基于Langchain的txt文本向量库搭建与检索
这里的源码主要来自于Langchain-ChatGLM中的向量库部分,做了一些代码上的修改和封装,以适用于基于问题和包含数据库表描述的txt文件(文件名为库表名,文件内容为库表中的字段及描述)对数据库表进行快速检索。
中文分词类
splitter.py
from langchain.text_splitter import CharacterTextSplitter
import re
from typing import Listclass ChineseTextSplitter(CharacterTextSplitter):def __init__(self, pdf: bool = False, sentence_size: int = 100, **kwargs):super().__init__(**kwargs)self.pdf = pdfself.sentence_size = sentence_sizedef split_text1(self, text: str) -> List[str]:if self.pdf:text = re.sub(r"\n{3,}", "\n", text)text = re.sub('\s', ' ', text)text = text.replace("\n\n", "")sent_sep_pattern = re.compile('([﹒﹔﹖﹗。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))') # del :;sent_list = []for ele in sent_sep_pattern.split(text):if sent_sep_pattern.match(ele) and sent_list:sent_list[-1] += eleelif ele:sent_list.append(ele)return sent_listdef split_text(self, text: str) -> List[str]: ##此处需要进一步优化逻辑if self.pdf:text = re.sub(r"\n{3,}", r"\n", text)text = re.sub('\s', " ", text)text = re.sub("\n\n", "", text)text = re.sub(r'([;;!?。!?\?])([^”’])', r"\1\n\2", text) # 单字符断句符text = re.sub(r'(\.{6})([^"’”」』])', r"\1\n\2", text) # 英文省略号text = re.sub(r'(\…{2})([^"’”」』])', r"\1\n\2", text) # 中文省略号text = re.sub(r'([;;!?。!?\?]["’”」』]{0,2})([^;;!?,。!?\?])', r'\1\n\2', text)# 如果双引号前有终止符,那么双引号才是句子的终点,把分句符\n放到双引号后,注意前面的几句都小心保留了双引号text = text.rstrip() # 段尾如果有多余的\n就去掉它# 很多规则中会考虑分号;,但是这里我把它忽略不计,破折号、英文双引号等同样忽略,需要的再做些简单调整即可。ls = [i for i in text.split("\n") if i]for ele in ls:if len(ele) > self.sentence_size:ele1 = re.sub(r'([,,]["’”」』]{0,2})([^,,])', r'\1\n\2', ele)ele1_ls = ele1.split("\n")for ele_ele1 in ele1_ls:if len(ele_ele1) > self.sentence_size:ele_ele2 = re.sub(r'([\n]{1,}| {2,}["’”」』]{0,2})([^\s])', r'\1\n\2', ele_ele1)ele2_ls = ele_ele2.split("\n")for ele_ele2 in ele2_ls:if len(ele_ele2) > self.sentence_size:ele_ele3 = re.sub('( ["’”」』]{0,2})([^ ])', r'\1\n\2', ele_ele2)ele2_id = ele2_ls.index(ele_ele2)ele2_ls = ele2_ls[:ele2_id] + [i for i in ele_ele3.split("\n") if i] + ele2_ls[ele2_id + 1:]ele_id = ele1_ls.index(ele_ele1)ele1_ls = ele1_ls[:ele_id] + [i for i in ele2_ls if i] + ele1_ls[ele_id + 1:]id = ls.index(ele)ls = ls[:id] + [i for i in ele1_ls if i] + ls[id + 1:]return ls
faiss向量库类
myfaiss.py
from langchain.vectorstores import FAISS
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.faiss import dependable_faiss_import
from typing import Any, Callable, List, Dict
from langchain.docstore.base import Docstore
from langchain.docstore.document import Document
import numpy as np
import copy
import osclass MyFAISS(FAISS, VectorStore):def __init__(self,embedding_function: Callable,index: Any,docstore: Docstore,index_to_docstore_id: Dict[int, str],normalize_L2: bool = False,):super().