管理逻辑备数据库(Logical Standby Database)
1. SQL Apply架构概述
SQL Apply使用一组后台进程来应用来自主数据库的更改到逻辑备数据库。
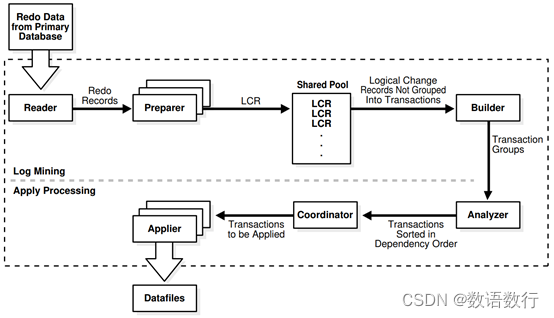
在日志挖掘和应用处理中涉及到的不同的进程和它们的功能如下:
在日志挖掘过程中:
1)READER进程从归档redo日志文件或备redo日志文件中读取redo记录
2)PREPARER进程转换redo记录中包含的数据块更改到逻辑更改记录(LCRs,Logical Change Records)。可以为一个指定的redo日志文件激活多个PREPARER进程。LCRs存放在SGA(system global area)中,称为LCR缓存。
3)BUILDER进程将LCRs组合成事务和执行其他任务,比如在LCR缓存中进行内存管理,重启与SQL Apply相关的检查点和滤除无用的更改。
在应用过程中:
1)ANALYZER进程确认不同事务之间的依赖关系。
2)COORDINATOR进程(LSP)分配事务给不同的应用器,然后在事务间进行协调来确保遵循事务之间的依赖关系。
3)APPLIER进程在协调进程的监督下应用事务到逻辑备数据库。
1.1. SQL Apply考虑的各种因素
1.1.1. 事务大小考虑
SQL Apply将事务分成两类:小事务和大事务。
每种类别的定义如下:
1)小事务—SQL Apply一旦遇到redo日志文件中的事务提交记录,就会启动应用属于小事务的LCRs。
2)大事务—SQL Apply将大事务分割成更小的事务块(transcation chunks),然后在看到redo日志文件中的大事务提交记录之前启动应用事务块。这样可以减轻LCR缓存的内存压力和减少整体故障切换的时间。
例如,如果不将大事务分割成小块事务,SQL*Loader导入1千万行,每行100 bytes,那么LCR缓存将会使用1G的内存。如果分配给LCR缓存的内存小于1G,就会导致从LCR缓存中移出页面(pageout)。
降了内存方面的考虑,如果SQL Apply直到遇到事务的COMMIT记录才开始应用SQL*Loader导入1千万行的相关的更改,它会阻滞角色的转换。在事务提交后发起的正常切换或故障切换不能完成,直到SQL Apply已经应用事务到逻辑备数据库为止。
虽然使用了事务块,当处理修改多于8百万行的事务时,SQL Apply的性能可能会降低。对于多于8百万行的事务,SQL Apply使用临时段来存放处理事务的部分内部元数据。确保在临时段中分配更多的空间让SQL Apply能成功地处理多于8百万行的事务。
所有事务开始时会分类成小事务。取决于LCR缓存的可用内存容量和属于事务的LCR消耗的内存容量,SQL Apply决定什么时候重新将事务分类为大事务。
1.1.2. 页出(pageout)考虑
当LCR缓存的内存耗尽时,需要释放空间来让SQL Apply来继续进行,就会发生页出(pageout)。
例如,假设分配给LCR缓存的内存是100MB,SQL Apply遇到一条INSERT到表的一个LONG列的大小为300MB的事务。在这种情况下,日志挖掘组件页出第一部分LONG数据来读取后面部分的列更改。在一个调优好的逻辑备数据库中,页出活动偶尔会发生,不会影响系统 的整体吞吐量。
参考“自定义逻辑备数据库”章节关于如何识别有问题的页出和执行纠正操作。
1.1.3. 重启考虑
对逻辑备数据库的更改不会成为持久的,直到从redo日志文件中挖掘到事务的提交记录和应用到逻辑备数据库为止。
因此,每次SQL Apply停止时,不管是因为用户的指令还是系统故障的结果,SQL Apply必须进行回溯,重新挖掘最早的没有提交的事务。
在事务只做了少量的工作但打开了很长一段时间的情况下,从一开始重启SQL Apply可能会付出过高的代价,因为SQL Apply必须重新挖掘大量的归档redo日志文件,只为了读取一部分没有提交的数据的redo数据。为了减轻这种情况,SQL Apply定期地对旧的未提交的数据执行检查点操作。检查点进行时的SCN反映在视图V$LOGSTDBY_PROGRESS的列RESTART_SCN中。在进行重启时,SQL Apply从大于列RESETART_SCN的值的SCN时产生的redo记录开始挖掘。重启时不需要的归档redo日志文件会自动被SQL Apply删除。
某些负载,例如大的DDL事务,并行的DML语句(PDML),和直接路径导入,阻止RESTART_SCN在负载的持续时间里向前推进。
1.1.4. DML Apply考虑
SQL Apply在应用影响逻辑备数据库的吞吐量和延迟的DML事务时有以下特性:
1)在主数据库上做批量更新或删除时,一条语句会导致多行被修改,这时在逻辑备数据库上则作为单独的行修改来应用。因为,对于每个维护的表,必须有唯一的索引或主键。
2)在主数据库上执行的直接路径插入,在逻辑备数据库上使用传统的INSERT语句来应用。
3)并行的DML(PDML)事务在逻辑备数据库上不是并行地执行。
1.1.5. DDL Apply考虑
SQL Apply在应用影响逻辑备数据库的吞吐量和延迟的DDL事务时有以下特性:
1)DDL事务在逻辑备数据库上是串行地应用。因此,在主数据库上并行应用的DDL事务是一次一个地在逻辑备数据库上应用。
2)CREATE TABLE AS SELECT(CTAS)语句如此执行以致DML操作(CATS语句的一部分)在逻辑备数据库上受到抑制。作为CTAS语句的一部分插入到新创建的表的行从redo日志文件中挖掘出来和使用INSERT语句应用到逻辑备数据库。
3)SQL Appy重新发出在主数据库上执行的DDL,确保作为DDL操作目标的相同对象上的相同的事务中发生的DML不会在逻辑备数据库上复制(SQL Apply reissues the DDL that was performed at the primary database, and ensures that DMLs that occur within the same transaction on the same object that is the target of the DDL operation are not replicated at the logical standby database)。因此,以下两个情况会导致主备数据库相互偏离:
a. DDL包含从主数据库的状态获取的非文字的值。这样的DDL的一个例子是:
ALTER TABLE hr.employees ADD (start_date date default sysdate);
由于SQL Apply在逻辑备数据库重新发出相同的DDL,函数sysdate() 在逻辑备数据库重新取值。因此,列start_date使用与主数据库不同的缺省值来创建。
b. DDL激发在目标表上定义的DML触发器。由于触发的DMLs发生在与DDL相同的事务上,操作的表也是DDL的目标,这些触发的DML不会在逻辑备数据库上复制。
例如,假设创建一个如下的表:
create table HR.TEMP_EMPLOYEES (
emp_id number primary key,
first_name varchar2(64),
last_name varchar2(64),
modify_date timestamp);
假设在表上创建一个触发器使得任何时候表进行更新时列modify_date也更新来反映更改的时间:
CREATE OR REPLACE TRIGGER TRG_TEST_MOD_DT BEFORE UPDATE ON HR.TEST_EMPLOYEES
REFERENCING
NEW AS NEW_ROW FOR EACH ROW
BEGIN
:NEW_ROW.MODIFY_DATE:= SYSTIMESTAMP;
END;
/
表在一般的DML/DDL负载下可以正确地维护。但如果使用缺省值往表里增加一列,ADD COLUMN DDL操作会激发更新触发器,更改表中所有行的MODIFY_DATE列为新的时间戳。这些对MODIFY_DATE列的更改不会复制到逻辑备数据库上。接下来对表的DML操作会停止SQL Apply,因为记录在redo流中的MODIFY_DATE列数据与存在于逻辑备数据库上的数据不匹配。
1.1.6. 密码验证函数
检查密码复杂度的密码验证函数必须在SYS模式中创建。
因为SQL Apply不会复制SYS模式中创建的对象,这些密码验证函数不会复制到逻辑备数据库。必须在逻辑备数据库上手动创建密码验证函数,然后与合适的profile关联。
2.控制用户对表的访问
SQL语句ALTER DATABASE GUARD在逻辑备数据库上控制用户对表的访问。
缺省情况下,在逻辑备数据库上database guard设置为ALL。
ALTER DATABASE GUARD语句允许以下关键字:
1)ALL
指定ALL来阻止除SYS外的所有用户对逻辑备数据库的任何数据进行更改。
2)STANDBY
指定STANDBY来阻止除SYS之外的所有用户对通过SQL Apply维护的任何表或序列进行DML和DDL更改。
3)NONE
指定NONE来对数据库的所有数据使用典型的保护措施。
例如,使用以下语句来启用用户更改不是SQL Apply维护的表。
SQL> ALTER DATABASE GUARD STANDBY;
特权用户可以分别使用ALTER SESSION DISABLE GUARD和ALTER SESSION ENABLE GUARD语句为当前会话临时关闭和打开database guard。这个语句替代了DBMS_LOGSTDBY.GUARD_BYPASS PL/SQL存储过程在Oracle 9i中执行相同的功能。当你想临时禁用database guard来对数据库进行更改时,语句ALTER SESSION [ENABLE|DISABLE] GUARD很有用。
注:在database guard禁用时,不要让主数据库和逻辑备数据库偏离。
3.监控逻辑备数据库
3.1. 监控SQL Apply的进度
SQL Apply可以在六个进度状态中的任何一个:初始化SQL Apply,等待字典日志,导入LogMiner字典,应用redo数据,等待归档缺口(gap)得到解决,和空闲。
下图显示了这些状态的流动:
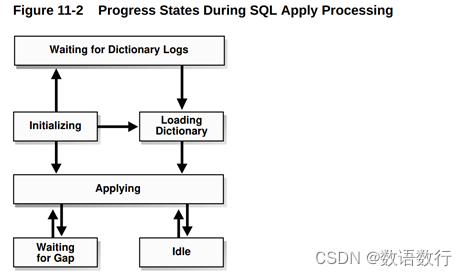
3.1.1.初始化状态
当使用ALTER DATABASE START LOGICAL STANDBY APPLY语句启动SQL APPLY时,它会进入到initializing状态。
查询V$LOGSTDBY_STATE视图来确认SQL Apply的当前状态。
SQL> SELECT SESSION_ID, STATE FROM V$LOGSTDBY_STATE;
SESSION_ID STATE
---------- -------------
1 INITIALIZING
列SESSION_ID显示SQL Apply创建的持久的LogMiner会话,用来挖掘主数据库产生的归档redo日志文件。
3.1.2.等待字典日志
SQL Apply第一次启动时,它需要导入redo日志文件中记录的LogMiner字典。SQL Apply停留在WAITING FOR DICTIONARY LOGS状态直到它已经接收到导入LogMiner字典所要求的所有的redo数据。
3.1.3.导入字典状态
Loading dictionary的状态会持续一会。导入一个大数据库的LogMiner字典会花很长的时间。当导入字典时,查询视图V$LOGSTDBY_STATE会返回以下输出:
SQL> SELECT SESSION_ID, STATE FROM V$LOGSTDBY_STATE;
SESSION_ID STATE
---------- ------------------
1 LOADING DICTIONARY
只有COORDINATOR进程和挖掘进程启动直到LogMiner字典完全导入为止。因此,此时如果查询视图V$LOGSSTDBY_PROCESS,将会看不到任何APPLIER进程。
