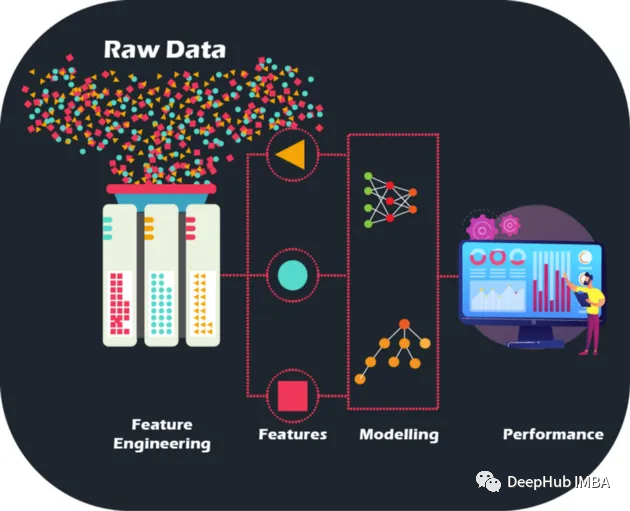
使用手工特征提升模型性能
本文将使用信用违约数据集介绍手工特征的概念和创建过程。
通过对原始数据进行手工的特征工程,我们可以将模型的准确性和性能提升到新的水平,为更精确的预测和更明智的业务决策铺平道路, 可以以前所未有的方式优化模型并提升业务能力。

