MySQL_InnoDB引擎
InnoDB引擎
逻辑存储结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tKPl61tI-1676083936977)(file://C:\Users\82391\AppData\Roaming\marktext\images\2023-02-08-11-33-48-image.png?msec=1676083920402)]](https://img-blog.csdnimg.cn/d91700b6845c479b9ad3a1a8570f6265.png)
-
表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
-
段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollback segment)InnoDB是索引组织表。
-
数据段就是B+tree的叶子阶段;
-
索引段即为B+Tree的非叶子节点。
-
段用来管理多个Extent(区)。
-
-
区,表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16k,即一个区中一共有64个连续的页。
-
页,是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16kB。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区。
-
行,InnoDB存储引擎数据是按行进行存放的。
-
Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。
-
Roll_pointer:每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
-
架构
MySQL5.5版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。
下图是InnoDB架构图,左侧为内存结构,右侧为磁盘结构。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sV6aNhKO-1676083936978)(file://C:\Users\82391\AppData\Roaming\marktext\images\2023-02-08-12-28-10-image.png?msec=1676083920431)]](https://img-blog.csdnimg.cn/5a5b2be08b3d4dbc8d3503a9e33e0b92.png)
内存架构
-
Buffer Pool:缓冲池是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
-
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
-
free page:空闲page,未被使用。
-
clean page:被使用page,数据没有被修改过。
-
dirty page:脏页,被使用page,数据被修改过,内存与磁盘的数据不一致。
-
-
Change Buffer:更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果这些数据Page没有在buffer Pool中,不会直接操作磁盘,而会将数据变更在更改缓冲区Change Buffer中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘。
-
Change Buffer的意义是什么?
- 与聚集索引不同,二级索引通常是非唯一的,并且相对随机的顺序插入二级索引,同样,删除和更新可能会影响索引数中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了Change Buffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
-
-
Adaptive Hash index:自适应hash索引,用于优化对bufferPool的数据查询。InnoDB存储引擎会监控对表上各索引页的查询,如果观察到hash索引可以提升速度,则简历索引,故称之为自适应哈希索引。
-
自适应哈希索引,无需人工干预,是系统根据情况自动完成。
-
参数:adaptive_hash_index
-
-
Log Buffer:日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log、undo log),默认大小为16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
-
参数:
-
innodb_log_buffer_size:缓冲区大小
-
innodb_flush_log_at_trx_commit:日志刷新到磁盘的时机
-
日志在每次事务提交时写入并刷新到磁盘。
-
每秒将日志写入并刷新到磁盘一次。
-
日志在每次事务提交后写入,并每秒刷新到磁盘一次
-
-
-
磁盘结构
-
System Tablespace:系统表空间是更改缓冲区的存储区域。如果表是在系统空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)
- 参数:innodb_data_file_path
-
File-Per-Table Tablespaces:每个表的文件表空间包含单个innodb表的数据和索引,并存储在文件系统上的单个数据文件中。
- 参数:innodb_file_per_table
-
General Tablespaces:通用表空间,需要通过create tablespace语法创建通用表空间,在创建表时,可以指定该表空间。
-
create tablespace xxxxx add datafile ‘file_name’ engine = engine_name;
-
create table xxx… tablespace ts_name;
-
-
Undo Tablespaces:撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
-
Temporary Tablespaces:InnoDB使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
-
Doublewrite Buffer Files:双写缓冲区,InnoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
-
Redo Log:重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把修改信息都会存在该日志中,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
后台线程
后台线程的作用:在合适的时机,将InnoDB缓冲池中的数据存储到磁盘之中。
-
Master Thread
- 核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
-
IO Thread
- 在InnoDB存储引擎中大量使用了AIO来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read Thread | 4 | 负责读操作 |
