One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
Abstract
一对一(o2o)标签分配对基于变换器的端到端检测起着关键作用,最近已经被引入到全卷积检测器中,用于端到端密集检测。然而,o2o可能因为正样本数量有限而降低特征学习效率。尽管最近的DETRs引入了额外的正样本来缓解这个问题,但解码器中的自注意力和交叉注意力计算限制了其在密集和全卷积检测器中的实际应用。在这项工作中,我们提出了一种简单而有效的一对少数(o2f)标签分配策略,用于端到端密集检测。除了为每个对象定义一个正锚点和多个负锚点之外,我们还定义了几个软锚点(soft anchor),同时充当正负样本。这些软锚点的正负权重在训练过程中动态调整,使它们在训练初期更多地贡献于“表示学习”,在后期更多地贡献于“重复预测移除”。以这种方式训练的检测器不仅可以学习强大的特征表示,还能进行端到端密集检测。在COCO和CrowdHuman数据集上的实验展示了o2f方案的有效性。代码可在以下链接获取:https://github.com/strongwolf/o2f。
Introduction
(仅记录一些我认为比较重要的句子)
-
During the evolution of object detectors, one important trend is to remove the hand-crafted components to achieve end-to-end detection.
-
One hand-crafted component in object detection is the design of training samples.
- However, the performance of anchor-based detectors is sensitive to the shape and size of anchor boxes. To mitigate this issue, anchor-free [19,48] and query-based [5,8,34,61] detectors have been proposed to replace anchor boxes by anchor points and learnable positional queries, respectively.
-
Another hand-crafted component is non-maximum suppression(NMS) to remove duplicated predictions.
- Since NMS has hyperparameters to tune and introduces additional cost, NMS-free end-to-end object detection is highly desired. (由于NMS需要调整超参数并带来额外的成本,因此非常希望实现无NMS的端到端对象检测。)
-
With a transformer architecture, DETR [5] achieves competitive end-to-end detection performance.
- However, o2o can impede the training efficiency due to the limited number of positive samples.
-
Recent studies [7, 17, 22] on DETR try to overcome this shortcoming of o2o scheme by introducing independent query groups to increase the number of positive samples. The independency between different query groups is ensured by the self-attention computed in the decoder, which is however infeasible for FCN-based detectors.(最近的研究[7, 17, 22]尝试通过引入独立的查询组来增加正样本数量,以克服DETR中一对一(o2o)方案的这一缺点。不同查询组之间的独立性由解码器中计算的自注意力来保证,但这对于基于FCN的检测器来说是不可行的。)
-
In this paper, we aim to develop an efficient FCN-based dense detector, which is NMS-free yet end-to-end trainable.
