2 文本分类入门:TextCNN
论文链接:https://arxiv.org/pdf/1408.5882.pdf
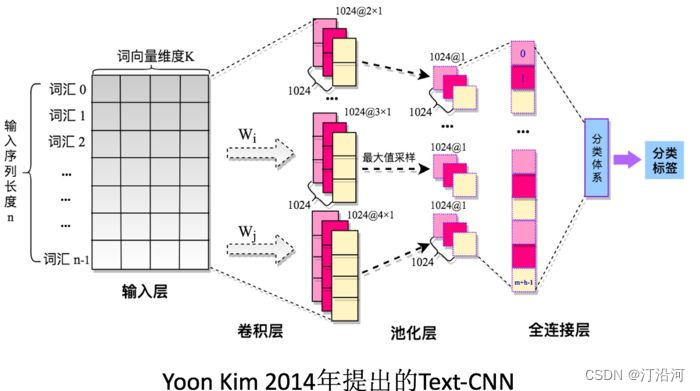
TextCNN 是一种用于文本分类的卷积神经网络模型。它在卷积神经网络的基础上进行了一些修改,以适应文本数据的特点。
TextCNN 的主要思想是使用一维卷积层来提取文本中的局部特征,并通过池化操作来减少特征的维度。这些局部特征可以捕获词语之间的关系和重要性,从而帮助模型进行分类。
nn.Conv2d
nn.Conv2d的构造函数包含以下参数:
in_channels:输入数据的通道数。out_channels:卷积核的数量,也是输出数据的通道数。kernel_size:卷积核的大小,可以是一个整数或一个元组,表示宽度和高度。stride:卷积核的步幅,可以是一个整数或一个元组,表示水平和垂直方向的步幅。nn.Conv2d(1, config.num_filters, (k, config.embed))
输入通道是1 , 输出通道的维度, 卷积核(k, config.embed))
代码部分:
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import pickle as pkl
from tqdm import tqdm
import time
from torch.utils.data import Datasetfrom datetime import timedeltafrom sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from torch.optim import AdamWdf = pd.read_csv("./data/online_shopping_10_cats.csv")
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号
RANDOM_SEED = 2023file_path = "./data/online_shopping_10_cats.csv"
vocab_file = "./data/vocab.pkl"
emdedding_file = "./data/embedding_SougouNews.npz"
vocab = pkl.load(open(vocab_file, 'rb'))class MyDataSet(Dataset):def __init__(self, df, vocab,pad_size=None):self.data_info = dfself.data_info['review'] = self.data_info['review'].apply(lambda x:str(x).strip())self.data_info = self.data_info[['review','label']].valuesself.vocab = vocab self.pad_size = pad_sizeself.buckets = 250499 def biGramHash(self,sequence, t):t1 = sequence[t - 1] if t - 1 >= 0 else 0return (t1 * 14918087) % self.bucketsdef triGramHash(self,sequence, t):t1 = sequence[t - 1] if t - 1 >= 0 else 0t2 = sequence[t - 2] if t - 2 >= 0 else 0return (t2 * 14918087 * 18408749 + t1 * 14918087) % self.bucketsdef __getitem__(self, item):result = {}view, label = self.data_info[item]result['view'] = view.strip()result['label'] = torch.tensor(label,dtype=torch.long)token = [i for i in view.strip()]seq_len = len(token)# 填充if self.pad_size:if len(token) < self.pad_size:token.extend([PAD] * (self.pad_size - len(token)))else:token = token[:self.pad_size]seq_len = self.pad_sizeresult['seq_len'] = seq_len# 词表的转换words_line = []for word in token:words_line.append(self.vocab.get(word, self.vocab.get(UNK)))result['input_ids'] = torch.tensor(words_line, dtype=torch.long) # bigram = []trigram = []for i in range(self.pad_size):bigram.append(self.biGramHash(words_line, i))trigram.append(self.triGramHash(words_line, i))result['bigram'] = torch.tensor(bigram, dtype=torch.long)result['trigram'] = torch.tensor(trigram, dtype=torch.long)return resultdef __len__(self):return len(self.data_info)#myDataset[0]
df_train, df_test = train_test_split(df, test_size=0.1, random_state=RANDOM_SEED)
df_val, df_test = train_test_split(df_test, test_size=0.5, random_state=RANDOM_SEED)
df_train.shape, df_val.shape, df_test.shape#((56496, 3), (3139, 3), (3139, 3))def create_data_loader(df,vocab,pad_size,batch_size=4):ds = MyDataSet(df,vocab,pad_size=pad_size)return DataLoader(ds,batch_size=batch_size)MAX_LEN = 256
BATCH_SIZE = 4
train_data_loader = create_data_loader(df_train,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
val_data_loader = create_data_loader(df_val,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
