你了解互联网APP搜索和推荐的背后逻辑么?
1.搜索和推荐无处不在
我们习惯了百度、Google、360搜索的便捷,输入你想要搜索的关键词,立马呈现给你一批对应的结果,供你筛选。我们也经常上淘宝、京东、拼多多购物,输入想买的商品,瞬间列出一页一页的商品清单供我们选择。我们使用美团、饿了么搜索想吃的美食,美食列表会按照距离,订单数量,好评给你做排行榜。我们想要去旅行,打开去哪儿网、大众点评、小红书,搜索一下地名,就出现对应地方的旅游景点、住宿旅馆、网红打卡点等相应的信息和评价。
当然,打开今日头条、抖音、微博、小红书不用搜索也会推荐出热点新闻、热点视频等事件供你浏览。而你的浏览记录、点赞、转发、收藏、评论等动作,还会为接下来的事件推荐,提供更加准确的依据来。让你驻足停留,流连忘返,上瘾并沉迷其中无法自拔。还会引导你去做出消费的行为,比如:直播打赏,进入超链接,去购物商城等等。而你的这些动作,统统被称为用户行为,这些行为,还会继续曝光对应的内容,让其成为更火爆的新闻,会立马推荐给其他人,形成一波又一波的热点事件。
想想,是不是很惊讶?但是,这就是事实,我们深陷其中,却都习以为常,每天沉浸在手机端的各大APP里,畅游在这些信息的海洋中,被包围着,甚至被左右和绑架着,这个专业术语叫:用户粘性。
这就是目前互联网各个大厂主要玩的东西。是的,BTA,这也是他们最主要的赚钱办法。
想过没有,这里背后的逻辑是什么?对我们的生活有什么影响?积极的、消极的,这里我不去谈论,一句话两句话好像也说不清楚。我只想拆拆,背后的逻辑是什么?
这背后做决策的,就是被称之为智能搜索和推荐的算法。国内互联网,都足劲儿,搞这些算法,谁家的算法更智能更强大,更贴近你的习惯,谁家的用户量就多,对应APP的使用率就更广泛。而你,就是他们的用户。
本质,让你习惯上他们的搜索和推荐算法来,我们就是这样被套路的。
下面,用最通俗的语言,来拨开这套算法最神秘的面纱,科普一下背后的逻辑,当然不用担心,不涉及具体的算法、逻辑架构以及数据存储、处理等等。
互联网的数据从哪里来
我们打开互联网APP,里面的内容包罗万象,我们可以搜索感兴趣的内容,或者上京东购买商品,或者上知乎表达想法,或者刷抖音的短视频、看直播,在美团点个外卖、在去哪儿网购买个机票、浏览今日头条、微博的热点新闻和资讯、上淘票票订购电影票或者查询百度知识问答库、维基百科,用高德定位导航去某个地方等等。这些动作所呈现的内容信息,统统叫做数据。专业点叫做互联网大数据。
比如百度搜索,你搜出来的所有内容都是百度搜索引擎通过网络爬虫爬过来进行整合的数据,以及各大网站主动提交规则给百度的数据,让百度添加到搜索的规则引擎中,增加网站的曝光率,这个数据非常海量,那么百度大数据的容量有多少?百度技术委员会理事长陈尚义透露:“百度每天处理的数据量将近100个PB,1PB就等于100万个G,相当于5000个国家图书馆的信息量的总和”。
而淘宝、京东、拼多多、美团里面的数据,主要包括店铺数据、商品数据、客户数据、物流数据、运营数据等等。这里主要介绍商品数据,它的来源就比较专项了,这里有运营人员通过店铺后台按照类别进行编辑和上架,也有个人通过APP的运营后台进行注册店铺。而像京东自营平台的商品信息,更多是商家上架的商品栏目。当然,这个数据量非常庞大。据统计,淘宝拥有近5亿的注册用户数,每天有超过6000万的固定访客,同时每天的在线商品数已经超过了8亿件,平均每分钟售出4.8万件商品。这背后就包含每个电商经营者具体电商的支付数据、库存数据、物流数据、日志数据等等。光订单量产生的数据,淘宝日订单量在5000万单以上,美团3000万单以上。淘宝单日数据产生量超过50TB(1TB等于1000GB),总体存储量可达40PB(1PB等于1000TB)。