__init__(embedding_function=embedding_function,index=index,docstore=docstore,index_to_docstore_id=index_to_docstore_id,normalize_L2=normalize_L2)def seperate_list(self, ls: List[int]) -> List[List[int]]:lists = []ls1 = [ls[0]]source1 = self.index_to_docstore_source(ls[0])for i in range(1, len(ls)):if ls[i - 1] + 1 == ls[i] and self.index_to_docstore_source(ls[i]) == source1:ls1.append(ls[i])else:lists.append(ls1)ls1 = [ls[i]]source1 = self.index_to_docstore_source(ls[i])lists.append(ls1)return listsdef similarity_search_with_score_by_vector(self, embedding: List[float], k: int = 4) -> List[Document]:faiss = dependable_faiss_import()# (1,1024)vector = np.array([embedding], dtype=np.float32)# 默认FALSEif self._normalize_L2:faiss.normalize_L2(vector)# shape均为(1, k)scores, indices = self.index.search(vector, k)docs = []id_set = set()# 存储关键句keysentences = []# 遍历找到的k个最近相关文档的索引# top-k是第一次的筛选条件,score是第二次的筛选条件for j, i in enumerate(indices[0]):if i in self.index_to_docstore_id:_id = self.index_to_docstore_id[i]# 执行接下来的操作else:continue# index→id→contentdoc = self.docstore.search(_id)doc.metadata["score"] = int(scores[0][j])docs.append(doc)# 其实存的都是indexid_set.add(i)docs.sort(key=lambda doc: doc.metadata['score'])return docs
嵌入检索类
embedder.py
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.document_loaders import TextLoader
from embeddings.splitter import ChineseTextSplitter
from embeddings.myfaiss import MyFAISS
import os
import torch
from config import *def torch_gc():if torch.cuda.is_available():# with torch.cuda.device(DEVICE):torch.cuda.empty_cache()torch.cuda.ipc_collect()elif torch.backends.mps.is_available():try:from torch.mps import empty_cacheempty_cache()except Exception as e:print(e)print("如果您使用的是 macOS 建议将 pytorch 版本升级至 2.0.0 或更高版本,以支持及时清理 torch 产生的内存占用。")class Embedder:def __init__(self, config):self.model = HuggingFaceEmbeddings(model_name="/home/df1500/NLP/LLM/pretrained_model/WordEmbeddings/"+config.emb_model,model_kwargs={'device': 'cuda'})self.config = configself.create_vector_score()self.vector_store = MyFAISS.load_local(self.config.db_vs_path, self.model)def load_file(self, filepath):# 对文件分词if filepath.lower().endswith(".txt"):loader = TextLoader(filepath, autodetect_encoding=True)textsplitter = ChineseTextSplitter(pdf=False, sentence_size=self.config.sentence_size)docs = loader.load_and_split(textsplitter)else:raise Exception("{}文件不是txt格式".format(filepath))return docsdef txt2vector_store(self, filepaths):# 批量建立知识库docs = []for filepath in filepaths:try:docs += self.load_file(filepath)except Exception as e:raise Exception("{}文件加载失败".format(filepath))print("文件加载完毕,正在生成向量库")vector_store = MyFAISS.from_documents(docs, self.model)torch_gc()vector_store.save_local(self.config.db_vs_path)def create_vector_score(self):if "index.faiss" not in os.listdir(self.config.db_vs_path):filepaths = os.listdir(self.config.db_doc_path)filepaths = [os.path.join(self.config.db_doc_path, filepath) for filepath in filepaths]self.txt2vector_store(filepaths)print("向量库已建立成功")def get_topk_db(self, query):related_dbs_with_score = self.vector_store.similarity_search_with_score(query, k=self.config.sim_k)topk_db = [{'匹配句': db_data.page_content, '数据库': os.path.basename(db_data.metadata['source'])[:-4], '得分': db_data.metadata['score']} for db_data in related_dbs_with_score]return topk_db
测试代码
Config是用来传参的类,这里略去定义
if __name__ == '__main__':Conf = Config()configs = Conf.get_config()embedder = Embedder(configs)query = "公司哪个月的出勤率是最高的?"topk_db = embedder.get_topk_db(query)print(topk_db)
相关文章:

基于Langchain的txt文本向量库搭建与检索
这里的源码主要来自于Langchain-ChatGLM中的向量库部分,做了一些代码上的修改和封装,以适用于基于问题和包含数据库表描述的txt文件(文件名为库表名,文件内容为库表中的字段及描述)对数据库表进行快速检索。 中文分词…...