test_data_loader = create_data_loader(df_test,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)class Config(object):"""配置参数"""def __init__(self):self.model_name = 'FastText'self.embedding_pretrained = torch.tensor(np.load("./data/embedding_SougouNews.npz")["embeddings"].astype('float32')) # 预训练词向量self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备self.dropout = 0.5 # 随机失活self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练self.num_classes = 2 # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 20 # epoch数self.batch_size = 128 # mini-batch大小self.learning_rate = 1e-4 # 学习率self.embed = self.embedding_pretrained.size(1)\if self.embedding_pretrained is not None else 300 # 字向量维度self.hidden_size = 256 # 隐藏层大小self.n_gram_vocab = 250499 # ngram 词表大小self.filter_sizes = [2,3,4]self.num_filters = 256 # 卷积核数量(channels数)class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)self.convs = nn.ModuleList([nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])# self.convs = nn.ModuleList(# [nn.Conv1D(1, config.num_filters, k) for k in config.filter_sizes]# )self.dropout = nn.Dropout(config.dropout)self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)def conv_and_pool(self, x, conv):x = F.relu(conv(x)).squeeze(3)x = F.max_pool1d(x, x.size(2)).squeeze(2)return xdef forward(self, x):out = self.embedding(x['input_ids'])out = out.unsqueeze(1)out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)out = self.dropout(out)out = self.fc(out)return outconfig = Config()
model = Model(config)
sample = next(iter(train_data_loader))device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)EPOCHS = 5 # 训练轮数
optimizer = AdamW(model.parameters(),lr=2e-4)
total_steps = len(train_data_loader) * EPOCHS
# schedule = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,
# num_training_steps=total_steps)
loss_fn = nn.CrossEntropyLoss().to(device)def train_epoch(model,data_loader,loss_fn,device, optimizer,n_examples,schedule=None):model = model.train()losses = []correct_predictions = 0for d in tqdm(data_loader):# input_ids = d['input_ids'].to(device)# attention_mask = d['attention_mask'].to(device)targets = d['label']#.to(device)outputs = model(d)_,preds = torch.max(outputs, dim=1)loss = loss_fn(outputs,targets)losses.append(loss.item())correct_predictions += torch.sum(preds==targets)loss.backward()nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)optimizer.step()#scheduler.step()optimizer.zero_grad()#break#print(n_examples)return correct_predictions.double().item() / n_examples, np.mean(losses)def eval_model(model, data_loader, loss_fn, device, n_examples):model = model.eval() # 验证预测模式losses = []correct_predictions = 0with torch.no_grad():for d in data_loader:targets = d['label']#.to(device)outputs = model(d)_, preds = torch.max(outputs, dim=1)loss = loss_fn(outputs, targets)correct_predictions += torch.sum(preds == targets)losses.append(loss.item())return correct_predictions.double() / n_examples, np.mean(losses)# train model
EPOCHS = 10
history = defaultdict(list) # 记录10轮loss和acc
best_accuracy = 0for epoch in range(EPOCHS):print(f'Epoch {epoch + 1}/{EPOCHS}')print('-' * 10)train_acc, train_loss = train_epoch(model,train_data_loader,loss_fn = loss_fn,optimizer=optimizer,device = device,n_examples=len(df_train))print(f'Train loss {train_loss} accuracy {train_acc}')val_acc, val_loss = eval_model(model,val_data_loader,loss_fn,device,len(df_val))print(f'Val loss {val_loss} accuracy {val_acc}')print()history['train_acc'].append(train_acc)history['train_loss'].append(train_loss)history['val_acc'].append(val_acc)history['val_loss'].append(val_loss)if val_acc > best_accuracy:torch.save(model.state_dict(), 'best_model_state.bin')best_accuracy = val_acc一维卷积模型,直接替换就行了
class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)# self.convs = nn.ModuleList(# [nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])self.convs = nn.ModuleList([nn.Conv1d(MAX_LEN, config.num_filters, k) for k in config.filter_sizes])self.dropout = nn.Dropout(config.dropout)self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)def conv_and_pool(self, x, conv):#print(x.shape)x = F.relu(conv(x))#.squeeze(3)#print(x.shape)x = F.max_pool1d(x, x.size(2))#.squeeze(2)return xdef forward(self, x):out = self.embedding(x['input_ids'])#print(out.shape)#out = out.unsqueeze(1)out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)out = out.squeeze(-1)#print(out.shape)out = self.fc(out)return outEpoch 1/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:19<00:00, 28.29it/s]
