基于jsp的搜索引擎
摘 要
随着互联网的不断发展和日益普及,网上的信息量在迅速地增长,在2004年4月,全球Web页面的数目已经超过40亿,中国的网页数估计也超过了3亿。 目前人们从网上获得信息的主要工具是浏览器,搜索引擎在网络中占有举足轻重的地位,本文将在此深入的对搜索引擎做一个研究与阐述。并且详细介绍了基于因特网的搜索引擎的系统结构,然后从网络机器人、索引引擎、Web服务器三个方面进行详细的说明。为了更加深刻的理解这种技术,本人还亲自实现了一个简单的搜索引擎Damon。
关键词: 1、jsp搜索引擎 2、spider 3、Lucene
目 录
一、前言 6
二、搜索引擎的历史渊源 7
三、搜索引擎基本结构 9
(一)网络机器人 9
(二)索引与搜索 9
(三)Web服务器 10
(四)搜索引擎的主要指标及分析 10
四、网络机器人 11
(一)什么是网络机器人 11
(二)网络机器人的结构分析 11
(三)Spider程序结构 12
(四)如何提高程序性能 13
五、基于Tomcat的Web服务器jsp搜索引擎程序设计详解 14
(一)开发工具、平台及资源 14
(二)Lucene开源组件简介 14
(三)引入基于Tomcat的Web服务器开发设计 15
(四)用户接口设计 16
(五)机器人的设计分析 18
(六)关于程序说明 23
六、在Tomcat上部署项目 24
七、总结 25
致谢 26
参考文献 27
一、前言
在网络迅速发展的今天,面临非常丰富的网络资源,不论我们是学习、研究、还是工作需要在网络上能查找到相关的资料信息,人们现在对网络的依赖程度越来越高,但是如何有效的搜索信息却是一件困难的事情。但是幸运的是类似于百度、Google这样的搜索网站的出现能帮助我们解决这样的问题,使我们可以在网络中查找自己所需要的信息资源。从理论上讲所有的用户都可以从搜索出发到达自己想去的网上任何一个地方。并且我们在网络中可以找到几乎我们需要的一切的可能的东西,本文从搜索引擎发展历史开始,然后详细介绍了程序中使用的组件Lucene,重点阐述了全文搜索引擎的基本原理、所采用的相关技术,进而引出专题搜索引擎,并且为提高专题性所采取的一些方法。分析了网页文档半结构化的数据特点以及使用自己编写的spider程序从Internet上取回综合的信息经过Lucene处理加入索引文件中,最终用户在客户端输入关键字后实现将与关键字相关信息返回给用户。
二、搜索引擎的历史渊源
早在 Web出现之前,互联网上就已经存在许多让人们共享的信息资源了。那些资源当时主要存在于各种允许匿名访问的FTP 站点(anonymous ftp),内容以学术技术报告、研究性软件居多,它们以计算机文件的形式存在,文字材料的编码通常是PostScript 或者纯文本(那时还没有HTML)。在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了。为了便于人们在分散的FTP 资源中找到所需的东西,1990年由蒙特利尔大学学生Alan Emtage发明的Archie。虽然当时World Wide Web还未出现,但网络中文件传输还是相当频繁的,而且由于大量的文件散布在各个分散的FTP主机中,查询起来非常不便,因此Alan Emtage想到了开发一个可以以文件名查找文件的系统,于是便有了Archie。
Archie工作原理与现在的搜索引擎已经很接近,它依靠脚本程序自动搜索网上的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。受其启发, 1993 年Matthew Gray 开发了World Wide Web Wanderer,它是 世界上第一个利用HTML 网页之间的链接关系来监测Web 发展规模的“机器人”(robot )程序。现代搜索引擎的思路源于Wanderer,不少人在此基础上对它的蜘蛛程序做了改进。
当时,“机器人”一词在编程者中十分流行。电脑“机器人”(Computer Robot)是指某个能以人类无法达到的速度不间断地执行某项任务的软件程序。由于专门用于检索信息的“机器人”程序像蜘蛛一样在网络间爬来爬去,因此,搜索引擎的“机器人”程序就被称为“蜘蛛”程序。
1994 年7 月,Michael Mauldin 将John Leavitt 的蜘蛛程序接入到其索引程序中,创建了大家现在熟知的Lycos,成为第一个现代意义的搜索引擎。在那之后,随着Web上信息的爆炸性增长,搜索引擎的应用价值也越来越高,不断有更新、更强的搜索引擎系统推出。同年,斯坦福(Stanford)大学的两名博士生,共同创办了超级目录索引Yahoo,并成功地使搜索引擎的概念深入人心。从此搜索引擎进入了高速发展时期。
随着互联网规模的急剧膨胀,一家搜索引擎光靠自己单打独斗已无法适应目前的市场状况,因此现在搜索引擎之间开始出现了分工协作,并有了专业的搜索引擎技术和搜索数据库服务提供商。如国外的Inktomi,它本身并不是直接面向用户的搜索引擎,但向包括Overture(原GoTo)、LookSmart、MSN、HotBot等在内的其他搜索引擎提供全文网页搜索服务,因此从这个意义上说,它们是搜索引擎的搜索引擎。
三、搜索引擎基本结构
搜索引擎是根据用户的查询请求信息,按照一定算法从索引数据中查找符合用户需求的信息后将结果返回给用户。一般的搜索引擎由网络机器人程序、索引与搜索程序、索引数据库等部分组成。
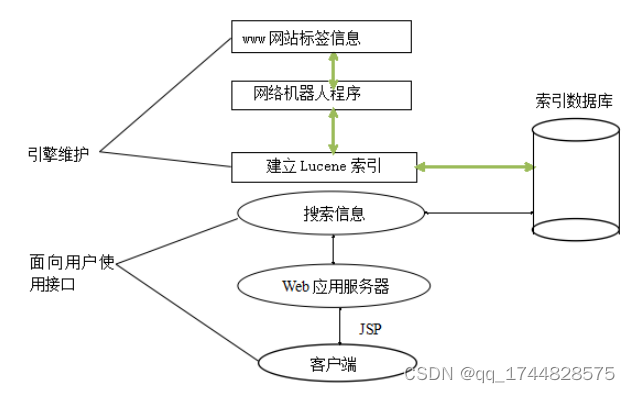
图3-1结构图
(一)网络机器人
网络机器人也称为“网络蜘蛛”(Spider),是一个功能很强的WEB扫描程序。它可以在扫描WEB页面的同时检索其内的超链接并加入扫描队列等待以后扫描。因为WEB中广泛使用HTML超链接,所以一个Spider程序理论上可以访问整个WEB页面。
为了保证网络机器人遍历信息的广度和深度需要设定一些重要的链接并制定相关的扫描策略。其设计思想就是将整个网络看做一颗树,通过递归不断的将符合条件的页面的连接拿到进行处理。
(二)索引与搜索
网络机器人将遍历得到的页面存放在临时数据库中,如果通过SQL直接查询信息速度将会难以忍受。为了提高检索效率,需要建立索引(我们学过的SqlServer2005中曾介绍字段添加索引能提高查询速度这个倍数是惊人的),用户输入搜索条件后搜索程序将通过索引数据库进行检索然后把符合查询要求的数据返回给用户。
(三)Web服务器
在Web程序开发中,使用的Wdb服务器有很多种类,其中比较常见的有,tomcat服务器、WebLogic服务器、还有JBoss服务器,其中tomcat是最比较普遍常用的一个,它以稳定的性能,和开源的优势得到了广大用户的承认,其实JBoss也是一个开源的但是它的结构比较复杂使用起来不是很灵活,而WebLogic则是一款收费的商业型的服务器,在我实现的开发中择用了简单使用的tomcat容器作为我web程序的服务器。客户一般通过浏览器进行查询,这就需要系统提供Web服务器并且与后台的搜索逻辑进行交互。客户在浏览器中输入查询条件,Web服务器接收到客户的查询条件后在索引数据库中进行查询处理然后返回给客户端。
