面试官:给你一段有问题的SQL,如何优化?
大家好,我是飘渺!
我在面试的时候很喜欢问候选人这样一个问题:“你在项目中遇到过慢查询问题吗?你是怎么做SQL优化的?”
很多时候,候选人会直接跟我说他们在编写SQL时会遵循的一些常用技巧,比如:
合理使用索引
使用UNION ALL替代UNION
不要使用select * 写法
JOIN字段建议建立索引
避免复杂SQL语句
这里不能说完全错误,因为这些技巧确实可以提高SQL运行效率;但是也不能说完全正确,毕竟我是想问他具体怎么是做SQL优化的。
接下来我问他,我这里有一段复杂的SQL,你可以动手帮我优化一下吗?到这一步的时候就有很多候选人做不好打了退堂鼓。他们有很扎实的理论知识,但是动手能力却差点火候。
今天这篇文章就从实战的角度出发,带大家走一遍SQL优化的真实流程。
找出有问题的SQL?
在实际开发中要判断一段SQL有没有问题可以从两方面来判断:
1、系统层面
CPU消耗严重
IO等待严重
页面响应时间过长
应用的日志出现超时等错误
2、SQL语句层面
冗长
执行时间过长
从全表扫描获取数据
执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,出现问题的频率肯定会更高。更进一步判断SQL问题就必须得从执行计划入手,如下所示:

执行计划告诉我们本次查询走了全表扫描Type=ALL,rows很大(9950400)基本可以判断这是一段"有味道"的SQL。
查看SQL执行计划?
找到了有问题的SQL就要确定优化方案,那究竟从何处下手呢?这里必须要通过执行计划来观察。
执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以MYSQL为例,看看执行计划是什么。(每个数据库的执行计划都不一样,需要自行了解)
explain select * from xxx当使用explain sql后会看到执行计划

执行计划中几个重要字段的解释说明,大家需要记住
| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
通过执行计划我们就可以确定优化方案,优化一处后再回过头来观察执行计划,如此往复循环直到找到最优目标为止。
下面给出一段有问题的SQL具体操作一下。
SQL优化案例
慢查询
1、表结构如下:
CREATE TABLE `a`
(`id` int(11) NOT NULLAUTO_INCREMENT,`seller_id` bigint(20) DEFAULT NULL,`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,`gmt_create` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(`id` int(11) NOT NULLAUTO_INCREMENT,`seller_name` varchar(100) DEFAULT NULL,`user_id` varchar(50) DEFAULT NULL,`user_name` varchar(100) DEFAULT NULL,`sales` bigint(20) DEFAULT NULL,`gmt_create` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(`id` int(11) NOT NULLAUTO_INCREMENT,`user_id` varchar(50) DEFAULT NULL,`order_id` varchar(100) DEFAULT NULL,`state` bigint(20) DEFAULT NULL,`gmt_create` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)
);2、有问题的查询SQL
select a.seller_id,a.seller_name,b.user_name,c.state
from a,b,c
where a.seller_name = b.seller_nameand b.user_id = c.user_idand c.user_id = 17and a.gmt_createBETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;a,b,c 三张表关联,查询用户17 在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列
优化步骤
1、先查看各表数据量