vue2-router
1.基础 1.1.安装 npm install vue-router3.6.5 1.2.引入 import VueRouter from "vue-router" 1.3.注册 Vue.use(VueRouter) 1.4.创建 const router new VueRouter({routes: [{path:/page1, page1},{path:/page2, page2}]} ) 1.5.引用 new Vue({render: h >…...

css新闻链接案例
利用html和css构建出新闻链接案例,使用渐变色做出背景色变化 background: linear-gradient(to bottom, rgb(137, 210, 251), rgb(238, 248, 254), white); 利用背景图片,调整位置完成 dd { height: 28px; line-height: 28px; background-image: url(./图…...
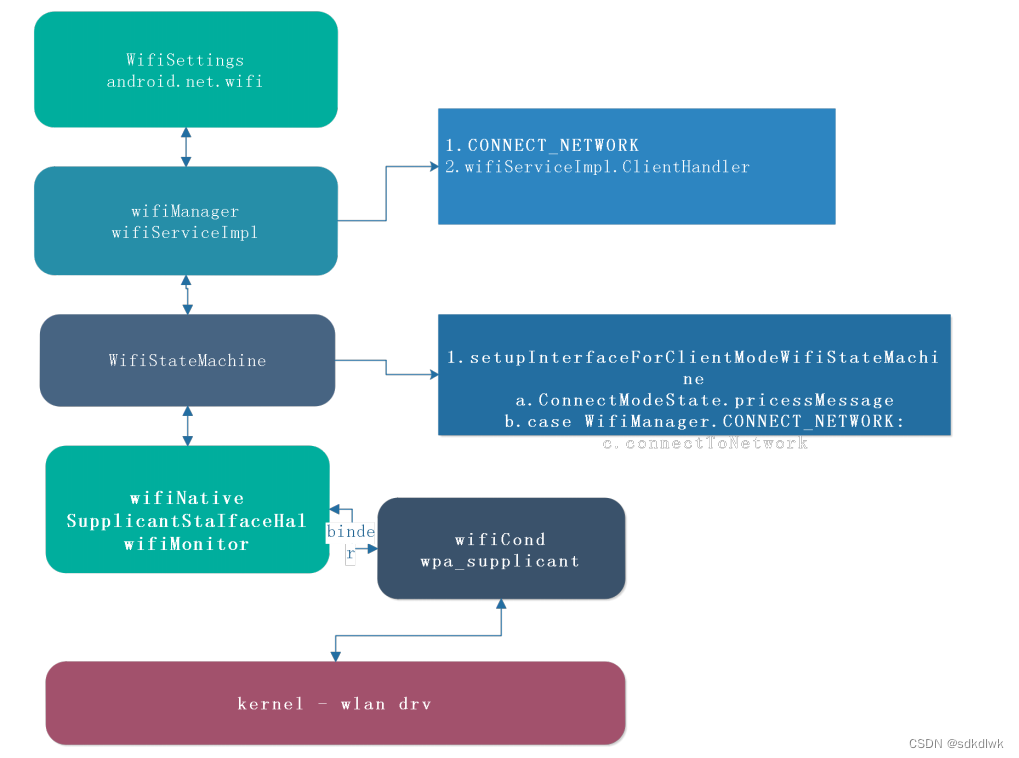
Android wifi连接和获取IP分析
wifi 连接&获取IP 流程图 代码流程分析 一、关联阶段 1. WifiSettings.submit – > WifiManager WifiSettings 干的事情比较简单,当在dialog完成ssid 以及密码填充后,直接call WifiManager save 即可WifiManager 收到Save 之后,就开…...
)
MLIR笔记(5)
4.3.4. 图区域 在MLIR中,区域里类似图的语义由RegionKind::Graph来表示。对没有控制流的并发语义,以及通用有向图数据结构的建模,图区域是合适的。图区域适用于表示耦合值之间的循环关系,这些关系没有基本的序。例如,…...
