Linux 常用 API 函数
文章目录
- 1. 系统调用与库函数
- 1.1 什么是系统调用
- 1.2 系统调用的实现
- 1.3 系统调用和库函数的区别
- 2. 虚拟内存空间
- 3. 错误处理函数
- 4. C 库中 IO 函数工作流程
- 5. 文件描述符
- 6. 常用文件 IO 函数
- 6.1 open 函数
- 6.2 close 函数
- 6.3 write 函数
- 6.4 read 函数
- 6.5 lseek 函数
- 7. 文件操作相关函数
- 7.1 stat 函数
- 7.2 access 函数
- 7.3 chmod 函数
- 7.4 chown 函数
- 7.5 truncate 函数
- 7.6 link 函数
- 7.7 symlink 函数
- 7.8 readlink 函数
- 7.9 unlink 函数
- 8. 文件描述符复制
- 8.1 概述
- 8.1 dup 函数
- 8.2 dup2 函数
- 8.3 示例分析
- 9. fcnlt 函数
- 10. 目录相关操作
- 10.1 getcwd 函数
- 10.2 chdir 函数
- 10.3 opendir 函数
- 10.4 readdir 函数
- 10.5 closedir 函数
- 10.6 mkdir 函数
- 10.7 rename 函数
- 11. 时间相关函数
- 11. 0 时间相关概念
- 11.1 时间获取函数
- 11.1.1 time 函数
- 11.1.2 clock 函数
- 11.1.3 gettimeofday() 函数
- 11.2 日历时间转换为分解时间
- 11.2.1 localtime() 函数
- 11.2.2 gmtime() 函数
- 11.3 分解时间转换为日历时间
- 11.3.1 mktime() 函数
- 11.4 将时间转换为字符串相关函数
- 11.4.1 asctime() 函数
- 11.4.2 ctime() 函数
- 11.4.3 strftime() 与 strptime() 函数
- 11.5. 时间差计算函数
- 11.5.1 difftime() 函数
- 11.6 线程安全的时间转换函数
1. 系统调用与库函数
1.1 什么是系统调用
系统调用,顾名思义,说的是操作系统提供给用户程序调用的一组“特殊”接口。用户程序可以通过这组“特殊”接口来获得操作系统内核提供的服务,比如用户可以通过文件系统相关的调用请求系统打开文件、关闭文件或读写文件,可以通过时钟相关的系统调用获得系统时间或设置定时器等。
从逻辑上来说,系统调用可被看成是一个内核与用户空间程序交互的接口——它好比一个中间人,把用户进程的请求传达给内核,待内核把请求处理完毕后再将处理结果送回给用户空间。

系统服务之所以需要通过系统调用来提供给用户空间的根本原因是为了对系统进行“保护”,因为我们知道 Linux 的运行空间分为内核空间与用户空间,它们各自运行在不同的级别中,逻辑上相互隔离。
所以用户进程在通常情况下不允许访问内核数据,也无法使用内核函数,它们只能在用户空间操作用户数据,调用用户空间函数。比如我们熟悉的“hello world”程序(执行时)就是标准的用户空间进程,它使用的打印函数 printf() 就属于用户空间函数,打印的字符“hello word”字符串也属于用户空间数据。
但是很多情况下,用户进程需要获得系统服务(调用系统程序),这时就必须利用系统提供给用户的“特殊接口”——系统调用了,它的特殊性主要在于规定了用户进程进入内核的具体位置。
换句话说,用户访问内核的路径是事先规定好的,只能从规定位置进入内核,而不准许肆意跳入内核。有了这样的陷入内核的统一访问路径限制才能保证内核安全无误。我们可以形象地描述这种机制:作为一个游客,你可以买票要求进入野生动物园,但你必须老老实实地坐在观光车上,按照规定的路线观光游览。当然,不准下车,因为那样太危险,不是让你丢掉小命,就是让你吓坏了野生动物。
1.2 系统调用的实现
系统调用是属于操作系统内核的一部分的,必须以某种方式提供给进程让它们去调用。CPU 可以在不同的特权级别下运行,而相应的操作系统也有不同的运行级别,用户态和内核态。运行在内核态的进程可以毫无限制的访问各种资源,而在用户态下的用户进程的各种操作都有着限制,比如不能随意的访问内存、不能开闭中断以及切换运行的特权级别。显然,属于内核的系统调用一定是运行在内核态下,那如何从用户态切换到内核态呢?
答案是软件中断。软件中断和我们常说的中断(硬件中断)不同之处在于,它是通过软件指令触发而并非外设引发的中断,也就是说,又是编程人员开发出的一种异常(该异常为正常的异常)。操作系统一般是通过软件中断从用户态切换到内核态。
1.3 系统调用和库函数的区别
Linux 下对文件操作有两种方式:系统调用(system call)和库函数调用(Library functions)。
库函数由两类函数组成:
1)不需要调用系统调用:不需要切换到内核空间即可完成函数全部功能,并且将结果反馈给应用程序,如 strcpy()、bzero() 等字符串操作函数。
2)需要调用系统调用:需要切换到内核空间,这类函数通过封装系统调用去实现相应功能,如 printf()、fread() 等。