2、查看原执行时间,总耗时0.21s
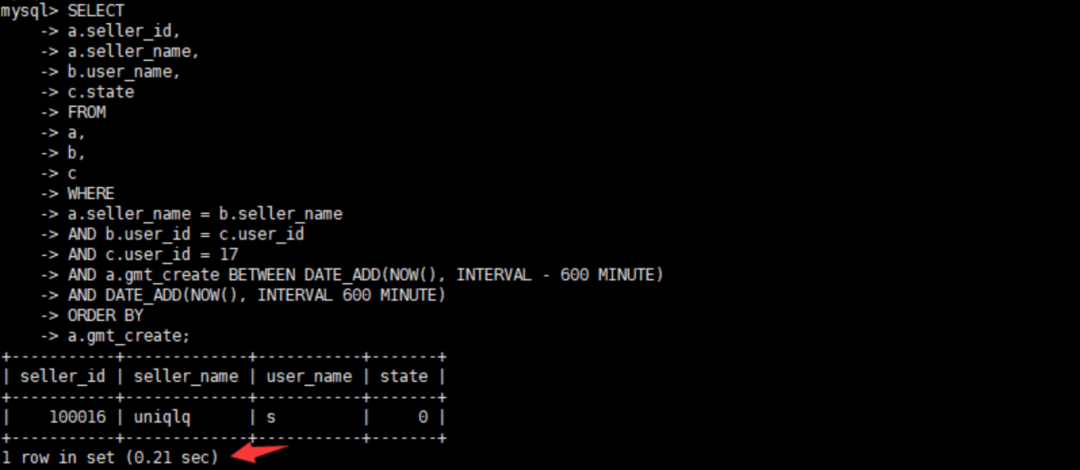
3、查看原执行计划
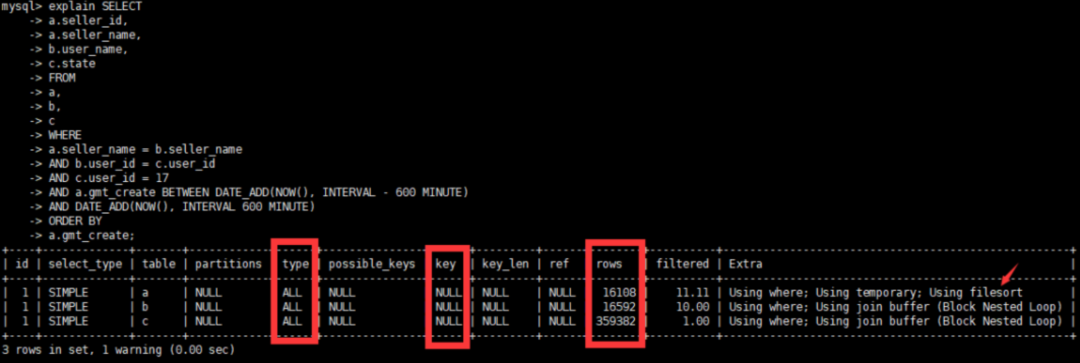
4、通过观察执行计划和SQL语句,确定初步优化方案
SQL中 where条件字段类型要跟表结构一致,表中
user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。因存在b表和c表关联,将b和c表
user_id创建索引因存在a表和b表关联,将a和b表
seller_name字段创建索引利用复合索引消除临时表和排序
初步优化的SQL:
alter table b modify `user_id` int(10) DEFAULT NULL;
alter table c modify `user_id` int(10) DEFAULT NULL;
alter table c add index `idx_user_id`(`user_id`);
alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);查看优化后的执行时间
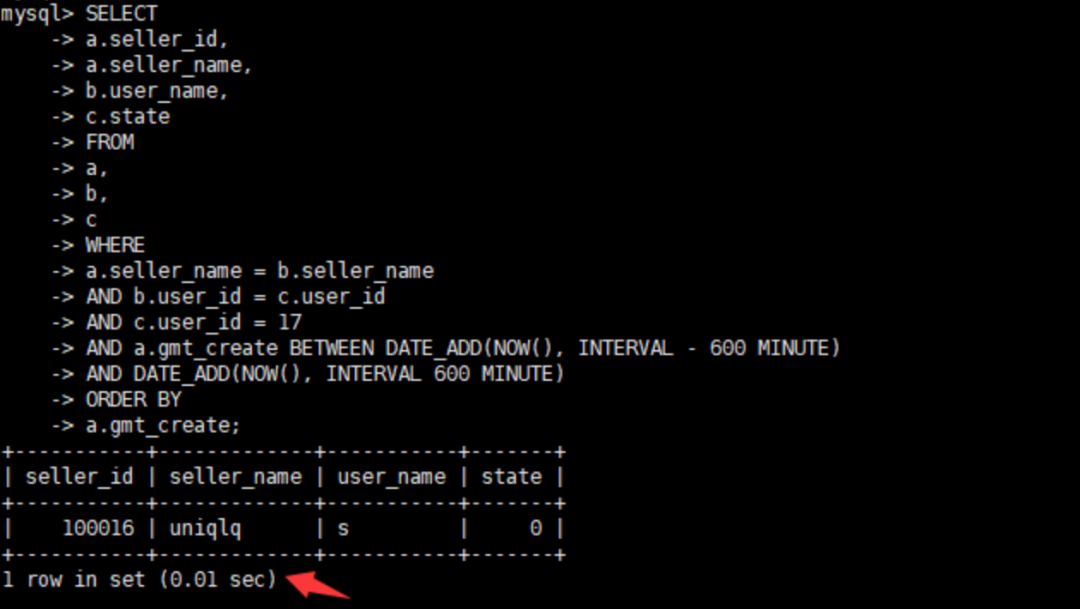
初步优化后执行速度提升了20倍,是否还能继续优化呢?
5、继续查看优化后的执行计划
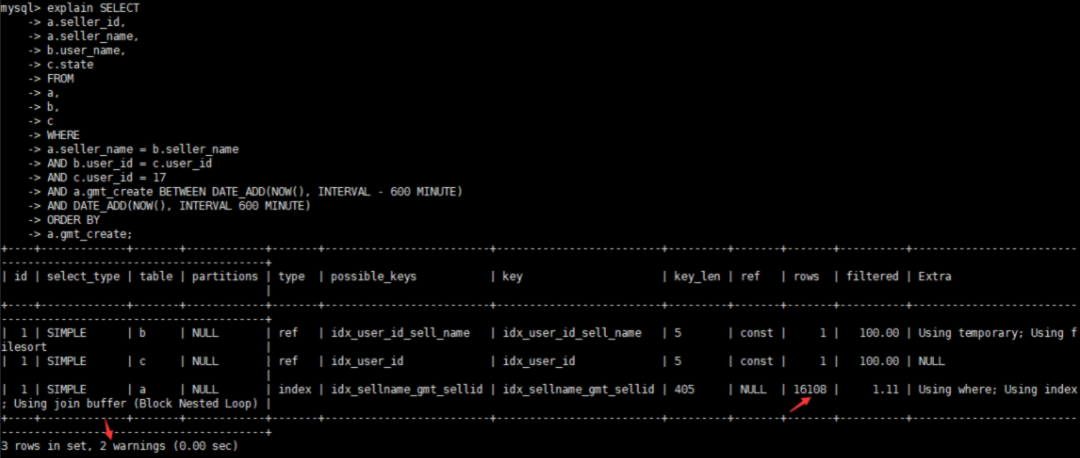
这里只看到查询需要扫描的元素比较大,不过还看到了有两处告警信息,直接查看告警信息
show warnings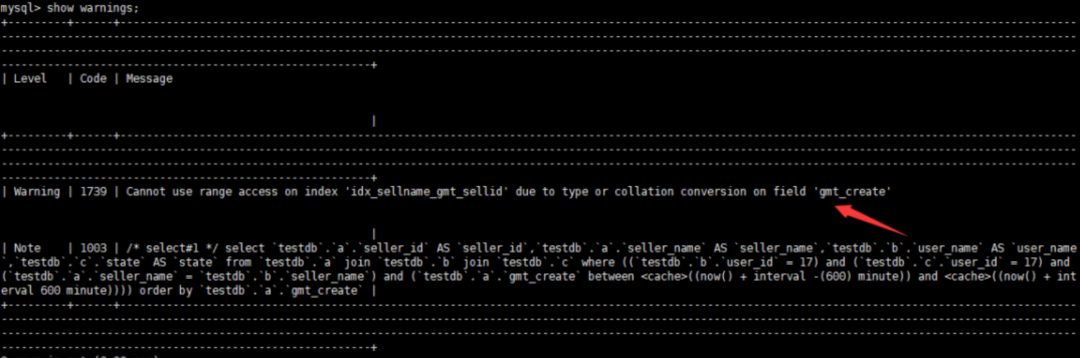