Train loss 0.32963800023092527 accuracy 0.889903709997168 Val loss 0.2872631916414839 accuracy 0.9197196559413826Epoch 2/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:19<00:00, 28.25it/s]
Train loss 0.26778308933985917 accuracy 0.925392948173322 Val loss 0.29051536209677714 accuracy 0.9238611022618668Epoch 3/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:17<00:00, 28.39it/s]
Train loss 0.23998896145841375 accuracy 0.9368450863777966 Val loss 0.29530937147389363 accuracy 0.9238611022618668Epoch 4/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:21<00:00, 28.14it/s]
Train loss 0.21924698638110582 accuracy 0.9446863494760691 Val loss 0.3079132618505083 accuracy 0.9260911118190507Epoch 5/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:21<00:00, 28.15it/s]
Train loss 0.1976975509786261 accuracy 0.9515717926932881 Val loss 0.3294101043627459 accuracy 0.9267282574068174Epoch 6/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:14<00:00, 28.56it/s]
Train loss 0.18130036814091913 accuracy 0.9575899178702917 Val loss 0.34197808585767564 accuracy 0.9260911118190507Epoch 7/10 ----------
100%|█████████████████████████████████████| 14124/14124 [09:03<00:00, 26.00it/s]
Train loss 0.16165128718584662 accuracy 0.9624044180118947 Val loss 0.34806641904714486 accuracy 0.924816820643517
conv1D:
Epoch 1/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:53<00:00, 48.14it/s]Train loss 0.4587948323856965 accuracy 0.7931711979609176 Val loss 0.3846700458902963 accuracy 0.8738451736221726Epoch 2/10 ----------100%|█████████████████████████████████████| 14124/14124 [05:21<00:00, 43.93it/s]Train loss 0.3450994613828836 accuracy 0.8979219767771169 Val loss 0.39124348195663816 accuracy 0.8932781140490602Epoch 3/10 ----------100%|█████████████████████████████████████| 14124/14124 [05:14<00:00, 44.93it/s]Train loss 0.3135276534462201 accuracy 0.9156046445766072 Val loss 0.38953639226077036 accuracy 0.9041095890410958Epoch 4/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:32<00:00, 51.76it/s]Train loss 0.29076329547278607 accuracy 0.926224865477202 Val loss 0.4083191853780146 accuracy 0.9063395985982797Epoch 5/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:33<00:00, 51.70it/s]Train loss 0.2712314691068196 accuracy 0.9351989521382045 Val loss 0.44957431750859633 accuracy 0.9063395985982797Epoch 6/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:28<00:00, 52.56it/s]Train loss 0.2521194787317903 accuracy 0.9424561030869442 Val loss 0.4837963371119771 accuracy 0.9082510353615801Epoch 7/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:28<00:00, 52.64it/s]Train loss 0.2317749120263705 accuracy 0.9494831492495044 Val loss 0.5409662437294889 accuracy 0.9063395985982797Epoch 8/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:29<00:00, 52.39it/s]Train loss 0.2093608888886245 accuracy 0.9562269895213821 Val loss 0.5704389385299592 accuracy 0.9037910162472125Epoch 9/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:28<00:00, 52.68it/s]Train loss 0.1867563983566425 accuracy 0.9619088077032002 Val loss 0.6150021497048127 accuracy 0.9015610066900287Epoch 10/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:29<00:00, 52.45it/s]Train loss 0.16439846786478746 accuracy 0.9669003115264797 Val loss 0.6261858006026605 accuracy 0.9098438993309972
使用Conv2D 的效果比Conv1D的效果好。
最近在忙着打一个数据挖掘的比赛,后续会持续输出,请大家关注,谢谢!
