二元分类模型评估方法
文章目录
- 前言
- 一、混淆矩阵
- 二、准确率
- 三、精确率&召回率
- 四、F1分数
- 五、ROC 曲线
- 六、AUC(曲线下面积)
- 七、P-R曲线
- 类别不平衡问题中如何选择PR与ROC
- 八、 Python 实现代码
- 混淆矩阵、命中率、覆盖率、F1值
- ROC曲线、AUC面积
| | 公式 | |
|---|---|---|
| 真正例 (TP) | 被模型预测为正的正样本;即预测为正样本,且预测结果为真 | |
| 假正例 (FP) | 被模型预测为正的负样本;即预测为正样本,且预测结果为假 | |
| 真负例 (TN) | 被模型预测为负的正样本;即预测为负样本,且预测结果为假 | |
| 假负例 (FN) | 被模型预测为负的负样本;即预测为负样本,且预测结果为真 | |
| 准确率(Accuracy) | A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy=\frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN | 模型正确分类的样本占总样本数的比例 |
| 精确率(Precision) | P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP | 模型预测为正类别的样本中有多少是真正的正类别 |
| 召回率(Recall) /真正率(TPR) | R e c a l l / T P R = T P T P + F N Recall/TPR=\frac{TP}{TP+FN} Recall/TPR=TP+FNTP | 召回率,也称为 True Positive Rate (TPR) 或灵敏度,是指在所有实际为正类别的样本中,模型能够正确预测为正类别的比例 |
| 特异度 (TNR) | T N P = T N T N + F P TNP=\frac{TN}{TN+FP} TNP=TN+FPTN | 特异度(True Negative Rate),是指在所有实际为负类别的样本中,模型能够正确预测为负类别的比例 高特异度意味着模型能够有效地将实际为负类别的样本正确分类。 |
| 假正率(FPR) | F P F P + T N \frac{FP}{FP+TN} FP+TNFP | False Positive Rate (FPR) 是指在所有实际为负类别的样本中,模型错误预测为正类别的比例 FPR 与特异度有关,是衡量模型在负类别样本中的误判程度。 |
| 假负率(FNR) | F N F N + T P \frac{FN}{FN+TP} FN+TPFN | False Negative Rate (FNR) 是指在所有实际为正类别的样本中,模型错误预测为负类别的比例 FNR 表示模型在正类别样本中的遗漏程度,即未能正确识别的正类别样本比例 |
| F1 分数(F1-score) | F 1 = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1=\frac{2 \cdot Precision \cdot Recall }{Precision + Recall } F1=Precision+Recall2⋅Precision⋅Recall | F1 分数是精确率和召回率的调和平均数,它综合了两者的性能 |
前言
根据分类模型和回归模型的不同,相应的评价标准也不尽相同,例如在分类模型中,就有以下 8 种不同的评价标准。
一、混淆矩阵
混淆矩阵是评价分类模型性能的基础,它展示了模型的预测结果核真实标签之间的对应关系。混淆矩阵由4个指标构成,分别是:
记忆小窍门:第一个字母 T / F 代表,是否分类正确。第二个字母 P / N 代表预测结果
- 真正例 (True Positive,TP)
- 假正例 (False Positive,FP)
- 真负例 (True Negative,TN)
- 假负例 (False Negative,FN)
通过计算这4个指标可以得到模型的准确率、精确率、召回率和F1得分。


