06、基于内容的过滤算法Tensorflow实现
06、基于内容的过滤算法Tensorflow实现
开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。全部工程可从最上方链接下载。
05、基于梯度下降的协同过滤算法中已经介绍了协同过滤算法的基本实现方法,但是这种方法仅根据用户的相似度进行推荐,而不关注用户或者电影本身的一些特征的匹配,基于内容的过滤算法正式为了对此进行改进。
此处还是以电影推荐作为实际的案例。
1、基于内容的过滤算法实现原理
基于内容的过滤算法的神经网络实现依赖于现有的特征数据,这个特征数据包括用户的特征数据和电影本身的特征数据。常理来讲,最终的打分结果是用户自身的特征和电影本身的属性共同决定的,但是其互相影响的机制可能并不明确,因此可以使用如下的神经网络模型直接训练得到结果:
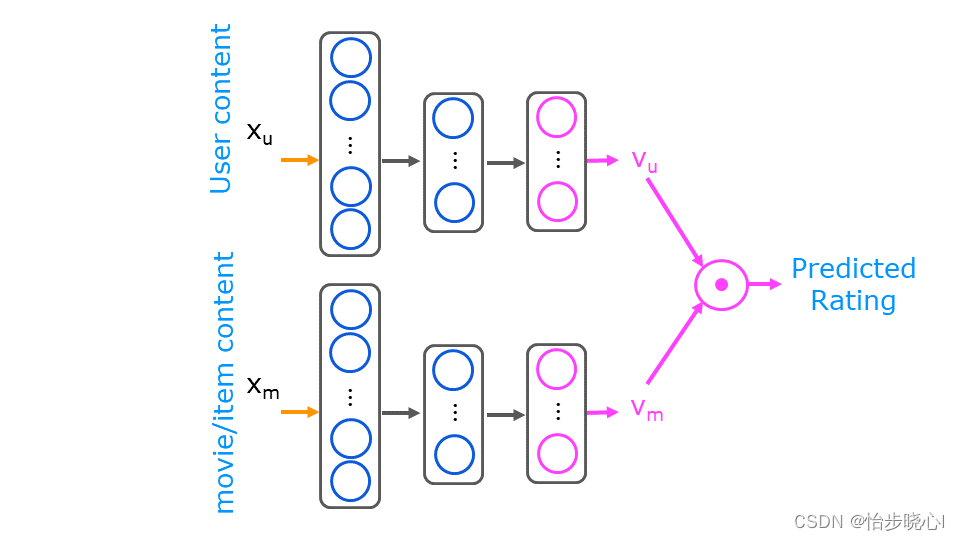
对于上图,在吴恩达的解释中,Vu和Vm分别是用户和电影的特征向量,这个特征是从原有的基础数据(如电影类型、用户爱好、用户年龄等等)中训练出来的,其并没有具体对应的特征含义。
因此,其所介绍的基于内容的过滤算法完全基于神经网络的模型得到预测的打分结果,进而进行推荐,下面对原理步骤进行解释。
2、数据集的简单解释
全部的工程文件可以在最上方的链接进行下载。这个数据集的来源是:dataset,吴恩达老师的数据在此基础上进行了二元化的处理,所以看着非常难以理解。
首先是content_user_train.csv这个文件,,其抬头在content_user_train_header.txt中将其组合即可得到用户的数据,如下所示:

但是值得注意的是,数据和很多的重复的,例如对于用户3,其第40-43行都是一样的数据,可以看到用户3给一个电影打过分:

而这代表用户3看过的电影在content_item_train.csv这个文件的第40-43行,可以看到只有72378这个代号的电影,这个电影占用四行,代表它在四个分类(比如爱情、浪漫、动作等等),电影的平均分是2.6。

content_item_train.csv这个文件的抬头在content_item_train_header.txt中,将其组合即可得到电影的数据,例如:

为充分解释,再举一个用户2的例子,其重复占用从第1行到第39行:
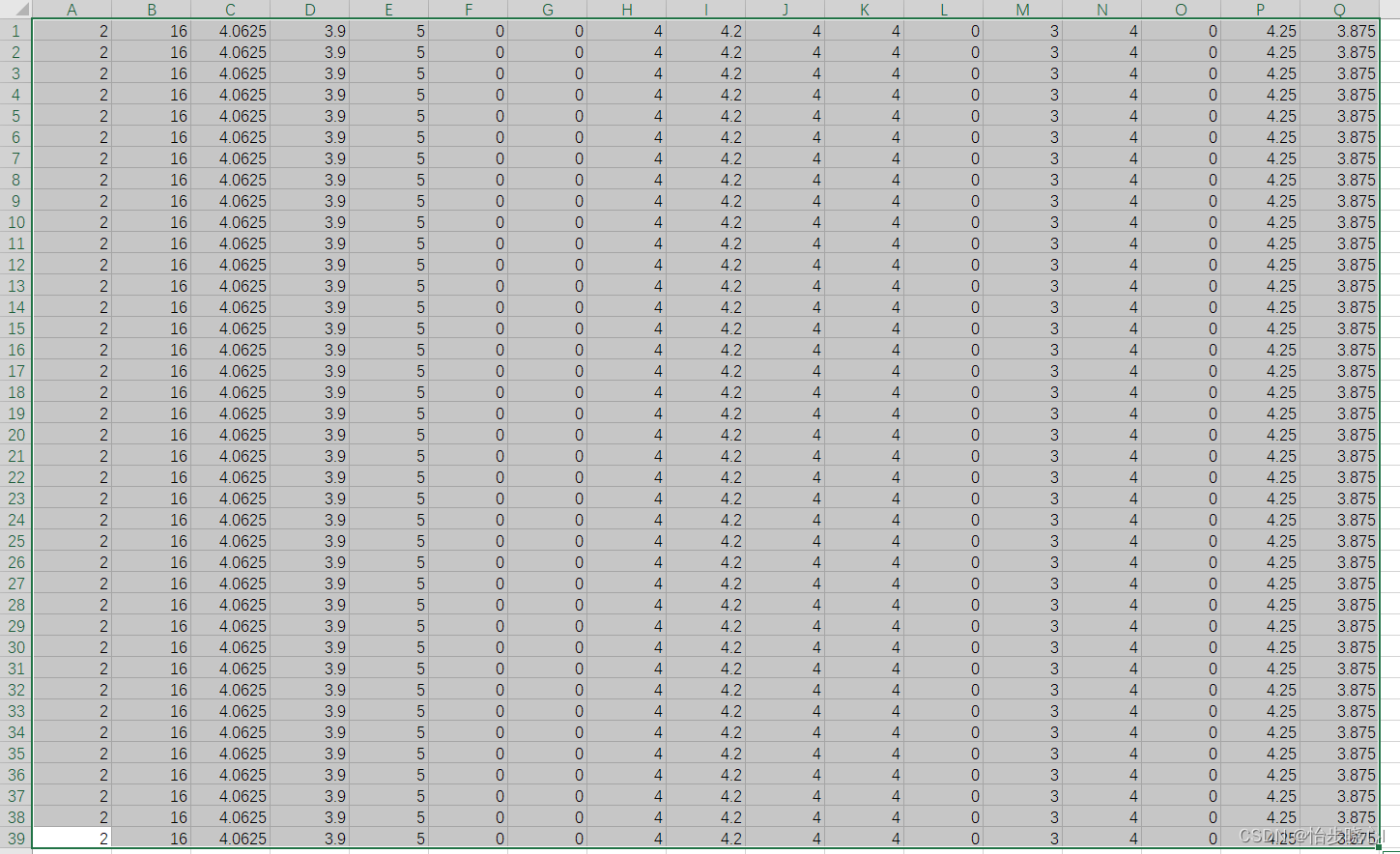
而在content_item_train.csv这个文件中的第1行到第39行,表示其看过6874、8798、46970等16个电影,每个电影属于多少个分类,每个电影就会占用多少行(6874占用3个分类就有三行):
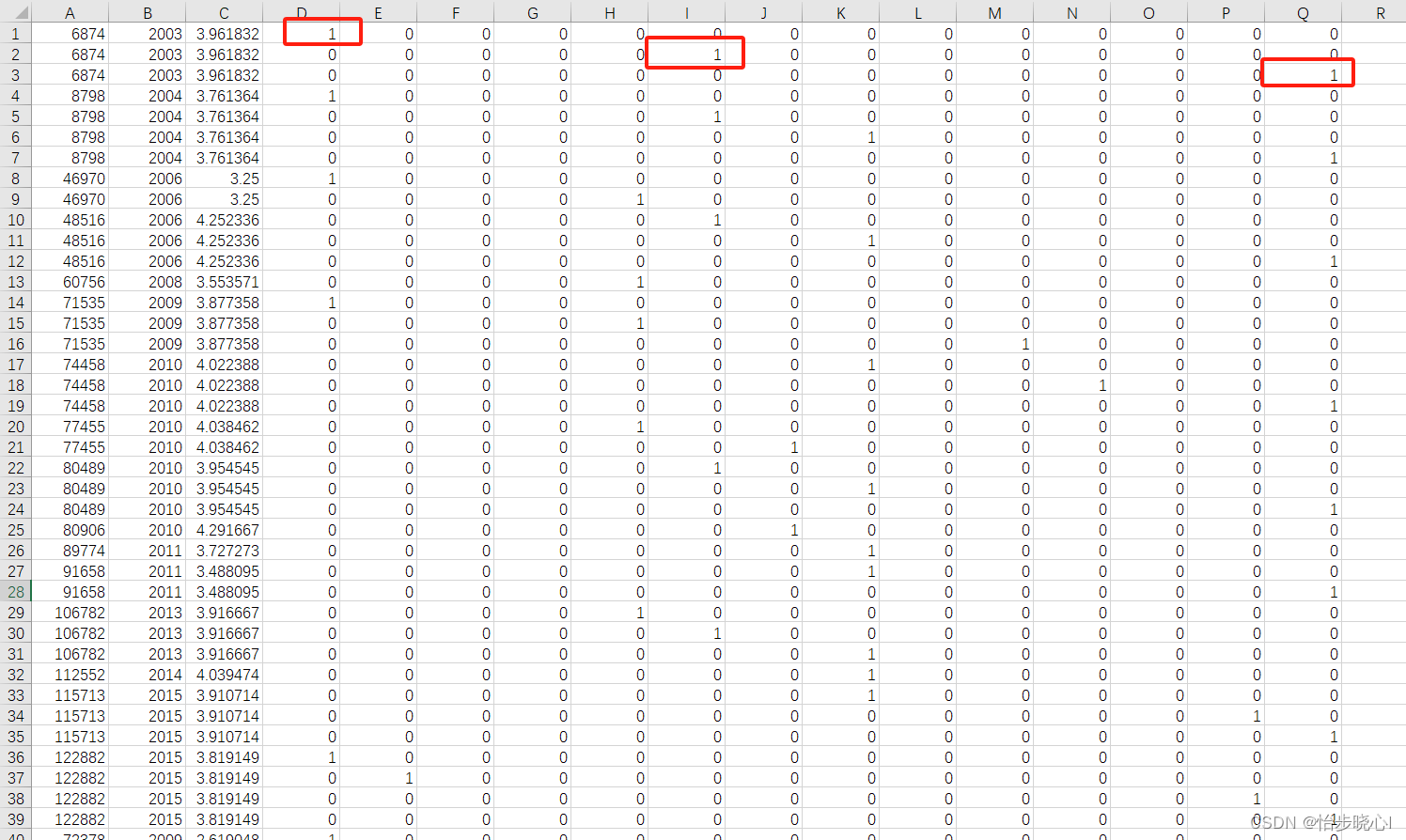
content_item_train.csv中的电影会有重复,毕竟可能不同用户都给同一电影打分,因此6874除了第一行有第474行也有,这么设计只是为了查找时方便对应,但是训练速度估计比较着急。

content_item_vecs.csv这里面存储的也是电影的相关原始特征,但是其不会出现上面的重复,因为其不需要和用户对应且电影id递增排列。
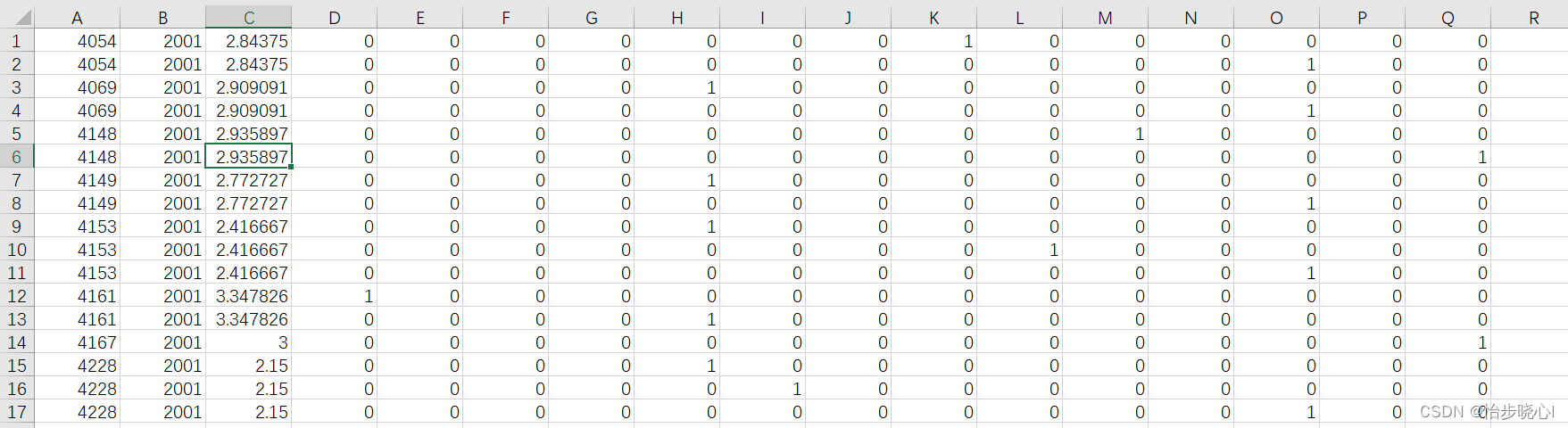
content_movie_list.csv这里面是id所对应的实际电影:
3、基于内容的过滤算法实现步骤
STEP1: 引入包并加载数据集(不考虑用户ID、评分次数和平均评分、电影ID,所以需要移除部分数据):
from keras import Model
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from Content_Based_Filtering_recsysNN_utils import *
pd.set_option("display.precision", 1)# 加载数据,设置配置变量