相关文章:
2 文本分类入门:TextCNN
论文链接:https://arxiv.org/pdf/1408.5882.pdf TextCNN 是一种用于文本分类的卷积神经网络模型。它在卷积神经网络的基础上进行了一些修改,以适应文本数据的特点。 TextCNN 的主要思想是使用一维卷积层来提取文本中的局部特征,并通过池化操…...

算法初阶双指针+C语言期末考试之编程题加强训练
双指针 常⻅的双指针有两种形式,⼀种是对撞指针,⼀种是左右指针。 对撞指针:⼀般⽤于顺序结构中,也称左右指针。 • 对撞指针从两端向中间移动。⼀个指针从最左端开始,另⼀个从最右端开始,然后逐渐往中间逼…...

【Spark基础】-- 宽窄依赖
目录 1、前言 2、宽窄依赖 2.1 窄依赖 2.2 宽依赖 3、宽窄转换的算子 1、前言 要理解宽窄依赖,首先我们需要了解 Transform...
Spatial Data Analysis(六):空间优化问题
Spatial Data Analysis(六):空间优化问题 使用pulp库解决空间优化问题: pulp是一个用于优化问题的Python库。它包含了多种优化算法和工具,可以用于线性规划、混合整数线性规划、非线性规划等问题。Pulp提供了一个简单…...

PHP短信接口防刷防轰炸多重解决方案三(可正式使用)
短信接口盗刷轰炸:指的是黑客利用非法手段获取短信接口的访问权限,然后使用该接口发送大量垃圾短信给目标用户 短信验证码轰炸解决方案一(验证码类解决)-CSDN博客 短信验证码轰炸解决方案二(防止海外ip、限制ip、限制手机号次数解决)-CSDN博客 PHP短信…...
C#大型LIS检验信息系统项目源码
LIS系统,一套医院检验科信息系统。它是以数据库为核心,将实验仪器与电脑连接成网,基础功能包括病人样本登录、实验数据存取、报告审核、打印分发等。除基础功能外,实验数据统计分析、质量控制管理、人员权限管理、试剂出入库等功能…...
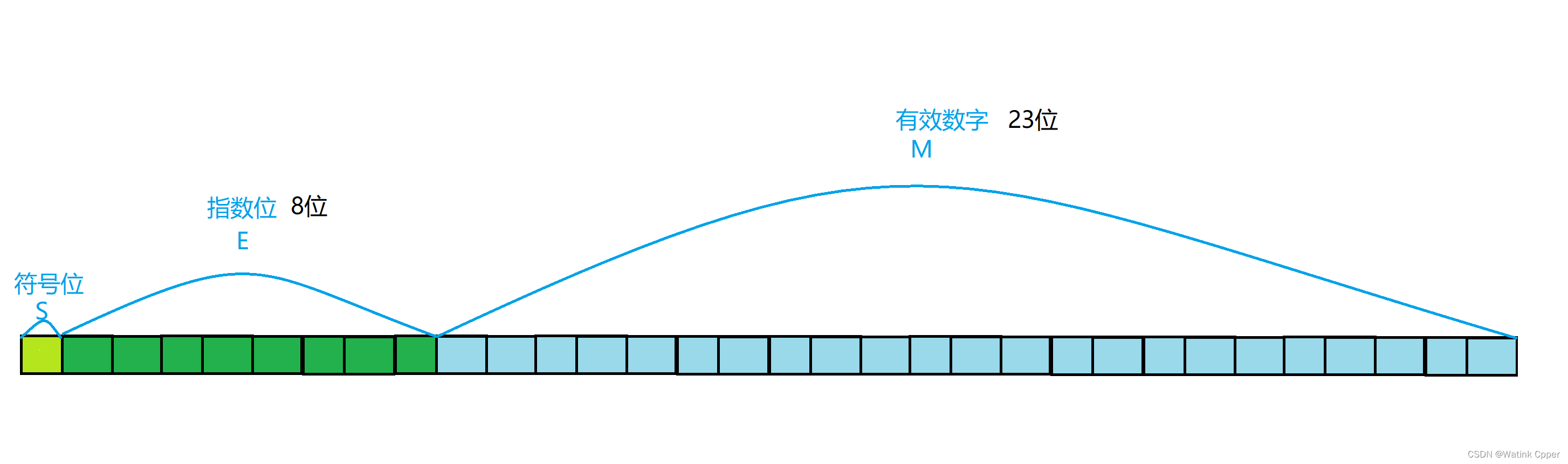
【C语言】数据在内存中的存储
目录 练笔 整型数据的存储: char 型数据——最简单的整型 整型提升: 推广到其他整形: 大小端: 浮点型数据的存储: 存储格式: 本篇详细介绍 整型数据,浮点型数据 在计算机中是如何储存的。…...
