大数据技术之Hive(四)分区表和分桶表、文件格式和压缩
一、分区表和分桶表
1.1 分区表partition
hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择式选择查询所需要的分区,这样的查询效率辉提高很多。
1.1.1 分区表基本语法
a. 创建分区表
create table dept_partition(deptno int,dname string,loc string
)partitioned by (day string)row format delimited fields terminated by '\t'lines terminated by '\n';b. 分区表读写数据
写数据--load
load data local inpath '/opt/stufile/dept_20230225.log'
into table dept_partition
partition (day='20230225')写数据--insert
insert overwrite table dept_partition partition (day='20230226')
select deptno,dname,loc from dept_partition where day='20230225';读数据
查询分区表数据时,可以将分区字段看作表的伪劣,可像使用其他字段一样使用分区字段。
select deptno,dname,loc,day
from dept_partition
where day='2020-04-01'c. 分区表基本操作
查看所有分区信息
show prtitions dept_partition;增加分区
创建单个分区
alter table dept_partition
add partition(day='20220403');同时创建多个分区(分区之间不能有逗号)
alter table dept_partition
add partition(day='20220404') partition(day='20220405');删除分区
删除单个分区
alter table dept_partition
drop partition(day='20220403');同时删除多个分区(分区之间必须有逗号)
alter table dept_partition
drop partition(day='20220404'), partition(day='20220405');d. 修复分区
Hive 将分区表的所有分区信息都保存在了元数据中,只有元数据与 HDFS 上的分区路径一致时,分区表才能正常读写数据。若用户手动创建/删除分区路径,Hive 都是感知不到的,这样就会导致 Hive 的元数据和 HDFS 的分区路不一致。再比如,若分区表为外部表用户执行 drop partition 命令后,分区元数据会被删除,而 HDFS 的分区路径不会被删除同样会导致 Hive 的元数据和 HDFS 的分区路径不一致。
若出现元数据和 HDFS 路径不一致的情况,可通过如下几种手段进行修复:
add partition
若手动创建HDFS 的分区路径,Hive 无法识别,可通过add partition 命令增加分区元数据信息,从而使元数据和分区路径保持一致。
drop partition
若手动删除 HDFS 的分区路径,Hive 无法识别,可通过 drop partition 命令删除分区元数据信息,从而使元数据和分区路径保持一致。
msck
若分区元数据和 HDFS 的分区路径不一致,还可使用 msck 命令进行修复。
msck repair table table_name [add/drop/sync partitions];1.1.2 二级分区表
如果一天内的日志数据量也很大,可以创建二级分区表,例如可以在按天分区的基础上,再对每天的数据按小时进行分区。
二级分区表建表语句
create create table dept partition2(dleptno int,dnamne string,,loc string
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';数据装载语句
load data local inpath '/opt/stufile/dept_20220401.log'
into table dept_partition
partition (day='20220401', hour='12');查询分区数据
select *
from dept_partition2
where day='20220401' and hour='12';1.1.3 动态分区
动态分区是指向分区表 insert 数据时,被写往的分区不由用户指定,而是由每行数据的最后一个宁段的值来动态的决定。使用动态分区,可只用一个 insert 语句将数据写入多个分区。
动态分区相关参数
1. 动态分区功能总开关(默认 true,开启)
set hive.exec.dynamic.partition=true2. 严格模式和非严格模式
-> 动态分区的模式,默认 strict(严格模式),要求必须指定至少一个分区为静态分区,
-> nonstrict(非严格模式) 允许所有的分区字段都使用动态分区。
set hive.exec.dynamic.partition.mode=nonstrict3. 一条 insert 语句可同时创建的最大的分区个数,默认为 1000。
set hive.exec.max.dynamic.partitions=10004. 单个 Mapper 或者 Reducer 可同时创建的最大的分区个数,默认为 100。
set hive.exec.max.dynamic.partitions.pernode=1005. 一条 insert 语句可以建的最大的文件个数,默认 100000
hive.exec.max.created.files=1000006. 当查询结果为空时且进行动态分区时,是否抛出异常,默认 false。
hive.error.on.empty.partition=false1.2 分桶表bucket
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分,分区针对的是数据的存储路径,分桶针对的是数据文件。
分桶表的基本原理是,首先为每行数据计算一个指定字段的数据的 hash 值,然后模以·个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)。
1.2.1 分桶表基本语法
建表语句
create table stu buck(id int,name string
)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';数据装载
load data local inpath '/opt/module/hive/datas/student.txt'
into table stu_buck;1.2.2 分桶排序表
建表语句
create table stu buck(id int,name string
)
clustered by(id) sorted by(id)
into 4 buckets
row format delimited fields terminated by '\t';数据装载
load data local inpath '/opt/module/hive/datas/student.txt'
into table stu_buck_sort;二、文件格式和压缩
2.1hive文件格式
为 Hive 表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive 表数据的存储格式,可以选择 text file、orc、parquet、sequence file 等。
2.1.1 Text File
文本文件是 Hive 默认使用的文件格式,文本文件中的一行内容,就对应 Hive 表中的行记录。
可通过以下建表语句指定文件格式为文本文件:
create table textfile_table
(column specs)
stored as textfile;2.1.2 ORC
ORC (Optimized Row Columnar) file format 是 Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高 Hive 读写数据和处理数据的性能。
与列式存储相对的是行式存储,下图是两者的对比:

行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
前文提到的 text file 和 sequence file 都是基于行存储的,orc 和 parquet 是基于列式存储的。

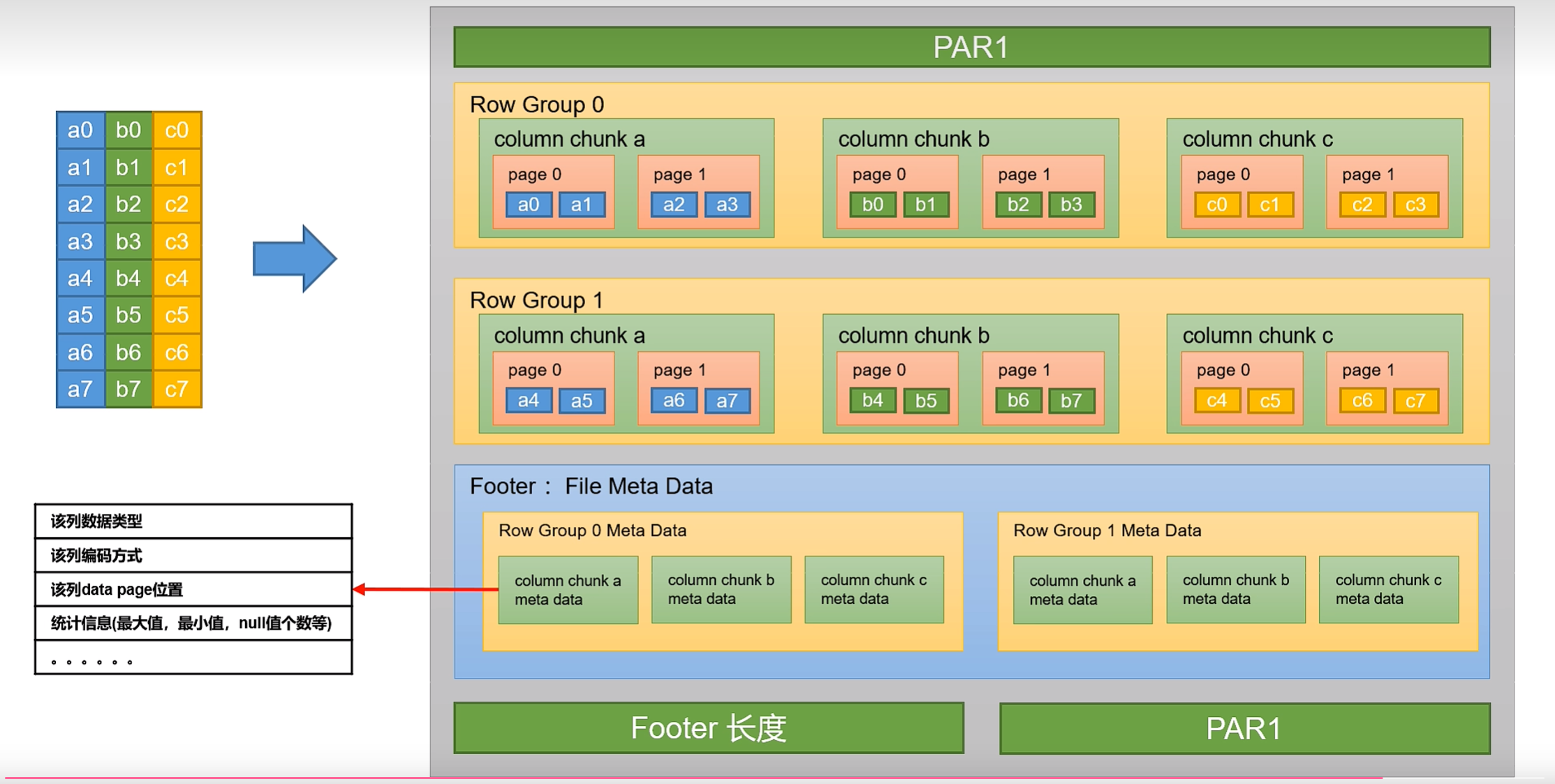
每个Orc 文件由 Header、Body 和 Tail 三部分组成。
其中Header内容为ORC,用于表示文件类型。
Body由1个或多个 stripe 组成,每个 stripe 一般为 HDFS 的块大小,每一个 stripe 包含多条记录,这些记录按照列进行独立存储,每个 stripe 里有三部分组成,分别是 index Data, Row Data,Stripe Footere。
index Data:一个轻量级的 index,默认是为各列每隔 1w 行做一个索引。每个索引会Index Data:记录第n万行的位置,和最近一万行的最大值和最小值等信息。
Row Data:存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream 来存储。
Stripe Footer:存放的是各个Stream 的位置以及各 column 的编码信息。
Tail 由File Footer PostScript 组成。File Footer 中保存了各 Stripe 的其实位置、索引长度、数据长度等信息,各 Column 的统计信息等;PostScript 记录了整个文件的压缩类型以及Fle Footer 的长度信息等。
在读取ORC 文件时,会先从最后一个字节读取 PostScript 长度,进而读取到 PostScript,从里面解析到 File Footer 长度,进而读取 FileFooter,从中解析到各个Stripe信息,再读各个stripe,即从后往前读。
建表语句
create table orc table
(column specs)
stored as orc
tblproperties (property_name=property value, ...) ;ORC文件格式支持的参数如下:
参数 | 默认值 | 说明 |
orc.compress | ZLIB | 压缩格式,可选项:NONE、ZLIB、SNAPPY |
orc.compress.size | 262,144 | 每个压缩快的大小(ORC文件是分块压缩的) |
orc.tripe.size | 67,108,864 | 每个stripe的大小 |
orc.row.index.stride | 10,000 | 索引步长(每隔多少行数据建一条索引) |
2.13 Parqust
Parquet 文件是 Hadoop 生态中的一个通用的文件格式,它也是一个列式存储的文件格式。
建表语句
create table parquet_table
(column specs)
stored as parcuet
tbproperties (property_name=propertu_value, ...);支持的参数如下:
参数 | 默认值 | 说明 |
parquet.compression | uncompressed | 压缩格式,可选项:uncompressed,snappy,gzip,lzo,brotli,lz4 |