(四)搜索引擎的主要指标及分析
搜索引擎的主要指标有响应时间、准确率、相关度等。这些指标决定了搜索引擎的技术指标。搜索引擎的技术指标决定了搜索引擎的评价指标。好的搜索引擎应该是具有较快的反应速度和准确率的,当然这些都需要搜索引擎技术指标来保障。
(1)准确率:一次搜索结果中符合用户要求的数目与该次搜索结果总数之比
(2)相关度:用户查询与搜索结果之间相似度的一种度量
(3)精确度:对搜索结果的排序分级能力和对垃圾网页的抗干扰能力
四、网络机器人
(一)什么是网络机器人
网络机器人又称为Spider程序,是一种专业的网页爬虫程序。它能查找大量的Web页面。从一个简单的Web入口页面上开始执行,然后通过其超链接一次递归访问其他页面,因此理论上网络机器人可以扫描互联网上的所有页面。但是实际中并非如此,因为这样将会耗去大量的时间和金钱,一次所有的企业基于商业盈利的角度都不会不停的使用网络机器人进行搜索WEB页面。一般来说这些企业都是定时的进行索引数据库的更新,据说Google是每隔28天进行一次索引数据库的更新并维护这些大型数据库。
(二)网络机器人的结构分析
Internet是建立在很多相关协议基础上的,而更复杂的协议又建立在系统层协议之上。Web就是建立在HTTP ( Hypertext Transfer Protocol ) 协议基础上,而HTTP又是建立在TCP/IP ( Transmission Control Protocol / Internet Protocol ) 协议之上,它同时也是一种Socket协议。所以网络机器人本质上是一种基于Socket的网络程序。
因为Web中的网页信息都是使用HTML标记语言,因此网络机器人在检索网页时首先就是对HTML标记进行解析。在处理解析之前,先来了解一下HTML中主要数据类型。我们在进行解析的时候不用关心所有的标签,只需要对其中几种重要的进行解析即可。以下是一些HTML基本的标签元素。
(1)脚本:一些嵌入HTML标签中的代码语言(例如:JavaScript、jsp页面中的Java代码等等)
(2)注释:程序员留下的说明文字,对用户是不可见的(即: )
(3)简单标签:由单个表示的HTML标签(例如:、 等等)
①超连接标签
超连接定义了WWW通过Internet链接文档的功能。他们的主要目的是使用户能够任意迁移到新的页面,这正是网络机器人最关心的标签。
②图像映射标签
图像映射是另一种非常重要的标签。它可以让用户通过点击图片来迁移到新的页面中。
③表单标签
表单是Web页面中可以输入数据的单元。许多站点让用户填写数据然后通过点击按钮来提交内容,这就是表单的典型应用。
④表格标签
表格是HTML的构成部分,通常用来格式化存放、显示数据。
我们在具体解析这些HTML标签有两种方法:通过JavaTM中的Swing类来解析或者通过组件包中的HTMLParser来解析,本人在实际编程中采用后者使用组件对html进行操作。HTMLParser是一个很优秀的开源组件,它有很强大的支持HTML解析的功能,下面我就来介绍一下HTMLParser中的核心组件类。
(1)org.htmlparser.Parser 定义了htmlparser的一些基础类。其中最为重要的是Parser类。Parser是htmlparser的最核心的类。
(2)org.htmlparser.beans对Visitor和Filter的方法进行了封装,定义了针对一些常用html元素操作的bean,简化对常用元素的提取操作。
(3)org.htmlparser.nodes定义了基础的node,包括:AbstractNode、RemarkNode、TagNode、TextNode等。
(4)org.htmlparser.tags定义了htmlparser的各种tag。
(5)org.htmlparser.filters定义了htmlparser所提供的各种filter,主要通过extractAllNodesThatMatch (NodeFilter filter)来对html页面指定类型的元素进行过滤。
(6)org.htmlparser.visitors定义了htmlparser所提供的各种visitor,主要通过visitAllNodesWith (NodeVisitor visitor)来对html页面元素进行遍历。
(三)Spider程序结构
网络机器人必须从一个网页迁移到另一个网页,所以必须找到该页面上的超连接。程序首先解析网页的HTML代码,查找该页面内的超连接然后通过递归和非递归两种结构来实现Spider程序。
(1)递归结构
递归是在一个方法中调用自己本身的程序设计技术。虽然比较容易实现但耗费内存且不能使用多线程技术,故不适合大型项目。
(2)非递归结构
这种方法使用队列的数据结构,当Spider程序发现超连接后并不调用自己本身而是把超链接加入到等待队列中。当Spider程序扫描完当前页面后会根据制定的策略访问队列中的下一个超链接地址。虽然这里只描述了一个队列,但在实际编程中用到了四个队列,他们每个队列都保存着同样处理状态的URL。
等待队列:在这个队列中,URL等待被Spider程序处理。新发现的URL也被加入到这个队列中
处理队列: 当Spider程序开始处理时,他们被送到这个队列中
错误队列: 如果在解析网页时出错,URL将被送到这里。该队列中的URL不能被移入其他队列中。
完成队列: 如果解析网页没有出错,URL将被送到这里。该队列中的URL不能被移入其它队列中,在同一时间URL只能在一个队列中,把它称为URL的状态。
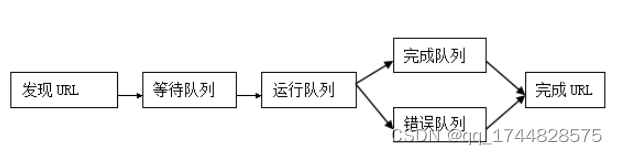
图4-1spider运行过程
以上的图表示了队列的变化过程,在这个过程中,当一个URL被加入到等待队列中时Spider程序就会开始运行。只要等待队列中有一个网页或Spider程序正在处理一个网页,程序就会继续他的工作。当等待队列为空并且当前没有任何网页时,Spider程序就会停止它的工作。
(四)如何提高程序性能
Internet中拥有大量的Web页面,如果开发出高效的Spider程序是非常重要的。通过查询资料我主要研究了使用Java的多线程技术提高性能的技术:
线程是通过程序的一条执行路线。多线程是一个程序同时运行多个任务的能力。它是在一个程序的内部进行分工合作。
优化程序的通常方法是确定瓶颈并改进他。瓶颈是一个程序中最慢的部分,他限制了其他任务的运行。例如:一个Spider程序需要下载十个页面,要完成这一任务,程序必须向服务器发出请求然后接受这些网页。当程序等待响应的时候其他任务不能执行,这就影响了程序的效率。如果用多线程技术可以让这些网页的等待时间合在一起,不用互相影响,这就可以极大的改进程序性能。
五、基于Tomcat的Web服务器jsp搜索引擎程序设计详解
(一)开发工具、平台及资源
1、 MyEclipse 6.0开发工具
2、Sun JDK 1.6.1
3、Tomcat 6.1服务器
4、开源Lucene组件