- 我们观察到,在一对一(o2o)方案中,将语义上类似于正样本的模糊锚点设为完全负样本是不合适的。相反,这些锚点可以在训练期间同时用于计算正损失和负损失,如果损失权重设计得当,不会影响端到端的能力。基于上述观察,我们提议为这些模糊锚点分配动态的软分类标签。如图1所示,与o2o不同,后者将模糊锚点(锚点B或C)设为完全负样本,我们将每个模糊锚点标记为部分正样本和部分负样本。正负标签的程度在训练过程中自适应调整,以保持“表示学习”和“重复预测移除”之间的良好平衡。特别是,在训练的早期阶段,我们开始以较大的正度数和较小的负度数,以便网络能更有效地学习特征表示能力,而在后期训练阶段,我们逐渐增加模糊锚点的负度数,以指导网络学习去除重复预测。我们将我们的方法命名为一对少数(o2f)标签分配,因为一个对象可以有几个软锚点。我们将o2f LA实例化到密集检测器FCOS中,我们在COCO [29]和CrowHuman [40]的实验表明,它实现了与带有NMS的检测器相当甚至更好的性能。

Related Work
在过去的十年里,随着深度学习技术[14, 32, 41, 49, 52, 55]的迅猛发展,对象检测领域取得了巨大进展。现代对象检测器大致可以分为两种类型:基于卷积神经网络(CNN)的检测器[1, 3, 21, 28, 31, 36-38, 48, 50]和基于变换器的检测器[5, 8, 30, 34, 53, 54, 61]。
2.1. 基于CNN的对象检测器
基于CNN的检测器可进一步划分为两阶段检测器和一阶段检测器。两阶段检测器[3, 38]在第一阶段生成区域提议,在第二阶段细化这些提议的位置并预测类别,而一阶段检测器[28, 31]直接在卷积特征图上预测密集锚点的类别和位置偏移。早期的检测器大多使用预定义的锚点作为训练样本。由于不同数据集的适宜设置不同,必须仔细调整锚点形状和大小的超参数。为了克服这一问题,提出了无锚点检测器[19, 48]以简化检测流程。FCOS [48]和CenterNet [10]用锚点替代锚框,并直接使用这些点来回归目标对象。CornerNet [20]首先预测对象关键点,然后使用关联嵌入将它们组合成边界框。
大多数基于CNN的检测器在训练过程中采用一对多(o2m)的标签分配方案。早期的检测器,如Faster RCNN [38]、SSD [31]和RetinaNet [28],使用IoU作为定义正负锚点的指标。FCOS限制正锚点必须在对象的某些尺度和范围内。最近的方法[11, 18, 23, 57, 59, 60]通常考虑网络预测的质量和分布,以更可靠地分配锚点的标签。然而,o2m标签分配需要一个后处理步骤,即非极大值抑制(NMS),以去除重复的预测。NMS引入了一个参数来折衷所有实例的精确度和召回率,但这对于拥挤场景尤其不理想。在本文中,我们的目标是去除基于CNN检测器中的手工NMS步骤,实现端到端的密集检测。
2.2. 基于Transformer的对象检测器
作为先驱的基于Transformer的检测器,DETR [5] 使用一套可学习的对象查询作为与图像特征互动的训练候选项。它通过使用一对一的二部匹配和全局注意力机制,实现了具有竞争力的端到端检测性能。然而,DETR在小物体上的性能较差,收敛速度慢。许多后续工作[8, 12, 35, 56]旨在改进特征图和对象查询之间的注意力建模机制,以提取更相关和精确的特征,提升小物体的检测性能。最近的研究[7, 17, 22]表明,正样本数量有限是导致DETR收敛缓慢的原因。因此,它们引入了几个额外的解码器来增加正样本数量。然而,这些方法都基于稀疏候选项,其计算成本在进行密集预测时可能难以承受。与这些方法不同,我们提出了一种软标签分配方案,引入更多的正样本,使得端到端密集检测器能够更容易地进行训练。
One-to-Few Soft Labeling
3.1. Ambiguous Anchors

-
o2o仅选择一个anchor作为正样本分配为positive sample,而o2m则选取多个anchor作为Positive sample。在o2o和o2m中,除了正样本之外的其余锚点都被定义为负样本。
-
图2中,红色为certain anchor,绿色为ambiguous anchors
-
Now we have divided the anchors into three groups: one certain positive anchor, a few ambiguous anchors, and the remaining multiple negative anchors.
