“速通“ 老生常谈的HashMap [实现原理源码解读]
👳我亲爱的各位大佬们好😘😘😘
♨️本篇文章记录的为 HashMap 实现原理&&源码解读 相关内容,适合在学Java的小白,帮助新手快速上手,也适合复习中,面试中的大佬🙉🙉🙉。
♨️如果文章有什么需要改进的地方还请大佬不吝赐教❤️🧡💛
👨🔧 个人主页 : 阿千弟
🔥 上期内容👉👉👉 : 都2023年了,如果不会Lambda表达式、函数式编程?你确定能看懂公司代码?
HashMap在现在已然成为了一个老生常谈的话题, 不管是正在学java的小白还是不断跳槽升值的老鸟, 在面试中HashMap几乎不可避免的会被问到, 你可以不被问到, 但你不能不会.😎😎😎
本篇文章的内容就是HashMap的实现原理和源码解读, 各位观众老爷们一起来看看吧👉👉👉
文章目录
- 1、概述
- 2、属性
- 3、方法
- 1、get 方法
- 2、put 方法
- 3、remove 方法
- 4、hash 方法
- 5、resize 方法
- 4、总结
- HashMap小结
- HashMap底层机制及源码剖析
1、概述
二话不说,一上来就点开源码,发现里面有一段介绍如下:
/*** Hash table based implementation of the <tt>Map</tt> interface. This* implementation provides all of the optional map operations, and permits* <tt>null</tt> values and the <tt>null</tt> key. (The <tt>HashMap</tt>* class is roughly equivalent to <tt>Hashtable</tt>, except that it is* unsynchronized and permits nulls.) This class makes no guarantees as to* the order of the map; in particular, it does not guarantee that the order* will remain constant over time.*/
英语好的大佬可以直接看源注释, 翻译一下大概就是在说,这个哈希表是基于 Map 接口的实现的,它允许 null 值和null 键,它不是线程同步的,同时也不保证有序。
/*** This implementation provides constant-time performance for the basic* operations (<tt>get</tt> and <tt>put</tt>), assuming the hash function* disperses the elements properly among the buckets. Iteration over* collection views requires time proportional to the "capacity" of the* <tt>HashMap</tt> instance (the number of buckets) plus its size (the number* of key-value mappings). Thus, it's very important not to set the initial* capacity too high (or the load factor too low) if iteration performance is* important.** An instance of <tt>HashMap</tt> has two parameters that affect its* performance: <i>initial capacity</i> and <i>load factor</i>. The* <i>capacity</i> is the number of buckets in the hash table, and the initial* capacity is simply the capacity at the time the hash table is created. The* <i>load factor</i> is a measure of how full the hash table is allowed to* get before its capacity is automatically increased. When the number of* entries in the hash table exceeds the product of the load factor and the* current capacity, the hash table is <i>rehashed</i> (that is, internal data* structures are rebuilt) so that the hash table has approximately twice the* number of buckets.*/
再来看看这一段,讲的是 Map 的这种实现方式为 get(取)和 put(存)带来了比较好的性能。但是如果涉及到大量的遍历操作的话,就尽量不要把 capacity 设置得太高(或 loadfactor 设置得太低),否则会严重降低遍历的效率。