真正例 (True Positive,TP):被模型预测为正的正样本;即预测为正样本,且预测结果为真,所以样本实际是正样本假正例 (False Positive,FP):被模型预测为正的负样本;即预测为正样本,且预测结果为假,所以样本实际是负样本真负例 (True Negative,TN):被模型预测为负的正样本;即预测为负样本,且预测结果为假,所以样本实际是正样本假负例 (False Negative,FN):被模型预测为负的负样本;即预测为负样本,且预测结果为真,所以样本实际是负样本
混淆矩阵的指标:预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。
混混淆矩阵是评估分类模型性能的基础,目的是帮助理解分类模型在不同类别上的表现。通过将模型的分类结果分成真正类别(True)和错误类别(False),帮助计算多种重要的性能指标,以量化模型在不同类别上的表现,例如准确率、精确率、召回率和F1分数。这些指标帮助我们量化模型的分类准确性、可靠性和全面性。
二、准确率
准确率(ACC)是衡量分类模型性能最直观的指标之一,它表示模型正确分类的样本数与总样本数之间比。准确率越高,表示模型的分类结果月准确。然而,准确率不能完全反映模型的性能,因为在样本不均衡的情况下,准确率可能会出现较高的偏差。此时,需要借助其他指标来综合评价模型。
A C C = T P + T N T P + F P + T N + F N ACC=\frac{TP+TN}{TP+FP+TN+FN} ACC=TP+FP+TN+FNTP+TN
三、精确率&召回率
- 精确率
精确率 (Precision) 是指模型预测为正例的样本中真正为正例的比例。精确率越高,表示模型将负例预测为正例的能力越强,即假正例的数量越少。精确率可以帮助我们评估模型的分类准确性,特别是在关注假正例数量的应用场景中
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP - 召回率
召回率 (Recall) 是指真正为正例的样本中被预测为正例的比例。召回率越高,表示模型将真正为正例的样本正确检测出来的能力越强,即假负例的数量越少。召回率可以帮助我们评估模型的分类完整性,特别是在关注假正例数量的应用场景中。
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
- 可以发现,当假正(即预测为正样本且预测结果为假:FP)的样本数越少,准确率就越高。相应的对应 FN 就越大,召回率就越小。
如果我们只预测最可能为正的那一个样本为正,其余的都为负,那么这时候我们的查准率很可能为 100%- 同样的道理:预测为正的样本越多,即 FP 越大,相应的对应 FN 就越小,召回率就越大,准确率也就越小
如果我们把所有的样本都预测为正,其余的都为负,那么此时的召回率必然为 100%
上面这句话也就说明了:我们分别用准确率或召回率对模型的预测结果进行评价会有片面性。所以,基于上面的片面性,引出了一个新的标准:F1度量(F-Score)
精确率和召回率两个概念,但在实际建模过程中,这两个指标往往是此消彼长的,召回率越高,准确率越低,反之亦然。所以想要找到二者之间的一个平衡点,就需要一个新的指标:F1分数。F1分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。
四、F1分数
F1分数是精确率和召回率的调和平均值,它综合考虑了分类模型的准确性和完整性。
F 1 = 2 T P 2 T P + F N + F P = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1=\frac{2TP}{2TP+FN+FP}=\frac{2 \cdot Precision \cdot Recall }{Precision + Recall } F1=2TP+FN+FP2TP=Precision+Recall2⋅Precision⋅Recall
F1 分数的取值范围是 [0, 1],越接近 1 表示模型的性能越好,同时考虑到了模型在查准率和查全率之间的平衡。F1 分数对于二元分类问题非常有用,特别是当我们希望在精确率和召回率之间取得平衡时。在样本不均衡的情况下,F1分数比准确率更能反映模型的性能。
五、ROC 曲线
接受者操作特性曲线(receiver operating characteristic curve,简称ROC曲线)。该曲线最早应用于雷达信号检测领域,用于区分信号与噪声。后来人们将其用于评价模型的预测能力,ROC曲线是基于混淆矩阵得出的。它反映了模型在不同阈值下的分类性能。
逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。
如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。
举个例子:逻辑回归对正负结果的判定默认是 0.5,模型预测的结果如果超过 0.5 则确定样本预测结果为正,否则样本预测为负,但是当我们将0.5 提高到 0.8,则 0.8 以下的就都预测为负了。
为了直观表示这一现象,引入 ROC 曲线:根据分类结果计算得到空间中相应的点,连接这些点就形成 ROC curve
ROC曲线中的主要两个指标就是真正率和假正率,其中横坐标为假正率(FPR),纵坐标为真正率(TPR),当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5。
ROC曲线绘制: ROC曲线的横坐标为FPR,纵坐标为TPR
- 将预测结果按照预测为正类概率值排序
- 将阈值由1开始逐渐降低,按此顺序逐个把样本作为正例进行预测,每次可以计算出当前的FPR,TPR值
- 以TPR为纵坐标,FPR为横坐标绘制图像

