强化学习——简单解释
一、说明
最近 OpenAI 上关于 Q-star 的热议激起了我温习强化学习知识的兴趣。这是为强化学习 (RL) 新手提供的复习内容。
二、强化学习的定义
强化学习是人类和其他动物用来学习的学习类型。即,通过阅读房间来学习。(从反馈中学习)。让我解释。
作为一个幼儿,你正在积极地探索你的环境,在这个探索过程中,你采取一些行动,例如,你尝试站起来,你尝试爬行,行走,接触火,吞下泥土,(在那个年龄,我们尝试吞下一切)。我们微笑并做出可爱的鬼脸,这给我们带来了父母的拥抱和微笑的回报。我们可能会大喊大叫、发脾气,这会让我们的父母生气,甚至会导致我们暂停、延迟玩游戏。因此,我们通过我们的行动收到的反馈来学习。这就是你教你的狗行为举止的方式。通过奖励来强化其良好行为,并通过“Nooooo”来阻止不良行为。

来源: https: //www.wikihow.com/Teach-Your-Dog-to-Speak
强化学习 (RL) 是机器学习 (ML) 的一种,涉及从环境收到的反馈进行学习,而不是从标记数据(如监督学习)或数据的固有属性(如无监督学习)中学习。
三、强化学习框架
强化学习框架涉及多个方面。让我们一一看看:
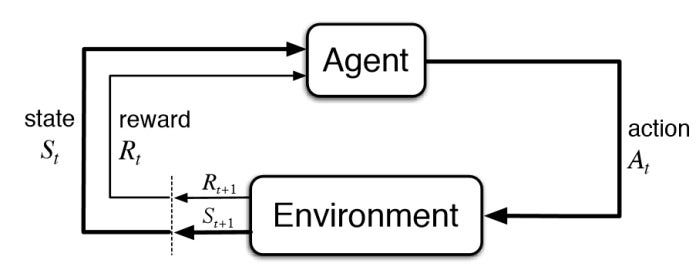
强化学习框架的重要元素来源:强化学习:简介,Richard Sutton 和 Andrew G. Barto
代理人——行动者或决策者
在强化学习中,学习者被称为“代理”。代理可以是一个软件,也可以是软件和硬件的组合,例如机器人。学习任务中可能有一个或多个代理。
环境——周围环境或代理人的世界
代理驻留在“环境”中并在其中导航。“环境”是指与代理交互的外部系统或周围环境。
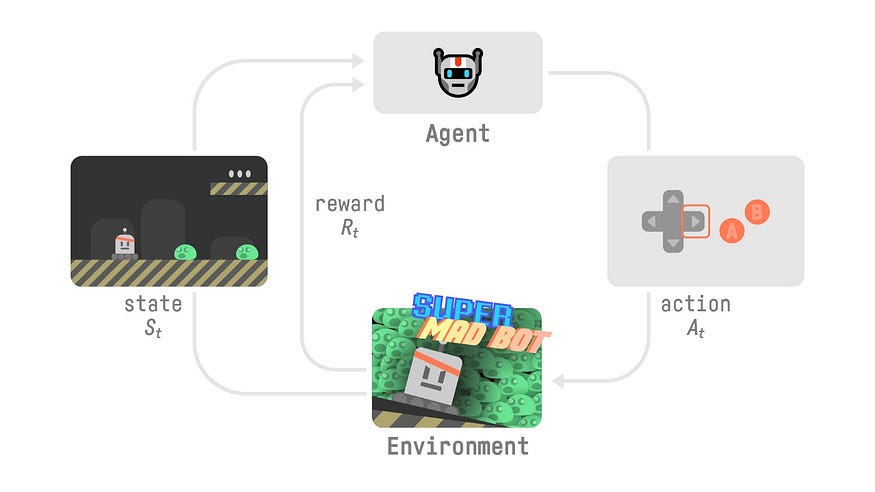
来源:抱脸深度强化学习课程
环境状况
在任何时候,代理都可以查看完整的配置或其环境的状态。(例如,游戏特定阶段的完整棋盘的快照)。
在某些强化学习任务中,代理无法看到其环境的整个配置,只能看到其中的一部分(例如,在超级马里奥游戏中,代理(即玩家)无法看到整个环境,只能看到其中的一部分在特定时间。)在这种情况下,我们说智能体看到了来自环境的观察结果。
报酬
奖励是智能体在采取行动后从环境收到的反馈。奖励是一个数字。代理的目标是积累最大的累积奖励。
价值
价值是智能体从处于特定环境状态并采取特定行动时获得的累积长期奖励。因此,强化学习代理的目标是最大化其价值。
折扣未来奖励
对于我们人类来说,有即时的满足感,也有长期的价值。同样,对于 RL 代理来说,它在环境状态下采取行动后会立即收到奖励。并且它期望通过未来采取的行动获得累积的未来奖励(其行动的长期后果(业力,你看)。
RL 中的折扣因子(Gamma , γ)平衡即时奖励与未来奖励。它通过确定未来奖励的权重来帮助智能体决定在任何状态下采取哪些行动。
状态转移概率
状态转换概率是当智能体采取特定动作时从环境的一种状态转移到另一种状态的概率。在这里,我们需要谈谈强化学习中的确定性和随机环境。
确定性环境是指代理在特定状态下只能采取一个预先确定的操作,并且该操作会将您引导到预先确定的下一个状态。例如,如果你当前的状态是你在学校,那么唯一可能的行动就是学习。
随机环境是代理可以选择采取多种可能行动之一的环境。每个动作都有一个代理执行的相关概率。例如,你在学校,你有 90% 的概率可以学习,你有 5% 的概率可以做运动,你有 5% 的概率可以和朋友聊天。在随机环境中,状态之间的转换存在不确定性或随机性。
表示为P ( s '∣ s , a ) 的状态转换概率是在智能体当前处于状态s并采取动作a 的情况下转换到状态 ' s ' 的概率。该概率函数捕获特定 RL 任务中代理环境的动态。