影响 HashMap 性能的两个重要参数:“initial capacity”(初始化容量)和”load factor“(负载因子)。简单来说,容量就是哈希表桶的个数,负载因子就是键值对个数与哈希表长度的一个比值,当比值超过负载因子之后,HashMap 就会进行 rehash操作来进行扩容。
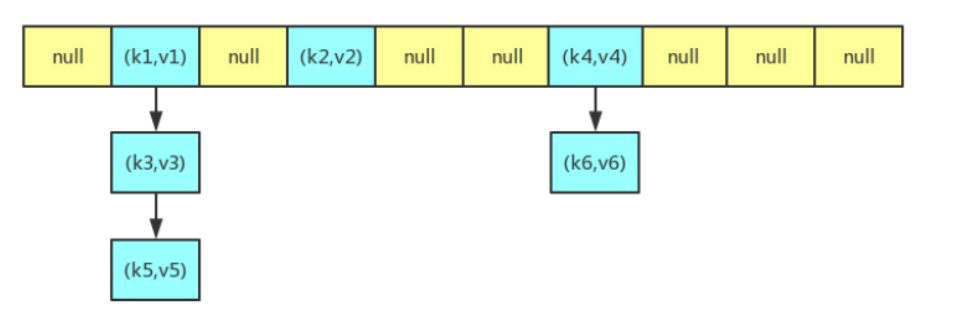
HashMap 的大致结构如下图所示,其中哈希表是一个数组,我们经常把数组中的每一个节点称为一个桶,哈希表中的每个节点都用来存储一个键值对。在插入元素时,如果发生冲突(即多个键值对映射到同一个桶上)的话,就会通过链表的形式来解决冲突。因为一个桶上可能存在多个键值对,所以在查找的时候,会先通过 key 的哈希值先定位到桶,再遍历桶上的所有键值对,找出 key 相等的键值对,从而来获取 value。
2、属性
//默认的初始容量为 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//最大的容量上限为 2^30
static final int MAXIMUM_CAPACITY = 1 << 30;//默认的负载因子为 0.75
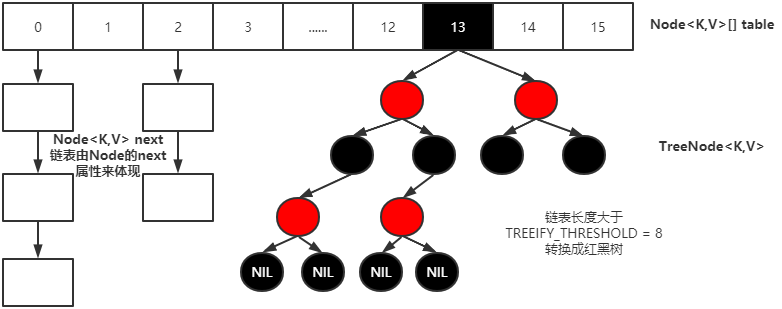
static final float DEFAULT_LOAD_FACTOR = 0.75f;//变成树型结构的临界值为 8
static final int TREEIFY_THRESHOLD = 8;//恢复链式结构的临界值为 6
static final int UNTREEIFY_THRESHOLD = 6;//哈希表
transient Node<K,V>[] table;//哈希表中键值对的个数
transient int size;//哈希表被修改的次数
transient int modCount;//它是通过 capacity*load factor 计算出来的,当 size 到达这个值时,就会进行扩容操作
int threshold;//负载因子
final float loadFactor;//当哈希表的大小超过这个阈值,才会把链式结构转化成树型结构,否则仅采取扩容来尝试减少冲突
static final int MIN_TREEIFY_CAPACITY = 64;
下面是 Node 类的定义,它是 HashMap 中的一个静态内部类,哈希表中的每一个节点都是 Node 类型。我们可以看到,Node 类中有 4 个属性,其中除了 key 和value 之外,还有 hash 和 next 两个属性。hash 是用来存储 key 的哈希值的,next 是在构建链表时用来指向后继节点的。
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}
3、方法
1、get 方法
// get 方法主要调用的是 getNode 方法,所以重点要看 getNode 方法的实现
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;// 如果哈希表不为空 && key 对应的桶上不为空if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {// 是否直接命中if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;// 判断是否有后续节点if ((e = first.next) != null) {// 如果当前的桶是采用红黑树处理冲突,则调用红黑树的 get 方法去获取节点if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {// 不是红黑树的话,那就是传统的链式结构了,通过循环的方法判断链中是否存在该 keyif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}
实现步骤大致如下:
- 通过 hash 值获取该 key 映射到的桶。
- 桶上的 key 就是要查找的 key,则直接命中。
- 桶上的 key 不是要查找的 key,则查看后续节点:
- 如果后续节点是树节点,通过调用树的方法查找该 key。
- 如果后续节点是链式节点,则通过循环遍历链查找该 key。
2、put 方法
//put 方法的具体实现也是在 putVal 方法中,所以我们重点看下面的 putVal 方法