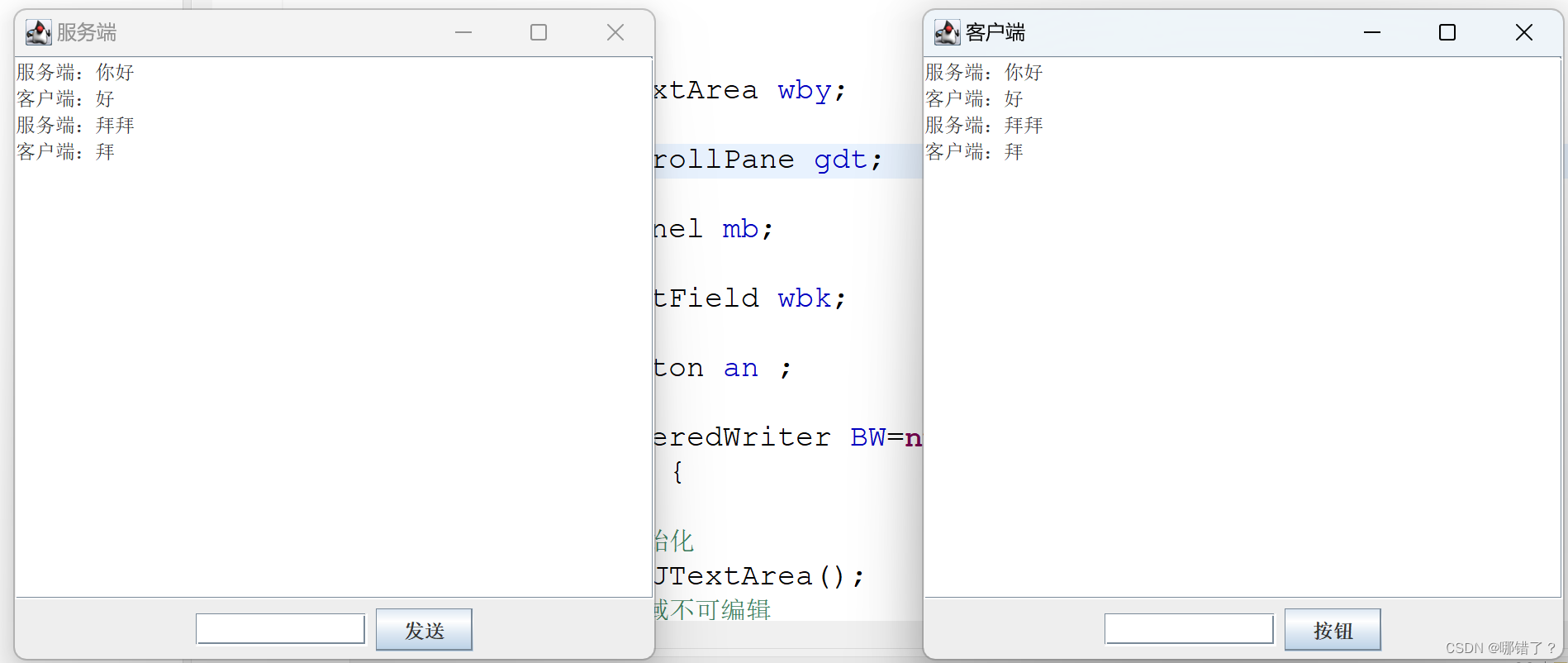
Java聊天程序(一对一)简单版
我们首先要完成服务端,不然出错,运行也要先运行服务端,如果不先连接服务端,就不监听,那客户端不知道连接谁 服务端 import java.awt.BorderLayout; import java.awt.event.ActionEvent; import java.awt.event.Actio…...

Linux下超轻量级Rust开发环境搭建:一、安装Rust
Rust语言在国内逐步开始流行,但开发环境的不成熟依然困扰不少小伙伴。 结合我个人的使用体验,推荐一种超轻量级的开发环境:Rust Helix Editor。运行环境需求很低,可以直接在Linux终端里进行代码开发。对于工程不是太过庞大的Rus…...