系统调用是需要时间的,程序中频繁的使用系统调用会降低程序的运行效率。当运行内核代码时,CPU 工作在内核态,在系统调用发生前需要保存用户态的栈和内存环境,然后转入内核态工作。系统调用结束后,又要切换回用户态。这种环境的切换会消耗掉许多时间 。
2. 虚拟内存空间
区分程序和进程:程序就是磁盘上的代码(包括可执行程序和代码),它只占用磁盘空间,不占用内存空间;进程(运行中的程序)会将代码加载到内存中进行运行,并分配一些列资源。进程的知识在后续的文章中还会讲解。
虚拟地址空间是不存在的,而是人为想象出来的。可执行程序运行起来后,就会产生一个虚拟地址空间,如果运行结束,虚拟地址空间就结束了。这个虚拟地址空间是虚拟出来的,大小由计算机决定,比如32位的操作系统中,虚拟地址空间为 4G ,虚拟地址空间最终会被逻辑管理单元(MMU)映射到真实的物理内存中。
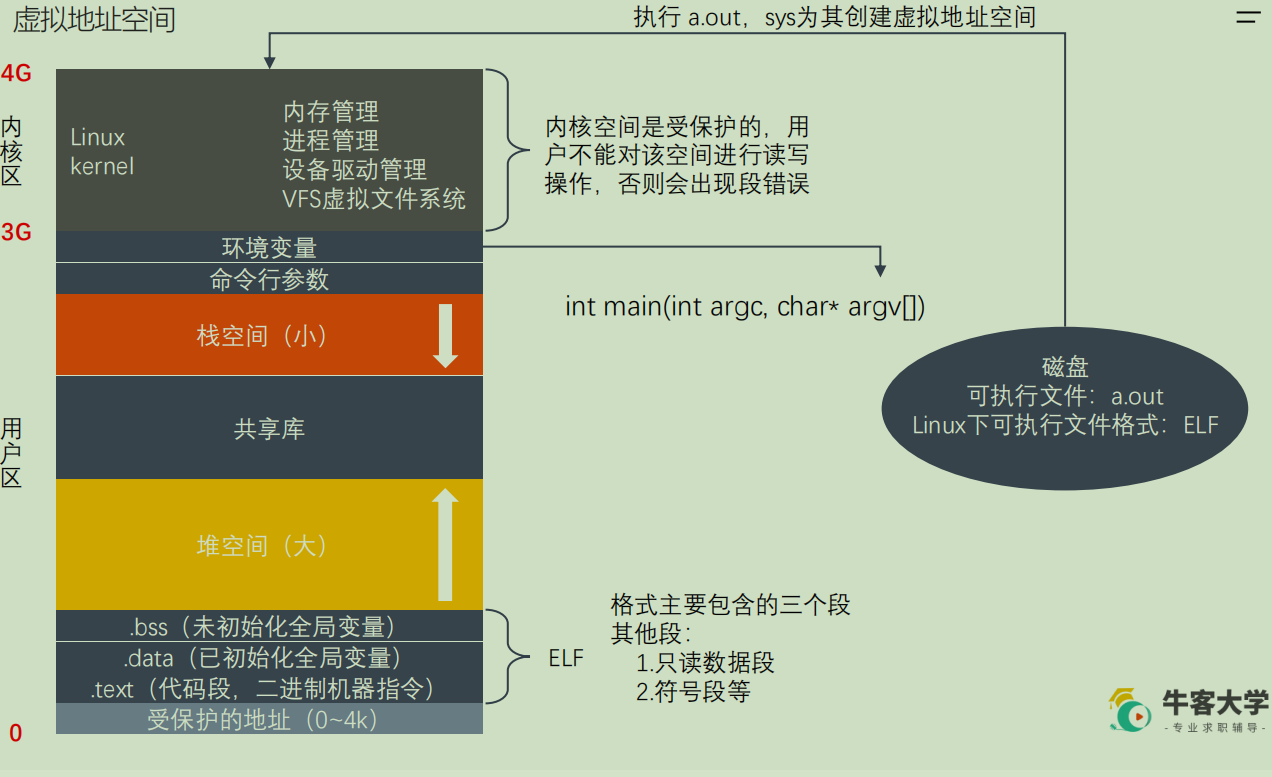
每个进程都会分配虚拟地址空间,在32位机器上,该地址空间为4G 。在进程里,平时所说的指针变量,保存的就是虚拟地址。当应用进程使用虚拟地址访问内存时,处理器(CPU)会将其转化成物理地址(MMU)。
MMU:将虚拟的地址转化为物理地址。这样做的好处在于:
- 进程隔离,更好的保护系统安全运行
- 屏蔽物理差异带来的麻烦,方便操作系统和编译器安排进程地址
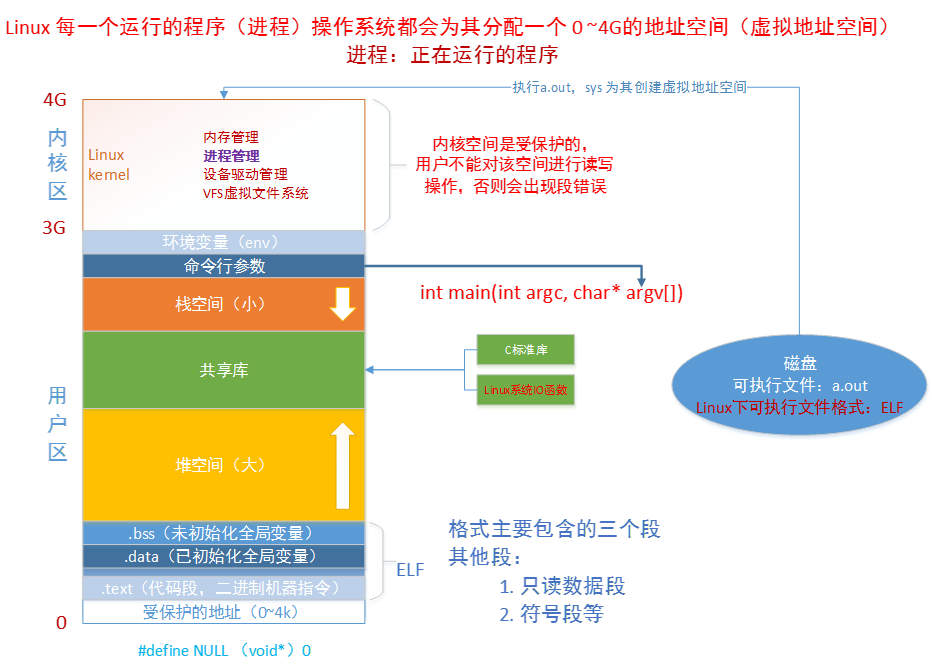
【补充】如上图中 a.out 可执行文件是存放在磁盘中,执行可执行文件后文件会被加载到内存中执行,形成进程。所以此时即使删除掉磁盘中的 a.out 文件也不会影响正在执行的该进程。
3. 错误处理函数
查看错误代码是调试程序的一个重要方法。c 语言中,errno 是记录系统的最近一次错误代码。该代码是一个 int 型的值,在 errno.h 中定义。
当 Linux C API 函数发生异常时,一般会将 errno 全局变量赋一个整数值,不同的值表示不同的含义,可以通过查看该值推测出错的原因。Linux 下也提供了 相关的库函数,方便的将 errno 整数值转换成描述了错误的字符串:
strerror():将错误号转换成字符串。- 函数原型:char *strerror(int errnum)
- 头文件:<string.h>
- 参数: errnum – 错误号,通常是 errno。
- 返回值:该函数返回一个指向错误字符串的指针,该错误字符串描述了错误 errnum。
perror():输出一个描述性错误消息。- 函数原型:void perror(const char *str)
- 头文件:<stdio.h>
- 参数: str – 这是 C 字符串,包含了一个自定义消息,将显示在原本的错误消息之前。
- 返回值:该函数不返回任何值。
测试程序:
#include <errno.h> //errno
#include <stdio.h> //fopen
#include <string.h> //strerror(errno)int main() {FILE* fp = fopen("xxxx", "r"); // 打开一个不存在的文件。if (NULL == fp) {//打印错误码printf("errno:%d\n", errno);// strerror把errno的数字转换成相应的文字printf("fopen:%s\n", strerror(errno));// perror打印错误原因的字符串,等同于上面strerror(errno)perror("fopen");}return 0;
}
查看错误号(可以通过vim打开查看):
- /usr/include/asm-generic/errno-base.h
- /usr/include/asm-generic/errno.h

4. C 库中 IO 函数工作流程
在 Linux 的世界里,一切设备皆文件。我们可以系统调用 I/O 的函数(I:input,输入;O:output,输出),对文件进行相应的操作( open()、close()、write() 、read() 等),流程如下图所示:

库函数访问文件的时候根据需要,设置不同类型的缓冲区,从而减少了直接调用 IO 系统调用的次数,提高了访问效率。
为什么需要缓冲区:
- 内存读写熟读非常快,但是写入到磁盘中非常慢,在将数据从内存存储到磁盘时,为了缓冲两者的读写速度,设置了缓冲区。
- 使用库函数访问文件的时候根据需要,设置不同类型的缓冲区,从而减少了直接调用 IO 系统调用的次数,提高了访问效率。
这个过程类似于快递员给某个区域(内核空间)送快递一样,快递员有两种方式送:
- 来一件快递就马上送到目的地,来一件送一件,这样导致来回走比较频繁(系统调用)。
- 等快递攒着差不多后(缓冲区),才一次性送到目的地(库函数调用)。
5. 文件描述符
[[一、Linux 下进程概述| 前置知识之进程与虚拟地址空间]]
打开现存文件或新建文件时,系统(内核)会返回一个文件描述符,文件描述符用来指定已打开的文件。这个文件描述符相当于这个已打开文件的标号,文件描述符是非负整数,是文件的标识,操作这个文件描述符相当于操作这个描述符所指定的文件。
程序运行起来后(每个进程)都有虚拟内存空间,虚拟内存空间的 PCB(PCB 可以理解为一个非常复杂的结构体)中有一张文件描述符表(数组,默认大小1024),专门用于存放文件描述符,每个文件描述符都可以定位一个文件。
文件描述符表中前三个是被默认占用的,分别是标准输入、标准输出、和标准错误(对应的文件描述符 0、1、2 ),他们默认都是打开的状态且都对应了一个文件,即当前终端(一个设备文件),所以也可以看出不同的文件描述符可以对应这同一个文件,比如对于某一个文件(a.txt),可以调用多次 fopen() 函数打开该文件,多次调用产生的文件描述符的值都是不同的。
#define STDIN_FILENO 0 //标准输入的文件描述符
#define STDOUT_FILENO 1 //标准输出的文件描述符
#define STDERR_FILENO 2 //标准错误的文件描述符
在程序运行起来后打开其他文件时,系统会返回文件描述符表中最小可用的文件描述符,并将此文件描述符记录在表中。文件描述符表位于 PCB 进程。

最大打开的文件个数:Linux 中一个进程最多只能打开 NR_OPEN_DEFAULT (即1024)个文件,故当文件不再使用时,应及时调用 close() 函数关闭文件,释放文件描述符。
- 查看当前系统允许打开最大文件个数:
cat /proc/sys/fs/file-max - 查看当前默认设置最大打开文件个数:
ulimit -a----> “open files” - 修改默认设置最大打开文件个数为 4096:ulimit -n 4096
6. 常用文件 IO 函数
此处文件 IO 函数是 Linux下系统函数,标准 c 库,例如 fopen() 等文件 IO 函数底层就是封装了此处的文件 IO 函数。

