SpringCloud系列知识快速复习 -- part 1(SpringCloud基础知识,Docker,RabbitMQ)
SpringCloud知识快速复习
- SpringCloud基础知识
- 微服务特点
- SpringCloud常用组件
- 服务拆分和提供者与消费者概念
- Eureka注册中心
- 原理
- Ribbon负载均衡
- 原理
- 负载均衡策略
- 饥饿加载
- Nacos注册中心
- 服务分级存储模型
- 权重配置
- 环境隔离
- Nacos与Eureka的区别
- Nacos配置管理
- 拉取配置流程
- 配置热更新
- 配置共享
- 配置共享的优先级
- Feign远程调用
- 使用Feign的步骤
- Feign使用优化
- 最佳实践
- Gateway服务网关
- 核心功能特性
- 分类
- 网关搭建步骤
- 断言
- 过滤器
- defaultFilters的作用是什么?
- 全局过滤器
- 过滤器执行顺序
- 跨域问题
- Docker
- Docker是什么
- Docker和虚拟机的差异
- Docker架构
- 镜像和容器
- DockerHub
- Docker架构
- Docker的基本操作
- 镜像操作
- 容器操作
- 数据卷
- Dockerfile自定义镜像
- Docker-Compose
- RabbitMQ
- 异步和同步通讯
- 技术对比
- MQ的基本结构
- RabbitMQ消息模型
- 发送接收流程
- SpringAMQP
- 消息转换器
- 消息可靠性
- 生产者消息确认
- 消息持久化
- 消费者消息确认
- 消费失败重试机制
- 如何确保RabbitMQ消息的可靠性?
- 死信交换机
- TTL
- 延迟队列
- 惰性队列
- 消息堆积问题
- 惰性队列的特征
SpringCloud基础知识
微服务特点
-
单体架构:简单方便,高度耦合,扩展性差,适合小型项目。例如:学生管理系统
-
分布式架构:松耦合,扩展性好,但架构复杂,难度大。适合大型互联网项目,例如:京东、淘宝
-
微服务:一种良好的分布式架构方案
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责
- 自治:团队独立、技术独立、数据独立,独立部署和交付
- 面向服务:服务提供统一标准的接口,与语言和技术无关
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
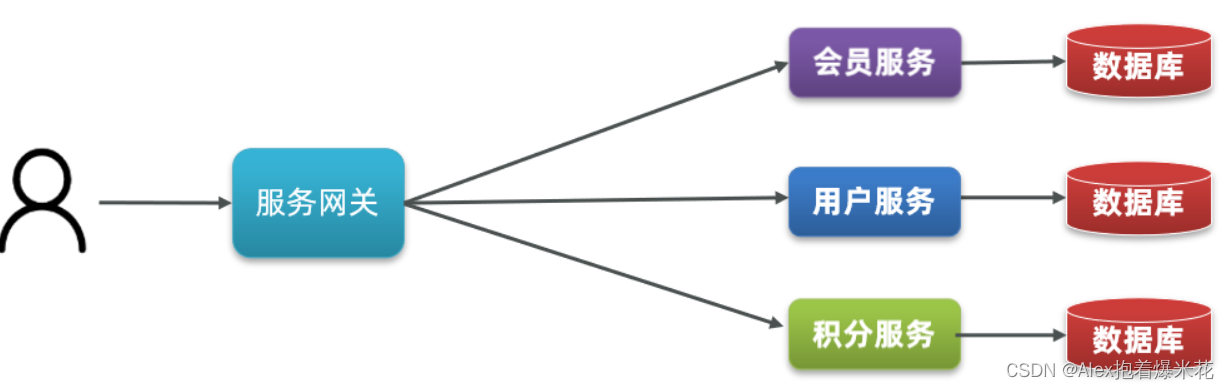
SpringCloud常用组件
- 服务注册发现
Eureka、Nacos、Consul - 服务远程调用
OpenFeign、Dubbo - 统一配置管理
SpringCloudConfig、Nacos - 统一网关路由
- SpringCloudGateway、Zuul
- 流控、降级、保护
Hystix、Sentinel - 服务链路监控
Zipkin、Sleuth
服务拆分和提供者与消费者概念
- 不同微服务,不要重复开发相同业务
- 微服务数据独立,不要访问其它微服务的数据库
- 微服务可以将自己的业务暴露为接口,供其它微服务调用
提供者与消费者
在服务调用关系中,会有两个不同的角色:
服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)
但是,服务提供者与服务消费者的角色并不是绝对的,而是相对于业务而言。
如果服务A调用了服务B,而服务B又调用了服务C,服务B的角色是什么?
- 对于A调用B的业务而言:A是服务消费者,B是服务提供者
- 对于B调用C的业务而言:B是服务消费者,C是服务提供者
因此,服务B既可以是服务提供者,也可以是服务消费者。
Eureka注册中心
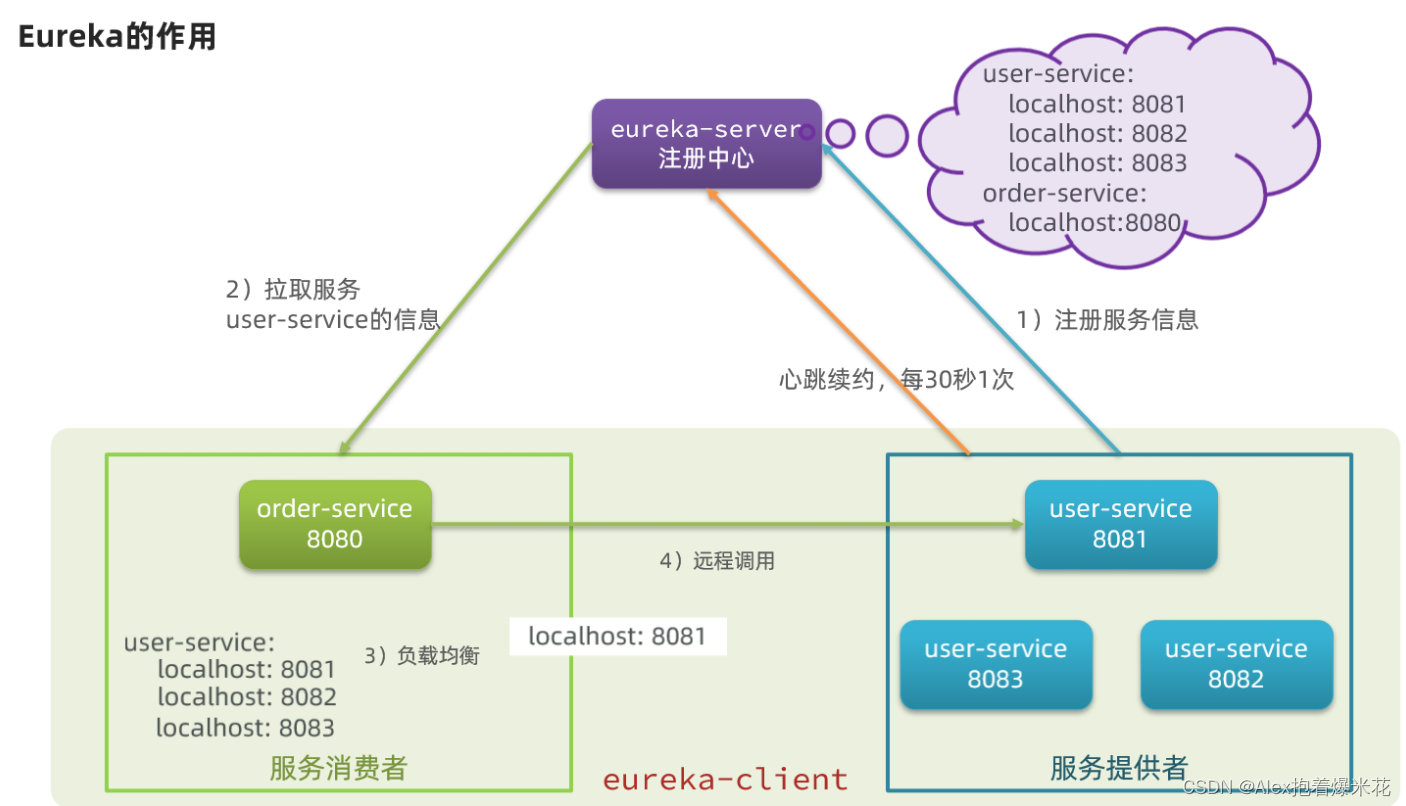
原理
- order-service得知user-service实例地址
- user-service服务实例启动后,将自己的信息注册到
eureka-server(Eureka服务端)。这个叫服务注册 - eureka-server保存服务名称到服务实例地址列表的映射关系
- order-service根据服务名称,拉取实例地址列表。这个叫
服务发现或服务拉取
- order-service从多个user-service实例中选择具体的实例
- order-service从实例列表中利用
负载均衡算法选中一个实例地址 - 向该实例地址发起远程调用
- order-service得知某个user-service实例并持续检测健康或已经宕机
- user-service会每隔一段时间(默认30秒)向eureka-server发起请求,报告自己状态,称为心跳
- 当超过一定时间没有发送心跳时,eureka-server会认为微服务实例故障,将该实例从服务列表中剔除
- order-service拉取服务时,就能将故障实例排除了
Ribbon负载均衡
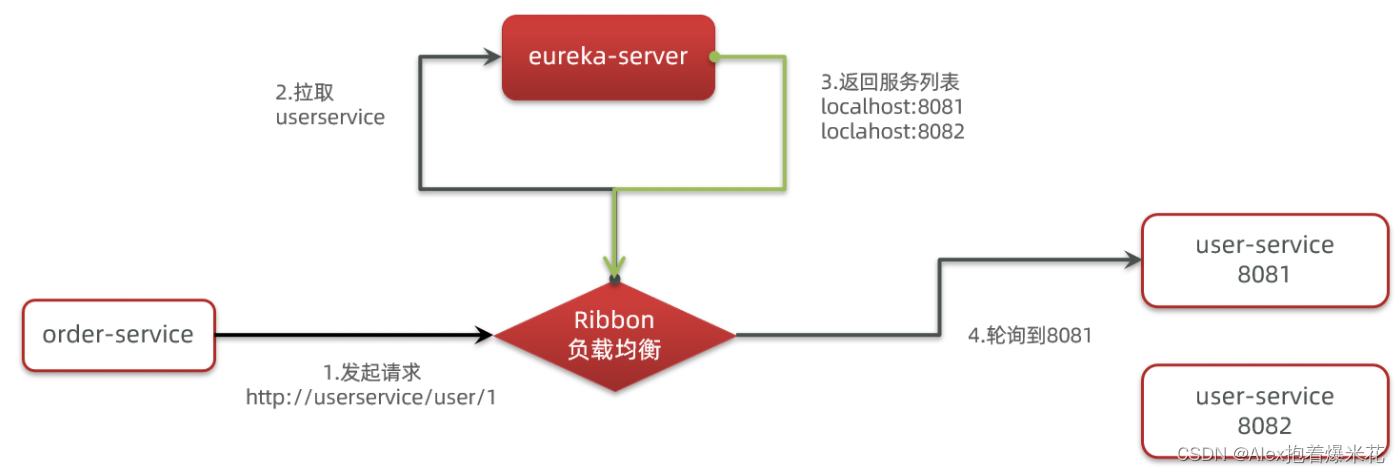
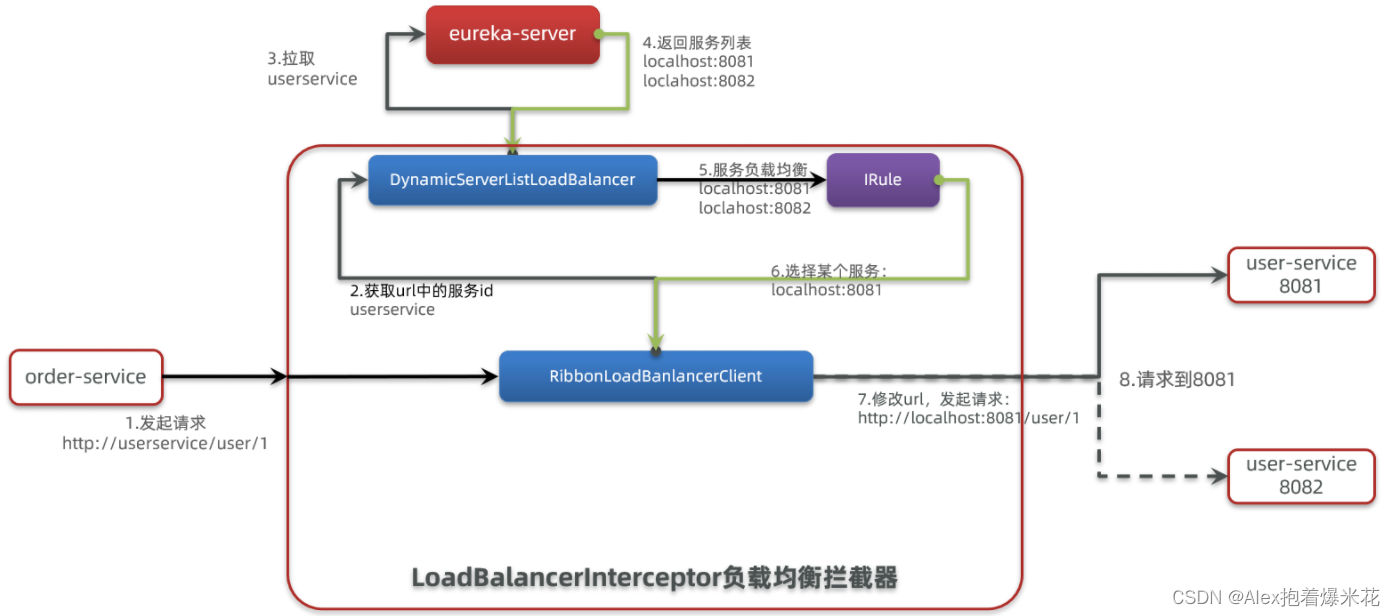
原理
底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改
- 拦截我们的RestTemplate请求http://userservice/user/1
- RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
- DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
- eureka返回列表,localhost:8081、localhost:8082
- IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
- RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求
负载均衡策略
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:eager-load:enabled: trueclients: userservice
Nacos注册中心
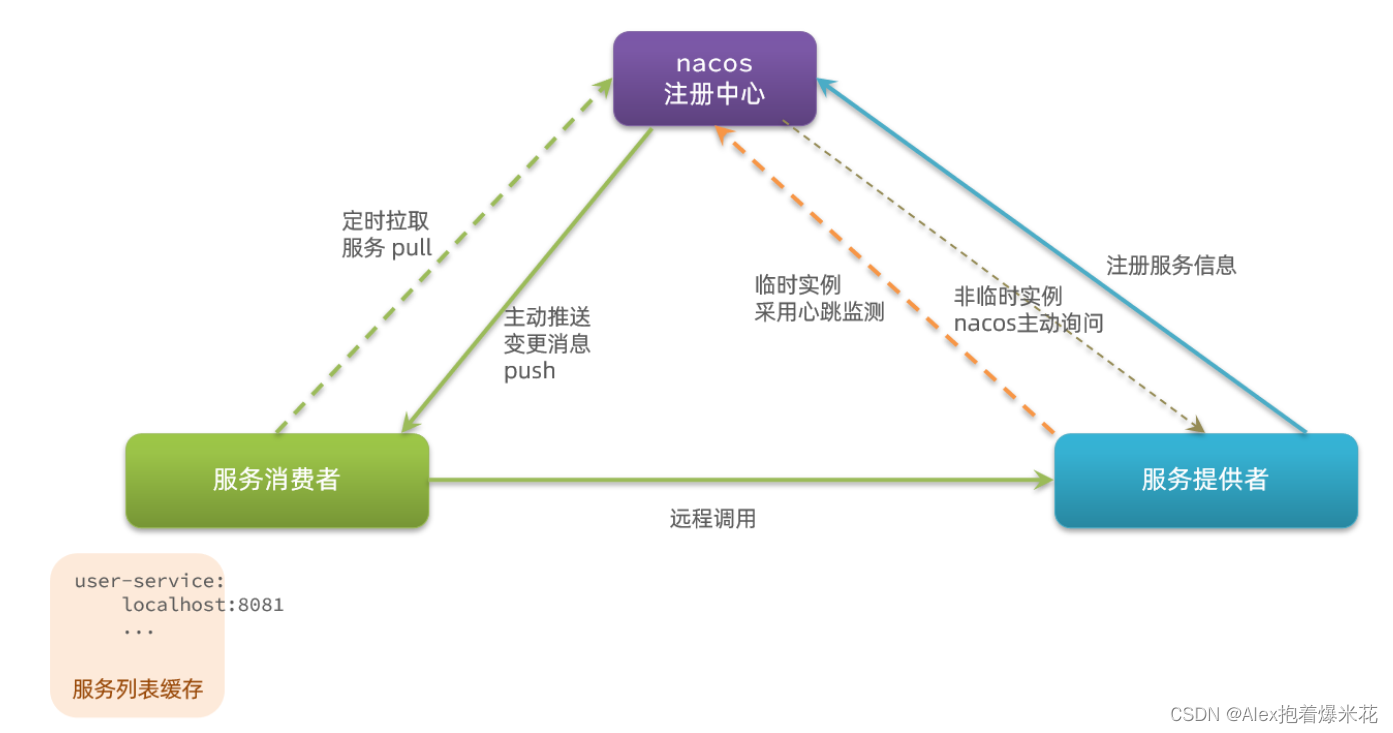
Nacos的服务实例分为两种类型:
-
临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认的类型。
-
非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
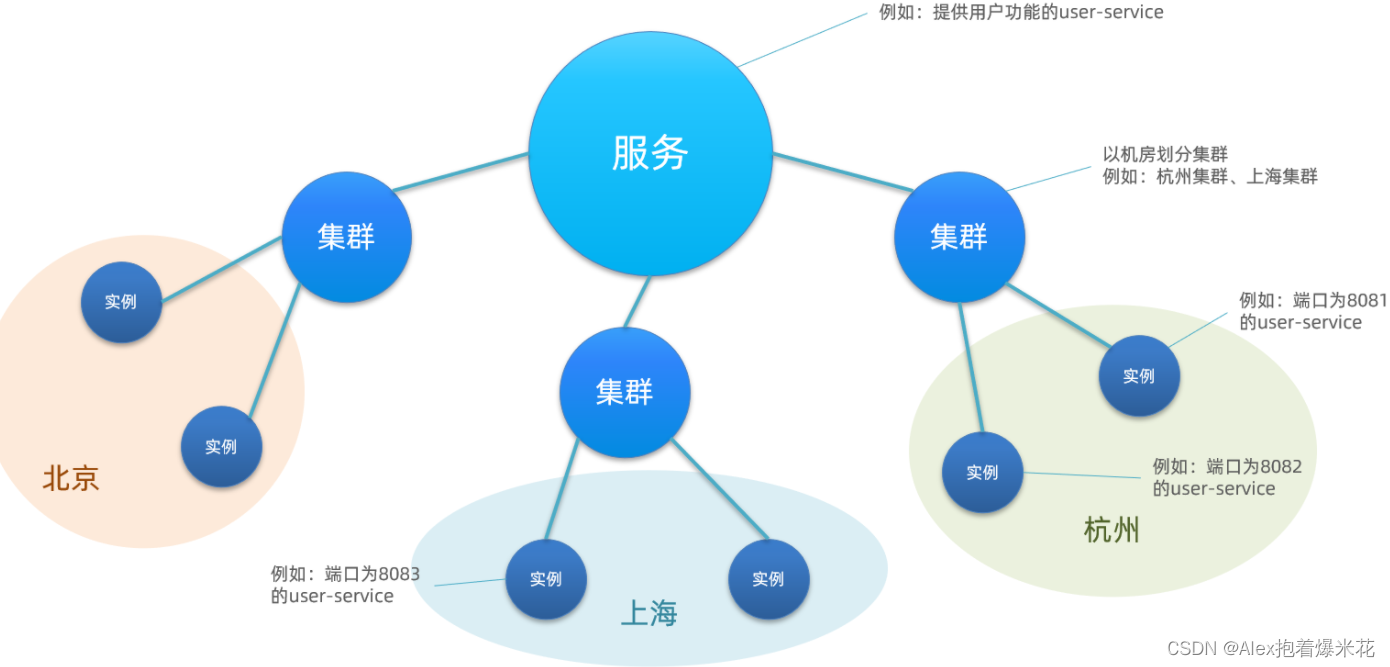
服务分级存储模型
一个服务可以有多个实例,同一机房内的实例 划分为一个集群
权重配置
注意:如果权重修改为0,则该实例永远不会被访问
环境隔离
Nacos提供了namespace来实现环境隔离功能。
- nacos中可以有多个
namespace - namespace下可以有
group、service等 - 不同namespace之间相互隔离,例如不同namespace的服务互相不可见
Nacos与Eureka的区别
-
Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
-
Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Nacos配置管理
Nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。
注意:项目的核心配置,需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。
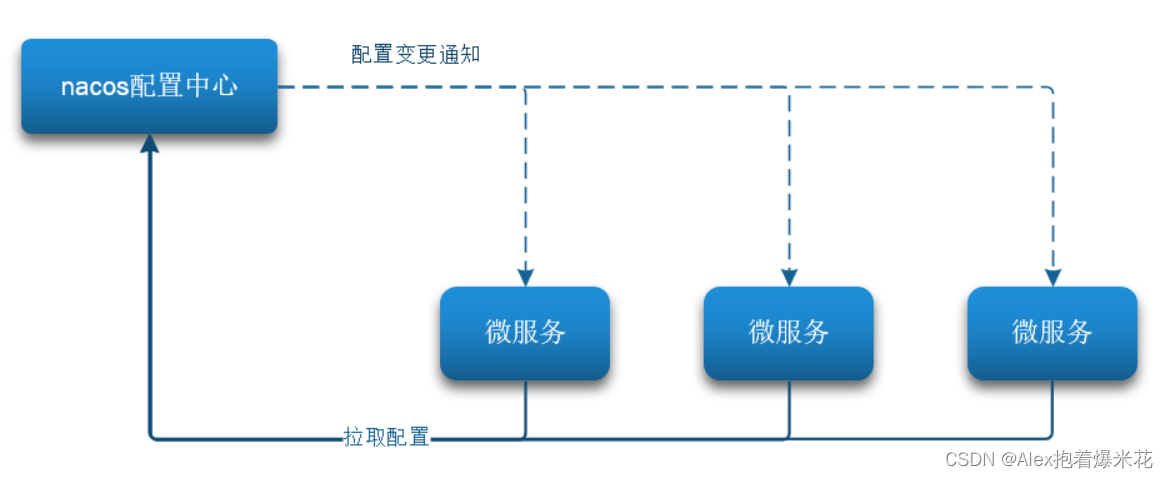
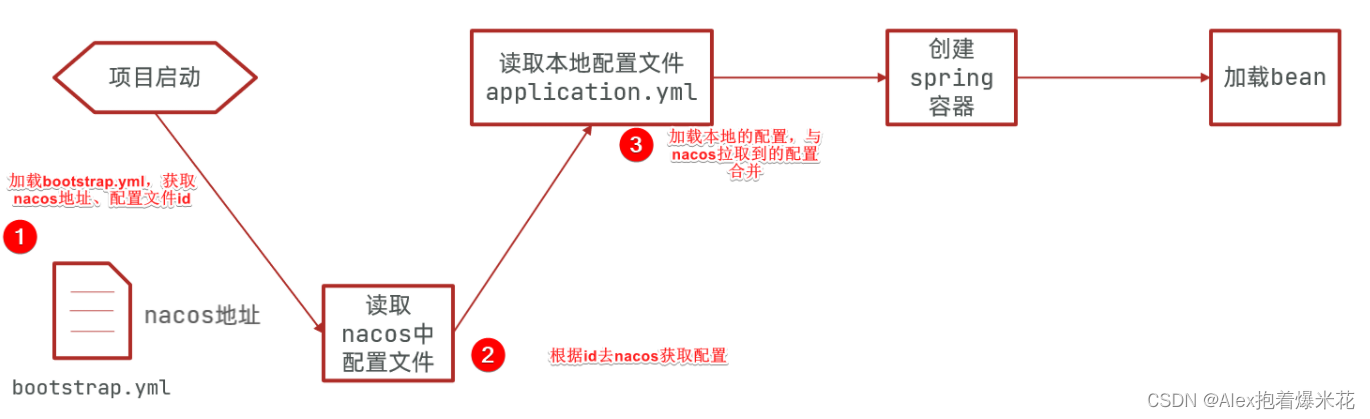
拉取配置流程
配置信息:[服务名称]-[profile].[后缀名] + 分组 + 配置格式
配置热更新
要实现配置热更新,可以使用两种方式:
- 在@Value注入的变量所在
类上添加注解@RefreshScope - 使用@ConfigurationProperties注解代替@Value注解。
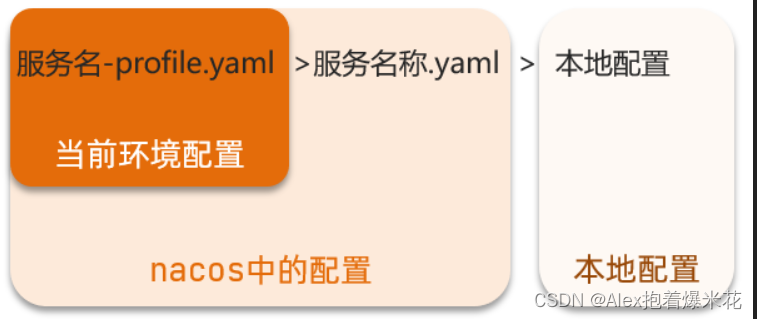
配置共享
其实微服务启动时,会去nacos读取多个配置文件,例如:
-
[服务名称]-[profile].[后缀名],例如:userservice-dev.yaml -
[服务名称].[后缀名],例如:userservice.yaml
而[服务名称].[后缀名]不包含环境,因此可以被多个环境共享。
配置共享的优先级
Feign远程调用
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:
•URLConnection:默认实现,不支持连接池
•Apache HttpClient :支持连接池
•OKHttp:支持连接池
Feign的客户端基于SpringMVC的注解来声明远程调用的信息,比如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
使用Feign的步骤
- 引入依赖
- 添加@EnableFeignClients注解
- 编写FeignClient接口
- 使用FeignClient中定义的方法代替RestTemplate
- 继承FallbackFactory接口编写熔断
Feign使用优化
提高Feign的性能主要手段就是使用连接池代替默认的URLConnection(不支持连接池)
- 日志级别尽量用basic
- 使用HttpClient或OKHttp代替URLConnection
① 引入feign-httpClient依赖
② 配置文件开启httpClient功能,设置连接池参数
最佳实践
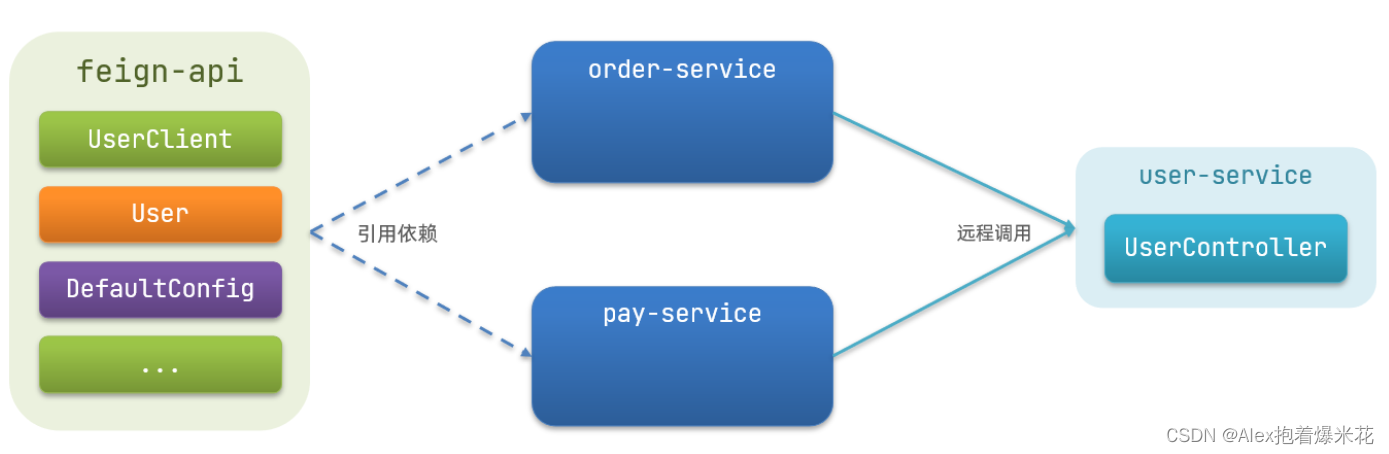
抽取的方式
将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用。
例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。
Gateway服务网关
核心功能特性
-
权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
-
路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。
-
限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。
分类
在SpringCloud中网关的实现包括两种:
- gateway
- zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
网关搭建步骤
-
创建项目,引入nacos服务发现和gateway依赖
-
配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
-
路由id:路由的唯一标示
-
路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
-
路由断言(predicates):判断路由的规则,
-
路由过滤器(filters):对请求或响应做处理
断言
判断请求是否符合某种规则的条件
server:port: 10010 # 网关端口
spring:application:name: gateway # 服务名称cloud:nacos:server-addr: localhost:8848 # nacos地址gateway:routes: # 网关路由配置- id: user-service # 路由id,自定义,只要唯一即可# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称predicates: # 路由断言,也就是判断请求是否符合路由规则的条件- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
过滤器
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理
过滤器的作用是什么?
① 对路由的请求或响应做加工处理,比如添加请求头
② 配置在路由下的过滤器只对当前路由的请求生效
Spring提供了31种不同的路由过滤器工厂。例如:
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
defaultFilters的作用是什么?