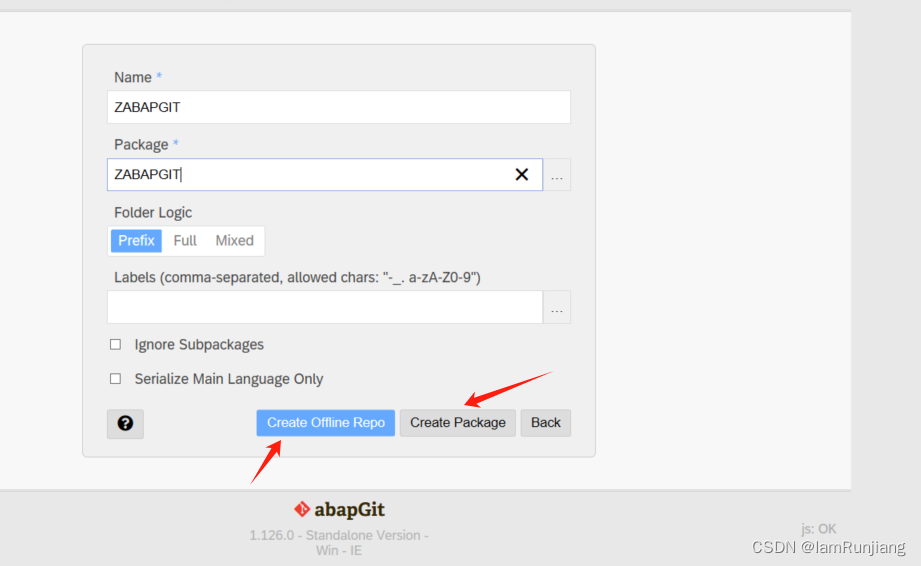
abapgit 安装及使用
abapgit 需求 SA[ BASIS 版本 702 及以上 版本查看路径如下: 安装步骤如下: 1. 下载abapgit 独立版本 程序 链接如下:raw.githubusercontent.com/abapGit/build/main/zabapgit_standalone.prog.abap 2.安装开发版本 2.1 在线安装 前置条…...

园区无线覆盖方案(智慧园区综合解决方案)
李经理正苦恼头疼的工业园区数字化改造项目。近年企业快速增长,园区内Argent工业设备激增,IT部门应接不暇。为确保生产系统稳定运行,IT管理团队经过反复摸索,决定进行全面的数字化升级。然而改造之艰巨远超想象——混杂的接入环境、复杂的专线部署、长达数月的建设周期,种种…...

配置中心--Spring Cloud Config
目录 概述 环境说明 步骤 创建远端git仓库 准备配置文件 配置中心--服务端 配置中心--客户端 配置中心的高可用 配置中心--服务端 配置中心--客户端 消息总线刷新配置 配置中心--服务端 配置中心--客户端 概述 因为微服务架构有很多个服务,手动一个一…...
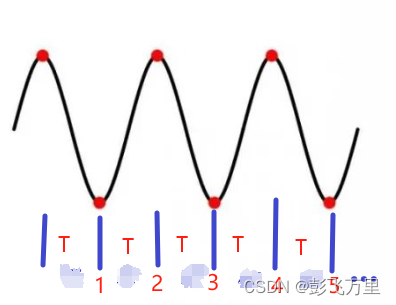
笔记-模拟角频率和数字角频率的关系理解
先建议阅读前人此文(点击这里),有助于理解。 模拟频率:f 模拟角频率:Ω 数字角频率:ω 其中:在模拟信号中Ω 2πf 正弦波表示:sin(2πft) sin(Ωt) 数字信号就是离散的ÿ…...

Zookeeper+Kafka集群
注:本章使用的Kafka为2.7.0版本 Zookeeper概述 1.Zookeeper定义 Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。 2.Zookeeper工作机制 Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理…...
Sunshine+Moonlight+Android手机串流配置(局域网、无手柄)
目录 前言Sunshine(服务端)ApplicationConfigurationGeneralAdvance Moonlight(客户端)配对打开虚拟手柄串流按键调整退出串流 原神,启动! 前言 写这篇文章单纯是因为搜来搜去没有很符合我需求的教程&#…...
 并由函数返回被删元素的值。空出的位 置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。)
从顺序表中删除具有最小值的元素(假设唯一) 并由函数返回被删元素的值。空出的位 置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。
题目描述:从顺序表中删除具有最小值的元素(假设唯一) 并由函数返回被删元素的值。空出的位置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。 bool DeleteMin(SqList &L,int &min){if(L.length 0)return false;min L…...