而像抖音、今日头条、小红书、知乎这样的APP平台,其数据主要包括新闻、资讯类、视频内容、直播,当然现在也有抖音电商、抖音外卖等等,这里的数据类型更为丰富。但是数据来源更多是用户自产自销,广大用户在对应的APP后台编辑好文章、短视频,上传给对应APP,后台APP的审核机制对信息进行审核,形成即将发布的新闻资讯,再通过推荐算法推荐给广大用户。抖音用户人数为8亿,抖音的活跃人数1.3亿人而快手的活跃人数为7300万人。可以想想这些人,也就是广大用户我们,每天产生多少新的视频出来。
而像知乎、博客、CSDN、各大新闻的留言网站、评论网站等,其数据主要为留言数据,图片数据,各大网站直接收录到对应数据在网站里面,充实网站的信息,这里也可以用海量来形容。据报道,知乎发布“我的知乎十年历”用户数据报告。报告显示,成立十年以来,知乎已经积累了超过4400万个问题和2.4亿个回答。想想,你想要的问题,是不是知乎都有?知乎背后的搜索引擎会对问题进行类型分类和数据训练、做活跃度排序、再进行分布式存储。然后当你按照问题的描述去搜索的时候,知乎的搜索引擎会进行一系列的流程,呈现给你排序好的答案。当然还会做热门排行榜推荐。
上面的各大APP的数据内容,其实只举了一些经典案例,不过已经包罗万象了,这个就是互联网的魅力,所有的内容以数据的形式,被搬上互联网,被随时随机的检索和浏览。而我们,拿起手机,在数据形成的虚拟世界里徜徉。为什么总说互联网是有记忆的,因为我们每个人,每一次的上网的过程,浏览过的信息,所做的操作、交流的文案,在这里都会留下足迹,而且永久存储。想想,是不是还是挺震撼的。
百度输入关键字,背后发生了什么
有没有想过,当你在百度、360、知乎、头条、抖音输入了一段想要搜索的文字,点击一下搜索按钮就呈现给你一页一页排好序的结果列表。这里面就是搜索引擎在起作用,背后的搜索链路也非常长,这里用比较通俗的语言向大家展示背后的逻辑。
搜索的本质是想检索出用户需要的数据,再以一种动态网页(HTML)的形式展示给用户,上面我们已经介绍了各大互联网的数据,这个数据是海量的,也是非常丰富多彩的。需要将这些数据组织、管理、存储并且高效的利用,就需要各种手段。
互联网大数据工程师就是专门干这个的,本质就是做数据的存储与计算、任务的调度与管理。这里我们主要以存储来介绍,数据本身都是在高性能的分布式服务器中存着,而且各种类型的数据需要各种不同的数据库去存储,比如常见的关系型数据库oracle、myql、sqlserver、postgresql等等。如视频类、图片、文本类、日志类数据存储需要存在非关系形数据库中,如:mongodb、elasticsearch、hbase等,上面的数据库产品可能大家或多或少的听说过。
而搜索的过程,就是搜索引擎分析你输入的句子(语义解析),并通过自然语言处理(NLP)来进行分词,以标准化你输入的关键字。因为人们输入的句子是千差万别的,怎么让机器理解你得想法,以及准确让机器知道你想搜索的目标结果是什么(意图分析),再进行类型预测,这里每种不同的资料存储再不同的服务器上,所以需要做预测到底是想搜哪个(类目预测)。此时服务器拿到了一批结果,但是结果很多,有相关性强的也有相关性弱的,就需要做排序(召回结果排序),而且排序的过程通常需要好几轮,因为指标太多了,我们经常看到搜索某个关键词,返回上亿条分页的结果。但是往往你只会看最前面的几条(当然你说最前面是广告,这就另说了,百度要盈利,将付费的广告排在了前面,这个体验大家都会吐槽)。上面的流程,是不是非常绕口又感觉很难理解?下面拆开进行详细分析。
