初探推荐系统-01
文章目录
- 一、什么是推荐系统
- 是什么
- 为什么
- 长尾理论
- 怎么做
- 二、相似度算法
- 杰卡德相似系数
- 余弦相似度
- 三、基于内容的推荐算法
- 如何获取到用户喜欢的物品
- 如何确定物品的特征
- 四、推荐算法实验方法评测指标
- 推荐效果实验方法
- 1、离线实验
- 2、用户调查
- 3、在线实验
- 评测指标
- 1、预测准确度
- 评分预测
- TopN预测
- 关于评分预测问题和TopN预测的讨论
- 2、用户满意度
- 3、 覆盖率
- 4、多样性
- 5、新颖度
- 6、惊喜度
- 7、信任度
- 8、实时性
- 9、健壮性
- 总结
一、什么是推荐系统
是什么
推荐系统,顾名思义,就是向用户推荐物品或信息的系统。
推荐系统在我们的生活中随处可见:
- 在内容推送平台,比如抖音、头条、快手,推荐系统会根据你的兴趣向你推荐合适的内容
- 在电商平台,比如淘宝、京东,推荐系统会根据你的喜欢将一些物品优先放在首页
- 在社交平台,比如微博、facebook,推荐系统会向推荐你可能感兴趣的人
- 广告服务可以根据用户的兴趣针对性的投放广告
- …
为什么
我们为什么需要推荐系统?
对于用户而言(信息消费者),面对网上海量的信息,要从中找出我们感兴趣的信息,是一件非常难的事情。比如某一天我们闲来无事,想看一部电影解解闷,可是市面上的电影实在太多了,一时也不知道该看哪部电影。这时,推荐系统就可以为你选择一部你最可能感兴趣的电影。治好了你的选择困难症。
对平台而已(信息生成者),如何让自己生产的信息被广大用户关注到也是一个非常困难的事。而推荐系统就可以将这些信息针对性的推送给需要的人。拿电商平台举例,如果将用户感兴趣的物品放在用户浏览的首页,那么该物品被对应用户消费的概率将极大的提升,从而提高电商平台的销量。对于内容平台来说,好的推荐系统可以更好的留住用户,提高平台的用户留存率。
另外,推荐系统可以更好的发掘物品的长尾。
长尾理论
在了解长尾理论,先来看一个非常著名的定律:82定律。82定律相信在座的大家应该都有所耳闻。
82原则也叫二八定律,正规叫法是巴莱多定律。巴莱多定律是1897年意大利经济学家巴莱多提出的。他认为,在任何一组东西中,最重要的只占其中一小部分,约20%,其余80%的尽管是多数,却是次要的,因此又称二八法则。

82定律在我们的生活中普遍适用:80%的销售额都来自于20%的热门商品,20%的人占据了社会财富的80%,80%的业务收入是由20%的客户创造的,20%的强势品牌,占有80%的市场份额。
然而,这个定律在互联网时代受到了挑战。美国《连线》杂志主编克里斯·安德森在2004年发表了"The Long Tail"一文并于2006年出版了《长尾理论》一书。该书指出,传统的82原则在互联网的加入下会受到挑战。
在互联网的条件下,由于货架成本低端低廉,电子商务网站往往能出售比传统零食店更多的商品。虽然这些商品绝大数都不热门,但是数量却极其庞大,总体销售额并不会输给那些热门商品。
这里我们将那些不热门的商品统称为长尾商品,热门的成为头部商品。