item_train, user_train, y_train, item_features, user_features, item_vecs, movie_dict, user_to_genre = load_data()
# 计算用户特征的数量,训练时移除用户ID、评分次数和平均评分
num_user_features = user_train.shape[1] - 3
# 计算物品特征的数量,训练时移除电影ID
num_item_features = item_train.shape[1] - 1
# 用户向量的起始位置
uvs = 3
# 物品向量的起始位置
ivs = 3
# 在训练中使用的用户列的起始位置
u_s = 3
# 在训练中使用的物品列的起始位置
i_s = 1
STEP2: 数据标准化与测试集的分割:
# 如果为True,则对数据应用标准化
scaledata = True
# 归一化训练数据
if scaledata:# 保存原始的item_train和user_train数据item_train_save = item_trainuser_train_save = user_train# 对item_train数据进行标准化处理scalerItem = StandardScaler()scalerItem.fit(item_train)item_train = scalerItem.transform(item_train)# 对user_train数据进行标准化处理scalerUser = StandardScaler()scalerUser.fit(user_train)user_train = scalerUser.transform(user_train)# 对y_train数据进行归一化处理,使其值在-1到1之间scaler = MinMaxScaler((-1, 1))scaler.fit(y_train.reshape(-1, 1))y_train = scaler.transform(y_train.reshape(-1, 1))# 使用train_test_split函数将数据集分割为训练集和测试集,其中训练集占比为80%
item_train, item_test = train_test_split(item_train, train_size=0.80, shuffle=True, random_state=1)
user_train, user_test = train_test_split(user_train, train_size=0.80, shuffle=True, random_state=1)
y_train, y_test = train_test_split(y_train, train_size=0.80, shuffle=True, random_state=1)# 打印训练集和测试集的形状
print(f"movie/item training data shape: {item_train.shape}")
print(f"movie/item test data shape: {item_test.shape}")STEP3: 模型构建与训练(其中特征数量num_outputs 指的是训练最终得到的特征数量,即Vu和Vm的维度,理论上可以随意选取):
# 构建模型
# 输出的电影特征和用户特征数量,都是32
num_outputs = 32
tf.random.set_seed(1) # 设置随机种子以确保结果的可复现性 # 定义用户神经网络
user_NN = tf.keras.models.Sequential([ tf.keras.layers.Dense(256, activation='relu'), # 第一层有256个神经元,使用ReLU激活函数 tf.keras.layers.Dense(128, activation='relu'), # 第二层有128个神经元,使用ReLU激活函数 tf.keras.layers.Dense(num_outputs), # 输出层有32个神经元
]) # 定义物品神经网络