(二)Lucene开源组件简介
我在程序设计实现中,使用了lucene开源组件,并未使用数据库做为存放大量信息的索引数据库,最主要的原因就是考虑使用Lucene效率会大大的高于使用普通数据库的性能。因此首先简单介绍一下Lucene相关的技术。
1、什么是Lucene全文检索以及引入Lucene的原因
Lucene是Jakarta Apache的开源项目。它是一个用Java写的全文索引引擎工具包,可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。如果搜索引擎网络机器人检索到的网页信息放到数据库中的话,当用户在客户端检索数据的时候,如果数据库中存放着大量数据的话,没有好的数据库检索策略,数据查询速度大大减慢,而且其搜索引擎的性能也会因此而大打折扣,会导致用户长期的等待,结果超出用户的人手时间。考虑以上的原因,我在设计的时候选择了使用Lucene,将网络机器人,检索到的网页的基本信息交给Lucene处理,经过Lucene处理后将搜索到的网页信息建立相应的索引,并且存放到Lucene创建的索引文件中去,从而在用户检索相应的数据的时候,免去了从数据库中查询的步骤,直接从索引文件中获取所需的信息,这样程序对文件的IO操作要远远大于数据库的检索的效率。从而提高了程序的性能和用户的体验。
2、Lucene的基本介绍
(1)对于Lucene的感性认识
Lucene的API接口设计的比较通用,输入输出结构都很像数据库的表==>记录==>字段,所以很多传统的应用文件、数据库等都可以比较方便的映射到Lucene的存储结构和接口中。总体上看:可以先把Lucene当成一个支持全文索引的数据库系统,因此Lucene和数据库在很大程度上有一定的相似度,在Lucene中的索引数据源(即:doc(field1,field2…) doc(field1,field2…))很像数据库中的数据库表,而Lucene中的Document类即:(一个需要进行索引的“单元”,一个Document由多个字段组成)很类似与数据库中表中的一条记录(行),在Lucene中的Field类则是充当了索引文件中的Decument类的属性的集合字段,它的作用当然就是相当于数据库的列的属性,在我们使用Java也好或者是C#也罢查询数据库的时候,数据库返回的结果集就相当于Lucene结果输出,也就是Hits类对象了,即:(doc(field1,field2) doc(field1…))在Hits中查询结果集,匹配是由Document组成相当于数据库中查询出来的结果集。
(2)Lucene的索引效率
前面提到了,我使用Lucene主要的目的就是为了提高索引数据库中的数据查询速度,下面我们就来看看Lucene的基本的索引原理吧,通常书籍后面常常附关键词索引表(比如:北京:12, 34页,上海:3,77页……),感性的讲它就像我们常用的字典中的目录很相似,它能帮读者较快地找到相关内容的页码。而数据库索引能够大大提高查询的速度原理也是如此,通过书后面的索引查找的速度要比一页一页地翻内容高多少倍……而索引之所以效率高,另外一个原因是它是排好序的。对于检索系统来说核心是一个排序问题。
由于数据库索引不是为全文索引设计的,因此,使用like “%keyword%“时,数据库索引是不起作用的,在使用like查询时,搜索过程又变成类似于一页页翻书的遍历过程了,所以对于含有模糊查询的数据库服务来说,LIKE对性能的危害是极大的。我曾经在Oracle中做过一个实验,在数据库中使用索引和不使用索引的速度先比,前者是后者速度的将近上百倍,当然这个结果不是唯一的,对于数据量越大的数据库中我们使用索引的效率以及能给我们带来的方便时越为明显的,如果是需要对多个关键词进行模糊匹配:like”%keyword1%” and like “%keyword2%” …其效率也就可想而知了。所以建立一个高效检索系统的关键是建立一个类似于科技索引一样的反向索引机制,将数据源排序顺序存储的同时,有另外一个排好序的关键词列表,用于存储关键词==>文章映射关系,这样检索过程就是把模糊查询变成多个可以利用索引的精确查询的逻辑组合的过程。从而大大提高了多关键词查询的效率,所以,全文检索问题归结到最后是一个排序问题。在本文中我们主要是研究的搜索引擎的效率问题,其实在Lucene中还有很多个人认为很经典的技术,比如是分词技术,还有相关的信息匹配技术等等由于时间和文章篇幅的限制,我在此不多赘述。
(三)引入基于Tomcat的Web服务器开发设计
Web服务器是在网络中为实现信息发布、资料查询、数据处理等诸多应用搭建基本平台的服务器。Web服务器如何工作:在Web页面处理中大致可分为三个步骤,第一步,Web浏览器向一个特定的服务器发出Web页面请求;第二步,Web服务器接收到Web页面请求后,寻找所请求的Web页面,并将所请求的Web页面传送给Web浏览器;第三步,Web服务器接收到所请求的Web页面,并将它显示出来。这就是一个典型的HTTP请求过程。
Tomcat是一个开放源代码、运行servlet和JSP Web应用软件的基于Java的Web应用软件容器。Tomcat由Apache-Jakarta子项目支持并由来自开放性源代码Java社区的志愿者进行维护。Tomcat Server是根据servlet和JSP规范进行执行的,因此我们就可以说Tomcat Server也实行了Apache-Jakarta规范且比绝大多数商业应用软件服务器要好。
(四)用户接口设计
1、客户端设计
一个良好的查询界面非常重要,例如Google就以他简洁的查询界面而闻名。我在设计的时候也充分考虑了实用性和简洁性。
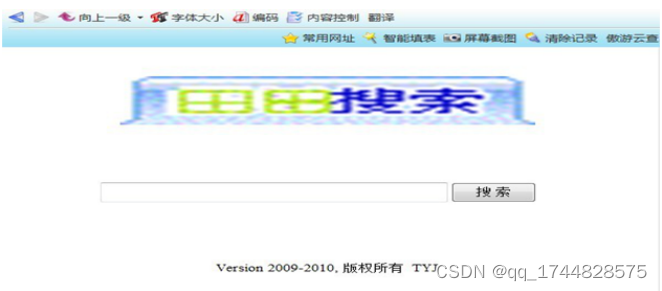
图5-1查询界面
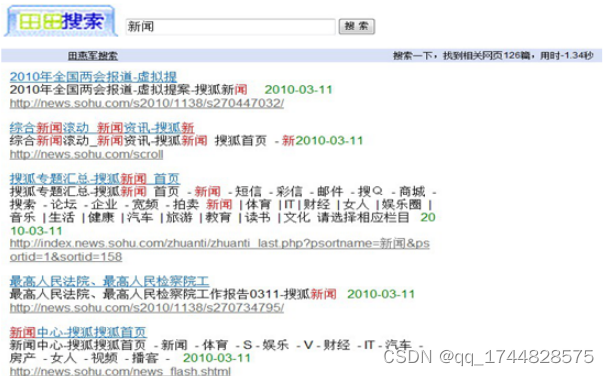
图5-2查询结果
2、服务端设计
主要利用jsp技术实现,用户通过GET方法从客户端向服务端提交查询条件,服务端通过Tomcat的jsp接受并分析提交参数,再调用lucene的开发包进行搜索操作。最后把搜索的结果以HTTP消息包的形式发送至客户端,从而完成一次搜索操作。
实现的关键代码如下:
int thispage = (request.getParameter(“thispage”) == null) ?
Integer.parseInt(request.getParameter(“thispage”));//当前页码
long starttime = System.currentTimeMillis();
//拿到用户请求的查询内容
String queryString = request.getParameter(“query”);
if ((queryString == null) || queryString.equals(“”)) {
queryString = “dd”;
response.sendRedirect(“./index.jsp”);}
//以下代码是使用Lucene索引文件进行搜索符合条件的内容