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 如果底层的table数组(哈希表)为null, 或者length==0, 则先创建一个哈希表, 并扩容到16if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 取出hash值对应的table的索引位置的Node, 如果当前桶没有碰撞冲突, // 就直接把加入的k-v创建成一个Node, 加入该位置即可if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 如果table索引位置的key的hashcode值与新的key的hashcode值相同//并满足(table现有的节点的key和准备添加的key是同一个对象 || equals返回真)//就认为不能加入新的k-vif (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// 如果当前table的已有Node是红黑树,则通过红黑树的 putTreeVal 方法去插入这个键值对else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 否则就是传统的链式结构else {// 采用循环遍历的方式,判断链中是否有重复的 keyfor (int binCount = 0; ; ++binCount) {// 到了链尾还没找到重复的 key,则说明 HashMap 没有包含该键if ((e = p.next) == null) {// 创建一个新节点插入到尾部p.next = newNode(hash, key, value, null);// 如果链的长度大于 TREEIFY_THRESHOLD 这个临界值,则把链变为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// 找到了重复的 keyif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 这里表示在上面的操作中找到了重复的键,所以这里把该键的值替换为新值if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;// 判断是否需要进行扩容if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}
put 方法比较复杂,实现步骤大致如下:
-
先通过 hash 值计算出 key 映射到哪个桶。
-
如果桶上没有碰撞冲突,则直接插入。
-
如果出现碰撞冲突了,则需要处理冲突:
-
如果该桶使用红黑树处理冲突,则调用红黑树的方法插入。
-
否则采用传统的链式方法插入。如果链的长度到达临界值,则把链转变为红黑树。
-
-
如果桶中存在重复的键,则为该键替换新值。
-
如果 size 大于阈值,则进行扩容。
3、remove 方法
// remove 方法的具体实现在 removeNode 方法中,所以我们重点看下面的 removeNode 方法
public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;
}final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;// 如果当前 key 映射到的桶不为空if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {Node<K,V> node = null, e; K k; V v;// 如果桶上的节点就是要找的 key,则直接命中if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))node = p;else if ((e = p.next) != null) {// 如果是以红黑树处理冲突,则构建一个树节点if (p instanceof TreeNode)node = ((TreeNode<K,V>)p).getTreeNode(hash, key);// 如果是以链式的方式处理冲突,则通过遍历链表来寻找节点else {do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}// 比对找到的 key 的 value 跟要删除的是否匹配if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {// 通过调用红黑树的方法来删除节点if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);// 使用链表的操作来删除节点else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount;--size;afterNodeRemoval(node);return node;}}return null;
}4、hash 方法
在 get 方法和 put 方法中都需要先计算 key 映射到哪个桶上,然后才进行之后的操作,计算的主要代码如下:
(n - 1) & hash
上面代码中的 n 指的是哈希表的大小,hash 指的是 key 的哈希值,hash 是通过下面这个方法计算出来的,采用了二次哈希的方式,其中 key 的 hashCode 方法是一个native 方法:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个 hash 方法先通过 key 的 hashCode 方法获取一个哈希值,再拿这个哈希值与它的高 16 位的哈希值做一个异或操作来得到最后的哈希值,计算过程可以参考下图。为啥要这样做呢?注释中是这样解释的:如果当 n 很小,假设为 64 的话,那么 n-1即为 63(0x111111),这样的值跟 hashCode()直接做与操作,实际上只使用了哈希值的后 6 位。如果当哈希值的高位变化很大,低位变化很小,这样就很容易造成冲突了,所以这里把高低位都利用起来,从而解决了这个问题。