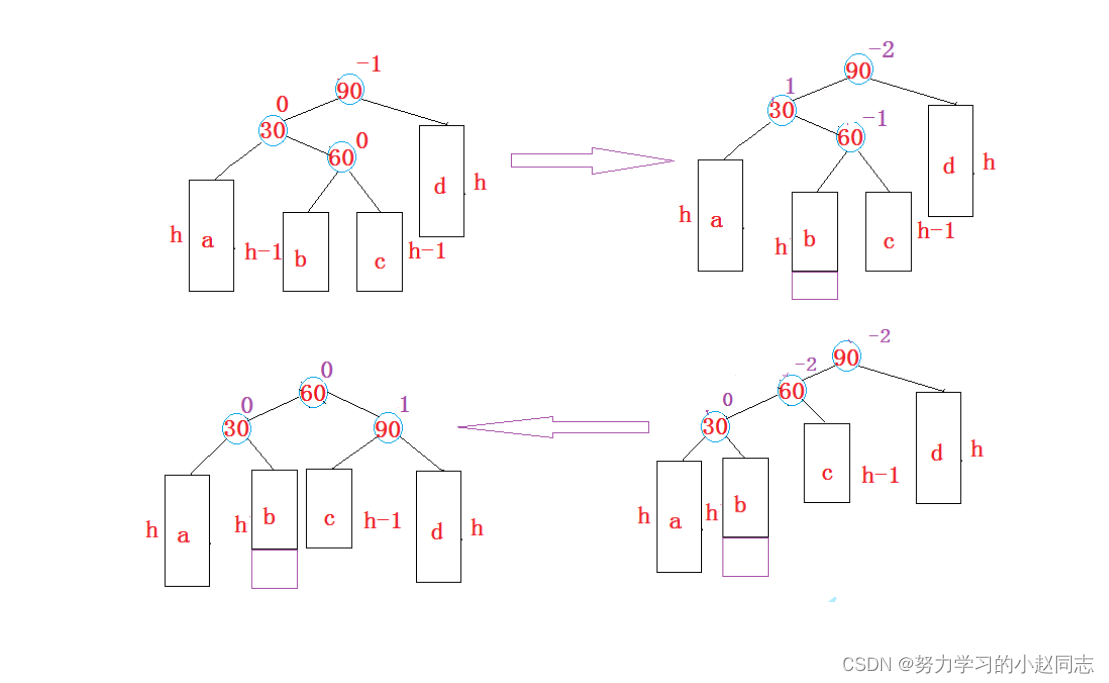
详解—[C++ 数据结构]—AVL树
目录 一.AVL树的概念 二、AVL树节点的定义 三、AVL树的插入 3.1插入方法 四、AVL树的旋转 1. 新节点插入较高左子树的左侧---左左:右单旋 2. 新节点插入较高右子树的右侧---右右:左单旋 3.新节点插入较高左子树的右侧---左右:先左单旋…...