IndexFiles indexFiles = new IndexFiles();
String path = request.getRealPath(“/”) + “index”;
//建立符合条件的搜索结果集合存放准备将其返回给用户
Hits hits = indexFiles.searchIndexContent(path, queryString);
System.out.println(“一共查到” + hits.length() + “记录”);
long endtime = System.currentTimeMillis();
//将搜用户索条件进行分词处理
ChineseAnalyzer abc = new ChineseAnalyzer();
TokenStream tokenStream = null;
QueryParser parser = new QueryParser(“title”,
new StandardAnalyzer());
Query query = parser.parse(queryString);
//将拿到的内容进行高亮关键字处理
Highlighter highlighter = new Highlighter
(new SimpleHTMLFormatter(“”, “”), newQueryScorer(query));highlighter.setTextFragmenter(new SimpleFragmenter(99));/
(五)机器人的设计分析
1、程序结构图如下:
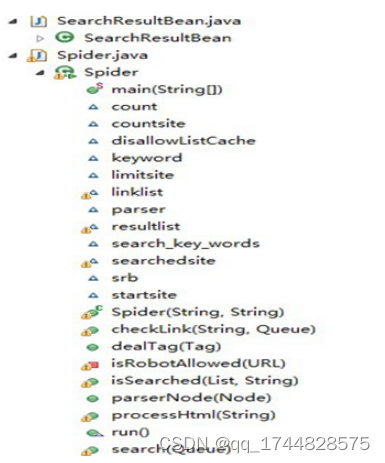
图5-3 spider程序结构
2、程序关键代码实现如下:
(1)网络机器人搜索网页核心代码
public void search(Queue queue) {
while (!queue.isEmpty()) { // 只要是队列不为空则网络机器人工作
url = queue.peek().toString();// 查找列队
if (!isSearched(searchedsite, url)) { // 查看当前连接是否被扫描过
if (isRobotAllowed(new URL(url))) // 检查该链接是否被允许搜索
processHtml(url); // 分析当前地址的页面
System.out.println(“此页面禁止爬虫获取资源!”);
queue.remove(); // 搜索操作完成之后进行出对操作。
* 检查该链接是否已经被扫描
*已经处理完成的URL列表
*当前处理的URL字符串
public boolean isSearched(List list, String url) {
String url_end_ = “”;
if (url.endsWith(“/”)) { // 测试此字符串是否以"/“后缀结束
// 返回指定子字符串(”/“)在此字符串中最右边出现处的索引
// (拿到连接地址最右边的”/“索引) 例如 http://www.google.cn/
// 能拿到最右边的即最后一个”/“的索引位置,
// 最终的目的是要拿到”/“之前的连接地址
url_end_ = url.substring(0, url.lastIndexOf(”/“));
} else {
url_end_ = url + “/”;}
if (list.size() > 0) {
// indexOf(Object o)
// 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1
// 我们在此不使用循环进行选重原因就是因为使用index of方法效率要高些,
// 因为Java已经将它的算法封装在里面并且进行了优化
if (list.indexOf(url) != -1 || list.indexOf(url_end_) != -1) {
return true; // 如果在list中没有找到当前要处理的url则表示可以处理
return false; // 否则此链接地址已经处理过在此不做任何处理
}
* 检查URL是否被允许搜索
private boolean isRobotAllowed(URL urlToCheck) {
String host = urlToCheck.getHost().toLowerCase();
// 获取给出RUL的主机并且使用给定 Locale 的规则将此 String 中的所有字符都转换为小写
// System.out.println(“主机=”+host);
// 获取主机不允许搜索的URL缓存
ArrayList disallowList = disallowListCache.get(host);
// 如果还没有缓存,下载并缓存。
if (disallowList == null) {
disallowList = new ArrayList();
URL robotsFileUrl = new URL(“http://” + host + “/robots.txt”);
BufferedReader reader = new BufferedReader(
new InputStreamReader(robotsFileUrl.openStream()));
// 读robot文件,创建不允许访问的路径列表。
while ((line = reader.readLine()) != null) {
if (line.indexOf(“Disallow:”) == 0) {
// 是否包含"Disallow:”
String disallowPath = line.substring(“Disallow:”.length()); // 获取不允许访问路径检查是否有注释。
int commentIndex = disallowPath.indexOf(“#”);
if (commentIndex != -1) {disallowPath = disallowPath.substring(0,
commentIndex);// 去掉注释}disallowPath = disallowPath.trim();
disallowList.add(disallowPath); }
// 在此确队列中的元素不是为空的
for (Iterator it = disallowList.iterator(); it.hasNext()😉 {
System.out.println(“Disallow is :” + it.next());
}// 缓存此主机不允许访问的路径。// 将此主机名相对应的禁止访问的路径放到定义的map中disallowListCache.put(host, disallowList);
说明:
①以上是网络机器人的核心算法代码,运用的是半自动递归思想,搜索引擎系统维护人员将定时的执行网络机器人代码,来更新索引数据库中的内容确保用户能拿到自己所需要的最符合用户的,最新的消息。