正是因为与的这个操作,决定了 HashMap 的大小只能是 2 的幂次方,想一想,如果不是 2 的幂次方,会发生什么事情?即使你在创建 HashMap 的时候指定了初始大小,HashMap 在构建的时候也会调用下面这个方法来调整大小:
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
这个方法的作用看起来可能不是很直观,它的实际作用就是把 cap 变成第一个大于等于 2 的幂次方的数。例如,16 还是 16,13 就会调整为 16,17 就会调整为 32。
5、resize 方法
HashMap 在进行扩容时,使用的 rehash 方式非常巧妙,因为每次扩容都是翻倍,与原来计算(n-1)&hash 的结果相比,只是多了一个 bit 位,所以节点要么就在原来的位置,要么就被分配到“原位置+旧容量”这个位置。
例如,原来的容量为 32,那么应该拿 hash 跟 31(0x11111)做与操作;在扩容扩到了 64 的容量之后,应该拿 hash 跟 63(0x111111)做与操作。新容量跟原来相比只是多了一个 bit 位,假设原来的位置在 23,那么当新增的那个 bit 位的计算结果为 0时,那么该节点还是在 23;相反,计算结果为 1 时,则该节点会被分配到 23+31 的桶上。
正是因为这样巧妙的 rehash 方式,保证了 rehash 之后每个桶上的节点数必定小于等于原来桶上的节点数,即保证了 rehash 之后不会出现更严重的冲突。
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;// 计算扩容后的大小if (oldCap > 0) {// 如果当前容量超过最大容量,则无法进行扩容if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 没超过最大值则扩为原来的两倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}// 新的 resize 阈值threshold = newThr;// 创建新的哈希表@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 遍历旧哈希表的每个桶,重新计算桶里元素的新位置for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;// 如果桶上只有一个键值对,则直接插入if (e.next == null)newTab[e.hash & (newCap - 1)] = e;// 如果是通过红黑树来处理冲突的,则调用相关方法把树分离开else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);// 如果采用链式处理冲突else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;// 通过上面讲的方法来计算节点的新位置do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}
在这里有一个需要注意的地方,有些文章指出当哈希表的桶占用超过阈值时就进行扩容,这是不对的;实际上是当哈希表中的键值对个数超过阈值时,才进行扩容的。
4、总结
按照原来的拉链法来解决冲突,如果一个桶上的冲突很严重的话,是会导致哈希表的效率降低至 O(n),而通过红黑树的方式,可以把效率改进至 O(logn)。相比链式结构的节点,树型结构的节点会占用比较多的空间,所以这是一种以空间换时间的改进方式。
HashMap小结
- Map接口的常用实现类:
HashMap、Hashtable和Properties。 HashMap是Map接口使用频率最高的实现类。HashMap是以key-val对的方式来存储数据(HashMap$Node类型)- key 不能重复,但是值可以重复,允许使用
null键和null值。 - 如果添加相同的key , 则会覆盖原来的key-val ,等同于修改.(key不会替换,val会替换)
- 与
HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的.(jdk8的hashMap 底层 数组+链表+红黑树) HashMap没有实现同步,因此是线程不安全的, 方法没有做同步互斥的操作, 没有synchronized
HashMap底层机制及源码剖析
HashMapSource.java 先说结论-》debug源码.
扩容机制 [和HashSet相同]
- HashMap底层维护了Node类型的数组table,默认为null
- 当创建对象时,将加载因子(loadfactor)初始化为0.75.
- 当添加key-val时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key和准备加入的key相是否等,如果相等,则直接替换val;如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
- 第1次添加,则需要扩容table容量为16,临界值(threshold)为12 (16*0.75)
- 以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,即24,依次类推.