Linux 中调用此处的文件 IO 函数,Windows 中则调用 windows 平台的文件 IO 函数,所以标准 c 库的函数封装了这些系统函数,更加高级,效率也更高(带有缓冲区),还可以跨平台,平常建议使用标准 c 库的文件 IO 函数。

6.1 open 函数
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>// 打开一个已经存在的文件
int open(const char *pathname, int flags);// 创建一个新的文件
int open(const char *pathname, int flags, mode_t mode);功能:打开文件,如果文件不存在则可以选择创建。
参数:pathname:文件的路径及文件名flags:打开文件的行为标志,必选项:O_RDONLY, O_WRONLY, O_RDWRmode:这个参数只有在文件不存在时有效,即新建文件时指定文件的权限
返回值:成功:成功返回打开的文件描述符失败:-1, 并设置 errno
(1)flags 详细说明
必选项(以下三个选项是互斥的,即每次智能选择一个):
| 取值 | 含义 |
|---|---|
| O_RDONLY | 以只读的方式打开 |
| O_WRONLY | 以只写的方式打开 |
| O_RDWR | 以可读、可写的方式打开 |
可选项,可以和必选项按位或联合起来使用
| 取值 | 含义 |
|---|---|
| O_CREAT | 文件不存在则创建文件,使用此选项时需使用mode说明文件的权限 |
| O_EXCL | 如果同时指定了O_CREAT,且文件已经存在,则出错 |
| O_TRUNC | 如果文件存在,则清空文件内容 |
| O_APPEND | 写文件时,数据添加到文件末尾 |
| O_NONBLOCK | 对于设备文件, 以O_NONBLOCK方式打开可以做非阻塞I/O |
(2)mode 补充说明
mode 是一个八进制的数,表示创建出的新的文件的操作权限,比如:0775
- 文件最终权限:mode & ~umask
- umask 的作用是抹去某些权限,让文件或者目录的权限更加合理一些,shell 进程的 umask 掩码可以用 umask 命令查看。
- 不同用户 umask 值是不同的
- umask mode:设置掩码,例如:umask 022,这种设置方法只在当前终端有效。
- umask -S:查看各组用户的默认操作权限
| 取值 | 八进制 | 含义 |
|---|---|---|
| S_IRWXU | 00700 | 文件所有者的读、写、可执行权限 |
| S_IRUSR | 00400 | 文件所有者的读权限 |
| S_IWUSR | 00200 | 文件所有者的写权限 |
| S_IXUSR | 00100 | 文件所有者的可执行权限 |
| S_IRWXG | 00070 | 文件所有者同组用户的读、写、可执行权限 |
| S_IRGRP | 00040 | 文件所有者同组用户的读权限 |
| S_IWGRP | 00020 | 文件所有者同组用户的写权限 |
| S_IXGRP | 00010 | 文件所有者同组用户的可执行权限 |
| S_IRWXO | 00007 | 其他组用户的读、写、可执行权限 |
| S_IROTH | 00004 | 其他组用户的读权限 |
| S_IWOTH | 00002 | 其他组用户的写权限 |
| S_IXOTH | 00001 | 其他组用户的可执行权限 |
#include <fcntl.h>
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>int main(void) {int fd = -1;// 1.以只读方式打开一个文件 如果文件不存在就报错// fd = open("txt", O_RDONLY);// 2.以只写的方式打开一个文件 如果文件不存在就报错// fd = open("txt", O_WRONLY);// 3.以只写的方式打开一个文件 如果文件不存在就创建, 如果文件存在就直接打开// fd = open("txt", O_WRONLY | O_CREAT, 0644);// 4.以只读的方式打开一个文件 如果文件不存在就创建// fd = open("txt", O_RDONLY | O_CREAT, 0644);// 5.以读写的方式打开文件 如果文件存在就报错, 如果文件不存在就创建// fd = open("txt", O_RDWR | O_CREAT | O_EXCL, 0644);// 6.以读写的方式打开一个文件 如果文件不存在就创建 如果文件存在就清零fd = open("txt", O_RDWR | O_CREAT | O_TRUNC, 0644);if (-1 == fd) {perror("open");return 1;}printf("打开文件成功....\n");return 0;}
6.2 close 函数
#include <unistd.h>
int close(int fd);
功能:关闭已打开的文件
参数:fd : 文件描述符,open()的返回值
返回值:成功:0失败: -1, 并设置 errno
需要说明的是,当一个进程终止时,内核对该进程所有尚未关闭的文件描述符调用 close 关闭,所以即使用户程序不调用 close,进程在终止时内核也会自动关闭它打开的所有文件。
但是对于一个长年累月运行的程序(比如网络服务器),打开的文件描述符一定要记得关闭,否则随着打开的文件越来越多,会占用大量文件描述符和系统资源(Linux 中一个进程最多只能打开 NR_OPEN_DEFAULT (即1024)个文件,故当文件不再使用时,应及时调用 close() 函数关闭文件,释放文件描述符)。
6.3 write 函数
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
功能:把指定数目的数据写到文件(fd)
参数:fd : 文件描述符buf : 数据首地址,一般是数组count : 写入数据的长度(字节)
返回值:成功:实际写入数据的字节个数失败: - 1, 并设置 errno
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>int main(void) {int fd = -1;int ret = -1;//1. 打开文件//fd = open("txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);//fd = open("txt", O_WRONLY | O_CREAT , 0644);fd = open("txt", O_WRONLY | O_CREAT | O_APPEND, 0644);if (-1 == fd) {perror("open"); }printf("fd = %d\n", fd);//2. 写文件ret = write(fd, "ABCDEFG", 7); if (ret < 7) {perror("write"); }//3. 关闭文件close(fd);return 0;
}
注意:上面中 if (-1 == fd) 的写法,推荐 -1 写在前面,因为如果少写一个等于号,将 fd 赋值给-1会报错,但是如果将 -1 写在后面,少写一个等于号,将 -1 赋值给 fd 不会报错,并且永远为真,这种错误排查难度大。
6.4 read 函数
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
功能:把指定数目的数据读到内存(缓冲区)
参数:fd : 文件描述符buf : 内存首地址,,一般是数组,是一个传出参数count : 读取的字节个数
返回值:成功:实际读取到的字节个数失败: - 1, 并设置 errno
阻塞和非阻塞的概念
- 读
- 读常规文件是不会阻塞的,不管读多少字节,read 一定会在有限的时间内返回。
- 从终端设备或网络读则不一定,如果从终端输入的数据没有换行符,调用 read 读终端设备就会阻塞,如果网络上没有接收到数据包,调用 read 从网络读就会阻塞,至于会阻塞多长时间也是不确定的,如果一直没有数据到达就一直阻塞在那里。
- 写:同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定。
【注意】阻塞与非阻塞是对于文件而言的,而不是指 read、write 等的属性。
以非阻塞方式打开文件程序示例:
#include <unistd.h> //read
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h> //EAGAIN
int main() {// /dev/tty --> 当前终端设备// 以不阻塞方式(O_NONBLOCK)打开终端设备int fd = open("/dev/tty", O_RDONLY | O_NONBLOCK);char buf[10];int n;n = read(fd, buf, sizeof(buf));if (n < 0) {// 如果为非阻塞,但是没有数据可读,此时全局变量 errno 被设置为 EAGAINif (errno != EAGAIN) {perror("read /dev/tty");return -1;}printf("没有数据\n");}return 0;
}
6.5 lseek 函数
所有打开的文件都有一个当前文件偏移量(current file offset),以下简称为 cfo。cfo 通常是一个非负整数,用于表明文件开始处到文件当前位置的字节数。
读写操作通常开始于 cfo,并且使 cfo 增大,增量为读写的字节数。文件被打开时,cfo 会被初始化为 0,除非使用了 O_APPEND 。
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
功能:改变文件的偏移量,常见作用:1、移动文件指针到头文件:lseek(fd, 0, SEEK_SET);2.获取当前文件指针的位置:lseek(fd, 0, SEEK_CUR);3.获取文件长度:lseek(fd, 0, SEEK_END);4.拓展文件的长度,比如当前文件为 10字节, 需要拓展到110字节:lseek(fd, 100, SEEK_END),注意:需要写一次数据才能实现拓展参数:fd:文件描述符offset:根据 whence 来移动的位移数(偏移量)可以是正数,如果正数,则相对于 whence 往右移动也可以负数,如果是负数,则相对于 whence 往左移动。如果向前移动的字节数超过了文件开头则出错返回,如果向后移动的字节数超过文件末尾,再次写入时将增大文件尺寸。whence:其取值如下:SEEK_SET:从文件开头移动 offset 个字节SEEK_CUR:从当前位置移动 offset 个字节SEEK_END:从文件末尾移动 offset 个字节
返回值:若 lseek 成功执行, 则返回新的偏移量如果失败, 返回-1, 并设置 errno
// 扩展文件的长度
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>int main() {int fd = open("hello.txt", O_RDWR);if(fd == -1) {perror("open");return -1;}// 扩展文件的长度int ret = lseek(fd, 100, SEEK_END);if(ret == -1) {perror("lseek");return -1;}// 写入一个空数据// 注意,需要写一次数据才能实现拓展,否则文件大小依旧不会拓展write(fd, " ", 1);// 关闭文件close(fd);return 0;
}
7. 文件操作相关函数
7.1 stat 函数
# 查看文件信息命令
deng@itcast:~/share/4th$ stat txt