-
第一个选项是将一对一(o2o)改为一对二,为每个实例增加一个正样本。第二个选项是为每个模糊锚点分配一个软标签t,其中0 ≤ t ≤ 1表示其正样本程度,因此1 − t是其负样本程度。我们定义正锚点和负锚点的分类损失分别为−log§和−log(1 − p),其中p是预测的分类得分。那么第二个选项的分类损失将是−t × log§ − (1 − t) × log(1 − p)。在COCO数据集上的检测结果如表1所示,我们可以看到,即使只增加一个正样本,一对二的标签分配方案也会显著降低性能。相比之下,为模糊锚点分配合适的软标签可以有效提高端到端性能。(软标签分配的细节将在后面的章节中讨论。)
- 上述结果表明,使一个模糊锚点同时具有正负属性可能是有效实现端到端密集检测的一个可行方案。因此,我们提出了一种一对少数(o2f)标签分配策略,它选择一个确定的锚点作为完全正样本,几个模糊锚点同时作为正负样本,其余锚点作为负样本。模糊锚点的正负程度在训练过程中动态调整,使得网络既能保持强大的特征表征能力,又能实现端到端检测能力。
3.2. Selection of Certain Positive Anchor
在我们的方法中,每个实例都将选定一个确定的正锚点。之前基于一对一(o2o)的检测器都使用一个预测感知的选择度量,考虑了分类和回归的成本来选择唯一的正样本。我们遵循这一原则,并将分类得分和IoU整合进确定锚点的选择度量中,其定义为:
S i , j = 1 [ i ∈ Ω j ] × p i , c j 1 − α × IoU ( b i , b j ) α , S_{i,j} = \mathbb{1}[i \in \Omega_j] \times p_{i,c_j}^{1-\alpha} \times \text{IoU}(b_i, b_j)^\alpha, Si,j=1[i∈Ωj]×pi,cj1−α×IoU(bi,bj)α,
其中 S_{i,j} 表示锚点i和实例j之间的匹配得分,c_j 是实例j的类别标签,p_{i,c_j} 是锚点i属于类别 c_j 的预测分类得分,b_i 是锚点i的预测边界框坐标,b_j 表示实例j的坐标,而 \alpha 控制分类和回归的重要程度。当锚点i的中心点在实例j的中心区域 \Omega_j 内时,空间指示器 1[i \in \Omega_j] 输出1;否则输出0。这种空间先验在基于o2o和o2m的方法中被普遍使用,因为观察到实例中心区域的锚点更有可能是正样本。
锚点可以根据度量 ( S_{i,j} ) 进行降序排序。之前的研究通常将正锚点选择问题构建为一个二分匹配问题,并使用匈牙利算法解决。为了简化,在本研究中,我们直接为每个实例选择得分最高的锚点作为确定的正锚点。
3.3. Label Assignment for Ambiguous Anchors
除了确定的正锚点之外,我们根据得分 S i , j S_{i,j} Si,j选择排名前K的锚点作为模糊锚点,因为它们与确定的正锚点有相似的语义上下文。为了减少重复预测的可能性,我们为这些模糊锚点分配动态软标签。假设我们训练网络N个周期,在第j个周期中,每个模糊锚点i的分类损失定义为:
l i j = − t i j × log ( p i ) − ( 1 − t i j ) × log ( 1 − p i ) l_i^j = -t_i^j \times \log(p_i) - (1 - t_i^j) \times \log(1 - p_i) lij=−tij×log(pi)−(1−tij)×log(1−pi)
除了确定的正锚点,我们基于得分 (S_{i,j}) 选择排名前K的锚点作为模糊锚点,因为它们与确定的正锚点有相似的语义环境。为了降低重复预测的可能性,我们为这些模糊锚点分配动态软标签。假设我们训练网络进行N个周期,每个模糊锚点i在第j个周期的分类损失定义为:
l i j = − t i j × log ( p i ) − ( 1 − t i j ) × log ( 1 − p i ) , l_i^j = -t_i^j \times \log(p_i) - (1 - t_i^j) \times \log(1 - p_i), lij=−tij×log(pi)−(1−tij)×log(1−pi), (随着epochs的增加, l i j l_i^j lij逐渐的就只等于 − ( 1 − t i j ) × log ( 1 − p i ) - (1 - t_i^j) \times \log(1 - p_i) −(1−tij)×log(1−pi))
其中 (p_i) 是锚点i的预测分类得分,(t_i^j) 和 (1 - t_i^j) 分别是该锚点在第j个周期的正负程度(即,损失权重)。(t_i^j) 的动态定义为:
t i j = p i max k p k × T j , t_i^j = \frac{p_i}{\max_k p_k} \times T_j, tij=maxkpkpi×Tj,