item_NN = tf.keras.models.Sequential([ tf.keras.layers.Dense(256, activation='relu'), # 第一层有256个神经元,使用ReLU激活函数 tf.keras.layers.Dense(128, activation='relu'), # 第二层有128个神经元,使用ReLU激活函数 tf.keras.layers.Dense(num_outputs), # 输出层有32个神经元
]) # 创建用户输入并连接到基础网络
input_user = tf.keras.layers.Input(shape=(num_user_features)) # 定义用户输入层
vu = user_NN(input_user) # 将用户输入传入用户神经网络
vu = tf.linalg.l2_normalize(vu, axis=1) # 对用户向量进行L2正则化 # 创建物品输入并连接到基础网络
input_item = tf.keras.layers.Input(shape=(num_item_features)) # 定义物品输入层
vm = item_NN(input_item) # 将物品输入传入物品神经网络
vm = tf.linalg.l2_normalize(vm, axis=1) # 对物品向量进行L2正则化 # 计算两个向量vu和vm的点积
output = tf.keras.layers.Dot(axes=1)([vu, vm]) # 计算点积作为输出 # 指定模型的输入和输出
model = Model([input_user, input_item], output) # 定义模型
model.summary() # 打印模型概要 # 设置模型的优化器和损失函数
tf.random.set_seed(1)
cost_fn = tf.keras.losses.MeanSquaredError() # 使用均方误差作为损失函数
opt = keras.optimizers.Adam(learning_rate=0.01) # 使用Adam优化器,学习率为0.01
model.compile(optimizer=opt, loss=cost_fn) # 编译模型 # 训练模型
tf.random.set_seed(1)
model.fit([user_train[:, u_s:], item_train[:, i_s:]], y_train, epochs=20) # 对模型进行20轮训练 # 评估模型在测试集上的表现
model.evaluate([user_test[:, u_s:], item_test[:, i_s:]], y_test) # 计算模型在测试集上的损失值
STEP4: 基于模型的新用户最佳推荐
首先要构建新用户的特征:
# 给新用户推荐
new_user_id = 5000
new_rating_ave = 1.0
new_action = 5
new_adventure = 1
new_animation = 1
new_childrens = 5
new_comedy = 1
new_crime = 5
new_documentary = 1
new_drama = 1
new_fantasy = 1
new_horror = 1
new_mystery = 1
new_romance = 1
new_scifi = 5
new_thriller = 1
new_rating_count = 1user_vec = np.array([[new_user_id, new_rating_count, new_rating_ave,new_action, new_adventure, new_animation, new_childrens,new_comedy, new_crime, new_documentary,new_drama, new_fantasy, new_horror, new_mystery,new_romance, new_scifi, new_thriller]])
下面是基于新用户特征、所有的电影特征和现有模型进行预测:
# generate and replicate the user vector to match the number movies in the data set.
user_vecs = gen_user_vecs(user_vec,len(item_vecs))# 进行预测并按照推荐程度进行排序
sorted_index, sorted_ypu, sorted_items, sorted_user = predict_uservec(user_vecs, item_vecs, model, u_s, i_s,scaler, scalerUser, scalerItem, scaledata=scaledata)
# 打印结果
print_pred_movies(sorted_ypu, sorted_user, sorted_items, movie_dict, maxcount = 10)
其中预测函数中需要先进行归一化,如何进行预测:
def predict_uservec(user_vecs, item_vecs, model, u_s, i_s, scaler, ScalerUser, ScalerItem, scaledata=False): """ 给定一个用户向量,对item_vecs中的所有电影进行预测,返回一个按预测评分排序的数组预测值, 以及按预测评分排序索引排序的用户和物品数组。 """ # 判断是否需要缩放数据 if scaledata: # 如果需要缩放,则使用ScalerUser和ScalerItem对user_vecs和item_vecs进行缩放 scaled_user_vecs = ScalerUser.transform(user_vecs) scaled_item_vecs = ScalerItem.transform(item_vecs) # 使用缩放后的数据进行预测 y_p = model.predict([scaled_user_vecs[:, u_s:], scaled_item_vecs[:, i_s:]]) else: # 如果不需要缩放,则直接使用原始数据进行预测 y_p = model.predict([user_vecs[:, u_s:], item_vecs[:, i_s:]]) # 使用scaler对预测结果进行逆变换 y_pu = scaler.inverse_transform(y_p) # 检查预测结果中是否有负数,如果有则打印错误信息 if np.any(y_pu < 0): print("Error, expected all positive predictions") # 对预测结果进行排序,获取排序索引,并按照排序索引对预测结果、物品和用户进行排序 sorted_index = np.argsort(-y_pu, axis=0).reshape(-1).tolist() # 取反以获得最高评分在前 sorted_ypu = y_pu[sorted_index] sorted_items = item_vecs[sorted_index] sorted_user = user_vecs[sorted_index] # 返回排序索引、排序后的预测结果、排序后的物品和用户 return (sorted_index, sorted_ypu, sorted_items, sorted_user)4、结果分析
按照我给出的新用户的特性:action、childrens、crime、scifi是其比较喜欢的,推荐的排名前十的电影如下:
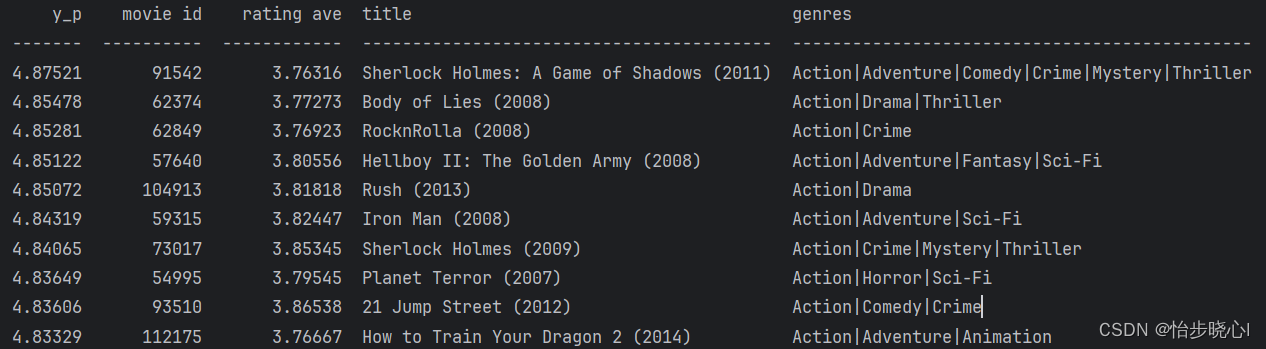
可以看到其推荐的东西也比较符合这些特征。
相关文章:
06、基于内容的过滤算法Tensorflow实现
06、基于内容的过滤算法Tensorflow实现 开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。全部工程可从最上方链接下载。 05、基于梯度下降的协同过滤算法中已经介绍了协同过滤算法的基本实现方法,但是这种方法仅…...
