【ES】Elasticsearch-深入理解索引原理
文章目录
- Elasticsearch-深入理解索引原理
- 读操作
- 更新操作
- SHARD
- 不变性
- 动态更新索引
- 删除和更新
- 实时索引
- 更新持久化
- Segment合并
- 近实时搜索,段数据刷新,数据可见性更新和事务日志
- 更新索引并且将改动提交
- 修改Searcher对象默认的更新时间
Elasticsearch-深入理解索引原理
索引(Index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
我们了解索引的写操作后可知,更新、索引、删除文档都是写操作,这些操作必须在primary shard完全成功后才能拷贝至其对应的replicas上,默认情况下主分片等待所有备份完成索引后才返回客户端。
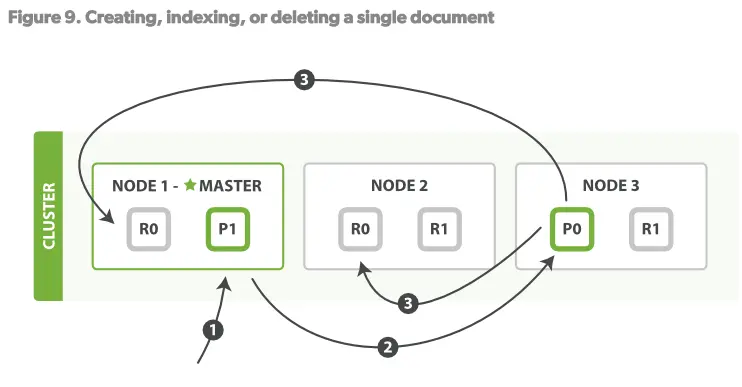
步骤:
- 客户端向Node1 发送索引文档请求
- Node1 根据文档ID(_id字段)计算出该文档应该属于shard0,然后请求路由到Node3的P0分片上
- Node3在P0上执行了请求。如果请求成功,则将请求并行的路由至Node1,Node2的R0上。当所有的Replicas报告成功后,Node3向请求的Node(Node1)发送成功报告,Node1再报告至Client。
当客户端收到执行成功后,操作已经在Primary shard和所有的replica shards上执行成功了
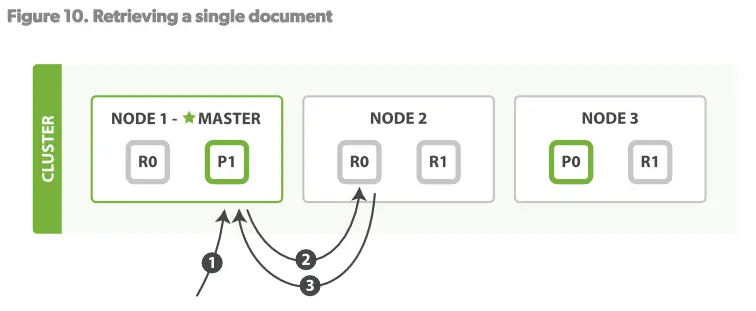
读操作
一个文档可以在primary shard和所有的replica shard上读取。见Figure10
读操作步骤:
1.客户端发送Get请求到NODE1。
2.NODE1使用文档的_id决定文档属于shard 0.shard 0的所有拷贝存在于所有3个节点上。这次,它将请求路由至NODE2。
3.NODE2将文档返回给NODE1,NODE1将文档返回给客户端。 对于读请求,请求节点(NODE1)将在每次请求到来时都选择一个不同的replica。
shard来达到负载均衡。使用轮询策略轮询所有的replica shards。
更新操作
更新操作,结合了以上的两个操作:读、写。见Figure11
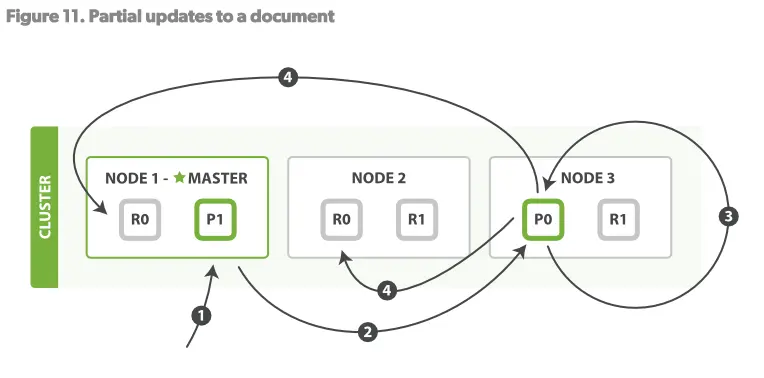
步骤:
1.客户端发送更新操作请求至NODE1
2.NODE1将请求路由至NODE3,Primary shard所在的位置
3.NODE3从P0读取文档,改变source字段的JSON内容,然后试图重新对修改后的数据在P0做索引。如果此时这个文档已经被其他的进程修改了,那么它将重新执行3步骤,这个过程如果超过了retryon_conflict设置的次数,就放弃。
4.如果NODE3成功更新了文档,它将并行的将新版本的文档同步到NODE1和NODE2的replica shards重新建立索引。一旦所有的replica
shards报告成功,NODE3向被请求的节点(NODE1)返回成功,然后NODE1向客户端返回成功。
SHARD
- 为什么搜索是实时的