T j = T m i n − T m a x N − 1 × j + T m a x , T_j = \frac{T_{min} - T_{max}}{N - 1} \times j + T_{max}, Tj=N−1Tmin−Tmax×j+Tmax,
其中 (T_j) 是一个随时间变化的变量,它在第j个周期为所有样本分配相同的值,(T_{max}) 和 (T_{min}) 控制模糊锚点在第一个周期和最后一个周期的degree。我们将损失权重与分类得分呈正相关,考虑到预测得分较高的锚点应该更多地贡献于正信号。直接使用 ( p_i ) 作为权重会使得在难样本上的训练变得不稳定,因为这些样本的预测得分远小于简单样本的得分。因此,我们使用 ( p_i ) 与最大得分的比率来规范化不同样本的权重至同一尺度。动态调整 ( T_j ) 是很重要的,因为它在不同的训练阶段控制着“特征学习”与“重复预测移除”之间的平衡。
在训练的早期阶段,我们设置 (T_j) 相对较大,以引入更多的正监督信号以进行表示学习,从而使网络能够迅速收敛到一个稳健的特征表示空间。随着训练的进行,我们逐渐减少模糊锚点的正度,以便网络学会去除重复的预测。
3.4. Network Structure
我们将提出的一对少数(o2f)标签分配策略应用到FCOS上,这是一个典型的全卷积密集检测器。网络结构如图3所示。检测头由两个平行的卷积分支组成,每个特征金字塔网络(FPN)层的输出都连接一个分支。一个分支预测大小为 ( H × W × C H \times W \times C H×W×C) 的得分图,其中 (C) 是数据集中的类别数,(H) 和 (W) 分别是特征图的高度和宽度。另一个分支预测大小为 ( H × W × 4 H \times W \times 4 H×W×4) 的位置偏移图和大小为 ( H × W × 1 H \times W \times 1 H×W×1) 的中心度图。我们按照之前的工作将中心度图与分类得分图相乘,作为最终的分类-交并比联合得分。
"Centerness map"是FCOS(Fully Convolutional One-Stage Object Detector)中用于提高检测性能的一个概念。它是一个得分,用来表示一个位置相对于其目标边界框中心的偏离程度。这个得分用于在非极大抑制(NMS)过程中下调低质量边界框的权重,以抑制这些低质量的检测结果。"Centerness"得分是通过与边界框回归分支平行的一个分支(只有一层)来预测的,这个简单而有效的"centerness"分支能够显著提高检测性能,而计算时间的增加微不足道
对于每个实例,我们选择一个确定的正锚点和 (K) 个模糊锚点。其余的锚点被设置为负样本。分类分支的训练目标为每个实例定义如下:
L c l s = B C E ( p c , 1 ) + ∑ i ∈ A B C E ( p i , t i ) + ∑ i ∈ B F L ( p i , 0 ) L_{cls} = BCE(p_c, 1) + \sum_{i \in A} BCE(p_i, t_i) + \sum_{i \in B} FL(p_i, 0) Lcls=BCE(pc,1)+∑i∈ABCE(pi,ti)+∑i∈BFL(pi,0)
其中 (p_c) 是单个确定锚点的分类得分,(A) 和 (B) 分别代表模糊锚点和负锚点的集合。BCE表示二元交叉熵损失,FL表示焦点损失。回归损失定义为:
L r e g = ∑ i ∈ B G I o U ( b i , b g t ) L_{reg} = \sum_{i \in B} GIoU(b_i, b_{gt}) Lreg=∑i∈BGIoU(bi,bgt)
其中GIoU损失是基于广义交并比的位置损失,(b_i) 是锚点 (i) 的预测位置,(b_{gt}) 是与锚点 (i) 对应的GT对象的位置。请注意,我们对正锚点和模糊锚点都应用了回归损失。
相关文章:
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记 Abstract 一对一(o2o)标签分配对基于变换器的端到端检测起着关键作用,最近已经被引入到全卷积检测器中,用于端到端密集检测。然而,o2o可能因为…...

Ubuntu22.04 使用Docker部署Neo4j出错 Exited(70)
项目场景: 最近需要使用Neo4j图数据库,因此打算使用docker部署 环境使用WSL Ubuntu22.04 问题描述 拉下最新Neo4j镜像,执行命令部署 启动容器脚本 docker run -d -p 7474:7474 -p 7687:7687 \ --name neo4j \ --env "NEO4J_AUTHneo…...