SQL> SELECT SID, SERIAL#, SPID, TYPE FROM V$LOGSTDBY_PROCESS;
SID SERIAL# SPID TYPE
------ --------- --------- ---------------------
47 3 11438 COORDINATOR
50 7 11334 READER
45 1 11336 BUILDER
44 2 11338 PREPARER
43 2 11340 PREPARER
可以通过查询视图V$LOGMNR_DICTIONARY_LOAD来获取关于导入字典进度更详细的信息。导入字典分3个阶段进行:
1)挖掘相关的归档redo日志文件或备redo日志文件来收集与导入LogMiner字典相关的redo更改;
2)这些更改被处理和导入到数据库中的阶段表;
3)发出一序列的DDL语句导入LogMiner字典表。
SQL> SELECT PERCENT_DONE, COMMAND FROM V$LOGMNR_DICTIONARY_LOAD WHERE SESSION_ID = (SELECT SESSION_ID FROM V$LOGSTDBY_STATE);
PERCENT_DONE COMMAND
------------- -------------------------------
40 alter table SYSTEM.LOGMNR_CCOL$ exchange partition P101 with table SYS.LOGMNRLT_101_CCOL$ excluding indexes without validation
如果PERCENT_DONE或COMMAND列很长一段时间没有变化,查询视图V$SESSION_LONGOPS来监控有问题的DDL事务的进度。
3.1.4.应用状态
在这个状态中,SQL Apply已经成功导入LogMiner字典的初始快照和正在应用redo数据到逻辑备数据库。
查询视图V$LOGSTDBY_PROGRESS,取得关于SQL Apply进度的详细信息:
SQL> ALTER SESSION SET NLS_DATE_FORMAT = ‘DD-MON-YYYY HH24:MI:SS’;
SQL> SELECT APPLIED_TIME, APPLIED_SCN, MINING_TIME, MINING_SCN FROM V$LOGSTDBY_PROGRESS;
APPLIED_TIME APPLIED_SCN MINING_TIME MINING_SCN
-------------------- ----------- -------------------- -----------
10-JAN-2005 12:00:05 346791023 10-JAN-2005 12:10:05 3468810134
主数据库的所有在APPLIED_SCN(或APPLIED_TIME)之前的提交的事务都已经应用到逻辑备数据库。挖掘引擎已经处理了所有在MINING_SCN(和MINING_TIME)之前产生的redo记录。在稳定的状态下,MINING_SCN(和MINING_TIME)总是在APPLIED_SCN(和APPLIED_TIME)的前面。
3.1.5.等待gap状态
这个状态发生在当SQL Apply已经挖掘和应用所有可用的redo记录,在等待新的日志文件(或缺失的日志文件)来通过RFS进程归档的时候。
SQL> SELECT STATUS FROM V$LOGSTDBY_PROCESS WHERE TYPE = ‘READER’;
STATUS
------------------------------------------------------------------------
ORA-16240: waiting for log file (thread# 1, sequence# 99)
3.1.6.空闲状态
一旦SQL Apply已经应用完主数据库产生的所有redo,它就进入到这个状态。
SQL> SELECT SESSION_ID, STATE FROM V$LOGSTDBY_STATE;
SESSION_ID STATE
---------- -----------------
1 IDLE
3.2. 自动删除日志文件
外来的归档日志包含从主数据库传输来的redo。
有两种方式来存储外来的归档日志:
1)快速恢复区域
2)在快速恢复区域以外的目录
存储在快速恢复区域的外来归档日志由SQL Apply管理。包含在日志中的所有redo记录已经应用到逻辑备数据库后,它们会保留一段由参数DB_FLASHBACK_RETENTION_TARGET指定的时间(或如果参数DB_FLASHBACK_RETENTION_TARGET没有指定,则保留1440分钟)。不可以撤销自动管理存放在快速恢复区域中的外来归档日志。
不是存储在快速恢复区域的外来归档日志缺省由SQL Apply管理。在自动管理下,在日志包含的所有redo记录已经应用到逻辑备数据库后,不是存储在快速恢复区域的外来归档日志,保留一段由参数LOG_AUTO_DEL_RETENTION_TARGET指定的时间。可以执行以下PL/SQL存储过程取消自动管理不是存储在快速恢复区域中的外来归档日志。
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘LOG_AUTO_DELETE’, ‘FALSE’);
注:使用DBMS_LOGSTDBY.APPLY_SET存储过程来设置这个参数,如果不明确指定参数LOG_AUTO_DEL_RETENTION_TARGET,它缺省为逻辑备数据库设置的参数DB_FLASHBACK_RETENTION_TARGET的值,或者在DB_FLASHBACK_RETENTION_TARGET参数没有设置时为1440分钟。
如果撤消缺省的自动日志删除功能,定期执行以下步骤来发现和删除SQL Apply不再需要的归档redo日志文件:
1)执行以下PL/SQL语句来清除不需要的元数据的逻辑备会话:
SQL> EXECUTE DBMS_LOGSTDBY.PURGE_SESSION;
这条语句也更新视图DBA_LOGMNR_PURGED_LOG。
2)查询视图DBA_LOGMNR_PURGED_LOG来列出可以删除的归档redo日志文件:
SQL> SELECT * FROM DBA_LOGMNR_PURGED_LOG;
FILE_NAME
------------------------------------
/boston/arc_dest/arc_1_40_509538672.log
/boston/arc_dest/arc_1_41_509538672.log
/boston/arc_dest/arc_1_42_509538672.log
/boston/arc_dest/arc_1_43_509538672.log
/boston/arc_dest/arc_1_44_509538672.log
/boston/arc_dest/arc_1_45_509538672.log
/boston/arc_dest/arc_1_46_509538672.log
/boston/arc_dest/arc_1_47_509538672.log
3)使用操作系统的命令来删除查询列出的归档redo日志文件。
4.自定义逻辑备数据库
4.1.在视图DBA_LOGSTDBY_EVENTS中自定义事件记录
视图DBA_LOGSTDBY_EVENTS可以视为一个循环的日志,日志包含最近的发生在SQL Apply环境中有用的事件。
缺省情况下,最后的10,000个事件会记录在事件视图中。可以调用存储过程DBMS_LOGSTDBY.APPLY_SET更改记录的事件数量。例如,可以执行以下语句来确保最后的100,000事件会被记录。
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET (‘MAX_EVENTS_RECORDED’, ‘100000’);
引起SQL Apply停止的错误会一直记录在DBA_LOGSTDBY_EVENTS视图中(除非SYSTEM表空间没有足够的空间)。这些事件也会存放到alert告警文件中,文本包含关键字LOGSTDBY。当查询视图时,通过EVENT_TIME,COMMIT_SCN和CURRENT_SCN排序来选择这些列。这样排序确保关闭故障显示在视图的最后。
下面的示例显示DBMS_LOGSTDBY子程序指定记录到视图中的事件。
示例1:确认DDL语句是否已经应用
例如,执行以下语句来记录应用DDL事务到DBA_LOGSTDBY_EVENTS视图中。
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET (‘RECORD_APPLIED_DDL’, ‘TRUE’);
示例2:检查视图DBA_LOGSTDBY_EVENTS来确认逻辑备数据库不支持的操作
执行以下语句来捕获运行在主数据库上的逻辑备数据库不支持的事务信息
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
SQL> EXEC DBMS_LOGSTDBY.APPLY_SET(‘RECORD_UNSUPPORTED_OPERATIONS’, ‘TRUE’);
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
然后,检查DBA_LOGSTDBY_EVENTS视图来查看不支持的操作。一般情况下,在不支持的表上的操作会被SQL Apply安静地忽略。然而,在滚动升级过程(当备数据库在更高的版本,挖掘更低版本的主数据库产生的redo时),如果在主数据库执行不支持的操作,逻辑备数据库可能不是你想执行正常切换的数据库。Oracle Data Guard在视图DBA_LOGSTDBY_EVENTS中为每个表记录至少一条不支持的操作。
4.2. 使用DBMS_LOGSTDBY.SKIP来阻止更改特定的模式对象
缺省情况下,主数据库上所有支持的表都会复制到逻辑备数据库。
可以通过指定规则来略过应用特定的表的修改,从而更改缺省的行为。例如,为了忽略表HR.EMPLOYEES的更改,可以指定规则来阻止应用DML和DDL更改到特定的表。例如:
1)停止SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
2)注册SKIP规则:
SQL> EXECUTE DBMS_LOGSTDBY.SKIP (stmt => ‘DML’, schema_name => ‘HR’, object_name => ‘EMPLOYEES’);
SQL> EXECUTE DBMS_LOGSTDBY.SKIP (stmt => ‘SCHEMA_DDL’, schema_name => ‘HR’, object_name => ‘EMPLOYEES’);
3)启动SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
4.3. 为DDL语句设置Skip Handler
可以创建一个存储过程来拦截某些DDL语句和使用不同的语句替换原始的DDL语句。
例如,如果逻辑备数据库的文件系统结构与主数据库的不同,可以写一个DBMS_LOGSTDBY.SKIP存储过程来使用文件规范透明地处理DDL事务。
下面的步骤可以处理主备数据库之间不同的文件系统结构,只要为文件参数字符串使用特定的命名惯例。
1)创建SKIP存储过程来处理表空间DDL事务:
CREATE OR REPLACE PROCEDURE SYS.HANDLE_TBS_DDL (OLD_STMT IN VARCHAR2,STMT_TYP IN VARCHAR2,SCHEMA IN VARCHAR2,NAME IN VARCHAR2,XIDUSN IN NUMBER,XIDSLT IN NUMBER,XIDSQN IN NUMBER,ACTION OUT NUMBER,NEW_STMT OUT VARCHAR2
) AS