- 为什么文档的CRUD操作是实时的
- ES怎么保障你的更新在宕机的时候不会丢失
- 为什么删除文档不会立即释放空间
不变性
写到磁盘的倒序索引是不变的:自从写到磁盘就再也不变。 这会有很多好处:
不需要添加锁。如果你从来不用更新索引,那么你就不用担心多个进程在同一时间改变索引。
一旦索引被内核的文件系统做了Cache,它就会待在那因为它不会改变。只要内核有足够的缓冲空间,绝大多数的读操作会直接从内存而不需要经过磁盘。这大大提升了性能。
其他的缓存(例如fiter cache)在索引的生命周期内保持有效,它们不需要每次数据修改时重构,因为数据不变。
写一个单一的大的倒序索引可以让数据压缩,减少了磁盘I/O的消耗以及缓存索引所需的RAM。
当然,索引的不变性也有缺点。如果你想让新修改过的文档可以被搜索到,你必须重新构建整个索引。这在一个index可以容纳的数据量和一个索引可以更新的频率上都是一个限制。
动态更新索引
如何在不丢失不变形的好处下让倒序索引可以更改?答案是:使用不只一个的索引。 新添额外的索引来反映新的更改来替代重写所有倒序索引的方案。 Lucene引进了per-segment搜索的概念。一个segment是一个完整的倒序索引的子集,所以现在index在Lucene中的含义就是一个segments的集合,每个segment都包含一些提交点(commit point)。见Figure16。新的文档建立时首先在内存建立索引buffer,见Figure17。然后再被写入到磁盘的segment,见Figure18。
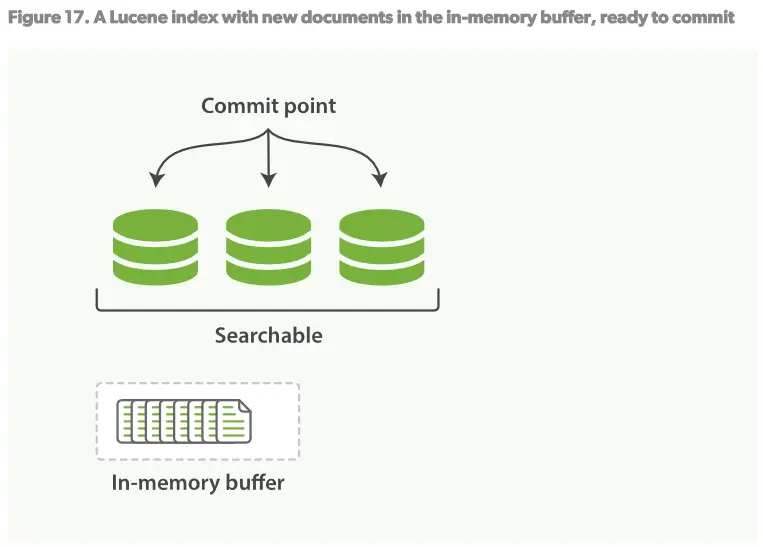
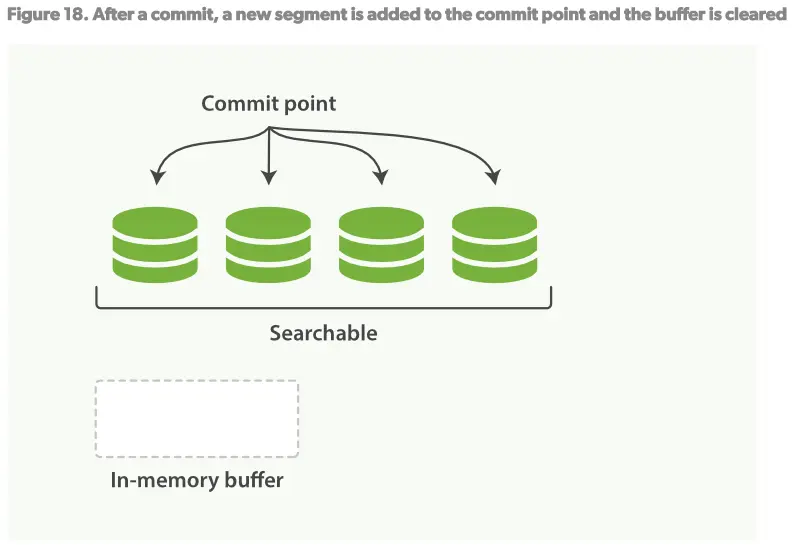
一个per-segment的工作流程如下:
1.新的文档在内存中组织,见Figure17。
2.每隔一段时间,buffer将会被提交: 一个新的segment(一个额外的新的倒序索引)将被写到磁盘 一个新的提交点(commit point)被写入磁盘,将包含新的segment的名称。 磁盘fsync,所有在内核文件系统中的数据等待被写入到磁盘,来保障它们被物理写入。
3.新的segment被打开,使它包含的文档可以被索引。
4.内存中的buffer将被清理,准备接收新的文档。
当一个新的请求来时,会遍历所有的segments。词条分析程序会聚合所有的segments来保障每个文档和词条相关性的准确。通过这种方式,新的文档轻量的可以被添加到对应的索引中。
删除和更新
segments是不变的,所以文档不能从旧的segments中删除,也不能在旧的segments中更新来映射一个新的文档版本。取之的是,每一个提交点都会包含一个.del文件,列举了哪一个segmen的哪一个文档已经被删除了。 当一个文档被”删除”了,它仅仅是在.del文件里被标记了一下。被”删除”的文档依旧可以被索引到,但是它将会在最终结果返回时被移除掉。
文档的更新同理:当文档更新时,旧版本的文档将会被标记为删除,新版本的文档在新的segment中建立索引。也许新旧版本的文档都会本检索到,但是旧版本的文档会在最终结果返回时被移除。
实时索引
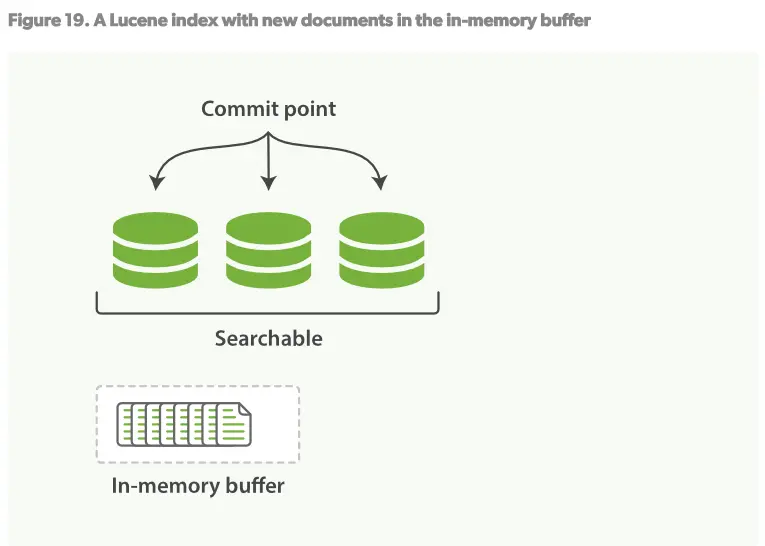
