目标检测算法之voxelNet与pointpillars对比
算法对比
3D目标检测发展简史
点云目标检测目前发展历经VoxelNet、SECOND、PointPillars、PV-RCNN。
2017年苹果提出voxelnet,是最早的一篇将点云转成voxel体素进行3D目标检测的论文。
然后2018年重庆大学的一个研究生Yan Yan在自动驾驶公司主线科技实习的时候将voxelnet代码完善,提出了高效的spconv实现,并增加了数据增强等,效果提高不少,论文起名SECOND。
PointPillars看到SECOND效果那么好,走了个捷径,把SECOND代码中的体素改成长条状的pillar,让代码跑的快,但是实际效果降低了。
后续就是PV-RCNN,把难看的SECOND代码重新整理,把point方法的优势结合进来,改成两阶段法,进一步提高SECOND效果,发表到CVPR2020。到此,基于voxel体素的方法基本达到了很高的效果,没法再大规模提高了。重庆大学的Yan Yan对这个领域的发展起到了至关重要的作用。
PointPillars 由于没有3D卷积,结构简单,效果也不错,是实际用的3D点云检测算法。
netron使用及理解
- 环境安装
pip install netron
- 运行py文件
import netron
if __name__ == '__main__': adress = ("localhost",8081) netron.start("alexnet.onnx",address=adress)
- 通过alex理解
Alexnet包括5个卷积和三个全连接层,共八层。网络结构如下:

其各层含义如下图所示:

netron可视化展示中,可详细看到5个卷积,三个全连接层。
补充:
netron可视化展示里,可在menu(菜单里)设置展示信息,图示中我已经设置展示所有信息,因此有很多hide操作。

pointpillars模型总结

- 将点云转换为稀疏伪图像的特征编码器网络;
- 首先在俯视图的平面上打网格(H x W)的维度;然后对于每个网格所对应的柱子中的每个点都取(x,y,z,r,x_c,y_c,z_c,x_p,y_p)9个维度。其中前三个为每个点的真实位置坐标,r为反射率,带c下表示该点到柱子中心的偏差,带p下标的是对点相对于网络中心的偏差。每个柱子中点多于N的进行采样,少于N的进行填充0.于是形成(D,N,P)D=9,N为点数(设定值),P=H*W。
- 然后学习特征,用一个简化的PointNet从D维中学出C个channel来,变为(C,N,P),然后对N进行最大化操作操作变为(C,P),又因为P是H*W的,我们再展开成一个伪图像形式,H,W为宽高,C为通道数。
- 2D卷积基础网络,用于将伪图像处理成高维特征表示;
- 包含两个子网络(1.top-down网络,2.second网络)top-down网络结构为了捕获不同尺度下的特征信息,主要是由卷积层、归一化、非线性层构成的,second网络用于将不同尺度特征信息融合,主要由反卷积来实现(上采样)。由一个2D卷积神经网络组成,其作用是用于在第一部分网络输出的伪图像上提取高维特征。
- 检测头部(detection head,SSD),对类别预测和对3D检测框的位置进行回归
- SSD检测头用于实现3D目标检测,与SSD类似,PointPillars在2D网格中进行目标检测,而Z轴坐标和高度则是通过回归方式得到。
VoxelNets模型可视化总结
VoxelNets模型是由28个卷积,3个转置卷积,26个BN,26层relu以及多个转置、重设等操作组成【BN主要解决传播过程中的梯度消失问题】。
输入由40000 x 4 的 voxel_coords及40000 x 32 x 10的features组成。

输出由1 x 200 x 380 x 8的hm与1 x 200 x 380 x 2的rot与1 x 200 x 380 x 3的dim及1 x 200 x 380 x 1的height及1 x 200 x 380 x 2的reg组成。

VoxelNet主要工作:
- 解决了点云无序化数据结构的提取问题。
使用voxel(三维世界中每一定空间大小划分成一个各自,然后用pointnet网络对小格子进行特征提取,用提取的特征代表这个小格子,并放回3D空间中。这样无序的点云数据就变成一个个高维特征数据并且这些数据在三维空间中变得有序。)
下图展示Voxel和点云关系(图来自github: KITTI_VIZ_3D)。