BEGIN-- All primary file specification that contains a directory-- /usr/orcl/primary/dbs-- should go to /usr/orcl/stdby directory specificationNEW_STMT := REPLACE(OLD_STMT,'/usr/orcl/primary/dbs','/usr/orcl/stdby');ACTION := DBMS_LOGSTDBY.SKIP_ACTION_REPLACE;
EXCEPTIONWHEN OTHERS THENACTION := DBMS_LOGSTDBY.SKIP_ACTION_ERROR;NEW_STMT := NULL;
END HANDLE_TBS_DDL;
c. 停止SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
d. 注册SKIP存储过程:
SQL> EXECUTE DBMS_LOGSTDBY.SKIP (stmt => ‘TABLESPACE’, proc_name => ‘sys.handle_tbs_ddl’);
e. 停止SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
4.4. 修改逻辑备数据库
逻辑备数据库可以用来做报告活动,即使在SQL语句正在应用的时候。
在逻辑备数据库中,Database guard控制用户对表的访问,语句ALTER SESSION DISABLE GUARD用来绕过database guard,允许在逻辑备数据库中修改表。
注:为了使用逻辑备数据库来存放其他应用程序,处理从主数据库复制过来的数据,同时创建属于它们自己的其他表,database guard必须设置为STANDBY。为了这些应用程序无缝地工作,确保PRESERVE_COMMIT_ORDER参数设置为TRUE(SQL Apply的缺省设置)。(参考Oracle Database PL/SQL Packages and Types Reference关于在DBMS_LOGSTDBY PL/SQL包的参数PRESERVE_COMMIT_ORDER的信息)
执行以下SQL语句来设置database guard为STANDBY:
SQL> ALTER DATABASE GUARD STANDBY;
在这个设置中,从主数据库复制的表被保护不允许用户更改,但在备数据库上创建的表可以被运行在逻辑备数据库的应用程序更改。
缺省时,逻辑备数据库以database guard设置为ALL来运行,这是最有限制性的设置,不允许任何用户对数据库执行更改。可以执行ALTER SESSION DISABLE GUARD来撤销database guard,允许对逻辑备数据库更改。特权用户可以执行这个语句来为当前会话关闭database guard。
以下部分提供了一些示例。这些部分中的讨论假设database guard设置为ALL或STANDBY。
4.4.1. 在逻辑备数据库上执行DDL
可以增加约束到SQL Apply维护的表。
缺省时,当database guard设置为ALL或STANDBY时,只有具有SYS特权的账户可以修改数据库。如果以SYSDG,,SYSTEM,或其他特权账户登录,不可以在逻辑备数据库上执行DDL语句,除非先在会话中绕过database guard。
下面的示例显示如何停止SQL Apply,绕过database guard,在逻辑备数据库上执行SQL语句,然后重新启用guard。在这个示例中,探测索引(soundex index)被增加到姓氏列SCOTT.EMP来加速部分匹配查询。探测索引在主数据库上可能被禁止维护。
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
Database altered.
SQL> ALTER SESSION DISABLE GUARD;
PL/SQL procedure successfully completed.
SQL> CREATE INDEX EMP_SOUNDEX ON SCOTT.EMP(SOUNDEX(ENAME));
Table altered.
SQL> ALTER SESSION ENABLE GUARD;
PL/SQL procedure successfully completed.
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
Database altered.
SQL> SELECT ENAME,MGR FROM SCOTT.EMP WHERE SOUNDEX(ENAME) = SOUNDEX(‘CLARKE’);
ENAME MGR
---------- ----------
CLARK 7839
Oracle建议当绕过database guard启用时,不要在SQL Apply维护的表上执行DML操作。这样做会影响主备数据库的偏离,让逻辑备数据库不可能被维护。
4.4.2. 修改不是SQL Apply维护的表
有时,报告应用程序必须收集统计结果和临时存储它们或跟踪报告运行的次数。虽然应用程序的主要目的是执行报告活动,应用程序也许需要在逻辑备数据库上执行DML(插入,更新和删除)操作。它可能需要创建或删除表。可以设置database guard来允许报告操作更改数据,只要数据不是由SQL Apply正在维护。
分两个步骤来实现对不是SQL Apply维护的表进行更改:
1)在逻辑备数据库上执行存储过程DBMS_LOGSTDBY.SKIP指定一组应用程序可以写数据的表。忽略的表不会被SQL Apply维护。
2)设置database guard只保护备表。
在下面的示例中,假设报告写的表也在主数据库上。
示例停止SQL Apply,忽略需要修改的表,重新启动SQL Apply。报告应用程序写到模式HR的对象TESTEMP%。这些表不再由SQL Apply维护。
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
Database altered.
SQL> EXECUTE DBMS_LOGSTDBY.SKIP(stmt => ‘SCHEMA_DDL’,schema_name => ‘HR’, object_name => ‘TESTEMP%’);
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGSTDBY.SKIP(‘DML’,‘HR’,‘TESTEMP%’);
PL/SQL procedure successfully completed.
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
Database altered.
一旦SQL Apply启动,它需要为增加到skip规则的新指定的表更新备数据库上的元数据。
在SQL Apply有机会更新元数据之前,尝试更改新忽略的表会失败。执行以下查询,可以确认SQL Apply是否已经成功将刚增加的SKIP规则考虑在内:
SQL> SELECT VALUE FROM SYSTEM.LOGSTDBY$PARAMETERS WHERE NAME = ‘GUARD_STANDBY’;
VALUE
---------------
Ready
当VALUE值显示为Ready时,SQL Apply已经成功为略过的表更新所有相关的元数据,可以安全地修改表。
4.5. 在逻辑备数据库上增加或重建表
一般情况下,使用DBMS_LOGSTDBY.INSTANTIATE_TABLE存储过程在无法恢复的操作后重建表。
也可以使用这个存储过程来为之前跳过的表启用SQL Apply。
在创建表前,必须满足“确保主数据库的表行可以被唯一区别”章节描述的要求。然后,可以使用以下步骤来重建表HR.EMPLOYEES和恢复SQL Apply。指令假设已经存在一个定义来访问主数据库的链接BOSTON。
1)停止SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
2)查询视图DBA_LOGSTDBY_SKIP,确保有问题的表没有操作正在被忽略:
SQL> SELECT * FROM DBA_LOGSTDBY_SKIP;
ERROR STATEMENT_OPT OWNER NAME
----- ------------ ----- -----------
N SCHEMA_DDL HR EMPLOYEES
N DML HR EMPLOYEES
N SCHEMA_DDL OE TEST_ORDER
N DML OE TEST_ORDER
因为在逻辑备数据库上已经有SKIP规则与想重建的表相关联,必须首先删除这些规则。可以调用DBMS_LOGSTDBY.UNSKIP存储过程来完成。例如:
SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP(stmt => ‘DML’, schema_name => ‘HR’, object_name => ‘EMPLOYEES’);
SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP(stmt => ‘SCHEMA_DDL’, schema_name => ‘HR’, object_name => ‘EMPLOYEES’);
3) 在逻辑备数据库使用它所有的数据来重建表HR.EMPLOYEES。例如:
SQL> EXECUTE DBMS_LOGSTDBY.INSTANTIATE_TABLE(schema_name => ‘HR’, table_name => ‘EMPLOYEES’, dblink => ‘BOSTON’);
4)启动SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
为了确保新实例化的表和数据库的其余数据有一个一致性的视图,在查询表之前等待SQL Apply追上主数据库。可以执行以下步骤来确认:
1)在主数据库上,确认当前的SCN:
SQL> SELECT CURRENT_SCN FROM V$DATABASE@BOSTON;
CURRENT_SCN
---------------------
345162788
2)确保SQL Apply已经应用所有在CURRENT_SCN之前提交的事务:
SQL> SELECT APPLIED_SCN FROM V$LOGSTDBY_PROGRESS;
APPLIED_SCN
--------------------------
345161345
当查询返回的APPLIED_SCN大于前面查询中返回的CURRENT_SCN时,可以安全地查询新重建的表。
5.管理逻辑备数据库环境下特定的负载
5.1. 导入可传输的表空间到主数据库
可传输的表空间可以导入到主数据库。
执行以下步骤:
1)禁用database guard设置从而可以修改逻辑备数据库:
SQL> ALTER DATABASE GUARD STANDBY;
2)在逻辑备数据库导入表空间。
3)启用database guard设置:
SQL> ALTER DATABASE GUARD ALL;
4)在主数据库导入表空间。
5.2. 使用物化视图
逻辑备数据库自动跳过与物化视图有关的DDL语句。
例如,逻辑备数据库跳过下面的语句:
1)CREATE,ALTER,或DROP MATERIALIZED VIEW
2)CREATE,ALTER,或DROP MATERIALIZED VIEW LOG
在逻辑备数据库已经创建之后在主数据库上创建,修改,或删除的新的物化视图不会在逻辑备数据库上创建。然而,在逻辑备数据库创建之前在主数据库上创建的物化视图存在于逻辑备数据库上。
逻辑备数据库支持本地创建和维护新的物化视图,除了其他种类的辅助数据结构之外。例如,OLTP系统为了更新性能会频繁地使用高度标准化(normalized)的表,但这些会导致复杂决策支持查询的响应时间缓慢。为了在逻辑备数据库上有更高效的查询支持,非标准化(denormalize)复制的数据的物化视图可以被创建,如下(在执行以下语句前以SYS用户连接):