- 在Java8中, 如果一条链表的元素个数超过 TREEIFY THRESHOLD(默认是 8 ), 并且table的大小 >= MIN TREEIFY CAPACITY(默认64),就会进行树化(红黑树)
- 剪枝: 当hash表上的一个节点是红黑树, 且当这个树上的节点被频繁移除直到节点数<=6时, 红黑树会重新退化成为链表

如果这篇【文章】有帮助到你💖,希望可以给我点个赞👍,创作不易,如果有对Java后端或者对
spring感兴趣的朋友,请多多关注💖💖💖
👨🔧 个人主页 : 阿千弟
相关文章:
“速通“ 老生常谈的HashMap [实现原理源码解读]
👳我亲爱的各位大佬们好😘😘😘 ♨️本篇文章记录的为 HashMap 实现原理&&源码解读 相关内容,适合在学Java的小白,帮助新手快速上手,也适合复习中,面试中的大佬🙉🙉…...
Linux系统介绍及熟悉Linux基础操作
一、什么是Liunx Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由林纳斯本纳第克特托瓦兹(Linus Benedict Torvalds)于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发&am…...
mysql数据库limit的四种用法
文章目录前言一、语法二、参数说明三、常用示例-4种用法总结前言 mysql数据库中limit子句可以被用于强制select语句返回指定的记录数。limit接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,…...
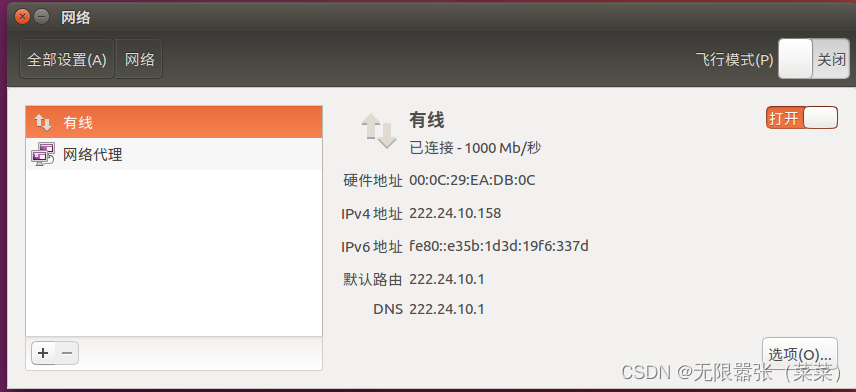
嵌入式 linux 系统开发网络的设置
目录 一、前言 二、linux网络静态地址设置 前言 为什么要对linux系统下的ubuntu进行网络设置呢? 因为我们在嵌入式开发中,我们要保证windows系统、linux系统、开发板的ip要处于同一个网段,而默认ubuntu下的linux系统的ip是动态分配的&#…...
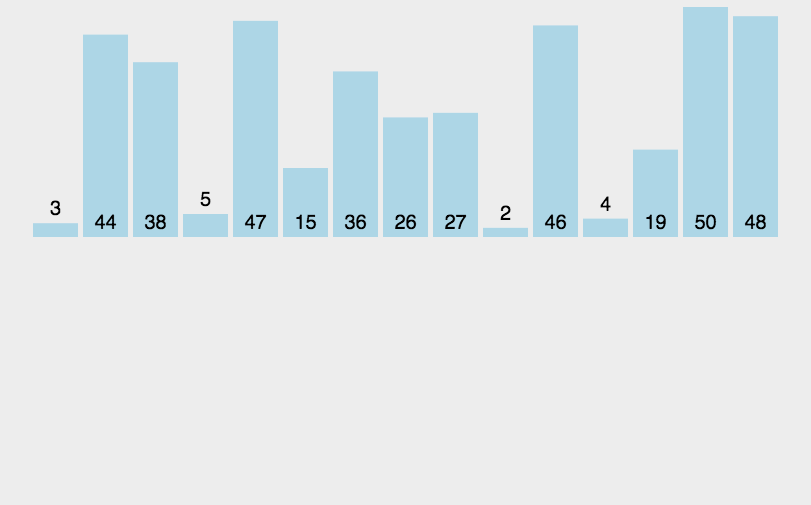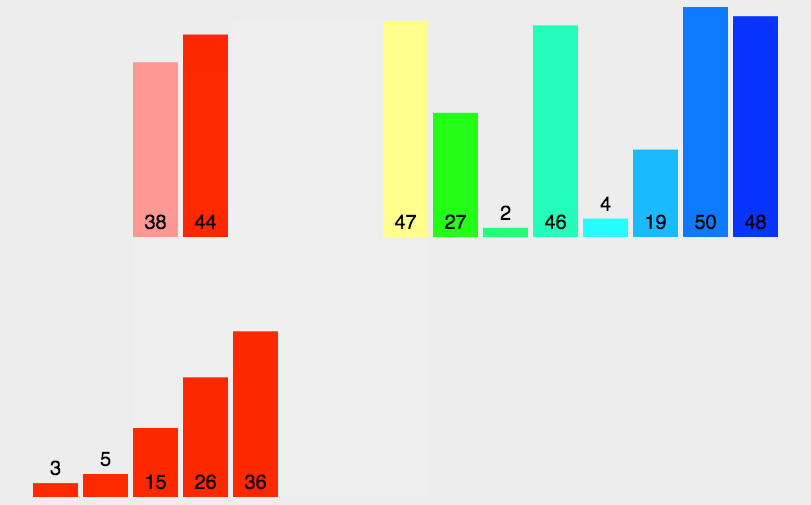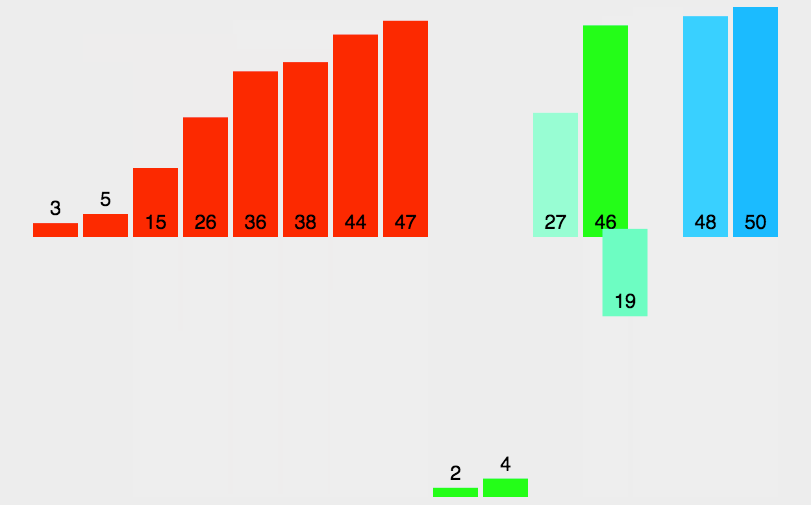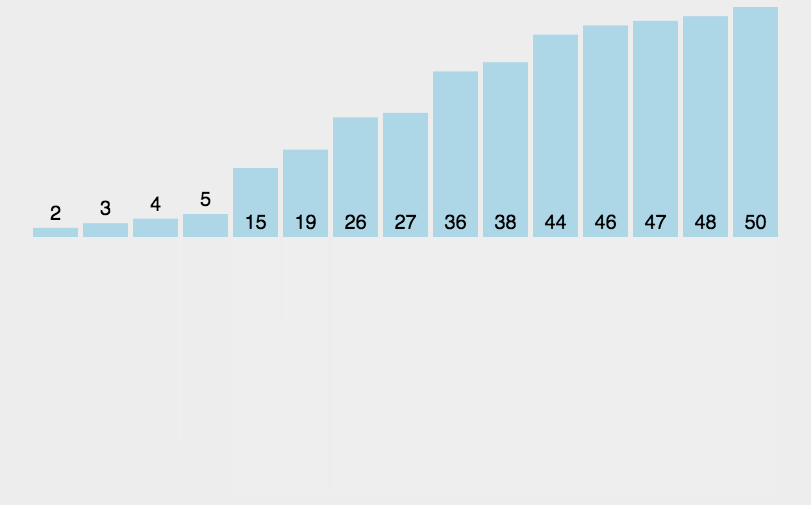
算法设计与分析——十大经典排序算法一(1--5)
目录 算法设计与分析——十大经典排序算法 第1关:冒泡排序 参考代码 第2关:选择排序 参考代码 第3关:插入排序 参考代码 第4关:希尔排序 参考代码 第5关:归并排序 参考代码 作者有言 一个不知名大学生&#x…...