html/css中用float实现的盒子案例
运行效果: 代码部分: <!doctype html> <html> <head> <meta charset"utf-8"> <title>无标题文档</title> <style type"text/css">.father{width:300px; height:400px; background:gray;…...
simulink中 Data store memory、write和read模块及案例介绍
目录 1.Data store memory模块 2.data store write模块 3.data store read模块 4.仿真分析 4.1简单使用三个模块 4.2 模块间的调用顺序剖析 1.Data store memory模块 向右拖拉得到Data store read模块,向左拉得到Data write模块 理解:可视为定义变量…...
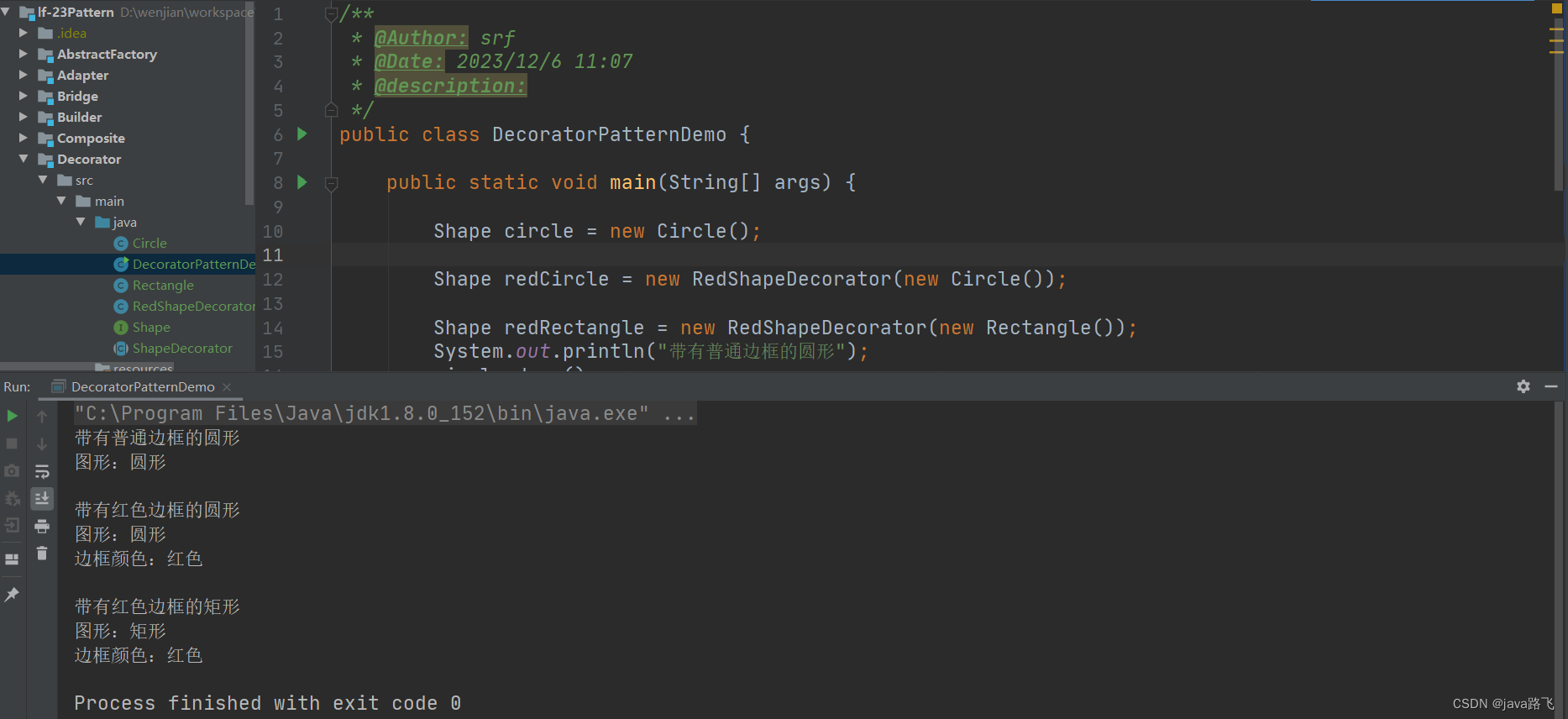
java设计模式学习之【装饰器模式】
文章目录 引言装饰器模式简介定义与用途实现方式 使用场景优势与劣势装饰器模式在Spring中的应用画图示例代码地址 引言 在日常生活中,我们常常对基本事物添加额外的装饰以增强其功能或美观。例如,给手机加一个保护壳来提升其防护能力,或者在…...
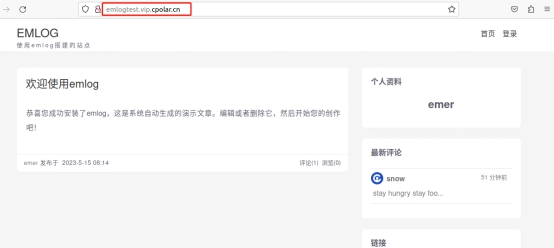
Ubuntu宝塔面板本地部署Emlog个人博客网站并远程访问【内网穿透】
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

简述IO流的使用以及使用时需要注意的事项
Hi i,m JinXiang ⭐ 前言 ⭐ 本篇文章主要介绍介绍IO流的使用以及使用时需要注意的事项以及部分理论知识 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主收将持续更新学习记录获,友友们有任何问题可…...
