、配置历史服务器
- 10.1 修改配置文件
- 10.2 分发配置文件
- 10.3 启动历史服务器
- 10.4 访问WEB
- 十一、配置日志的聚集
- 11.1 修改配置文件
- 11.2 分发配置文件
- 11.3 重启NM、RM、HistoryServer
- 11.4 测试
- (1)删除HDFS已经存在的输出文件
- (2)执行WordCount程序
- (3)查看日志
一、下载安装包
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
二、上传压缩包
使用普通账号,上传到/opt/software目录
三、解压压缩包
使用普通账号
[hadoop@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
四、配置环境变量
[hadoop@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让新的环境变量PATH生效:
[hadoop@hadoop102 hadoop-3.1.3]$ source /etc/profile
五、测试Hadoop
5.1 测试hadoop命令
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop version
5.2 测试wordcount案例
5.2.1 创建wordcount输入文本信息
[hadoop@hadoop102 hadoop-3.1.3]$ mkdir wcinput
[hadoop@hadoop102 hadoop-3.1.3]$ cd wcinput/
[hadoop@hadoop102 wcinput]$ vim word.txt
内容:
hadoop yarn
hadoop mapreduce
vimgo
jbl jbl jbl
5.2.2 执行程序
[hadoop@hadoop102 hadoop-3.1.3]$ cd /opt/module/hadoop-3.1.3
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput/
5.2.3 查看结果
[hadoop@hadoop102 hadoop-3.1.3]$ cd wcoutput/
[hadoop@hadoop102 wcoutput]$ cat part-r-00000
hadoop 2
jbl 3
mapreduce 1
vimgo 1
yarn 1
六、分发压缩包到集群中其他机器
6.1 分发压缩包
[hadoop@hadoop102 module]$ cd /opt/software/
[hadoop@hadoop102 software]$ mytools_rsync hadoop-3.1.3.tar.gz
6.2 解压压缩包
同第三步骤
6.3 配置环境变量
同第四步骤
七、配置集群
有两种类型的配置文件:*-default.xml 和 *-site.xml。 *-site.xml 中的配置项覆盖 *-default.xml的相同配置项。
7.1 核心配置文件
core-default.xml:默认的核心Hadoop属性配置文件。该配置文件位于下面的JAR文件中:hadoop-common-x.x.x.jar
[hadoop@hadoop102 software]$ cd $HADOOP_HOME/etc/hadoop
[hadoop@hadoop102 hadoop]$ vim core-site.xml
新增内容:
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:9820</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为hadoop --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property><!-- 配置该hadoop用户(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><!-- 配置该hadoop用户(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><!-- 配置该hadoop用户(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.hadoop.users</name><value>*</value></property>
说明:
fs.defaultFS:文件系统地址。可以是HDFS,也可以是ViewFS等其他文件系统。
hadoop.tmp.dir:默认值为/tmp/hadoop-${user.name}。比如跑MR时生成的临时路径本质上其实就是生成在它的下面,当然如果你不想也可以去更改 mapred-site.xml 文件。再比如,如果你不配置namenode和datanode的数据存储路径,那么默认情况下,存储路径会放在hadoop.tmp.dir所指路径下的dfs路径中。
hadoop.http.staticuser.user:默认值是dr.who。需要调整为启动HDFS的用户(普通用户/root),才能访问(增删文件/文件夹)WEB HDFS。
代理配置:hadoop.proxyuser.hadoop.hosts必须配,hadoop.proxyuser.hadoop.groups和hadoop.proxyuser.hadoop.users至少配置一个。如果不配置代理会有什么问题?????