【数据分析 | Numpy】Numpy模块系列指南(一),从设计架构说起
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
多人聊天室
多人聊天包 由于要先创建服务面板,接收客户端连接的信息,此代码使用顺序为先启动服务端,在启动客户端,服务端不用关,不然会报错。多运行几次客户端,实现单人聊天 1.创建服务面板 package yiduiy;import j…...
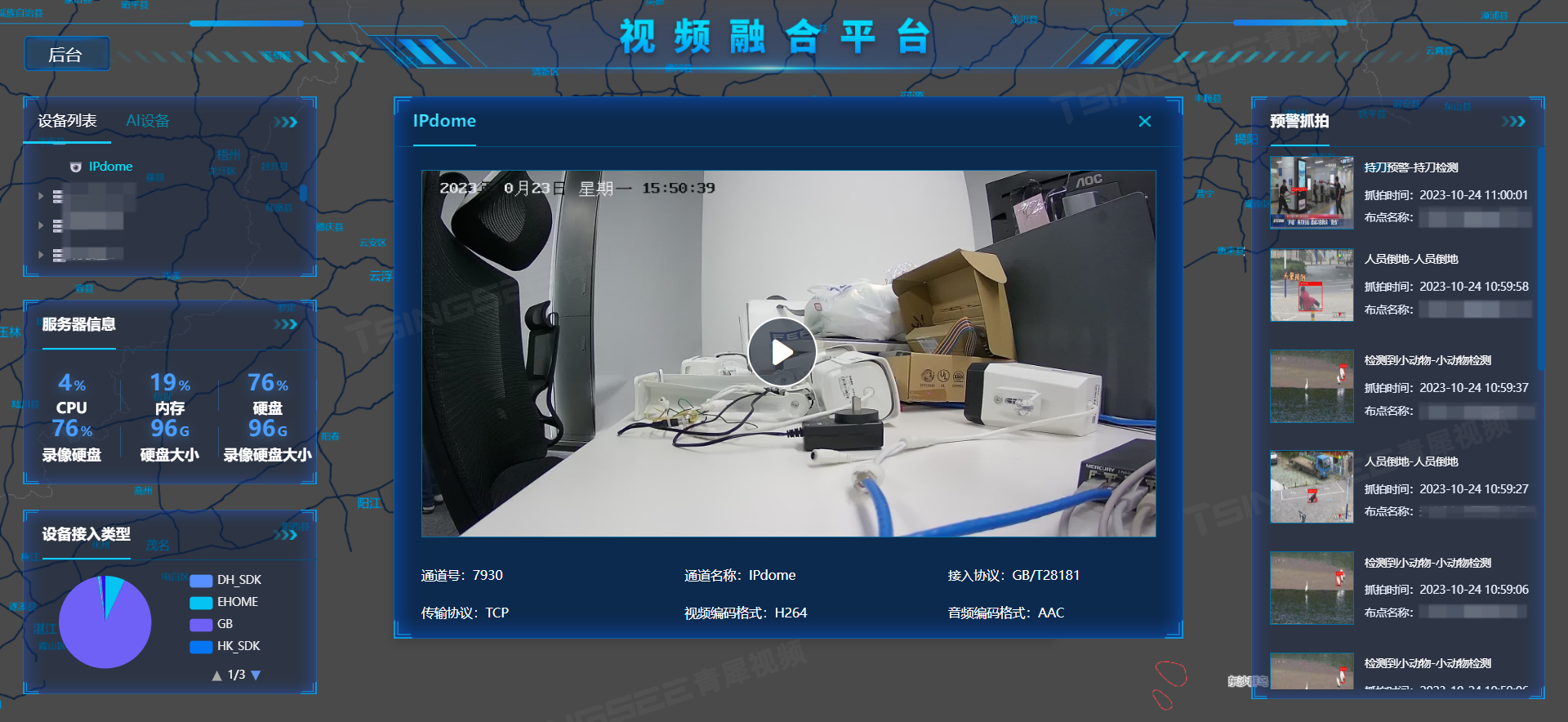
智慧园区可视化综合管理平台建设方案,智能化、数字化才是关键
园区作为城市的基本单元,是经济发展的重要载体。随着我国经济的快速发展,各类工业园区、办公园区等园区的规划建设也越来越多。伴随着互联网新兴技术的发展和应用,智慧园区已成为当今城市规划和社会发展的关注焦点,今天我们来介绍…...