对所有路由都生效的过滤器
全局过滤器
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
如:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
-
参数中是否有authorization,
-
authorization参数值是否为admin
如果同时满足则放行,否则拦截
过滤器执行顺序
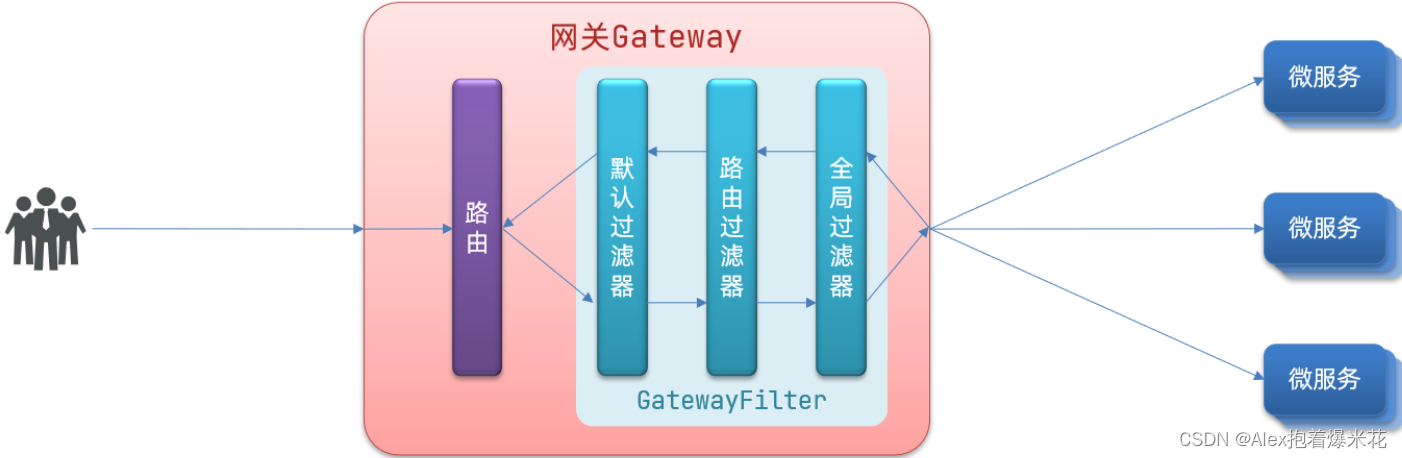
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
排序的规则
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
跨域问题
跨域:IP和端口其中一个不一致就是跨域,主要包括:
-
IP不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
-
IP相同,端口不同:localhost:8080和localhost:8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS
gateway中解决
在gateway服务的application.yml文件中,添加下面的配置:
spring:cloud:gateway:# 。。。globalcors: # 全局的跨域处理add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题corsConfigurations:'[/**]':allowedOrigins: # 允许哪些网站的跨域请求 - "http://localhost:8090"allowedMethods: # 允许的跨域ajax的请求方式- "GET"- "POST"- "DELETE"- "PUT"- "OPTIONS"allowedHeaders: "*" # 允许在请求中携带的头信息allowCredentials: true # 是否允许携带cookiemaxAge: 360000 # 这次跨域检测的有效期
Docker
Docker是什么
Docker解决大型项目依赖关系复杂,不同组件依赖的兼容性问题
- Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
- Docker应用运行在容器中,使用沙箱机制,相互隔离
Docker解决开发、测试、生产环境有差异的问题
- Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker是一个快速交付应用、运行应用的技术,具备下列优势:
- 可以将程序及其依赖、运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统
- 运行时利用沙箱机制形成隔离容器,各个应用互不干扰
- 启动、移除都可以通过一行命令完成,方便快捷
Docker和虚拟机的差异
-
docker是一个系统进程;虚拟机是在操作系统中的操作系统
-
docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
Docker架构
镜像和容器
镜像,就是把一个应用在硬盘上的文件、及其运行环境、部分系统函数库文件一起打包形成的文件包。这个文件包是只读的。
容器呢,就是将这些文件中编写的程序、函数加载到内存中允许,形成进程,只不过要隔离起来。因此一个镜像可以启动多次,形成多个容器进程
DockerHub
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry
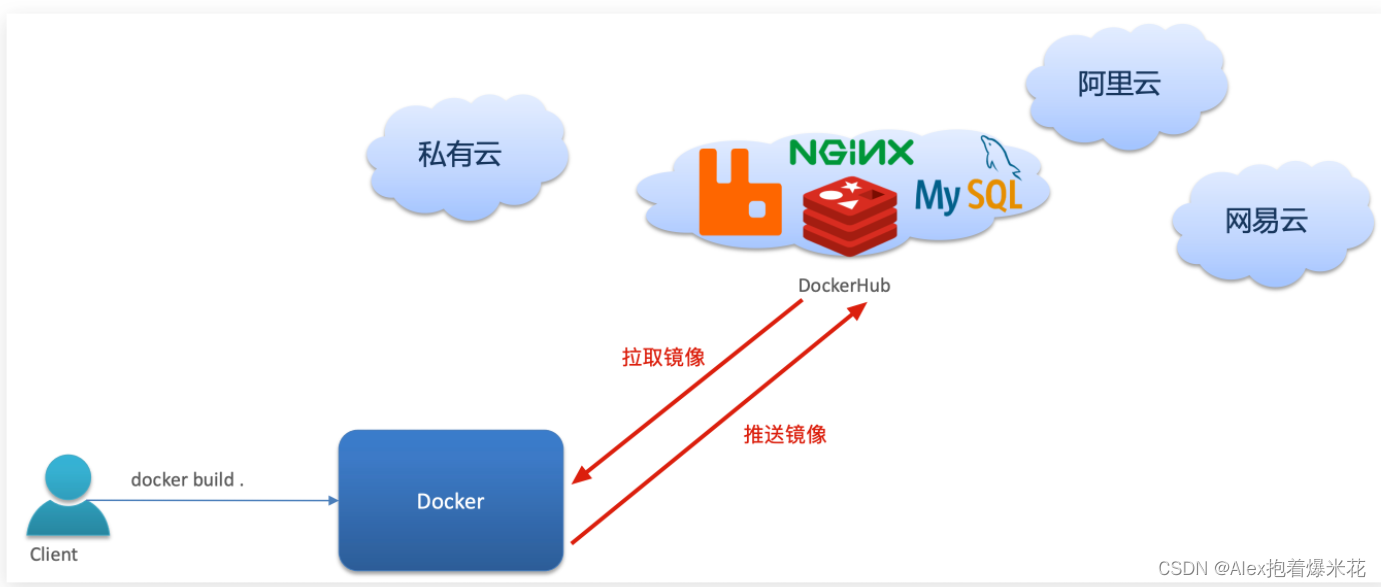
Docker架构
Docker是一个CS架构的程序,由两部分组成:
-
服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等。
接收命令或远程请求,操作镜像或容器 -
客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令。
发送命令或者请求到Docker服务端
Docker的基本操作
镜像操作
镜名称一般分两部分组成:[repository]:[tag]
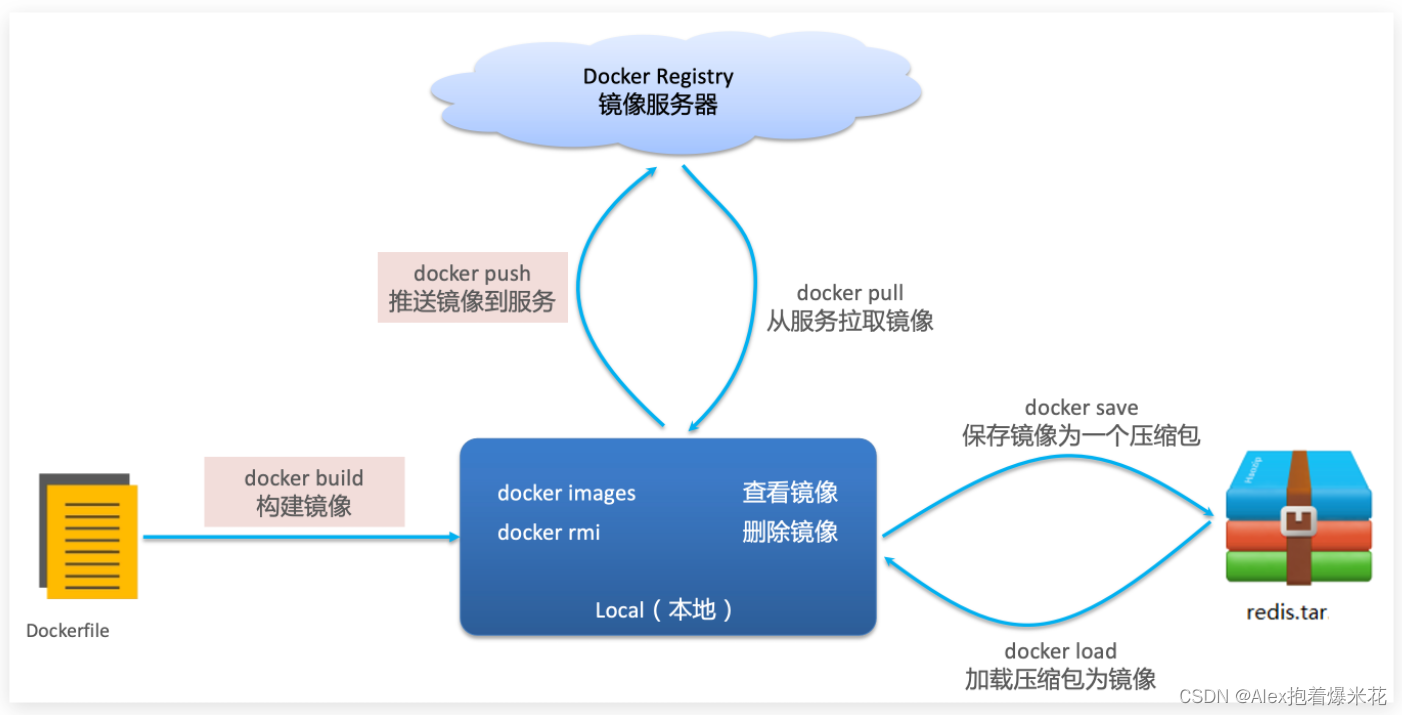
- docker pull:从服务拉取镜像
- docker push:推送镜像到服务
- docker build:构建镜像
- docker save:保存镜像为一个压缩包
- docker load:加载压缩包为镜像
- docker images:查看镜像
- docker rmi:删除镜像
容器操作
容器保护三个状态:
- 运行:进程正常运行
- 暂停:进程暂停,CPU不再运行,并不释放内存
- 停止:进程终止,回收进程占用的内存、CPU等资源
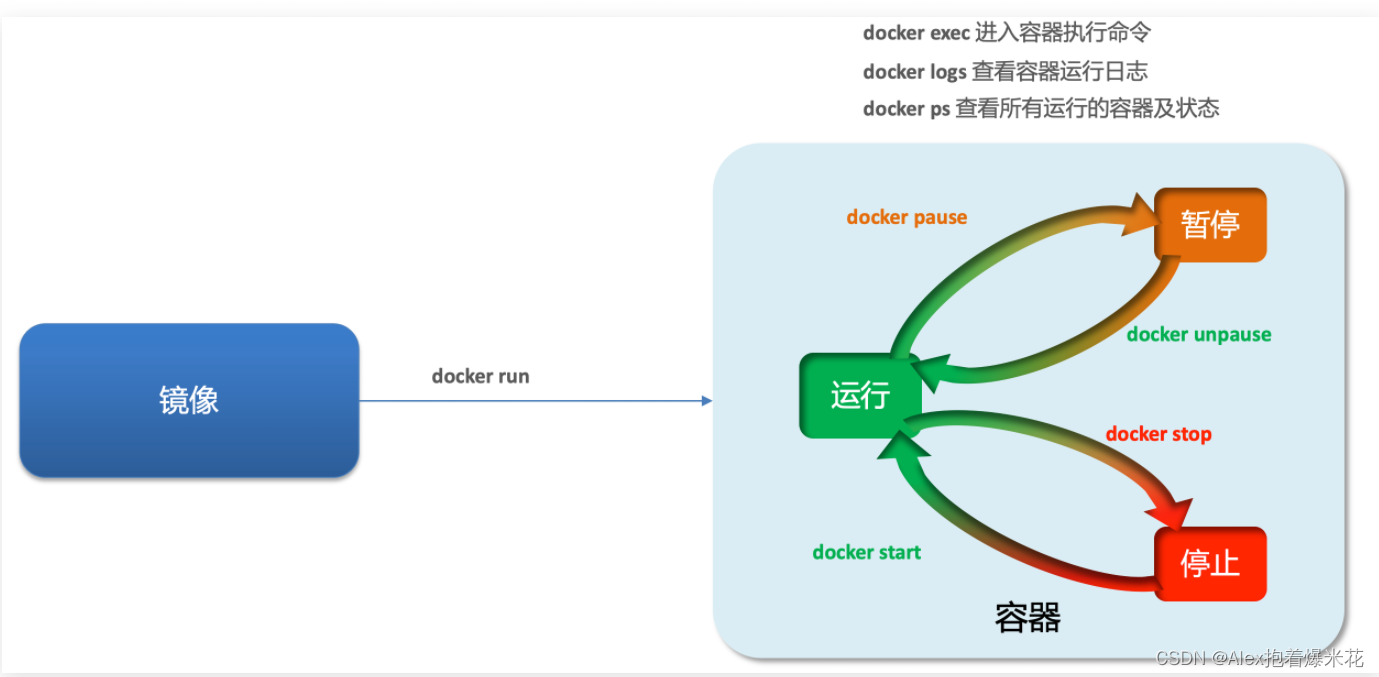
- docker run:创建并运行一个容器,处于运行状态
- docker pause:让一个运行的容器暂停
- docker unpause:让一个容器从暂停状态恢复运行
- docker stop:停止一个运行的容器
- docker start:让一个停止的容器再次运行
- docker rm:删除一个容器
- docker exec -it [name] bash:进入容器
docker run命令的常见参数有哪些?
- –name:指定容器名称
- -p:指定端口映射
- -d:让容器后台运行
查看容器日志的命令:
- docker logs
- 添加 -f 参数可以持续查看日志
查看容器状态:
- docker ps
- docker ps -a 查看所有容器,包括已经停止的
数据卷
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。
一旦完成数据卷挂载,对容器的一切操作都会作用在数据卷对应的宿主机目录了。
操作宿主机的/var/lib/docker/volumes/html目录,就等于操作容器内的/usr/share/nginx/html目录了
docker run的命令中通过 -v 参数挂载文件或目录到容器中:
- -v volume名称:容器内目录
- -v 宿主机文件:容器内文