ROC 曲线中有四个点需要注意,分别是:
- 点(0,1):即 FPR=0, TPR=1,意味着 FN=0 且 FP=0,将所有的样本都正确分类。
- 点(1,0):即 FPR=1,TPR=0,最差分类器,避开了所有正确答案。
- 点(0,0):即FPR=TPR=0,FP=TP=0,分类器把每个实例都预测为负类。
- 点(1,1):分类器把每个实例都预测为正类。
ROC 曲线越接近左上角,该分类器的性能越好,其泛化性能就越好。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。而且一般来说,如果ROC是光滑的,那么基本可以判断没有太大的过拟合。
总结:
🎈ROC曲线:ROC曲线(receiver operating characteristic curve),
- 是反映灵敏性和特效性连续变量的综合指标;
- 是用构图法揭示敏感性和特异性的相互关系;
- 它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性;
- ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真正例率(True Positive Rate,TPR 也就是灵敏度)为纵坐标,假正例率(False Positive Rate,FPR,1-特效性)为横坐标绘制的曲线。
ROC曲线优缺点:
优点 :
- 1、兼顾正例和负例的权衡。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。适用于评估分类器的整体性能。
- 2、ROC曲线的两个指标, TPR的分母是所有正例,FPR的分母是所有负例,故都不依赖于具体的类别分布。
缺点:
- 在类别不平衡的背景下,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。如果主要关心正例的预测准确性的话,这就不太可接受了。
六、AUC(曲线下面积)
如果两条ROC曲线没有相交,我们可以根据哪条曲线最靠近左上角哪条曲线代表的学习器性能就最好。但是,实际任务中,情况很复杂,如果两条ROC曲线发生了交叉,则很难一般性地断言谁优谁劣。在很多实际应用中,我们往往希望把学习器性能分出个高低来。在此引入AUC面积。
AUC(Area Under Curve): 被定义为 ROC 曲线下的面积( ROC 的积分),通常大于0.5小于1。
随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。AUC值(面积)越大的分类器,性能越好,如图:

上图中 AUC=1 当然是最好的, 这代表着将所有的样本都正确分类,但是实际 AUC 是达不到 1 的,这种极端情况下只能说明样本数据是存在问题,需要再次筛选模型入模特征。
AUC只能用来评价二分类。AUC非常适合评价样本不平衡中的分类器性能
AUC的一般判断标准: AUC的范围在[0, 1]之间,并且越接近1越好
- 0.5-0.7 : 效果较低,但用于预测股票已经很不错了
- 0.7-0.85 : 效果一般
- 0.85-0.95 : 效果很好
- 0.95-1 : 效果非常好,但一般不太可能
AUC的概率意义: 随机取一对正负样本,正样本得分大于负样本得分的概率
AUC的物理意义: 曲线下面积对所有可能的分类阈值的效果进行综合衡量。曲线下面积的一种解读方式是:看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。以下面的样本为例,逻辑回归预测从左到右以升序排列:

AUC的优点和缺点
优点:
- AUC衡量的是一种排序能力,因此特别适合排序类业务;
- AUC对正负样本均衡并不敏感,在样本不均衡的情况下,也可以做出合理的评估。
- 其他指标比如precision,recall,F1,根据区分正负样本阈值的变化会有不同的结果,而AUC不需要手动设定阈值,是一种整体上的衡量方法。
缺点:
- 忽略了预测的概率值和模型的拟合程度;
- AUC反映了太过笼统的信息,无法反映召回率、精确率等在实际业务中经常关心的指标;
- 它没有给出模型误差的空间分布信息,AUC只关注正负样本之间的排序,并不关心正样本内部,或者负样本内部的排序,这样我们也无法衡量样本对于好坏客户的好坏程度的刻画能力;
AUC计算
AUC如果按照原始定义ROC曲线下的面积来计算,非常之麻烦。
可以转换一下思路,按照上述给出的常用的AUC定义,即随机选出一对正负样本,分类器对于正样本打分大于负样本打分的概率。咱们就来算算这个概率到底是多少,那么也就算出AUC是多少了。
假设数据集一共有M个正样本,N个负样本,预测值也就是M+N个。我们将所有样本按照预测值进行从小到大排序,并排序编号由1到M+N。
- 对于正样本概率最大的,假设排序编号为 r a n k 1 rank_1 rank1 ,比它概率小的负样本个数= r a n k 1 − M rank_1-M rank1−M (仔细体会一下);
- 对于正样本概率第二大的 r a n k 2 rank_2 rank2 ,假设排序编号为
,比它概率小的负样本个数= r a n k 2 − ( M − 1 ) rank_2-(M-1) rank2−(M−1) ;- 以此类推…
- 对于正样本概率最小的,假设排序编号为 r a n k M rank_M rankM ,比它概率小的负样本个数= r a n k M − 1 rank_M-1 rankM−1
那么在所有情况下,正样本打分大于负样本的个数= r a n k 1 + r a n k 2 + ⋯ + r a n k M − ( 1 + 2 + ⋯ + M ) rank_1+rank_2+\cdots+rank_M-(1+2+\cdots+M) rank1+rank2+⋯+rankM−(1+2+⋯+M) 。
所以,AUC的正式计算公式也就有了,如下!(需要牢记)
A U C = ∑ i ∈ 正样本 r a n k ( i ) − M × ( 1 + M ) 2 M × N AUC=\frac{\sum_{i \in 正样本}rank(i)-\frac{M \times(1+M)}{2}}{M \times N} AUC=M×N∑i∈正样本rank(i)−2M×(1+M)
r a n k ( i ) rank(i) rank(i)表示正样本 i i i 的排序编号, M × N M \times N M×N表示随机从正负样本各取一个的所有情况数。一般考代码题,比如用python写个AUC计算,也是用上述公式原理。
但是,还没有完,有一个小问题,可能大家没注意到。那就是如果有预测值是一样的,那么怎么进行排序编号呢?
其实很简单,对于预测值一样的样本,我们将这些样本原先的排号平均一下,作为新的排序编号就完事了。仔细理解可看下图:

上图中,正样本个数M=5(黄底样本),负样本个数N=3(白底样本),预测值相同有4个(ID为CDEF)。我们将预测值pred相等的情况(上图红色字体),对其进行新的排序编号,变成(3+4+5+6)/4 = 4.5。
那么根据公式就可以算出上图的 A U C = ( 2 + 4.5 + 5.5 + 7 + 8 ) − 5 × ( 5 + 1 ) 2 5 × 3 = 0.7333 AUC = \frac{(2+4.5+5.5+7+8)-\frac{5 \times (5+1)}{2}}{5 \times 3}=0.7333 AUC=5×3(2+4.5+5.5+7+8)−25×(5+1)=0.7333
用sklearn的auc计算验证一下,一样。

七、P-R曲线
精确率和召回率是互相影响的,有时会相互矛盾,理想情况下肯定是做到两者都高,但是一般情况下精确率高、召回率就低,召回率低、精确率高,当然如果两者都低,那就是有地方出问题了。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个 CutOff 阈值点,高于这个点的判正,低于的判负,其中,这个点的选择需要结合你的具体场景去选择。
用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
PR曲线绘制
PR曲线的横坐标为召回率R,纵坐标为查准率P,绘制步骤如下:
- 将预测结果按照预测为正类概率值排序;
- 将概率阈值由1开始逐渐降低,按此顺序逐个把样本作为正例进行预测,每次可以计算出当前的P,R值;
- 以P为纵坐标,R为横坐标绘制点,将所有点连成曲线后构成PR曲线。

如何利用PR曲线对比算法的优劣:
- 如果一条曲线完全“包住”另一条曲线,则前者性能优于另一条曲线(P和R越高,代表算法分类能力越强)。
- PR曲线发生了交叉时:以PR曲线下的面积作为衡量指标,但这个指标通常难以计算
- 使用 “平衡点”(Break-Even Point),他是查准率=查全率时的取值,值越大代表效果越优
- BEP过于简化,
更常用的是F1度量
曲线越靠近右上边性能越好,描述曲线下方面积叫 AP 分数(Average Precision Score),AP 分数越高,表示模型性能越好。
但是有时候模型没有单纯的谁比谁好,和文章开头的例子一样,需要结合具体的使用场景。下面是两个场景:
- 地震的预测:我们希望的是 Recall 非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲 Precision。情愿发出 1000次 警报,把 10次 地震都预测正确了,也不要预测 100次 对了 8次 漏了 2次。
- 嫌疑人定罪:基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。即时有时候放过了一些罪犯(Recall 低),但也是值得的。
所以,针对场景,如果是做搜索,那就是保证召回的情况下提升精确率;如果做 疾病监测、反垃圾,则是保证精确率的条件下,提升召回;在两者都要求高的情况下,可以用 F1 来衡量。
反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看Recall=99.9999%(地震全中)时的 Precision,其他指标就变得没有了意义。
注意一下,PR 和 ROC 是两个不同的评价指标和计算方式,一般情况下,检索用 PR,分类、识别等用 ROC。
类别不平衡问题中如何选择PR与ROC
这里特指负样本数量远大于正样本时,在这类问题中,我们往往更关注正样本是否被正确分类,即TP的值。PR曲线更适合度量类别不平衡问题
- 因为在PR曲线中TPR和FPR的计算都会关注TP,PR曲线对正样本更敏感。
- 而ROC曲线正样本和负样本一视同仁,在类别不平衡时ROC曲线往往会给出一个乐观的结果。
八、 Python 实现代码
混淆矩阵、命中率、覆盖率、F1值
#随机森林模型
model= RandomForestClassifier(random_state=12,n_estimators = 300,class_weight={0:1,1:8},min_samples_split=8, min_samples_leaf=5,max_depth=6)
model.fit(x_train, y_train)'''输出混淆矩阵'''
#混淆矩阵中会给出命中率、覆盖率、F1值
import sklearn.metrics as metrics
pre_test = model.predict(x_test) #predict 默认阈值0.5, predict_proba 是没有默认阈值
print(metrics.confusion_matrix(y_test, pre_test, labels=[0, 1])) # 混淆矩阵集的f1值
print(metrics.classification_report(y_test, pre_test))