在上述的per-segment搜索的机制下,新的文档会在分钟级内被索引,但是还不够快。 瓶颈在磁盘。将新的segment提交到磁盘需要fsync来保障物理写入。但是fsync是很耗时的。它不能在每次文档更新时就被调用,否则性能会很低。 现在需要一种轻便的方式能使新的文档可以被索引,这就意味着不能使用fsync来保障。 在ES和物理磁盘之间是内核的文件系统缓存。之前的描述中,Figure19,Figure20,在内存中索引的文档会被写入到一个新的segment。但是现在我们将segment首先写入到内核的文件系统缓存,这个过程很轻量,然后再flush到磁盘,这个过程很耗时。但是一旦一个segment文件在内核的缓存中,它可以被打开被读取。

更新持久化
不使用fsync将数据flush到磁盘,我们不能保障在断电后或者进程死掉后数据不丢失。ES是可靠的,它可以保障数据被持久化到磁盘。 在2.6.2中,一个完全的提交会将segments写入到磁盘,并且写一个提交点,列出所有已知的segments。当ES启动或者重新打开一个index时,它会利用这个提交点来决定哪些segments属于当前的shard。 如果在提交点时,文档被修改会怎么样?不希望丢失这些修改:
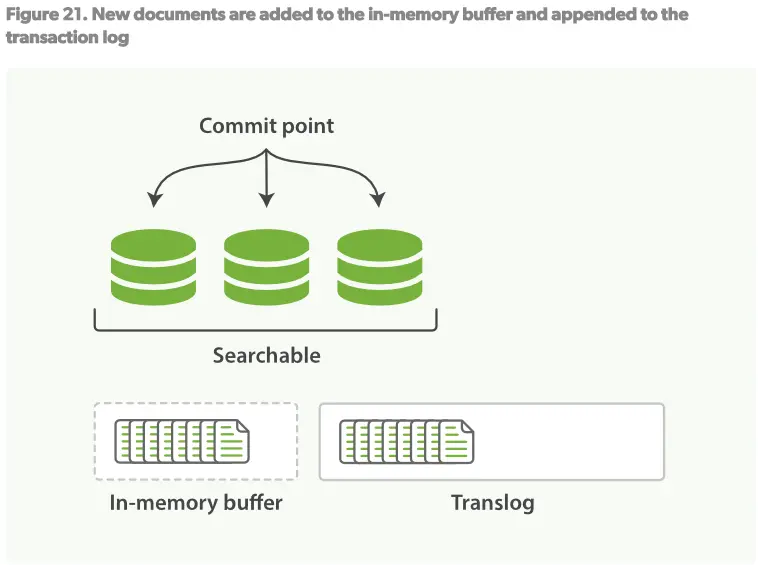
1.当一个文档被索引时,它会被添加到in-memory buffer,并且添加到Translog日志中,见Figure21.
2.refresh操作会让shard处于Figure22的状态:每秒中,shard都会被refreshed:
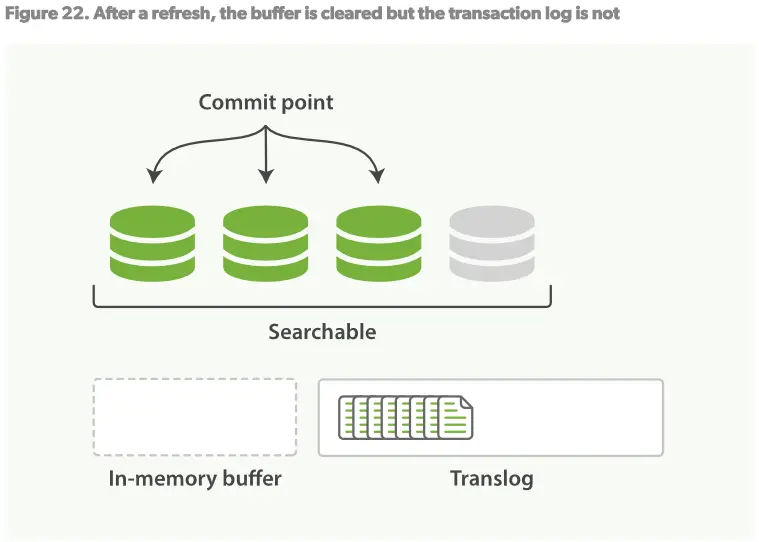
在in-memory buffer中的文档会被写入到一个新的segment,但没有fsync。
in-memory buffer被清空
3.这个过程将会持续进行:新的文档将被添加到in-memory buffer和translog日志中,见Figure23
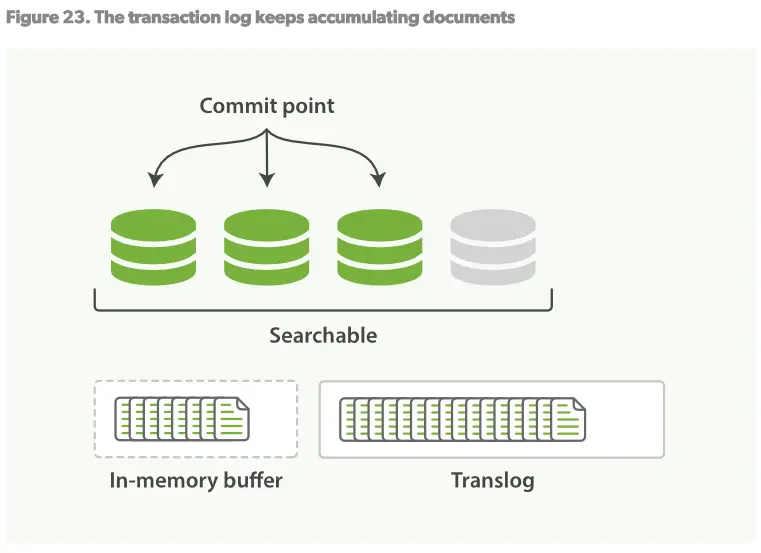
4.一段时间后,当translog变得非常大时,索引将会被flush,新的translog将会建立,一个完全的提交进行完毕。见Figure24
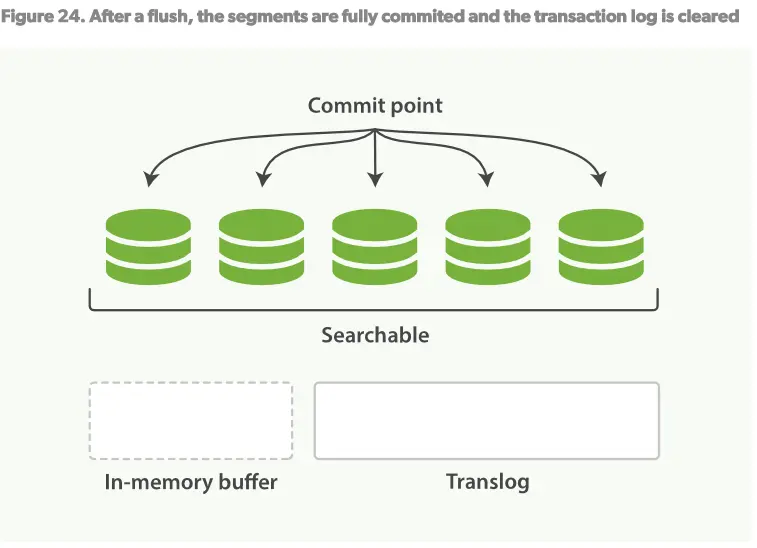
在in-memory中的所有文档将被写入到新的segment
内核文件系统会被fsync到磁盘。
旧的translog日志被删除
translog日志提供了一个所有还未被flush到磁盘的操作的持久化记录。当ES启动的时候,它会使用最新的commit point从磁盘恢复所有已有的segments,然后将重现所有在translog里面的操作来添加更新,这些更新发生在最新的一次commit的记录之后还未被fsync。
translog日志也可以用来提供实时的CRUD。当你试图通过文档ID来读取、更新、删除一个文档时,它会首先检查translog日志看看有没有最新的更新,然后再从响应的segment中获得文档。这意味着它每次都会对最新版本的文档做操作,并且是实时的。
Segment合并