- -v 宿主机目录:容器内目录
数据卷挂载与目录直接挂载的
- 数据卷挂载耦合度低,由docker来管理目录,但是目录较深,不好找
- 目录挂载耦合度高,需要我们自己管理目录,不过目录容易寻找查看
Dockerfile自定义镜像
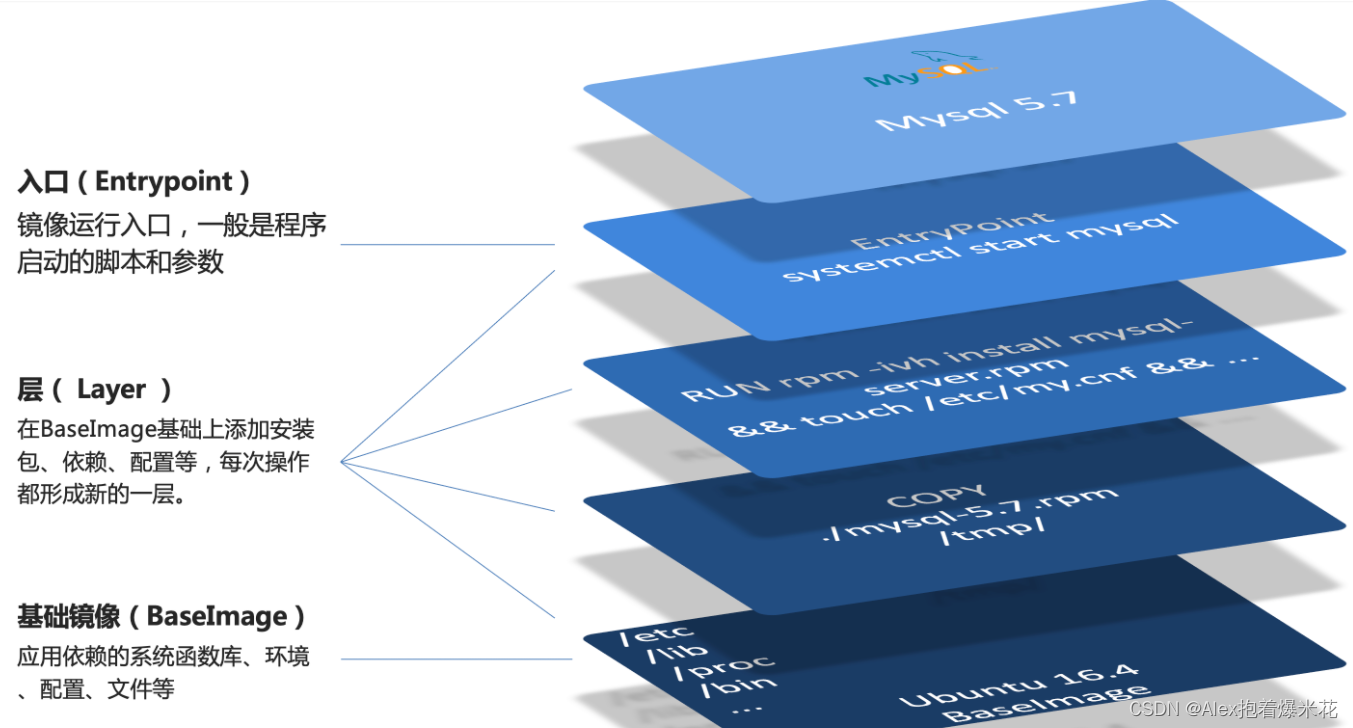
镜像就是在系统函数库、运行环境基础上,添加应用程序文件、配置文件、依赖文件等组合,然后编写好启动脚本打包在一起形成的文件
-
Dockerfile的本质是一个文件,通过指令描述镜像的构建过程
-
Dockerfile的第一行必须是FROM,从一个基础镜像来构建
-
基础镜像可以是基本操作系统,如Ubuntu。也可以是其他人制作好的镜像,例如:java:8-alpine
Docker-Compose
Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器!
RabbitMQ
异步和同步通讯
Fegin属于同步通讯
同步调用的优点:
- 时效性较强,可以立即得到结果
同步调用的问题:
- 耦合度高
- 性能和吞吐能力下降
- 有额外的资源消耗
- 有级联失败问题
RabbitMQ属于异步通讯
为了解除事件发布者与订阅者之间的耦合,两者并不是直接通信,而是有一个中间人(Broker)。发布者发布事件到Broker,不关心谁来订阅事件。订阅者从Broker订阅事件,不关心谁发来的消息。
异步好处:
- 吞吐量提升:无需等待订阅者处理完成,响应更快速
- 故障隔离:服务没有直接调用,不存在级联失败问题
- 调用间没有阻塞,不会造成无效的资源占用
- 耦合度极低,每个服务都可以灵活插拔,可替换
- 流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件
异步缺点:
- 架构复杂了,业务没有明显的流程线,不好管理
- 需要依赖于Broker的可靠、安全、性能
技术对比
MQ,中文是消息队列(MessageQueue),字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。
比较常见的MQ实现:
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
MQ的基本结构
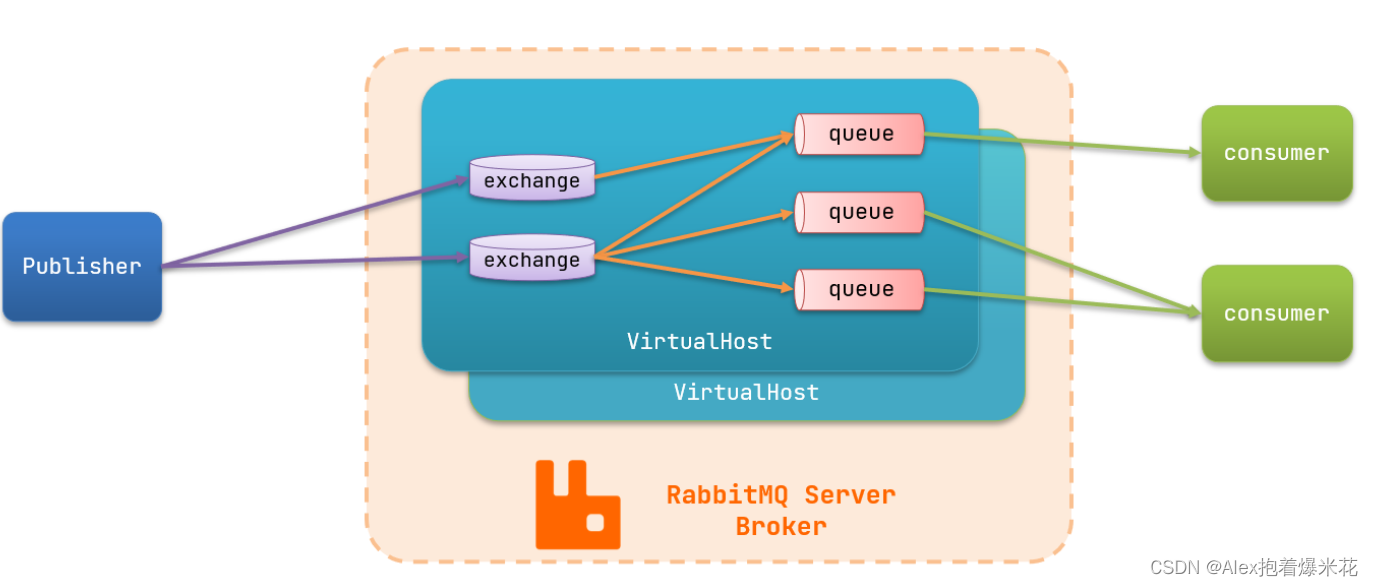
RabbitMQ中的一些角色:
- publisher:生产者
- consumer:消费者
- exchange个:交换机,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
RabbitMQ消息模型
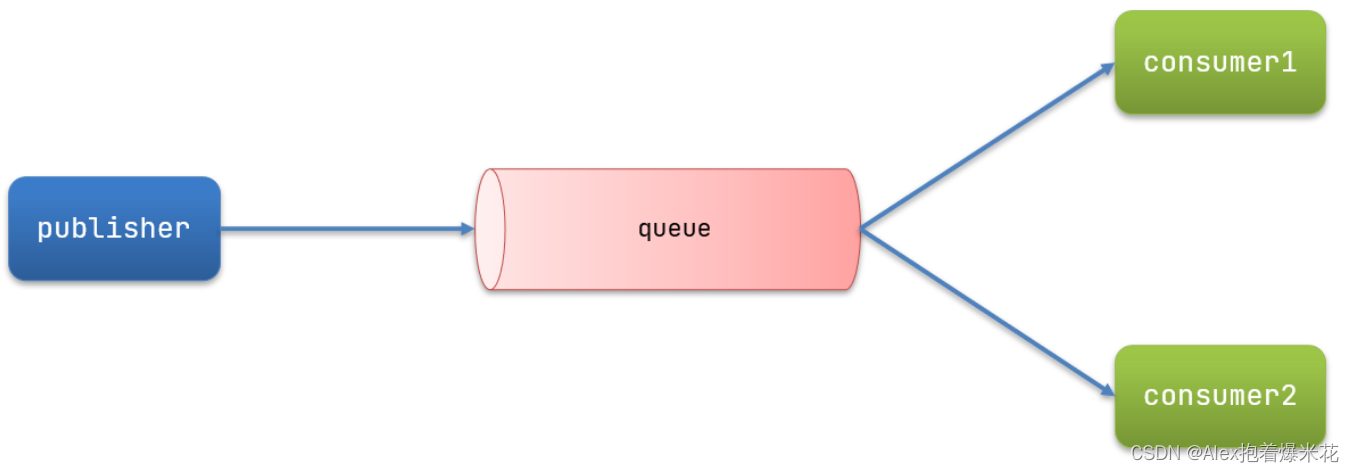
-
Basic Queue 简单队列模型
-
WorkQueue 简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息
-
发布/订阅
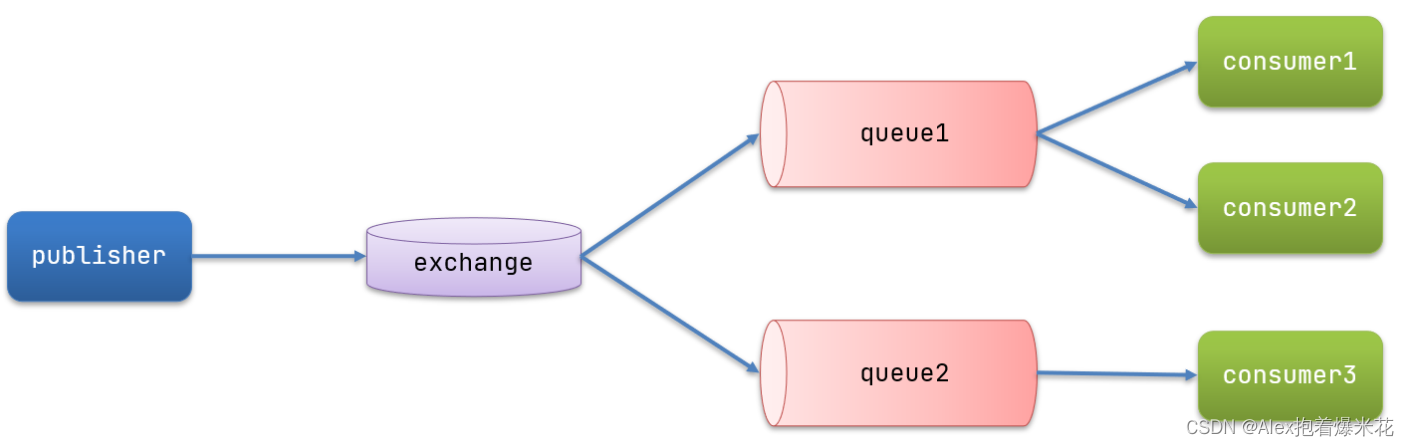
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
- Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
- Consumer:消费者,与以前一样,订阅队列,没有变化
- Queue:消息队列也与以前一样,接收消息、缓存消息
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
发送接收流程
基本消息队列的消息发送流程:
-
建立connection
-
创建channel
-
利用channel声明队列
-
利用channel向队列发送消息
基本消息队列的消息接收流程:
-
建立connection
-
创建channel
-
利用channel声明队列
-
定义consumer的消费行为handleDelivery()
-
利用channel将消费者与队列绑定
SpringAMQP
SpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么?
- Queue
- FanoutExchange
- Binding
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
- @Queue
- @Exchange
描述下Direct交换机与Topic交换机的差异?
- Topic交换机接收的消息RoutingKey必须是多个单词,以
**.**分割 - Topic交换机与队列绑定时的bindingKey可以指定通配符
#:代表0个或多个词*:代表1个词
消息转换器
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>2.9.10</version>
</dependency>
配置消息转换器。
在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){return new Jackson2JsonMessageConverter();
}
消息可靠性
消息从发送,到消费者接收,会经理多个过程:
其中的每一步都可能导致消息丢失,常见的丢失原因包括:
- 发送时丢失:
- 生产者发送的消息未送达exchange
- 消息到达exchange后未到达queue
- MQ宕机,queue将消息丢失
- consumer接收到消息后未消费就宕机
针对这些问题,RabbitMQ分别给出了解决方案:
- 生产者确认机制
- mq持久化
- 失败重试机制
- 消费者确认机制
生产者消息确认
RabbitMQ提供了publisher confirm机制来判断消息发送到MQ过程中是否丢失。这种机制必须给每个消息指定一个唯一ID。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。
返回结果有两种方式:
- publisher-comfirm:
- 消息成功发送到exchange,返回ack
- 消息发送失败,没有到达交换机,返回nack
- 消息发送过程中出现异常,没有收到回执
- publisher-return:
- 消息成功发送到exchange,但没有路由到queue,调用ReturnCallback