ROC曲线、AUC面积
from sklearn import metrics
import matplotlib.pyplot as pltfpr, tpr, _ = metrics.roc_curve(labels, preds)
roc_auc = metrics.auc(fpr, tpr)plt.figure(figsize=(8, 7), dpi=80, facecolor='w') # dpi:每英寸长度的像素点数;facecolor 背景颜色
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc) # 绘制AUC面积
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.05])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right") # 设置显示标签的位置
plt.grid(b=True, ls=':') # 绘制网格作为底板;b是否显示网格线;ls表示line style
plt.show()from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt'''将多个模型的ROC曲线绘制在一张图'''
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt##计算ROC值
fpr1, tpr1, thresholds1 = roc_curve(y_test, y_prob1)
roc_auc1 = roc_auc_score(y_test, y_prob1)fpr2, tpr2, thresholds2 = roc_curve(y_test, y_prob2)
roc_auc2 = roc_auc_score(y_test, y_prob2)# 绘制ROC曲线
plt.plot(fpr1, tpr1, color='darkorange', label='LR ROC curve (area = %0.2f)' % roc_auc1)
plt.plot(fpr2, tpr2, color='blue', label='SVM ROC curve (area = %0.2f)' % roc_auc2)plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic (ROC) curve')
plt.legend(loc="lower right")
plt.show()
参考:
分类模型评估方法
分类问题的 8 种评估方法(全)
精确率、召回率、F1值、ROC、AUC各自的优缺点
相关文章:
二元分类模型评估方法
文章目录 前言一、混淆矩阵二、准确率三、精确率&召回率四、F1分数五、ROC 曲线六、AUC(曲线下面积)七、P-R曲线类别不平衡问题中如何选择PR与ROC 八、 Python 实现代码混淆矩阵、命中率、覆盖率、F1值ROC曲线、AUC面积 指标 公式 意义 真正例 (TP)被…...

专业数据标注公司:景联文科技领航数据标注行业,满足大模型时代新需求
随着大模型的蓬勃发展和相关政策的逐步推进,为数据要素市场化配置的加速推进提供了有力的技术保障和政策支持。数据要素生产力度的不断提升,为数据标注产业带来了迅速发展的契机。 根据国家工信安全发展研究中心测算,2022年中国数据加工环节的…...
.Net8 Blazor 尝鲜
全栈 Web UI 随着 .NET 8 的发布,Blazor 已成为全堆栈 Web UI 框架,可用于开发在组件或页面级别呈现内容的应用,其中包含: 用于生成静态 HTML 的静态服务器呈现。使用 Blazor Server 托管模型的交互式服务器呈现。使用 Blazor W…...

Vue.js 页面加载时触发函数
使用 Vue 的生命周期钩子函数: 在 Vue 组件中,可以使用生命周期钩子函数来执行特定的代码。其中,mounted 钩子函数可以在组件被挂载到 DOM 后触发。 <template><div><!-- 页面内容 --></div> </template>expo…...