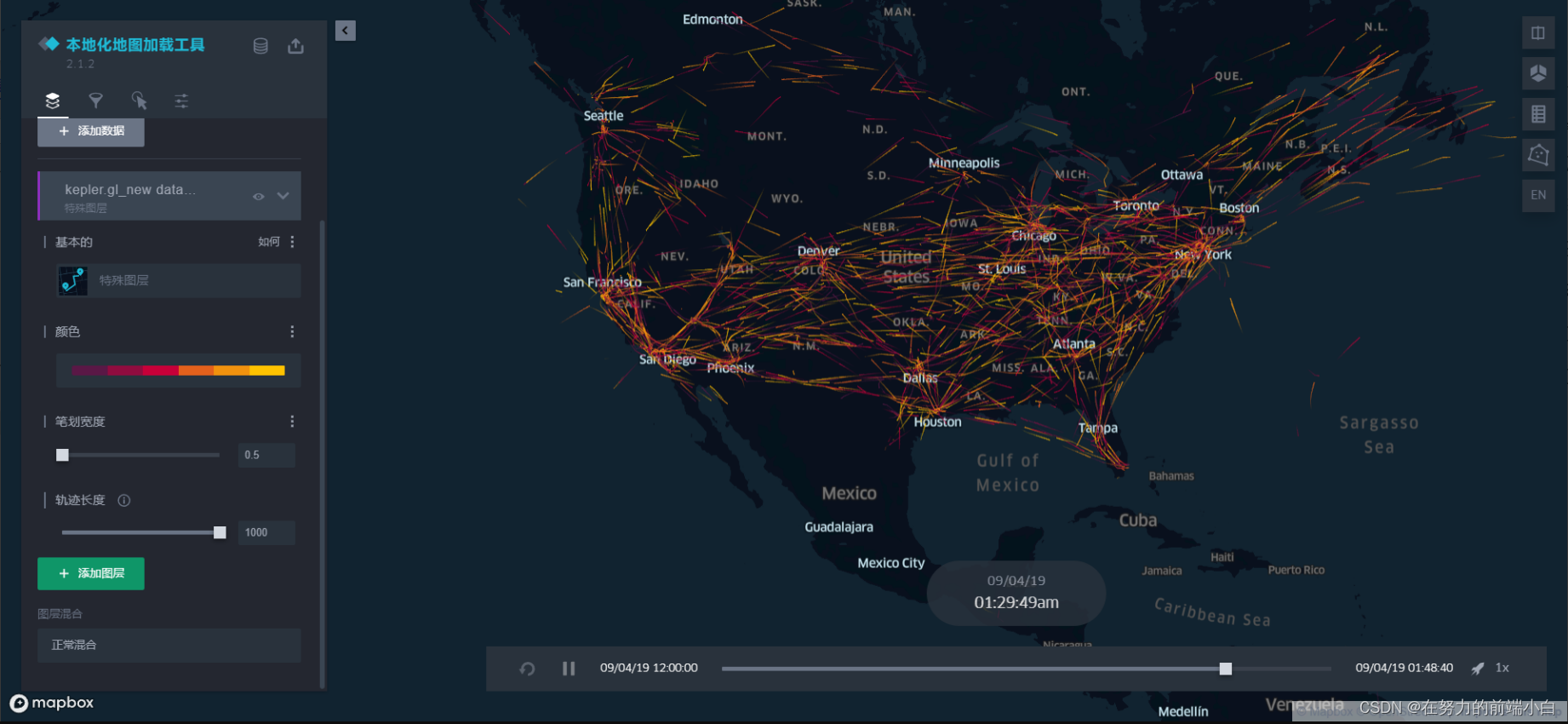
kepler.gl部署在线说明文档
1 概述 1.1 介绍 1、Kepler.gl 是一个强大的开源地理空间分析工具,用于大规模数据集的可视化。它由 Uber 的数据可视化团队开发,并且是基于 Web 技术构建的。Kepler.gl 涉及到以下几个主要技术领域: WebGL: Kepler.gl 通过 WebGL 进行渲染…...