通过每隔一秒的自动刷新机制会创建一个新的segment,用不了多久就会有很多的segment。segment会消耗系统的文件句柄,内存,CPU时钟。最重要的是,每一次请求都会依次检查所有的segment。segment越多,检索就会越慢。
ES通过在后台merge这些segment的方式解决这个问题。小的segment merge到大的,大的merge到更大的。。。
这个过程也是那些被”删除”的文档真正被清除出文件系统的过程,因为被标记为删除的文档不会被拷贝到大的segment中。
合并过程如Figure25:
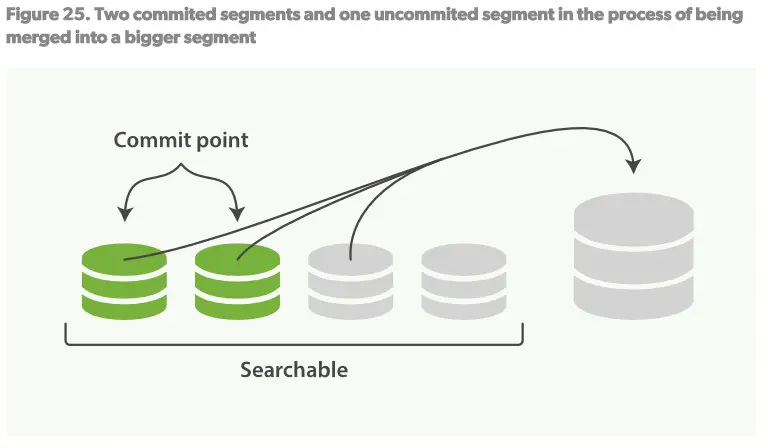
1.当在建立索引过程中,refresh进程会创建新的segments然后打开他们以供索引。
2.merge进程会选择一些小的segments然后merge到一个大的segment中。这个过程不会打断检索和创建索引。
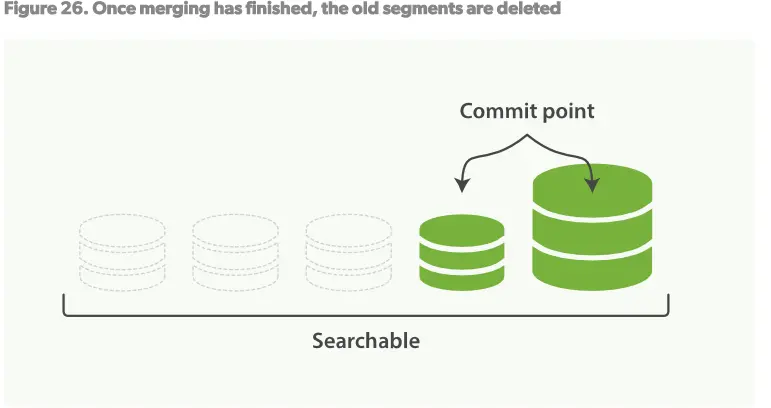
3.Figure26,一旦merge完成,旧的segments将被删除
- 新的segment被flush到磁盘
- 一个新的提交点被写入,包括新的segment,排除旧的小的segments
- 新的segment打开以供索引
- 旧的segments被删除
merge大的segments会消耗大量的I/O和CPU,严重影响索引性能。默认,ES会节制merge过程来给留下足够多的系统资源。
近实时搜索,段数据刷新,数据可见性更新和事务日志
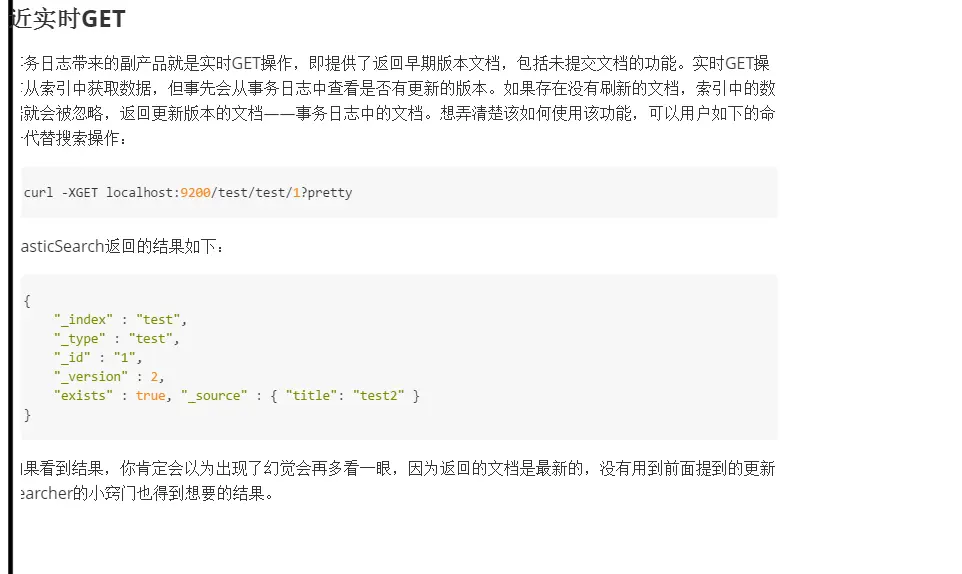
理想的搜索解决方案是这样的:新的数据一添加到索引中立马就能搜索到。第一眼看上去,这不正是ElasticSearch的工作方式吗,即使是多服务器环境也是如此。但是真实情况不是这样的(至少现在不是),后面会讲到为什么它是似是而非。首先,我们往新创建的索引中添加一个新的文档,命令如下:
curl -XPOST localhost:9200/test/test/1 -d '{ "title": "test" }'
接下来,我们在替换文档的同时查找该文档。我们用如下的链式命令来实现这一点:
curl -XPOST localhost:9200/test/test/1 -d '{ "title": "test2" }' ; curl
localhost:9200/test/test/_search?pretty
上面命令的结果类似如下:
{"ok":true,"_index":"test","_type":"test","_id":"1","_version":2}
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"failed" : 0},"hits" : {"total" : 1,"max_score" : 1.0,"hits" : [ {"_index" : "test","_type" : "test","_id" : "1","_score" : 1.0, "_source" : { "title": "test" }} ]}
}
第一行是第一个命令,即索引命令的返回结果。可以看到,数据更新成功。因此,第二个命令,即查询命令查询到的文档title域值应该为test2。但是,可以看到结果并不如人所愿。这背后发生了什么呢?