六.慕课的冲击:知识何以有力量?
6.1知识就是力量?【单选题】关于技术进步,以下说法错误的是( )。A、技术进步可以不依靠知识积累B、知识的力量推动技术进步C、技术黑箱换句话说即是天上掉馅饼D、专利保护产生的垄断利润,构成创新动力我的答案:A【判断题】罗伯特索洛认为,技…...

SQL基础
sql基础笔记 DATEDIFF() 函数返回两个日期之间的时间。 DATEDIFF(parameter1,parameter2,parameter3) parameter1:可为 年月日时分秒或周 parameter2,parameter3:合法的日期 如:…...
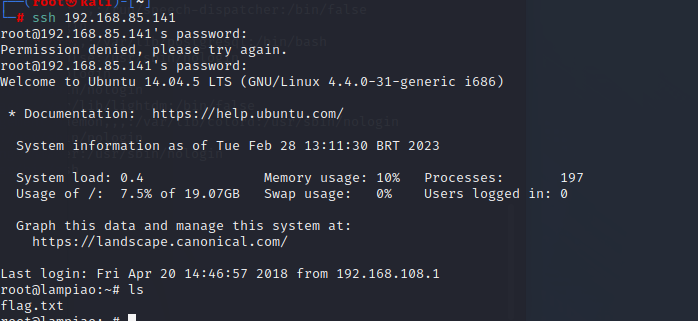
脏牛复现(CVE2016-5195)
nmap扫描全网段,发现存货主机,ip为192.168.85.141nmap 192.168.85.0/24nmap 扫描端口,发现80端口,访问该网站nmap -p1-65535 192.168.85.141扫描该网站目录,什么也没扫出来 ,dirb扫描目录的字典在usr/share…...

Redis源码---内存友好的数据结构该如何细化设计
目录 前言 内存友好的数据结构 SDS 的内存友好设计 redisObject 结构体与位域定义方法 嵌入式字符串 压缩列表和整数集合的设计 节省内存的数据访问 前言 Redis 是内存数据库,所以,高效使用内存对 Redis 的实现来说非常重要而实际上,R…...

获取 本周、本月、本年 的开始或结束时间
获取 本周、本月、本年 的开始或结束时间 public class DateTimeUtil{// 获取 本周、本月、本年 的开始或结束时间/// <summary>/// 获取开始时间/// </summary>/// <param name"TimeType">Week、Month、Year</param>/// <param name&quo…...

算法训练营 day58 动态规划 判断子序列 不同的子序列
算法训练营 day58 动态规划 判断子序列 不同的子序列 判断子序列 392. 判断子序列 - 力扣(LeetCode) 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而…...

优思学院|DFMEA是全球制造业的必修课!
DFMEA(Design Failure Mode and Effects Analysis)是一种分析技术,在产品设计的早期阶段识别和解决潜在的失效问题。它通过分析设计的各个方面,识别潜在的失效模式和影响,并提出相应的改进措施,以减少失效的…...

【Day02数据结构 空间复杂度】
最近太忙了都好久没有更新博客了,太难了,抽空水一篇文章,大佬们多多支持. 上篇:时间复杂度分析 目录 前言 一、空间复杂度概念? 二、实例展示 三、.有复杂度要求的算法题练习 1.题目链接:力扣--消失的数字 2.题目链接:力扣--旋转数组 总结: 1…...

