HBase整合Phoenix
文章目录
- 一、简介
- 1、Phoenix定义
- 2、Phoenix架构
- 二、安装Phoenix
- 1、安装
- 三、Phoenix操作
- 1、Phoenix 数据映射
- 2、Phoenix Shell操作
- 3、Phoenix JDBC操作
- 3.1 胖客户端
- 3.2 瘦客户端
- 四、Phoenix二级索引
- 1、为什么需要二级索引
- 2、全局索引(global index)
- 3、包含索引(covered index)
- 4、本地索引(local index)
一、简介
1、Phoenix定义
1)官网地址:http://phoenix.apache.org/
Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。
优点:使用简单,直接能写sql。
缺点:效率没有自己设计rowKey再使用API高,性能较差。
2、Phoenix架构
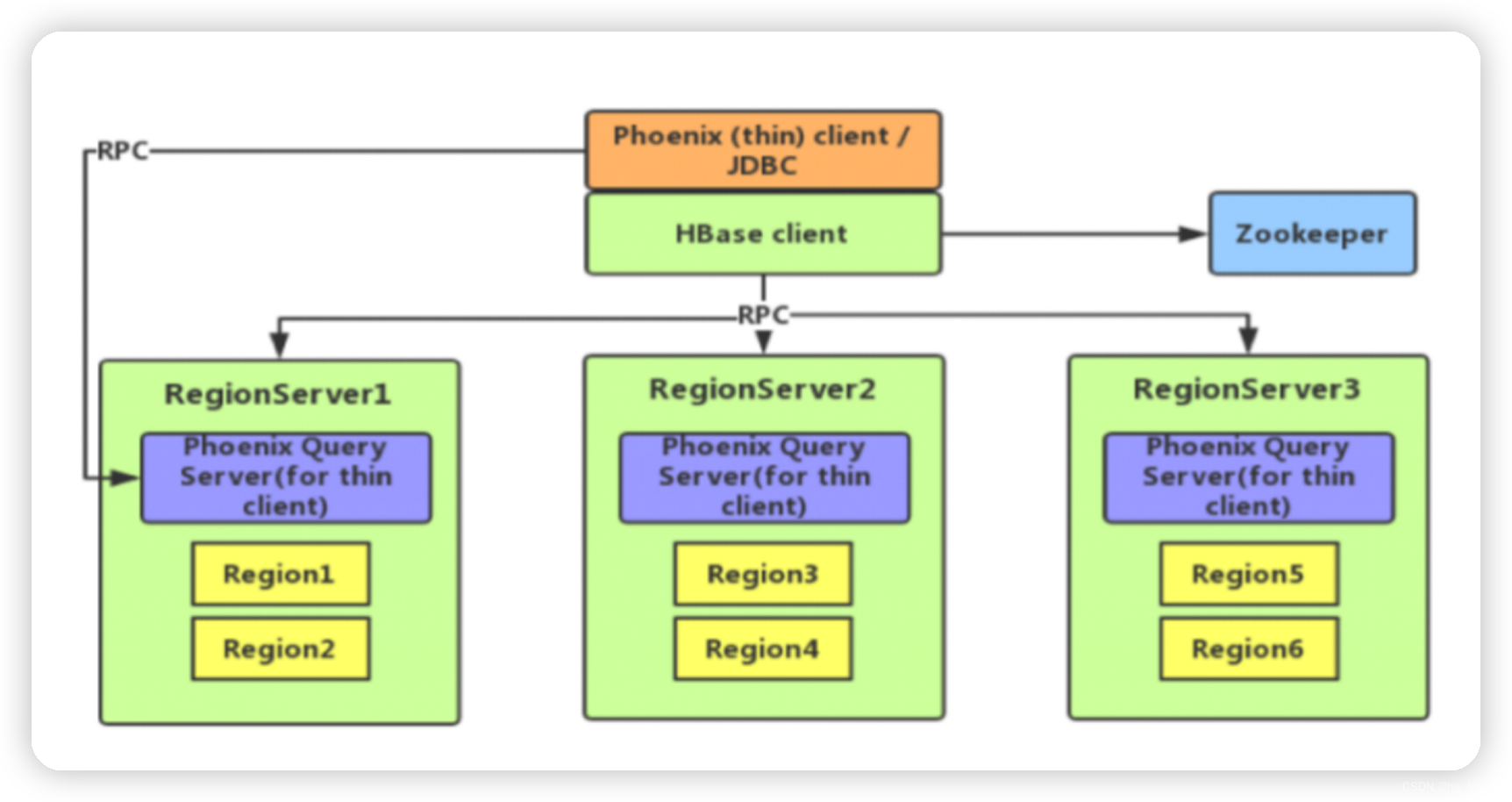
二、安装Phoenix
1、安装
将安装包上传到服务器目录
解压安装包
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/
mv /opt/module/apache-phoenix-5.0.0-HBase-2.0-bin /opt/module/phoenix
复制server包并拷贝到各个节点Hadoop101、Hadoop102、Hadoop103的hbase/lib
cp /opt/module/phoenix/phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
xsync /opt/module/hbase/lib/phoenix-5.0.0-HBase-2.0-server.jar
配置环境变量
vim /etc/profile.d/my_env.sh
添加内容
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
在hbase-site.xml中添加支持二级索引的参数(如果不需要创建二级索引,不用不加)。之后分发到所有regionserver的节点上。
vim /opt/module/hbase/conf/hbase-site.xml
xsync /opt/module/hbase/conf/hbase-site.xml
配置内容