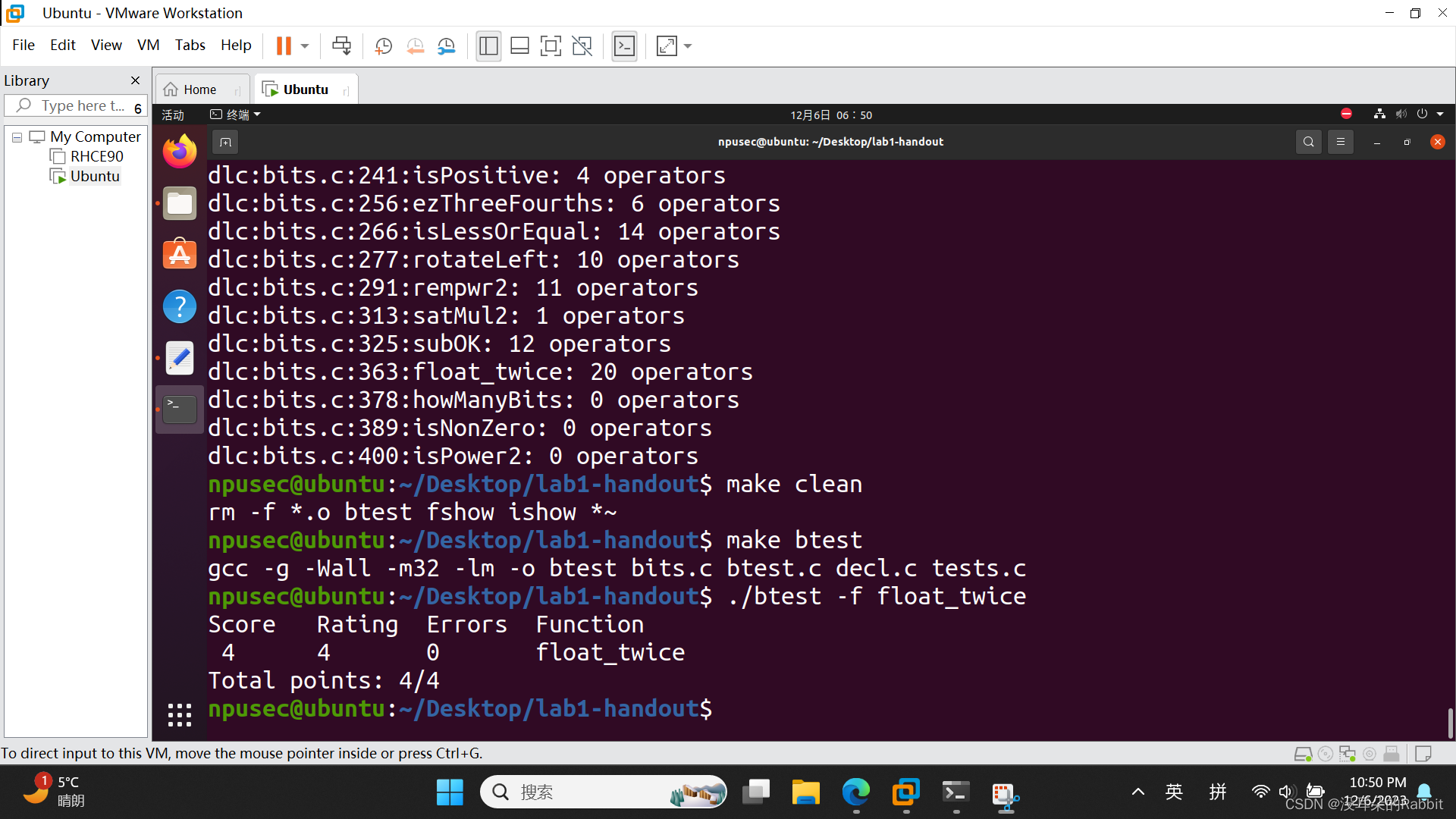
西工大计算机学院计算机系统基础实验一(函数编写11~14)
稳住心态不要慌,如果考试周冲突的话,可以直接复制这篇博客和上一篇博客西工大计算机学院计算机系统基础实验一(函数编写1~10)-CSDN博客最后的代码,然后直接提交,等熬过考试周之后回过头再慢慢做也可以。 第…...
Spring 声明式事务
Spring 声明式事务 1.Spring 事务管理概述1.1 事务管理的重要性1.2 Spring事务管理的两种方式1.2.1 编程式事务管理1.2.2 声明式事务管理 1.3 为什么选择声明式事务管理 2. 声明式事务管理2.1 基本用法2.2 常用属性2.2.1 propagation(传播行为)2.2.2 iso…...

通达OA inc/package/down.php接口存在未授权访问漏洞
声明 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 一. 产品简介 通达OA(Office Anywhere网络智能办公系统&am…...

数据库原理: 笛卡儿积
笛卡儿积(Cartesian Product)是集合论中的一个概念,也在数据库中的查询操作中经常使用。笛卡儿积是指两个集合(或更多集合)之间所有可能的组合。如果有两个集合A和B,它们的笛卡儿积记作A B,表示…...