- 消息成功发送到exchange,但没有路由到queue,调用ReturnCallback
Publisher Confirms(发布者确认):当生产者(Publisher)发送消息(Message)到RabbitMQ时,它可能会丢失或未被传递到队列(Queue)中。为了确保消息已被正确处理,RabbitMQ提供了Publisher Confirms机制。该机制会向生产者发送确认消息,以指示消息已被正确处理并已进入队列。如果消息未被正确处理,则生产者可以在收到确认消息之后执行操作,例如重新发送消息或记录日志等。
Publisher Returns(发布者返回):在某些情况下,生产者发送的消息无法到达目标队列(Queue)。这可能是由于队列不存在、队列已满或消息被拒绝等原因。在这种情况下,RabbitMQ提供了Publisher Returns机制,允许生产者在消息无法到达目标队列时收到通知。在启用Publisher Returns后,生产者可以指定一个回调函数,用于处理无法路由的消息。该回调函数将在消息无法到达目标队列时被调用,以允许生产者执行适当的操作,例如重新发送消息或记录日志等。
综上所述,Publisher Confirms用于确保消息已被正确处理并已进入队列,而Publisher Returns则用于在无法路由消息时向生产者返回通知,以便其执行适当的操作。这两个机制都可以提高消息发布的可靠性和可用性。
publisher使用
- 每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目加载时配置
- ConfirmCallback可以在发送消息时指定,因为每个业务处理confirm成功或失败的逻辑不一定相同。
消息持久化
生产者确认可以确保消息投递到RabbitMQ的队列中,但是消息发送到RabbitMQ以后,如果突然宕机,也可能导致消息丢失。
要想确保消息在RabbitMQ中安全保存,必须开启消息持久化机制。
- 交换机持久化
- 队列持久化
- 消息持久化
RabbitMQ中交换机默认是非持久化的,mq重启后就丢失。
事实上,默认情况下,由SpringAMQP声明的交换机都是持久化的。
可以在RabbitMQ控制台看到持久化的交换机都会带上D的标示
消费者消息确认
RabbitMQ是阅后即焚机制,RabbitMQ确认消息被消费者消费后会立刻删除。
而RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理消息。
设想这样的场景:
- 1)RabbitMQ投递消息给消费者
- 2)消费者获取消息后,返回ACK给RabbitMQ
- 3)RabbitMQ删除消息
- 4)消费者宕机,消息尚未处理
这样,消息就丢失了。因此消费者返回ACK的时机非常重要。
而SpringAMQP则允许配置三种确认模式:
•manual:手动ack,需要在业务代码结束后,调用api发送ack。
•auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
•none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
由此可知:
- none模式下,消息投递是不可靠的,可能丢失
- auto模式类似事务机制,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
- manual:自己根据业务情况,判断什么时候该ack
一般,我们都是使用默认的auto即可。
消费失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力:
- 本地重试
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回ack,消息会被丢弃
- 失败策略
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecovery接口来处理,它包含三种不同的实现:
-
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
-
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
-
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
如何确保RabbitMQ消息的可靠性?
- 开启生产者确认机制,确保生产者的消息能到达队列
- 开启持久化功能,确保消息未消费前在队列中不会丢失
- 开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
- 开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
死信交换机
什么样的消息会成为死信?
- 消息被消费者reject或者返回nack
- 消息超时未消费
- 队列满了
如何给队列绑定死信交换机?
- 给队列设置dead-letter-exchange属性,指定一个交换机
- 给队列设置dead-letter-routing-key属性,设置死信交换机与死信队列的RoutingKey
TTL
也就是Time-To-Live。如果一个队列中的消息如果超时未消费,则会变为死信,超时分为两种情况:
- 消息所在的队列设置了超时时间
- 消息本身设置了超时时间
消息超时的两种方式是?
- 给队列设置ttl属性,进入队列后超过ttl时间的消息变为死信
- 给消息设置ttl属性,队列接收到消息超过ttl时间后变为死信
如何实现发送一个消息20秒后消费者才收到消息?
- 给消息的目标队列指定死信交换机
- 将消费者监听的队列绑定到死信交换机
- 发送消息时给消息设置超时时间为20秒
延迟队列
利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列(Delay Queue)模式。
延迟队列的使用场景包括:
- 延迟发送短信
- 用户下单,如果用户在15 分钟内未支付,则自动取消
- 预约工作会议,20分钟后自动通知所有参会人员
延迟队列插件的使用步骤包括哪些?
•声明一个交换机,添加delayed属性为true
•发送消息时,添加x-delay头,值为超时时间
惰性队列
消息堆积问题
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
解决消息堆积有两种思路:
- 增加更多消费者,提高消费速度。也就是我们之前说的work queue模式
- 扩大队列容积,提高堆积上限
要提升队列容积,把消息保存在内存中显然是不行的。
惰性队列的特征
增加了Lazy Queues的概念,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
消息堆积问题的解决方案?
- 队列上绑定多个消费者,提高消费速度
- 使用惰性队列,可以再mq中保存更多消息
惰性队列的优点有哪些?
- 基于磁盘存储,消息上限高
- 没有间歇性的page-out,性能比较稳定
惰性队列的缺点有哪些?
- 基于磁盘存储,消息时效性会降低
- 性能受限于磁盘的IO
相关文章:
SpringCloud系列知识快速复习 -- part 1(SpringCloud基础知识,Docker,RabbitMQ)
SpringCloud知识快速复习SpringCloud基础知识微服务特点SpringCloud常用组件服务拆分和提供者与消费者概念Eureka注册中心原理Ribbon负载均衡原理负载均衡策略饥饿加载Nacos注册中心服务分级存储模型权重配置环境隔离Nacos与Eureka的区别Nacos配置管理拉取配置流程配置热更新配…...