hadoop.proxyuser.hadoop.hosts和hadoop.proxyuser.hadoop.users:本案例配置表示允许用户hadoop,在任意主机节点,代理任意用户。
7.2 HDFS配置文件
hdfs-default.xml:默认的HDFS属性配置文件。该配置文件位于下面的JAR文件中:hadoop-hdfs-x.x.x.jar
[hadoop@hadoop102 hadoop]$ vim hdfs-site.xml
新增内容:
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
7.3 YARN配置文件
yarn-default.xml:默认的YARN属性配置文件。该配置文件位于下面的JAR文件中:hadoop-yarn-common-x.x.x.jar
[hadoop@hadoop102 hadoop]$ vim yarn-site.xml
新增内容:
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
说明:
yarn.nodemanager.env-whitelist:默认JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ
yarn.scheduler.minimum-allocation-mb:单位为MB
7.4 MapReduce配置文件
mapred-default.xml:默认的MapReduce属性配置文件。该配置文件位于下面的JAR文件中:hadoop-mapreduce-client-core-x.x.x.jar
[hadoop@hadoop102 hadoop]$ vim mapred-site.xml
新增内容:
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
说明:
mapreduce.framework.name 默认值为 local,设置为 yarn,让 MapReduce 程序运行 在 YARN 框架上。
7.5 分发配置文件
[hadoop@hadoop102 hadoop]$ mytools_rsync /opt/module/hadoop-3.1.3/etc/hadoop/
八、启动集群
8.1 编辑workers文件确定数据节点
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
[hadoop@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
内容:
hadoop102
hadoop103
hadoop104
同步到所有节点:
[hadoop@hadoop102 hadoop]$ mytools_rsync /opt/module/hadoop-3.1.3/etc/
8.2 启动集群
步骤1: 格式化NameNode(首次启动集群时)
注意:在NameNode所在节点(core-site.xml中配置的)执行命令
原因:先前在care_site.xml中配置了文件系统为HDFS,HDFS类似一块磁盘,初次使用硬盘需要格式化,让存储空间明白该按什么方式组织存储数据。
[hadoop@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
看到下图样例代表格式化成功

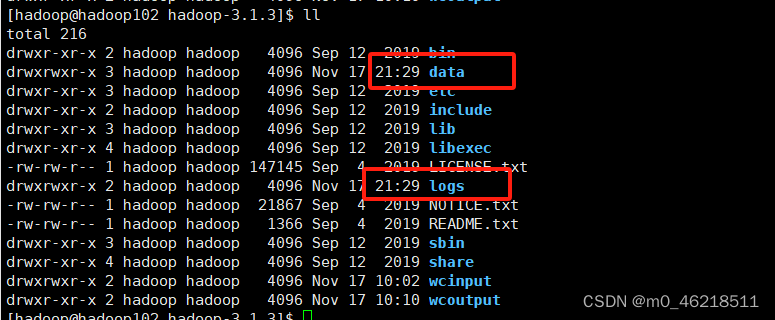
步骤2:启动HDFS
注意:在NameNode所在节点执行命令
[hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
步骤3:启动YARN
注意:在ResourceManager所在节点(yarn-site.xml中配置的)执行命令
[hadoop@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
步骤4:测试WEB访问
(1)配置阿里云安全组
查看本机ip:百度搜索ip
配置阿里云安全组放开ip + 端口
配置本机hosts文件:用swichhosts配置
(2)浏览器访问
Web端查看HDFS的NameNode:http://hadoop102:9870
Web端查看YARN的ResourceManager:http://hadoop103:8088
九、测试集群
9.1 上传文件
上传小文件:
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/wcinput/word.txt /input
上传大文件:
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/software/jdk-8u291-linux-x64.tar.gz /
9.2 查看文件
[hadoop@hadoop102 subdir0]$ cat /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-343847855-172.28.76.203-1700227787497/current/finalized/subdir0/subdir0/blk_1073741825
9.3 下载文件
[hadoop@hadoop102 software]$ cd /opt/software/test_tmp
[hadoop@hadoop102 test_tmp]$ hadoop fs -get /input ./
9.4 执行程序
[hadoop@hadoop102 software]$ cd /opt/module/hadoop-3.1.3/
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
查看执行结果(通过WEB页面下载执行结果文件):
配置安全组:放开9864端口
访问HDFS WEB下载文件
查看执行结果(在服务器上直接查看文件):
cat /opt/module/hadoop-3.1.3/data/xxx
十、配置历史服务器
10.1 修改配置文件
10.2 分发配置文件
10.3 启动历史服务器
10.4 访问WEB
十一、配置日志的聚集
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
11.1 修改配置文件
11.2 分发配置文件
11.3 重启NM、RM、HistoryServer
11.4 测试
(1)删除HDFS已经存在的输出文件
(2)执行WordCount程序
(3)查看日志
相关文章:
大数据基础设施搭建 - Hadoop
文章目录 一、下载安装包二、上传压缩包三、解压压缩包四、配置环境变量五、测试Hadoop5.1 测试hadoop命令5.2 测试wordcount案例5.2.1 创建wordcount输入文本信息5.2.2 执行程序5.2.3 查看结果 六、分发压缩包到集群中其他机器6.1 分发压缩包6.2 解压压缩包6.3 配置环境变量 七…...