上面搜索的流程,大概分别为:抓取建库;意图识别;结果召回;检索排序;结果展现,以保证搜索的内容能够满足快速,全面、准确、稳定。
抓取建库
本质就是组织数据,训练数据。从海量的互联网信息中获得有用的数据进行清洗、保存、更新。这个过程因此通常会被叫做“spider”,Spider抓取系统是搜索引擎数据来源的重要保证,如果把web理解为一个有向图,那么spider的工作过程可以认为是对这个有向图的遍历。从一些重要的种子 URL开始,通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型spider系统,因为每时每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对spider过去抓取过的页面保持更新,维护一个URL库和页面库。
抓取过来的数据需要进行清洗,数据清洗就是对数据进行质量把控,比如百度有专门的模式识别方案。提出那些违反规则的超链接进行屏蔽。还有最关键的一步就是对所有的资源建立索引。索引就相当于一个字典给其建立目录,当你的内容发生变化了,相应的就需要更新索引,以维持整个索引的有效性。
意图识别
在用户输入的句子中,搜索引擎准确理解用户表达意图的效果,是能够完成一次查询的关键,因此系统对用户关键字的理解是用户和搜索引擎建立联系的必要环节。而搜索引擎做的这部分工作,被成为意图识别。主要包括关键词的分词、类目预测、改写、实体识别、分词权重等部分(各模块前后顺序会因系统需要而做适当调整)。这部分的工作就主要是自然语言处理和机器学习的部分,还需要不断训练的语料库作为支撑,一般搞人工智能的开发,会负责这部分,当然数据标注,人工干预通常都是苦力活。一方面,搜索系统往往可以积累大量的用户行为数据,如点击、收藏、购买等。另一方面电商场景有比较健全的商品类目体系。
结果召回
结果召回,是更加专业点的叫法。本质就是搜索的过程。你的词想服务器发送搜索的命令,会拿到一批结果,而这个叫做搜索召回。除了搜索召回,还有文本召回,结构化召回,个性化召回。本质都是拿数据,拿到一批数据。
检索排序
搜索的结果有很多,但是哪一条数据最重要的呢?这里就需要排序,具体的算法就不说了,总体思路是对每条结果有其权重和指标,来计算对应的分数。再通过分数进行排序,当然可不是一次就完成的,这个过程选哟重排序、粗排序、精排序等等。
结果展现
排序的数据,就等于有了结果,然后搜索引擎的用户来说,搜索结果页是离其最近的部分。搜索结果页的主体包含与查询的相关网页链接(URL)和与查询相关的自动摘要(Automatic Summary),这两个部分的合成还需要一些额外的计算。做分页下一步就需要通过网络响应给前端去展示了,但是如果这样搞,拿百度估计要崩了,考虑一下,全国几亿人有多少人会搜索相同的结果,好不容易拿到的结果接下来又一个人再走一下流程,那服务器的炸。所以一般而言,垂直内搜索都会建立缓存。将结果一方面响应给前端进行展示,尤其视频、音频都是多节点存储。另一方面会做分布式缓存,满足下一次有命中缓存的结果进行直接返回,加快响应速度。
总结
本文以概述的方式大概介绍了互联网搜索背后的故事,让普通没有涉及到开发的用户能够概览,也期望能够解开互联网那层最神秘的面纱。这里没有深入讲解专业知识和模型算法,因为涉及的链路非常长,某一个环境进去,都是知识的海洋和无底洞,我也仅仅只知其一。
下一节,会重点讲当你打开抖音时候,手动划一划,就能为你推荐出你喜欢的小视频,其背后的逻辑。
相关文章:

你了解互联网APP搜索和推荐的背后逻辑么?