其中上图中绿色的立方体可看成一个个voxel,黑色的点可看成激光雷达生成的点云数据,每个点云落到某个voxel内,则该点就被划分到这个voxel中。
整体模块大致分为三个模块:

分别是Feature Learning Network、Convolutional middle layers、Region proposal network。
1. Feature Learning Network:
1)Voxel 划分(分配每个voxel到3D空间中对应位置):
对于一个三维空间的长宽高分别为X、Y、Z,每个voxel的大小分别为长Vx,宽Vy,高Vz,整个三维空间就可以划分成X上有X/Vx个voxel,Y上就有Y/Vy个voxel(假设X,Y,Z均为Vx,Vy,Vz的倍数)。
注释:X,Y,Z分别是0-70.4;-40-40;-3-1,Vx,Vy,Vz分别是0.4,0.2,0.2,单位均为米。因为点云空间中远处的物体产生的点过于稀疏,超出X,Y,Z范围外的点会被删除。
2) Grouping(将每个点分配给对应的Voxel)和Sampling(voxel中点云的采样)
把3D空间Voxel化后,需要将3D空间中所有点云分配到他们所属的voxel中。由于激光雷达本身的特性和捕获反射的光束时,会受到距离、物体遮挡、物体之间的相对姿态和不均匀采样的影响。导致产生的点云数据在整个三维空间中是十分稀疏并且不均匀的(有些voxel甚至没有点)。
而且,一个高精度的激光雷达点云会包含10万以上的点,如果直接对所有点进行处理可能会导致极大的计算和内存消耗,还会因点密度差距大,导致模型检测偏差。
因此在Grouping操作后,需要对每个非空的voxel中随机采样T个点。(不足补0,超出仅采样T个点)。
经过Grouping后数据可表示为(N,T,C),其中N为非空的voxel的个数,T为每个voxel中点的个数,C表示点的特征。
注释:论文中T为35,Z=Z/Vz…分别等于10,352,400.Z,X,Y表示每个轴上有多少个voxel。
3) VFE堆叠(Stacked Voxel Feature Encoding)
之前的工作使用voxel的数据经过编码之后拿来使用,包括每个非空的voxel编码成6维的统计向量,这些统计量都来源于voxel内部的点,或者将统计量在融合上voxel所在的局部信息,或者使用二值编码的方式来编码voxel操作,然而都没能达到很好的效果。
VoxelNet解决了上述问题,如图所示:

每一个非空的Voxel都是一个点集,定义为V={pi=[xi,yi,zi,ri]T属于R的四次方},V=1…t;其中t小于等于35,Pi代表点云数据中的第i个点:xi,yi,zi分别是该点在3D空间中的X,Y,Z坐标,n表示光线反射到雷达的强度(与距离、入射角度,物体材质等有关,数值在0-1之间)。
首先,先对voxel中的每个点进行数据增强操作,先计算出每个voxel的所有点的平均值,计为(V_Cx,V_Cy,V_Cz),然后将每个点的xi,yi,zi减去对应轴上的平均值,得到每个点到自身voxel中心的偏移量(xi_offset,yi_offset,zi_offset)。再将得到的偏移数据和原始的数据拼接在一起得到网络的输入数据V = {pi = [xi , yi , zi , ri, xi_offset,yi_offset,zi_offset]T ∈ R^7}i=1…t。
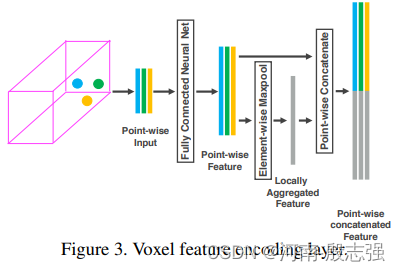
接着就是用PointNet提出的方法,将每个voxel中的点通过全连接层转化到高维空间(每个全连接层包含了FC, RELU, BN)。维度也从(N,35,7)变成了(N,35,C1)。然后在这个特征中,取出特征值最大的点(Element-wise Maxpool)得到一个voxel的聚合特征(Locally Aggreated Feature),可以用这个聚合特征来编码这个voxel包含的表面形状信息。这也是PointNet中所提到的。获得每个voxel的聚合特征后,再用该特征来加强经过FC后的高维特征;将聚合特征拼接到每一个高维点云特征中(Point-wise Concatenate);得到(N,35,2*C1)。
作者把上述的这个特征提取的模块称之为VFE(Voxel Feature Encoding),这样每个VFE模块都只仅仅包含了一个(C_in,C_out/2)的参数矩阵。每个voxel经过VFE输出的特征都包含了voxel内每个点的高维特征和经过聚合的局部特征,那么只需要堆叠VFE模块就可以实现voxel中每个点的信息和局部聚合点信息的交互,使得最终得到的特征能够描述这个voxel的形状信息。