| Write Thread | 4 | 负责写操作 |
| Log Thread | 1 | 负责将日志缓冲区刷新到磁盘 |
| Insert buffer Thread | 1 | 负责将写缓存区内容刷新到磁盘 |
-
Purge Thread
- 主要用于回收事务已经提交了的undo log(撤销日志),在事务提交之后,undo log可能不用了,就用它来回收。
-
Page Cleaner Thread
- 协助Master Thread刷新脏页到磁盘的线程,它可以减轻Master Thread的工作压力,减少阻塞。
事务原理
事务
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作同时成功或同时失败。
在mysql的InnoDB引擎中:redo log和undo log 保证事务的原子性、一致性、持久性。
锁和MVCC保证事务的隔离性。
-
特性
-
原子性:事务是不可分割的最小操作单元。
-
一致性:事务完成时,必须使所有的数据都保持一致状态。
-
隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发操作的独立环境下运行。
-
持久性:事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
-
-
redo log :持久性
-
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
-
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到日志文件中,用于刷新页到磁盘,发生错误是,进行数据恢复使用。
-
-
undo log:原子性
-
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚和MVCC(多版本并发控制)
-
undo log和redo log记录物理日志不一样,他是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录。反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
-
undo log销毁:
- undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
-
undo log存储:
- undo log采用段的方式进行管理和记录,存放在前面介绍的rollbask segment回滚段中,内部包含1024个undo log segment。
-
MVCC
-
基本概念
-
当前读
-
读取记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
-
对于我们日常的操作,如select … lock in share mode(共享锁),select … for update、update、insert、delete(排他锁)都是一种当前读。
-
-
快照读
-
简单的select(不加锁)就是快照读,读取的记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
-
read Committed:每次select,都生成一个快照读。
-
Repeatable Read:开启事务后第一个select语句才是快照读的地方。
-
Serializable:快照读会退化为当前读。
-
-
-
MVCC(Multi-Version Concurrency Control)
- 多版本并发控制,指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log 日志、readView。
-
-
MVCC-实现原理
- 记录中的隐藏字段
隐藏字段 含义 db_trx_id 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID db_roll_ptr 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。 db_row_id 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 -
undo log
-
回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志。
-
当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。
-
而update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读也需要,不会立即被删除。
-
undo log 版本链
- 不同事务或相同事务对同一条记录进行修改,会导致该记录的undo log生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
-
-
readview
-
readview(读视图)是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
-
readview中包含了四个核心字段:
-
字段 含义 m_ids 当前活跃的事务ID集合 min_trx_id 最小活跃事务ID max_trx_id 预分配事务ID,当前最大事务ID+1 creator_trx_id readview创建者的事务ID -
版本链数据访问规则(trx_id:代表是当前事务ID)
-
trx_id == creator_trx_id
- 可以访问该版本–>成立,说明数据是当前这个事务更改的。
-
trx_id < min_trx_id
- 可以访问该版本,说明数据已经提交了
-
trx_id > max_trx_id
- 不可以访问该版本,说明该事务是在readview生成后才开启。
-
min_trx_id<=trx_id<=max_trx_id
- 如果trx_id不在m_ids中是可以访问该版本的,说明数据已经提交。
-
-
不同的隔离记录,生成readView的时机不同
-
read committed:在事务中每一次执行快照读是都生成readview
-
repeatable read:仅在事务中第一次执行快照读时生成readview,后续复用该readview。
-
-
相关文章:
MySQL_InnoDB引擎
InnoDB引擎 逻辑存储结构 表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。 段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollba…...
json-server使用
文章目录json-server使用简介安装json-server启动json-server操作创建数据库查询数据增加数据删除数据修改数据putpatch配置静态资源静态资源首页资源json-server使用 简介 github地址 安装json-server npm install -g json-server启动json-server json-server --watch db…...
)
实现mint操作(参考pancake)
区块链发展越来越好,nft已经火了很久,今天写一下如何用js、web3js、调用合约,实现mint nft。简单的调用://引入一些依赖 (根据需要,有一些是其他功能的) import useActiveWeb3React from ./web3…...