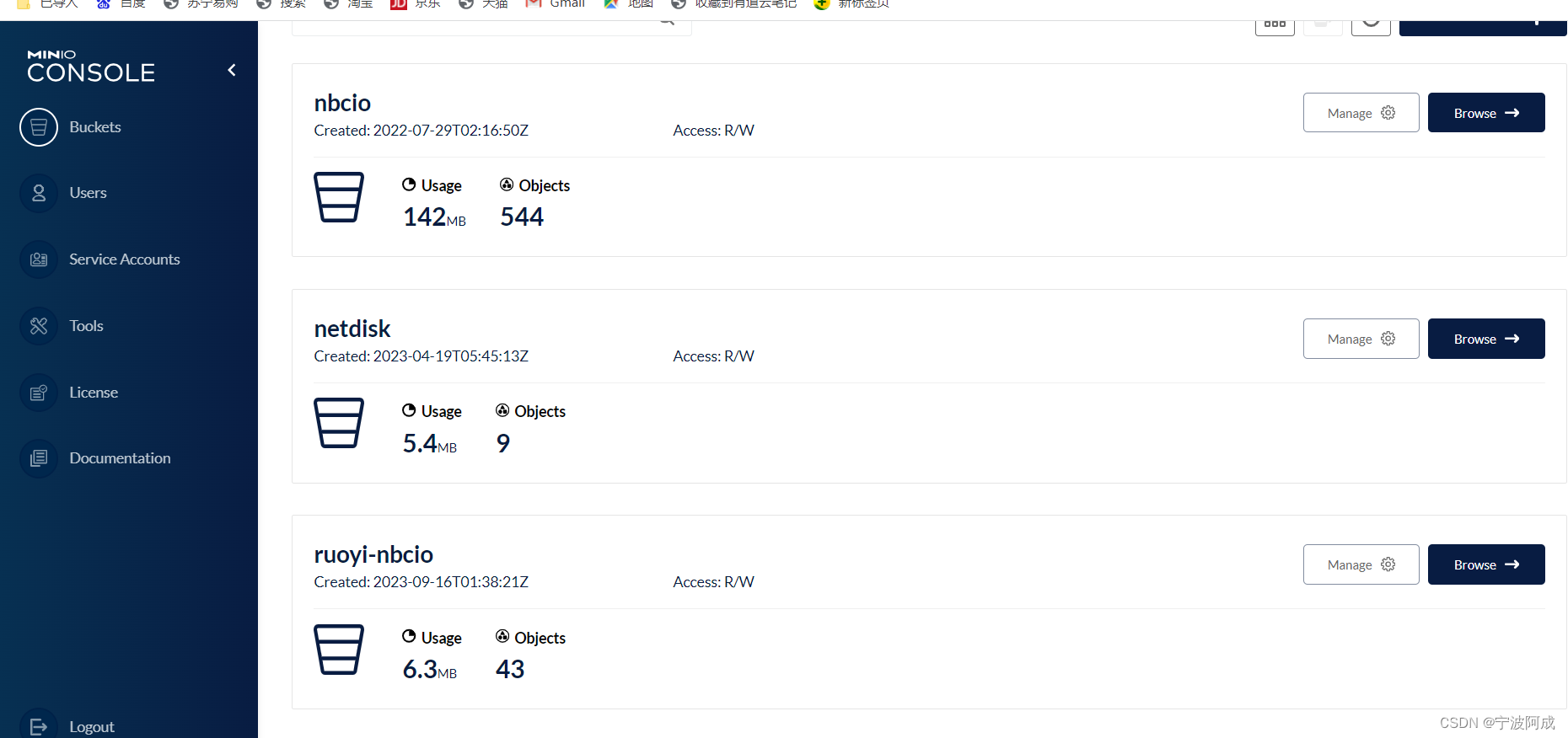
测试开发环境下centos7.9下安装docker的minio
按照以下方法进行 1、安装docker,要是生产等还是要按照docker-ce yum install docker 2、启动docker service docker start 3、 查看docker信息 docker info 4、加到启动里 systemctl enable docker.service 5、开始docker pull minio/minio 但报错&#x…...