2023上半年北京/上海/广州/深圳NPDP产品经理认证报名
产品经理国际资格认证NPDP是国际公认的唯一的新产品开发专业认证,集理论、方法与实践为一体的全方位的知识体系,为公司组织层级进行规划、决策、执行提供良好的方法体系支撑。 【认证机构】 产品开发与管理协会(PDMA)成立于1979年…...

面试半年,总结了1000道2023年Java架构师岗面试题
半年前还在迷茫该学什么,怎样才能走出现在的困境,半年后已经成功上岸阿里,感谢在这期间帮助我的每一个人。 面试中总结了1000道经典的Java面试题,里面包含面试要回答的知识重点,并且我根据知识类型进行了分类…...

通过MySQL驱动拦截器实现执行sql耗时计算
文章目录背景具体实现MySQL5MySQL6MySQL8使用方法测试结果背景 公司的一个需求,公司既有的链路追踪日志组件要支持MySQL的sql执行时间打印,要实现链路追踪常用的手段就是实现第三方框架或工具提供的拦截器接口或者是过滤器接口,对于MySQL也不…...

易基因|独家分享:高通量测序后的下游实验验证方法——DNA甲基化篇
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。此前,我们分享了DNA甲基化研究的测序数据挖掘思路(点击查看详情),进而鉴定出研究的目的基因或目标区域的DNA甲基化。做完测序后,…...
 同步和异步理解)
java基础系列(七) 同步和异步理解
一. 问题描述 同步传输和异步传输是web和数据库的重要知识点,会被很多老师强调。那么,它们有什么相同点和不同点?它们对于我们学习编程的意义在哪里? 二. 概念 首先什么是同步和异步? 这里的同步是指&…...