原始数据就像一个没有图片的拼图游戏——但通过特征工程,我们可以将这些碎片拼在一起,虽然拥有大量数据确实是寻求建立机器学习模型的金融机构的宝库,但同样重要的是要承认并非所有数据都提供信息。并且手工特征是人工设计出来,每一步操作能够说出理由,也带来了可解释性。
特征工程不仅仅是选择最好的特征。它还涉及减少数据中的噪音和冗余,以提高模型的泛化能力。这是至关重要的,因为模型需要在看不见的数据上表现良好才能真正有用。
数据集描述
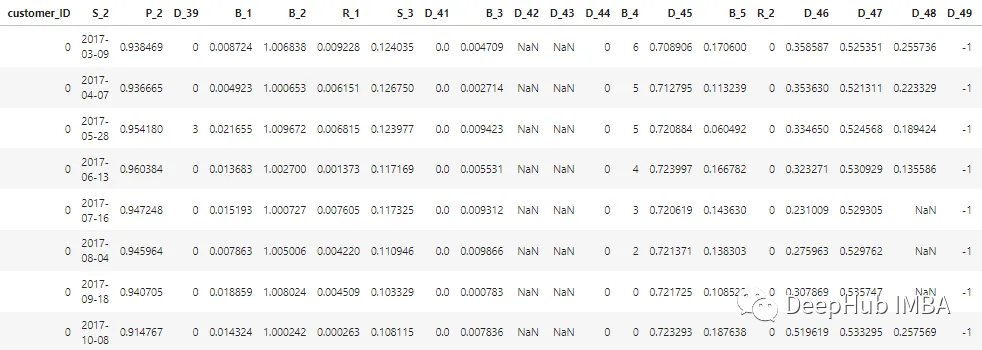
本文中描述的数据集经过匿名处理和屏蔽,以维护客户数据的机密性。特征可分类如下:
D_* = 拖欠变量S_* = 支出变量P_* = 支付变量B_* = 平衡变量R_* = 风险变量
总共有 100 个整数特征和 100 个浮点特征代表过去 12 个月客户的状态。该数据集包含有关客户报表的信息,从 1 到 13 不等。客户的每张信用卡报表之间可能有 30 到 180 天的间隔(即客户的信用卡报表可能缺失)。每个客户都由一个客户 ID 表示。customer_ID=0的客户前5条的样本数据如下所示:
在 700 万个 customer_ID 中,98% 的标签为“0”(好客户,无默认),2% 的标签为“1”(坏客户,默认)。
数据集很大,所以我们使用cudf来加速处理,如果你没有安装cudf,那么使用pandas也是一样的
# LOAD LIBRARIESimport pandas as pd, numpy as np # CPU librariesimport cudf # GPU librariesimport matplotlib.pyplot as plt, gc, osdf = cudf.read_parquet('./data.parquet')
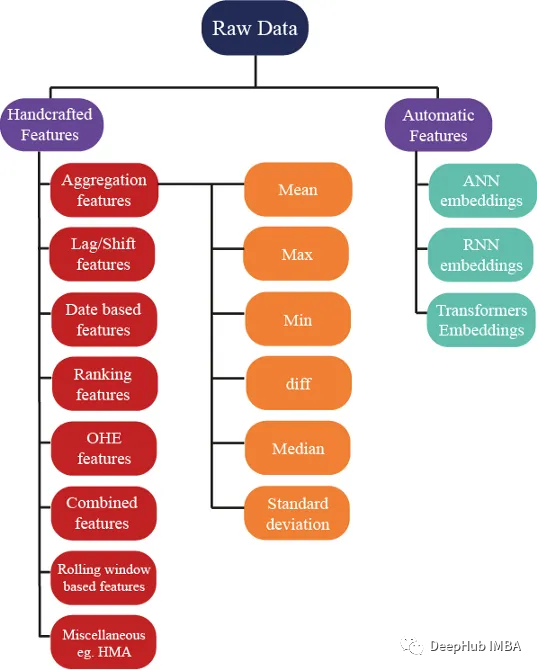
特征生成方法
有数百种想法可用于生成特征;但是我们还确保这些特征有助于提高模型的性能,下图显示了特征工程中使用的一些基本方法:
聚合特征
聚合是理解复杂数据的秘诀。通过计算分类分组变量(如 customer_ID (C_ID) 或产品类别)的汇总统计数据或数值变量的聚合,我们可以发现一些不可见的模式和趋势。借助均值、最大值、最小值、标准差和中值等汇总统计数据,我们可以构建更准确的预测模型,并从客户数据、交易数据或任何其他数值数据中提取有意义的见解。
可以计算每个客户的这些统计属性
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]num_features = [col for col in all_cols if col not in cat_features] #all features accept cateforical features.test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerIDtest_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]
均值:一个数值变量的平均值,可以给出数据集中趋势的一般意义。平均值可以捕获:
客户拥有的平均银行余额。
- 平均客户支出。
- 两个信用报表之间的平均时间(信用付款之间的时间)。
- 借钱的平均风险。
标准偏差 (Std):衡量数据围绕均值的分布情况,可以深入了解数据的变异程度。余额的高度可变性表明客户有消费。
最小值和最大值可以捕获客户的财富,也可以捕获有关客户支出和风险的信息。
中位数:当数据高度倾斜时,使用平均值并不是一个更好的主意,因此可以使用中值(可以使用数值的中间值。
最新值可能是最重要的特征,因为它们包含有关发布给客户的最新已知信用声明的信息,也就表明目前客户账户的最新状态。
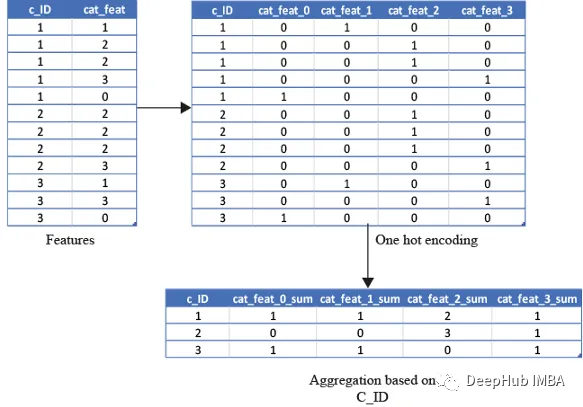
独热编码
对分类变量使用上述统计属性是不明智的,因为计算最小值、最大值或标准偏差并不能给我们任何有用的信息。那么我们应该怎么做呢?可以使用像count这样的特征,和唯一的数量来计算特征,最新的值也可以使用
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]
但是这些信息不会捕获客户是否被归类到特定的类别中。所以我们通过对变量进行独热编码,然后对变量(例如均值、总和和最后)进行聚合来实现。
平均值将捕获客户属于该类别的总次数/银行对帐单总数的比率。总和将只是客户属于该类别的总次数。
from cuml.preprocessing import OneHotEncoderdf_categorical = df_last[cat_features].astype(object)ohe = OneHotEncoder(drop='first', sparse=False, dtype=np.float32, handle_unknown='ignore')ohe.fit(df_categorical)with open("ohe.pickle", 'wb') as f: pickle.dump(ohe, f) #save the encoder so that it can be used for test data as well df_categorical = pd.DataFrame(ohe.transform(df_categorical).astype(np.float16),index=df_categorical.index).rename(columns=str)df_categorical['customer_ID']=df['customer_ID']df_categorical.groupby('customer_ID').agg(['mean', 'sum', 'last'])