Django之模版层
目录 一、常用语法 二、模版语法之变量 三、模板之过滤器(Filters) 【1】default 【2】length 【3】filesizeformat 【4】slice 【5】date 【6】safe 【7】truncatechars 【8】其它过滤器(了解) 四、模版之标签 【1】for标签 【2】if 标签…...
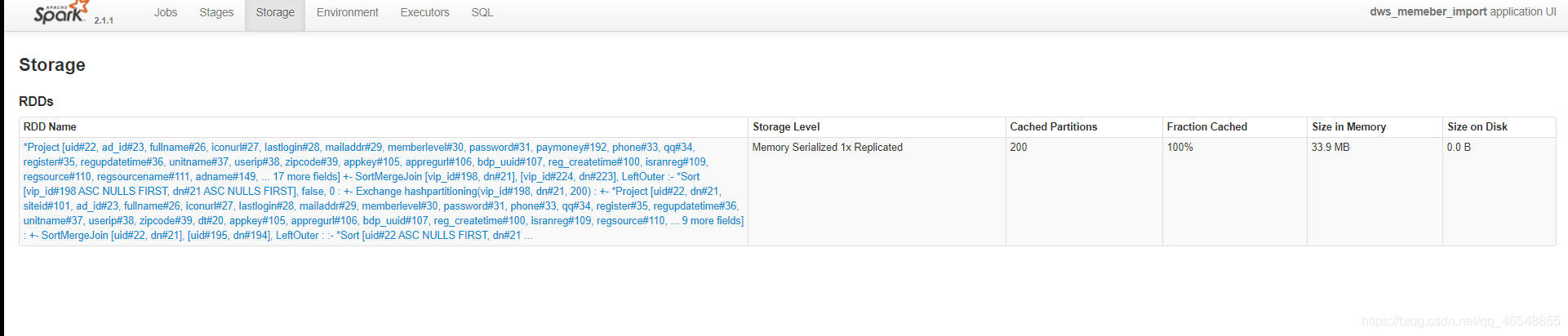
spark性能调优 | 内存优化
目录 我们先了解一下有哪些内存温馨提示RDD示范(spark版本2.1.1)RDD进行优化Df和Ds进行示范 我们先了解一下有哪些内存 1.storage内存 存储数据,缓存 可预估2.shuffle内存 计算join groupby 不可预估spark1.6之前 静态管理的,spark1.6之…...

【PG】PostgreSQL高可用之自动故障转移-repmgrd
前言 上面的几篇文章介绍了repmgr的部署,手动进行 从节点提升,主从切换,孤立从从节点找到新的主库等操作,但是都是需要通过手动去执行命令。大家都知道,在线上生产环境中数据库每秒钟的不可用都会造成严重的事故&am…...