在传统的82定律中,头部商品的销售额可能是80%,长尾商品的销售额可能仅20%
在长尾理论中,得利于互联网低廉的货架成本,长尾商品的销售额能得到50%甚至更多。
一般而言,头部商品代表了绝大数用户的需求,而长尾商品往往代表了一小部分用户的个性化需求。因此,如果想通过发掘长尾提高销售额,就必须充分研究用户的兴趣,这正是个性化推荐系统主要解决的问题。
举个例子,某个用户喜欢玩游戏,尤其偏好动作类游戏,但是如今市面上的游戏实在太多了,用户不可能全部都了解。但有了推荐系统后,游戏平台就可以根据该用户的爱好,给他推送一些他没玩过的冷门但口碑不错的动作游戏。这类冷门的动作游戏就属于长尾商品,如果没有推荐系统主动推荐,大部分用户都不会找到并购买这些游戏。
因此,推荐系统可以很好的发掘那些长尾物品的销量。
怎么做
抛开推荐系统,我们先想象一下在生活中面对很多选择时做决定的过程。我们以看电影为例,假设我们一时不知道要看什么电影,那么我们可能采用如下方式来决定最终要看什么电影:
- 想朋友咨询。我们可能会打开聊天工具,找几个经常看电影的朋友,问他们有没有什么好看的电影可以推荐。或者打开微博,发一句"我想看电影,求推荐",然后等待热心人推荐电影。
- 我们一般都有喜欢的演员和导演。这时我们可以打开搜索引擎,输入自己喜欢的演员名,然后看看结果中还有什么电影是自己没看过的。这种方式是寻找和自己之前看过的电影在内容上相似的电影。推荐系统可以将上诉过程自动化,通过分析用户曾经看过的电影找到用户喜欢的演员和导演,然后给用户推荐这些演员或导演的其他电影。这种推荐方式在推进系统中称为基于内容的推荐。
- 我们可以查看排行榜,比如豆瓣电影排行榜,看看别人都在看什么电影,别人都喜欢什么电影,然后找一部广受好评的电影观看。这种方式可以进一步扩展:如果能找到和自己历史兴趣相似的一群用户,看看他们最近都在看什么电影,那么就能结果会比宽泛的排行榜更能符合自己的兴趣。这种方式称为基于协同过滤的推荐。
从上面的方法可以看出,推荐算法的本质是通过一定的方式将用户和物品联系起来,不同的推荐系统使用了不同的方式。上面的例子让我们了解了两种实现推荐系统的方式:
- 基于内容的推荐:找到用户感兴趣的类型,推荐给他和该类型相似的物品
- 基于协同过滤的推荐:找到和用户兴趣相似的用户,从这些相似用户中找出用户之前没接触过的物品推荐给用户
如果仔细琢磨,会发现这两个方式有个共同点,那就是寻找相似。是的,基于内容的推荐需要寻找相似的物品,基于协同过滤的推荐需要寻找兴趣相似的用户。那么,如果定义物品之间的相似度以及用户之间的相似度,是一个很重要的命题。
二、相似度算法
要判断物品、用户之间的相似度,需要一定的算法。目前常见的相似度算法有:
- 杰卡德相似系数
- 余弦相似度
- 通过距离计算相似度(比如欧式距离、曼哈顿距离)
- 皮尔逊相关系数
下面我们分别使用杰卡德相似系数和余弦相似度为大家介绍一下如何计算物品或用户之间的相似度。
杰卡德相似系数
假设现在有4个用户,他们的购买行为如下:
| 用户标识 | 购买物品列表 |
|---|---|
| u1 | a、b、d、e |
| u2 | a、c |
| u3 | b、c、d |
| u4 | a、c、d、e |
我们来看一下如何利用杰卡德相似系数来计算这些用户之间的相似度。首先杰卡德系数的计算公式如下:
J(A,B)=∣A∩B∣∣A∪B∣=∣A∩B∣∣A∣+∣B∣−∣A∩B∣=A和B的交集AunionBJ(A, B)=\frac{|A \cap B|}{|A \cup B|}=\frac{|A \cap B|}{|A|+|B|-|A \cap B|}=\frac{A和B的交集}{A union B} J(A,B)=∣A∪B∣∣A∩B∣=∣A∣+∣B∣−∣A∩B∣∣A∩B∣=AunionBA和B的交集
J(A,B) 表示用户A和用户B之间的相似度。
公式很简单,我们先来看一下分子,A ∩ B表示用户A的购买记录和用户B的购买记录的交集。拿上面的数据举例,u1用户和u2用户的交集为:{a、b、d、e} ∩ {a、c} = {a}
之后来看一下分母,它的意思是A和B做union的结果(注意不是union all)。因此,拿u1用户和u2用户距离,此时union出来的结果为 {a、b、d、e} union {a、c} = {a、b、c、d、e}
因此我们可以得出
J(u1,u2)={a}{a、b、c、d、e}=15=0.2J(u_1, u_2)=\frac{\{a\}}{\{a、b、c、d、e\}}=\frac{1}{5}=0.2 J(u1,u2)={a、b、c、d、e}{a}=51=0.2
之后继续计算u1和u3、u4之间的相似度:
J(u1,u3)={a、b、d、e}∩{b、c、d}{a、b、d、e}union{b、c、d}={b、d}{a、b、c、d、e}=25=0.4J(u_1, u_3)=\frac{\{a、b、d、e\}\cap\{b、c、d\}}{\{a、b、d、e\}union\{b、c、d\}}=\frac{\{b、d\}}{\{a、b、c、d、e\}}=\frac{2}{5}=0.4 J(u1,u3)={a、b、d、e}union{b、c、d}{a、b、d、e}∩{b、c、d}={a、b、c、d、e}{b、d}=52=0.4
J(u1,u4)={a、b、d、e}∩{a、c、d、e}{a、b、d、e}union{a、c、d、e}={a、d、e}{a、b、c、d、e}=35=0.6J(u_1, u_4)=\frac{\{a、b、d、e\}\cap\{a、c、d、e\}}{\{a、b、d、e\}union\{a、c、d、e\}}=\frac{\{a、d、e\}}{\{a、b、c、d、e\}}=\frac{3}{5}=0.6 J(u1,u4)={a、b、d、e}union{a、c、d、e}{a、b、d、e}∩{a、c、d、e}={a、b、c、d、e}{a、d、e}=53=0.6
因此从杰卡德相似系数可以看出,u1用户和u4用户是相似的。
余弦相似度
余弦相似度是通过测量两个向量之间的夹角余弦值来衡量他们之间的相似程度。

如上图,A(1,2)和B(2,1)分别是两个向量,θ 是两个向量的夹角,cosθ 是夹角的余弦值。θ的取值范围是是[0,180度],对应的cosθ范围为[-1,1]

- 当cosθ等于1时,也就是θ=0,a和b的方向一致,此时可以认为它们的相似度最大
- 当cosθ等于-1时,也就是θ=180度时,a和b的方向完全相反,此时可以认为它们的相似度最小
因此,cosθ的值越大,两个向量的相似度就越大
需要注意的是,余弦相似度关注的是向量的方向,因此向量的大小并不重要。比如下图:

向量(1,2)和向量(2,1)的相似度是cosθ,和向量(4,2)的相似度也是cosθ。
知道了余弦值如何表达相似度后,我们该计算两个向量之间的余弦值呢。
首先从余弦定理出发,高中时大家应该都有学过余弦定理:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FM0SqtwS-1677574284171)(推荐系统-1.assets/image-20220928160004213.png)]
c2=a2+b2−2abcosθa2=b2+c2−2bccosβb2=c2+a2−2cacosα\begin{array}{l} c^{2}=a^{2}+b^{2}-2 a b \cos \theta \\ a^{2}=b^{2}+c^{2}-2 b c \cos \beta \\ b^{2}=c^{2}+a^{2}-2 c a \cos \alpha \end{array} c2=a2+b2−2abcosθa2=b2+c2−2bccosβb2=c2+a2−2cacosα
勾股定理是余弦定理的特殊情况,即α为90度时,cosα=0,此时
b2=a2+c2b^{2}=a^{2}+c^{2} b2=a2+c2
根据余弦定理,我们可以推出
cosθ=a2+b2−c22ab\cos \theta=\frac{a^2+b^2-c^2}{2ab} cosθ=2aba2+b2−c2
其中a、b、c三条边的大小我们通过两个向量A、B可以求出(A、B加上坐标轴原点构成了一个三角形)。
假设有向量A(x1,x2)和B(y1,y2),那么
a2=(x1−0)2+(x2−0)2=x12+x22b2=(y1−0)2+(y2−0)2=y12+y22c2=(x1−y1)2+(x2−y2)2=x12−2∗x1y1+y12+x22−2∗x2y2+y22\begin{array}{l} a^{2}=(x_1-0)^{2}+(x_2-0)^{2}=x_1^2+x_2^2 \\ b^{2}=(y_1-0)^{2}+(y_2-0)^{2}=y_1^2+y_2^2 \\ c^{2}=(x_1-y_1)^{2}+(x_2-y_2)^{2}=x_1^{2}-2 * x_1 y_1+y_1^{2}+x_2^{2}-2 * x_2 y_2+y_2^{2} \end{array} a2=(x1−0)2+(x2−0)2=x12+x22b2=(y1−0)2+(y2−0)2=y12+y22c2=(x1−y1)2+(x2−y2)2=x12−2∗x1y1+y12+x22−2∗x2y2+y22