Go 语言常用数据结构
1. 请解释 Go 语言中的 map 数据结构,以及它与数组和切片的区别。 ①、解释说明: 在Go语言中,map是一种内置的数据类型,它是一种无序的键值对集合。每个键值对都由一个键和一个值组成,它们之间用冒号分隔。键可以是任…...
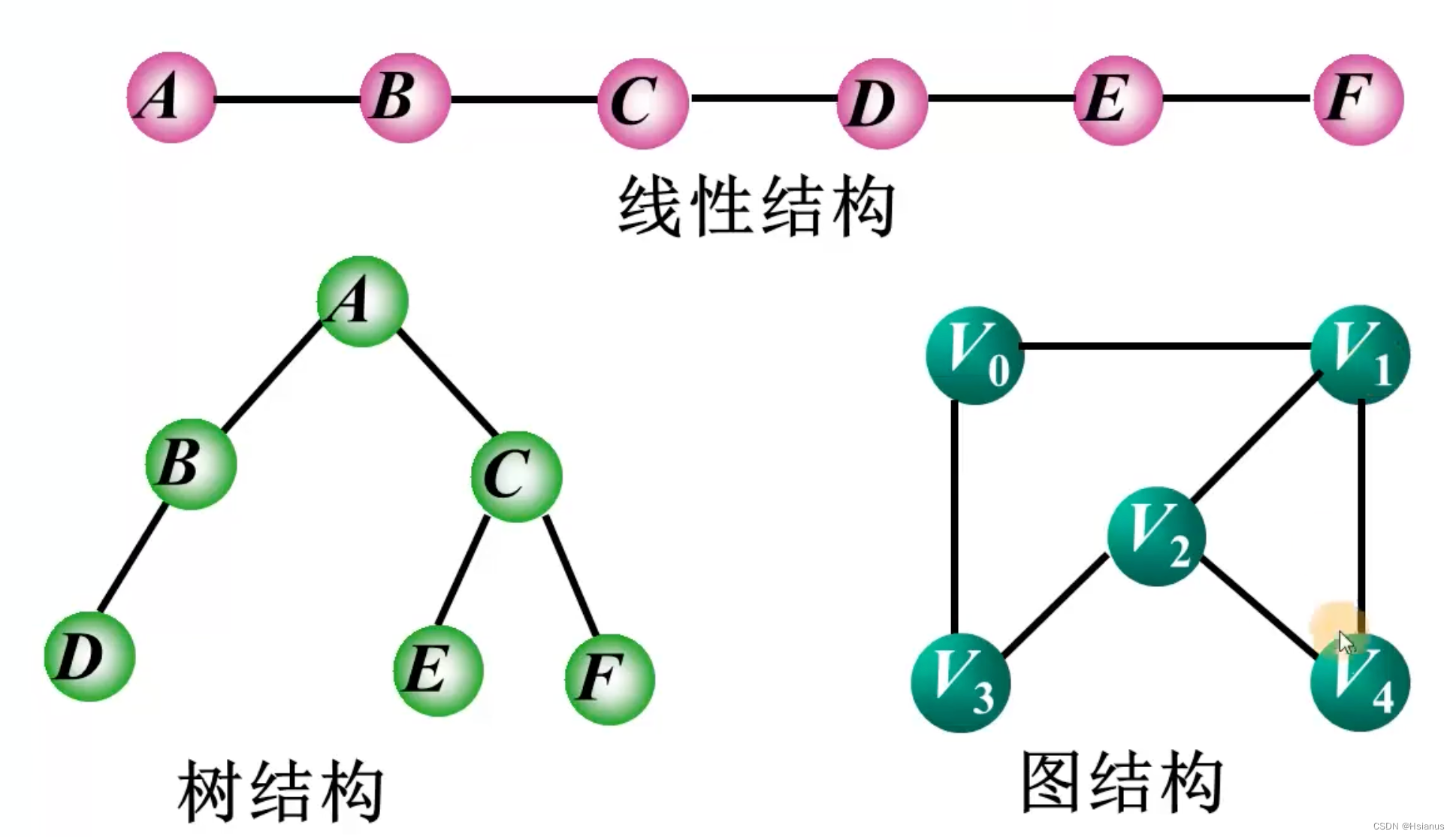
【数据结构】图的简介(图的逻辑结构)
一.引例(哥尼斯堡七桥问题) 哥尼斯堡七桥问题是指在哥尼斯堡市(今属俄罗斯)的普雷格尔河(Pregel River)中,是否可以走遍每座桥一次且仅一次,最后回到起点的问题。这个问题被认为是图…...