<property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property><property><name>hbase.region.server.rpc.scheduler.factory.class</name><value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property><property><name>hbase.rpc.controllerfactory.class</name><value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
重启HBase
stop-hbase.sh
start-hbase.sh
连接 phoenix
/opt/module/phoenix/bin/sqlline.py hadoop101,hadoop102,hadoop103:2181
三、Phoenix操作
1、Phoenix 数据映射
Phoenix 将 HBase 的数据模型映射到关系型模型中。
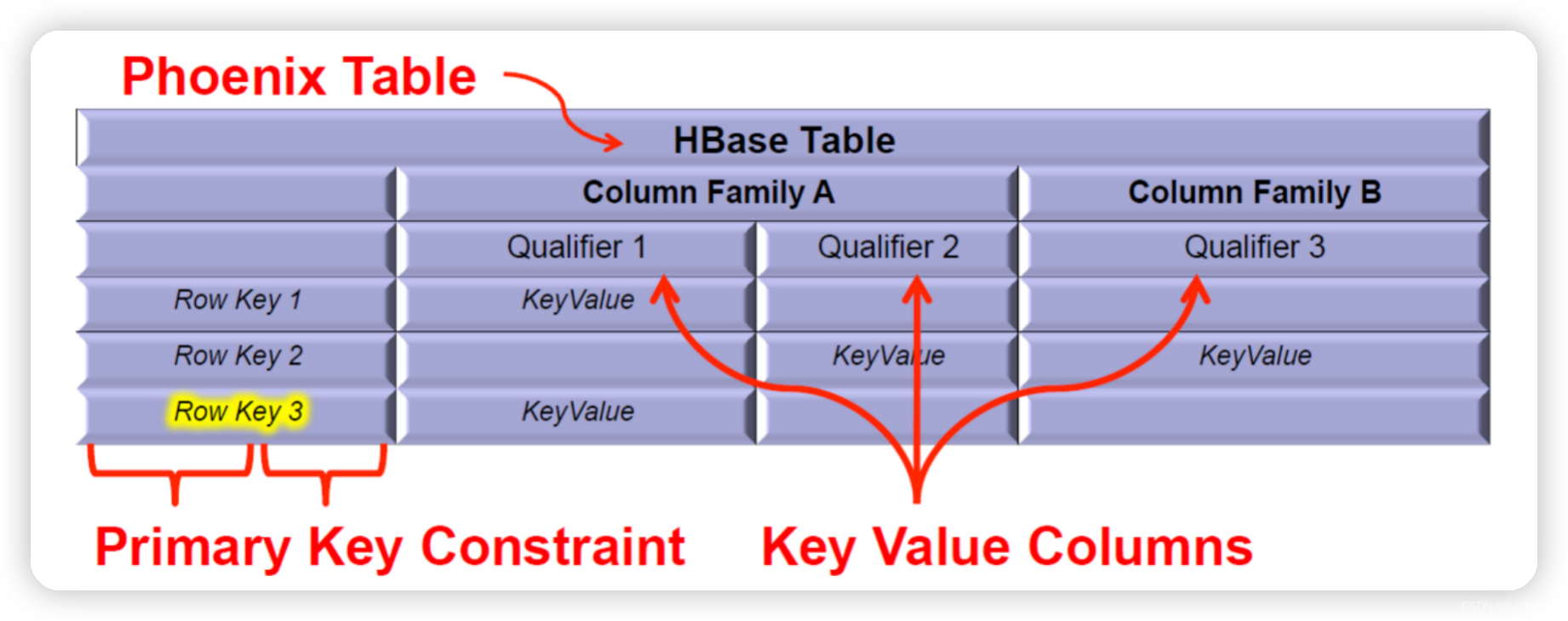
Phoenix中的主键会作为rowkey,非主键列作为普通字段。默认使用0作为列族,也可以在建表时使用 列族.列名 作为字段名,显式指定列族。
如果主键是联合主键,则会将主键字段拼接作为rowkey。
2、Phoenix Shell操作
- 登录Phoenix
/opt/module/phoenix/bin/sqlline.py hadoop101,hadoop102,hadoop103:2181
- 创建表
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR);
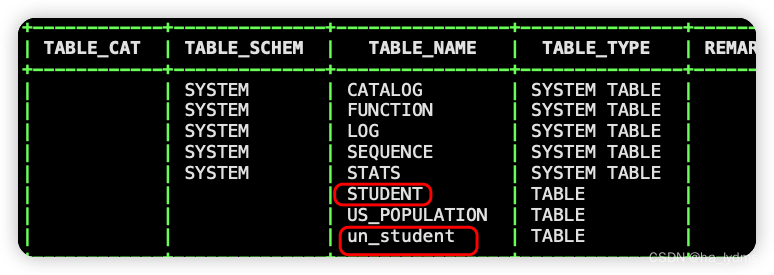
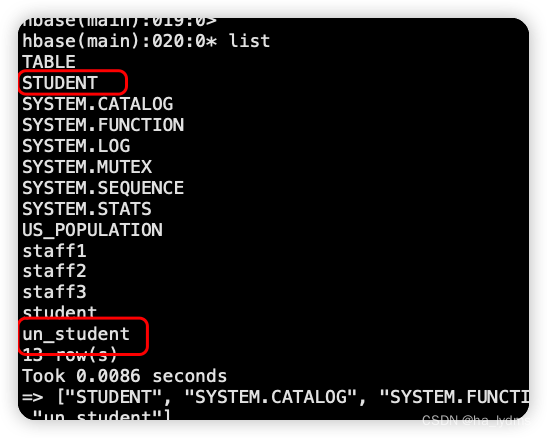
在phoenix中,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
CREATE TABLE IF NOT EXISTS "un_student"(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR);
# 指定多个列的联合作为RowKey
CREATE TABLE IF NOT EXISTS us_population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
注意:Phoenix中建表,会在HBase中创建一张对应的表。为了减少数据对磁盘空间的占用,Phoenix默认会对HBase中的列名做编码处理。具体规则可参考官网链接:https://phoenix.apache.org/columnencoding.html,若不想对列名编码,可在建表语句末尾加上COLUMN_ENCODED_BYTES = 0;
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR)