Linux进程信号
目录 一、认识信号 1.1 生活角度的信号 1.2 技术角度的信号 1.3 信号的发送与记录 1.4 常见信号处理方式 二、产生信号 2.1 通过终端按键产生信号(核心转储) 2.2 通过系统函数向进程发送信号 2.2.1 kill()函数 2.2.2 raise()函数 2.2.3 abort()函数 2.3 因软件条件…...

1.7 Web学生管理系统
1.定义通讯协议基于前面介绍过的 FLask Web 网站 与 urlib 的访问网站的方法,设计一个综合应用实例。它是一个基于 Web 的学生记录管理程序。学生的记录包括 id(学号) 、name(姓名) 、grade(成绩),服务器的作用是建立与维护一个Sqllite 的学生数据库 stu…...

前端教学视频分享(视频内容与市场时刻保持紧密相连,火热更新中。。。)
⚠️获取公众号 本次要想大家推荐一下本人的公众号,在微信中搜索公众号 李帅豪在对话框中输入前端视频四个字即可立即获取所有视频,不收费无广告!!! 本公众号收集了近两年来前端最新最优秀的学习视频,涵盖…...
Docker-consul的容器服务更新与发现
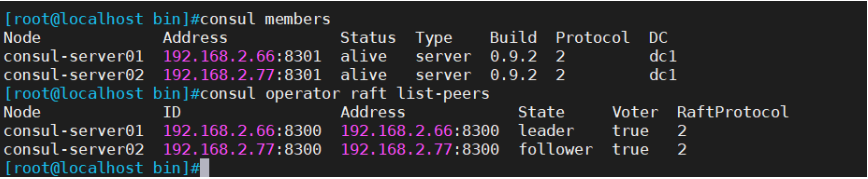
一.Consul概述1.1 什么是服务注册与发现服务注册与发现是微服务架构中不可或缺的重要组件。起初服务都是单节点的,不保障高可用性,也不考虑服务的压力承载,服务之间调用单纯的通过接口访问。直到后来出现了多个节点的分布式架构,起…...
Java笔记-线程中断
线程的中断 1.应用场景: 假设从网络下载一个100M的文件,如果网速很慢,用户等得不耐烦,就可能在下载过程中点“取消”,这时,程序就需要中断下载线程的执行。 2.常用中断线程的方法: 1.使用标…...

js中的自调用表达式
自调用表达式 由函数表达式创建的函数可以自调用,称之为自调用表达式。 语法 由函数表达式创建函数: const myFn function () {let a 100console.log(a);return a } myFn() //调用后执行,输出100表达式后面紧跟 ( ) 则会自动调用: const myFn fu…...

Python操作的5个坏习惯,你中了几个呢?
很多文章都有介绍怎么写好 Python,我今天呢相反,说说写代码时的几个坏习惯。有的习惯会让 Bug 变得隐蔽难以追踪,当然,也有的并没有错误,只是个人觉得不够完美。 注意:示例代码在 Python 3.6 环境下编写 …...
---线程间共享数据)
C++并发与多线程编程(3)---线程间共享数据
主要内容:共享数据带来的问题使用互斥量保护数据数据保护的替代方案共享数据带来的问题当涉及到共享数据时,问题可能是因为共享数据修改所导致。如果共享数据是只读的,那么只读操作不会影响到数据,更不会涉及对数据的修改…...

洞察:2022年医疗行业数据安全回顾及2023年展望
过去的2022年,统筹安全与发展,在医疗信息化发展道路中,数据安全不可或缺。这一年,实施五年多的《网络安全法》迎来首次修改,《数据安全法》、《个人信息保护法》实施一周年,配套的《数据出境安全评估办法》…...