注:每个VFE模块中FC的参数共享的。原论文的实现中一共堆叠了两个VFE模块,其中第一个VFE模块将维度从输入的7维度升高到了32,第二个VFE模块将数据的维度从32升高到了128。
经过Stacked Voxel Feature Encoding后,可以得到一个(N,35,128)的特征,然后为了得到这个voxel的最终特征表达。需要对这个特征再进行一个FC操作来融合之前点特征和聚合特征,这个FC操作的输入输出保持不变。即得到的tensor还是(N,35,128),之后进行Element-wise Maxpool来提取每个voxel中最具体代表性的点,并用这个点来代表这个voxel,即(N,35,128)–> (N,1,128)
4) Sparse Tensor Representation(特征提取后稀疏特征的表示)
在前面的Stacked Voxel Feature Encoding 的处理中,都是对非空的voxel进行处理,这些voxel仅仅对应3D空间中很小的一部分空间。这里需要将得到的N个非空的voxel特征重新映射回来源的3D空间中,表示成一个稀疏的4D张量,(C,Z’,Y’,X’)–> (128, 10, 400, 352)。这种稀疏的表示方法极大的减少了内存消耗和反向传播中的计算消耗。同时也是VoxelNet为了效率而实现的重要步骤。
5) 高效实现(voxel补0)
前面的voxel采样中,如果一个voxel中没有T个点,就直接补0直到点的数量达到35个,如果超出35个点就随机采样35个点。但是在原论文中的具体实现如下。原作者为Stacked Voxel Feature Encoding的处理设计了一个高效实现,如下图。