所以可得:
cosθ=x12+x22+y12+y22−x12+2∗x1y1−y12−x22+2∗x2y2−y222(x12+x22)(y12+y22)=x1y1+x2y2x12+x22×y12+y22\cos \theta=\frac{x_1^2+x_2^2+y_1^2+y_2^2-x_1^{2}+2 * x_1 y_1-y_1^{2}-x_2^{2}+2 * x_2 y_2-y_2^{2}}{2\sqrt{(x_1^2+x_2^2)} \sqrt{(y_1^2+y_2^2)} }=\frac{x_{1} y_{1}+x_{2} y_{2}}{\sqrt{x_{1}^{2}+x_{2}^{2}} \times \sqrt{y_{1}^{2}+y_{2}^{2}}} cosθ=2(x12+x22)(y12+y22)x12+x22+y12+y22−x12+2∗x1y1−y12−x22+2∗x2y2−y22=x12+x22×y12+y22x1y1+x2y2
数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, …, An] ,B是 [B1, B2, …, Bn] ,则A与B的夹角θ的余弦等于:
cosθ=∑i=1n(Ai×Bi)∑i=1n(Ai)2×∑i=1n(Bi)2=A⋅B∣A∣×∣B∣\begin{aligned} \cos \theta &=\frac{\sum_{i=1}^{n}\left(A_{i} \times B_{i}\right)}{\sqrt{\sum_{i=1}^{n}\left(A_{i}\right)^{2}} \times \sqrt{\sum_{i=1}^{n}\left(B_{i}\right)^{2}}} \\ &=\frac{A \cdot B}{|A| \times|B|} \end{aligned} cosθ=∑i=1n(Ai)2×∑i=1n(Bi)2∑i=1n(Ai×Bi)=∣A∣×∣B∣A⋅B
知道了余弦相似度如何计算后,我们该如何去计算用户之间的相似度呢,还是以这几个用户举例:
| 用户标识 | 购买物品列表 |
|---|---|
| u1 | a、b、d、e |
| u2 | a、c |
| u3 | b、c、d |
| u4 | a、c、d、e |
余弦相似度只能计算两个向量之间的相似,而上面用户对应数据是一个物品列表,因此我们需要对其进行编码。
因为物品的总数量是5个,因此我们可以用一个5维的向量来表示。比如A[A1、A2、A3、A4、A5]的5个值分别对应a、b、c、d、e的购买行为,购买过则值为1,没购买过则为0。通过编码,我们可以得到各个用户对应的向量:
| a | b | c | d | e | 最终编码(向量) | |
|---|---|---|---|---|---|---|
| u1 | 1 | 1 | 0 | 1 | 1 | (1,1,0,1,1) |
| u2 | 1 | 0 | 1 | 0 | 0 | (1,0,1,0,0) |
| u3 | 0 | 1 | 1 | 1 | 0 | (0,1,1,1,0) |
| u4 | 1 | 0 | 1 | 1 | 1 | (1,0,1,1,1) |
之后使用余弦相似度计算u1和其他用户之间的相似度:
cos(u1,u2)=1∗1+1∗0+0∗1+1∗0+1∗01∗1+1∗1+0∗0+1∗1+1∗1∗1∗1+0∗0+1∗1+0∗0+0∗0=18cos(u1,u3)=1∗0+1∗1+0∗1+1∗1+1∗01∗1+1∗1+0∗0+1∗1+1∗1∗0∗0+1∗1+1∗1+1∗1+0∗0=212=13cos(u1,u4)=1∗1+1∗0+0∗1+1∗1+1∗11∗1+1∗1+0∗0+1∗1+1∗1∗1∗1+0∗0+1∗1+1∗1+1∗1=34\begin{array}{l} \cos (u_1,u_2)=\frac{1*1+1*0+0*1+1*0+1*0}{\sqrt{1*1+1*1+0*0+1*1+1*1}*\sqrt{1*1+0*0+1*1+0*0+0*0}}=\frac{1}{\sqrt{8} }\\ \cos (u_1,u_3)=\frac{1*0+1*1+0*1+1*1+1*0}{\sqrt{1*1+1*1+0*0+1*1+1*1}*\sqrt{0*0+1*1+1*1+1*1+0*0}}=\frac{2}{\sqrt{12} }=\frac{1}{\sqrt{3} }\\ \cos (u_1,u_4)=\frac{1*1+1*0+0*1+1*1+1*1}{\sqrt{1*1+1*1+0*0+1*1+1*1}*\sqrt{1*1+0*0+1*1+1*1+1*1}}=\frac{3}{4} \end{array} cos(u1,u2)=1∗1+1∗1+0∗0+1∗1+1∗1∗1∗1+0∗0+1∗1+0∗0+0∗01∗1+1∗0+0∗1+1∗0+1∗0=81cos(u1,u3)=1∗1+1∗1+0∗0+1∗1+1∗1∗0∗0+1∗1+1∗1+1∗1+0∗01∗0+1∗1+0∗1+1∗1+1∗0=122=31cos(u1,u4)=1∗1+1∗1+0∗0+1∗1+1∗1∗1∗1+0∗0+1∗1+1∗1+1∗11∗1+1∗0+0∗1+1∗1+1∗1=43
通过余弦相似度公式我们可以算出,u4和u1的相似度是最大的。
三、基于内容的推荐算法
Content-based Recommendations(CB)是推荐系统中最基础的算法,也是最古老的算法。它会根据用户过去喜欢的物品,为用户推荐和这个物品相似的物品。这个相似判断是通过抽取物品的内在或外在的特征值来实现的。
举个例子,对于一个电影来说,它的特征可能有[导演、演员、影片类型、时长、所属国家、用户打分、…]。基于这些特征,我们通过相似度算法计算出各个电影之间的相似度。
总得来说,基于内存的推荐算法很好理解,一共就分两步:
- 获取用户喜欢的物品
- 通过该物品的特征,找到和该物品最相似的N个物品,推荐给用户