1.搜索和推荐无处不在我们习惯了百度、Google、360搜索的便捷,输入你想要搜索的关键词,立马呈现给你一批对应的结果,供你筛选。我们也经常上淘宝、京东、拼多多购物,输入想买的商品,瞬间列出一页一页的商品清单供我们选…...

Bug的级别,按照什么划分
Bug分类和定级一、bug的定义二、bug的类型三、bug的等级四、bug的优先级一、bug的定义一般是指不满足用户需求的则可以认为是bug,狭义指软件程序的漏洞或缺陷,广义指测试工程师或用户提出的软件可改进的细节、或与需求文档存在差异的功能实现等对应三个测…...
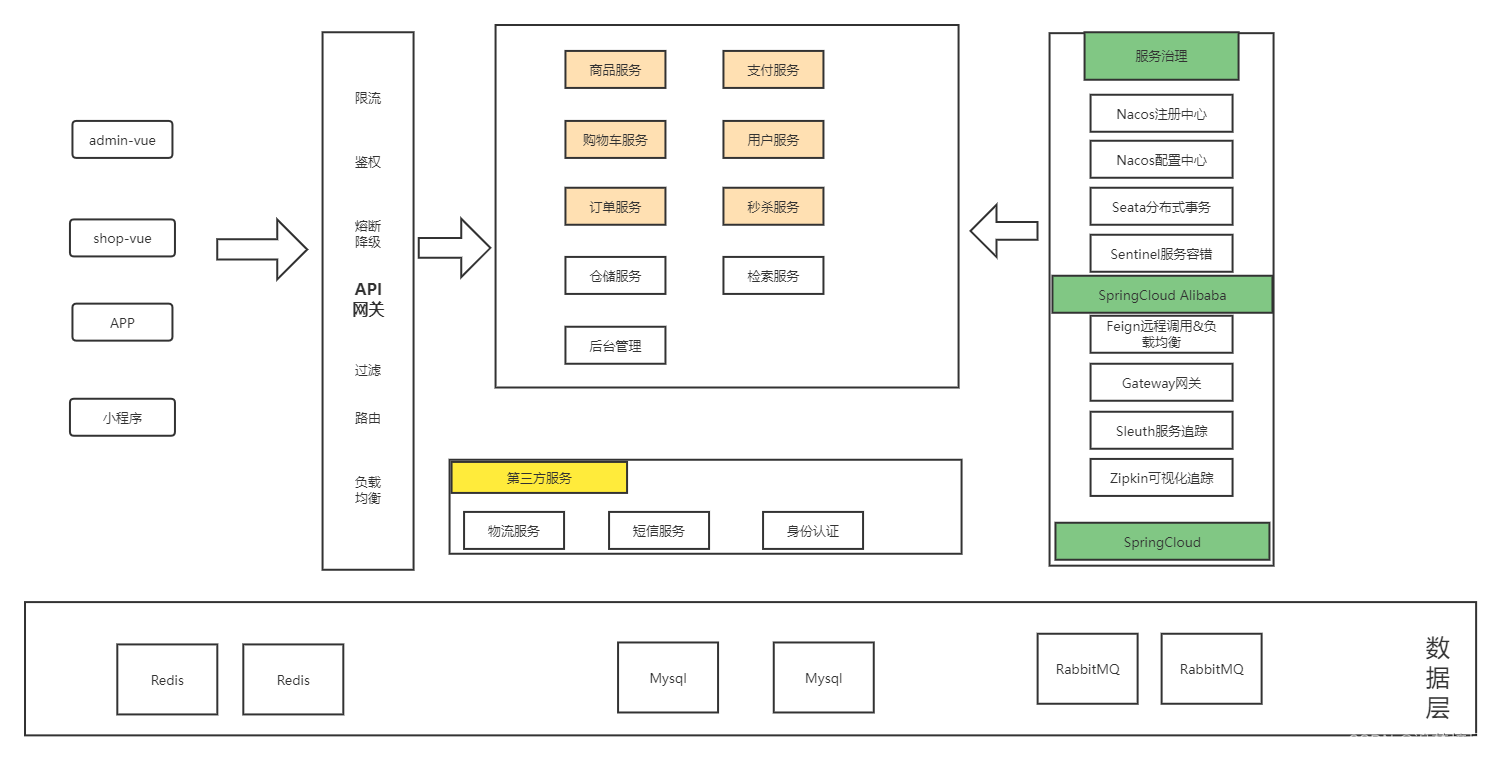
微服务项目简介
项目简介 项目模式 电商模式:市面上有5种常见的电商模式,B2B、B2C、 C2B、 C2C、O2O; 1、B2B模式 B2B (Business to Business),是指 商家与商家建立的商业关系。如:阿里巴巴 2、B2C 模式 B2C (Business to Consumer), 就是我们经常看到的供…...