Cannot use range access on index ‘idx_sellname_gmt_sellid’ due to type or collation conversion on field ‘get_create’,这句话是告诉你由于gmt_create列发生了类型转换所以无法走索引。
查看SQL建表语句发现gmt_create字段被设计成了varchar类型,在SQL查询时需要转化成时间格式做查询,确实不能走索引。
所以需要调整一下gmt_create字段格式
alter table a modify "gmt_create" datetime DEFAULT NULL;6、修改字段后再来查看执行时间
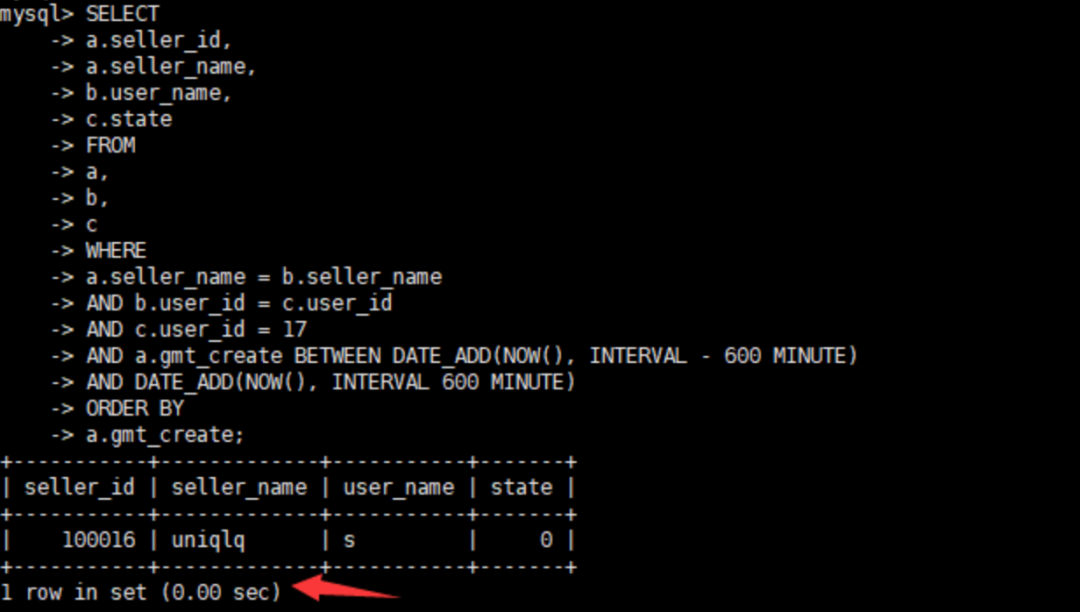
执行速度非常完美。
7、再观察优化后的执行计划
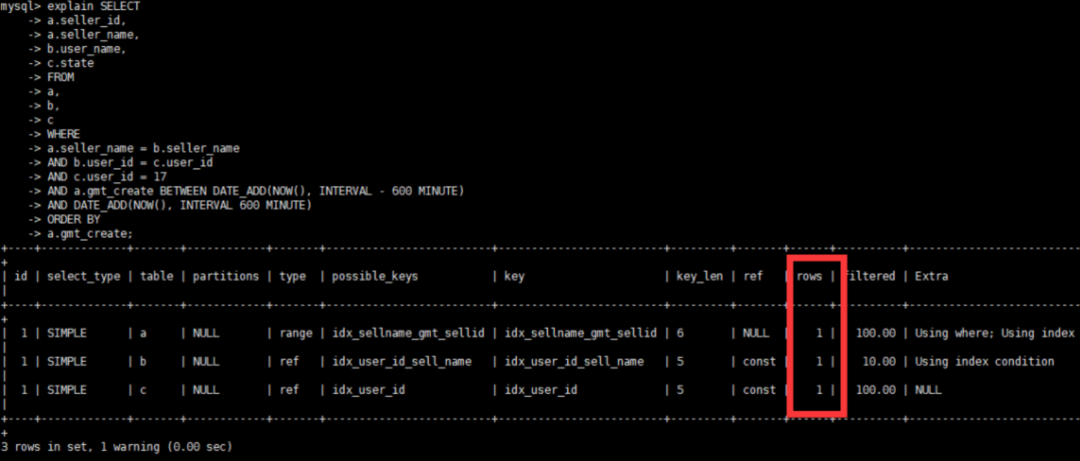
可以看到执行计划也很完美,至此SQL优化结束。
SQL优化小结
这里给大家总结一下优化SQL的套路,再也不怕面试官问你怎么做SQL优化的啦。
查看执行计划 explain
如果有告警信息,查看告警信息 show warnings;
查看SQL涉及的表结构和索引信息
根据执行计划,思考可能的优化点
按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
查看优化后的执行时间和执行计划
如果优化效果不明显,重复第四步操作
在看、点赞、转发,是对我最大的鼓励。您的支持就是我坚持下去的最大动力!
另外我的 知识星球 开通了,点击 知识星球 获取限量40元优惠券加入,每天不到3毛钱。目前更新了SpringCloud alibaba开发实战、Kubernetes云原生实战、分库分表实战、设计模式实战、一起学DDD 等,还有每周的送书活动等着你....