parquet.block.size | 134217728 | 行组大小,通常与HDFS块大小保持一致 |
parquet.page.size | 1048576 | 页大小 |
2.2 压缩
在 Hive 表中和计算过程中,保持数据的压缩,对磁盘空间的有效利用和提高查询性能都是十分有益的。
2.2.1 hive表数据进行压缩
在 Hive 中,不同文什类型的表,声明数据压缩的方式是不同的。
TextFile
若一张表的文件类型为 TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive 在查询表中数据时,可自动识别其压缩格式,进行解压。
需要注意的是,在执行往表中导入数据的 SQL 语句时,用户需设置以下参数,来保证写入表中的数据是被压缩的。
——SQL语句的最终输出结果是否压缩
set hive.exec.compress.output=true;
——输出结果的压缩格式
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;ORC
若一张表的文件类型为 ORC,若需要对该表数据进行压缩,需在建表语句中声明压缩,格式如下:
create table orc table
(column specs)
stored as orc
tblproperties("orc.compress"="snappy");Parquet
若一张表的文件类型为 parquet,若需要对该表数据进行压缩,需在建表语句中声明压缩,格式如下:
create table orc table
(column specs)
stored as parquet
tblproperties("parquet.compress"="snappy");2.2.2 计算过程中使用压缩
单个MR的中间结果进行压缩
单个MR 的中间结果是指 Mapper 输出的数据,对其进行压缩可降低 shuffle 阶段的网络10,可通过以下参数进行配置:
——开启MapReduce中间数据压缩功能
set mapreduce.map.output.compress=true;——设置MapReduce中间数据的压缩方式
set mapreduce.map.output.codec=org.apache.hadoop.io.compress.SnappyCodec;单条SQL语句的中间结果进行压缩
单条 SQL 语句的中间结果是指,两个 MR(一条 SQL 语可能需要通过 MR 进行计算)之间的临时数据,可通过以下参数进行配置:
——是否对两个MR 之间的临时数据进行压缩
set hive.exec.compress .intermediate=true;
——压缩格式(以下示例为 snappy)
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;相关文章:
大数据技术之Hive(四)分区表和分桶表、文件格式和压缩
一、分区表和分桶表1.1 分区表partitionhive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择式选择查询所需要的分区,这样的查询效率辉提高很多。1.1.1 分区表基本语…...