COLUMN_ENCODED_BYTES = 0
;
- 插入或更新数据
upsert执行时,判断如果主键存在就更新,不存在则执行插入。
- 插入或更新数据
upsert执行时,判断如果主键存在就更新,不存在则执行插入。
upsert into student values('1001','zhangsan','beijing');
- 查询记录
select * from student;
select * from student where id='1001';
- 删除记录
delete from student where id='1001';
- 删除表
drop table student;
- 退出命令行
!quit
3、Phoenix JDBC操作
3.1 胖客户端
- 胖客户端指将Phoenix的所有功能都集成在客户端,导致客户端代码打包后体积过大。
pom依赖
<!-- 胖客户端-->
<dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-core</artifactId><version>5.0.0-HBase-2.0</version><exclusions><exclusion><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version>
</dependency>
测试代码:
import java.sql.*;public class TestThickClient {public static void main(String[] args) throws SQLException {// 1.添加链接String url = "jdbc:phoenix:hadoop101,hadoop102,hadoop103:2181";// 2.获取连接Connection connection = DriverManager.getConnection(url);// 3.编译SQL语句PreparedStatement preparedStatement = connection.prepareStatement("select * from student");// 4.执行语句ResultSet resultSet = preparedStatement.executeQuery();System.out.println("===");// 5.输出结果while (resultSet.next()) {System.out.println(resultSet.getString(1) + ":" + resultSet.getString(2) + ":" + resultSet.getString(3));}// 6.关闭资源connection.close();}
}