如何获取到用户喜欢的物品
用户不会主动告诉我们他喜欢什么物品,因此我们需要根据用户的相关行为来构建用户画像信息。具体什么行为得根据不同的场景来判断。
- 对于电影网站来说,用户的评分就可以拿来当评判依据,如果用户喜欢一个电影,自然会打比较高的分数
- 对于电商网站,用户的购买行为也可以当成用户喜欢这个物品
- 对于资讯类网站,我们可以拿用户的浏览时长来作为评判标准

如何确定物品的特征
基于内容的推荐第二步是找到和用户喜欢物品最相似的N个物品。
相似度算法之前已经介绍过了,但在使用相似度算法之前,我们需要确定物品有哪些特征。因此,如何挖掘物品的特征是基于内容的推荐算法中的核心问题。可以说,基于内容的推荐,最重要的不是推荐算法,而是内容挖掘和分析(也就是挖掘物品的特征/标签)。内容挖掘的越深,才能让推荐算法达到更好的效果。
对于物品的特征提取/标签挖掘,一般有几种办法:
- 专家标签:雇佣一些专门的人员为网站上的物品逐个打标签(数据标注工程师)
- 用户自定义标签(UGC):让用户自己为各个物品打标签(豆瓣)
- 降维分析数据,提取隐语义标签(隐语义模型)
- 分词、语议处理和情感分析 —— 适用于一些物品是文本的网站(NLP)