基于排名的特征
在预测客户行为方面,基于排名的特征是非常重要的。通过根据收入或支出等特定属性对客户进行排名,我们可以深入了解他们的财务习惯并更好地管理风险。
使用 cudf 的 rank 函数,我们可以轻松计算这些特征并使用它们来为预测提供信息。例如,可以根据客户的消费模式、债务收入比或信用评分对客户进行排名。然后这些特征可用于预测违约或识别有可能拖欠付款的客户。
基于排名的特征还可用于识别高价值客户、目标营销工作和优化贷款优惠。例如,可以根据客户接受贷款提议的可能性对客户进行排名,然后将排名最高的客户作为目标。
df[feat+'_rank']=df[feat].rank(pct=True, method='min')
PCT用于是否做百分位排名。客户的排名也可以基于分类特征来计算。
df[feat+'_rank']=df.groupby([cat_feat]).rank(pct=True, method='min')
特征组合
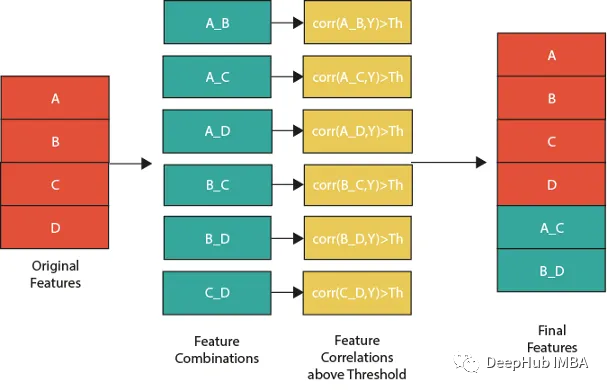
特征组合的一种流行方法是线性或非线性组合。这包括采用两个或多个现有特征,将它们组合在一起创建一个新的复合特征。然后使用这个复合特征来识别单独查看单个特征时可能不可见的模式、趋势和相关性。
例如,假设我们正在分析客户消费习惯的数据集。可以从个人特征开始,比如年龄、收入和地点。但是通过以线性或非线性的方式组合这些特性,可以创建新的复合特性,使我们能够更多地了解客户。可以结合收入和位置来创建一个复合特征,该特征告诉我们某一地区客户的平均支出。
但是并不是所有的特征组合都有用。关键是要确定哪些组合与试图解决的问题最相关,这需要对数据和问题领域有深刻的理解,并仔细分析创建的复合特征和试图预测的目标变量之间的相关性。
下图展示了一个组合特征并将信息用于模型的过程。作为筛选条件,这里只选择那些与目标相关性大于最大值 0.9 的特征。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]for feat1 in features:for feat2 in features:th=max(np.corr(feat1,Y)[0],np.corr(feat1,Y)[0]) #calculate thresholdfeat3=df[feat1]-df[feat2] #difference featurecorr3=np.corr(feat3,Y)[0]if(corr3>max(th,0.9)): #if correlation greater than max(th,0.9) we add it as featuredf[feat1+'_'+feat2]=feat3
基于时间/日期的特征
在数据分析方面,基于时间的特征非常重要。通过根据时间属性(例如月份或星期几)对数据进行分组,可以创建强大的特征。这些特征的范围可以从简单的平均值(如收入和支出)到更复杂的属性(如信用评分随时间的变化)。
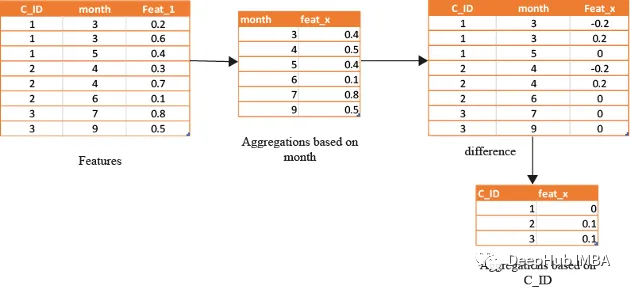
借助基于时间的特征,还可以识别在孤立地查看数据时可能看不到的模式和趋势。下图演示了如何使用基于时间的特征来创建有用的复合属性。
首先,计算一个月内的值的平均值(可以使用该月的某天或该月的某周等),将获得的DF与原始数据合并,并取各个特征之间的差。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]month_Agg=df.groupby([month])[features].agg('mean')#grouping based on month featuremonth_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]month_Agg.reset_index(inplace=True)df=df.groupby(month_Agg,on='month')for feat in features: #create composite features b taking differencedf[feat+'_'+feat+'_month_mean']=df[feat]-df[feat+'_month_mean']
还可以通过使用时间作为分组变量来创建基于排名的特征,如下所示
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]month_Agg=df.groupby([month])[features].rank(pct=True) #grouping based on month featuremonth_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]month_Agg.reset_index(inplace=True)df=pd.concat([df,month_Agg],axis=1) #concat to original dataframe
滞后特征
滞后特征是有效预测金融数据的重要工具。这些特征包括计算时间序列中当前值与之前值之间的差值。通过将滞后特征纳入分析,可以更好地理解数据中的模式和趋势,并做出更准确的预测。