在揭开前一个问题的答案之前,我们先退一步,来了解底层的Apache Lucene工具包是如何让新添加的文档对搜索可见的。
更新索引并且将改动提交
从 第1章 介绍ElasticSearch 的 介绍Apache Lucene一节中,我们已经了解到,在索引过程中,新添加的文档都是写入到段(segments)中。每个段都是有着独立的索引结构,这意味着查询与索引两个过程是可以并行存在的,索引过程中,系统会不定期创建新的段。Apache Lucene通过在索引目录中创建新的segments_N文件来标识新的段。段创建的过程就称为索引的提交。Lucene可以一种安全的方式实现索引的提交——我们可以确定段文件要么全部创建成功,要么失败。如果错误发生,我们可以确保索引状态的一致性。
回到我们的例子中,第一条命令添加文档到索引中,但是没有提交。这就是它的工作方式。然而,索引数据的提交也不能保证数据是搜索可见的。Lucene工具包使用一个名为Searcher的抽象类来读取索引。索引提交操作完成后,Searcher对象需要重新打开才能加载到新创建的索引段。这整个过程称为更新。出于性能的考虑,ElasticSearch会将推迟开销巨大的更新操作,默认情况下,单个文档的添加并不会触发搜索器的更新,Searcher对象会每秒更新一次。这个频率已经比较高了,但是在一些应用程序中,需要更频繁的更新。对面这个需求,我们可以考虑使用其它的解决方案或者再次核实我们是否真的需要这样做。如果确实需要,那么可以使用ElasticSearch API强制更新。比如,上面的例子中,我们可以执行如下的命令强制更新:
curl –XGET localhost:9200/test/_refresh
如果在搜索前执行了上面的命令,那么ElasticSearch就可以搜索到修改后的文档。
修改Searcher对象默认的更新时间
Searcher对象的默认更新时间可以通过使用index.refresh_interval参数来修改,该参数无论是添加到ElasticSearch的配置文件中或者使用update settings API都可以生效。例如:
curl -XPUT localhost:9200/test/_settings -d '{"index" : {"refresh_interval" : "5m"}
}'
上面的命令将使Searcher每5秒钟自动更新一次。请记住在更新两个时间点之间添加到索引的数据对查询是不可见的。

总结
本篇从索引的创建操作和原理等方面介绍了ES索引的一些内容,很多都来自各位大神的总结。经过使用ES越来越多开始作为数据库的辅助。希望大家多多指点。
相关文章:
【ES】Elasticsearch-深入理解索引原理
文章目录Elasticsearch-深入理解索引原理读操作更新操作SHARD不变性动态更新索引删除和更新实时索引更新持久化Segment合并近实时搜索,段数据刷新,数据可见性更新和事务日志更新索引并且将改动提交修改Searcher对象默认的更新时间Elasticsearch-深入理解…...
pdf压缩文件大小的方法是什么?word文件怎么批量转换成pdf格式?