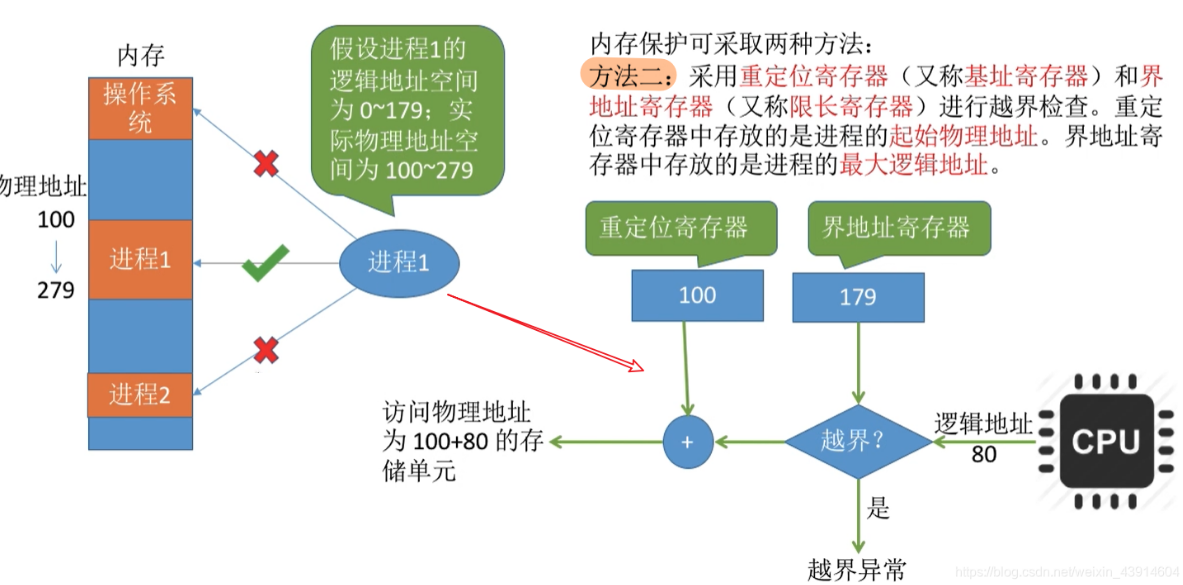
操作系统OS/存储管理/内存管理/内存管理的主要功能_基本原理_要求
基本概念 内存管理的主要功能/基本原理/要求 **内存管理的主要功能: ** 内存空间的分配与回收。由操作系统完成主存储器空间的分配和管理,使程序员摆脱存储分配的麻烦,提高编程效率。地址转换。在多道程序环境下,程序中的逻辑地…...

【手写数据库toadb】SQL解析器的实现架构,create table/insert 多values语句的解析树生成流程和输出结构分析
SQL解析器架构和实现 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方…...
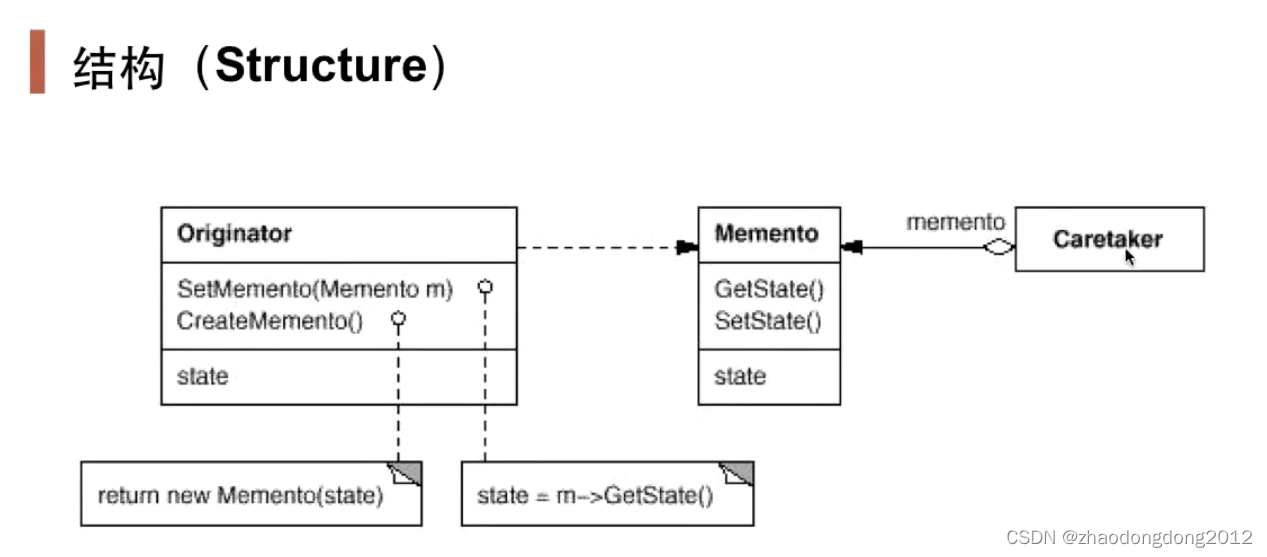
设计模式-备忘录模式-笔记
动机(Motivation) 在软件构建过程中,某些对象的状态在转换过程中,可能由于某种需要,要求程序能够回溯到对象之前处于某个点时的状态。如果使用一些公有接口来让其他对象得到对象的状态,便会暴露对象的细节…...