相关文章:
面试官:给你一段有问题的SQL,如何优化?
大家好,我是飘渺!我在面试的时候很喜欢问候选人这样一个问题:“你在项目中遇到过慢查询问题吗?你是怎么做SQL优化的?”很多时候,候选人会直接跟我说他们在编写SQL时会遵循的一些常用技巧,比如&a…...

嵌入式 Linux 文件IO操作
目录 Linux 文件操作 1 Linux 系统环境文件操作概念 2 缓冲 IO 文件操作 1 文件的创建,打开与关闭 fopen 函数函数 2 freopen 函数 3、fdopen函数 4、fclose函数 5、格式化读写 6、单个字符读写 7、文件定位 8、标准目录文件 9、非缓冲IO文件操作 Linux 文…...
植物大战 二叉搜索树——C++
这里是目录标题二叉排序树的概念模拟二叉搜索树定义节点类insert非递归Finderase(重点)析构函数拷贝构造(深拷贝)赋值构造递归FindRInsertR二叉搜索树的应用k模型KV模型二叉排序树的概念 单纯的二叉树存储数据没有太大的作用。 搜索二叉树作用很大。 搜索二叉树的一般都是用…...

[MatLab]矩阵运算和程序结构
一、矩阵 1.定义 矩阵以[ ]包含,以空格表示数据分隔,以;表示换行。 A [1 2 3 4 5 6] B 1:2:9 %1-9中的数,中间是步长(不能缺省) C repmat(B,3,2) %将B横向重复2次,纵向重复2次 D ones(2,4) …...