大家在存储文件时,通常会遇到一些较大的文件,这时需要对其进行压缩处理。下面介绍一下如何压缩PDF文件大小以及批量转换Word文件为PDF格式。pdf压缩文件大小的方法是什么?1.打开小圆象PDF转换器,选择“PDF压缩”功能。2.在“PDF压缩”界面中…...
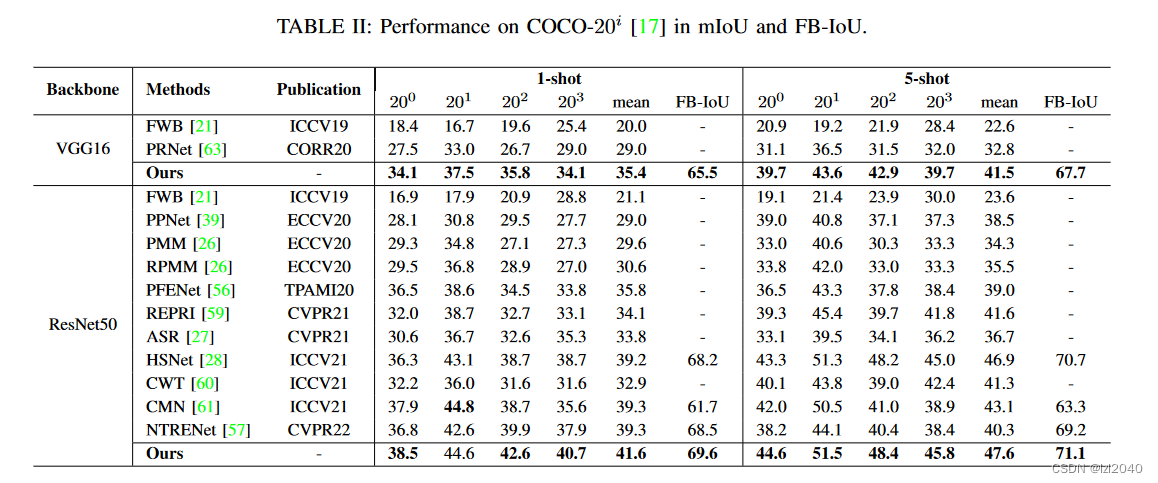
论文阅读——FECANet:应用特征增强的上下文感知小样本语义分割网络
代码:NUST-Machine-Intelligence-Laboratory/FECANET (github.com) 文章地址:地址 文章名称:FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network 摘要 Few-shot semantic segmentation 是学习…...
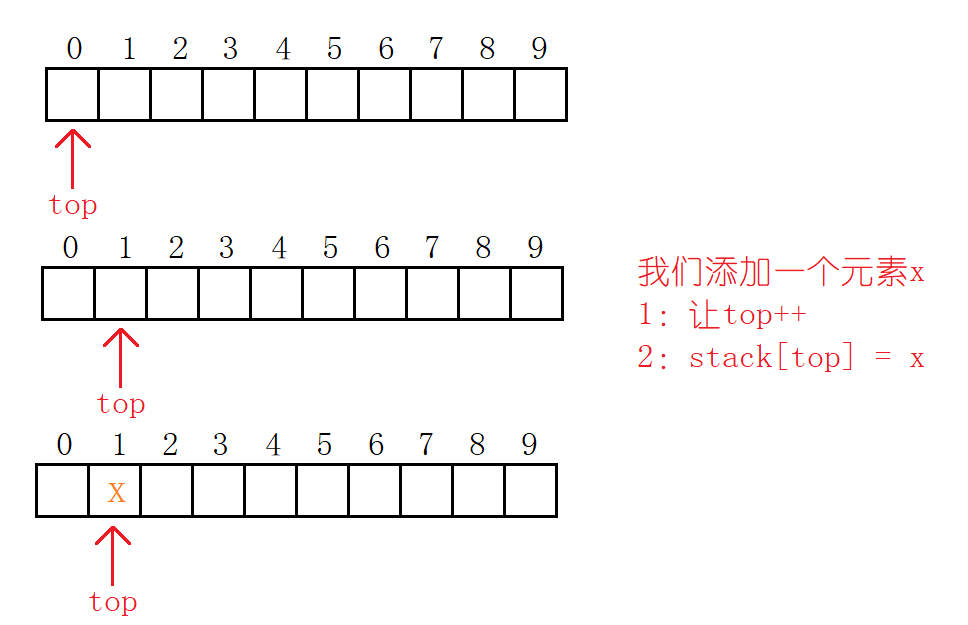
数组模拟常见数据结构
我们来学习一下用数组模拟常见的数据结构:单链表,双链表,栈,队列。用数组模拟这些常见的数据结构,需要我们对这些数据结构有一定的了解哈。单链表请参考:http://t.csdn.cn/SUv8F 用数组模拟实现比STL要快&a…...
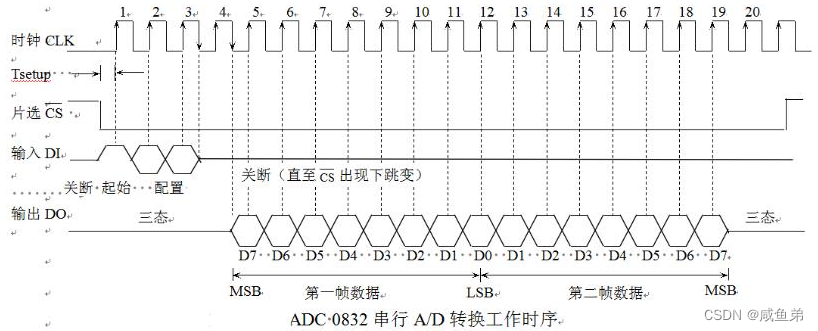
ADC0832的AD模数转换原理及编程
✅作者简介:嵌入式领域优质创作者,博客专家 ✨个人主页:咸鱼弟 🔥系列专栏:单片机设计专栏 📃推荐一款求职面试、刷题神器👉注册免费刷题 目录 一、描述 二、模数转换原理: 三、…...