2342.数位和相等数对的最大和
题目来源: leetcode题目,网址:2342. 数位和相等数对的最大和 - 力扣(LeetCode) 解题思路: 哈希表,根据数位和分组后,计算每组中最大两个数之和,然后返回最大值即可。…...

关于Spring Bean的一些总结
一、Spring Bean的生命周期 Spring中的Bean生命周期是指一个Bean从被创建、初始化,到被使用,再到被销毁的整个过程。在Spring容器管理的Bean中,生命周期的管理主要通过回调方法和事件监听来实现。以下是Spring Bean的生命周期的主要阶段和回…...
6.2 List和Set接口
1. List接口 List接口继承自Collection接口,List接口实例中允许存储重复的元素,所有的元素以线性方式进行存储。在程序中可以通过索引访问List接口实例中存储的元素。另外,List接口实例中存储的元素是有序的,即元素的存入顺序和取…...

2023数维杯国际赛数学建模D题完整论文分享!
大家好,终于完成了2023年第九届数维杯国际大学生数学建模挑战赛D题The Mathematics of Laundry Cleaning(洗衣清洁的数学原理)的完整论文啦。 D论文共43页,一些修改说明10页,正文25页,附录8页。 D题第一问…...
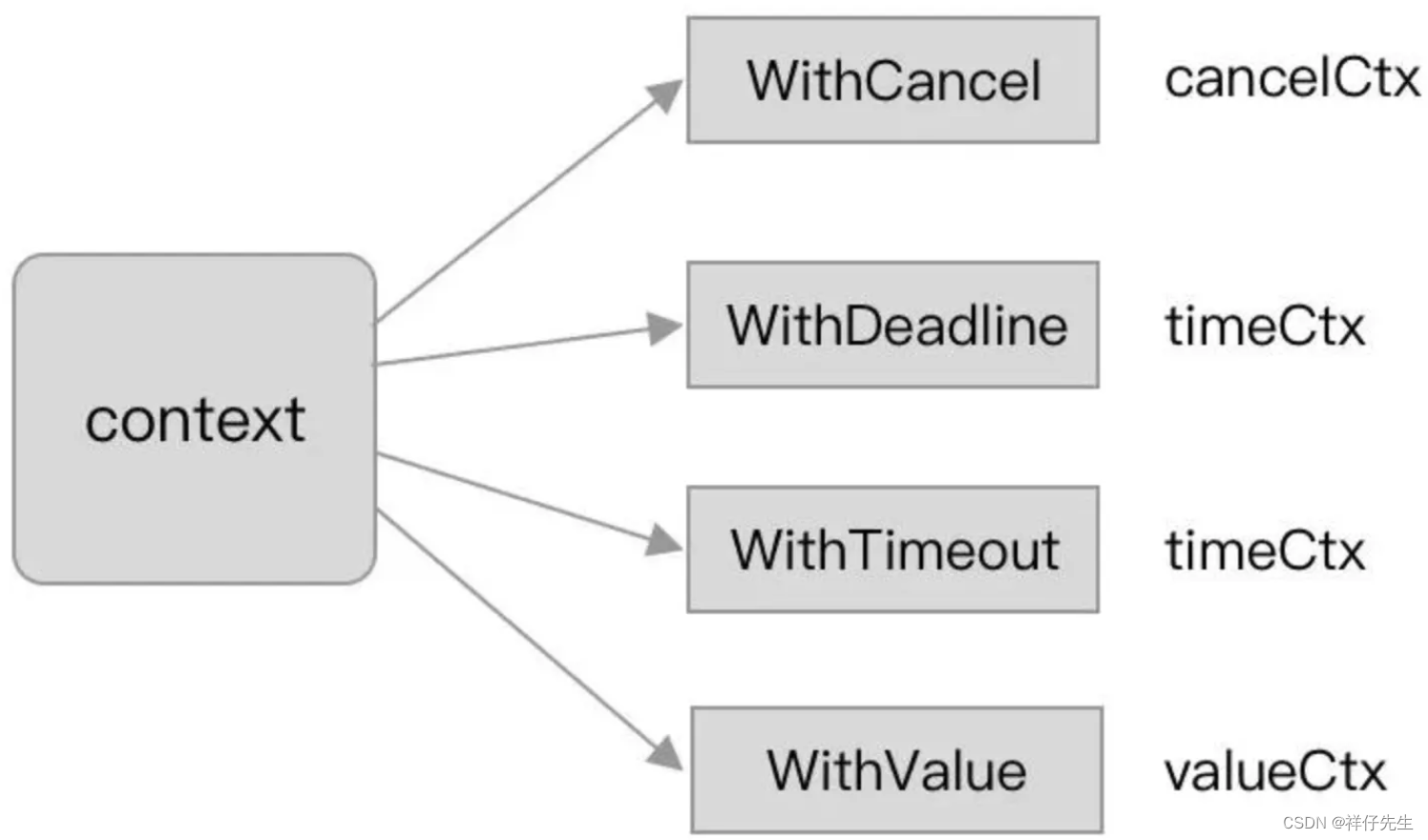
golang中context使用总结
一、context使用注意事项 在使用context时,有一些需要注意的事项,以及一些与性能优化相关的建议: 避免滥用context传递数据:context的主要目的是传递请求范围的数据和取消信号,而不是用于传递全局状态或大量数据。滥用…...
医院数字化LIS(检验信息系统)源码
临床检验信息管理系统(LIS)是利用计算机连接医疗设备,通过计算机信息处理技术,将医院检验科或实验室的临床检验数据进行自动收集、存储、处理、提取、传输和交换,满足所有授权用户的功能需求。 一、系统概述 1.LIS&am…...