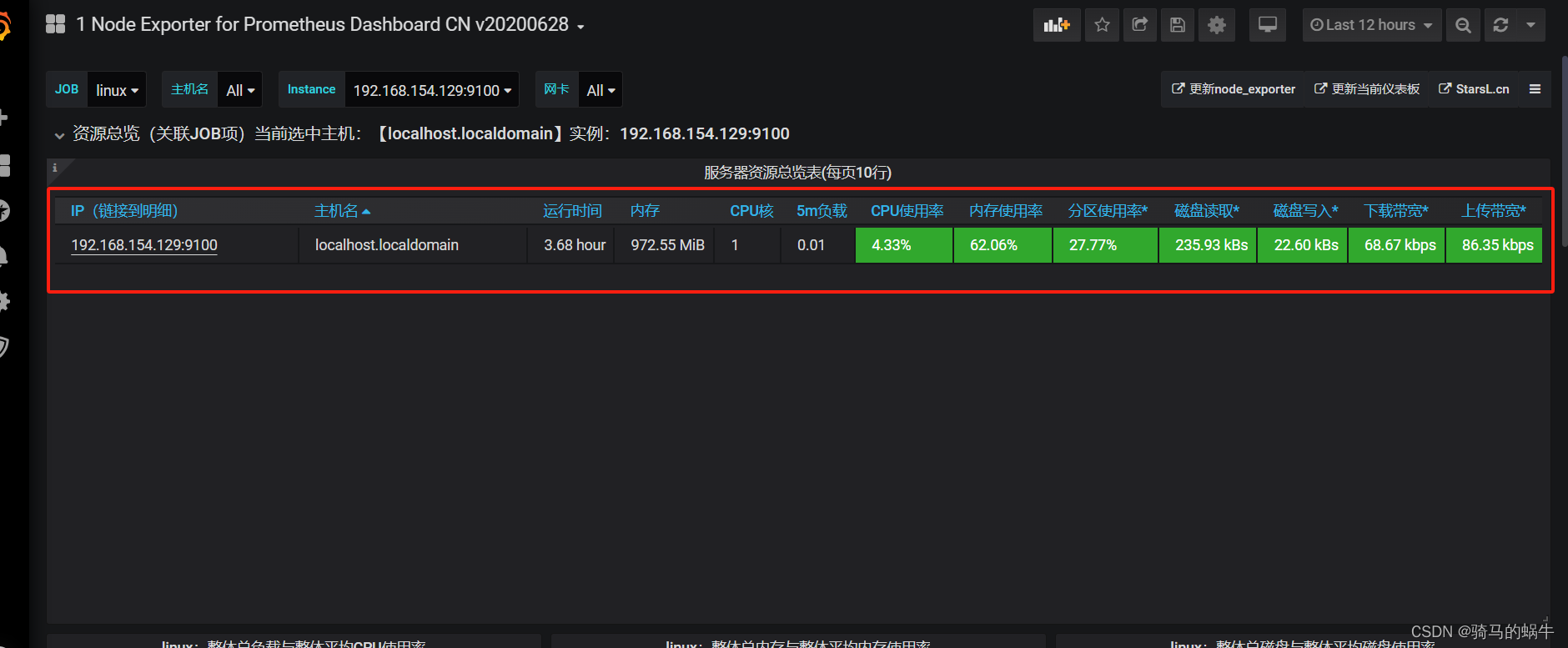
docker安装配置prometheus+node_export+grafana
简介 Prometheus是一套开源的监控预警时间序列数据库的组合,Prometheus本身不具备收集监控数据功能,通过获取不同的export收集的数据,存储到时序数据库中。Grafana是一个跨平台的开源的分析和可视化工具,将采集过来的数据实现可视…...
【JavaScript】JS——Map数据类型
【JavaScript】JS——Map数据类型 什么是Map?特性Map与Object的比较 map的创建map的属性map相关方法map的遍历 什么是Map? 存储键值对的对象。 能够记住键的原始插入顺序任何值(对象或原始值)都可以作为键或值。 特性 Map中的一个键只能出现一次&am…...
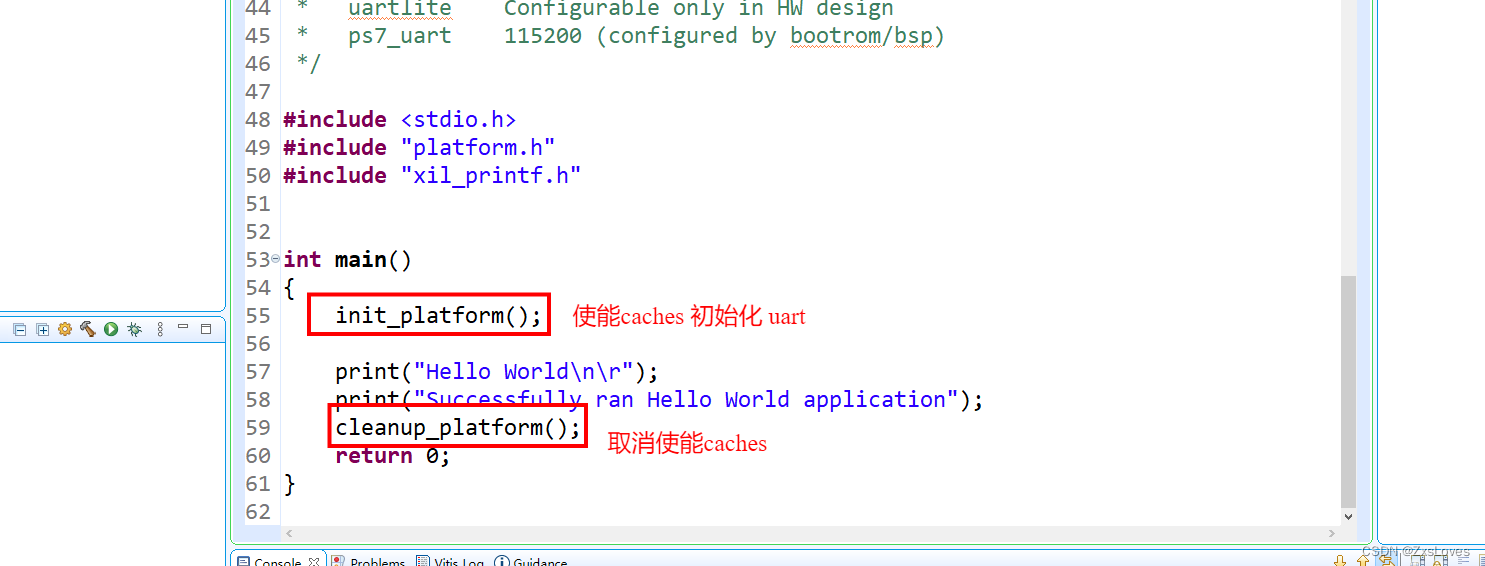
【【FPGA的 MicroBlaze 的 介绍与使用 】】
FPGA的 MicroBlaze 的 介绍与使用 可编程片上系统(SOPC)的设计 在进行系统设计时,倘若系统非常复杂,采用传统 FPGA 单独用 Verilog/VHDL 语言进行开发的方式,工作量无疑是巨大的,这时调用 MicroBlaze 软核…...