多传感器融合定位十五-多传感器时空标定(综述)
多传感器融合定位十五-多传感器时空标定1. 多传感器标定简介1.1 标定内容及方法1.2 讲解思路2. 内参标定2.1 雷达内参标定2.2 IMU内参标定2.3 编码器内参标定2.4 相机内参标定3. 外参标定3.1 雷达和相机外参标定3.2 多雷达外参标定3.3 手眼标定3.4 融合中标定3.5 总结4. 时间标…...
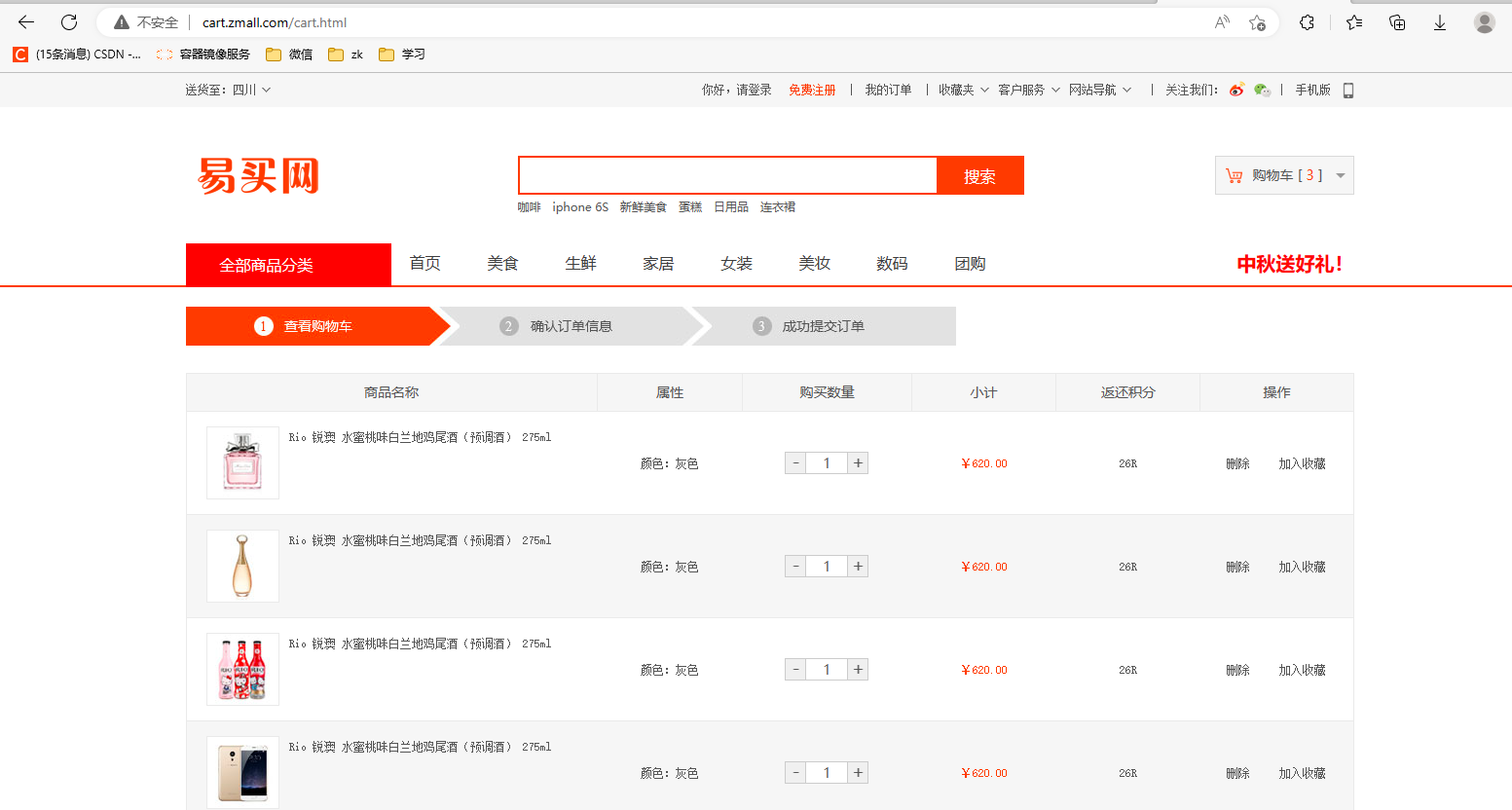
开发微服务电商项目演示(三)
一,nginx动静分离第1步:通过SwitchHosts新增二级域名:images.zmall.com第2步:将本次项目的易买网所有静态资源js/css/images复制到nginx中的html目录下第3步:在nginx的核心配置文件nginx.conf中新增二级域名images.zma…...