环形缓冲区(c语言)
1、概念介绍 在我们需要处理大量数据的时候,不能存储所有的数据,只能先处理先来的,然后将这个数据释放,再去处理下一个数据。 如果在一个线性的缓冲区中,那些已经被处理的数据的内存就会被浪费掉。因为后面的数据只能…...
创建自助服务知识库的指南
在SaaS领域,自助文档是你可以在客户登录你的网站时为他们提供的最灵活的帮助方式,简单来说,一个自助知识库是一个可以帮助许多客户的文档,拥有出色的自助服务知识库,放在官网或者醒目的地方,借助自助服务知…...

分层测试(1)分层测试是什么?【必备】
1. 什么是分层测试? 分层测试是通过对质量问题分类、分层来保证整体系统质量的测试体系。 模块内通过接口测试保证模块质量,多模块之间通过集成测试保证通信路径和模块间交互质量,整体系统通过端到端用例对核心业务场景进行验证,…...

开源ZYNQ AD9361软件无线电平台
(1) XC7Z020-CLG400 (2) AD9363 (3) 单发单收,工作频率400MHz-2.7GHz (4) 发射带PA,最大输出功率约20dbm (5) 接收带LNA,低…...
第四阶段-12关于Spring Security框架,RBAC,密码加密原则
关于csmall-passport项目 此项目主要用于实现“管理员”账号的后台管理功能,主要实现: 管理员登录添加管理员删除管理员显示管理员列表启用 / 禁用管理员 关于RBAC RBAC:Role-Based Access Control,基于角色的访问控制 在涉及…...

JPA——Date拓展之Calendar
Java Calendar 是时间操作类,Calendar 抽象类定义了足够的方法,在某一特定的瞬间或日历上,提供年、月、日、小时之间的转换提供方法 一、获取具体时间信息 1. 当前时间 获取此刻时间的年月日时分秒 Calendar calendar Calendar.getInstance(); int …...