PyQt pdf格式保存
参考文章 pyqt5:利用QFileDialog从本地选择图片\文本文档显示到label、保存图片\label文本到本地(附代码)_pyqt5中qfiledialog.getopenfileurl-CSDN博客 txt文件的打开与保存 def openTextFile(self): # 选择文本文件上传fd,fp QFileDialog.getOpen…...

微前端介绍
目录 微前端概念 微前端特性 场景演示 微前端方案 iframe 方案 qiankun 方案 micro-app 方案 EMP 方案 无界微前端 方案 无界方案 成本低 速度快 原生隔离 功能强大 总结 前言:微前端已经是一个非常成熟的领域了,但开发者不管采用哪个现…...
使用说明书(一,轻量级的visionpro))
工业机器视觉megauging(向光有光)使用说明书(一,轻量级的visionpro)
机器视觉megauging(未名之光,向光有光)程序软件资源已经发布,欢迎下载尝新 8:11 2023/12/2 首先,既然觉得可以发表了,就发表。 其次,我这个人没写过什么软件使用说明书,既然走到这路…...

Java——面试:String 和 StringBuffer 的区别?
相同点: String 和 StringBuffer,它们可以储存和操作字符串, 即包含多个字符的字符数据。 String 和 StringBuffer 的区别有以下几点: 1.String 类提供了数值不可改变的字符串。而 StringBuffer 类提供的字符串进行修改。 当你知…...

图扑软件受邀出席高交会-全球清洁能源创新博览会
“相聚鹏城深圳,共享能源盛宴” 第二十五届中国国际高新技术成果交易会(简称“高交会”)于 11 月 15-18 日在深圳盛大开幕。高交会由商务部、科学技术部、工业和信息化部、国家发展改革委、农业农村部、国家知识产权局、中国科学院、中国工程院和深圳市人民政府共同…...
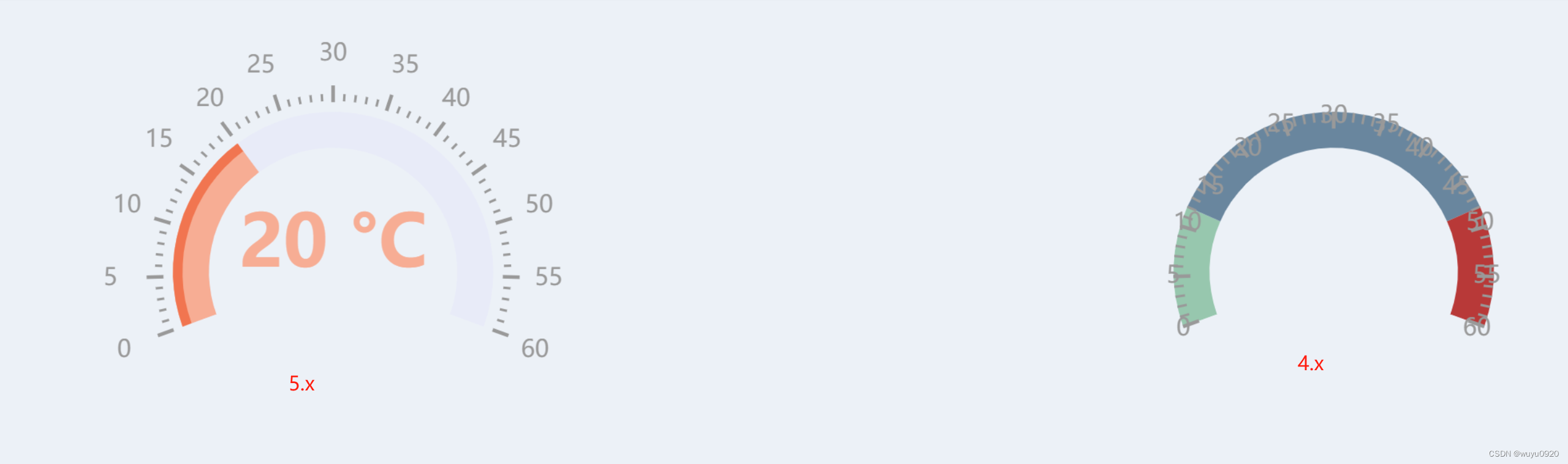
vue项目下npm或yarn下安装echarts多个版本
最近在大屏展示的时候,用到了百度的echarts图表库,看完效果图后,又浏览了一下echarts官网案例,大同小异。但是搬砖过程中发现实际效果和demo相差甚远,一番折腾发现,项目中安装的是echarts4.x版本࿰…...

在内网开发中使用Nginx代理来访问钉钉新版服务端API
如果你在内网开发中使用Nginx代理来访问钉钉新版服务端API,你可以在Nginx配置文件中进行相应的配置。 以下是一个简单的示例Nginx配置,用于将对指定URL的请求代理到钉钉服务端API: server { listen 80; server_name your_server_domain; l…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...