②值得说明的一点是,在我做这个程序的时候遇见的一个难题吧,在确定URL的时候怎么能知道我们访问的网站是否允许我们的搜索引擎访问本网站的内容呢, 这样roboots.txt就起到了关键的作用,在此我们介绍一下roboots文件.
搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。我们可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。
robots.txt文件应该放在网站根目录下。举例来说,当robots访问一个网站(比如http://www.abc.com)时,首先会检查该网站中是否存在http://www.abc.com/robots.txt这个文件,如果机器人找到这个文件,它会根据这个文件的内容,来确定它访问权限的范围。
网站URL相应的 robots.txt的URL http://www.w3.org/robots.txt,在robots.txt中 Disallow : 该项的值用于描述不希望被访问到的一个URL,这个URL可以是一条完整的路径,也可以是部分的,任何以Disallow开头的URL均不会被robot访问到。
例如"Disallow: /help"对/help.html和/help/index.html都不允许搜索引擎访问,而"Disallow: /help/“则允许robot访问/help.html,而不能访问/help/index.html。任何一条Disallow记录为空,说明该网站的所有部分都允许被访问, 在”/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"是一个空文件,则对于所有的搜索引擎robot, 该网站都是开放的。
(2)网络机器人解析网页HTML核心代码
处理HTML标签
public void dealTag(Tag tag) throws Exception {
NodeList list = tag.getChildren();
if (list != null) {
NodeIterator it = list.elements();
while (it.hasMoreNodes()) {
Node node = it.nextNode();
parserNode(node);
处理HTML标签结点
public void parserNode(Node node) throws Exception {
// instanceof 用于判断所拿到的节点类型是不是标准定义好的节点类型hen
if (node instanceof StringNode) { // 判断是否是文本结点
StringNode sNode = (StringNode) node;
StringFilter sf = new StringFilter(keyword, false);
search_key_words = sf.accept(sNode);
if (search_key_words) {
count++;
}
// System.out.println(“text is :”+sNode.getText().trim());
} else if (node instanceof Tag) {// 判断是否是标签库结点
Tag atag = (Tag) node;
if (atag instanceof TitleTag) {// 判断是否是标TITLE结点
srb.setTitle(atag.getText());
}
if (atag instanceof LinkTag) {// 判断是否是标LINK结点
LinkTag linkatag = (LinkTag) atag;
checkLink(linkatag.getLink(), linklist);
/ System.out.println("-----------------this is link
dealTag(atag);
} else if (node instanceof RemarkNode) {
// 判断是否是注释
}
(3)网络机器人与Lucene结合核心代码
if (!iswrite) {//切入蜘蛛程序
System.out.println(“开始为页面建立索引” + url + “…
”);
IndexFiles.updateURL(path, url);
说明:本代码是将网络机器人拿到符合条件的标签加到Lucene索引文件中,即搜索引擎的索引数据库。
(六)关于程序说明
(1)本人在网络机器人运用了Java语言开发,主要涉及到了net和io两个包。
(2)还有Java线程技术,由于时间比较紧迫,本程序只用的了Java中的单线程技术,具体的程序优化后期应该能涉及到Java中的线程池技术。
(3)此外还用了第三方开发包htmlparser组件用于解析HTML网页标签。
本程序使用的算法是介于递归和非递归的半自动递归算法,使用递归算法的时候,如果有意外可能会导致内存溢出,对于本文的程序如果使用非递归算法的话有点复杂,会使得程序的性能无法达到最佳的状态,因为我对非递归的算法进行了改造,自己将它命名为半自动的非递归算法,是本程序性能达到比较好的状态。
六、在Tomcat上部署项目
Tomcat中的应用程序是一个WAR(Web Archive)文件。WAR是Sun提出的一种Web应用程序格式,与JAR类似,也是许多文件的一个压缩包。这个包中的文件按一定目录结构来组织:通常其根目录下包含有Html和Jsp文件或者包含这两种文件的目录,另外还会有一个WEB-INF目录,这个目录很重要。通常在WEB-INF目录下有一个web.xml文件和一个classes目录,web.xml是这个应用的配置文件,它是JavaWeb应用程序的入口点,而classes目录下则包含编译好的Servlet类和Jsp或Servlet所依赖的其它类(如JavaBean)。通常这些所依赖的类也可以打包成JAR放到WEB-INF下的lib目录下,当然也可以放到系统的CLASSPATH中。
在Tomcat中,应用程序的部署很简单,你只需将你的WAR放到Tomcat的webapp目录下,Tomcat会自动检测到这个文件,并将其解压。你在浏览器中访问这个应用的Jsp时,通常第一次会很慢,因为Tomcat要将Jsp转化为Servlet文件,然后编译。编译以后,访问将会很快。
七、总结
全文搜索引擎已经成为人们在信息化时代中检索信息不可缺少的工具。本设计将lucene这一开源的搜索引擎框架,结合Java Web开发流行的SSH、Ajax等技术,实现一个可以在小型局域网或海量文件存储的主机上进行数据检索的引擎。并且通过Spring可以实现灵活的配置。为无法使用互连网搜索引擎下的海量数据检索,提供了一个很好的解决方案。
致谢
当我写完这篇毕业论文的时候,心情十分激动,感慨很多。从开始进入课题到资料的搜集再到论文的顺利完成,整个过程都离不开指导老师、朋友们的热情帮助,在这里请接受我诚挚的谢意!