SLAM中坐标轴旋转及ros的接口解释
读完几个loam算法,满篇的坐标轴旋转,还是手写的(作者,用eigen写不好嘛。。。),我滴天适应了好久…,今天就总结一下坐标轴旋转问题。 一、首先,我们看一下ros中关于欧拉角旋转的函数:setRPY、set…...
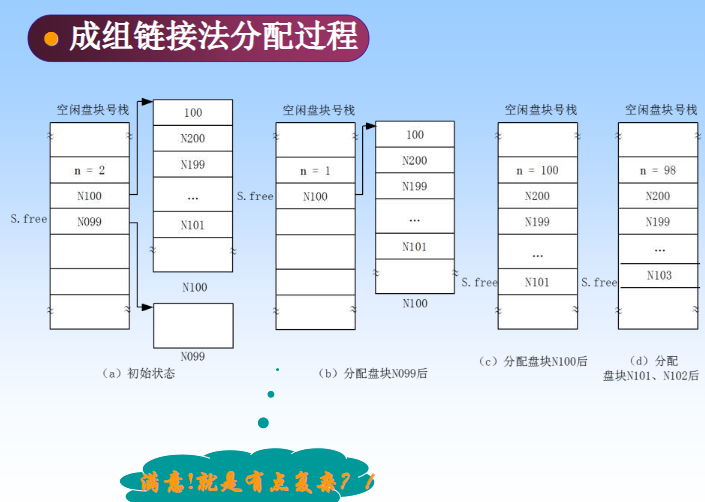
文件管理(9)
文件管理 0 引言 为什么要引入文件系统? 信息管理的需要:用户面前提供一种规格化的机制,方便用户对文件的存取、提高效率。操作系统本身需要–操作系统本身也不是常驻内存的,也有大量的信息需要存于外存。 1 文件定义 文件&a…...

PyTorch学习笔记:nn.TripletMarginLoss——三元组损失
PyTorch学习笔记:nn.TripletMarginLoss——三元组损失 torch.nn.TripletMarginLoss(margin1.0, p2.0, eps1e-06, swapFalse, size_averageNone, reduceNone, reductionmean)功能:创建一个三元组损失函数(triplet loss),用于衡量输入数据x1,x…...

冒泡排序详解
冒泡排序是初学C语言的噩梦,也是数据结构中排序的重要组成部分,本章内容我们一起探讨冒泡排序,从理论到代码实现,一步步深入了解冒泡排序。排序算法作为较简单的算法。它重复地走访过要排序的数列,一次比较两个元素&am…...
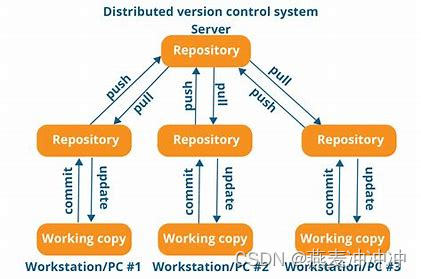
git极快上手指南超级精简版
注:本文参考https://www.liaoxuefeng.com/wiki/896043488029600 原文非常值得一读,作者学识渊博,补充了很多有意思的知识。我仅仅是拾人牙慧。 git是最先进的分布式版本控制系统。 版本控制系统——自动记录系统中文件的改动情况࿰…...