#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>int stat(const char *path, struct stat *buf);
int lstat(const char *pathname, struct stat *buf);
功能:获取文件状态信息,即获取文件信息比较 stat 和 lstat 的区别:当文件是一个符号链接时,lstat 返回的是该符号链接本身的信息;而 stat 返回的是该链接指向的文件的信息。
参数:path:文件名buf:保存文件信息的结构体
返回值:成功: 0失败: -1, 并设置 errno
struct stat结构体说明:
struct stat {dev_t st_dev; //文件的设备编号ino_t st_ino; //节点mode_t st_mode; //文件的类型和存取的权限nlink_t st_nlink; //连到该文件的硬连接数,刚建立的文件值为1uid_t st_uid; //用户IDgid_t st_gid; //组IDdev_t st_rdev; //设备文件的设备编号off_t st_size; //文件字节数(文件大小)blksize_t st_blksize;//块大小(文件系统的I/O 缓冲区大小)blkcnt_t st_blocks; //块数time_t st_atime; //最后一次访问时间time_t st_mtime; //最后一次修改时间time_t st_ctime; //最后一次改变时间(指属性)
};
st_mode(16位整数)参数说明


文件类型判断应使用宏函数

测试程序1:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>//获取文件相关信息
int main(void) {int ret = -1;struct stat buf;memset(&buf, 0, sizeof(buf));//获取文件相关信息ret = stat("txt", &buf);if (-1 == ret) {perror("stat"); return 1;}printf("st_dev: %lu\n", buf.st_dev);printf("st_ino: %lu\n", buf.st_ino);printf("st_nlink: %lu\n", buf.st_nlink);printf("st_uid: %d\n", buf.st_uid);printf("st_gid: %d\n", buf.st_gid);printf("st_rdev:%lu\n", buf.st_rdev);printf("st_size: %ld\n", buf.st_size);printf("st_blksize: %ld\n", buf.st_blksize);printf("st_blocks: %ld\n", buf.st_blocks);return 0;
}
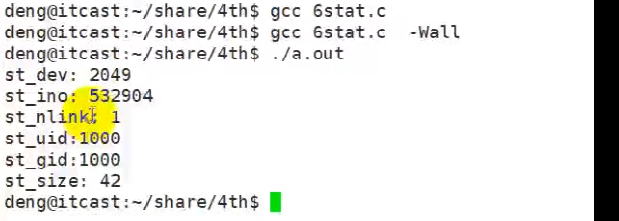
测试程序2:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>//获取文件相关信息
int main(int argc, char **argv) {int ret = -1;struct stat buf;if (2 != argc) {printf("usage: ./a.out filename\n"); return 1;}memset(&buf, 0, sizeof(buf));//获取文件相关信息ret = stat(argv[1], &buf);if (-1 == ret) {perror("stat"); return 1;}printf("st_dev: %lu\n", buf.st_dev);printf("st_ino: %lu\n", buf.st_ino);printf("st_nlink: %lu\n", buf.st_nlink);printf("st_uid: %d\n", buf.st_uid);printf("st_gid: %d\n", buf.st_gid);printf("st_rdev:%lu\n", buf.st_rdev);printf("st_size: %ld\n", buf.st_size);printf("st_blksize: %ld\n", buf.st_blksize);printf("st_blocks: %ld\n", buf.st_blocks);#if 0switch((buf.st_mode & S_IFMT)) {case S_IFSOCK: printf("socket\n");break;case S_IFLNK : printf("symbolic link\n");break;case S_IFREG : printf("regular file\n");break;case S_IFBLK : printf("block device\n");break;case S_IFDIR : printf("directory\n");break;case S_IFCHR : printf("character device\n");break;case S_IFIFO : printf("FIFO\n");break;defalt:printf("未知类型....\n");}
#elseif (S_ISREG(buf.st_mode) ) printf("is it a regular file \n"); if (S_ISDIR(buf.st_mode) ) printf("directory \n"); if (S_ISCHR(buf.st_mode) ) printf("character device \n"); if (S_ISBLK(buf.st_mode) ) printf("block device \n"); if (S_ISFIFO(buf.st_mode)) printf("FIFO (named pipe) \n"); if (S_ISLNK(buf.st_mode) ) printf("symbolic link \n"); if (S_ISSOCK(buf.st_mode)) printf("socket \n");
#endif//判断文件所属者权限if (buf.st_mode & S_IRUSR)printf("r");elseprintf("-");buf.st_mode & S_IWUSR ? printf("w") : printf("-");buf.st_mode & S_IXUSR ? printf("x") : printf("-");//判断文件所属组权限buf.st_mode & S_IRGRP ? printf("r") : printf("-");buf.st_mode & S_IWGRP ? printf("w") : printf("-");buf.st_mode & S_IXGRP ? printf("x") : printf("-");//判断文件其它权限buf.st_mode & S_IROTH ? printf("r") : printf("-");buf.st_mode & S_IWOTH ? printf("w") : printf("-");buf.st_mode & S_IXOTH ? printf("x") : printf("-");printf("\n");return 0;
}
7.2 access 函数
#include <unistd.h>int access(const char *pathname, int mode);
功能:判断指定文件是否具有某种权限,或者判断指定文件是否存在
参数:pathname:文件名mode:文件权限,4种权限R_OK:是否有读权限W_OK:是否有写权限X_OK:是否有执行权限F_OK:测试文件是否存在
返回值:0:有某种权限,或者文件存在-1:没有某种权限或文件不存在,并设置 errno
【注意】access() 函数判断权限实际上是帮助当前进程来判断指定文件是否具备某种权限。
#include <unistd.h>
#include <stdio.h>int main() {int ret = access("a.txt", F_OK);if(ret == -1) {perror("access");}printf("文件存在!!!\n");return 0;
}
7.3 chmod 函数
#include <sys/stat.h>int chmod(const char *pathname, mode_t mode);
功能:修改文件权限
参数:filename:文件名mode:权限(8进制数)
返回值:成功:0失败:-1, 并设置 errno
#include <sys/stat.h>
#include <stdio.h>
int main() {int ret = chmod("a.txt", 0777);if(ret == -1) {perror("chmod");return -1;}return 0;
}
7.4 chown 函数
#include <unistd.h>int chown(const char *pathname, uid_t owner, gid_t group);
功能:修改文件所有者和所属组
参数:pathname:文件或目录名owner:文件所有者id,通过查看 /etc/passwd 得到所有者idgroup:文件所属组id,通过查看 /etc/group 得到用户组id
返回值:成功:0失败:-1, 并设置 errno
7.5 truncate 函数
#include <unistd.h>
#include <sys/types.h>int truncate(const char *path, off_t length);
功能:修改文件大小
参数:path:文件文件名字length:指定的文件大小如果比原来小, 删掉后边的部分如果比原来大, 向后拓展
返回值:成功:0失败:-1, 并设置 errno
7.6 link 函数
#include <unistd.h>int link(const char *oldpath, const char *newpath);
功能:创建一个硬链接
参数:oldpath:源文件名字newpath:硬链接名字
返回值:成功:0失败:-1, 并设置 errno
7.7 symlink 函数
include <unistd.h>int symlink(const char *target, const char *linkpath);
功能:创建一个软链接
参数:target:源文件名字linkpath:软链接名字
返回值:成功:0失败:-1, 并设置 errno
7.8 readlink 函数
#include <unistd.h>ssize_t readlink(const char *pathname, char *buf, size_t bufsiz);
功能:读软连接对应的文件名,不是读内容(该函数只能读软链接文件)
参数:pathname:软连接名buf:存放软件对应的文件名bufsiz:缓冲区大小(第二个参数存放的最大字节数)
返回值:成功:>0,读到buf中的字符个数失败:-1, 并设置 errno
7.9 unlink 函数
#include <unistd.h>int unlink(const char *pathname);
功能:删除一个文件(软硬链接文件)
参数:pathname:删除的文件名字
返回值:成功:0失败:-1, 并设置 errno
8. 文件描述符复制
8.1 概述
dup() 和 dup2() 是两个非常有用的系统调用,都是用来复制一个文件的描述符,使新的文件描述符也标识旧的文件描述符所标识的文件。常用于文件重定向。
这个过程类似于现实生活中的配钥匙,钥匙相当于文件描述符,锁相当于文件,本来一个钥匙开一把锁,相当于,一个文件描述符对应一个文件,现在,我们去配钥匙,通过旧的钥匙复制了一把新的钥匙,这样的话,旧的钥匙和新的钥匙都能开启这把锁。
对比于 dup(), dup2() 也一样,通过原来的文件描述符复制出一个新的文件描述符,这样的话,原来的文件描述符和新的文件描述符都指向同一个文件,我们操作这两个文件描述符的任何一个,都能操作它所对应的文件。
8.1 dup 函数
#include <unistd.h>int dup(int oldfd);
功能:通过 oldfd 复制出一个新的文件描述符,新的文件描述符是调用进程文件描述符表中最小可用的文件描述符,最终 oldfd 和新的文件描述符都指向同一个文件。
参数:oldf:需要复制的文件描述符 oldfd
返回值:成功:新文件描述符失败: -1, 并设置 errno
8.2 dup2 函数
#include <unistd.h>int dup2(int oldfd, int newfd);
功能:通过 oldfd 复制出一个新的文件描述符 newfd,如果成功,newfd 和函数返回值是同一个返回值,最终 oldfd 和新的文件描述符 newfd 都指向同一个文件。
参数:oldfd:需要复制的文件描述符newfd:新的文件描述符,这个描述符可以人为指定一个合法数字(0 - 1023),如果指定的数字已经被占用(和某个文件有关联),此函数会自动关闭 close() 断开这个数字和某个文件的关联,再来使用这个合法数字。如果oldfd和newfd值相同,相当于什么都没有做。
返回值:成功:返回 newfd失败:返回 -1, 并设置 errno
8.3 示例分析
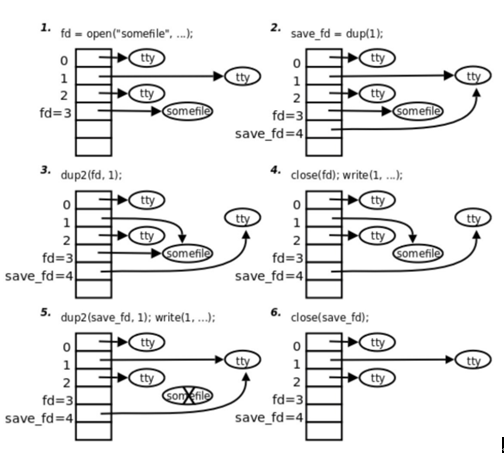
9. fcnlt 函数
#include <unistd.h>
#include <fcntl.h>int fcntl(int fd, int cmd, ... /* arg */);
功能:改变已打开的文件性质,fcntl 针对描述符提供控制。
参数:fd:操作的文件描述符cmd:操作方式arg:针对cmd的值,fcntl能够接受第三个参数int arg。
返回值:成功:返回某个其他值失败:-1, 并设置 errno
fcntl函数有5种功能(常用第一种和第三种):
-
复制一个现有的描述符(复制的是第一个参数 fd,返回值得到一个新的文件描述符)(cmd=F_DUPFD)
-
获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD)
-
获得/设置文件状态标记(cmd=F_GETFL或F_SETFL)
- F_GETFL:获取指定的文件描述符文件状态 flag,获取的 flag 和我们通过 open 函数传递的 flag 是一个东西。
- F_SETFL:设置文件描述符文件状态 flag
- 必选项:O_RDONLY, O_WRONLY, O_RDWR 不可以被修改
- 可选性:O_APPEND(表示追加数据), O_NONBLOCK(设置成非阻塞),可选项是可以被修改的。
-
获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN)
-
获得/设置记录锁(cmd=F_GETLK, F_SETLK或F_SETLKW)
参考示例:
// 等价于 dup()
int new_fd = fcntl(fd, F_DUPFD, 0);
// 获取文件状态标志
int flag = fcntl(fd, F_GETFL, 0);
switch (flag & O_ACCMODE) {case O_RDONLY:printf("read only\n");break;case O_WRONLY:printf("write only\n");break;case O_RDWR:printf("read and write\n");break;default:break;
}if (flag & O_APPEND) {printf("append\n");
}flag |= O_APPEND; // 追加flag
int ret = fcntl(fd, F_SETFL, flag); //设置文件状态标记
10. 目录相关操作
10.1 getcwd 函数
#include <unistd.h>char *getcwd(char *buf, size_t size);
功能:获取当前进程的工作目录
参数:buf:缓冲区,存储当前的工作目录size:缓冲区大小
返回值:成功:buf中保存当前进程工作目录位置失败:NULL,, 并设置 errno
【补充】可执行程序在某个目录下执行,该可执行程序的工作目录默认就是该目录。
10.2 chdir 函数
#include <unistd.h>int chdir(const char *path);
功能:修改当前进程的工作目录
参数:path:切换的路径
返回值:成功:0失败:-1, 并设置 errno
【补充】可执行程序在某个目录下执行,该可执行程序的工作目录默认就是该目录。
10.3 opendir 函数
#include <sys/types.h>
#include <dirent.h>DIR *opendir(const char *name);