四、推荐算法实验方法评测指标
推荐效果实验方法
当我们需要验证一个算法好坏的时候,需要进行一些实验。关于评测推荐效果的实验方法,一般有三种
1、离线实验
- 通过日志系统获取用户的行为数据,并按照一定格式生成一个标准的数据集
- 将数据集按照一定的规则分成训练集和测试集
- 在训练集上训练用户兴趣模型,在测试集上进行预测
- 通过实现定义的离线指标评测算法在测试集上的预测结果
这个可以说是机器学习领域中很通用的方法,它的优缺点如下:
- 优点:不需要有对实际系统的控制权、不需要用户参与实验、速度快且可以测试大量算法
- 缺点:离线实验的指标和具体商业指标存在差距
2、用户调查
离线实验虽然方便高效,但是离线实验出来的结果可能和实际效果有较大的出入。为了测试实际的效果,我们可以在上线前做一次小规模的用户测试调查,选择部分真实用户,在我们部署的测试环境中进行操作,完成一些任务,然后观察其行为,并问他们一些问题。通过分析他们的行为和答案来判断算法的效果。
- 优点:可以获得很多体现用户主观感受的指标,相对在线实验风险很低,出现错误后很容易弥补
- 缺点:招募测试用户代价较大,很难组织大规模的测试用户。另外,可能会因为一些心态的原因,导致用户在测试环境和行为和真实环境下的行为有些出入,对评测结果造成一些影响
3、在线实验
在完成离线实验和必要的用户调查后,可以将算法上线做AB测试,将其和旧的算法进行比较。
AB测试是常用的在线评测算法的实验方法,它可以通过一定的规则将用户随机分成几组,对不同组的用户采用不同的算法,然后通过各种不同的评测指标来衡量哪种算法比较好。比如可以统计用户的点击率、停留时间等指标来评测效果算法好坏。
- 优点:可以直接获得实际在线时的性能指标,包括商业上关注的指标
- 缺点:实验周期比较长,需要长期的实验才能得到可靠的结果。同时AB测试系统也是个复杂的工程,需要投入较多的人力成本开发。
评测指标
1、预测准确度
预测准确度是说一个推荐系统或者推荐算法预测用户行为的能力。它是推荐系统最重要的一个指标,从推荐系统诞生的那一天起, 几乎99%与推荐相关的论文都在讨论这个指标。这主要是因为该指标可以通过离线实验计算,方便了很多学术界的研究人员研究推荐算法。
在离线实现中,我们可以将数据集分为训练集和测试集,通过测试集来预测算法的准确度。不同的推荐场景对于准确度有不同的计算方法。主要的推荐场景一般有两种,分别是评分预测和TopN推荐。
评分预测
很多提供推荐服务的网站都有一个让用户给物品打分的功能。那么,如果知道了用户对物品的历史评分,就可以从中习得用户的兴趣模型, 并预测该用户在将来看到一个他没有评过分的物品时,会给这个物品评多少分。预测用户对物品评分的行为称为评分预测。
评分预测的预测准确度一般通过均方根误差 (RMSE) 和平均绝对误差 ( MAE ) 计算。rui表示用户u对物品i的实际评分,rui表示用户u对物品i的预测评分,T表示测试集的样本数量,那么
RMSE(均方根误差)=∑u,i∈T(rui−r^ui)2∣T∣=∑u,i∈T(实际评分−预测评分)2∣样本数量∣\operatorname{RMSE(均方根误差)}=\sqrt{\frac{\sum_{u, i \in T}\left(r_{u i}-\hat{r}_{u i}\right)^{2}}{|T|} }=\sqrt{\frac{\sum_{u, i \in T}\left(实际评分-预测评分\right)^{2}}{|样本数量|} } RMSE(均方根误差)=∣T∣∑u,i∈T(rui−r^ui)2=∣样本数量∣∑u,i∈T(实际评分−预测评分)2
MAE(平均绝对误差)=∑u,i∈T∣rui−r^ui∣∣T∣=∑u,i∈T∣实际评分−预测评分∣∣样本数量∣\mathrm{MAE(平均绝对误差)}=\frac{\sum_{u, i \in T}\left|r_{u i}-\hat{r}_{u i}\right|}{|T|}=\frac{\sum_{u, i \in T}\left|实际评分-预测评分\right|}{|样本数量|} MAE(平均绝对误差)=∣T∣∑u,i∈T∣rui−r^ui∣=∣样本数量∣∑u,i∈T∣实际评分−预测评分∣
RMSE与MAE对比:RMSE针对异常值更敏感(即有一个预测值与真实值相差很大,那么RMSE就会很大)。因此,使用RMSE来评测准确度就意味着对系统的评测更为苛刻。在实际情况中,我们可以同时用这两个指标,通过查看MAE和RMSE的比值找出那些存在较大但不常见的错误。
TopN预测
网站在提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做TopN推荐。 TopN推荐的预测准确率一般通过准确率 ( precision ) /召回率 (recall ) 度量。
假设R(u)是算法给用户u的推荐列表,T(u)是用户u真实的行为列表。那么
Recall(召回率) =∑u∈U∣R(u)⋂T(u)∣∑u∈U∣T(u)∣\text { Recall(召回率) }=\frac{\sum_{u \in U}|R(u) \bigcap T(u)|}{\sum_{u \in U}|T(u)|} Recall(召回率) =∑u∈U∣T(u)∣∑u∈U∣R(u)⋂T(u)∣
Precision(准确率) =∑u∈U∣R(u)⋂T(u)∣∑u∈U∣R(u)∣\text { Precision(准确率) }=\frac{\sum_{u \in U}|R(u) \bigcap T(u)|}{\sum_{u \in U}|R(u)|} Precision(准确率) =∑u∈U∣R(u)∣∑u∈U∣R(u)⋂T(u)∣
也就是说,假设我们给用户推荐了5个物品,用户自己消费了10个物品,而我们推荐的物品中只有一个和用户真实的列表一致,那么召回率就是1/10=10%,准确率就是1/5=20%。
关于评分预测问题和TopN预测的讨论
评分预测一直是推荐系统研究的热点,这主要是因为推荐系统的早期研究组GroupLens的研究主要是基于电影评分数据MovieLens进行的,同时推荐系统的Netflix大赛也主要面向评分预测问题。
但有科学家指出,TopN预测更符合实际的应用场景。因为即使我们对用户的评分预测的非常准确,也不能表明它能为我们带来多少收益。
举个例子,在豆瓣上有许多冷门的高分电视剧或电影,这些电影都是高品质的,大部分人去看应该也会打高分。但是打高分并不意味着用户就感兴趣,如果我们因为预测用户对这些电影评分高而向他们推荐这些电影,那最后八成会被大部分用户忽视。
备注:
但是准确的预测并不代表好的推荐。
比如一个用户本来就要准备购买某书,那么无论是否给他推荐,他都准备购买,所以这个推荐结果显然是不好的,因为它未使用户购买更多的书。
2、用户满意度
用户作为推荐系统的重要参与者,用户的满意度也是最重要的指标之一。与预测准确度相比,用户满意度是个相对主观的指标,因此无法通过离线实验计算出来,只能通过在线实验和用户调查中获得。
在做用户调查时,我们可以根据发放问卷的形式来收集用户的满意度,拿GroupLens曾经做过的一个论文推荐系统的问卷来举例。该问卷是让用户选择哪句话是看到推荐内容结果后的感受:
- 推荐的论文都是我比较想看的
- 推荐的论文很多我都看过了,确实是符台我兴趣的不错论文
- 推荐的论文和我的研究兴趣是相关的,但我并不喜欢
- 不知道为什么会推荐这些论文,他们和我的兴趣丝毫没有关系
这个问卷可以看出,设计满意度问卷时不能单单让用户回答是否满意,可能用户心里认为大体满意,但是对某些方面不满意,因而可能很难回答这个问题。需要设计问卷时需要充分考虑到用户各方面的感受,这样才能针对问题给出准确的回答。
在在线系统中,用户满意度用户的一些行为来统计得到。比如统计用户在对应物品上的点击率、用户停留时间和转化率等来手机用户的满意度。
3、 覆盖率
覆盖率是描述一个推荐系统对物品长尾的发掘能力。覆盖率有不同的定义方法,最简单的定义就是推荐出来的物品集合占总物品的比例。即:
覆盖率=推荐的物品数量总物品数量覆盖率=\frac{推荐的物品数量}{总物品数量} 覆盖率=总物品数量推荐的物品数量
再复杂些的系统就需要考虑上推荐列表中物品出现次数的分布。如果所有的物品都出现在推荐列表中,且出现的次数差不多,那么说明该推荐系统的覆盖率高,发掘长尾的能力很好。
在信息论和经济学中有两个著名的指标可以用来定义覆盖率。第一个是信息熵:
H=−∑i=1np(i)logp(i)H=-\sum_{i=1}^{n} p(i) \log p(i) H=−i=1∑np(i)logp(i)
这里的p(i)是物品的流行度除以所有物品流行度之和。
第二个是基尼系数:
G=1n−1∑j=1n(2j−n−1)p(ij)G=\frac{1}{n-1} \sum_{j=1}^{n}(2 j-n-1) p\left(i_{j}\right) G=n−11j=1∑n(2j−n−1)p(ij)
推荐系统的初衷是消除马太效应,需要用基尼系数。。。。
4、多样性
用户的兴趣是广泛的,在视频网站中,一个用户既可能喜欢看《猫和老鼠》一类的动画片,也喜欢看成龙的动作片。因此,推荐列表最好能覆盖用户不同的兴趣领域,即推荐结果需要具有多样性。
多样性保证了我们不会在一棵树上吊死。举个例子,某个用户对于电影的兴趣可能有很多,比如喜剧片、动作片、恐怖片。但是在某一时刻(比如他心情不好),只想看喜剧片,这时候多样性就保证了用户找到感兴趣电影的概率。而如果推进的列表品类单一,则用户找到感兴趣电影的概率就会降低。
多样性描述了推荐列表中物品的不相似程度,因此多样性和相似性是对应的。假设s(i,j)-[0,1]定义了物品i和物品j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下:
Diversity =1−∑i,j∈R(u),i≠js(i,j)12∣R(u)∣(∣R(u)∣−1)\text { Diversity }=1-\frac{\sum_{i, j \in R(u), i \neq j} s(i, j)}{\frac{1}{2}|R(u)|(|R(u)|-1)} Diversity =1−21∣R(u)∣(∣R(u)∣−1)∑i,j∈R(u),i=js(i,j)
推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
Diversity =1∣U∣∑u∈UDiversity (R(u))\text { Diversity }=\frac{1}{|U|} \sum_{u \in U} \text { Diversity }(R(u)) Diversity =∣U∣1u∈U∑ Diversity (R(u))
关于推荐系统的多样性最好达到什么程度,我们可以通过一个简单的例子来了解一下。假设某个用户喜欢动作片和动画片,且用户80%的时间都在看动作片,20%的时间都在看动画片。那么,下面4种推荐列表:
- A列表中有10部动作片,没有动画片
- B列表中有10部动画片,没有动作片
- C列表中有8部动作片,2部动画片
- D列表中有5部动作片,5部动画片
可以看出,AB列表缺乏多样性,D列表过于多样,没有考虑到用户的主要兴趣。C列表是最好的,因为它考虑到了用户的主要兴趣,又具有一定的多样性。因此,多样性也需要根据用户的实际情况来调整。
5、新颖度
新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。推荐列表保证一定的新颖度可以更好的发掘用户的兴趣。评测新颖度的最简单方法就是利用推荐结果的平均流行度,因为越不热门的物品越可能让用户觉的新颖。因此,如果推荐结果中物品的平均热门程度越低,那么推荐结果就可能有比较高的新颖度。
但是这个方法还是比较粗略的,因为不同用户不知道的东西是不同的,所以要准确的统计新颖度还需要做用户调查。
可能有同学会发现,要保证新颖度很可能会牺牲准确度。因此,如何不牺牲准确度的情况下,提高多样性和新颖度也是推荐系统近几年的一个研究方向。
6、惊喜度
惊喜度和新颖度有些相似,但也有一定区别。
举个例子,假设一个用户喜欢周星驰的电影,我们给他推荐了一部《临歧》的电影(1983年由刘德华、周星驰、梁朝伟合作演出,很少有人知道这部电影有周星驰出演),而该用户不知道这部电影,那可以说这个推荐具有新颖性,但是没有惊喜度,因为该用户一旦了解了这个电影的演员,就不会觉得特别奇怪。
如果我们给用户推荐了张艺谋导演的《红高粱》,假设用户没有看过这部电影,那么他看完这部电影后可能会觉的很奇怪,因为这部电影和他的兴趣一点关系也没有,但如果看完之后觉的很不错,那就可以说这个推荐是让用户惊喜的。
总的来说,惊喜度就是推荐和用户历史上喜欢的物品不想死,但用户却觉得很满意的推荐。
不过目前也没有什么公认的惊喜度指标定义的方式,虽然近几年学术界对惊喜度问题有了一定的关注,但是还没有太成熟的结果。
7、信任度
用户对推荐系统的信任度也是影响推荐好坏的一个非常重要的指标。
举个现实生活中的例子,你有2个朋友,一个非常靠谱,一个整天满嘴跑火车。那个靠谱的朋友推荐你去某个地方旅游时,你很可能听从他的建议。而那个满嘴跑火车的朋友的建议,你很可能就不会当回事。
提高推荐系统的信任度主要有两个方法:
- 增加系统的透明度,也就是需要向用户提供推荐解释,只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对系统的信任度。
- 充分利用用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推进解释。因为用户一般对他们的好友都比较信任,如果推进的商品刚好是好友购买过的,那么他们对推荐结果就会相比比较信任
8、实时性
实时性主要描述了时间因素对推荐效果带来的影响。
一种情况是物品本身具有时效性,比如一个新闻网站经常给用户推荐两三年前的新闻,那么这个网站无疑会失去大量用户。
还有一种情况,比如一个用户刚买了一部iphone,那么我们立刻给他推荐iphone相关配件肯定比第二天才给他推荐效果来的好。
9、健壮性
任何一个能带来收益的系统都会被人攻击。这方面最为典型的例子就是搜索引擎。搜索引擎的作弊和反作弊斗争异常激烈,因为如果能让自己的商品成为热门搜索的第一个搜索结果,会带来极大的商业利益。推荐系统也有类似的问题,而健壮性指标则衡量了一个推荐系统抗击作弊的能力。
举个例子,亚马逊有一种推荐叫做"购买商品A的用户也经常购买的其他商品",它的主要计算方法是统计购买商品A的用户购买其他商品的次数。那么,我们可以很简单的攻击这个算法,让自己的商品在这个推荐列表中获得比较高的排名。比如可以注册很多账号,用这些账号同时购买商品A和自己的商品。
为了让系统的健壮性更高,我们要尽量在使用数据前过滤掉一些异常数据,同时尽量使用用户代价较高的用户行为。比如对比用户购买行为和用户浏览行为,购买行为需要付费,代价相对更高,而浏览行为很容易伪造,因此选择用户购买行为作为依据的算法会更健壮些。
总结
上面介绍了很多指标,有些可以离线计算,有些只能在线获得。在实际的开发中,我们很难同时兼顾所有的指标。因此,如何有选择的放弃或降低一些指标来实现收益最大化也是推荐系统研究的重要问题。
比如我们的优化策略可以是保证覆盖率、多样性、新颖度达到一定值的情况下,尽可能的让预测准确度达到最大。
Max(预测准确度){覆盖度>A多样性>B新颖度>C\begin{array}{l} Max(预测准确度) \\ \left\{\begin{matrix} 覆盖度>A \\ 多样性>B \\ 新颖度>C \end{matrix}\right. \end{array} Max(预测准确度)⎩⎨⎧覆盖度>A多样性>B新颖度>C
其中A、B、C的具体取值可以根据实际情况进行调整。
相关文章:
初探推荐系统-01
文章目录一、什么是推荐系统是什么为什么长尾理论怎么做二、相似度算法杰卡德相似系数余弦相似度三、基于内容的推荐算法如何获取到用户喜欢的物品如何确定物品的特征四、推荐算法实验方法评测指标推荐效果实验方法1、离线实验2、用户调查3、在线实验评测指标1、预测准确度评分…...