由于每个voxel中包含的点的个数都是不一样的,所以这里作者将点云数据转换成了一种密集的数据结构,使得后面的Stacked Voxel Feature Encoding可以在所有的点和voxel的特征上平行处理。
1、首先创建一个KT7的tensor(voxel input feature buffer)用来存储每个点或者中间的voxel特征数据,其中K是最大的非空voxel数量,T是每个voxel中最大的点数,7是每个点的编码特征。所有的点都是被随机处理的。
2、遍历整个点云数据,如果一个点对应的voxel在voxel coordinate buffer中,并且与之对应的voxel input feature buffer中点的数量少于T,直接将这个点插入Voxel Input Feature Buffer中;否则直接抛弃这个点。如果一个点对应的voxel不在voxel coordinate buffer,需要在voxel coordinate buffer中直接使用这个voxel的坐标初始化这个voxel,并存储这个点到Voxel Input Feature Buffer中。这整个操作都是用哈希表完成,因此时间复杂度都是O(1)。整个Voxel Input Feature Buffer和voxel coordinate buffer的创建只需要遍历一次点云数据就可以,时间复杂度只有O(N),同时为了进一步提高内存和计算资源,对voxel中点的数量少于m数量的voxel直接忽略改voxel的创建。
3、再创建完Voxel Input Feature Buffer和voxel coordinate buffer后Stacked Voxel Feature Encoding就可以直接在点的基础上或者voxel的基础上进行平行计算。再经过VFE模块的concat操作后,就将之前为空的点的特征置0,保证了voxel的特征和点的特征的一致性。最后,使用存储在voxel coordinate buffer的内容恢复出稀疏的4D张量数据,完成后续的中间特征提取和RPN层。
2. 中间卷积层
在经过了Stacked Voxel Feature Encoding层的特征提取和稀疏张量的表示之后,就可以使用3维卷积来进行整体之间的特征提取了,因为在前的每个VFE中提取反应了每个voxel的信息,这里使用3维卷积来聚合voxel之间的局部关系,扩大感受野获取更丰富的形状信息,给后续的RPN层来预测结果。
三维卷积可以用ConvMD(cin, cout, k, s, p)来表示,cin和cout是输入和输出的通道数,k表示三维卷积的kernel大小,s表示步长,p表示padding参数。每个三维卷积后都接一个BN层和一个Relu激活函数。
注:原文中在Convolutional middle layers中分别使用了三个三维卷积,卷积设置分别为
Conv3D(128, 64, 3, (2,1,1), (1,1,1)),
Conv3D(64, 64, 3, (1,1,1), (0,1,1)),
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
最终得到的tensor shape是(64,2,400,352)。其中64为通道数。
经过Convolutional middle layers后,需要将数据整理成RPN网络需要的特整体,直接将Convolutional middle layers得到的tensor 在高度上进行reshape 变成(64 * 2,400,352)。那么每个维度就变成了 C、Y、X。这样操作的原因是因为KITTI等数据集的检测任务中,物体没有在3D空间中的高度方向进行堆叠,没有出现一个车在另一个车的上方这种情况。同时这样也大大减少了网络后期RPN层设计难度和后期anchor的数量。
3. 与pointpillars相同,或者说pointpillars引用了这种结构-RPN层
VoxelNet的RPN结构在经过前面的Convolutional middle layers和tensor重组得到的特征图后,对这个特征图分别的进行了多次下采样,然后再将不同下采样的特征进行反卷积操作,变成相同大小的特征图。再拼接这些来自不同尺度的特征图,用于最后的检测。
下图是VoxelNet中RPN的详细结构(图来自原论文)

VoxelNet的RPN结构在经过前面的Convolutional middle layers和tensor重组得到的特征图后,对这个特征图分别的进行了多次下采样,然后再将不同下采样的特征进行反卷积操作,变成相同大小的特征图。再拼接这些来自不同尺度的特征图,用于最后的检测。给人的感觉有点像图像目标检测的NECK模块中PAN。只不过这里只有一张特征图。将不同尺度的信息融合在了一起。这里每一层卷积都是二维的卷积操作,每个卷积后面都接一个BN和RELU层。详细的卷积核参数设置也都在图片中了。
最终的输出结果是一个分类预测结果和anchor回归预测结果。
anchor的参数设计
在VoxelNet中,只使用了一个anchor的尺度,不像FrCNN中的9个anchor。其中anchor的长宽高分别是3.9m、1.6m、1.56m。同时与FrCNN中不同的是,真是的三维世界中,每个物体都是有朝向信息的。所以VoxelNet为每个anchor加入了两个朝向信息,分别是0度和90度(激光雷达坐标系)。
注:由于在原论文中作者分别为车、行人、自行车设计了不同的anchor尺度,并且行人和自行车有自己单独的网络结构(仅仅在Convolutional middle layers的设置上有区别)。为了方便解析,这里仅以车的网络设计作为参考
4. 损失函数
在一个3D的数据的标注中,包含了7个参数(x, y ,z, l, w, h, θ),其中xyz代表了一个物体的中心点在雷达坐标系中的位置。lwh代表了这个物体的长宽高。θ代表了这个物体绕Z轴旋转角度(偏航角)。因此生成的anchor也包含对应的7个参数(xa, ya ,za, la, wa, ha, θa),其中xa, ya ,za表示这个anchor在雷达坐标系中的位置。 la, wa, ha反应了这个anchor的长宽高。θa表示这个anchor的角度。
因此编码每个anchor和GT的损失函数时,公式如下:

其中d^a表示一个anchor的底面对角线长度:

上面直接定义了每个anchor回归的7个参数;但是总的损失函数还包含了对每个anchor的分类预测,因此总的损失函数定义如下:

其中pipos表示经过softmax函数后该anchor为正样本,pjneg表示经过softmax函数后该anchor为负样本。ui和ui仅仅需要对正样本anchor回归计算loss。同时背景分类和类别分类都采用了BCE损失函数;1/Npos和1/Nneg用来normalize各项的分类损失。α, β为两个平衡系数,在论文中分别是1.5和1。最后的回归损失采用了SmoothL1函数。
5. 数据增强
1、由于点云的标注数据中,一个GTbox已经标注出来这个box中有哪些点,所以可以同时移动或者旋转这些点来创造大量的变化数据;在移动这些点后需要进行以下碰撞检测,删粗掉经过变换后这个GTbox和其它的GTbox混在一起的,不可能出现在现实中出现的情况。
2、对所有的GTbox进行放大或者缩小,放大或者缩小的尺度在 [ 0.95, 1.05]之间;引入缩放,可以使得网络在检测不同大小的物体上有更好的泛化性能,这一点在图像中很常见。
3、对所有的GTbox进行随机的进行旋转操作,角度在从[ -45, 45]均匀分布中抽取,旋转物体的偏航角可以模仿物体在现实中转了个弯的情况。
6. 结果查看

与只需要在二维平面上精确定位物体的鸟瞰探测相比,三维探测需要在三维空间中精确定位物体,因此具有更高的挑战性。表2总结了这些比较。对于Car类,VoxelNet在AP中所有难度级别的表现都明显优于其他所有方法。具体来说,只使用激光雷达,VoxelNet的性能明显优于基于LiDAR+RGB的最先进方法MV (BV+FV+RGB)[5]在简单、中等和困难级别上分别提高了10.68%、2.78%和6.29%。HC-baseline与MV[5]法具有相似的精度。与鸟瞰图评估一样,我们还将VoxelNet与HC-baseline在3D行人和自行车检测方面进行了比较。由于三维姿态和形状的高度变化,这两类物体的成功检测需要更好的三维形状表示。如表2所示,对于更具挑战性的3D检测任务,VoxelNet的性能得到了提高(从鸟瞰图的8%提高到3D检测的12%),这表明VoxelNet在捕捉3D形状信息方面比手工制作的特征更有效。
算法对比
VoxelNet:
空间上( z , y , x )的范围为 [ − 3 , 1 ] × [ − 40 , 40 ] × [ 0 , 70.4 ] [-3,1]\times[-40,40]\times[0,70.4][−3,1]×[−40,40]×[0,70.4],分辨率为( 0.4 , 0.2 , 0.2 )。所以, 分成( D , H , W ) = ( 10 , 400 , 352 个小voxel。
某种意义上,可以认为,现在体素就是一个个新的“点云”。
每一个体素中点云数目为T个,T<=35。
- VFE层
VFE层 要做的事情就是聚集单个体素中的点云特征。

这样每一个体素可以用(T,7) 表示,T是点云个数,7是单个点云的维度。
VFE层就是FCN + MaxPooling + Concat。
具体操作是:
(T,7) ----经过[7,16]的FCN---->(T,16) -----BN RELU------->(T,16)
(T,16) ----->在T这个维度上进行MaxPooling------>(1,16),得到体现该体素全局的向量
(1,16) 与经过FCN的)(T,16) 进行拼接操作,即每一个单独点云向量都拼接该体素的全局向量,得到(T,32)
VFE重复两次,第二次是
(T,32) -----经过[32,64]的FCN---->(T,64) -----BN RELU------->(T,64)
(T,64) ----->在T这个维度上进行MaxPooling------>(1,64),得到体现该体素全局的向量
(1,64) 与经过FCN的(T,64) 进行拼接操作,即每一个单独点云向量都拼接该体素的全局向量,得到(T,128)
最后再使用一次MaxPooling,使得(T,128) ---->(1,128),得到用来表示单个体素的特征向量(1,128)。
最后整张体素图的特征为(C,D,H,W)=(128,10,400,352)。
- 3D卷积与RPN
经过VFE处理,已经是规整的体素图了,就可以简单的看作2D图像的扩展,使用3D卷积提取特征,RPN 进行检测了。
(128,10,400,352) ----3D---->(64,2,400,352)------>(128,400,352) -->RPN
缺点:
显而易见,体素分割维度比较死板。
SECOND:
- 使用稀疏卷积来计算3D convolution
- 好像否定了VFE,只是简单的使用了平均值,需要用代码好好看一下(11.5)
- 数据增强手段值得关注.
- 加了一个loss
Pointpillars