一文吃透 Spring 中的 AOP 编程
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
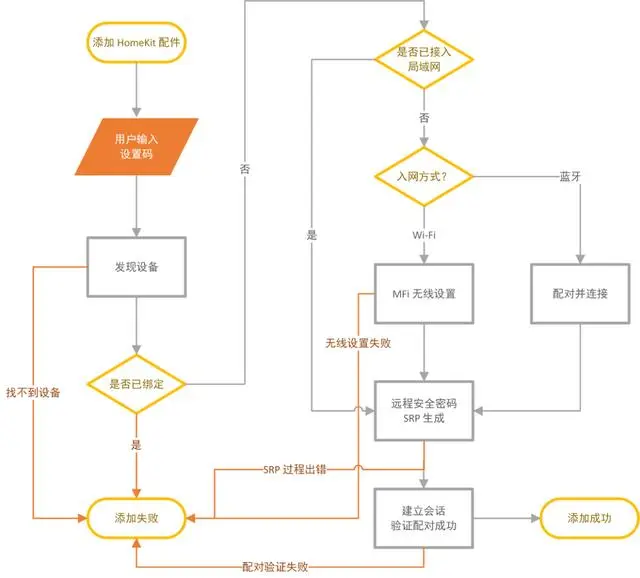
Apple主推的智能家居是什么、怎么用?一篇文章带你从零完全入门 HomeKit
如果你对智能家居有所了解,那应该或多或少听人聊起过 HomeKit。由 Apple 开发并主推的的 HomeKit 既因为产品选择少、价格高而难以成为主流,又因其独特的优秀体验和「出身名门」而成为智能家居领域的焦点。HomeKit 究竟是什么?能做什么&#…...

SpringCloud系列知识快速复习 -- part 1(SpringCloud基础知识,Docker,RabbitMQ)
SpringCloud知识快速复习SpringCloud基础知识微服务特点SpringCloud常用组件服务拆分和提供者与消费者概念Eureka注册中心原理Ribbon负载均衡原理负载均衡策略饥饿加载Nacos注册中心服务分级存储模型权重配置环境隔离Nacos与Eureka的区别Nacos配置管理拉取配置流程配置热更新配…...

2023上半年北京/上海/广州/深圳NPDP产品经理认证报名
产品经理国际资格认证NPDP是国际公认的唯一的新产品开发专业认证,集理论、方法与实践为一体的全方位的知识体系,为公司组织层级进行规划、决策、执行提供良好的方法体系支撑。 【认证机构】 产品开发与管理协会(PDMA)成立于1979年…...

面试半年,总结了1000道2023年Java架构师岗面试题
半年前还在迷茫该学什么,怎样才能走出现在的困境,半年后已经成功上岸阿里,感谢在这期间帮助我的每一个人。 面试中总结了1000道经典的Java面试题,里面包含面试要回答的知识重点,并且我根据知识类型进行了分类…...

通过MySQL驱动拦截器实现执行sql耗时计算
文章目录背景具体实现MySQL5MySQL6MySQL8使用方法测试结果背景 公司的一个需求,公司既有的链路追踪日志组件要支持MySQL的sql执行时间打印,要实现链路追踪常用的手段就是实现第三方框架或工具提供的拦截器接口或者是过滤器接口,对于MySQL也不…...

易基因|独家分享:高通量测序后的下游实验验证方法——DNA甲基化篇
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。此前,我们分享了DNA甲基化研究的测序数据挖掘思路(点击查看详情),进而鉴定出研究的目的基因或目标区域的DNA甲基化。做完测序后,…...
 同步和异步理解)
java基础系列(七) 同步和异步理解
一. 问题描述 同步传输和异步传输是web和数据库的重要知识点,会被很多老师强调。那么,它们有什么相同点和不同点?它们对于我们学习编程的意义在哪里? 二. 概念 首先什么是同步和异步? 这里的同步是指&…...

吉林大学 程序设计基础 2022级 OJ期末考试 2.23
本人能力有限,发出只为帮助有需要的人。 以下为实验课的复盘,内容会有大量失真,请多多包涵。 1.双手剑士的最优搭配 每把剑有攻击力和防御力两个属性。双手剑士可以同时拿两把剑,其得到攻击力为两把剑中的攻击力的最大值&#…...

【项目实战】SpringMVC拦截器实战 - 自定义拦截器防止重复提交
一、背景说明 如何能够实现防止重复提交呢?以下是一种可选的方式。 二、代码实战 2.1 注册重复提交拦截器到SpringMVC中 @Configuration @AllArgsConstructor public class ResourcesConfig implements WebMvcConfigurer {private final RepeatSubmitInterceptor repeatSu…...