功能:打开一个目录,返回一个指针指向目录,目录也是一个文件
参数:name:目录名
返回值:成功:返回指向该目录结构体指针,理解为目录流信息失败:NULL, 并设置 errno
10.4 readdir 函数
#include <dirent.h>struct dirent *readdir(DIR *dirp);
功能:读取目录中数据,即读取目录下的文件信息
参数:dirp:opendir 的返回值
返回值:成功:目录结构体指针,指针代表读取到的文件的信息失败:读取到目录信息流末尾或者读取失败了,返回NULL, 并设置 errno
相关结构体说明:
struct dirent
{ino_t d_ino; // 此目录进入点的inodeoff_t d_off; // 目录文件开头至此目录进入点的位移signed short int d_reclen; // d_name 的长度, 不包含NULL 字符unsigned char d_type; // d_type 所指的文件类型 char d_name[256]; // 文件名
};
d_type 文件类型说明:
| 取值 | 含义 |
|---|---|
| DT_BLK | 块设备 |
| DT_CHR | 字符设备 |
| DT_DIR | 目录 |
| DT_LNK | 软链接 |
| DT_FIFO | 管道 |
| DT_REG | 普通文件 |
| DT_SOCK | 套接字 |
| DT_UNKNOWN | 未知 |
10.5 closedir 函数
#include <sys/types.h>
#include <dirent.h>int closedir(DIR *dirp);
功能:关闭目录
参数:dirp:opendir返回的指针
返回值:成功:0失败:-1, 并设置 errno
示例:读取某个目录下所有的普通文件的个数
#include <sys/types.h>
#include <dirent.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>int getFileNum(const char * path);
int main(int argc, char * argv[]) {if(argc < 2) {printf("%s path\n", argv[0]);return -1;}int num = getFileNum(argv[1]);printf("普通文件的个数为:%d\n", num);return 0;}// 用于获取目录下所有普通文件的个数
int getFileNum(const char * path) {// 1.打开目录DIR * dir = opendir(path);if(dir == NULL) {perror("opendir");exit(0);}struct dirent *ptr;// 记录普通文件的个数int total = 0;while((ptr = readdir(dir)) != NULL) {// 获取名称char * dname = ptr->d_name;// 忽略掉. 和..if(strcmp(dname, ".") == 0 || strcmp(dname, "..") == 0) {continue;}// 判断是否是普通文件还是目录if(ptr->d_type == DT_DIR) {// 目录,需要继续读取这个目录char newpath[256];sprintf(newpath, "%s/%s", path, dname);total += getFileNum(newpath);}if(ptr->d_type == DT_REG) {// 普通文件total++;}}// 关闭目录closedir(dir);return total;
}
10.6 mkdir 函数
#include <sys/types.h>
#include <dirent.h>int mkdir(const char *pathname, mode_t mode);
功能:创建一个目录
参数:pathname: 创建的目录的路径mode: 权限,八进制的数
返回值:成功:0失败:-1, 并设置 errno
#include <sys/stat.h>
#include <sys/types.h>
#include <stdio.h>
int main() {int ret = mkdir("aaa", 0777);if(ret == -1) {perror("mkdir");return -1;}return 0;
}
10.7 rename 函数
#include <stdio.h>int rename(const char *oldpath, const char *newpath);
功能:把oldpath的文件名改为newpath,即修改目录名
参数:
oldpath:旧文件名
newpath:新文件名
返回值:
成功:0
失败:-1, 并设置 errno
11. 时间相关函数
11. 0 时间相关概念
谈到时间(包括日期),必须先明确下面的概念。
Linux 系统一直使用两种不同的时间值:日历时间和进程时间
1、日历时间:
日历时间是从国际标准时间公元 1970 年 1 月1日 00:00:00 到现在所经历的秒数(UTC);此时间精度为秒。系统用 time_t 保存这种时间值,如果时间要求不是非常精确则可以使用此时间,例如记录文件修改的时间。time_t 是个长整型数值,其定义为:typedef long time_t;,其实就是一个长整数。
日历时间还要注意时区问题:由于世界各国家与地区经度不同,地方时也有所不同,因此将其划分为 24 个时区,其中 UTC (Coordinated Universal Time,世界标准时间,以前称为格林威治时间(GMT))为 0 时区。所以同样都是日历时间,但是时区不同,时间也将不同。我们经常涉及的时区为 UTC 所在的 0 时区与东八区时区(中国所在的时区),两者两者相差 8 小时,比如 UTC 时间是10:00, 中国时间就是18:00。
分解时间(broken-down time):就是将时间按照年、月、日、时、分、秒等格式显示的时间。如Wed Apr 1 11:23:33 2020。【注意】**它与时区相关:时区不同,时间也将不同。
简单日历时间(simple calendar time):就是从固定时间点(1970年1月1日-00.00.00(UTC))到当前时间点所经过的秒数。计算机在计时时就使用它。【注意】它与时区无关。固定为 0 区(UTC)。
【注意】日历时间存在时区问题;简单日历时间不存在时区问题,简单日历时间相当于 UTC 时间。
2、进程时间:
也被称为 CPU 时间,用以度量进程使用的中央处理机资源。进程时间以时钟滴答计算,历史上曾经以每秒钟为50、60或100个滴答,使用 sysconf() 函数可以得到每秒钟的滴答数。系统用 clock_t 保存这种时间值,其定义为:typedef long clock_t;,其实就是一个长整数。
当度量一个进程的执行时间时,UNIX系统使用三个进程时间值:
- 时钟时间:时钟时间又称为墙上时钟时间(wall clock time)。它是进程运行的时间总量,其值与系统中同时运行的进程数有关。
- 用户CPU时间:用户 CPU 时间是执行用户指令所用的时间。
- 系统CPU时间:系统 CPU 时间是为该进程执行内核程序所经历的时间。例如,每当一个进程执行一个系统服务时,例如
read()或write(),则在内核中执行该服务所花费的时间就计入该进程的系统CPU时间。用户 CPU 时间和系统 CPU 时间之和常被称为 CPU 时间。
11.1 时间获取函数
11.1.1 time 函数
#include <time.h>time_t time(time_t * timer);
功能:获取机器(操作系统)当前的时间,返回的结果是一个 time_t,精确到秒。
参数:timer=NULL 时得到机器(操作系统)当前的日历时间; timer=时间数值时,用于设置日历时间;
返回值:成功: 返回机器(操作系统)当前的日历时间失败:-1, 并设置 errno
11.1.2 clock 函数
#include <time.h>clock_t clock(void);
功能:获取从程序启动到此函数调用所消耗的处理时间,精确到毫秒。
参数:空
返回值:成功:返回消耗的时间失败:-1, 并设置 errno
【注意】也获取程序所使用的秒数,除以 CLOCKS_PER_SEC 即可。
11.1.3 gettimeofday() 函数
#include<sys/time.h>
#include<unistd.h>int gettimeofday(struct timeval *tv, struct timezone *tz);
功能:获取机器(操作系统)当前的时间存于 tv 结构体中,相应的时区信息则存于 tz 结构体中。可以精确到微秒。参数:tv:存放机器(操作系统)当前的日历时间。tz:存放当前时区,通常设置为 NULL。
返回值:成功:返回 0失败:返回 -1, 并设置 errno
struct timeval,struct timezone 结构体
struct timeval { time_t tv_sec; /* seconds (秒)*/suseconds_t tv_usec; /* microseconds(微秒) */};struct timezone {int tz_minuteswest; /* minutes west of Greenwich */int tz_dsttime; /* type of DST correction */
};int tz_minuteswest; /* 格林威治时间往西方的时差 */
int tz_dsttime; /* 时间的修正方式*/
11.2 日历时间转换为分解时间
11.2.1 localtime() 函数
#include <time.h>struct tm *localtime(const time_t *timep);
功能:将 time_t 所表示的日历时间转换为本地时间(我们是东八区)并转成 tm 类型。
参数:timep 为日历时间,一般通过 time() 函数获取。;
返回值:以 tm 结构表达的时间;
struct tm 类型的各数据成员分别表示年月日时分秒。
struct tm {int tm_sec; // 代表目前秒数,正常范围为0-59,但允许至61秒int tm_min; // 代表目前分数,范围0-59int tm_hour; // 从午夜算起的时数,范围为0-23int tm_mday; // 目前月份的日数,范围01-31int tm_mon; // 代表目前月份,从一月算起,范围从0-11int tm_year; // 从1900 年算起至今的年数int tm_wday; // 一星期的日数,从星期一算起,范围为0-6int tm_yday; // 从今年1月1日算起至今的天数,范围为0-365int tm_isdst; // 日光节约时间的旗标
};
【注意】与下文 gmtime() 函数区分:localtime() 获得的是当地时区的分解时间。
11.2.2 gmtime() 函数
#include <time.h>struct tm *gmtime(const time_t *timep);
功能:将 time_t 结构所表示的日历时间转换成转成 struct tm 类型,然后将 tm 返回。
参数:timep 是由 time(NULL) 得到的日历时间;
返回值:返回 tm 格式的简单日历时间(UTC 时间)。
【注意】localtime() 和 gmtime() 区别:
gmtime()获得是 0 时区(即UTC时间)localtime()获得当地时区,我们获得的是东八区时间
两者两者相差 8 小时,比如gmtime()是10:00, 中国时间localtime()就是18:00。
11.3 分解时间转换为日历时间
11.3.1 mktime() 函数
#include <time.h>time_t mktime(struct tm *tm);
功能:将 tm 格式的时间转化为 time_t,即经历的秒数。
参数:tm 格式的时间。
返回值:成功:机器(操作系统)当前的日历时间。失败:返回 -1, 并设置 errno
【注意】此函数使用的时区为机器(操作系统)默认的时区。
11.4 将时间转换为字符串相关函数
11.4.1 asctime() 函数
#include <time.h>char *asctime(struct tm *ptr);
功能:将 tm 结构中的信息转换成真实世界所使用的时间日期表示方法,并以字符串形态返回。即将分解时间转换成字符串。参数:ptr 为 struct tm 类型的时间结构体;
返回值:返回的时间字符串格式为:星期,月,日,小时:分:秒,年
示例
#include <stdio.h>
#include <time.h>int main() {time_t timer;struct tm* tblock;timer = time(NULL);tblock = localtime(&timer);printf("Local time is: %s", asctime(tblock));return 0;
}
11.4.2 ctime() 函数
#include <time.h>char *ctime(const time_t *timep);
功能:将 time_t 结构中的信息转换成真实世界所使用的时间日期表示方法,并以字符串形态返回。即将日历时间转换为分解时间。
参数:timep 是由 time(NULL) 得到的日历时间;
返回值:返回的时间字符串格式为:星期,月,日,小时:分:秒,年
【注意】 若再调用相关的时间日期函数,此字符串可能会被破坏。
11.4.3 strftime() 与 strptime() 函数
#include <time.h>size_t strftime(char *s, size_t maxsize, char *format, const struct tm *timeptr);
char *strptime(const char *buf, const char*format, struct tm *timeptr)
功能:这两个函数都是时间格式控制函数,在功能上看起来正好相反。strftime 将一个 tm 结构格式化为一个字符串,strptime 则是将一个字符串格式化为一个 tm 结构。参数:s:存放格式化的字符串maxsize:最多可以输出的字符串数format:格式化timeptr:要转换的 tm 格式时间
返回值:strftime 返回 UTC 时间秒数;strptime() 返回一个指针,这个指针指向最后一个被转换内容的后面一个字符处。
【注意 】strptime() 如果它遇到无法转换的字符,转换就会简单的在那里停止。调用程序需要充分的检查已经转换的字符串以确保这些有效的转换值已经写进 tm 结构体中。
11.5. 时间差计算函数
11.5.1 difftime() 函数
#include <time.h>double difftime(time_t time1, time_t time0);
功能:计算两个时间的差值。
参数:两个 time_t 格式的时间
返回值:时间差,精确到秒
11.6 线程安全的时间转换函数
以下时间转换函数是线程安全的,多线程中应用对应的 xxx_r 函数代替 xxx 函数
// asctime_r: 将 tm 转换为字符串形式
char *asctime_r(const struct tm *tm, char *buf);// ctime_r: 将 time_t 时间转换为字符串形式
char *ctime_r(const time_t *timep, char *buf);// gmtime_r: 将 time_t 时间转换为 tm 格式时间
struct tm *gmtime_r(const time_t *timep, struct tm *result);// localtime_r: 将 time_t 时间转换为 tm 格式
struct tm *localtime_r(const time_t *timep, struct tm *result);
相关文章:
Linux 常用 API 函数
文章目录1. 系统调用与库函数1.1 什么是系统调用1.2 系统调用的实现1.3 系统调用和库函数的区别2. 虚拟内存空间3. 错误处理函数4. C 库中 IO 函数工作流程5. 文件描述符6. 常用文件 IO 函数6.1 open 函数6.2 close 函数6.3 write 函数6.4 read 函数6.5 lseek 函数7. 文件操作相…...
【转载】bootstrap自定义样式-bootstrap侧边导航栏的实现
bootstrap自带的响应式导航栏是向下滑动的,但是有时满足不了个性化的需求: 侧滑栏使用定位fixed 使用bootstrap响应式使用工具类 visible-sm visible-xs hidden-xs hidden-sm等对不同屏幕适配 侧滑栏的侧滑效果不使用jquery方法来实现,使用的是css3 tr…...