定义一个学生类,其中有3个私有数据成员学号、姓名、成绩,以及若于成员。 函数实现对学生数据的赋值和输出。
#include <stdio.h> // 定义学生类 typedef struct Student { int stuNum; // 学号 char name[20]; // 姓名,假设最长为20个字符 float score; // 成绩 } Student; // 初始化学生信息 void initializeStudent(Student *student, int num, const…...
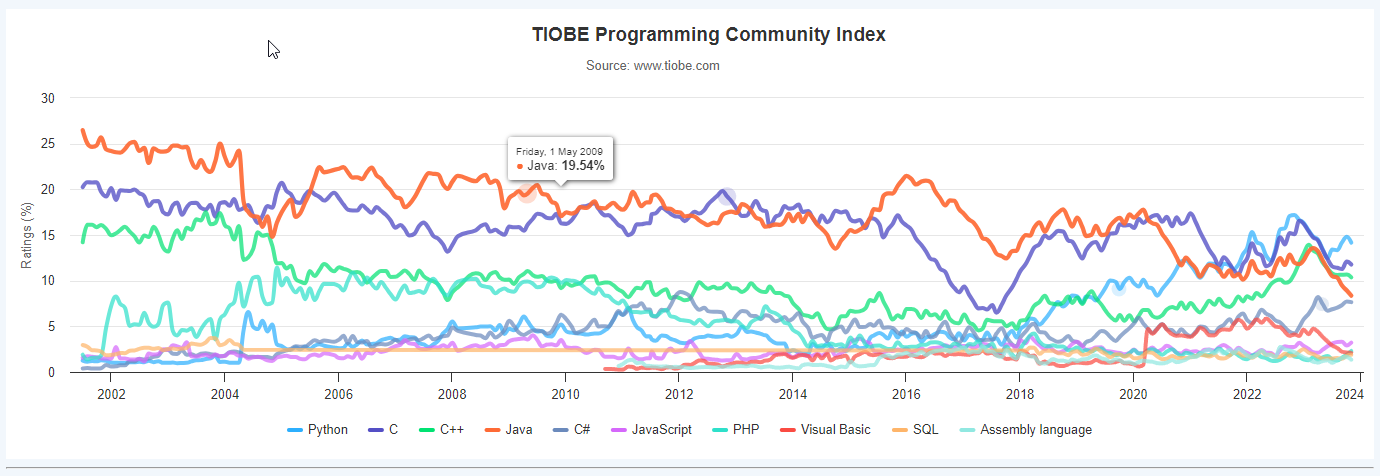
1.2 C语言简介
一、为什么要讲C语言 C语言是编程界的长青藤,可以查看语言排名发现,虽然现在语言很多,但是C语言一直占有一定地址 来源网站:https://www.tiobe.com/tiobe-index/ 在系统、嵌入式、底层驱动等领域存在一定的唯一性(C语…...

小白学Java之数组问题——第三关黄金挑战
内容1.数组中出现次数超过一般的数字2.数组中出现一次的数字3.颜色分类问题 1.数组中出现次数超过一半的数字 这是剑指offer中的一道题目,数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。 例如:输入如下所示的一个长度为9…...