相关文章:
目标检测算法之voxelNet与pointpillars对比
算法对比 3D目标检测发展简史 点云目标检测目前发展历经VoxelNet、SECOND、PointPillars、PV-RCNN。 2017年苹果提出voxelnet,是最早的一篇将点云转成voxel体素进行3D目标检测的论文。 然后2018年重庆大学的一个研究生Yan Yan在自动驾驶公司主线科技实习的时候将vo…...
电脑里的连接速度双工模式是什么?怎么设置
双工模式包括全双工、半双工模式。1.半双工1、半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信。所谓半双工就是指一个时间段内只有一个动作发生。早期的对…...
springboot整合单机缓存ehcache
区别于redis的分布式缓存,ehcache是纯java进程内的单机缓存,根据不同的场景可选择使用,以下内容主要为springboot整合ehcache以及注意事项添加pom引用<dependency><groupId>net.sf.ehcache</groupId><artifactId>ehc…...

在阿里干了2年的测试,总结出来的划水经验
测试新人 我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试。那时候在一家电商公司做测试,做了一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,这样我…...
硬盘分类及挂载硬盘知识补充和介绍
一、硬盘介绍Linux硬盘分IDE硬盘和SCSI硬盘,目前基本上是SCSI硬盘1.对于IDE硬盘,驱动器标识符为"hdx~",其中"hd"表明分区所在设备的类型,这里是指IDE硬盘了。"x"为盘号(a为基本盘,b为基…...
【MyBatis】自定义映射resultMap
8.1、resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射 <!--resultMap:设置自定义映射属性:id:表示自定义映射的唯一标识type:查询的数据要映射的实体类的…...

mysql的锁和事务
mysql的锁 读写锁: 读锁是共享锁,多个用户在同一时刻可以读取同一资源,相互不受干扰写锁是排他锁,写锁会阻塞其他的写锁和读锁,这样可以确保在指定的时间内,只有一个用户可以写入 锁的颗粒度: …...

为什么B站中的弹幕可以不遮挡人物
上班逛B站时摸鱼时,看到了满屏的弹幕,而且还不挡脸,突然心血来潮来看看它是怎么实现的? 不难发现弹幕其实它就是有一个蒙版层div,遮挡在视频组件的上方,z-index层级设置的比较高(这里是11&…...
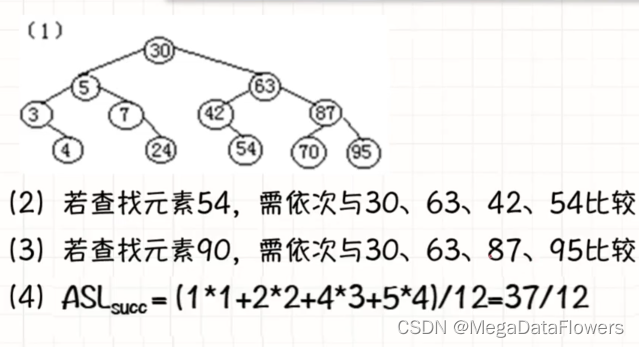
数据结构 第八章 查找(静态查找表)
集合 1、集合中的数据元素除了属于同一集合外,没有任何的逻辑关系 2、在集合中,每个数据元素都有一个区别于其他元素的唯一标识(键值或者关键字值) 3、集合的运算: 1 查找某一元素是否存在(内部查找、外部查找) 2 将集合中的元素按照它的唯一标识进行排序4、集合的…...
)
【Python基础】数据类型(元组、列表)
文章目录二. 数据类型2.1 元组 tuple2.1.1 定义特性2.1.2 拼接拷贝2.1.3 元组拆包2.1.4 元组方法 count2.2 列表 list2.2.1 基础定义2.2.2 增删操作2.2.3 连接联合2.2.4 其他常规操作2.2.5 列表推导式2.2.6 生成器表达式2.x 小结:何时使用元组或列表二. 数据类型 Py…...