奇瑞x华为纯电智选车来了,新版ADS成本将大幅下降
作者 | 德新 编辑 | 于婷HiEV获悉,问界M5将在4月迎来搭载高阶辅助驾驶的新款,而M9将在今年秋天发布。 奇瑞一侧,华为将与奇瑞首先推出纯电轿车,代号EH3。新车将在奇瑞位于芜湖江北新区的智能网联超级二工厂组装下线。目前超级二工…...
机器学习的特征归一化Normalization
为什么需要做归一化? 为了消除数据特征之间的量纲影响,就需要对特征进行归一化处理,使得不同指标之间具有可比性。对特征归一化可以将所有特征都统一到一个大致相同的数值区间内。 为了后⾯数据处理的⽅便,归⼀化可以避免⼀些不…...
程序员看过都说好的资源网站,看看你都用过哪些?
程序员必备的相关资源网站一.图片专区1.表情包(1)发表情(2)逗比拯救世界(3)搞怪图片生成(4)哇咔工具2.图标库(1)Font Awesome(2)iconf…...
Win11的两个实用技巧系列之设置系统还原点的方法、安全启动状态开启方法
Win11如何设置系统还原点?Win11设置系统还原点的方法很多用户下载安装win11后应该如何创建还原点呢?现在我通过这篇文章给大家介绍一下Win11如何设置系统还原点?在Windows系统中有一个系统还原功能可以帮助我们在电脑出现问题的时候还原到设置的时间上&…...
【Linux】项目的自动化构建-make/makefile
💣1.背景会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的 规则来指定,哪些文件需要先编译ÿ…...