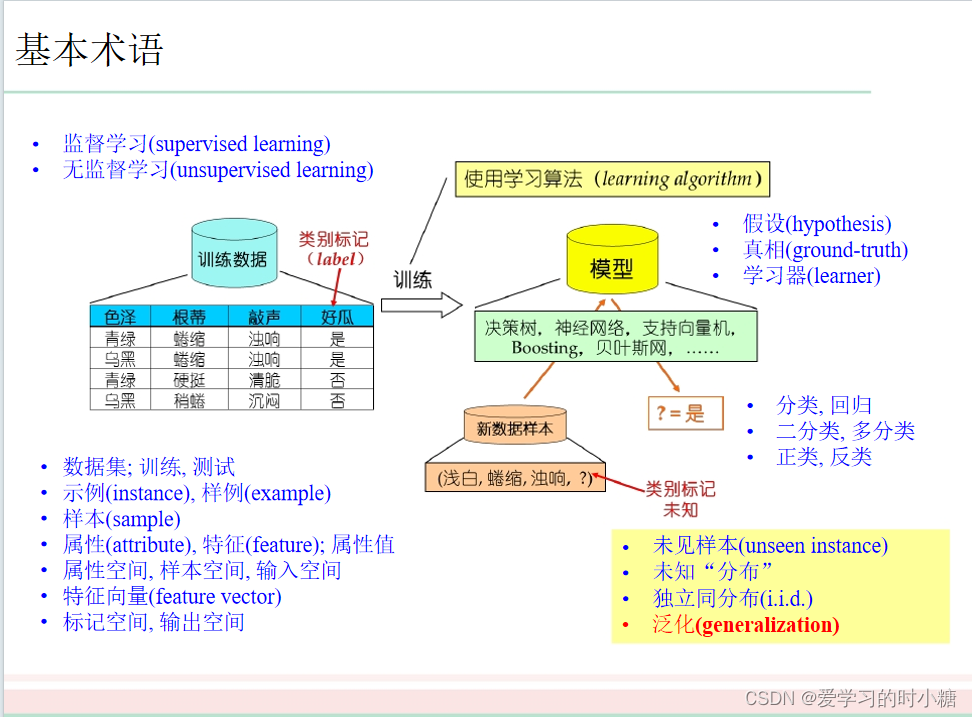
机器学习—基本术语
目录 1.样本(示例) 2.属性 3.属性值 4.属性空间 5.样本空间 6.学习(训练) 7.数据集 8.测试 9.假设 10.学习器 11.标记 12.样例 13.标记空间(样例空间) 14.分类与回归 15.有监督学习、无监督…...

pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed(环境没搞起来)模型训练代码,并对比不同方法的训练速度以及GPU内存的使用 代码:pytorch_model_train FairScale(你真…...
基于PHP的纺织用品商城系统
有需要请加文章底部Q哦 可远程调试 基于PHP的纺织用品商城系统 一 介绍 此纺织用品商城系统基于原生PHP开发,数据库mysql,前端bootstrap。用户可注册登录,购物下单,评论等。管理员登录后台可对纺织用品,用户…...

Go使用命令行输出二维码
引言 二维码(QR code)是一种矩阵条码的标准,广泛应用于商业、移动支付和数据存储等领域。在开发过程中,我们可能需要在命令行中显示二维码,这可以帮助我们快速生成和分享二维码信息。本文将介绍如何使用Go语言生成二维…...