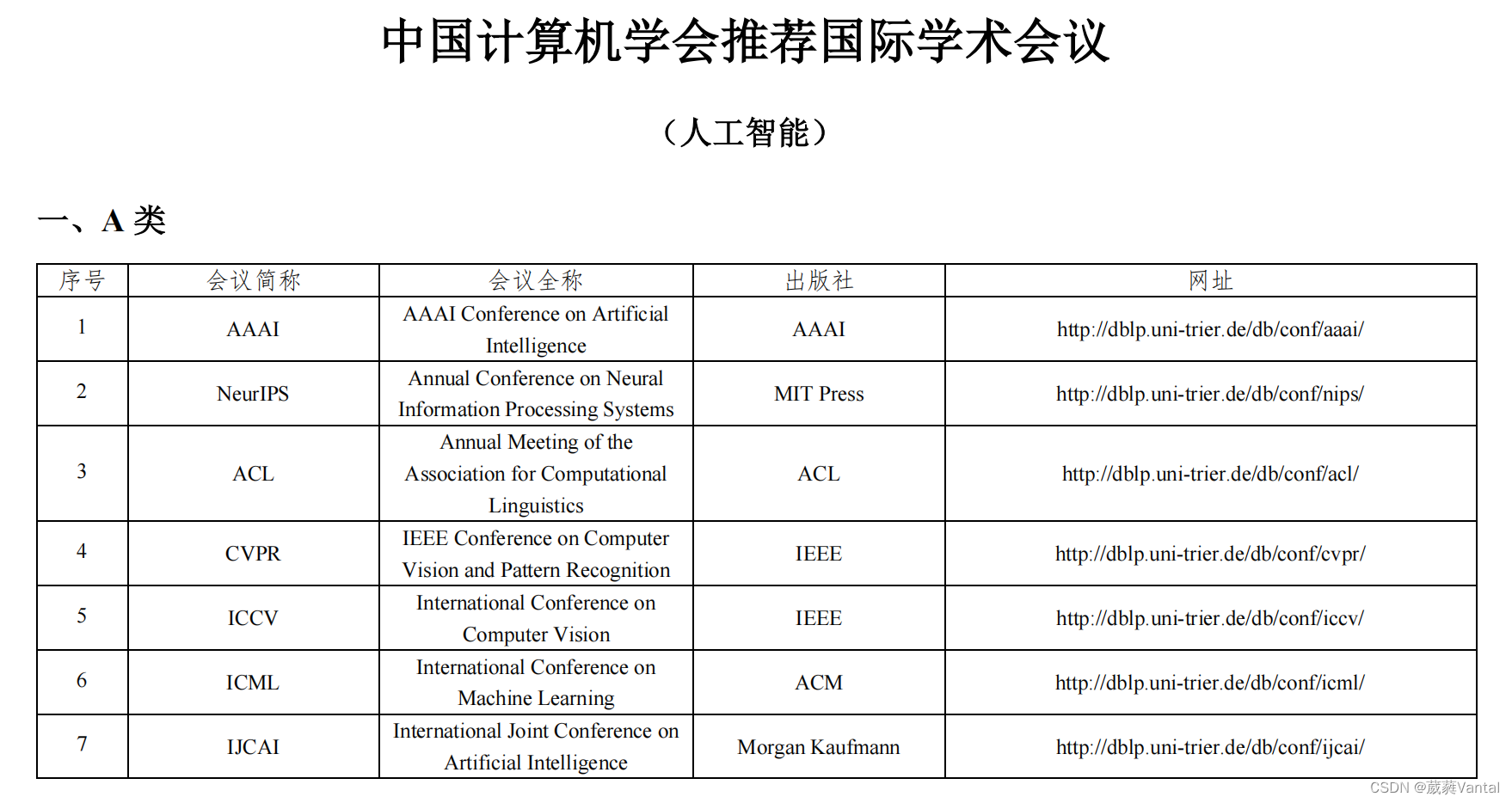
各大期刊网址
1.NeurIPS,全称Annual Conference on Neural Information Processing Systems, 是机器学习领域的顶级会议,与ICML,ICLR并称为机器学习领域难度最大,水平最高,影响力最强的会议! NeurIPS是CCF 推…...

使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s
1,演示视频 https://www.bilibili.com/video/BV1gu4y1c7KL/ 使用autodl服务器,在A40显卡上运行, Yi-34B-Chat-int4模型,并使用vllm优化加速,显存占用42G,速度18 words/s 2,关于A40显卡…...