【Redis学习2】Redis常用数据结构与应用场景
Redis常用数据结构与应用场景 redis中存储数据是以key-value键值对的方式去存储的,其中key为string字符类型,value的数据类型可以是string(字符串)、list(列表)、hash(字典)、set(集合) 、 zset(有序集合)。 这5种数据类型在开发中可以应对大部分场景的…...

踩了大坑:https 证书访问错乱
文章目录一、问题排查及解决问题一:证书加载错乱问题二:DNS 解析污染问题问题三:浏览器校验问题二、终极解决方法2.1 可外网访问域名2.2 只能内网访问域名2.3 内网自动化配置2.4 错误解决一、问题排查及解决 今天遇到这样一个问题࿰…...
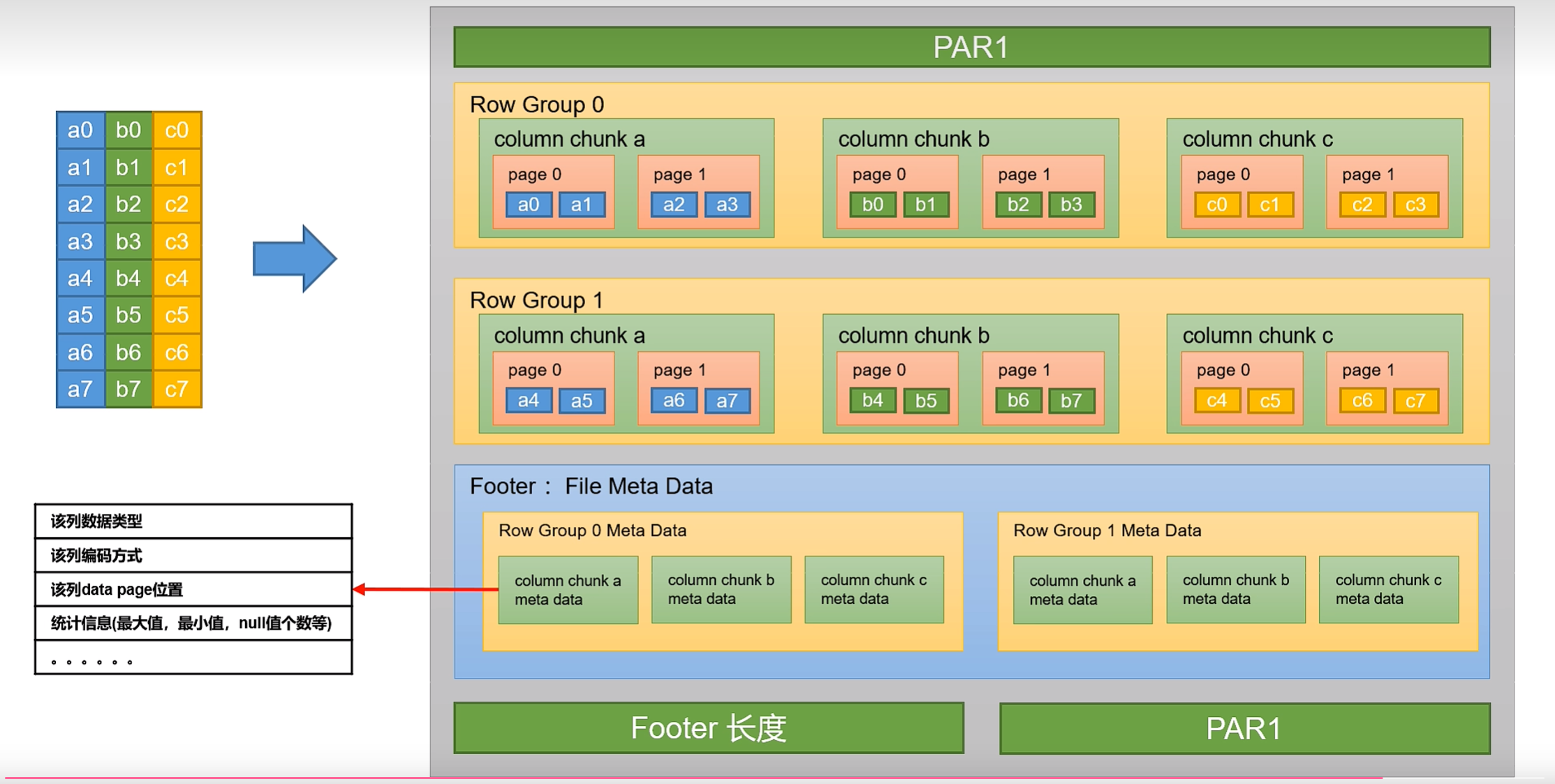
大数据技术之Hive(四)分区表和分桶表、文件格式和压缩
一、分区表和分桶表1.1 分区表partitionhive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择式选择查询所需要的分区,这样的查询效率辉提高很多。1.1.1 分区表基本语…...