【Leedcode】栈和队列必备的面试题(第四期)
【Leedcode】栈和队列必备的面试题(第四期) 文章目录【Leedcode】栈和队列必备的面试题(第四期)一、题目二、思路图解1.声明结构体2.循环链表开辟动态结构体空间3.向循环队列插入一个元素4.循环队列中删除一个元素5. 从队首获取元…...
Windows Server 2016搭建文件服务器
1:进入系统在服务器管理器仪表盘中添加角色和功能。 2:下一步。 3:继续下一步。 4:下一步。 5:勾选Web服务器(IIS) 6:添加功能。 7:下一步。 8:下一步。 9:下一步。 10&a…...
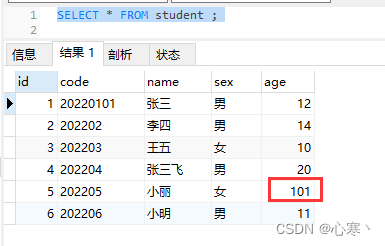
零基础学SQL(十一、视图)
目录 前置建表 一、什么是视图 二、为什么使用视图 三、视图的规则和限制 四、视图的增删改查 五、视图数据的更新 前置建表 CREATE TABLE student (id int NOT NULL AUTO_INCREMENT COMMENT 主键,code varchar(255) NOT NULL COMMENT 学号,name varchar(255) DEFAULT NUL…...
web,h5海康视频接入监控视频流记录三(后台node取流)
前端vue,接入ws视频播放 云台控制 ,回放预览,都是需要调对应的海康接口。相当于,点击时,请求后台写好的接口,接口再去请求海康的接口 调用云台控制是,操作一次,不会自己停止&#x…...
网络安全从入门到精通:30天速成教程到底有多狠?你能坚持下来么?
毫无疑问,网络安全是当下最具潜力的编程方向之一。对于许多未曾涉足计算机编程的领域「小白」来说,深入地掌握网络安全看似是一件十分困难的事。至于一个月能不能学会网络安全,这个要看个人,对于时间管理不是很高的,肯…...

世界上最流行的编程语言,用户数超过Python,Java,JavaScript,C的总和!
世界上最流行的编程语言是什么? Python? Java? JavaScript? C?都不是,是Excel!外媒估计,全球有12亿人使用微软的Office套件,其中估计有7.5亿人使用Excel!可是Excel不就是能写点儿公式&#x…...

杂谈:created中两次数据修改,会触发几次页面更新?
面试题:created生命周期中两次修改数据,会触发几次页面更新? 一、同步的 先举个简单的同步的例子: new Vue({el: "#app",template: <div><div>{{count}}</div></div>,data() {return {count…...

原生JS实现拖拽排序
拖拽(这两个字看了几遍已经不认识了) 说到拖拽,应用场景不可谓不多。无论是打开电脑还是手机,第一眼望去的界面都是可拖拽的,靠拖拽实现APP或者应用的重新布局,或者拖拽文件进行操作文件。 先看效果图&am…...

Coredump-N: corrupted double-linked list
文章目录 问题安装debuginfo之后分析参数确定确定代码逻辑解决问题 今天碰到一例: #0 0xf7f43129 in __kernel_vsyscall () #1 0xf6942b16 in raise () from /lib/libc.so.6 #2 0xf6928e64 in abort () from /lib/libc.so.6 #3 0xf6986e8c in __libc_message () from /lib/li…...

5个好用的视频素材网站
推荐五个高质量视频素材网站,免费、可商用,赶紧收藏起来! 1、菜鸟图库 视频素材下载_mp4视频大全 - 菜鸟图库 网站素材非常丰富,有平面、UI、电商、办公、视频、音频等相关素材,视频素材质量很高,全部都是…...

使用码匠连接一切|二
目录 Elasticsearch Oracle ClickHouse DynamoDB CouchDB 关于码匠 作为一款面向开发者的低代码平台,码匠提供了丰富的数据连接能力,能帮助用户快速、轻松地连接和集成多种数据源,包括关系型数据库、非关系型数据库、API 等。平台提供了…...