最长连续序列[中等]
优质博文:IT-BLOG-CN 一、题目 给定一个未排序的整数数组nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为O(n)的算法解决此问题。 示例 1: 输入:nums […...
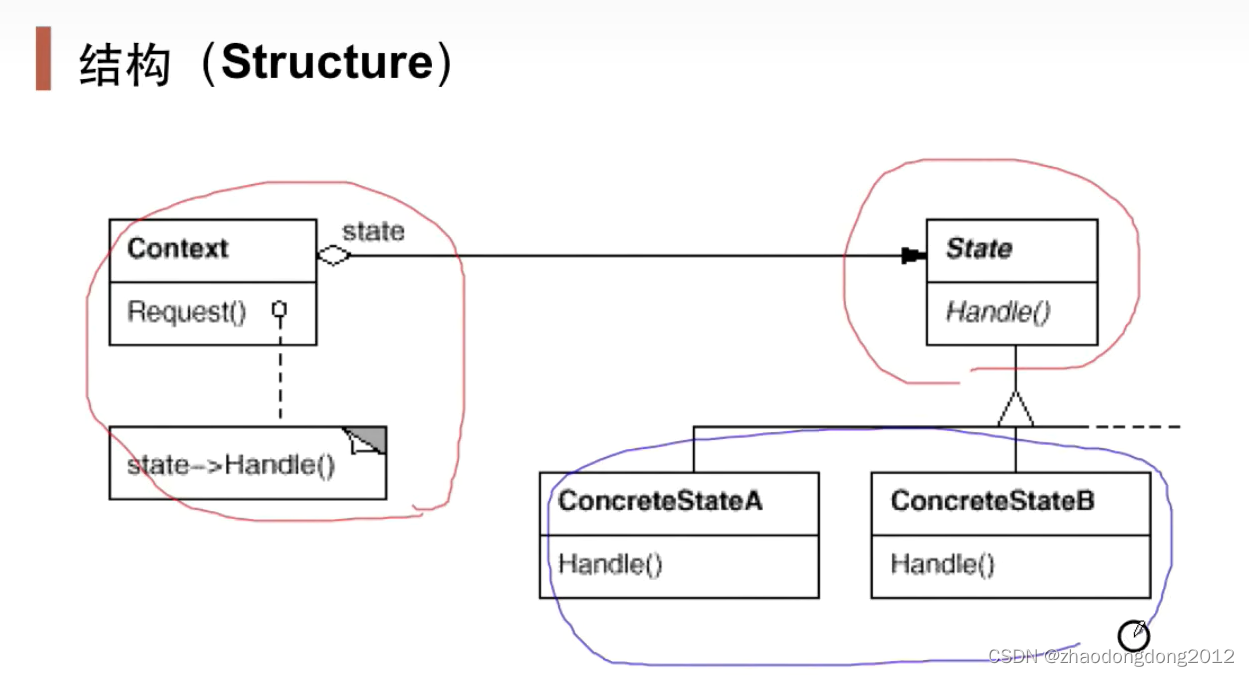
设计模式-状态模式-笔记
状态模式State 在组件构建过程中,某些对象的状态经常面临变化,如何对这些变化进行有效的管理?同时又维持高层模块的稳定?“状态变化”模式为这一问题提供了一种解决方案。 经典模式:State、Memento 动机(…...

Java中for、foreach、stream区别和性能比较
文章目录 性能比较区别使用方式和行为 性能比较 最终总结:如果数据在1万以内的话,for循环效率高于foreach和stream;如果数据量在10万的时候,stream效率最高,其次是foreach,最后是for。另外需要注意的是如果数据达到10…...