SQL> ALTER SESSION DISABLE GUARD;
SQL> CREATE MATERIALIZED VIEW LOG ON SCOTT.EMP WITH ROWID (EMPNO, ENAME, MGR, DEPTNO) INCLUDING NEW VALUES;
SQL> CREATE MATERIALIZED VIEW LOG ON SCOTT.DEPT WITH ROWID (DEPTNO, DNAME) INCLUDING NEW VALUES;
SQL> CREATE MATERIALIZED VIEW SCOTT.MANAGED_BY REFRESH ON DEMAND ENABLE QUERY REWRITE AS SELECT E.ENAME, M.ENAME AS MANAGER FROM SCOTT.EMP E, SCOTT.EMP M WHERE E.MGR=M.EMPNO;
SQL> CREATE MATERIALIZED VIEW SCOTT.IN_DEPT REFRESH FAST ON COMMIT ENABLE QUERY REWRITE AS SELECT E.ROWID AS ERID, D.ROWID AS DRID, E.ENAME, D.DNAME FROM SCOTT.EMP E, SCOTT.DEPT D WHERE E.DEPTNO=D.DEPTNO;
在逻辑备数据库上:
1)ON-COMMIT物化视图会在事务提交发生时在逻辑备数据库上自动刷新。
2)ON-DEMAND物化视图不会自动刷新:必须执行DBMS_MVIEW.REFRESH存储过程来刷新。
例如,执行以下命令来刷新在前面示例中创建的ON-DEMAND物化视图:
SQL> ALTER SESSION DISABLE GUARD;
SQL> EXECUTE DBMS_MVIEW.REFRESH (LIST => ‘SCOTT.MANAGED_BY’, METHOD => ‘C’);
如果DBMS_SCHEDULER工作被使用来定期刷新ON-DEMAND物化视图,database guard必须设置为STANDBY。(不可能在PL/SQL块中使用ALTER SESSION DISABLE GUARD语句和让它生效。)
5.3. 在逻辑备数据库上的触发器和约束如何处理
缺省情况下,触发器和约束会在逻辑备数据库上自动启用和处理。
对于由SQL Apply维护的表的触发器和约束:
1)约束—–检查约束会在主数据库上估值,不需要在逻辑备数据库上重新估值
2)触发器—在主数据库上执行触发器的效果会记录和应用到备数据库上。
对于不是SQL Apply维护的表的触发器和约束:
1)约束会估值
2)触发器会触发
5.4. 使用触发器来复制不支持的表
在表上创建的DML触发器的参数DBMS_DDL.SET_TRIGGER_FIRING_PROPERTY fire_once缺省时设置为TRUE。
触发器只有在表被用户进程修改时才触发。在SQL Apply进程中,它们会自动被禁用,因此SQL Apply进程修改表时不会触发。作为SQL Apply进程更改维护的表的结果,存在两种方法来触发触发器:
1)设置触发器的参数fire_once为FALSE,允许它在用户进程或SQL Apply进程的环境中触发
2)设置apply_server_onl参数为TRUE,导致触发器只有在SQL Apply进程的环境中触发,在用户进程的环境中不触发。
| fire_once | apply_server_only | 描述 |
|---|---|---|
| TRUE | FLASE | 这是DML触发器缺省的属性设置。触发器只有在用户进程修改基础表时触发。 |
| FALSE | FALSE | 触发器在用户进程和SQL Apply进程修改基础表的环境中触发。可以使用DBMS_LOGSTDBY.IS_APPLY_SERVER函数区分这两种环境。 |
| TRUE/FALSE | TRUE | 触发器只有在SQL Apply进程修改基础表时触发。触发器在用户进程修改基础表时不触发。因此属性apply_server_only覆写触发器的参数fire_once。 |
由于简单对象类型列而不支持的表,可以通过创建在SQL Apply环境中触发的触发器来复制(设置触发器的参数fire_once为FALSE或设置触发器的apply_server_only参数为TRUE)。可以在主数据库上使用普通的DML触发器来flatten对象类型到可以支持的表。在逻辑备数据库上SQL Apply环境中触发的触发器重组对象类型,以事务的方式更新不支持的表。
下面的示例显示具有简单对象类型的表如何使用触发器来复制。示例显示如何处理插入;相同的规则可以应用到更新和删除。嵌套表和VARRAY也可以使用这种技术和标准化嵌套数据的循环的额外步骤来复制。
-- simple object type
create or replace type Person as object
(FirstName varchar2(50),LastName varchar2(50),BirthDate Date
)-- unsupported object table
create table employees
(IdNumber varchar2(10) ,Department varchar2(50),Info Person
)-- supported table populated via trigger
create table employees_transfer
(t_IdNumber varchar2(10),t_Department varchar2(50),t_FirstName varchar2(50),t_LastName varchar2(50),t_BirthDate Date
)--
-- create this trigger to flatten object table on the primary
-- this trigger will not fire on the standby
--
create or replace trigger flatten_employeesafter insert on employees for each row
declare
begininsert into employees_transfer(t_IdNumber, t_Department, t_FirstName, t_LastName, t_BirthDate)values
(:new.IdNumber, :new.Department, :new.Info.FirstName,:new.Info.LastName, :new.Info.BirthDate);
end--
-- Option#1 (Better Option: Create a trigger and
-- set its apply-server-only property to TRUE)
-- create this trigger at the logical standby database
-- to populate object table on the standby
-- this trigger only fires when apply replicates rows
-- to the standby
--
create or replace trigger reconstruct_employees_asoafter insert on employees_transfer for each row
begininsert into employees (IdNumber, Department, Info)values (:new.t_IdNumber, :new.t_Department,Person(:new.t_FirstName, :new.t_LastName, :new.t_BirthDate));
end
-- set this trigger to fire from the apply server
execute dbms_ddl.set_trigger_firing_property(trig_owner => 'scott', trig_name => 'reconstruct_employees_aso', property => dbms_ddl.apply_server_only, setting => TRUE);--
-- Option#2 (Create a trigger and set
-- its fire-once property to FALSE)
-- create this trigger at the logical standby database
-- to populate object table on the standby
-- this trigger will fire when apply replicates rows to -- the standby, but we will need to make sure we are
-- are executing inside a SQL Apply process by invoking
-- dbms_logstdby.is_apply_server function
--
create or replace trigger reconstruct_employees_nfoafter insert on employees_transfer for each row
beginif dbms_logstdby.is_apply_server() theninsert into employees (IdNumber, Department, Info)values (:new.t_IdNumber, :new.t_Department,Person(:new.t_FirstName, :new.t_LastName, :new.t_BirthDate));end if;
end
-- set this trigger to fire from the apply server
execute dbms_ddl.set_trigger_firing_property(trig_owner => 'scott', trig_name => 'reconstruct_employees_nfo', property => dbms_ddl.fire_once, setting => FALSE);
5.5.在主数据库执行时间点恢复
当逻辑备数据库收到新的redo数据分支时,SQL Apply自动处理新分支的redo数据。
对于逻辑备数据库,如果备数据库没有应用超过新resetlogs SCN的redo数据(超过redo数据新分支的起点),不需要进行人工干预。
下表描述了如何让备数据库与主数据库分支同步。
| 如果备数据库… | 那么… | 执行这些步骤… |
|---|---|---|
| 没有应用超过新resetlogs SCN(超过redo数据新分支起点)的redo数据 | SQL Apply自动处理新分支的redo数据 | 不需要人工干预。SQL Apply使用新分支的redo数据自动同步备数据库。 |
| 已经应用超过新resetlogs SCN(超过redo数据新分支起点)的redo数据和闪回数据库已经在备数据库上启用 | 备数据库恢复到redo数据新分支的未来 | 1.闪回逻辑备数据库到特定的时间点。 2.重启SQL Apply来继续应用redo数据到新的resetlogs分支。 |
| 已经应用超过新resetlogs SCN(超过redo数据新分支起点)的redo数据和闪回数据库没有在备数据库上启用 | 主数据库与备数据库在指定的主数据库分支上偏离 | 重建逻辑备数据库 |
| 缺失从之前分支的redo数据末尾开始的归档redo日志文件 | SQL Apply不能继续直到找回缺失的日志文件 | 找到和注册来自之前分支的缺失的归档redo日志文件 |