你了解互联网APP搜索和推荐的背后逻辑么?
1.搜索和推荐无处不在我们习惯了百度、Google、360搜索的便捷,输入你想要搜索的关键词,立马呈现给你一批对应的结果,供你筛选。我们也经常上淘宝、京东、拼多多购物,输入想买的商品,瞬间列出一页一页的商品清单供我们选…...

Bug的级别,按照什么划分
Bug分类和定级一、bug的定义二、bug的类型三、bug的等级四、bug的优先级一、bug的定义一般是指不满足用户需求的则可以认为是bug,狭义指软件程序的漏洞或缺陷,广义指测试工程师或用户提出的软件可改进的细节、或与需求文档存在差异的功能实现等对应三个测…...
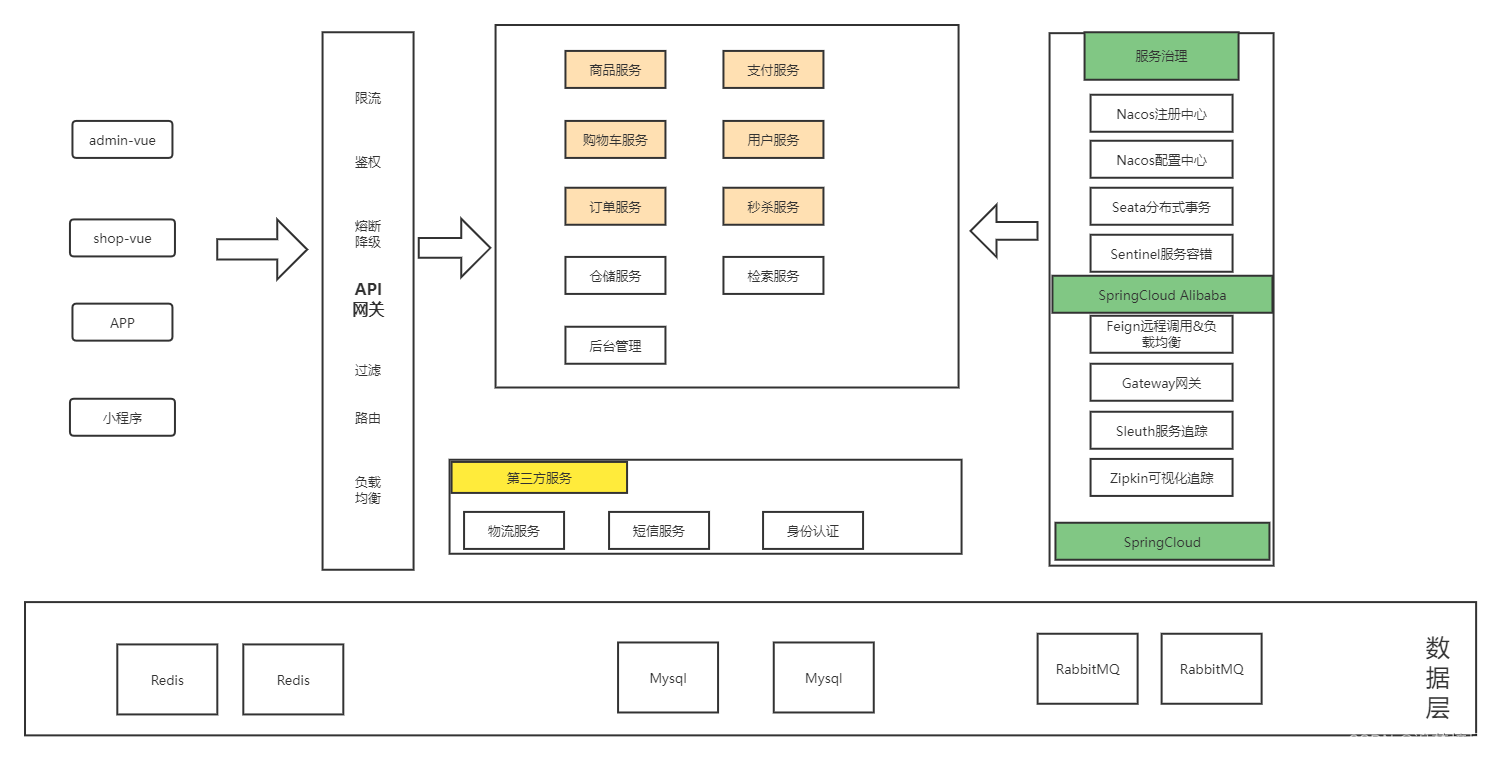
微服务项目简介
项目简介 项目模式 电商模式:市面上有5种常见的电商模式,B2B、B2C、 C2B、 C2C、O2O; 1、B2B模式 B2B (Business to Business),是指 商家与商家建立的商业关系。如:阿里巴巴 2、B2C 模式 B2C (Business to Consumer), 就是我们经常看到的供…...