如果滞后特征显示客户连续几个月按时支付信用卡账单,可能会预测他们将来不太可能违约。相反,如果延迟特征显示客户一直延迟或错过付款,可能会预测他们更有可能违约。
# difference function calculate the lag difference for numerical features #between last value and shift last value.def difference(groups,num_features,shift):data=(groups[num_features].nth(-1)-groups[num_features].nth(-1*shift)).rename(columns={f: f"{f}_diff{shift}" for f in num_features})return data#calculate diff features for last -2nd last, last -3rd last, last- 4th lastdef get_difference(data,num_features):print("diff features...")groups=data.groupby('customer_ID')df1=difference(groups,num_features,2).fillna(0)df2=difference(groups,num_features,3).fillna(0)df3=difference(groups,num_features,4).fillna(0)df1=pd.concat([df1,df2,df3],axis=1)df1.reset_index(inplace=True)df1.sort_values(by='customer_ID')del df2,df3gc.collect()return df1train_diff = get_difference(df, num_features)
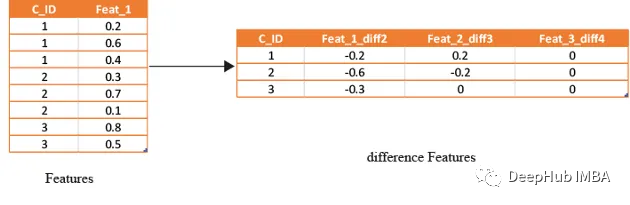
基于滚动窗口的特性
这些特征只是取最后3(4,5,…x)值的平均值,这取决于数据,因为基于时间的最新值携带了关于客户最新状态的信息。
xth=3 #define the window sizedf["cumulative"]=df.groupby('customer_ID').sort_values(by=['time'],ascending=False).cumcount()last_info=df[df["cumulative"]<=xth]last_info = last_info.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerIDlast_info.columns = ['_'.join(x) for x in last_info.columns]
其他的特征提取方法
上面的方法已经创建了足够多的特征来构建一个很棒的模型。但是根据数据的性质,还可以创建更多的特征。例如:可以创建像null计数这样的特征,它可以计算客户当前的总null值,从而帮助捕获基于树的算法无法理解的特征分布。
def calc_nan(df,features):print("calculating nan_info...")df_nan = (df[features].mul(0) + 1).fillna(0) #marke non_null values as 1 and null as zerodf_nan['customer_ID'] = df['customer_ID']nan_sum = df_nan.groupby("customer_ID").sum().sum(axis=1) #total unknown values for a customernan_last = df_nan.groupby("customer_ID").last().sum(axis=1)#how many last values that are not knowndel df_nangc.collect()return nan_sum,nan_last
这里可以不使用平均值,而是使用修正的平均值,如基于时间的加权平均值或 HMA(hull moving average)。
总结
在本文中介绍了一些在现实世界中用于预测违约风险的最常见的手工特性策略。但是总是有新的和创新的方法来设计特征,并且手工设置特征的方法是费时费力的,所以我们将在后面的文章中介绍如何实用工具进行自动的特征生成。
https://avoid.overfit.cn/post/2740ca61afb3438dbb8ab36b2250f37e
作者:Priyanshu Chaudhary
相关文章:
使用手工特征提升模型性能
本文将使用信用违约数据集介绍手工特征的概念和创建过程。 通过对原始数据进行手工的特征工程,我们可以将模型的准确性和性能提升到新的水平,为更精确的预测和更明智的业务决策铺平道路, 可以以前所未有的方式优化模型并提升业务能力。 原始…...
【运维有小邓】Oracle数据库审计
一些机构通常将客户记录、信用卡信息、财务明细之类的机密业务数据存储在Oracle数据库服务器中。这些数据存储库经常因为内部安全漏洞和外部安全漏洞而受到攻击。对这类敏感数据的任何损害都可能严重降低客户对机构的信任。因此,数据库安全性对于任何IT管理员来说都…...