5.6. 在逻辑备数据库上运行Oracle流捕获进程
可以在逻辑备数据库上运行Oracle流捕获进程(Oracle Streams capture process)来捕获存在于逻辑备数据库上的任何表的更改(不管它是一个本地表还是正在从主数据库复制的一个被维护的表)。
当捕获到被维护的表的更改时,跟运行在主数据库上的Oracle流捕获进程相比,存在额外的延迟。额外的延迟是由于在逻辑备数据库时,Oracle流捕获进程必须等待更改从主数据库传输到逻辑备数据库和被SQL Apply应用。在大部分情况下,如果运行实时应用,不会超过几秒钟。
Oracle流捕获进程与创建它的数据库关联;与数据库的角色无关。例如,假设有一个主数据库名为Boston和一个逻辑备数据库名为London。不可以在角色转换时,从一个数据库移动Oracle流捕获进程到其他数据库。例如,如果在逻辑备数据库London上创建Oracle流捕获进程,那么它一直在London上,即使London作为角色转换操作的结果(例如swichover或failover)成为主数据库。为了让Oracle流捕获进程在角色转换后继续工作,必须写一个角色转换触发器,比如以下:
create or replace trigger streams_aq_job_role_change1
after DB_ROLE_CHANGE on database
declare
cursor capture_aq_jobs isselect job_name, database_rolefrom dba_scheduler_job_roleswhere job_name like 'AQ_JOB%';
u capture_aq_jobs%ROWTYPE;
my_db_role varchar2(16);beginif (dbms_logstdby.db_is_logstdby() = 1) then my_db_role := 'LOGICAL STANDBY';else my_db_role := 'PRIMARY';end if;open capture_aq_jobs;
loopfetch capture_aq_jobs into u;exit when capture_aq_jobs%NOTFOUND;if (u.database_role != my_db_role) thendbms_scheduler.set_attribute(u.job_name,'database_role', my_db_role);end if;
end loop;
close capture_aq_jobs;exceptionwhen others thenbeginraise;end;
end;
6.调优逻辑备数据库
6.1. 创建主键依赖约束
在主数据库上,如果一个表不存在主键或唯一索引和你确定行是唯一的,那么可以创建一个主键RELY约束。
在逻辑备数据库上,在组成主键的列上创建索引。下面的查询产生一系列表,这些表没有索引信息可以被逻辑备数据库使用来唯一识别行。通过在下面的表上创建索引,性能可以显著地改善。
SQL> SELECT OWNER, TABLE_NAME FROM DBA_TABLES WHERE OWNER NOT IN (SELECT OWNER FROM DBA_LOGSTDBY_SKIP WHERE STATEMENT_OPT = ‘INTERNAL SCHEMA’) MINUS SELECT DISTINCT TABLE_OWNER, TABLE_NAME FROM DBA_INDEXES WHERE INDEX_TYPE NOT LIKE (‘FUNCTION-BASED%’) MINUS SELECT OWNER, TABLE_NAME FROM DBA_LOGSTDBY_UNSUPPORTED;
可以在主数据库上增加一个主键依赖约束到表,如下所示:
1)在主数据库增加主键依赖约束:
SQL> ALTER TABLE HR.TEST_EMPLOYEES ADD PRIMARY KEY (EMPNO) RELY DISABLE;
这确保列EMPNO用来唯一识别表HR.TEST_EMPLOYEES的行,作为表上所做的任何更新的一部分,补充地记录下来。
注意表HR.TEST_EMPLYEES在逻辑备数据库上依旧没有指定唯一索引。这可能会导致UPDATE语句在逻辑备数据库上去做全表扫描。可以在逻辑备数据库上通过增加唯一索引来补救。
参考章节“确保主数据库的表行可以被唯一区别”关于RELY约束的描述。
2)停止SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
3)禁用guard,从而可以修改逻辑备数据库上的被维护表:
SQL> ALTER SESSION DISABLE GUARD;
4)在列EMPNO上增加唯一索引:
SQL> CREATE UNIQUE INDEX UI_TEST_EMP ON HR.TEST_EMPLOYEES (EMPNO);
5)启用guard:
SQL> ALTER SESSION ENABLE GUARD;
6)启用SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
6.2. 在逻辑备数据库上收集数据
在逻辑备数据库上使用STATS 包和视图 V$SYSSTAT 确认哪些表消耗大部分资源和表扫描。
6.3. 调整进程的数量
有3个参数可以被修改来控制分配给SQL Apply的进程数量:MAX_SERVERS,APPLY_SERVERS,和PREPARE_SERVERS。
下面的关系必须总是适用的:
1)APPLY_SERVERS + REPARE_SERVERS = MAX_SERVERS -3
因为SQL Apply总是分别为READER,BUILDER,和ANALYZER角色分配一个进程。
2)缺省时,MAX_SERVERS设置为9,PREPARE_SERVERS设置为1,和APPLY_SERVERS设置为5。
3)Oracle建议通过DBMS_LOGSTDBY.APPLY_SET存储过程只更改MAX_SERVERS参数,允许SQL Apply在PREPARE和APPLY进程之间合理地分配服务器进程。
4)SQL Apply使用进程分配算法来为分配给SQL Apply的每20个服务器进程(由MAX_SERVERS指定)分配1个PREPARE_SERVER进程和限制PREPARE_SERVERS的数量为5。因此,如果设置MAX_SERVERS为1和20之间的任意值,SQL Apply分配1个服务器进程来担任PREPARER,在满足前面描述的关系后,分配剩余的进程为APPLIERS。相似地,如果设置MAX_SERVERS的值在21和24之间,SQL Apply分配2个服务器进程来担任PREPARERS,在满足前面描述的关系后,分配剩余的进程为APPLIERS。只要前面描述的关系满足时,可以通过直接设置APPLY_SERVERS和PREPARE_SERVERS来覆盖内部的进程分配算法。
6.3.1.调整APPLIER进程的数量
在调整APPLIER进程的数量之前,应该确认这样做是否会帮助获得更高的吞吐量。
为了确认这个,执行以下步骤:
1)执行以下查询检查APPLIER进程是否繁忙:
SQL> SELECT COUNT(*) AS IDLE_APPLIER FROM V$LOGSTDBY_PROCESS WHERE TYPE = ‘APPLIER’ and status_code = 16116;
IDLE_APPLIER
-------------------------
0
一旦确认不存在空闲的APPLIER进程,执行以下查询来确保如果选择调整APPLIERS进程的数量,存在足够的可用工作来使用额外的APPLIER进程。
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME = ‘txns applied’ OR NAME
= ‘distinct txns in queue’;
这两个统计数字存放准备被APPLIER进程应用的累积的事务总数和和已经被应用的事务数量。
如果数字(distinct txns in queue – txns applied)高于2倍的可用APPLIER进程数量,增加APPLIER进程的数量可能会带来吞吐量的提升。
假设想调整APPLIER进程的数量从缺省的5到20,同时保持PREPARER进程的数量为1。由于需要满足以下等式:
APPLY_SERVERS + REPARE_SERVERS = MAX_SERVERS -3
必须首先设置MAX_SERVERS为24。一旦完成后,就可以设置APPLY_SERVERS的数量为20,如下所示:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘MAX_SERVERS’, 24);
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘APPLY_SERVERS’, 20);
6.3.2.调整PREPARER进程的数量
需要调整PREPARER进程的数量是比较少见的。在增加它们的数量前,必须确保某些条件为真,如下所示:
1)所有PREPARER进程很繁忙;
2)准备应用的事务数量比可用的APPLIER进程少;
3)存在空闲的APPLIER进程。
下面的步骤显示如何确认这些条件为真:
1)确认所有REPARER进程繁忙:
SQL> SELECT COUNT(*) AS IDLE_PREPARER FROM V$LOGSTDBY_PROCESS WHERE TYPE = ‘PREPARER’ and status_code = 16116;
IDLE_PREPARER
-------------
0
2)确认准备应用的事务数量比可用的APPLIER进程少;
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME = ‘txns applied’ OR NAME = ‘distinct txns in queue’;
NAME VALUE
--------------------- -------
txns applied 27892
distinct txns in queue 12896
SQL> SELECT COUNT(*) AS APPLIER_COUNT FROM V$LOGSTDBY_PROCESS WHERE TYPE = ‘APPLIER’;
APPLIER_COUNT
-------------
20
注:执行查询几次来确保这不是瞬时的事件。
3)确保存在空闲的APPLIER进程:
SQL> SELECT COUNT(*) AS IDLE_APPLIER FROM V$LOGSTDBY_PROCESS WHERE TYPE = ‘APPLIER’ and status_code = 16116;
IDLE_APPLIER
-------------------------
19
在这个例子中,为增加PREPARER进程数量的所有3个必要条件都满足。假设想保持APPLIER进程的数量为20,和增加PREPARER进程的数量从缺省的1到3。由于需要满足以下等式:
APPLY_SERVERS + REPARE_SERVERS = MAX_SERVERS -3
必须首先增加MAX_SERVERS从24到26来容纳增加的PREPARER进程。然后就可以增加PREPARER进程的数量,如下所示:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘MAX_SERVERS’, 26);
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘PREPARE_SERVERS’, 3);
6.4.调整LCR(logical change records)缓存使用的内存
对于某些负载,SQL Apply可能会使用大量的页出操作,因此,减少系统总体的吞吐量。增加分配给LCR缓存的内存可能会有所帮助。