C/C++排序算法(二) —— 选择排序和堆排序
文章目录前言1. 直接选择排序🍑 基本思想🍑 具体步骤🍑 具体步骤🍑 动图演示🍑 代码实现🍑 代码升级🍑 特性总结2. 堆排序🍑 向下调整算法🍑 任意树调整为堆的思想&#…...
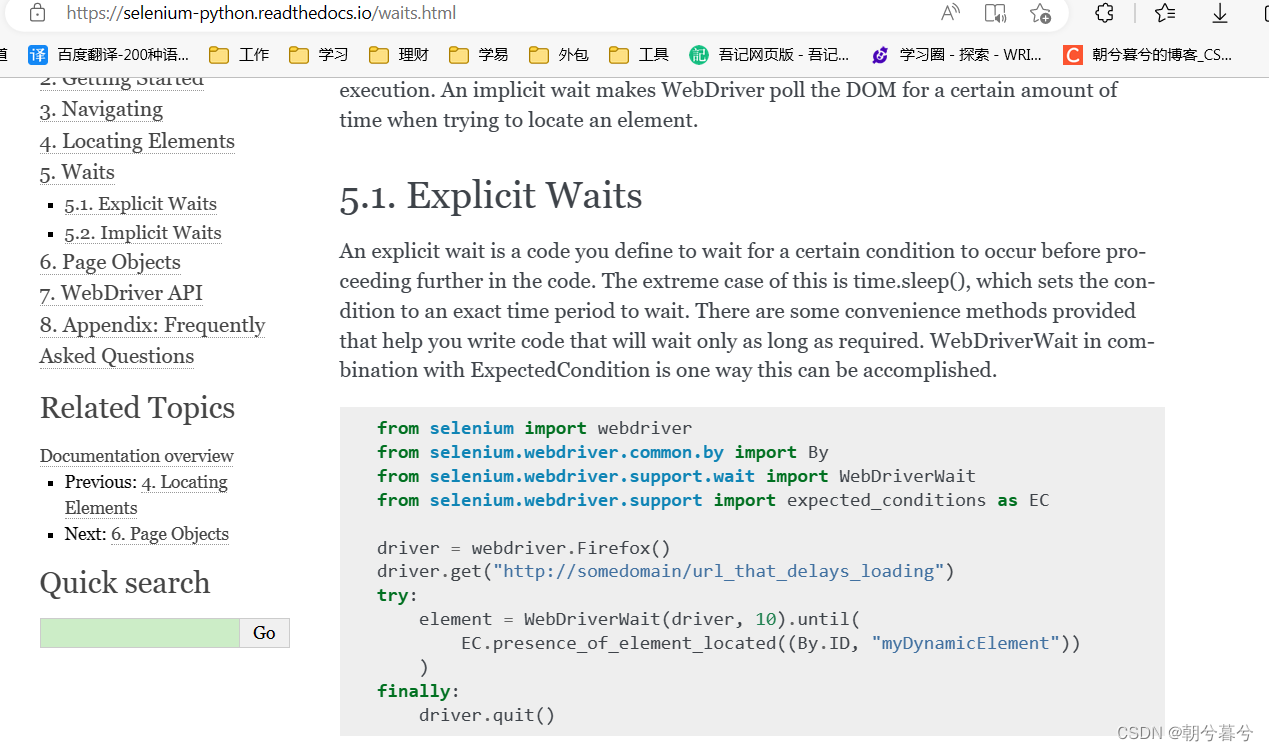
爬虫笔记之——selenium安装与使用(1)
爬虫笔记之——selenium安装与使用(1)一、安装环境1、下载Chrome浏览器驱动(1)查看Chrome版本(2)下载相匹配的Chrome驱动程序地址:https://chromedriver.storage.googleapis.com/index.html2、学…...