挑战单芯片NOA,这款“All in one”方案或将改变主流市场走向
随着降本增效、电子架构升级(尤其是跨域计算、多域融合等概念)以及供应链减复(降低电子物料的SKU)的需求愈加明确,对于车载计算赛道,也带来新的变化。 比如,去年9月,英伟达率先发布下…...

CODING DevOps产品认证笔记
1.敏捷&精益&瀑布概述 1.1 敏捷软件开发 第一章敏捷软件开发背景 背景:乌卡时代 易变性:当今世界的变化越来越多越来越快,越来越不可预测。不确定性:历史上的任何一个时代所带来的经验已经无法为当今世界的所有变化提供参照。复杂性:事物间的…...

信息系统项目管理师 第四版 第5章 信息系统工程
1.软件工程 1.1.架构设计 1.2.需求分析 1.3.软件设计 1.4.软件实现 1.5.部署交互 1.6.过程管理 2.数据工程 2.1.数据建模 2.2.数据标准化 2.3.数据运维 2.4.数据开发利用 2.5.数据库安全 3.系统集成 3.1.集成基础 3.2.网络集成 3.3.数据集成 3.4.软件集成 3.…...

对话芯动科技 | 助力云游戏 4K级服务器显卡的探索与创新
2021年芯动科技推出了基于IMG BXT GPU IP的风华1号显卡。单块风华1号显卡可在台式机和云游戏中实现4K级别的性能,渲染能力达到5 TFLOPS,如果在服务器中同时运行两块显卡,性能还可翻倍。该显卡是为不断扩大的安卓云游戏市场量身定制的…...

[HTML]Web前端开发技术1,meta,HBuilder等——喵喵画网页
希望你开心,希望你健康,希望你幸福,希望你点赞! 最后的最后,关注喵,关注喵,关注喵,大大会看到更多有趣的博客哦!!! 喵喵喵,你对我真的…...

网上申请的电信卡能用多长时间?可以长期使用吗?
我们在网上总能看到一些关于流量卡的广告,都是19元,29元100多g的套餐,乍一看这些套餐非常便宜,但是小编提醒大家一定要注意优惠期。 网上的流量卡套餐,都是由基础套餐额外赠送充值送话费等内容组成,…...

交换机的工作原理
局域网交换技术是数据链路层上的技术,就是转发数据帧。在数据通信中,所有交换设备都执行两个基本操作: 交换数据帧生成并维护交换地址表 交换数据帧 交换机根据数据帧的MAC地址(物理地址)进行数据帧的转发操作。交换…...
如何使用ArcGIS Pro制作粉饰效果
在地图上,如果某个部分比较重要,直接的制图不能将其凸显出来,如果想要突出显示重要部分,可以通过粉饰效果来实现,这里为大家介绍一下方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...
VisualXML全新升级 | 新增数据库编辑功能
VisualXML是一个功能强大的网络总线设计工具,专注于简化汽车电子系统中复杂的网络数据设计操作。它支持多种主流总线网络格式的数据编辑(如DBC、LDF、ARXML、HEX等),并能够基于Excel表格的方式生成和转换多种数据库文件。由此&…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...