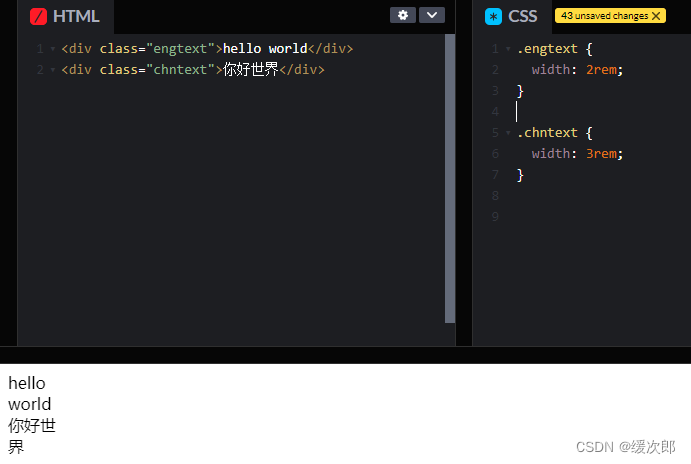
[CSS] 文本折行
文本折行一般分为两种情况: CJK(Chinese/Japanese/Korean) 字符和非 CJK 字符。一般非 CJK 字符折行发生在两个单词的空格中间,见下图: 图中文本 “hello world” 包裹容器的宽度为 2rem,但是 hello 并没有…...
)
033-从零搭建微服务-日志插件(一)
写在最前 如果这个项目让你有所收获,记得 Star 关注哦,这对我是非常不错的鼓励与支持。 源码地址(后端):mingyue: 🎉 基于 Spring Boot、Spring Cloud & Alibaba 的分布式微服务架构基础服务中心 源…...
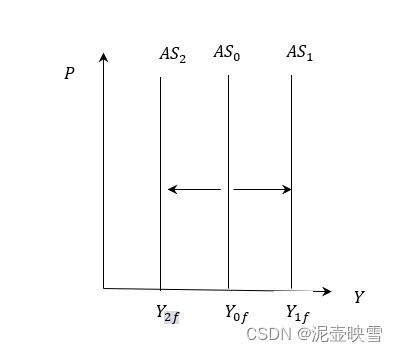
短期经济波动:均衡国民收入决定理论(三)
短期经济波动:国民收入决定理论(三) 文章目录 短期经济波动:国民收入决定理论(三)[toc]1 总需求曲线及其变动1.1 总需求曲线含义1.2 总需求曲线推导1.2.1 代数推导1.2.2 几何推导 1.3 AD曲线及其变动1.3.1 扩张性财政政策1.3.2 扩张性货币政策 2 总供给曲…...

电力感知边缘计算网关产品设计方案-网关软件架构
边缘计算网关采用ARM定制硬件平台架构,包含上位机端(内网)和FPGA网关端(外网)两部分,通过芯片间的高速信号总线实现边缘计算网关工业数据采集、数据实时传输、数据存储、网关状态信息收集等功能。 边缘计算网关上位机端(内网)重点完成工业数据采集、业务软件运算、客户…...
最新AI创作系统ChatGPT系统运营源码/支持最新GPT-4-Turbo模型/支持DALL-E3文生图
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...
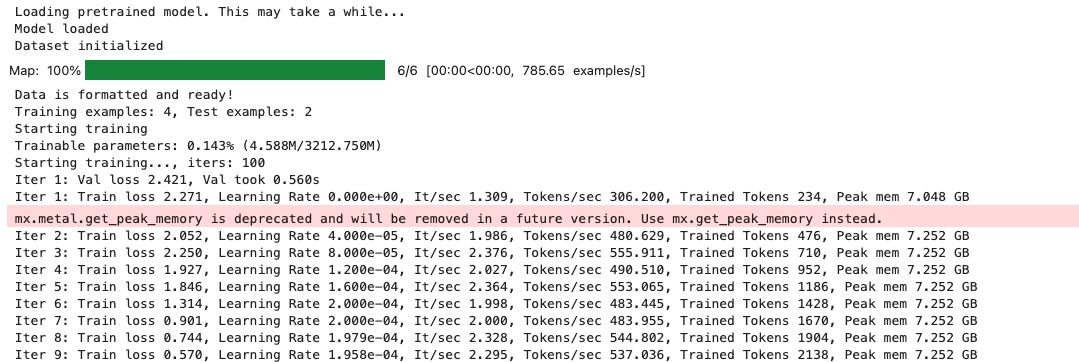
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...