执行以下步骤,确认增加分配给LCR缓存的内存是否是有益的:
1)执行以下查询来获取页出活动的快照:
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME LIKE ‘%page%’ OR NAME LIKE ‘%uptime%’ OR NAME LIKE ‘%idle%’;
NAME VALUE
---------------------------- --------------
coordinator uptime (seconds) 894856
bytes paged out 20000
pageout time (seconds) 2
system idle time (seconds) 1000
2)5分钟后再次执行查询:
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY_STATS WHERE NAME LIKE ‘%page%’ OR NAME LIKE ‘%uptime%’ OR NAME LIKE ‘%idle%’;
NAME VALUE
---------------------------- --------------
coordinator uptime (seconds) 895156
bytes paged out 1020000
pageout time (seconds) 100
system idle time (seconds) 1000
3)计算标准化的页出活动。例如:
Change in coordinator uptime ©= (895156 – 894856) = 300 secs
Amount of additional idle time (I)= (1000 – 1000) = 0
Change in time spent in pageout § = (100 – 2) = 98 secs
Pageout time in comparison to uptime = P/(C-I) = 98/300 ~ 32.67%
理想情况下,页出活动应该不要消耗多于5%的总运行时间。如果继续在持续的间隔里拍快照,发现页出活动继续消耗相当部分的应用时间,增加内存大小可能会提供某些好处。可以通过设置分配给LCR缓存的内存来增加分配给SQL Apply的内存(这个示例中,SGA设置为1GB):
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘MAX_SGA’, 1024);
PL/SQL procedure successfully completed
6.5. 调整事务如何在逻辑备数据库上应用
缺省时,事务在逻辑备数据库上按照在主数据库上提交的精确的顺序被应用。
这种严格的提交事务的缺省顺序允许任何应用程序在逻辑备数据库上透明地运行。
然而,许多应用程序在所有事务当中不需要如此严格的排序。这些应用程序不需要包含不重叠的行集的事务按照与主数据库上相同的提交顺序提交。这种较不严格的排序通常会在逻辑备数据库上带来更高的应用速度。执行以下步骤可以更改提交事务的缺省顺序:
1)停止SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
2)执行以下命令允许事务不按照在主数据库上提交的顺序应用:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_SET(‘PRESERVE_COMMIT_ORDER’, ‘FALSE’);
3)启动SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
使用以下步骤更改回应用模式:
1)停止SQL Apply:
SQL> ALTER DATABASE STOP LOGICAL STANDBY APPLY;
2)恢复参数PRESERVE_COMMIT_ORDER的缺省值:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_UNSET(‘PRESERVE_COMMIT_ORDER’);
3)启动SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
对于典型的在线事务处理(OLTP)负载,不是缺省的模式对比缺省的模式可以提供50%或更高的吞吐量提升。
7.逻辑备数据库环境下的备份和恢复
可以使用传统的可用方法来备份逻辑备数据库,然后通过还原数据库备份和与备份结合在归档日志上执行介质恢复来恢复数据库。
下面的项目在逻辑备数据库的环境下是相关的。
创建和使用本地RMAN恢复目录时的考虑
如果计划创建RMAN恢复目录或执行任何修改恢复目录的RMAN活动,必须在逻辑备数据库上设置GUARD为STANDBY。
如果本地恢复目录只保留在逻辑备数据库的控制文件中,可以让GUARD设置为ALL。
控制文件备份的考虑
Oracle建议在实例化逻辑备数据数据库后立即备份控制文件。
时间点恢复考虑
当SQL Apply在时间点恢复后第一次启动时,必须可以在本地系统上找到要求的归档日志或从主数据库上获取。使用V$LOGSTDBY_PROCESS视图来确认主数据库上是否有任何需要还原的归档日志。
表空间时间点恢复考虑
如果在逻辑备数据库上执行表空间的时间点恢复,必须确保满足以下条件中的一个:
1)表空间不包含由SQL Apply进程正在维护的表或分区
2)如果表空间包含由SQL Apply进程正在维护的表或分区,那么使用DBMS_LOGSTDBY.INSTANTIATE_TABLE存储过程在逻辑备数据库上重新实例化所有包含在恢复表空间的维护的表,或使用DBMS_LOGSTDBY.SKIP存储过程注册所有包含在恢复表空间的表,在逻辑备数据库上从维护表列表中跳过这些表。
8.主数据库执行Open Resetlogs语句后闪回数据库
如果在Oracle Data Guard环境的主数据库发生一个错误,备数据库正在使用实时应用,那么相同的错误也会应用到备数据库。如果闪回数据库已启用,可以复原主数据库和备数据库到错误之前的状态。
为了这些做,在主数据库上执行FLASHBACK DATABASE和OPEN RESETLOGS语句,然后在重启Apply Service之前,在备数据库上执行相应的FLASHBACK STANDBY DATABASE语句。如果闪回数据库没有启用,那么在主数据库上执行时间点恢复之后,需要重建备数据库。
8.1. 闪回逻辑备数据库到指定时间点
这些步骤描述如何闪回主数据库和使用OPEN RESETLOGS语句打开它后避免重建逻辑备数据库。
注:如果SQL Apply检测到主数据库resetlogs操作的发生,如果可能这么做而不需要闪回逻辑备数据库,它会自动挖掘正确的redo分支。否则,SQL Apply会停止和报错“ORA-1346: LogMiner processed redo beyond specified reset log scn”。在这个部分中,假设SQL Apply已经停止和有这个报错。
1)在主数据库上,使用以下查询来获取主数据库在RESETLOGS操作发生前2个SCN的SCN值:
SQL> SELECT TO_CHAR(RESETLOGS_CHANGE# - 2) AS FLASHBACK_SCN FROM V$DATABASE;
2)在逻辑备数据库上,确认闪回操作的目标SCN。
SQL> SELECT DBMS_LOGSTDBY.MAP_PRIMARY_SCN (PRIMARY_SCN => FLASHBACK_SCN) AS TARGET_SCN FROM DUAL;
3)执行下面的SQL语句来闪回逻辑备数据库到指定的SCN,然后使用RESETLOGS选项打开逻辑备数据库:
SQL> SHUTDOWN;
SQL> STARTUP MOUNT EXCLUSIVE;
SQL> FLASHBACK DATABASE TO SCN <TARGET_SCN>;
SQL> ALTER DATABASE OPEN RESETLOGS;
4) 在SQL启动之前确认来自主数据库新分支的日志文件已经注册。
在主数据库执行以下查询:
SQL> SELECT resetlogs_id FROM V$DATABASE_INCARNATION WHERE status = ‘CURRENT’;
在备数据库上执行以下查询:
SQL> SELECT * FROM DBA_LOGSTDBY_LOG WHERE resetlogs_id = resetlogs_id_at_primary;
如果返回一行或多行,它确认存在注册的来自主数据库新分支的日志文件。
1) 启动SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
9. 主数据库指定NOLOGGING子语句以后恢复
有些SQL语句允许指定NOLOGGING子语句,因此操作就不会记录在在线redo日志文件中。
实际上,redo记录仍然会写到在线redo日志文件,但没有数据与记录关联。这将导致备站点上的日志应用程序或数据访问错误,可能需要手动恢复来重新开始applying日志文件。
9.1. 在逻辑备数据库上的恢复步骤
在逻辑备数据库上,当SQL Apply遇到在表上执行NOLOGGING子语句的操作的redo记录时,它会停止和报以下错误:
ORA-16211 unsupported record found in the archived redo log
为了在指定的NOLOGGING子语句之后进行恢复,按照章节“在逻辑备数据库上增加或重建表”所描述的方法,重建来自主数据库的一个或多个表。
注:一般情况下,使用NOLOGGING子语句是不建议的。因此,如果你提前知道使用NOLOGGING子语句的操作会在主数据库的某些表上执行,那么你可能想阻止应用与这些表相关的SQL语句到逻辑备数据库。可以通过使用DBMS_LOGSTDBY.SKIP存储过程来实现。
来源:《Oracle Data Guard Concepts and Administration, 19c》
相关文章:
管理逻辑备数据库(Logical Standby Database)
1. SQL Apply架构概述 SQL Apply使用一组后台进程来应用来自主数据库的更改到逻辑备数据库。 在日志挖掘和应用处理中涉及到的不同的进程和它们的功能如下: 在日志挖掘过程中: 1)READER进程从归档redo日志文件或备redo日志文件中读取redo记…...

【C++】构造函数(初始化列表)、explicit、 Static成员、友元、内部类、匿名对象
构造函数(初始化列表)前提构造函数体赋值初始化列表explicit关键字static成员概念特性(重要)有元友元函数友元类内部类匿名对象构造函数(初始化列表) 前提 前面 六个默认成员对象中我们已经学过什么是构造…...
再来看看几个最常见和最基本的索引使用规则)
(六十)再来看看几个最常见和最基本的索引使用规则
今天我们来讲一下最常见和最基本的几个索引使用规则,也就是说,当我们建立好一个联合索引之后,我们的SQL语句要怎么写,才能让他的查询使用到我们建立好的索引呢? 下面就一起来看看,还是用之前的例子来说明。…...

机器学习与目标检测作业(数组相加:形状需要满足哪些条件)
机器学习与目标检测(数组相加:形状需要满足哪些条件)机器学习与目标检测(数组相加:形状需要满足哪些条件)一、形状相同1.1、形状相同示例程序二、符合广播机制2.1、符合广播机制的描述2.2、符合广播机制的示例程序机器学习与目标检…...
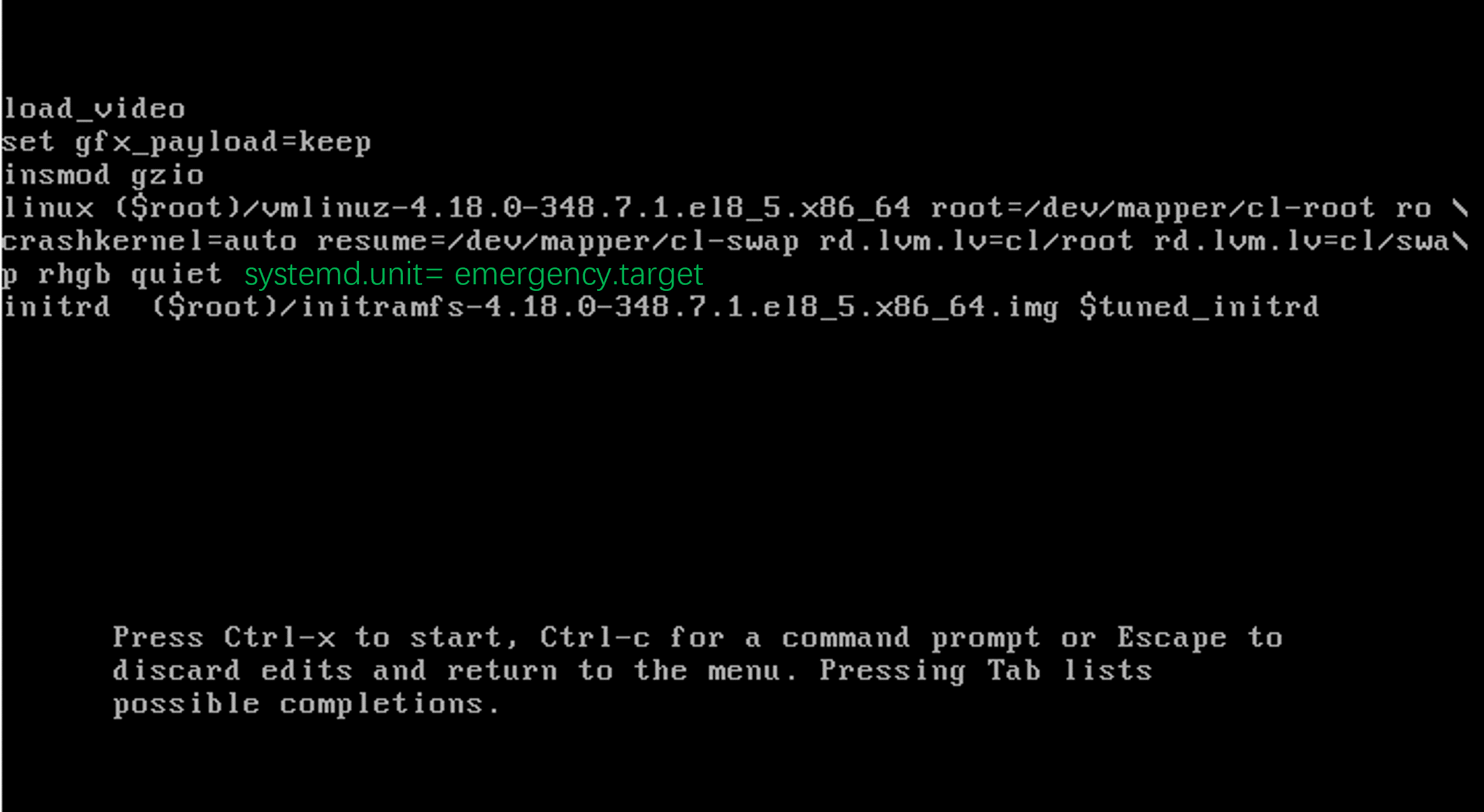
CentOS救援模式(Rescue Mode)及紧急模式(Emergency Mode)
当CentOS操作系统崩溃,无法正常启动时,可以通过救援模式或者紧急模式进行系统登录。启动CentOS, 当出现下面界面时,按e进入编辑界面。在编辑界面里,加入参数:systemd.unitrescue.target ,然后Ctrl-X启动进入…...