【工具插件类教学】UnityPackageManager私人定制资源工具包
目录 一.UnityPackageManager的介绍 二.package包命名 三.包的布局 四.生成清单文件 五.制作package内功能 六.为您的软件包撰写文档 1.信息的结构 2.文档格式 七.提交上传云端仓库 1.生成程序集文件 2.上传至云端仓库 八.下载使用package包 1.获取包的云端路径 …...
【软件测试】2023年了还不会接口测试?老鸟总结接口测试面试谁还敢说我不会......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 测试面试࿰…...

类Vuex轻量级状态管理实现
引用自 摸鱼wiki 1. vuex vuex是一个前端广泛流行的状态管理库,主要由以下几大模块组成: state:状态存储getter:属性访问器mutation:可以理解为一个同步的原子性事务,修改state状态action:触发…...

Java 基本数据类型
Java基本数据类型是Java编程语言中最基本的数据类型,包括整型、浮点型、字符型、布尔型和空类型。本文将详细介绍Java基本数据类型的作用和在实际工作中的用途。 整型(int、long、short、byte) 整型是Java中最常见的基本数据类型࿰…...

全网资料最全Java数据结构与算法-----算法分析
算法分析 研究算法的最终目的就是如何花更少的时间,如何占用更少的内存去完成相同的需求,并且也通过案例演示了不同算法之间时间耗费和空间耗费上的差异,但我们并不能将时间占用和空间占用量化,因此,接下来我们要学习…...

【封装xib补充 Objective-C语言】
一、那么首先,咱们就从这个结果来分析 1.就不给大家一步一步分析了,直接分析我们这里怎么想的, 首先,我们看到这样的一个界面,我们想,这些应用数据是不是来源于一个plist文件吧, 所以说,我们首先要,第一步,要懒加载,把这个plist文件中的数据,加载起来, 那么,因…...
linux + jenkins + svn + maven + node 搭建及部署springboot多模块前后端服务
linux搭建jenkins 基础准备 linux配置jdk、maven,配置系统配置文件 vi /etc/profile配置jdk、maven export JAVA_HOME/usr/java/jdk1.8.0_261-amd64 export CLASSPATH.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport MAVEN_H…...
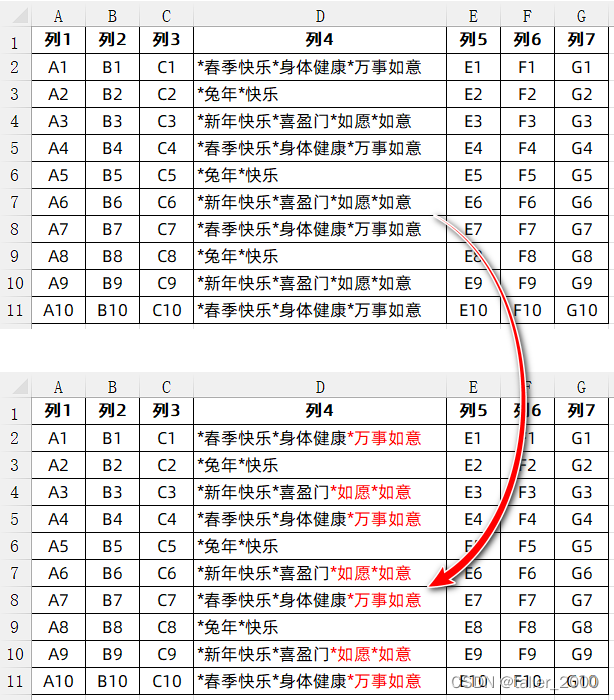
VBA之正则表达式(41)-- 快速标记两个星号之后的字符
实例需求:工作表中的数据保存在A列~G列,现需要识别D列中包含超过两个星号的内容,并将第3个星号及其之后的字符设置为红色字体,如图所示。 示例代码如下。 Sub Demo1()Dim objRegExp As ObjectDim objMatch As ObjectDim strMatch…...

VMware16安装MacOS【详细教程】
安装VMware workstation 双击安装包,然后一直下一步就行了。 进行VMware安装,一直 下一步 在输入产品密钥这一步,如果有查找到可用密钥就填进去,没有就跳过,进入软件后也能输入密钥的。 输入密钥。 最后一步ÿ…...
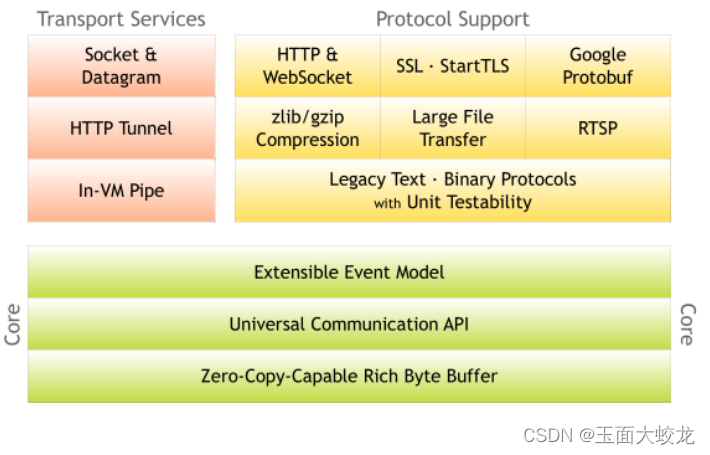
Netty学习(一):Netty概述
一、原生NIO存在的问题 NIO 的类库和API繁杂,使用麻烦:需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等。需要具备其他的额外技能:要熟悉Java 多线程编程,因为NIO编程涉及到Reactor 模式,你必须对多线程和网络编程…...