首先,我要感谢我的论文指导老师老师。这篇论文的每一步都是在齐老师的悉心指导下完成的。老师为人随和热情,正是有了齐老师的无私帮助与热忱鼓励,我的毕业论文才能够得以顺利完成,这里,我要诚挚的向老师说一声:“谢谢您,齐老师。”
此外,我要感谢身边的朋友们。在这次论文写作过程中,他们对我总是有求必应,帮助我搜集和提供了大量有价值的文献资料,帮助我理清了论文的写作思路,对我的论文提出了诸多宝贵的意见和建议。借此机会,我要对各位朋友们的帮助表示真挚的感谢,谢谢你们!
参考文献
[1]似杰.盘古搜索购物资讯引擎的设计与实现[D].北京工业大学,2013.
[2]李雪利.基于Solr的企业搜索引擎的研究与实现[D].浙江理工大学,2013.
[3]范晨熙.基于Hadoop的搜索引擎的研究与应用[D].浙江理工大学,2013.
[4]张菊琴.基于模糊聚类算法及推荐技术的搜索引擎结果排序[D].江西理工大学,2013.
[5]裴一蕾,薛万欣,赵宗,陶秋燕.基于用户体验视角的搜索引擎评价研究[J].情报科学,2013,05:94-97+112.
[6]雷鸣,刘建国,王建勇,陈葆珏.一种基于词典的搜索引擎系统动态更新模型[J].计算机研究与发展,2000,10:1265-1270.
[7]朱亮,顾俊峰,马范援.基于MobileAgent的搜索引擎关键技术研究[J].计算机工程,2000,08:126-129.
[8]项珍.基于语义的搜索引擎探讨[J].浙江高校图书情报工作,2008,06:15-20.
[9]张杰.基于Web数据挖掘的搜索引擎研究[J].信息与电脑(理论版),2013,11:95-96.
[10]李豫山.基于聚焦搜索引擎的搜索引擎优化策略的研究[J].科技信息,2014,12:10-11.
[11]伍大勇.搜索引擎中命名实体查询处理相关技术研究[D].哈尔滨工业大学,2012.
[12]宋巍.基于主题的查询意图识别研究[D].哈尔滨工业大学,2013.
相关文章:
基于jsp的搜索引擎
摘 要 随着互联网的不断发展和日益普及,网上的信息量在迅速地增长,在2004年4月,全球Web页面的数目已经超过40亿,中国的网页数估计也超过了3亿。 目前人们从网上获得信息的主要工具是浏览器,搜索引擎在网络中占有举足轻…...
【Altium designer 20】
Altium designer 20 1. Altium designer 201.1 原理图库1.1.1 上划岗 在字母前面加\在加字母1.1.2 自定义快捷键1.1.3 对齐1.1.4 在原有的电路图中使用封装1.1.5 利用excel创建IC类元件库1.1.6 现有原理图库分类以及调用1.1.7 现有原理图库中自动生成原理图库 1.2 绘制原理图1.…...
Proteus仿真--基于1602LCD与DS18B20设计的温度报警器
本文介绍基于1602LCD与DS18B20设计的温度报警器设计(完整仿真源文件及代码见文末链接) 仿真图如下 其中温度传感器选用DS18B20器件,主要用于获取温度数据并上传,温度显示1602LCD液晶显示器,报警模块选用蜂鸣器&#…...
Clickhouse Join
ClickHouse中的Hash Join, Parallel Hash Join, Grace Hash Join https://www.cnblogs.com/abclife/p/17579883.html https://clickhouse.com/blog/clickhouse-fully-supports-joins-full-sort-partial-merge-part3 总结 本文描述并比较了ClickHouse中基于内存哈希表的3种连接…...
)
Arduino驱动STS35数字温度传感器(温湿度传感器)
目录 1、传感器特性 2、硬件原理图 3、控制器和传感器连线图 4、驱动程序 STS35瑞士Sensirion公司新推出的温度传感器,STS35提供了一个完全校准、线性和供电电压补偿的数字输出&...

一起学docker系列之十八Docker可视化工具 Portainer:简介与安装
目录 前言1 简介2 安装过程2.1 创建docker容器数据卷2.2 构建运行protainer容器 3 Portainer 软件详细说明与界面导览3.1 查看本地Docker情况3.2 操作功能3.3 创建容器3.4 部署容器 4 Portainer的优势结语参考地址 前言 Docker作为容器化解决方案的热门工具,其可视…...