3.1.1 表的相关设计
文章目录1.表中实体与实体对应的关系2.实际案例分析3.表的实际创建4.总结1.表中实体与实体对应的关系 一对多 如一个班级对应多名学生,一个客户拥有多个订单等这种类型表的建表要遵循主外键关系原则,即在从表创建一个字段,此字段作为外键指向…...
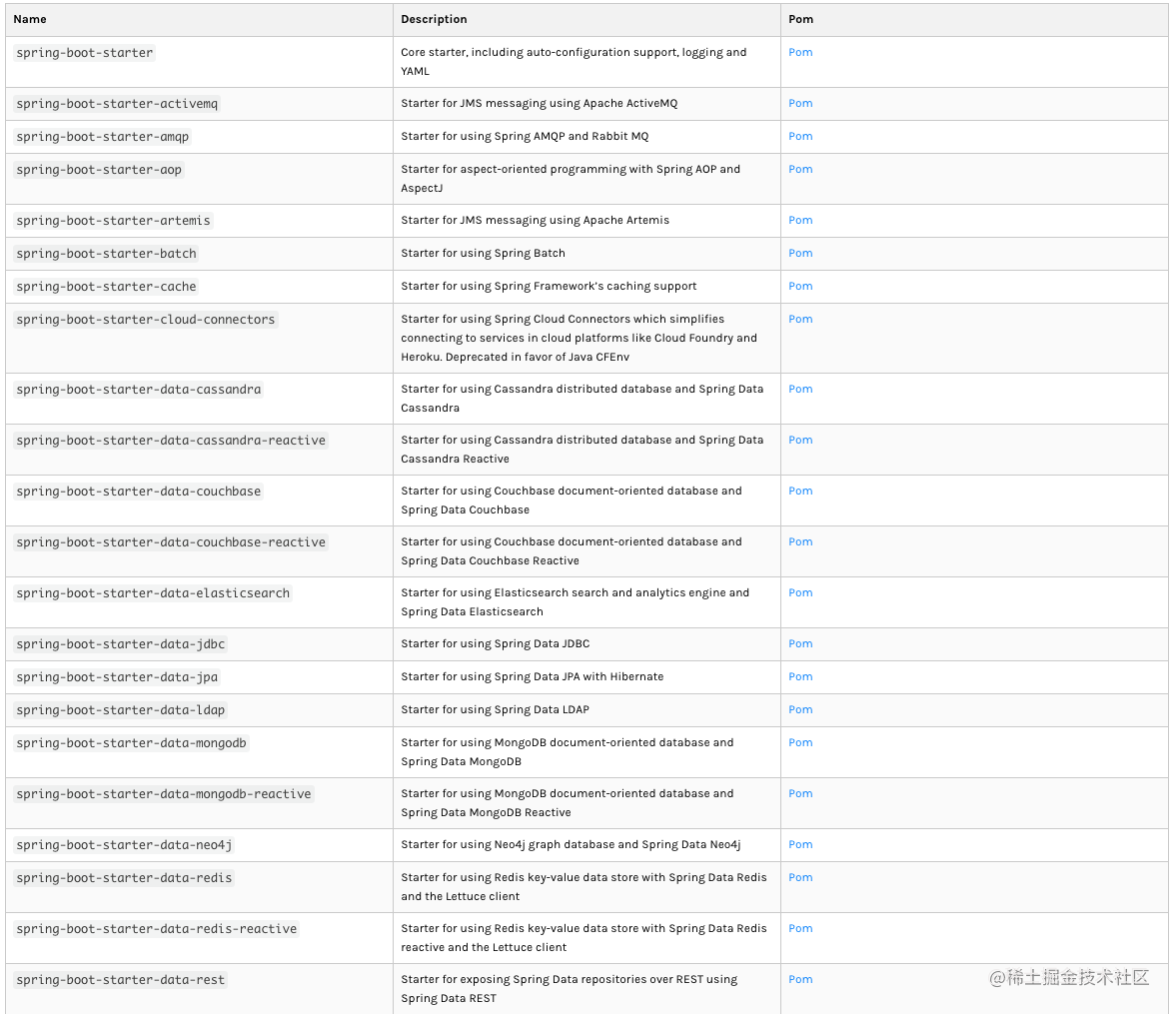
Vue3 企业级项目实战:认识 Spring Boot
Vue3 企业级项目实战 - 程序员十三 - 掘金小册Vue3 Element Plus Spring Boot 企业级项目开发,升职加薪,快人一步。。「Vue3 企业级项目实战」由程序员十三撰写,2744人购买https://s.juejin.cn/ds/S2RkR9F/ 越来越流行的 Spring Boot Spr…...
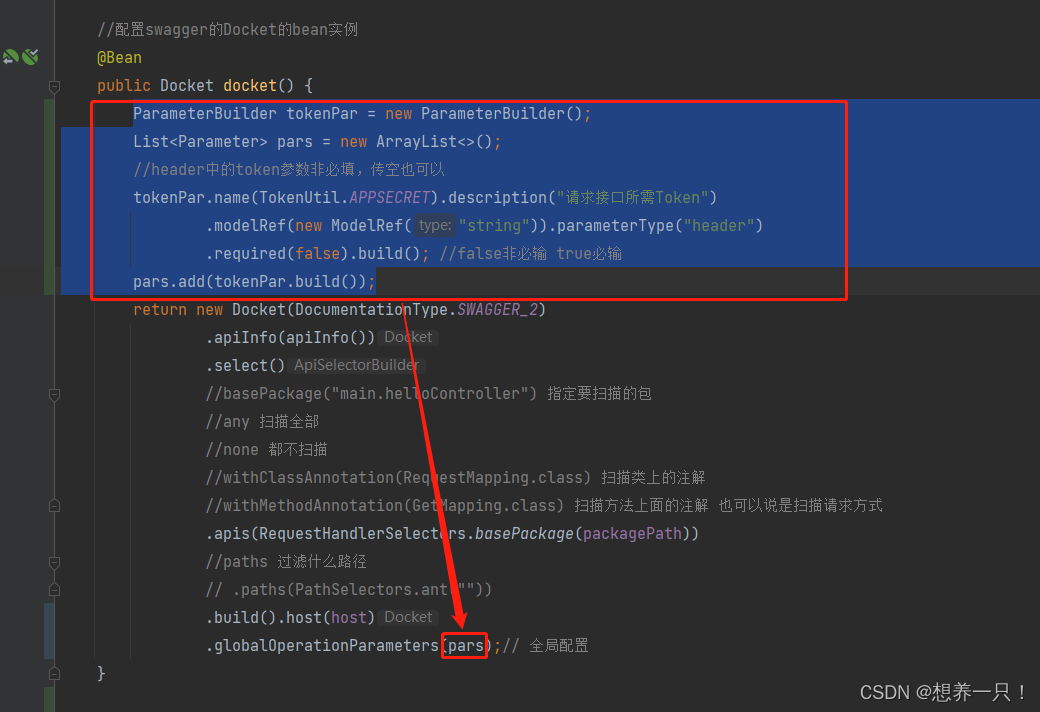
Swagger2实现配置Header请求头
效果 实现 大家使用swagger肯定知道在代码中会写一个 SwaggerConfig 配置类,如果没有这个类swagger指定也用不起来,所以在swagger中配置请求头也是在这个 SwaggerConfig 中操作。 1、要实现配置请求头在配置swagger的Docket的bean实例中添加一个 globa…...
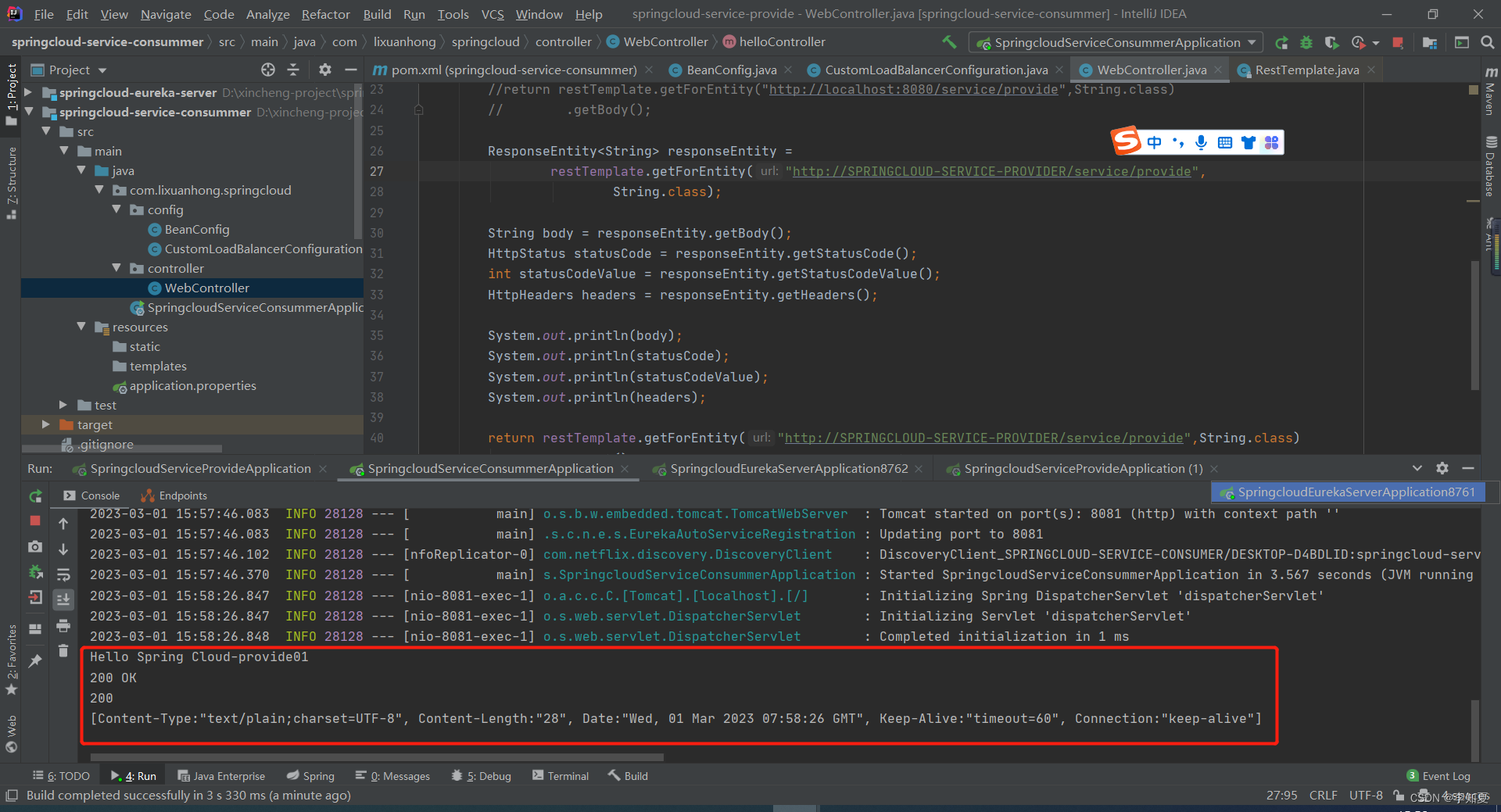
4-1 SpringCloud快速开发入门:RestTemplate类详细解读