C++ STL:容器 Container
文章目录1、序列容器1.1、容器共性1.2、vectorvector 结构* vector 扩容原理* vector 迭代器失效1.3、dequedeque 结构deque 迭代器deque 模拟连续空间1.4、listlist 特殊操作list 结构list 迭代器2、关联式容器2.1、容器共性2.2、容器特性3、无序关联式容器3.1、容器共性3.2、…...
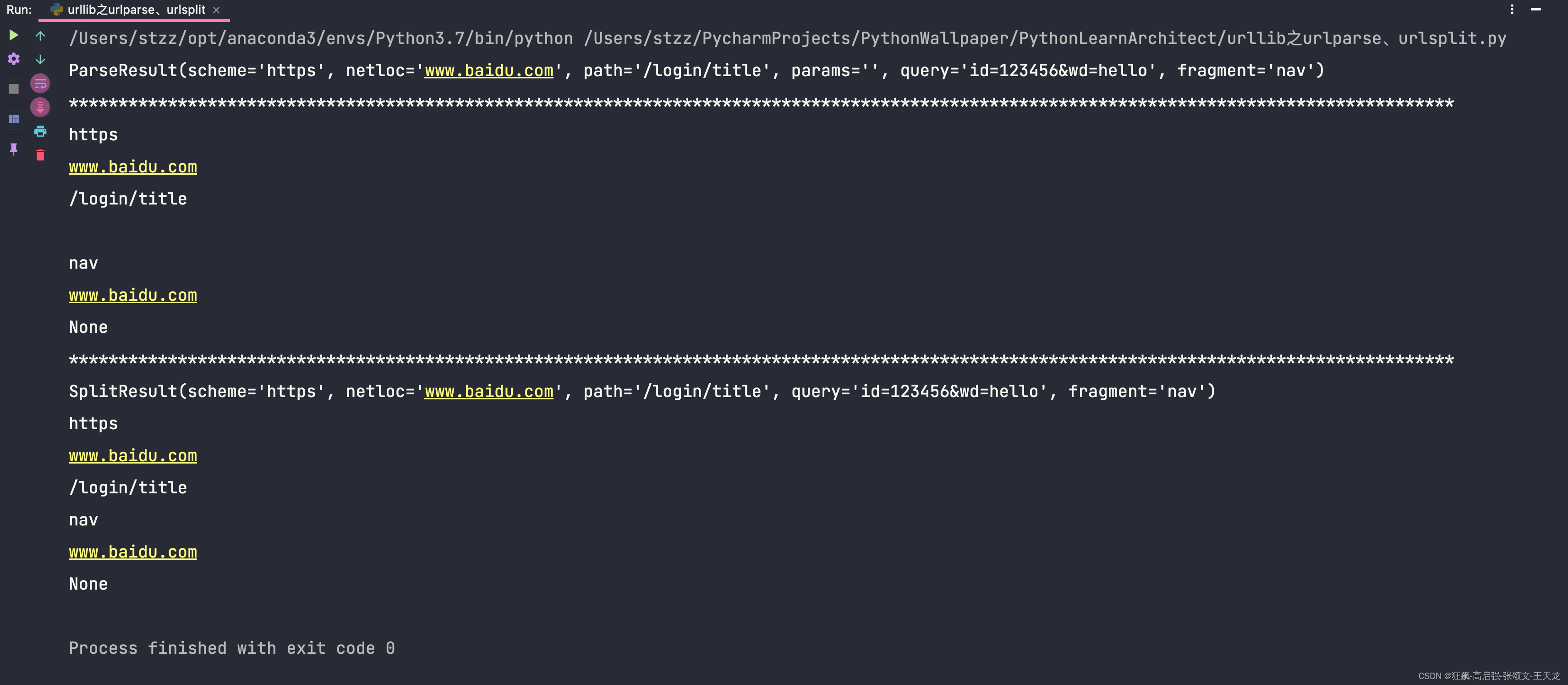
urllib之urlopen和urlretrieve的headers传入以及parse、urlparse、urlsplit的使用
urllib库是什么?urllib库python的一个最基本的网络请求库,不需要安装任何依赖库就可以导入使用。它可以模拟浏览器想目标服务器发起请求,并可以保存服务器返回的数据。urllib库的使用:1、request.urlopen(1)只能传入url的方式from http.clie…...