JDK下载安装与环境
🥲 🥸 🤌 🫀 🫁 🥷 🐻❄️🦤 🪶 🦭 🪲 🪳 🪰 🪱 🪴 🫐 🫒 🫑…...

FPGA纯verilog代码实现4路视频缩放拼接 提供工程源码和技术支持
目录1、前言2、目前主流的FPGA图像缩放方案3、目前主流的FPGA视频拼接方案4、本设计方案的优越性5、详细设计方案解读HDMI输入图像缩放图像缓存VGA时序HDMI输出6、vivado工程详解7、上板调试验证8、福利:工程源码获取1、前言 本文详细描述了FPGA纯verilog代码实现4…...
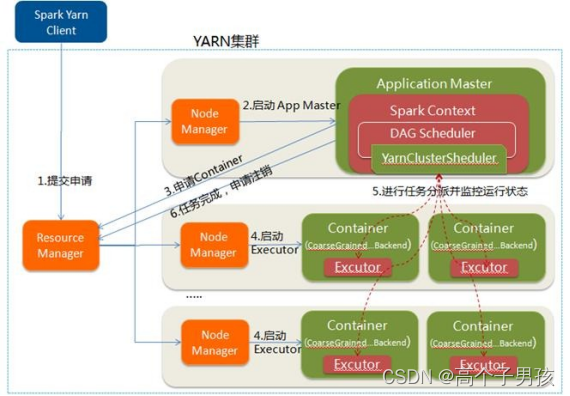
Spark on YARN运行过程,YARN-Client和YARN-Cluster
Spark on YARN运行过程 YARN是一种统一资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapRed…...
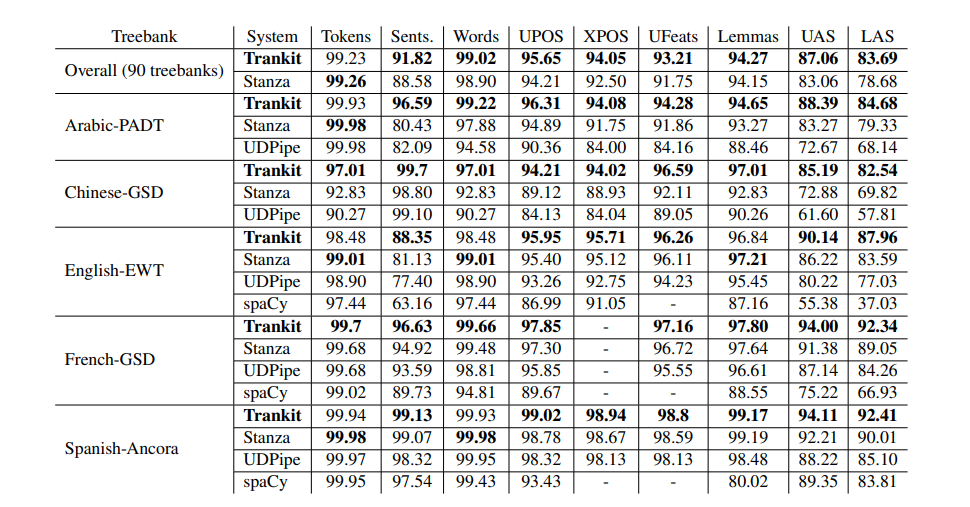
NLP中一些工具列举
文章目录StanfordcoreNLPStanzaTankitspaCySuPar总结StanfordcoreNLP 这个老早就出来了,用java写的,但是已经有很多比他效果好的了。 Stanza 2020ACL发表的,看名字就知道和上一个是同一家的。 用已经切好词的句子进行依存分析。 这个功能…...