3.2 瘦客户端
- 瘦客户端指将Phoenix的功能进行拆解,主要功能由服务端提供,只使用轻量级的客户端向服务端发送请求。
服务上启动hadoop101
queryserver.py start
pom文件
<!-- 瘦客户端-->
<dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-queryserver-client</artifactId><version>5.0.0-HBase-2.0</version>
</dependency>
<dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.21.4</version>
</dependency>
测试代码
import org.apache.phoenix.queryserver.client.ThinClientUtil;
import java.sql.*;public class TestThinClient {public static void main(String[] args) throws SQLException {// 1. 直接从瘦客户端获取链接String hadoop102 = ThinClientUtil.getConnectionUrl("hadoop101", 8765);System.out.println(hadoop102);// 2. 获取连接Connection connection = DriverManager.getConnection(hadoop102);// 3.编译SQL语句PreparedStatement preparedStatement = connection.prepareStatement("select * from student");// 4.执行语句ResultSet resultSet = preparedStatement.executeQuery();// 5.输出结果while (resultSet.next()) {System.out.println(resultSet.getString(1) + ":" + resultSet.getString(2) + ":" + resultSet.getString(3));}// 6.关闭资源connection.close();}
}
四、Phoenix二级索引
1、为什么需要二级索引
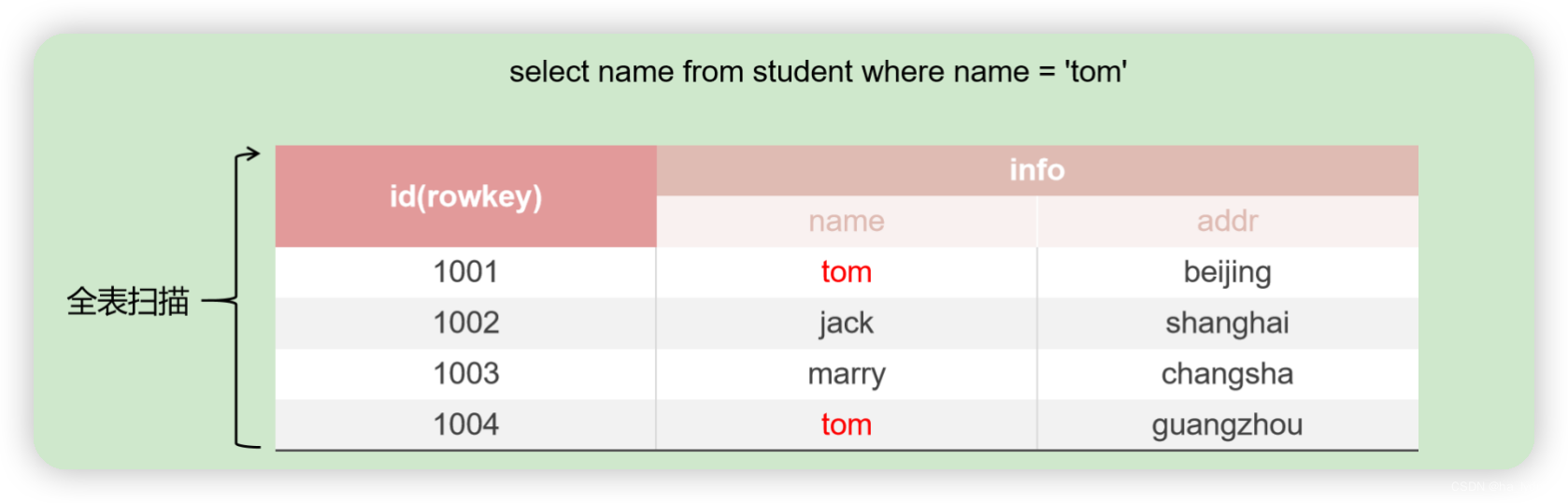
- 在HBase中查询时,必须指定rowkey。但是在Phoenix中,可以通过sql语句进行查询,在编写sql语句时,有事我们可能在不使用主键的情况下,进行过滤查询。此时好比是不使用rowkey,直接查询某一列。这样必须对某个表进行全表扫描,才能查询到指定的数据,效率低。
- 二级索引是针对列的索引,通过建立二级索引,可以在不使用主键进行查询的场景中提升查询效率。
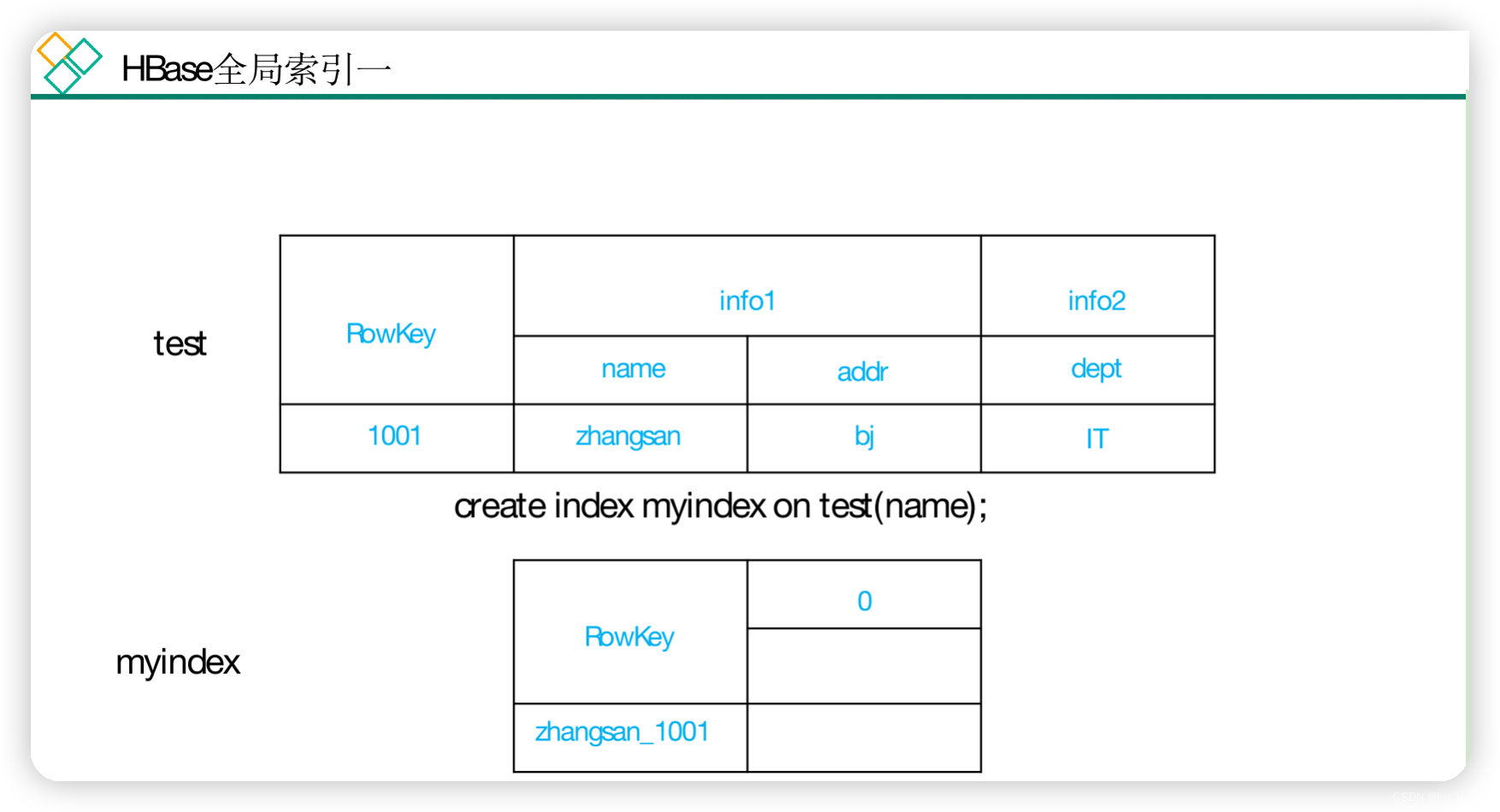
2、全局索引(global index)
- Global Index是默认的索引格式,创建全局索引时,会在HBase中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。
- 写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
- 在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。
创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);
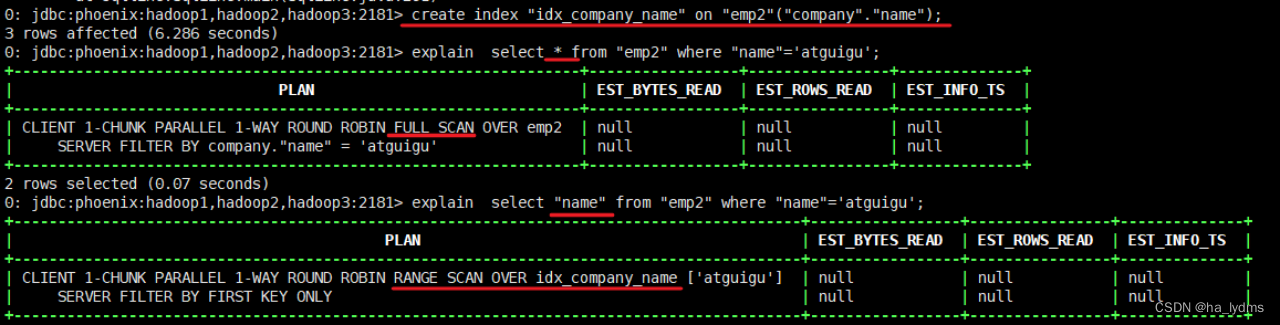
如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
3、包含索引(covered index)
- 包含索引会将指定的列作为rowkey,包含的列作为普通列建立索引。
创建携带其他字段的全局索引
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);