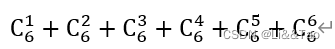
蓝桥杯-最长公共子序列(线性dp)
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 已知有两个数组a,b。已知每个数组的长度。要求求出两个数组的最长公共子序列 序列 1 2 3 4 5 序列 2 3 2 1 4 5 子序列:从其中抽掉某个或多个元素而产生的新…...

GO的并发模式Context
GO的并发模式Context 文章目录GO的并发模式Context一、介绍二、Context三、context的衍生四、示例:Google Web Search4.1 server程序4.2 userip 包4.3 google 包五、使用context包中程序实体实现sync.WaitGroup同样的功能(1)使用sync.WaitGro…...
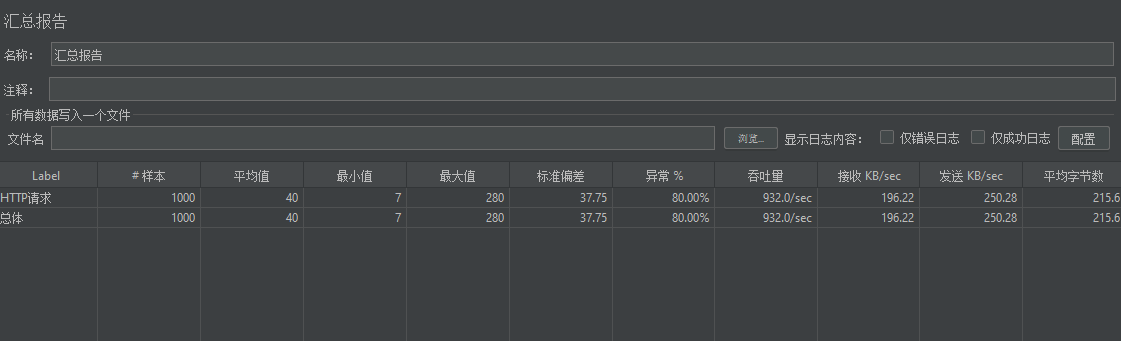
《Redis实战篇》六、秒杀优化
6、秒杀优化 6.0 压力测试 目的:测试1000个用户抢购优惠券时秒杀功能的并发性能~ ①数据库中创建1000用户 这里推荐使用开源工具:https://www.sqlfather.com/ ,导入以下配置即可一键生成模拟数据 {"dbName":"hmdp",…...
)
《C++ Primer Plus》第16章:string类和标准模板库(11)
其他库 C 还提供了其他一些类库,它们比本章讨论前面的例子更为专用。例如,头文件 complex 为复数提供了类模板 complex,包含用于 float、long 和 long double 的具体化。这个类提供了标准的复数运算及能够处理复数的标准函数。C11 新增的头文…...

声明和定义
前言 很多编程语言的语法中都有关于声明和定义的概念,这种概念一般会应用于函数或变量的创建和使用中,但是为什么要这么做? 以C语言为例,一些书籍或教程会要求读者在程序文件开头写上函数和变量的声明,然后再在后面对…...

Python获取最小路径,查找元素在list中的坐标
# codingutf-8__author__ Jeff.xiedef t(li):pass获取最小路径def minPathSum(grid):if not grid:return 0m len(grid) #m列n len(grid[0]) #n行print(grid[0])print("m: ",m)print("n: ",n)#创建一个二维数组dp [[0]*n for _ in range(m)]print(dp) #这…...

数据采集协同架构,集成马扎克、西门子、海德汉、广数、凯恩帝、三菱、海德汉、兄弟、哈斯、宝元、新代、发那科、华中各类数控以及各类PLC数据采集软件
文章目录 前言一、采集协同架构是什么?可以做什么(数控、PLC配置采集)?二、使用步骤 1.打开软件,配置MQTT或者数据库(支持sqlserver、mysql等)存储转发消息规则2.配置数控系统所采集的参数、转…...