马尔可夫性质
在强化学习中,我们假设状态表现出马尔可夫性质。马尔可夫性质意味着系统的未来状态仅取决于当前状态和操作,而不取决于之前的事件顺序。这使得对状态转换建模变得更加容易。
状态值函数 (V(s))
状态价值函数V ( s ) 计算代理可以从给定状态s并采取后续行动中获得的预期累积奖励(回报或价值)。即,它衡量代理的状态价值。
动作值函数 (Q(s, a))
动作价值函数Q ( s , a ) 计算智能体从处于状态s、采取动作a,然后遵循特定的动作序列(策略)可以获得的预期累积奖励(回报或价值) 。它衡量在给定状态下采取特定行动的质量。
价值函数和行动价值函数帮助智能体决定进入什么状态以及采取什么行动来最大化其整体奖励。
四、笔记
成功的代理人是实现其目标的代理人。代理的目标是最大化其长期奖励(价值/回报)。为了实现其目标,智能体需要学习在其环境中的每个连续状态下采取最佳行动(一系列最佳/最佳行动)。最佳的行动序列是最大化累积奖励的行动序列。因此,RL 的重点是让智能体了解每一步要采取什么行动来实现其目标。关于每一步要采取什么行动的知识称为策略。
政策
策略(π)定义了代理用来决定在不同状态下采取哪些操作的策略或规则。它本质上是从状态到动作的映射。有两种类型的政策:
- 确定性策略 ( π ( s )→ a ):在确定性策略中,对于每个状态,该策略精确指定要采取的一个操作。
- 随机策略 ( π ( a ∣ s )):在随机策略中,对于每个状态,该策略定义了许多可能操作的概率分布。
状态价值函数和行动价值函数经常用于 Q-learning 和 SARSA 等算法中,而策略在 RL 中的策略梯度方法和行动者批评方法中发挥着核心作用。
代理必须在其环境中学习自身的最优策略。即,它需要学习在不同环境状态下的多个时间步长采取的最佳行动顺序。
“学习”是指学习如何就在环境中采取什么行动做出正确的决策顺序。这种学习是通过从环境收到的反馈与环境交互来实现的。
从命中和尝试开始,智能体采取行动,如果行动好,智能体会收到奖励形式的反馈,如果行动不好,智能体会受到环境的惩罚。代理的目标是最大化其累积奖励。这很像一个幼儿通过跌倒和爬起来来学习走路。或者一只狗从父母的对待或责骂中学习表现良好。
其中心思想是让代理探索其环境,从其行为的后果中学习,并调整其行为以实现特定目标。
因此,代理可以从随机策略开始,随机采取任何可能的动作,然后根据获得的奖励的比较,下次调整其策略。迭代细化一直持续到智能体学会了最佳的动作序列,从而在其环境中获得最大的奖励。(政策优化)。
解决强化学习问题的两种方法是基于策略的方法和基于价值的方法。
在基于策略的方法中,代理学习针对每种环境状态的一组可能操作的概率分布。在基于价值的方法中,代理学习一个价值函数,该函数将状态映射到该状态的期望值,然后根据贪婪策略采取行动(进入最高价值的状态)。
政策迭代
策略迭代是一种用于寻找最优策略的迭代方法。关键思想是交替执行两个步骤:政策评估和政策改进。
政策评估
- 在策略评估步骤中,评估当前策略以估计其值(Vπ),即当前策略下每个状态的预期回报。此步骤涉及迭代更新状态值,直到它们收敛到准确表示当前政策下每个状态的预期回报的稳定值。
政策改进:
- 在策略改进步骤中,策略被更新为相对于当前价值函数更加贪婪。考虑到在策略评估步骤中获得的估计值,选择每个状态的操作以最大化预期回报。然后将更新后的策略用于下一轮策略评估,并重复该过程。
策略迭代将持续进行,直到策略在策略改进步骤中不再发生变化。至此,国家价值观和政策已经收敛到最优值。
五、基于模型和无模型的强化学习
有两种不同的方法来学习代理的最佳策略,具体取决于代理是否具有环境模型。
基于模型的强化学习