4、本地索引(local index)
- Local Index适用于写操作频繁的场景。
- 在数据表中新建一个列族来存储索引数据。避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
CREATE LOCAL INDEX my_index ON my_table (my_column);

相关文章:
HBase整合Phoenix
文章目录 一、简介1、Phoenix定义2、Phoenix架构 二、安装Phoenix1、安装 三、Phoenix操作1、Phoenix 数据映射2、Phoenix Shell操作3、Phoenix JDBC操作3.1 胖客户端3.2 瘦客户端 四、Phoenix二级索引1、为什么需要二级索引2、全局索引(global index)3、…...

C# 委托/事件/lambda
概念 委托 定义委托编译器会自动生成一个类派生自System.MulticastDelegate 这个类包含4个方法:一个构造器、Invoke、BeginInvoke、EndInvoke。 调用委托的时候实际上执行的是 Invoke方法。 MulticastDelegate类有三个重要字段: _targetÿ…...

13款趣味性不错(炫酷)的前端动画特效及源码(预览获取)分享(附源码)
文字激光打印特效 基于canvas实现的动画特效,你既可以设置初始的打印文字也可以在下方输入文字可实现激光字体打印,精简易用。 预览获取 核心代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&q…...
C# 友元程序集
1.友元程序集 使用友元程序集可以将internal成员提供给其他的友元程序集访问。 程序集FriendTest1.dll [assembly:InternalsVisibleTo("FriendTest2")] namespace FriendTest1 {internal class Friend{string name;public string Name > name;public Friend(str…...
CRM系统的数据分析和报表功能对企业重要吗?
竞争日益激烈,企业需要更加高效地管理客户关系,以获取更多的商机。为此,许多企业选择使用CRM系统。在CRM中,数据分析功能扮演着重要的角色。下面就来详细说说,CRM系统数据分析与报表功能对企业来说重要吗? …...