Allegro172版本如何用自带的功能实现快速在1MMBGA下方等距放置电容
Allegro172版本如何用自带的功能实现快速在1MMBGA下方等距放置电容 在做PCB设计的时候,在1MM中心间距的BGA背面放置电容,是非常常见的设计,如何快速把电容等距放在BGA下方,除了借助辅助工具外,在Allegro升级到了172版本的时候,可以借助本身自带的功能实现快速放置,以下图…...

一种简单的统计pytorch模型参数量的方法
nelememt()函数Tensor.nelement()->引自Tensor.numel()->引自torch.numel(input)三者的作用是相同的Returns the total number of elements in the inputtensor.返回当前tensor的元素数量利用上面的函数刚好可以统计模型的参数数量parameters()函数Module.parameters(rec…...

【PyTorch】教程:对抗学习实例生成
ADVERSARIAL EXAMPLE GENERATION 研究推动 ML 模型变得更快、更准、更高效。设计和模型的安全性和鲁棒性经常被忽视,尤其是面对那些想愚弄模型故意对抗时。 本教程将提供您对 ML 模型的安全漏洞的认识,并将深入了解对抗性机器学习这一热门话题。在图像…...

中国区使用Open AI账号试用Chat GPT指南
最近推出强大的ChatGPT功能,各大程序员使用后发出感叹:程序员要失业了 不过在国内并不支持OpenAI账号注册,多数会提示: OpenAI’s services are not available in your country. 经过一番搜索后,发现如下方案可以完…...
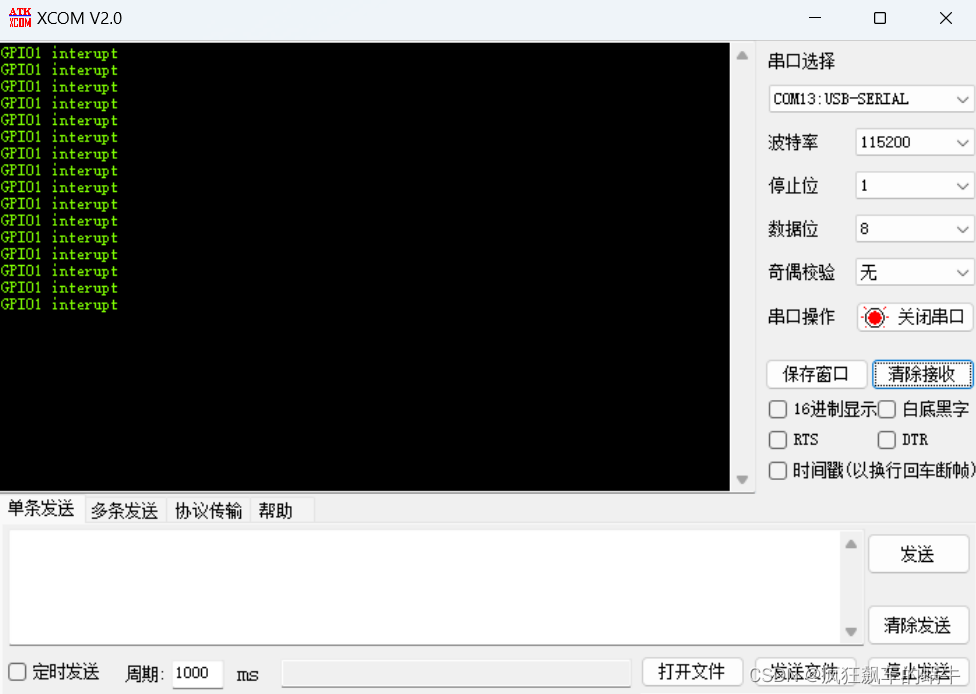
STM32开发(9)----CubeMX配置外部中断
CubeMX配置外部中断前言一、什么是中断1.STM32中断架构体系2.外部中断/事件控制器(EXTI)3.嵌套向量中断控制器(NIVC)二、实验过程1.CubeMX配置2.代码实现3.硬件连接4.实验结果总结前言 本章介绍使用STM32CubeMX对引脚的外部中断进…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...