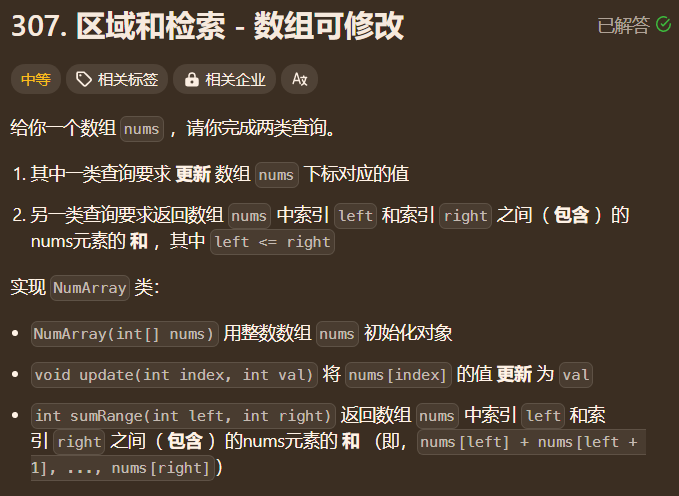
【数据结构】线段树
目录 1.概述2.代码实现2.1.聚合操作——求和2.2.聚合操作——求和、求最小值、求最大值 3.应用4.与前缀和之间的区别 更多数据结构与算法的相关知识可以查看数据结构与算法这一专栏。 1.概述 (1)线段树 (Segment Tree) 是一种二叉树形数据结构ÿ…...

王道数据结构课后代码题p175 06.已知一棵树的层次序列及每个结点的度,编写算法构造此树的孩子-兄弟链表。(c语言代码实现)
/* 此树为 A B C D E F G 孩子-兄弟链表为 A B E C F G D */ 本题代码如下 void createtree(tree* t, char a[], int degree[], int n) {// 为B数组分配内存tree* B (tree*)malloc(sizeof(tree) * n);int i 0;i…...
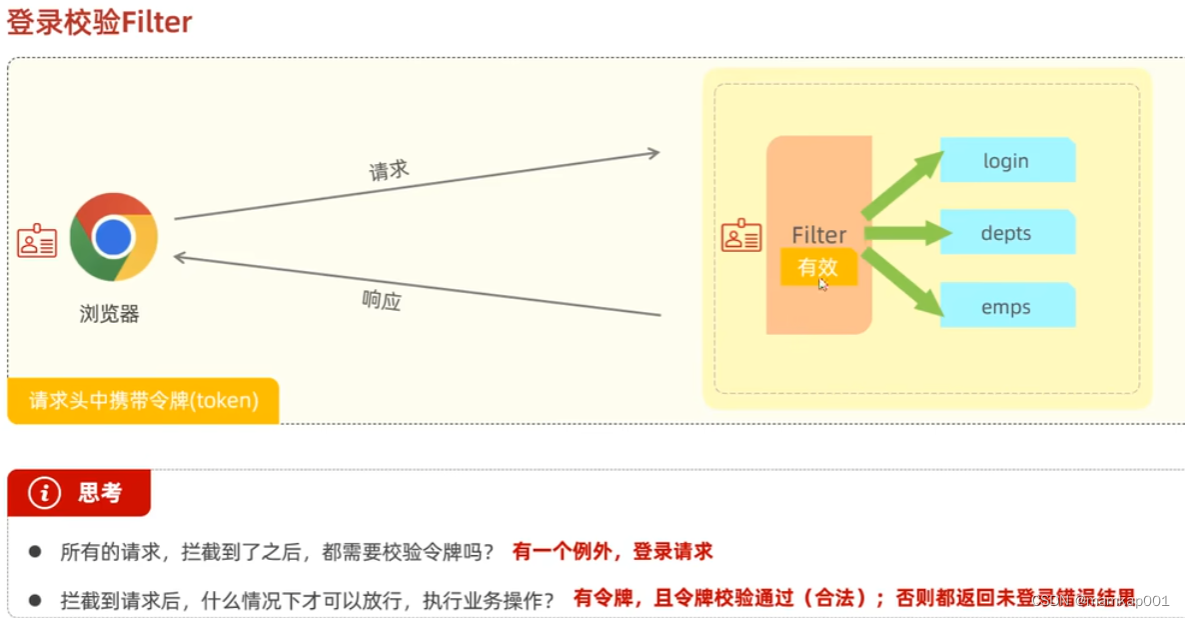
filter过滤器
package com.it.filter;import javax.servlet.*; import javax.servlet.annotation.WebFilter;import java.io.IOException;WebFilter(urlPatterns"/*") public class DemoFilter implements Filter {Override // 初始化的方法 只要调用一次public void init(Filte…...
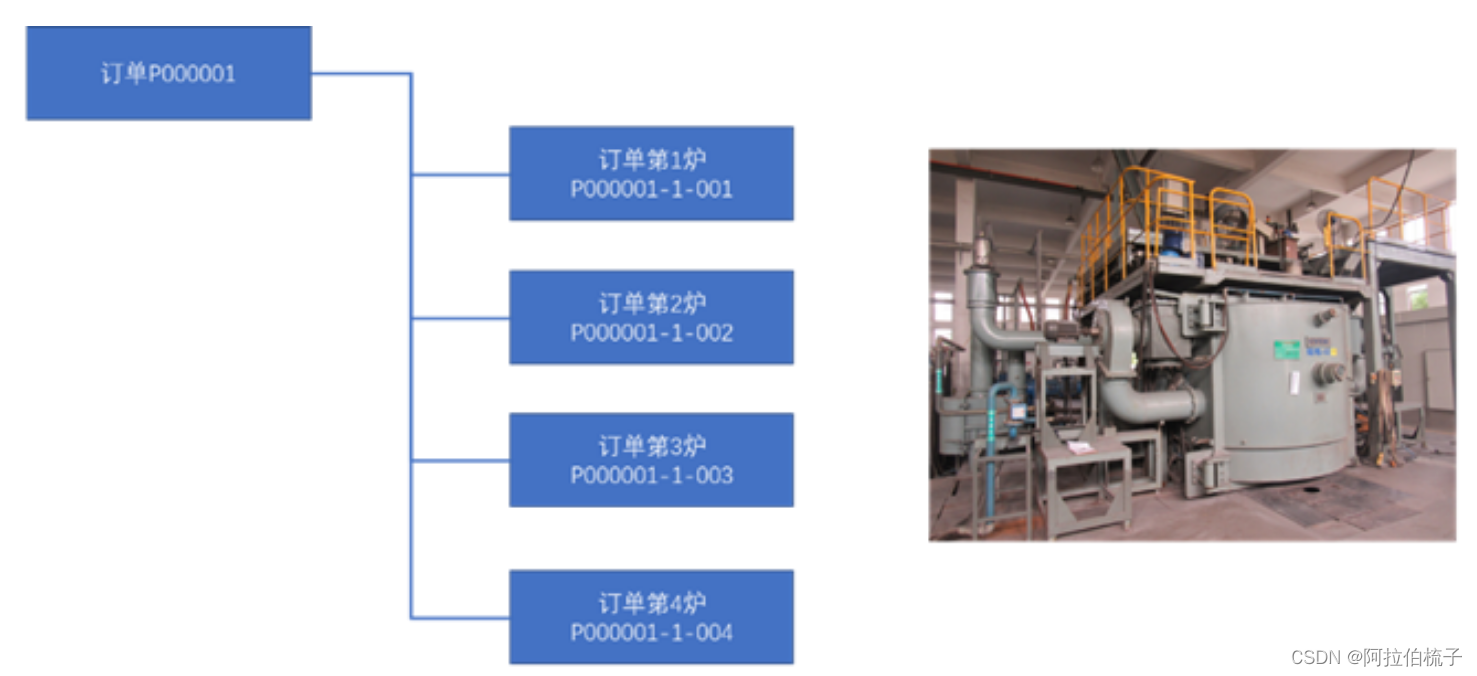
MES物料的动态批次管理漫谈
在制造企业中,原辅材料占产品制造总成本基本在60%以上,特殊材料加工企业可能达到80%以上,按“2/8管理原则”管理好物料就基本做好制造企业的成本管理,这也许是很多企业向“数字化转型”的一个主要原因,希望借助数字信息…...