吉林大学 程序设计基础 2022级 OJ期末考试 2.23
本人能力有限,发出只为帮助有需要的人。 以下为实验课的复盘,内容会有大量失真,请多多包涵。 1.双手剑士的最优搭配 每把剑有攻击力和防御力两个属性。双手剑士可以同时拿两把剑,其得到攻击力为两把剑中的攻击力的最大值&#…...

【项目实战】SpringMVC拦截器实战 - 自定义拦截器防止重复提交
一、背景说明 如何能够实现防止重复提交呢?以下是一种可选的方式。 二、代码实战 2.1 注册重复提交拦截器到SpringMVC中 @Configuration @AllArgsConstructor public class ResourcesConfig implements WebMvcConfigurer {private final RepeatSubmitInterceptor repeatSu…...

C++ STL:容器 Container
文章目录1、序列容器1.1、容器共性1.2、vectorvector 结构* vector 扩容原理* vector 迭代器失效1.3、dequedeque 结构deque 迭代器deque 模拟连续空间1.4、listlist 特殊操作list 结构list 迭代器2、关联式容器2.1、容器共性2.2、容器特性3、无序关联式容器3.1、容器共性3.2、…...
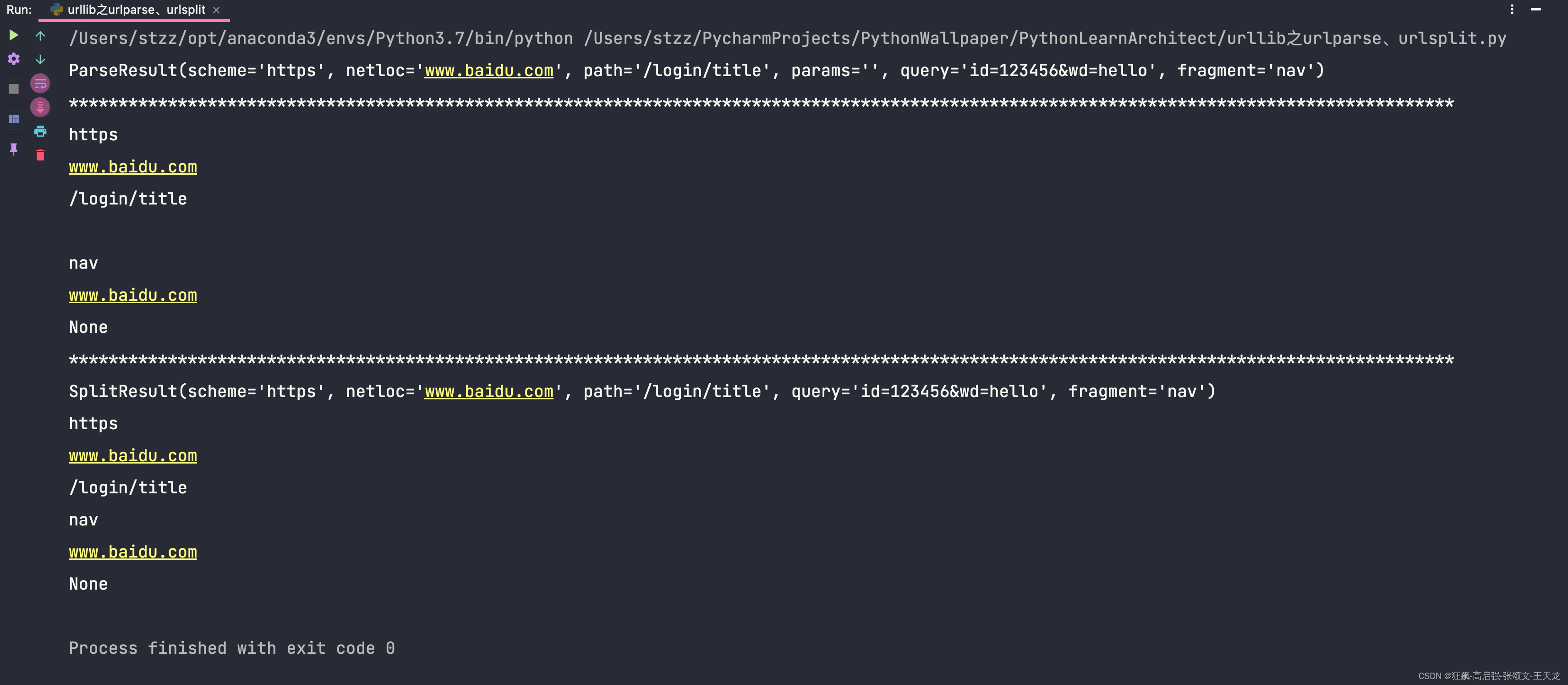
urllib之urlopen和urlretrieve的headers传入以及parse、urlparse、urlsplit的使用
urllib库是什么?urllib库python的一个最基本的网络请求库,不需要安装任何依赖库就可以导入使用。它可以模拟浏览器想目标服务器发起请求,并可以保存服务器返回的数据。urllib库的使用:1、request.urlopen(1)只能传入url的方式from http.clie…...
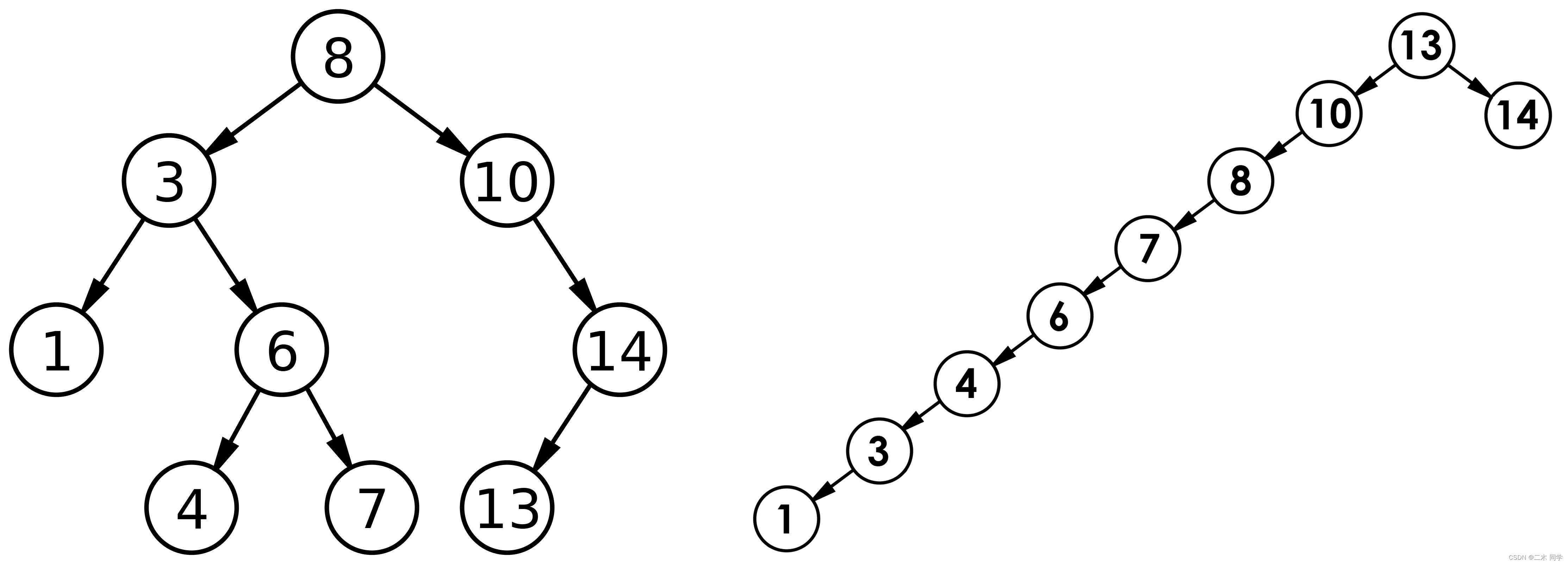
【C++】二叉搜索树的模拟实现
一、概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根节点的值它的左右子树也分别…...
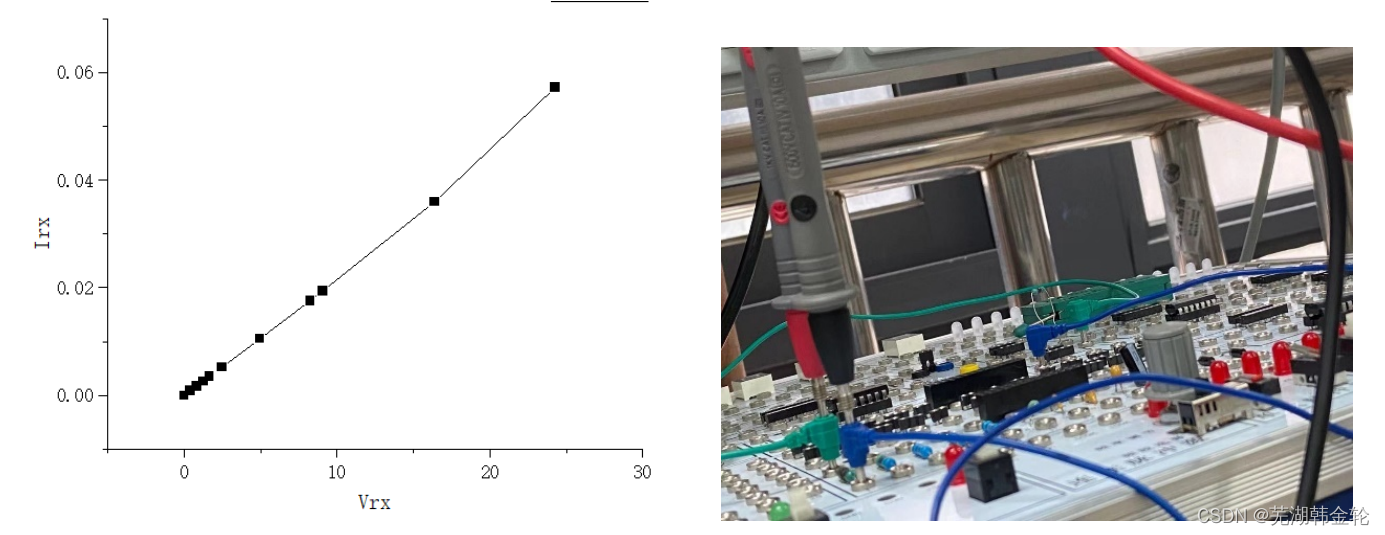
HNU工训中心:元器件及测量基础实验报告
工训中心的牛马实验 1.实验目的 1.熟悉测量验证常用元器件参数、 并采用替代法(测量回路电流)测量其伏安特性的方法。 2.熟悉测量误差及减小测量误差注意事项 2.实验仪器和器材 1.实验仪器. 直流稳压电源型号:IT6302 台式多用表型号:UT805A 2.实验( 箱)器材 电路实验箱…...
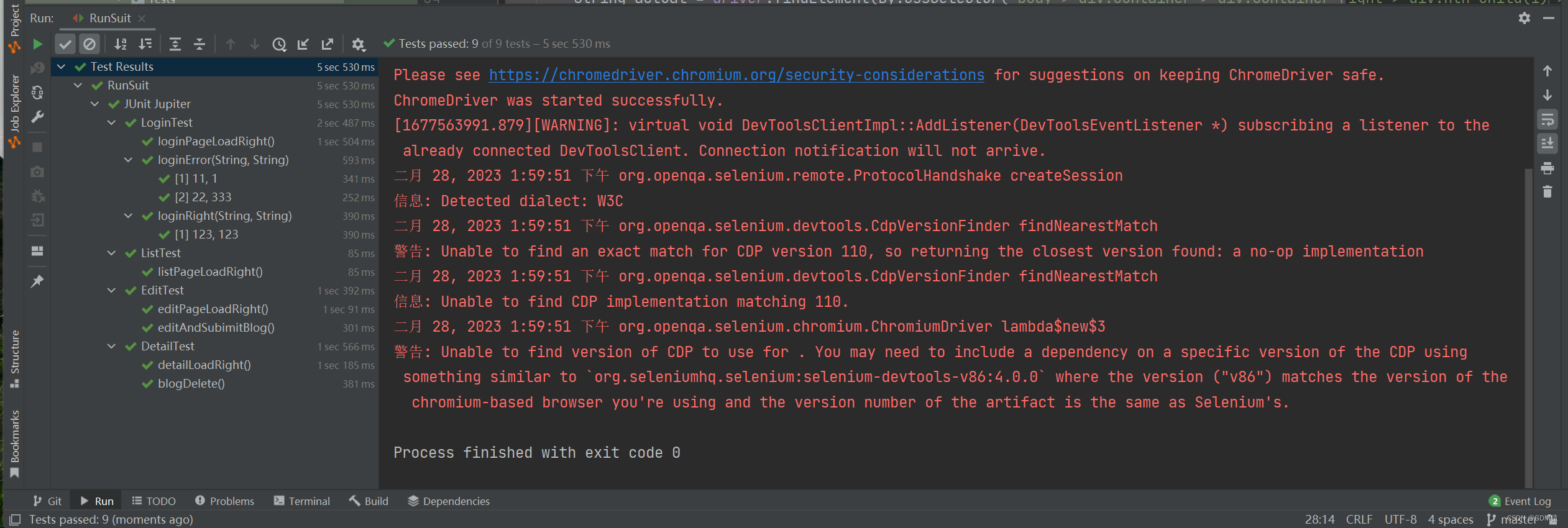
博客系统--自动化测试
项目体验地址(账号:123,密码:123)http://120.53.20.213:8080/blog_system/login.html项目后端说明:http://t.csdn.cn/32Nnv项目码云Gitee地址:https://gitee.com/GoodManSS/project/tree/master…...