html实现浪漫的爱情日记(附源码)
文章目录1.设计来源1.1 主界面1.2 遇见1.3 相熟1.4 相知1.5 相念2.效果和源码2.1 动态效果2.2 源代码2.3 代码结构源码下载更多爱情表白源码作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/129264757 html实现浪漫的爱情…...
)
detectron2容器环境安装问题(1)
1为避免后面出现需求python版本低于3.7的情况ERROR: Package detectron2 requires a different Python: 3.6.9 not in >3.7可以第一步就使用 nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04镜像2如果使用了18.04的镜像nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04可以使用我…...
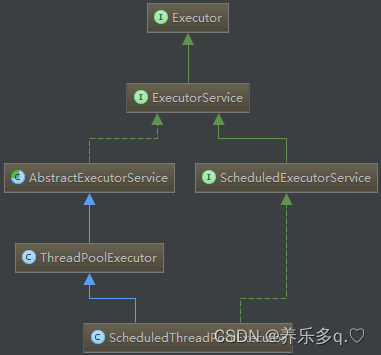
JAVA线程池原理详解二
JAVA线程池原理详解二 一. Executor框架 Eexecutor作为灵活且强大的异步执行框架,其支持多种不同类型的任务执行策略,提供了一种标准的方法将任务的提交过程和执行过程解耦开发,基于生产者-消费者模式,其提交任务的线程相当于生…...