【单体架构事务失效解决方式之___代理对象加锁】
单体架构__用户限买 一个id一单的多线程事务失效问题解决 背景介绍:有一种情况,我们在使用Synchronized的时候出现失效情况。 经过排查,是因为使用了this.当前对象,他现在使用的是目标对象加锁失效,使用代理对象加锁就…...

面试被问到 HTTP和HTTPS的区别有哪些?你该如何回答~
HTTP和HTTPS的区别有哪些,主要从以下几个方面来说: 1.安全性 HTTP和HTTPS是两种不同的协议,它们之间最主要的区别在于安全性。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,容易被攻击者截取信息。 HTTPS则在…...
点评项目——短信登陆模块
2023.12.6 短信登陆如果基于session来实现,会存在session共享问题:多台Tomcat不能共享session存储空间,这会导致当请求切换到不同服务器时出现数据丢失的问题。 早期的解决办法是让session提供一个数据拷贝的功能,即让各个Tomcat的…...

2023亚太地区五岳杯量子计算挑战赛
计算电源网 (CPN)布局优化 1. 介绍 计算能力网络 (CPN)是一种基于业务需求分配和调度计算资源的新型信息基础设施,计算资源通常由终端用户、边缘服务器和云服务器组成。该网络旨在满足各种计算任务的需求。根据计算需求的空间分…...

Python 模块的使用方法
Python 模块是一种组织和封装代码的方式,允许你将相关的功能和变量放在一个单独的文件中,以便在其他程序中重复使用。在Python中,模块是一种可执行的Python脚本,其文件扩展名为 .py。这里,我将详细讲解Python模块的使用…...
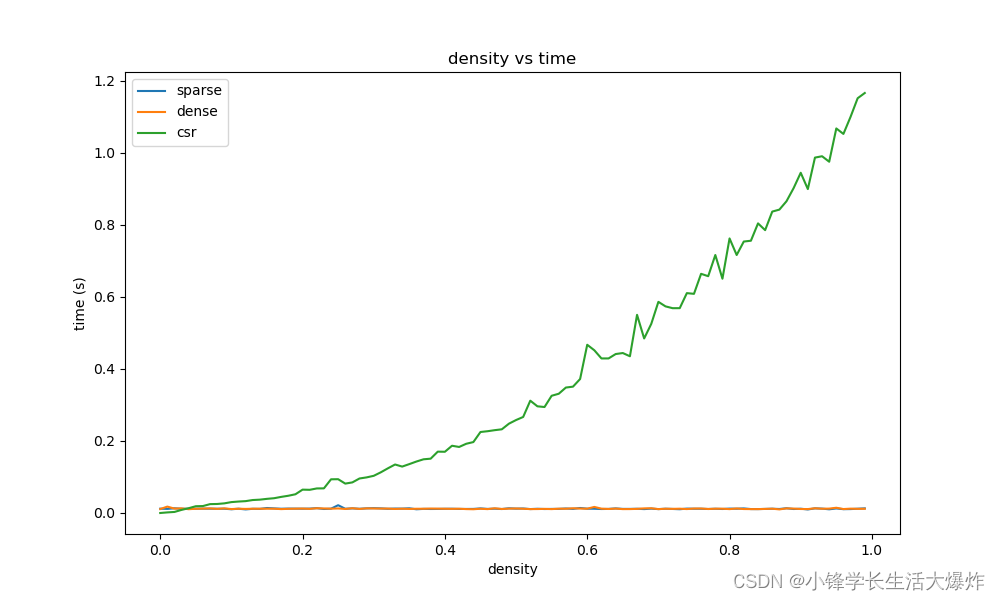
【知识】稀疏矩阵是否比密集矩阵更高效?
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 问题提出 有些地方说,稀疏图比密集图的计算效率更高,真的吗? 原因猜想 这里的效率高,应该是有前提的:当使用稀疏矩阵的存储格式(如CSR)时,计…...