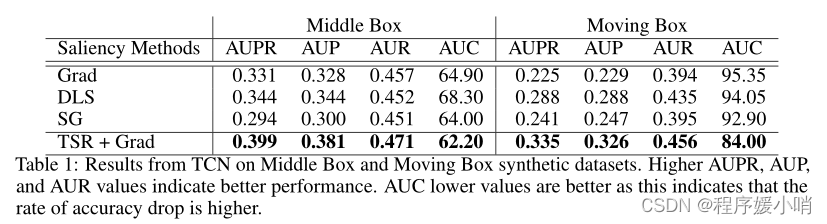
【论文精读】Benchmarking Deep Learning Interpretability in Time Series Predictions
【论文精读】Benchmarking Deep Learning Interpretability in Time Series Predictions Abstract Saliency methods are used extensively to highlight the importance of input features in model predictions. These methods are mostly used in vision and language task…...
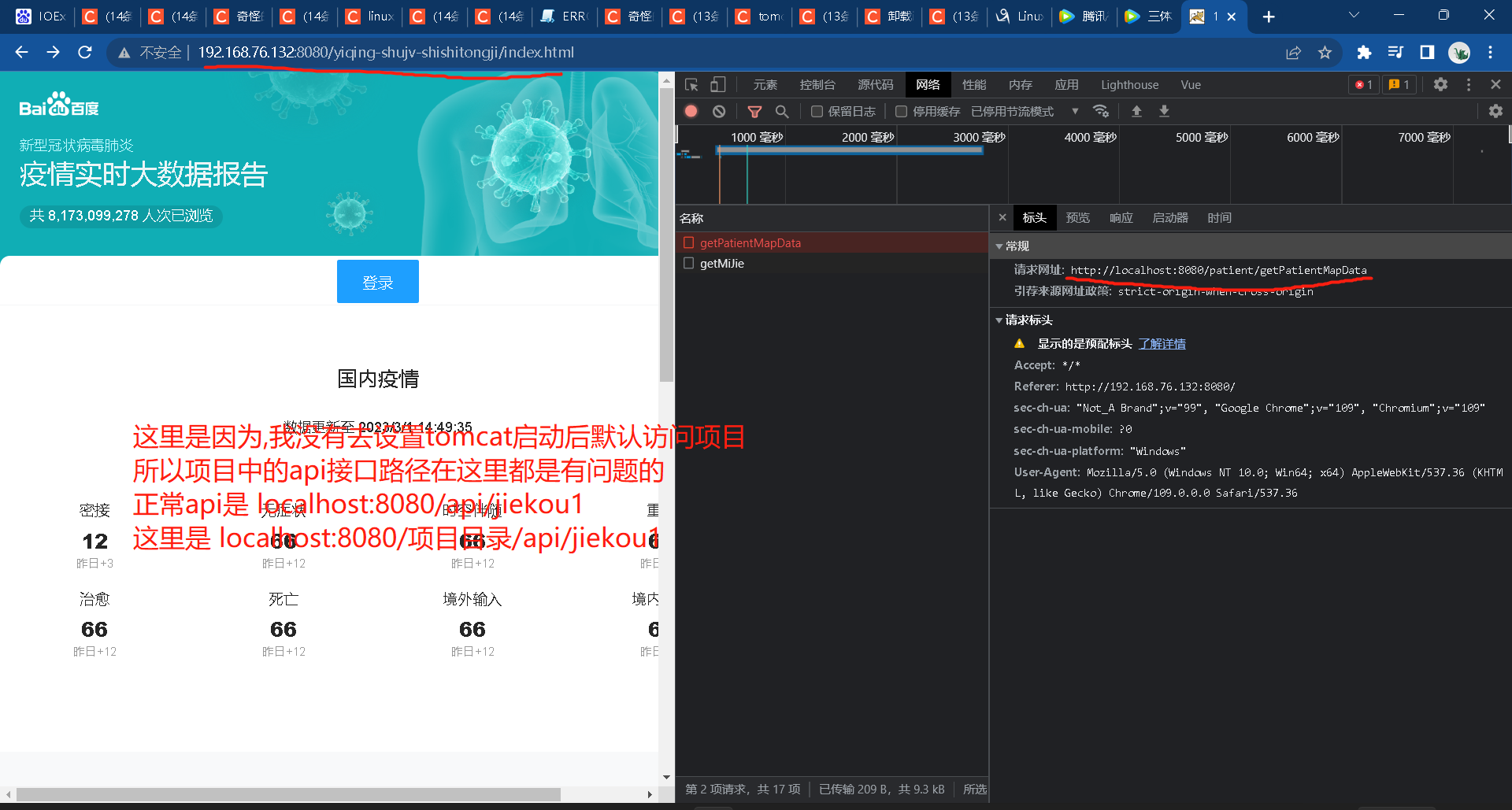
自己第一次在虚拟机完整部署ssm项目心得体会
过程使用资源和博文 琳哥发的linux课件文档,阳哥发的linux课件文档(私聊我要) https://www.likecs.com/show-205274015.html https://www.cnblogs.com/aluoluo/articles/15845183.html https://blog.csdn.net/osfipin/article/details/54405445 https://blog.csdn.net/drea…...

操作系统权限提升(二十二)之Linux提权-SUDO滥用提权
系列文章 操作系统权限提升(十八)之Linux提权-内核提权 操作系统权限提升(十九)之Linux提权-SUID提权 操作系统权限提升(二十)之Linux提权-计划任务提权 操作系统权限提升(二十一)之Linux提权-环境变量劫持提权 SUDO滥用提权 SUDO滥用提权原理 sudo是linux系统管理指令&…...

操作系统权限提升(二十四)之Linux提权-明文ROOT密码提权
系列文章 操作系统权限提升(十八)之Linux提权-内核提权 操作系统权限提升(十九)之Linux提权-SUID提权 操作系统权限提升(二十)之Linux提权-计划任务提权 操作系统权限提升(二十一)之Linux提权-环境变量劫持提权 操作系统权限提升(二十二)之Linux提权-SUDO滥用提权 操作系统权限…...

Linux基本命令复习-面试急救版本
1、file 通过探测文件内容判断文件类型,使用权是所有用户, file[options]文件名2、mkdir/rmdir 创建文件目录(文件夹)/删除文件目录 3、grep 指定文件中搜索的特定内容 4、find 通过文件名搜索文件 find name 文件名 5、ps 查…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...