Java程序员,你掌握了多线程吗?
文章目录 01 多线程对于Java的意义02 为什么Java工程师必须掌握多线程03 Java多线程使用方式04 如何学好Java多线程写作末尾 摘要:互联网的每一个角落,无论是大型电商平台的秒杀活动,社交平台的实时消息推送,还是在线视频平台的流…...

Android 11.0 长按按键切换SIM卡默认移动数据
Android 11.0 长按按键切换SIM卡默认移动数据 近来收到客户需求想要通过长按按键实现切换SIM卡默认移动数据的功能,该功能主要通过长按按键发送广播来实现,具体修改参照如下: 首先创建广播,具体修改参照如下: /vend…...
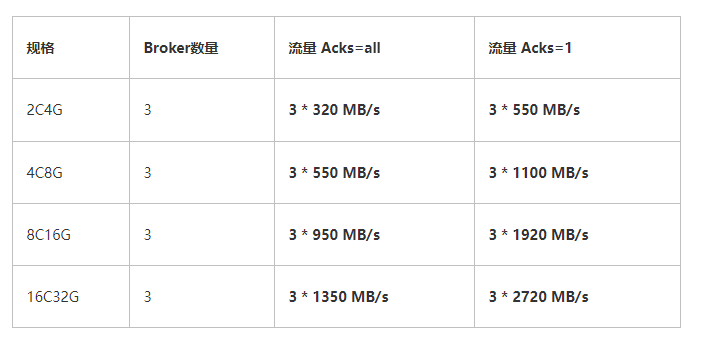
Kafka集群调优+能力探底
一、前言 我们需要对4个规格的kafka能力进行探底,即其可以承载的最大吞吐;4个规格对应的单节点的配置如下: 标准版: 2C4G 铂金版: 4C8G 专业版: 8C16G 企业版: 16C32G 另外,一般…...
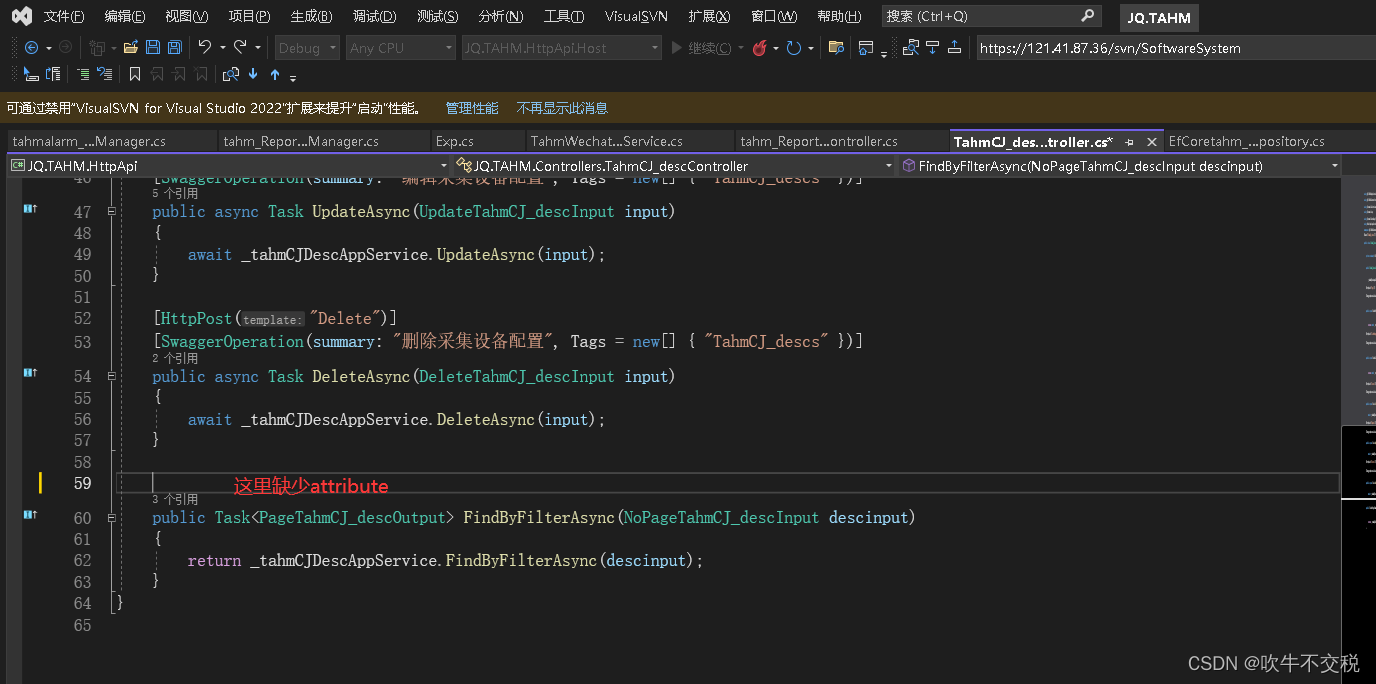
netcore swagger 错误 Failed to load API definition
后端接口报错如下: 前端nswag报错如下: 根据网上查询到的资料说明,说一般swagger这种错误都是控制器里有接口代码异常造成的,通常是接口没有加属性Attribute, 比如[HttpPost("Delete")]、[HttpGet("Del…...

UDP Socket API 的讲解,以及回显服务器客户端的实现
文章目录 UDPDatagramSocktet APIDatagramPacket API UDP 客户端服务器实现 UDP 先来认识一下 UDP 的 socket api,两个核心的类:DatagramSocket、DatagramPacket. DatagramSocktet API 是一个 socket 对象。 什么是 socket? 操作系统&…...
数据结构与算法-D7栈实现及应用
顺序栈 具有顺序表同样的存储结构,由数组定义,配合用数组下标表示的栈顶指针top完成操作 sqstack.h stack_creat stack_push stack_empty stack_full 1、判断栈是否为空 2、top--,取:data[top1] stack_top stack_clear stack_fre…...

蓝桥杯真题:分巧克力(二分法)-Java版