Java 常用 API
文章目录一、Math二、System三、Object1. toString() 方法2. equals() 方法四、Arrays1. 冒泡排序2. Arrays 常用方法五、基本类型包装类1. Integer2. int 和 String 相互转换3. 字符串中数据排序4. 自动装箱和拆箱六、日期类1. Date2. SimpleDateFormat3. Calendar4. 二月天一…...

记一次分布式环境下TOKEN实现用户登录
背景: 以前的单体项目,使用的是session来保存用户登录状态,控制用户的登录过期时间等信息,但是这个session是只保存在该服务器的这个系统内存中。系统只有一个服务就没关系,但是如果是分布式的服务,每个…...

用cpolar发布本地的论坛网站 1
网页论坛向来是个很神奇的地方,曾经的天涯论坛和各种BBS,大家聚在在一起讨论某个问题,也能通过论坛发布想法,各种思维碰撞在一起,发生很多有趣的故事,也产生了很多流传一时的流行语录。当然,如果…...

CSS的4种引入方式
CSS的4种引入方式 目录CSS的4种引入方式一、内嵌式:CSS写在style标签中二、外联式:CSS写在一个单独的.css文件中三、行内式:CSS写在标签的style属性中四、导入外部样式五、css引用的优先级六、link和import的区别一、内嵌式:CSS写…...
Shell高级——Linux中的文件描述符(本质是数组的下标)
以下内容源于C语言中文网的学习与整理,非原创,如有侵权请告知删除。 前言 Linux中一切接文件,比如 C 源文件、视频文件、Shell脚本、可执行文件等,就连键盘、显示器、鼠标等硬件设备也都是文件。 一个 Linux 进程可以打开成百上…...
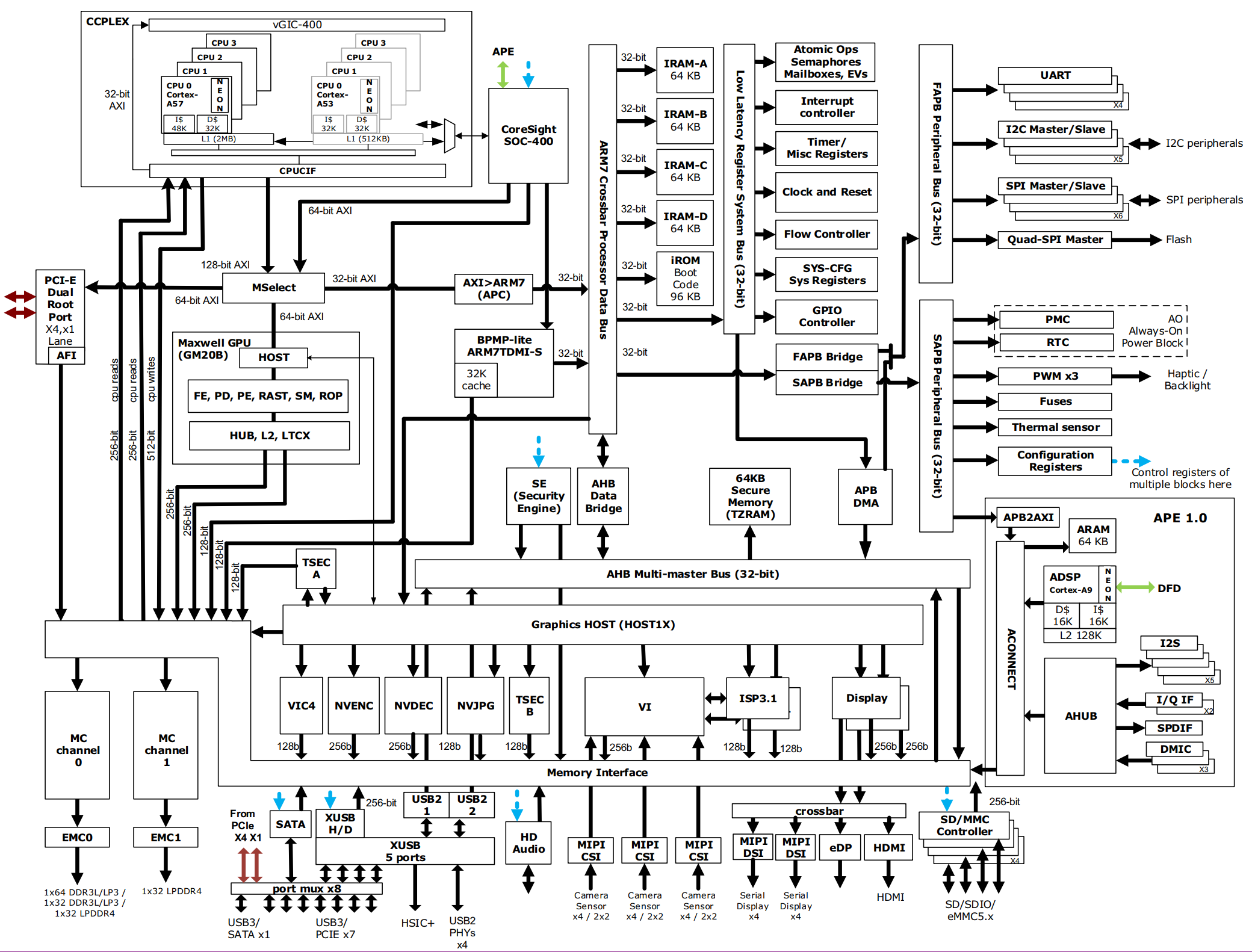
Nvidia jetson nano硬件架构
资料来源 官方文档中心 https://developer.nvidia.com/embedded/downloads -> 选jetson -> Jetson Nano Product Design Guide //产品设计指导(入口) //-> 1.1 References 列出了相关的文档 -> Jetson Nano Developer Kit Carrier Board Specification //板子标注…...

ffmpeg多路同时推流
一、ffmpeg常见使用方法1.1利用FFMPEG命令进行文件分割1.2转换格式1.3推流配置方法一:ngnix(不推荐,推流不好使)方法二:srs(强烈推荐)1.4查看nginx启动是否成功二、ffmpeg推流——>ngnix单路…...