代码随想Day24 | 回溯法模板、77. 组合
理论基础 回溯法和递归不可分割,回溯法是一种穷举的方法,通常需要剪枝来降低复杂度。回溯法有一个选择并退回的过程,可以抽象为树结构,回溯法的模板如下: void backtracking(参数) {if (终止条件) {存放结果;return;}…...

搜索与回溯算法②
求0-9的数字可以组成的所有k 位数。 def backtrack(start, path, k, n, results):"""核心函数。:param start: 下一个添加的数字的起始位置:param path: 当前构建的路径,代表一个组合:param k: 组合中所需的数字个数:param n: 可选数字的最大值:par…...
Centos图形化界面封装OpenStack Ubuntu镜像
目录 背景 环境 搭建kvm环境 安装ubuntu虚机 虚机设置 系统安装 登录虚机 安装cloud-init 安装cloud-utils-growpart 关闭实例 删除细节信息 删除网卡细节 使虚机脱离libvirt纳管 结束与验证 压缩与转移 验证是否能够正常运行 背景 一般的镜像文件在上传OpenSt…...

使用Jmeter进行http接口测试怎么做?
前言: 本文主要针对http接口进行测试,使用Jmeter工具实现。 Jmter工具设计之初是用于做性能测试的,它在实现对各种接口的调用方面已经做的比较成熟,因此,本次直接使用Jmeter工具来完成对Http接口的测试。 一、开发接…...

创建腾讯云存储桶---上传图片--使用cos-sdk完成上传
创建腾讯云存储桶—上传图片 注册腾讯云账号https://cloud.tencent.com/login 登录成功,选择右边的控制台 点击云产品,选择对象存储 创建存储桶 填写名称,选择公有读,私有写一直下一步,到创建 选择安全管理&#…...
12.3_黑马MybatisPlus笔记(上)
目录 02 03 04 05 06 07 编辑 thinking:system.out::println?编辑 thinking:list.of? 08 thinking:RequestParam和 ApiParam注解使用? thinking:RequestParam 和PathVariable的区别? 编辑 编…...

智能优化算法应用:基于寄生捕食算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于寄生捕食算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于寄生捕食算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.寄生捕食算法4.实验参数设定5.算法结果6.参考…...

全息图着色器插件:Hologram Shaders Pro for URP, HDRP Built-in
8个新的Unity全息图着色器,具有故障效果,扫描线,网格线,和更多其他效果!与所有渲染管线兼容。 软件包添加了一系列的全息图着色器到Unity。从基本的全息图与菲涅耳亮点,先进的全息图与两种故障效应,扫描线,文体点阵和网格线全息图! 特色全息效果 Basic-支持菲涅耳发光照…...

Python Opencv实践 - 简单的AR项目
这个简单的AR项目效果是,通过给定一张静态图片作为要视频中要替换的目标物品,当在视频中检测到图片中的物体时,通过单应矩阵做投影,将视频中的物体替换成一段视频播放。这个项目的所有素材来自自己的手机拍的视频。 静态图片&…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...