从面试官角度告诉你高级性能测试工程师面试必问的十大问题
目录 1、介绍下最近做过的项目,背景、预期指标、系统架构、场景设计及遇到的性能问题,定位分析及优化; 2、项目处于什么阶段适合性能测试介入,原因是什么? 3、性能测试场景设计要考虑哪些因素? 4、对于一…...
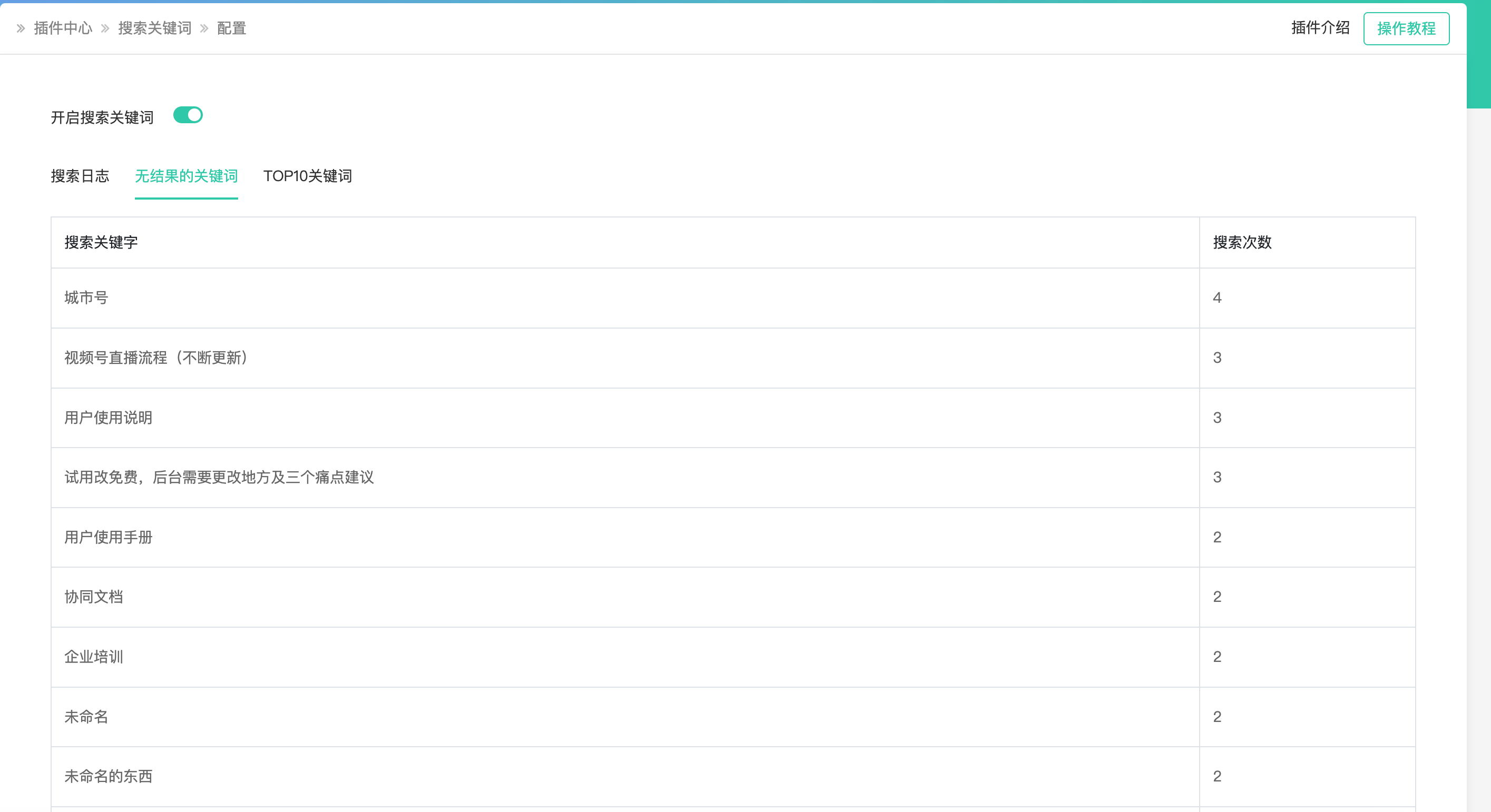
通过知识库深度了解用户的心理
自助服务知识库的价值是毋庸置疑的,如果执行得当,可以帮助减少客户服务团队的工作量,仅仅编写内容和发布是不够的,需要知道知识库对客户来说是否有用,需要了解客户获得的反馈,如果你正确的使用知识库软件&a…...
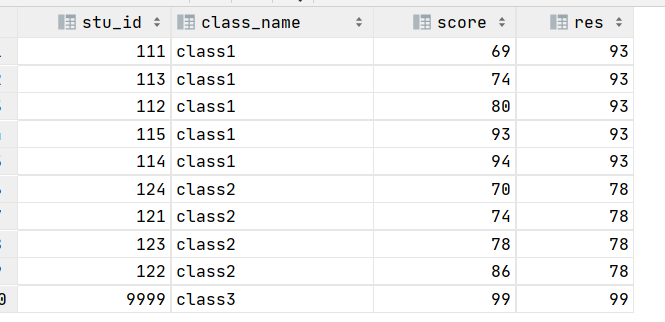
HiveSQL一天一个小技巧:如何将分组内数据填充完整?
0 需求1 需求分析需求分析:需求中需要求出分组中按成绩排名取倒数第二的值作为新字段,且分组内没有倒数第二条的时候取当前值。如果本题只是求分组内排序后倒数第二,则很简单,使用row_number()函数即可求出,但是本题问…...
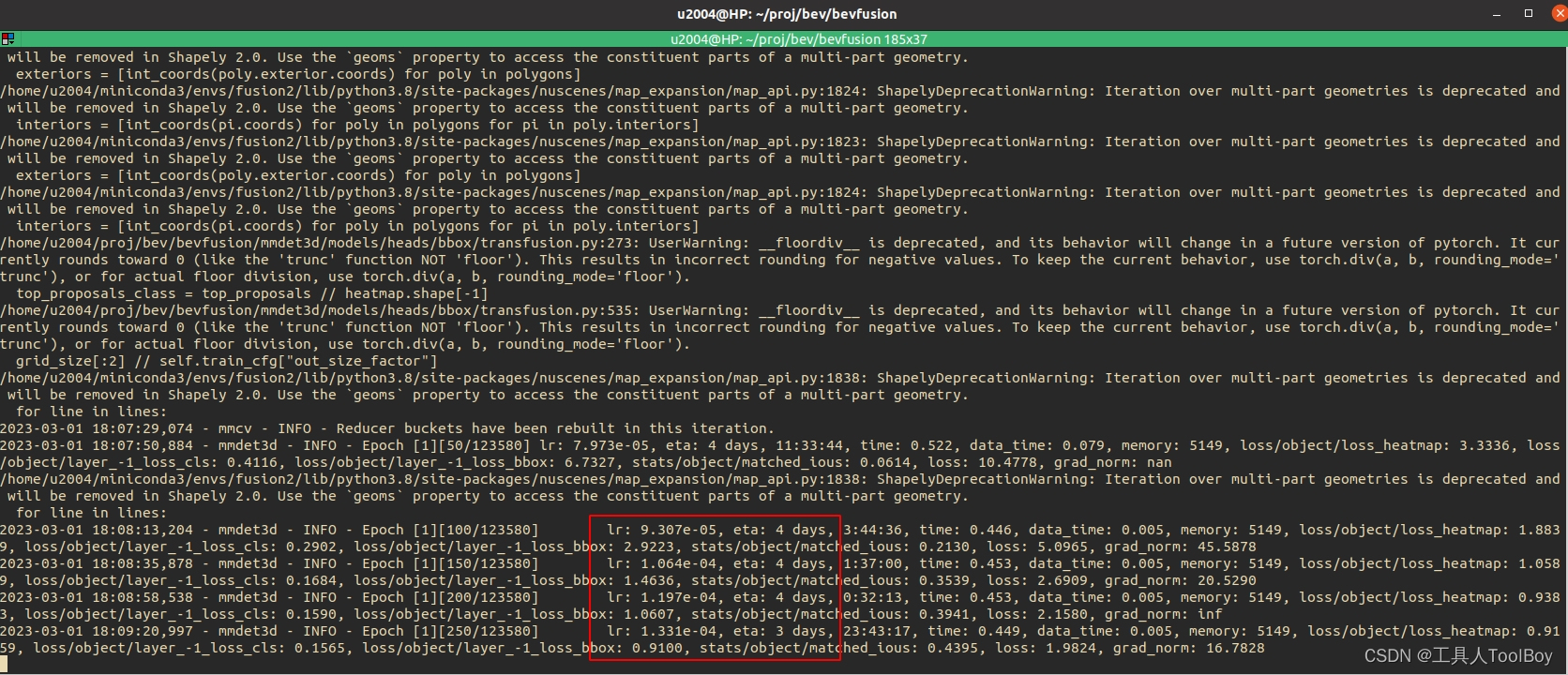
【亲测可用】BEV Fusion (MIT) 环境配置
CUDA环境 首先我们需要打上对应版本的显卡驱动: 接下来下载CUDA包和CUDNN包: wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run sudo sh cuda_11.6.2_510.47.03_linux.runwget htt…...