面试官:给你一段有问题的SQL,如何优化?
大家好,我是飘渺!我在面试的时候很喜欢问候选人这样一个问题:“你在项目中遇到过慢查询问题吗?你是怎么做SQL优化的?”很多时候,候选人会直接跟我说他们在编写SQL时会遵循的一些常用技巧,比如&a…...

嵌入式 Linux 文件IO操作
目录 Linux 文件操作 1 Linux 系统环境文件操作概念 2 缓冲 IO 文件操作 1 文件的创建,打开与关闭 fopen 函数函数 2 freopen 函数 3、fdopen函数 4、fclose函数 5、格式化读写 6、单个字符读写 7、文件定位 8、标准目录文件 9、非缓冲IO文件操作 Linux 文…...
植物大战 二叉搜索树——C++
这里是目录标题二叉排序树的概念模拟二叉搜索树定义节点类insert非递归Finderase(重点)析构函数拷贝构造(深拷贝)赋值构造递归FindRInsertR二叉搜索树的应用k模型KV模型二叉排序树的概念 单纯的二叉树存储数据没有太大的作用。 搜索二叉树作用很大。 搜索二叉树的一般都是用…...

[MatLab]矩阵运算和程序结构
一、矩阵 1.定义 矩阵以[ ]包含,以空格表示数据分隔,以;表示换行。 A [1 2 3 4 5 6] B 1:2:9 %1-9中的数,中间是步长(不能缺省) C repmat(B,3,2) %将B横向重复2次,纵向重复2次 D ones(2,4) …...