环形缓冲区(c语言)
1、概念介绍 在我们需要处理大量数据的时候,不能存储所有的数据,只能先处理先来的,然后将这个数据释放,再去处理下一个数据。 如果在一个线性的缓冲区中,那些已经被处理的数据的内存就会被浪费掉。因为后面的数据只能…...
创建自助服务知识库的指南
在SaaS领域,自助文档是你可以在客户登录你的网站时为他们提供的最灵活的帮助方式,简单来说,一个自助知识库是一个可以帮助许多客户的文档,拥有出色的自助服务知识库,放在官网或者醒目的地方,借助自助服务知…...

分层测试(1)分层测试是什么?【必备】
1. 什么是分层测试? 分层测试是通过对质量问题分类、分层来保证整体系统质量的测试体系。 模块内通过接口测试保证模块质量,多模块之间通过集成测试保证通信路径和模块间交互质量,整体系统通过端到端用例对核心业务场景进行验证,…...

开源ZYNQ AD9361软件无线电平台
(1) XC7Z020-CLG400 (2) AD9363 (3) 单发单收,工作频率400MHz-2.7GHz (4) 发射带PA,最大输出功率约20dbm (5) 接收带LNA,低…...
第四阶段-12关于Spring Security框架,RBAC,密码加密原则
关于csmall-passport项目 此项目主要用于实现“管理员”账号的后台管理功能,主要实现: 管理员登录添加管理员删除管理员显示管理员列表启用 / 禁用管理员 关于RBAC RBAC:Role-Based Access Control,基于角色的访问控制 在涉及…...

JPA——Date拓展之Calendar
Java Calendar 是时间操作类,Calendar 抽象类定义了足够的方法,在某一特定的瞬间或日历上,提供年、月、日、小时之间的转换提供方法 一、获取具体时间信息 1. 当前时间 获取此刻时间的年月日时分秒 Calendar calendar Calendar.getInstance(); int …...

一文吃透 Spring 中的 AOP 编程
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
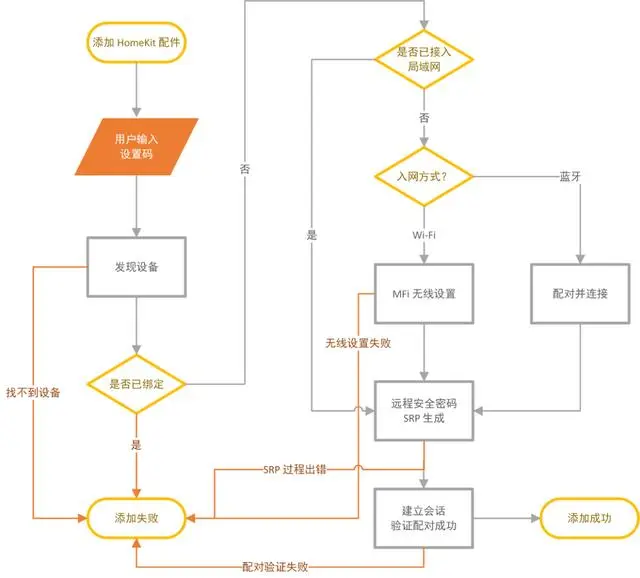
Apple主推的智能家居是什么、怎么用?一篇文章带你从零完全入门 HomeKit
如果你对智能家居有所了解,那应该或多或少听人聊起过 HomeKit。由 Apple 开发并主推的的 HomeKit 既因为产品选择少、价格高而难以成为主流,又因其独特的优秀体验和「出身名门」而成为智能家居领域的焦点。HomeKit 究竟是什么?能做什么&#…...

SpringCloud系列知识快速复习 -- part 1(SpringCloud基础知识,Docker,RabbitMQ)
SpringCloud知识快速复习SpringCloud基础知识微服务特点SpringCloud常用组件服务拆分和提供者与消费者概念Eureka注册中心原理Ribbon负载均衡原理负载均衡策略饥饿加载Nacos注册中心服务分级存储模型权重配置环境隔离Nacos与Eureka的区别Nacos配置管理拉取配置流程配置热更新配…...

2023上半年北京/上海/广州/深圳NPDP产品经理认证报名
产品经理国际资格认证NPDP是国际公认的唯一的新产品开发专业认证,集理论、方法与实践为一体的全方位的知识体系,为公司组织层级进行规划、决策、执行提供良好的方法体系支撑。 【认证机构】 产品开发与管理协会(PDMA)成立于1979年…...

从零构建Twitter数据应用:掌握Tweepy库的核心能力
从零构建Twitter数据应用:掌握Tweepy库的核心能力 【免费下载链接】tweepy tweepy/tweepy: Tweepy 是一个 Python 库,用于访问 Twitter API,使得在 Python 应用程序中集成 Twitter 功能变得容易。 项目地址: https://gitcode.com/gh_mirror…...

原神智能助手BetterGI:自动化游戏体验创新方案
原神智能助手BetterGI:自动化游戏体验创新方案 【免费下载链接】better-genshin-impact 🍨BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动派遣 | 一键强化 - UI Automation Testing Tools For Genshi…...

构建自动化Kubernetes集群健康检查的终极工作流:Popeye与CI/CD的完美集成指南
构建自动化Kubernetes集群健康检查的终极工作流:Popeye与CI/CD的完美集成指南 【免费下载链接】popeye 👀 A Kubernetes cluster resource sanitizer 项目地址: https://gitcode.com/gh_mirrors/po/popeye Popeye是一款强大的Kubernetes集群资源清…...

Elm-SPA-Example 完整指南:构建现代化单页面应用的终极教程
Elm-SPA-Example 完整指南:构建现代化单页面应用的终极教程 【免费下载链接】elm-spa-example A Single Page Application written in Elm 项目地址: https://gitcode.com/gh_mirrors/el/elm-spa-example Elm-SPA-Example 是一个基于 Elm 语言构建的单页面应…...

5分钟快速集成Material CalendarView:终极入门指南
5分钟快速集成Material CalendarView:终极入门指南 【免费下载链接】material-calendarview A Material design back port of Androids CalendarView 项目地址: https://gitcode.com/gh_mirrors/ma/material-calendarview Material CalendarView是一个遵循Ma…...

知识自由与内容价值:Bypass Paywalls Clean的平衡之道
知识自由与内容价值:Bypass Paywalls Clean的平衡之道 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息爆炸的数字时代,优质内容与访问限制之间的矛盾日益…...

单周期控制无桥PFC:高功率参数计算详解及单周期控制学习资源手册
单周期控制无桥PFC 85~264输入,400输出,功率2000W。 具体参数计算要求如下图 参数计算文档,其中包括电感电容详细计算,有单周期控制参考学习资料 单周期控制交错无桥PFC也有单周期控制无桥PFC这玩意儿搞电源的工程师都…...
)
SAP后台开发必备:这20个事务码能帮你省下50%查表时间(含DBACOCKPIT高阶用法)
SAP后台开发效率革命:20个事务码与DBACOCKPIT高阶实战指南 当系统突然提示"凭证不存在"时,你会不会下意识地打开SE16N输入T_BKPF?当用户抱怨报表运行缓慢时,是否还在用ST05逐个表追踪?作为经历过数百个SAP项…...

如何系统解决付费墙访问限制:技术方案解析
如何系统解决付费墙访问限制:技术方案解析 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字内容消费日益普及的今天,优质信息的获取却常常受到付费墙的技…...

YOLOv8模型改造实战:用AKConv替换普通卷积,实测mAP提升3个点
YOLOv8模型性能跃升实战:AKConv模块的即插即用改造指南 在目标检测领域,YOLO系列模型始终保持着技术前沿地位。当标准YOLOv8模型在您的工业质检或遥感分析任务中遇到精度瓶颈时,AKConv(可变形核卷积)的引入可能成为突破…...