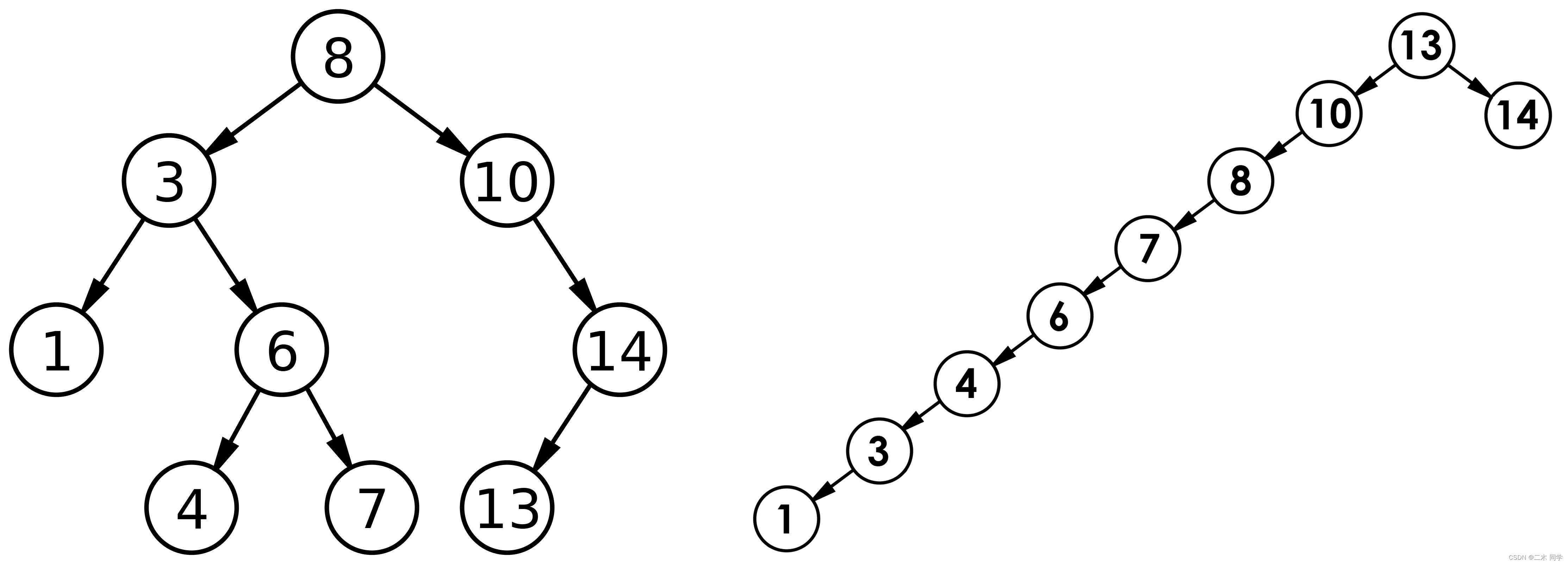
【C++】二叉搜索树的模拟实现
一、概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根节点的值它的左右子树也分别…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...
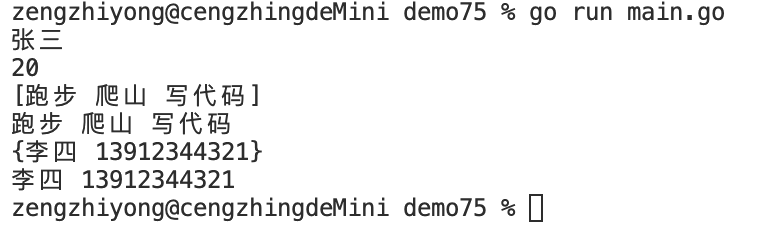
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

0x-3-Oracle 23 ai-sqlcl 25.1 集成安装-配置和优化
是不是受够了安装了oracle database之后sqlplus的简陋,无法删除无法上下翻页的苦恼。 可以安装readline和rlwrap插件的话,配置.bahs_profile后也能解决上下翻页这些,但是很多生产环境无法安装rpm包。 oracle提供了sqlcl免费许可,…...