【调试方法】基于vs环境下的实用调试技巧
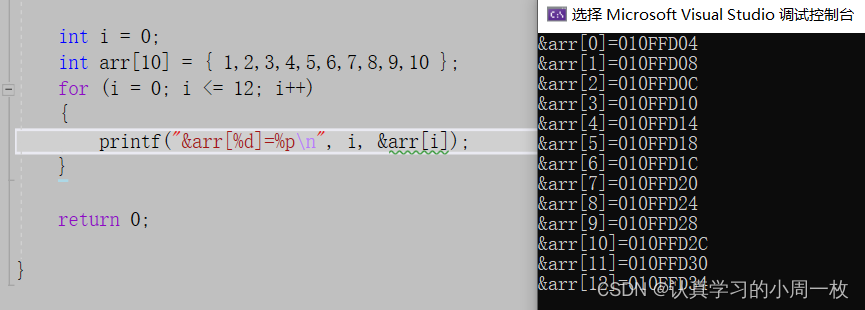
前言: 对万千程序猿来说,在这个世界上如果有比写程序更痛苦的事情,那一定是亲手找出自己编写的程序中的bug(漏洞)。作为新手在我们日常写代码中,经常会出现报错的情况(好的程序员只是比我们见过…...

单目标应用:蜣螂优化算法DBO优化RBF神经网络实现数据预测(提供MATLAB代码)
一、RBF神经网络 1988年,Broomhead和Lowc根据生物神经元具有局部响应这一特点,将RBF引入神经网络设计中,产生了RBF(Radical Basis Function)。1989年,Jackson论证了RBF神经网络对非线性连续函数的一致逼近性能。 RBF的基本思想是…...
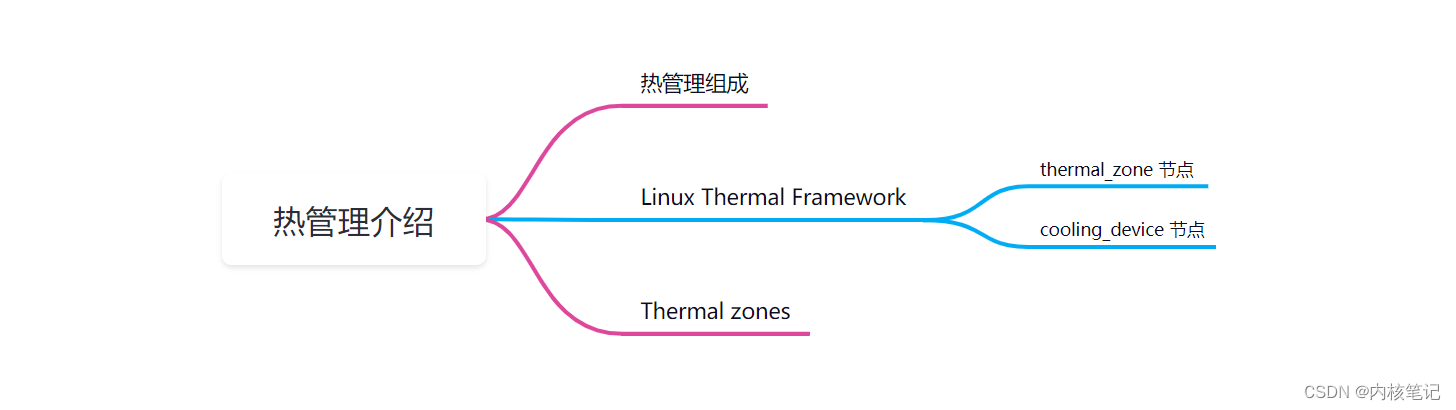
MTK平台开发入门到精通(Thermal篇)热管理介绍
文章目录 一、热管理组成二、Linux Thermal Framework2.1、thermal_zone 节点2.2、cooling_device 节点三、Thermal zones沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍MTK平台的热管理机制,热管理机制是为了防止模组在高温下工作导致硬件损坏而存在的…...
最好的 QML 教程,让你的代码飞起来!
想必大家都知道,亮哥一直深耕于 CSDN,坚持了好很多年,目前为止,原创已经 500 多篇了,一路走来相当不易。当然了,中间有段时间比较忙,没怎么更新。就拿 QML 来说,最早的一篇文章还是 …...
——stack容器的基础理论知识)
笔记(六)——stack容器的基础理论知识
stack是堆栈容器,元素遵循先进后出的顺序。头文件:#include<stack>一、stack容器的对象构造方法stack采用模板类实现默认构造例如stack<T> vecT;#include<iostream> #include<stack> using namespace std; int main(…...
Web前端学习:四 - 练习
三九–四一:百度页面制作 1、左右居中: text-align: center; 2、去掉li默认的状态 list-style: none; li中有的有点,有的有序,此代码去掉默认状态 3、伪类:hovar 一般显示为color: #0f0e0f, 当鼠标接触时…...
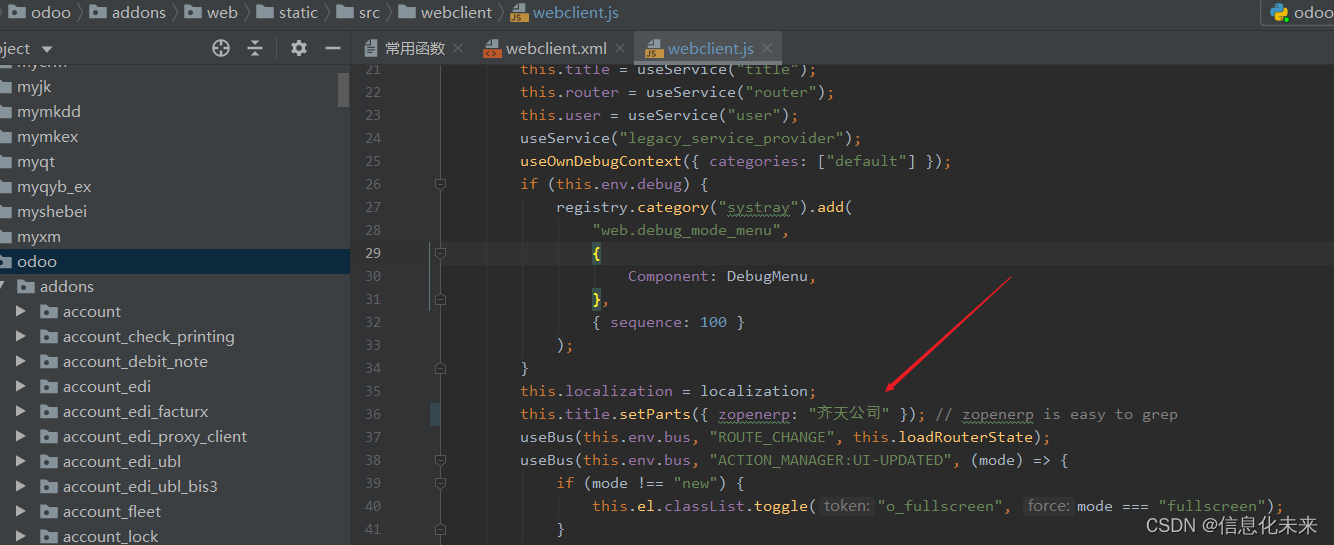
odoo15 标题栏自定义
odoo15 标题栏自定义 如何显示为自定义呢 效果如下: 代码分析: export class WebClient extends Component {setup() {this.menuService = useService("menu");this.actionService = useService("action");this.title = useService("title&…...

视觉SLAM十四讲 ch3 (三维空间刚体运动)笔记
本讲目标 ●理解三维空间的刚体运动描述方式:旋转矩阵、变换矩阵、四元数和欧拉角。 ●学握Eigen库的矩阵、几何模块使用方法。 旋转矩阵、变换矩阵 向量外积 向量外积(又称叉积或向量积)是一种重要的向量运算,它表示两个向量所形成的平行…...

问题解决:java.net.SocketTimeoutException: Read timed out
简单了解Sockets Sockets:两个计算机应用程序之间逻辑链接的一个端点,是应用程序用来通过网络发送和接收数据的逻辑接口 是IP地址和端口号的组合每个Socket都被分配了一个用于标识服务的特定端口号基于连接的服务使用基于tcp的流Sockets Java为客户端…...

前端代码优化方法
1.封装的css样式,增加样式复用性。如果页面加载10个css文件,每个文件1k,那么也要比只加载一个100k的css文件慢 2.减少css嵌套,最好不要嵌套三层以上 3.不要在ID选择器前面进行嵌套,ID本来就是唯一的而且权限值大,嵌套完…...

【批处理脚本】-1.16-文件内字符串查找增强命令findstr
"><--点击返回「批处理BAT从入门到精通」总目录--> 共9页精讲(列举了所有findstr的用法,图文并茂,通俗易懂) 在从事“嵌入式软件开发”和“Autosar工具开发软件”过程中,经常会在其集成开发环境IDE(CodeWarrior,S32K DS,Davinci,EB Tresos,ETAS…)中…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...

跨平台商品数据接口的标准化与规范化发展路径:淘宝京东拼多多的最新实践
在电商行业蓬勃发展的当下,多平台运营已成为众多商家的必然选择。然而,不同电商平台在商品数据接口方面存在差异,导致商家在跨平台运营时面临诸多挑战,如数据对接困难、运营效率低下、用户体验不一致等。跨平台商品数据接口的标准…...

【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...

【版本控制】GitHub Desktop 入门教程与开源协作全流程解析
目录 0 引言1 GitHub Desktop 入门教程1.1 安装与基础配置1.2 核心功能使用指南仓库管理日常开发流程分支管理 2 GitHub 开源协作流程详解2.1 Fork & Pull Request 模型2.2 完整协作流程步骤步骤 1: Fork(创建个人副本)步骤 2: Clone(克隆…...

【java】【服务器】线程上下文丢失 是指什么
目录 ■前言 ■正文开始 线程上下文的核心组成部分 为什么会出现上下文丢失? 直观示例说明 为什么上下文如此重要? 解决上下文丢失的关键 总结 ■如果我想在servlet中使用线程,代码应该如何实现 推荐方案:使用 ManagedE…...