SLAM中坐标轴旋转及ros的接口解释
读完几个loam算法,满篇的坐标轴旋转,还是手写的(作者,用eigen写不好嘛。。。),我滴天适应了好久…,今天就总结一下坐标轴旋转问题。 一、首先,我们看一下ros中关于欧拉角旋转的函数:setRPY、set…...
文件管理(9)
文件管理 0 引言 为什么要引入文件系统? 信息管理的需要:用户面前提供一种规格化的机制,方便用户对文件的存取、提高效率。操作系统本身需要–操作系统本身也不是常驻内存的,也有大量的信息需要存于外存。 1 文件定义 文件&a…...

PyTorch学习笔记:nn.TripletMarginLoss——三元组损失
PyTorch学习笔记:nn.TripletMarginLoss——三元组损失 torch.nn.TripletMarginLoss(margin1.0, p2.0, eps1e-06, swapFalse, size_averageNone, reduceNone, reductionmean)功能:创建一个三元组损失函数(triplet loss),用于衡量输入数据x1,x…...

冒泡排序详解
冒泡排序是初学C语言的噩梦,也是数据结构中排序的重要组成部分,本章内容我们一起探讨冒泡排序,从理论到代码实现,一步步深入了解冒泡排序。排序算法作为较简单的算法。它重复地走访过要排序的数列,一次比较两个元素&am…...
git极快上手指南超级精简版
注:本文参考https://www.liaoxuefeng.com/wiki/896043488029600 原文非常值得一读,作者学识渊博,补充了很多有意思的知识。我仅仅是拾人牙慧。 git是最先进的分布式版本控制系统。 版本控制系统——自动记录系统中文件的改动情况࿰…...
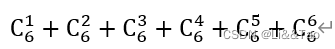
蓝桥杯-最长公共子序列(线性dp)
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 已知有两个数组a,b。已知每个数组的长度。要求求出两个数组的最长公共子序列 序列 1 2 3 4 5 序列 2 3 2 1 4 5 子序列:从其中抽掉某个或多个元素而产生的新…...

GO的并发模式Context
GO的并发模式Context 文章目录GO的并发模式Context一、介绍二、Context三、context的衍生四、示例:Google Web Search4.1 server程序4.2 userip 包4.3 google 包五、使用context包中程序实体实现sync.WaitGroup同样的功能(1)使用sync.WaitGro…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...