在基于模型的强化学习中,代理构建环境的内部模型(马尔可夫决策过程,MDP)。该模型包括有关环境中可用状态、代理可能采取的操作、状态转换概率、奖励函数、未来奖励的折扣因子的信息。代理使用其学习的模型来模拟未来可能的场景,并根据这些模拟来计划其行动。代理通过根据其内部模型选择预计会产生有利结果的行动来做出决策。模型中的不准确可能会导致性能不佳。
无模型强化学习:
在无模型强化学习中,代理直接与环境交互,无需显式构建模型。代理不是学习环境的动态,而是通过反复试验来学习策略(策略)或价值函数(预期累积奖励)。
无模型强化学习的关键步骤包括:
- 探索:智能体通过采取行动来探索环境并观察结果。
- 策略或价值函数学习:代理学习将行为与期望的结果关联起来,而无需显式地对环境进行建模。这可能涉及 Q 学习、SARSA 或策略梯度方法等技术。
- 适应:代理根据观察到的奖励调整其策略,不断改进其决策。
无模型强化学习在处理复杂和未知的环境方面更加灵活,但可能需要更多的探索才能发现有效的策略。
这些方法之间的选择通常取决于问题的特征以及环境的准确模型的可用性。
时间差分学习(TD Learning)
时间差分(TD)学习用于训练智能体在动态环境中做出决策。它是一种无模型强化学习,代理可以从其经验中学习,而不需要环境模型。TD 学习涉及根据未来奖励的预测值和观察值之间的差异来更新价值估计。
预测值是学习算法对某些状态或状态-动作对估计的值( V(s)或Q(s,a ))。真正的价值是通过与环境的相互作用获得的。在某个状态采取行动后,代理会收到奖励并转换到新状态。观察到的奖励和结果状态构成了真实值。学习算法通过将预测与实际结果进行比较来调整其预测,旨在随着时间的推移减少差异并改进决策。
时间差异误差是预测值与真实值之间的差异,用于迭代更新预测值。更新基于当前时间步的预测值与观察到的奖励和下一时间步的预测值的组合之间的差异。
例如,在 TD(0) 学习中,状态值函数V ( st ) 的更新公式可能如下所示:V ( st )← V ( st )+ α [ Rt +1+ γV ( st +1)− V ( st )] 这里,α是学习率,Rt +1是观察到的奖励,γ是折扣因子,V ( st +1) 是下一个状态的预测值。
六、Q-学习
Q-learning 是一种无模型 RL 算法,用于为给定的有限马尔可夫决策过程 (MDP) 寻找最优策略(为智能体提供最大奖励的策略)。Q-learning 首先估计在特定状态下采取特定行动的质量,并根据观察到的奖励更新这些估计。该算法是离策略的,这意味着它在遵循另一个(探索性)策略的同时学习单独的策略(Q 函数)。
Q-learning的更新规则为:
Q ( s , a )← Q ( s , a )+ α [ R + γ max a Q ( s ′, a )− Q ( s , a )]
这里,Q ( s , a ) 是在状态s下采取动作a的估计质量,R是观察到的奖励,γ是折扣因子,s ' 是下一个状态,α是学习率。
深度 Q 学习(深度 Q 网络 (DQN))
深度 Q 网络将 Q 学习与深度神经网络(深度 Q 学习)相结合,使算法能够处理具有大量状态的 RL 环境,例如图像。DQN 使用神经网络来近似 Q 函数。DQN 使用经验重放,其中过去的经验存储在重放缓冲区中,并在训练期间随机采样以打破数据中的相关性。
DQN中的损失函数定义为:
损失=E[( Q ( s , a )−( R + γ max a ′ Q ( s ′, a ′)))2]
网络经过训练,可以通过调整其参数来最小化这种损失。
Q*(Q 星)
Q*旨在找到最优动作价值函数Q*(s, a),它表示在状态“s”下采取动作“a”然后遵循最优策略可以获得的最大预期累积奖励。
SARSA(状态-行动-奖励-行动-状态)