由题目可知,该题的最终结果具有单调性,边长越大,可分蛋糕越少 可以用二分模板的向右找: 整数二分 import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader;public class Main {static int n,k; //n个块蛋糕,k个学生static int N 10…...

c++面试题
1.static的使用 1)修饰局部变量:在函数内部使用static修饰局部变量,会使它成为静态局部变量。静态局部变量只会被初始化一次,且只有在第一次调用该函数时才会被初始化,之后每次调用该函数时都会保留上一次的值.从原来…...
高精度加法,减法,乘法,除法(上)(C语言)
前言 加,减,乘,除这些运算我们自然信手捏来,就拿加法来说,我们要用c语言编程算ab的和,只需让sum ab即可,可是这是局限的,我们都知道int的表示的最大值为2147483647(32位…...

C++新经典模板与泛型编程:SFINAE特性的信息萃取
用成员函数重载实现is_default_constructible 首先介绍一个C标准库提供的可变参类模板std::is_default_constructible。这个类模板的主要功能是判断一个类的对象是否能被默认构造(所谓默认构造,就是构造一个类对象时,不需要给该类的构造函数…...
java单人聊天
服务端 package 单人聊天;import java.awt.BorderLayout; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import…...

nodejs环境安装
node安装 wget https://mirrors.tuna.tsinghua.edu.cn/nodejs-release/v20.8.0/node-v20.8.0-linux-x64.tar.gz tar xf node-v20.8.0-linux-x64.tar.xz -C /usr/local/ ln -s node-v20.8.0-linux-x64 nodevim /etc/profile.d/node.sh export PATH$PATH:/usr/local/node/binnp…...

R语言进行正态分布检验
查了很多资料,还是比较模糊 Kolmogorov-Smirnov检验(K-S检验)广泛用于正态性检验和其他分布的拟合检验。适用于中等到大样本。 Lilliefors检验是K-S检验的一种变体,专门为小样本设计。其通过使用更准确的临界值来提高对小样本的适…...

什么是SPA(Single Page Application)?它的优点和缺点是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...