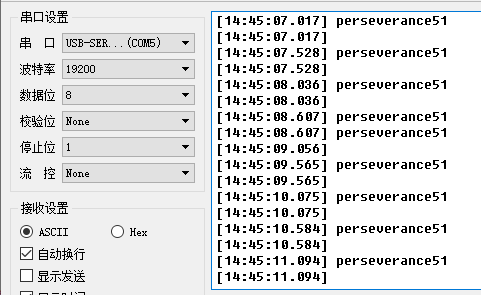
STC15单片机软串口的使用
STC15软串口的使用📖在没有使用定时器资源的情况下,根据波特率位传输时间,利用STC-ISP工具自动计算出位延时函数。 ✨在官方所提供的库函数中位传输时间函数,仅适用于使用波特率为:9600的串口数据传输: void BitTime(…...
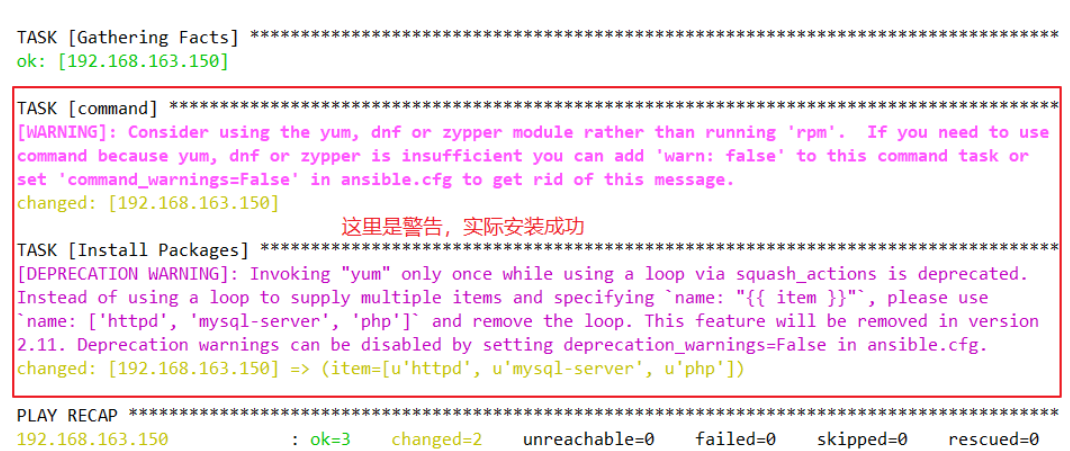
Ansible的脚本------playbook剧本
一、剧本的前置知识点1、主机清单ansible默认的主机清单是/etc/ansible/hosts文件主机清单可以手动设置,也可以通过Dynamic Inventory动态生成一般主机名使用FQDNvi /etc/ansible/hosts [webserver] #使用方括号设置组名 www1.example.org #定…...

实验5-计算中值及分治技术
目录 1.寻找中位数(利用快速排序来寻找中位数) 2.分治方法求数组的和 3.合并排序...

dbeaver从excel导入数据笔记
场景 有excel的数据,需要做到数据库里。 方案一: 开发代码来实现。缺点是需要开发成本。 方案二: 数据库导入工具导入。不用开发,相对快速一些。 这里说下数据库工具导入。 操作过程 1、拿到excel数据文件,根据标题…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...