RestTemplate类详细解读 RestTemplate 的 GET 请求 Get 请求可以有两种方式: 第一种:getForEntity 该方法返回一个 ResponseEntity对象,ResponseEntity是 Spring 对 HTTP 请求响应的封装,包括了几个重要的元素,比如响…...
【IDEA】【工具】幸福感UP!开发常用的工具 插件/网站/软件
IDEA 插件 CodeGlance Pro —— 代码地图 CodeGlance是一款非常好用的代码地图插件,可以在代码编辑区的右侧生成一个竖向可拖动的代码缩略区,可以快速定位代码的同时,并且提供放大镜功能。 使用:可以通过Settings—>Other Settings—&g…...
)
Spring Boot中RedisTemplate和StringRedisTemplate混用的那些坑(附解决方案)
Spring Boot中RedisTemplate与StringRedisTemplate混用陷阱与深度解决方案 Redis作为高性能键值数据库,在Spring Boot生态中通过RedisTemplate和StringRedisTemplate两大核心组件提供服务。但许多开发者在混合使用时频繁遭遇数据读取失败、序列化异常等问题。本文将…...
)
为什么92%的企业卡在Dify私有化最后1公里?3类典型失败场景+对应灾备回滚方案(含Ansible一键修复脚本)
第一章:Dify 企业级私有化部署架构 如何实现快速接入Dify 企业版支持全栈私有化部署,通过容器化与模块解耦设计,可在主流 Kubernetes 集群或单机 Docker 环境中 15 分钟内完成核心服务接入。其架构围绕「应用层-服务层-数据层」三层隔离展开&…...