Day903.自增主键不能保证连续递增 -MySQL实战
自增主键不能保证连续递增 Hi,我是阿昌,今天学习记录的是关于自增主键不能保证连续递增的内容。 MySql保证了主键是自增,但不相对连续;帮助开发人员快速识别每个行的唯一性,并提高查询效率。 自增主键可以让主键索引…...
02-MyBatis查询-
文章目录Mybatis CRUD练习1,配置文件实现CRUD1.1 环境准备Debug01: 别名mybatisx报错1.2 查询所有数据1.2.1 编写接口方法1.2.2 编写SQL语句1.2.3 编写测试方法1.2.4 起别名解决上述问题1.2.5 使用resultMap解决上述问题1.2.6 小结1.3 查询详情1.3.1 编写接口方法1.…...

外盘国际期货招商:2023年3月关注日历,把握重要投资机会
2023年3月大事件日历 关注大事日历,把握重要投资机会 3月1日:马斯克推出特斯拉宏图第三篇章 3月1-2日:G20外长会议 3月4-5日:全国两会召开 3月9日:中国2月CPI、PPI数据 待定(前次进行日期:…...
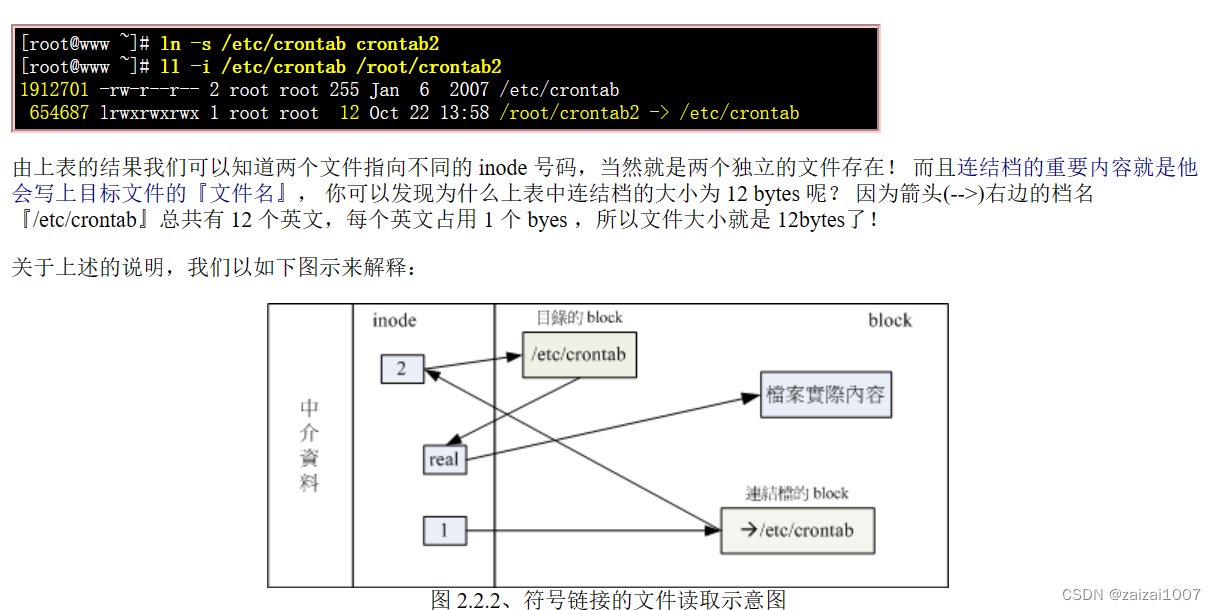
Linux学习(9.1)文件系统的简单操作
以下内容转载自鸟哥的Linux私房菜 原文:鸟哥的 Linux 私房菜 -- Linux 磁盘与文件系统管理 (vbird.org) 磁盘与目录的容量 df:列出文件系统的整体磁盘使用量;du:评估文件系统的磁盘使用量(常用在推估目录所占容量) df du 实体…...

Hadoop综合案例 - 聊天软件数据
目录1、聊天软件数据分析案例需求2、基于Hive数仓实现需求开发2.1 建库2.2 建表2.3 加载数据2.4 ETL数据清洗2.5 需求指标统计---都很简单3、FineBI实现可视化报表3.1 FineBI介绍3.2 FineBI配置数据3.3 构建可视化报表1、聊天软件数据分析案例需求 MR速度慢—引入hive 背景&a…...

Python进阶-----面向对象1.0(对象和类的介绍、定义)
目录 前言: 面向过程和面向对象 类和对象 Python中类的定义 (1)类的定义形式 (2)深层剖析类对象 前言: 感谢各位的一路陪伴,我学习Python也有一个月了,在这一个月里我收获满满…...

天猫淘宝企业服务为中小微企业打造供应链智能协同网络,让采购不再将就!丨爱分析报告
编者按:近日天猫淘宝企业服务&爱分析联合发布《2023中小微企业电商采购白皮书》,为中小微企业采购数字化带来红利。 某水泵企业:线上客户主要是中小微企业,线上业绩遇到瓶颈,如何突破呢?某焊割设备企业…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...

Docker、Wsl 打包迁移环境
电脑需要开启wsl2 可以使用wsl -v 查看当前的版本 wsl -v WSL 版本: 2.2.4.0 内核版本: 5.15.153.1-2 WSLg 版本: 1.0.61 MSRDC 版本: 1.2.5326 Direct3D 版本: 1.611.1-81528511 DXCore 版本: 10.0.2609…...

【Java】Ajax 技术详解
文章目录 1. Filter 过滤器1.1 Filter 概述1.2 Filter 快速入门开发步骤:1.3 Filter 执行流程1.4 Filter 拦截路径配置1.5 过滤器链2. Listener 监听器2.1 Listener 概述2.2 ServletContextListener3. Ajax 技术3.1 Ajax 概述3.2 Ajax 快速入门服务端实现:客户端实现:4. Axi…...
Springboot 高校报修与互助平台小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,高校报修与互助平台小程序被用户普遍使用,为…...

作为点的对象CenterNet论文阅读
摘要 检测器将图像中的物体表示为轴对齐的边界框。大多数成功的目标检测方法都会枚举几乎完整的潜在目标位置列表,并对每一个位置进行分类。这种做法既浪费又低效,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将物体建模为单…...