多数据库管理工具哪家强?ChatGPT点评,第一位并不是Navicat
SQL逐渐成为职场必备的编程语言,相信大家都不陌生。SQL是一种结构化查询语言,是用于数据库之间通信的编程语言。每个数据库都有着自己独特的访问规则,但大体上是遵循SQL标准。 因此,辗转于不同的数据库之间,开发者或D…...
)
UnityShader常用函数(UnityShader内置函数、CG和GLSL内置函数等)
空间变换函数函数名描述float4 UnityWorldToClipPos(float3 pos )把世界坐标空间中某一点pos变换到齐次裁剪空间float4 UnityViewToClipPos(float3 pos )把观察坐标空间中某一点pos变换到齐次裁剪空间float3 UnityObjectToViewPos(float3 pos或float4 pos)模型局部空间坐标系中…...

Springboot自定义注解-1
注解用于修饰其他的注解(纪委:管干部的干部) ① Retention:定义注解的保留策略 Retention(RetentionPolicy.SOURCE) //注解仅存在于源码中,在class字节码文件中不包含 Retention(RetentionPolicy.CLASS) …...
)
经纬度标定及大地坐标系相关概念(一)
经纬度标定及大地坐标系相关概念(一)一、背景二、经纬度的概念三、大地坐标系四、大地坐标系的分类五、各类坐标系介绍5.1 我国地理坐标系5.1.1 北京54坐标系5.1.2 1980西安坐标系5.1.3 2000国家大地坐标系5.2 世界大地坐标系5.1.1 WGS84坐标系5.3 加密坐…...
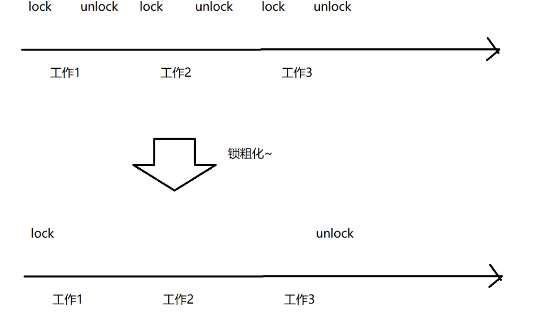
synchronized关键字原理
synchronized原理 1、基本特点 基于锁策略,可以知道synchronized具有以下特性: 1.开始时候是乐观锁,如果锁冲突频繁就转换为悲观锁 2.开始是轻量级锁,如果锁持有的时间较长,就转换成重量级锁 3.实现轻量级锁的时候…...

面试被问死怎么办?学会这四招,通过的机率提升30%
软件工程师面试很难,难到什么程度呢?有一句话可以来形容: 面试造飞机,上班拧螺丝 没错,面试的时候各种问你原理、机制,而这些在实际工作中却很难用到。于是乎,很多工程师面试的时候就非常害怕…...
Android TV UI开发常用知识
导入依赖 Google官方为Android TV的UI开发提供了一系列的规范组件,在leanback的依赖库中,这里介绍一些常用的组件,使用前需要导入leanback库。 implementation androidx.leanback:leanback:$version常用的页面 这些Fragment有设计好的样式&…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...
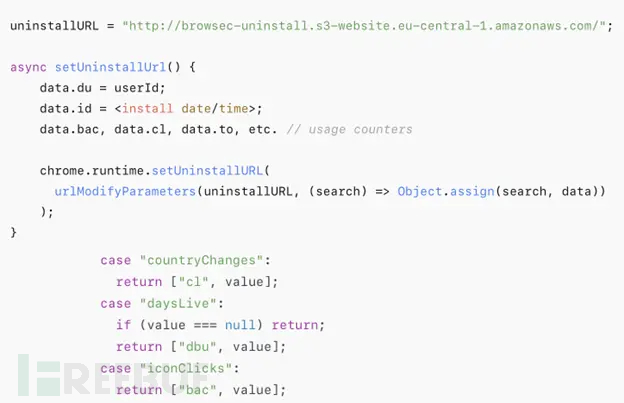
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...