Nano-Banana部署教程:Kubernetes集群中Nano-Banana Studio编排方案
Nano-Banana部署教程:Kubernetes集群中Nano-Banana Studio编排方案 1. 学习目标与价值 你是不是也遇到过这样的场景?作为一名设计师或产品经理,需要向团队展示一款复杂产品的内部结构,或者为一份设计文档制作精美的分解示意图。…...

Qwen3-32B-Chat镜像部署实战:50GB系统盘+40GB数据盘空间规划详解
Qwen3-32B-Chat镜像部署实战:50GB系统盘40GB数据盘空间规划详解 1. 镜像概述与硬件要求 1.1 镜像核心特性 本镜像为Qwen3-32B-Chat模型的私有部署优化版本,专为RTX 4090D 24GB显存显卡深度调优。主要技术亮点包括: 硬件适配:基…...

卡尔曼滤波调参避坑指南:从OpenCV代码反推Q/R矩阵设置技巧
卡尔曼滤波调参避坑指南:从OpenCV代码反推Q/R矩阵设置技巧 在目标跟踪、导航系统等实时应用中,卡尔曼滤波器的性能很大程度上取决于Q(过程噪声协方差)和R(测量噪声协方差)这两个关键参数的设置。许多开发者…...
)
避开这些坑!新手用股票API必知的5个隐藏成本(附沧海/麦蕊真实账单分析)
避开这些坑!新手用股票API必知的5个隐藏成本(附沧海/麦蕊真实账单分析) 在金融科技领域,数据是驱动决策的核心燃料。对于刚接触股票API的开发者或中小团队而言,表面上的报价单往往只是冰山一角。本文将揭示那些容易被忽…...

Qwen3-ASR-0.6B效果展示:地铁广播等强噪声场景下公交线路播报识别
Qwen3-ASR-0.6B效果展示:地铁广播等强噪声场景下公交线路播报识别 1. 引言:当语音识别遇上嘈杂环境 想象一下这个场景:你正站在地铁站台,耳边是列车进站的轰鸣、人群的嘈杂、还有广播里断断续续的报站声。你想用手机记下换乘信息…...

别再只懂systemd了!手把手教你用D-Bus守护进程实现Linux服务间通信
超越systemd:D-Bus守护进程在Linux服务通信中的实战指南 Linux系统管理员们早已习惯了使用systemd来管理服务,但当你需要实现服务间的高效通信时,D-Bus守护进程(db-daemon)才是真正的幕后英雄。本文将带你深入实战,掌握如何配置和…...
方案会留白?)
大屏开发避坑指南:为什么你的scale()方案会留白?
大屏开发避坑指南:为什么你的scale()方案会留白? 在数据可视化领域,大屏展示已成为企业决策和业务监控的重要窗口。然而,当开发者满怀信心地将精心设计的19201080界面部署到客户现场时,却常常遭遇令人尴尬的留白问题—…...

Robot Framwork自动化测试框架详解
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 一、Robot Framwork简述 Robot Framework是一款python编写的功能自动化测试框架,支持python2和python3两个版本,是一款开源自动化测试框架…...