【Leedcode】栈和队列必备的面试题(第四期)
【Leedcode】栈和队列必备的面试题(第四期) 文章目录【Leedcode】栈和队列必备的面试题(第四期)一、题目二、思路图解1.声明结构体2.循环链表开辟动态结构体空间3.向循环队列插入一个元素4.循环队列中删除一个元素5. 从队首获取元…...
Windows Server 2016搭建文件服务器
1:进入系统在服务器管理器仪表盘中添加角色和功能。 2:下一步。 3:继续下一步。 4:下一步。 5:勾选Web服务器(IIS) 6:添加功能。 7:下一步。 8:下一步。 9:下一步。 10&a…...
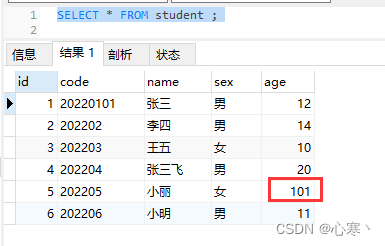
零基础学SQL(十一、视图)
目录 前置建表 一、什么是视图 二、为什么使用视图 三、视图的规则和限制 四、视图的增删改查 五、视图数据的更新 前置建表 CREATE TABLE student (id int NOT NULL AUTO_INCREMENT COMMENT 主键,code varchar(255) NOT NULL COMMENT 学号,name varchar(255) DEFAULT NUL…...
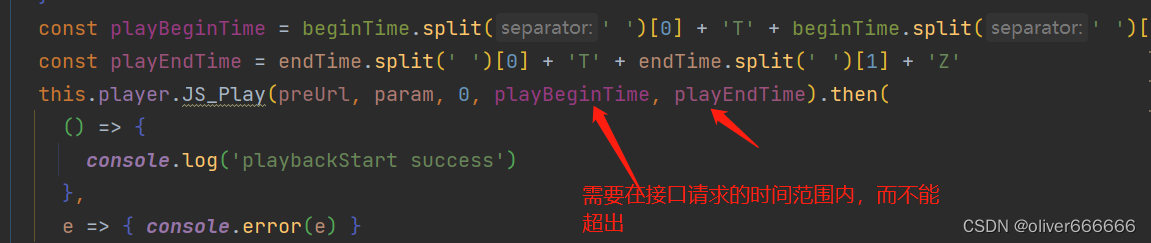
web,h5海康视频接入监控视频流记录三(后台node取流)
前端vue,接入ws视频播放 云台控制 ,回放预览,都是需要调对应的海康接口。相当于,点击时,请求后台写好的接口,接口再去请求海康的接口 调用云台控制是,操作一次,不会自己停止&#x…...
网络安全从入门到精通:30天速成教程到底有多狠?你能坚持下来么?
毫无疑问,网络安全是当下最具潜力的编程方向之一。对于许多未曾涉足计算机编程的领域「小白」来说,深入地掌握网络安全看似是一件十分困难的事。至于一个月能不能学会网络安全,这个要看个人,对于时间管理不是很高的,肯…...

世界上最流行的编程语言,用户数超过Python,Java,JavaScript,C的总和!
世界上最流行的编程语言是什么? Python? Java? JavaScript? C?都不是,是Excel!外媒估计,全球有12亿人使用微软的Office套件,其中估计有7.5亿人使用Excel!可是Excel不就是能写点儿公式&#x…...

杂谈:created中两次数据修改,会触发几次页面更新?
面试题:created生命周期中两次修改数据,会触发几次页面更新? 一、同步的 先举个简单的同步的例子: new Vue({el: "#app",template: <div><div>{{count}}</div></div>,data() {return {count…...

原生JS实现拖拽排序
拖拽(这两个字看了几遍已经不认识了) 说到拖拽,应用场景不可谓不多。无论是打开电脑还是手机,第一眼望去的界面都是可拖拽的,靠拖拽实现APP或者应用的重新布局,或者拖拽文件进行操作文件。 先看效果图&am…...

Coredump-N: corrupted double-linked list
文章目录 问题安装debuginfo之后分析参数确定确定代码逻辑解决问题 今天碰到一例: #0 0xf7f43129 in __kernel_vsyscall () #1 0xf6942b16 in raise () from /lib/libc.so.6 #2 0xf6928e64 in abort () from /lib/libc.so.6 #3 0xf6986e8c in __libc_message () from /lib/li…...