一次性搞定 `SHOW SLAVE STATUS` 的解读
一次性搞定 SHOW SLAVE STATUS 的解读 解析日志文件的位置 诚然, GTID(全局事务标识符)已经在 MySQL 5.6中得到支持, 此外,还可以通过 Tungsten replicator 软件来实现(2009年以后一直有谷歌在维护,不是吗?)。 但有一部分人还在使用MySQL 5.5的标准副本方式, 那么这些二进制日…...

【代码随想录训练营】【Day25】第七章|回溯算法 |216.组合总和III|17.电话号码的字母组合
组合总和III 题目详细:LeetCode.216 做过上一题组合后,再来写这道题就显得得心应手了,通过理解回溯算法的模版,也总结出了算法中的一些特点: 回溯算法与递归算法类似,同样需要参数、结束条件和主体逻辑回…...

docker使用
https://blog.csdn.net/u012563853/article/details/125295985http://www.ppmy.cn/news/11249.html启动 docker服务并设置开机自动启动dockersudo systemctl start docker sudo systemctl enable dockerdocker 常见启动失败问题:https://blog.csdn.net/zhulianseu/article/deta…...

手把手docker registry配置登录名/密码
我们的Docker私有仓库Registry服务只有加了认证机制之后我们的Registry服务才会更加的安全可靠。赶快跟随以下步骤来增加认证机制吧。 创建docker registry工作目录 mkdir -p /data/docker.registry 创建将保存凭据的文件夹 mkdir -p /data/docker.registry/etc/registry/auth…...

一步打通多渠道服务场景 中电金信源启移动开发平台MADP功能“上新”
日前,中电金信源启移动开发平台MADP功能迭代升级,“上新”源启小程序开发平台。定位“为金融业定制”的移动PaaS平台,源启小程序开发平台为银行、互联网金融、保险、证券客户提供一站式小程序的开发、运营、营销全生命周期管理技术支撑&#…...
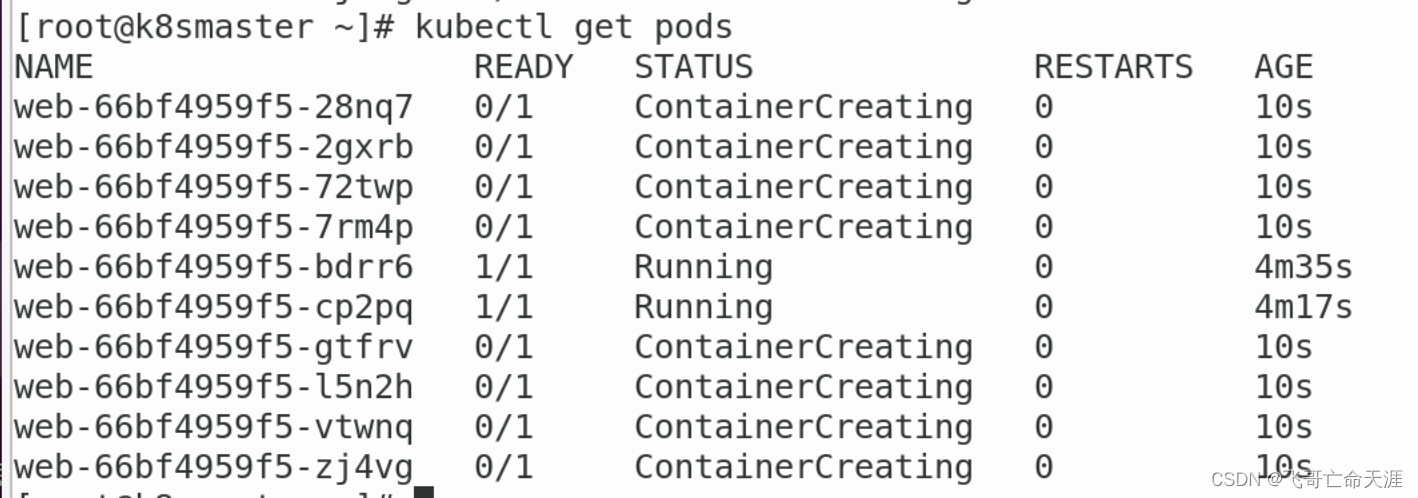
Kubernetes06:Controller (Deployment无状态应用)
Kubernetes06:Controller 1、什么是controller 管理和运行容器的对象,是一个物理概念 在集群上管理和运行容器的对象 2、Pod和Controller之间的关系 Pod是通过controller来实现应用的运维 比如伸缩、滚动升级等等操作Pod和Controller之间通过 label 标签建立关系…...

低代码开发平台选型必看指南
低代码开发是近年来逐渐兴起的一种新型软件开发方式。它通过封装常见的软件开发流程和代码,使得非专业的开发者也能够轻松创建复杂的应用程序。这种开发方式已经受到了许多企业的青睐,成为提高生产效率、降低开发成本的一种有效途径。 低代码开发的核心…...
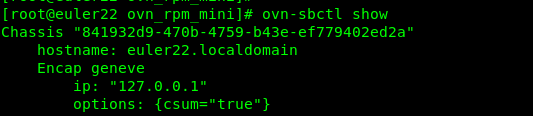
OVN:ovn20.03.1/ovs2.13.0编译rpm过程
操作系统openeuler22.0,x86架构分别下载ovn和ovs的源码https://github.com/openvswitch/ovs/tree/v2.13.0https://github.com/ovn-org/ovn/tree/v20.03.1安装必要工具:yum install -y unzip tar make autoconf automake libtool rpm-build gcc libuuid-d…...

Shell管道
一、管道是什么 英文是pipe。 把一个命令的标准输出作为下一个命令的标准输入,以这种方式连接的两个或者多个命令就形成了管道 使用竖线|连接多个命令,称为管道符。 语法格式如下: command1 | command2 [ | commandN... ] command1的标准…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...