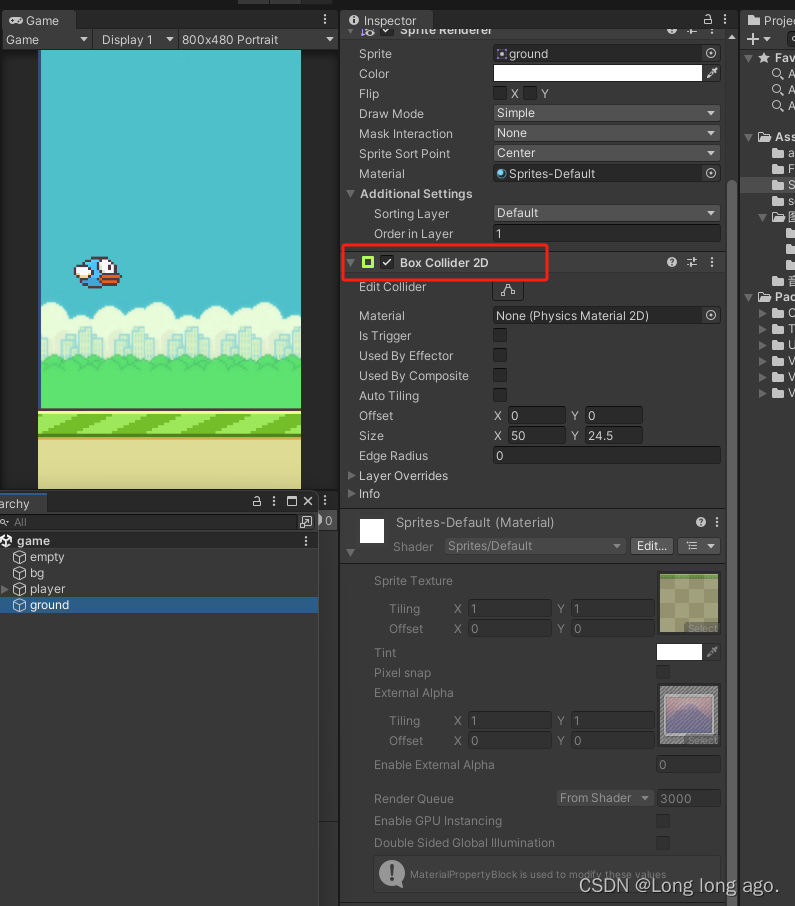
unity 2d 入门 飞翔小鸟 下坠功能且碰到地面要停止 刚体 胶囊碰撞器 (四)
1、实现对象要受重力 在对应的图层添加刚体 改成持续 2、设置胶囊碰撞器并设置水平方向 3、地面添加盒状碰撞器 运行则能看到小鸟下坠并落到地面上...
速达软件任意文件上传漏洞复现
简介 速达软件专注中小企业管理软件,产品涵盖进销存软件,财务软件,ERP软件,CRM系统,项目管理软件,OA系统,仓库管理软件等,是中小企业管理市场的佼佼者,提供产品、技术、服务等信息,百万企业共同选择。速达软件全系产品存在任意文件上传漏洞,未经身份认证得攻击者可以通过此漏…...

Name or service not knownstname
Name or service not knownstname Hadoop 或 Spark 集群启动时 报错 Name or service not knownstname 原因时因为 workers 文件在windows 使用图形化工具打开过 操作系统类型不对引发的 在Linux系统上删除 workers 文件 使用 vim 重新编辑后分发即可...
[Geek Challenge 2023] web题解
文章目录 EzHttpunsignn00b_Uploadeasy_phpEzRceezpythonezrfi EzHttp 按照提示POST传参 发现密码错误 F12找到hint,提示./robots.txt 访问一下,得到密码 然后就是http请求的基础知识 抓包修改 最后就是 我们直接添加请求头O2TAKUXX: GiveMeFlag 得到…...

【recrutment / Hiring / Job / Application】
Interviewee I), objected/targeted job/position1.1) Azure 平台运维工程师(comms&social)1.1.1), comms communication and social, for talk, content1.1.2) Cloud computing1.1.3) 拥有ITI/MCSE/RHCE相关认证或Azure认证(如Az204/Az304 have/own…...
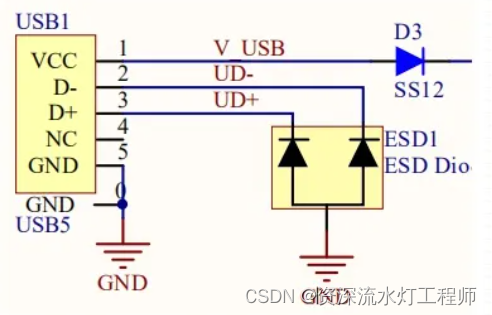
二极管:ESD静电保护二极管
一、什么是ESD二极管 ESD二极管与 TVS二极管原理是一样的,也是为了保护电,但ESD二极管的主要功能是防止静电。 静电防护的前提条件就要求其电容值要足够地低,一般在1PF-3.5PF之间最好,主要应用于板级保护。 二、什么是静电 静…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...