5个好用的视频素材网站
推荐五个高质量视频素材网站,免费、可商用,赶紧收藏起来! 1、菜鸟图库 视频素材下载_mp4视频大全 - 菜鸟图库 网站素材非常丰富,有平面、UI、电商、办公、视频、音频等相关素材,视频素材质量很高,全部都是…...

使用AI大大提升了学习代码的效率
最近看到一个观点,说AI的发展导致代码越来越不值钱了,AI降低了我们学习的门槛,大大提升了学习效率。好像很多程序都可以一个人一天上架一款产品。或许有夸张成分,但像我们普通人都体验到了AI的方便,比如在项目开发的过…...

Flink技术实践-超时异常踩坑与优化
一、背景介绍在Flink实时计算的生产环境中,最令人头疼的往往不是复杂的业务逻辑,而是那些突如其来的“超时异常”。这些异常就像是系统中的“幽灵”,通常在业务高峰期或网络抖动时出现,导致作业重启、数据延迟甚至数据丢失。最近几…...
)
5分钟搞定三网话费余额查询:手把手教你用PHP+HTML搭建查询系统(含API调用避坑指南)
三网话费查询系统开发实战:从API调用到前端优化的全流程指南 最近在帮朋友开发一个小型话费查询工具时,发现市面上关于三网运营商API调用的完整教程并不多见。大多数开发者遇到问题时只能靠反复试错,特别是当需要同时对接移动、联通、电信三家…...

无需编程!DouyinLiveWebFetcher让运营人员轻松实现抖音直播弹幕实时采集
无需编程!DouyinLiveWebFetcher让运营人员轻松实现抖音直播弹幕实时采集 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2024最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 如…...
)
VMware ESXi 上玩转 SmartX 超融合社区版:OVF 镜像部署全攻略(含网络配置避坑指南)
VMware ESXi 上部署 SmartX 超融合社区版:OVF 镜像实战指南 虚拟化管理员们常常面临一个现实困境:如何在有限的硬件资源下快速体验企业级超融合架构?SmartX 超融合社区版通过 OVF 镜像部署方案,为 VMware ESXi 环境提供了轻量级验…...

抖音批量下载终极指南:免费无水印视频一键获取
抖音批量下载终极指南:免费无水印视频一键获取 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 你是否曾为保存喜欢的抖音视频而烦恼?面对心仪的内容创作者,想要收藏他们的…...

Avalonia跨平台开发踩坑记:我的第一个带最小化/关闭按钮的MVVM应用
Avalonia跨平台开发实战:从零构建MVVM窗口控制应用 第一次接触Avalonia时,我被它"一次编写,多平台运行"的承诺所吸引。作为一个长期使用WPF的开发者,跨平台桌面应用开发一直是个痛点。但当我真正开始用Avalonia实现一个…...

3D打印桥接工具:从设计到输出的全流程优化
3D打印桥接工具:从设计到输出的全流程优化 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl SketchUp STL插件是连接…...
)
告别龟速滚屏!Ubuntu 20.04下用imwheel调鼠标滚轮速度(附开机自启保姆级教程)
Ubuntu 20.04终极鼠标滚轮优化指南:从基础配置到系统级调优 每次在Ubuntu上浏览长网页或翻阅代码时,那个慢如蜗牛的滚动速度是否让你抓狂?作为从Windows或macOS迁移过来的用户,这种体验落差尤为明显。鼠标滚轮响应迟缓不仅影响工作…...

信息安全毕设容易的项目选题汇总
0 选题推荐 - 网络与信息安全篇 毕业设计是大家学习生涯的最重要的里程碑,它不仅是对四年所学知识的综合运用,更是展示个人技术能力和创新思维的重要过程。选择一个合适的毕业设计题目至关重要,它应该既能体现你的专业能力,又能满…...