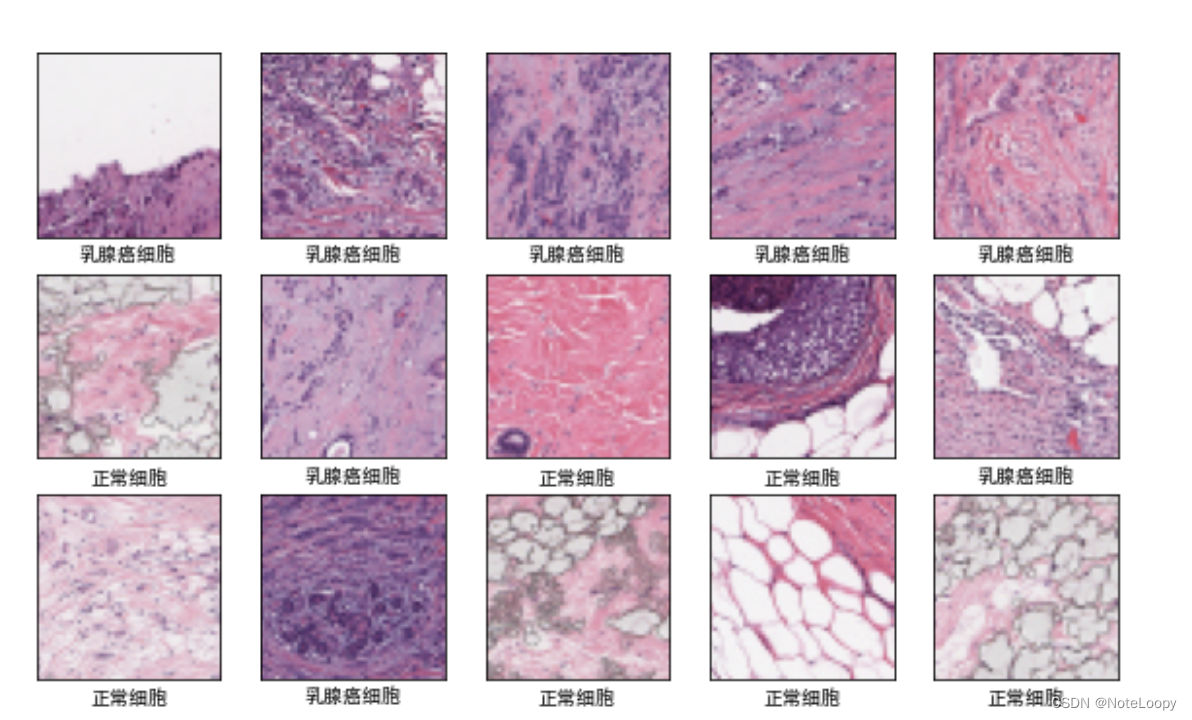
卷积神经网络(CNN):乳腺癌识别.ipynb
文章目录 一、前言一、设置GPU二、导入数据1. 导入数据2. 检查数据3. 配置数据集4. 数据可视化 三、构建模型四、编译五、训练模型六、评估模型1. Accuracy与Loss图2. 混淆矩阵3. 各项指标评估 一、前言 我的环境: 语言环境:Python3.6.5编译器…...
有文件实体的后门无文件实体的后门rootkit后门
有文件实体后门和无文件实体后门&RootKit后门 什么是有文件的实体后门: 在传统的webshell当中,后门代码都是可以精确定位到某一个文件上去的,你可以rm删除它,可以鼠标右键操作它,它是有一个文件实体对象存在的。…...

GPT实战系列-大模型训练和预测,如何加速、降低显存
GPT实战系列-大模型训练和预测,如何加速、降低显存 不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,…...

SQL Sever 基础知识 - 数据排序
SQL Sever 基础知识 - 二 、数据排序 二 、对数据进行排序第1节 ORDER BY 子句简介第2节 ORDER BY 子句示例2.1 按一列升序对结果集进行排序2.2 按一列降序对结果集进行排序2.3 按多列对结果集排序2.4 按多列对结果集不同排序2.5 按不在选择列表中的列对结果集进行排序2.6 按表…...

vscode配置使用 cpplint
标题安装clang-format和cpplint sudo apt-get install clang-format sudo pip3 install cpplint标题以下settings.json文件放置xxx/Code/User目录 settings.json {"sync.forceDownload": false,"workbench.sideBar.location": "right","…...
C++ 系列 第四篇 C++ 数据类型上篇—基本类型
系列文章 C 系列 前篇 为什么学习C 及学习计划-CSDN博客 C 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客 C 系列 第二篇 你真的了解C吗?本篇带你走进C的世界-CSDN博客 C 系列 第三篇 C程序的基本结构-CSDN博客 前言 面向对象编程(OOP)的…...
C++ 指针详解
目录 一、指针概述 指针的定义 指针的大小 指针的解引用 野指针 指针未初始化 指针越界访问 指针运算 二级指针 指针与数组 二、字符指针 三、指针数组 四、数组指针 函数指针 函数指针数组 指向函数指针数组的指针 回调函数 指针与数组 一维数组 字符数组…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

JMeter实现RSA签名验签全流程实战
1. 为什么RSA加密接口测试总卡在“连通但失败”这一步? 你有没有遇到过这种情况:接口文档写得清清楚楚,Postman里填好URL、Header、Body,一发请求——返回 {"code":4001,"msg":"签名验证失败"} …...