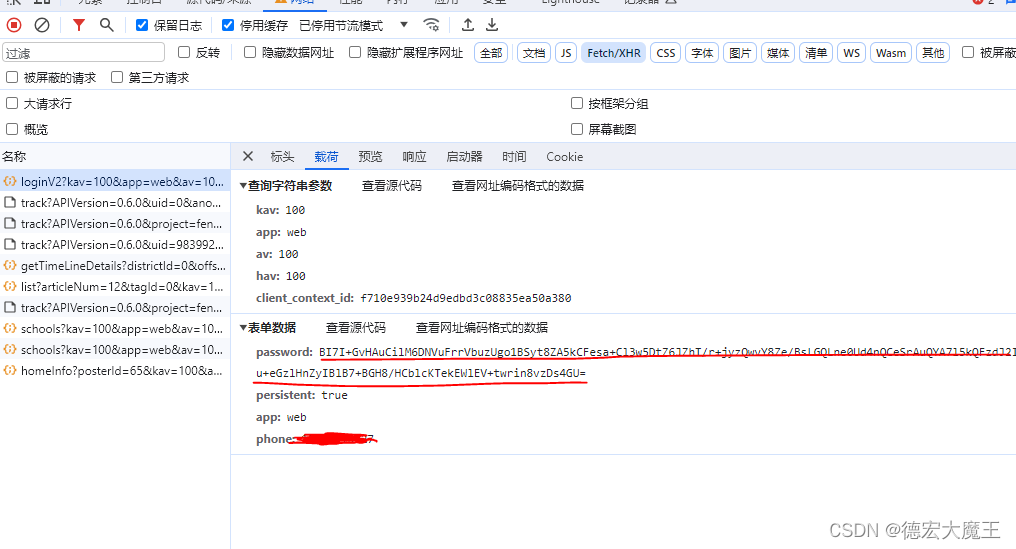
【爬虫逆向分析实战】某笔登录算法分析——本地替换分析法
前言 作者最近在做一个收集粉币的项目,可以用来干嘛这里就不展开了😁,需要进行登录换算token从而达到监控收集的作用,手机抓包发现他是通过APP进行计算之后再请求接口的,通过官网分析可能要比APP逆向方便多࿰…...

vue3使用动态component
使用场景: 多个组件通过component标签挂载在同一个组件中,通过触发时间进行动态切换。vue3与vue2用法不一样,这里有坑! 使用方法: 1.通过vue的defineAsyncComponent实现挂载组件 2.component中的is属性 父组件&am…...

单机游戏推荐:巨击大乱斗 GIGABASH 中文安装版
在泰坦之中称霸天下吧!《GigaBash 巨击大乱斗》是一款多人战斗擂台游戏,有着受特摄片启发的巨型怪兽,具有传奇色彩的英雄,震天动地的特别攻击,以及可以完全摧毁的擂台场景。 游戏特点 怪物大解放 多达10个独特的角…...

计算机系统启动过程
计算机系统启动过程 阅读笔记: 《计算机体系结构基础(第三版)》-- 胡伟武 第7章:计算机系统启动过程分析 系统启动的整个过程中, 计算机系统在软件的控制下由无序到有序, 所有的组成部分都由程序管理, 按照程序的执行发挥各自的功…...

DedeCms后台文章列表文档id吗?或者快速定位id编辑文章
我们在建站时有的时候发现之前的文章有错误了,要进行修改,但又不知道文章名,只知道大概的文章id,那么可以搜索到DedeCms后台文章列表文档id吗?或者快速定位文章id方便修改? 第一种方法:复制下面…...
【开发问题解决方法记录】03.dian
登录提示 ERR-1002 在应用程序 "304" 中未找到项 "ROLE_ID" 的项 ID。 一开始找错方向了,以为是代码错误,但是后来在蒋老师的提醒下在共享组件-应用程序项 中发现设的项不是ROLE_ID而是ROLEID,怪不得找不到ORZ 解决方法…...

QT之QString
QT之QString 添加容器 点击栅格布局 添加容器,进行栅格布局 布局总结:每一个模块放在一个Group中,排放完之后,进行栅格布局。多个Group进行并排时,先将各个模块进行栅格布局,然后都选中进行垂直布…...

常见的几种计算机编码格式
前言: 计算机编码是指将字符、数字和符号等信息转换为计算机可识别的二进制数的过程,正因如此,计算机才能识别中英文等各类字符。计算机中有多种编码格式用于表示和存储文本、字符和数据,实际走到最后都是二进制,本质一…...

3D旋转tab图
上图 代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>3D旋转tab图</title><style>* {margin: 0;padding: 0;}body {height: 100vh;background: linear-gradient(to top, #29323c, #…...

openGL 三:矩阵和向量
1.使用glm数学库进行矩阵和向量的计算 2.位置坐标可以看做一个向量 3.向量的移动,缩放,旋转,都是可以通过和矩阵的计算得出 4.向量的缩放乘一个44的矩阵 5.注意事项(有些版本的glm::mat4 不是默认构建一个单位44的矩阵)…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...