SARSA 是另一种无模型强化学习算法。与 Q-learning 不同,SARSA 是一种在策略算法,这意味着它可以学习当前正在使用的策略的价值。
SARSA的更新规则是:
Q ( s , a )← Q ( s , a )+ α [ R + γQ ( s ' , a ' )− Q ( s , a )]
这里,Q ( s , a ) 是在状态s下采取动作a的估计质量,R是观察到的奖励,s ' 是下一个状态,a ' 是下一个动作,γ是折扣因子,α是学习率。
策略梯度法
策略梯度方法是一类直接学习策略的强化学习算法。与旨在估计价值函数(状态值或行动值)的基于价值的方法不同,策略梯度方法直接参数化策略并更新其参数以最大化预期累积奖励。
在策略梯度方法中,策略由一组由神经网络表示的可学习参数参数化。该策略将状态作为输入并输出动作的概率分布。随着时间的推移,对参数进行调整以提高策略的性能。
目标函数是需要最大化的奖励总和的期望值。
计算相对于策略参数的预期累积奖励的梯度。该梯度用于更新策略参数,以增加导致更高奖励的行动的可能性。策略优化是通过梯度上升来执行的,即更新策略参数以朝着增加预期回报的配置移动。
为了防止过早收敛到次优策略并鼓励探索更多样化的行动空间,在目标函数中添加了与策略分布的负熵成比例的项。它被称为熵正则化。
REINFORCE算法是一种经典的策略梯度方法,它使用似然比技巧来估计预期回报的梯度。它按照梯度乘以与观察到的奖励相关的因子的比例更新策略参数。
演员批评家方法
Actor-Critic 方法结合了策略梯度和基于价值的方法的元素。这些算法有一个演员,它学习选择动作的策略,还有一个批评家,它评估这些动作或状态的价值。该行为者利用批评者的评估来指导其政策更新,旨在随着时间的推移改进决策。
Actor-Critic 方法的优点是观察到的回报(实际累积奖励)与批评者估计的值之间的差异。
Actor-Critic方法中的目标函数是Actor的策略梯度和Critic的价值函数的组合。更新参与者以最大化预期累积奖励,更新批评者以最小化其估计与观察到的回报之间的均方误差。Actor 使用策略梯度方法进行更新,例如 REINFORCE。更新与参与者参数的预期回报梯度成正比,并按优势缩放。批评者使用时间差(TD)学习进行更新。
七、强化学习的应用
强化学习的概念可以应用于解决游戏、机器人和自动化等各个领域的问题,从而提高 ChatGPT 等大型语言模型的性能。
有一些特定的框架和算法用于实现和训练 RL 模型,例如 Q 学习、深度 Q 网络 (DQN)、策略梯度方法等。这些算法提供了计算机制,使代理能够从经验中学习并提高决策能力。
这是对强化学习的过于简单化的介绍。强化学习有着巨大的应用。请查看参考资料中的详细学习资料。
- 强化学习:简介,Richard Sutton 和 Andrew G Barto,Sutton & Barto Book: Reinforcement Learning: AnIntroduction
- David Sliver 的强化学习课程Teaching - David Silver
- 斯坦福大学强化学习课程: https: //web.stanford.edu/class/cs234/
- 深度 RL 拥抱脸部课程:https://huggingface.co/learn/deep-rl-course/unit0/introduction
- Deep Deterministic Policy Gradient — Spinning Up documentation
相关文章:
强化学习——简单解释
一、说明 最近 OpenAI 上关于 Q-star 的热议激起了我温习强化学习知识的兴趣。这是为强化学习 (RL) 新手提供的复习内容。 二、强化学习的定义 强化学习是人类和其他动物用来学习的学习类型。即,通过阅读房间来学习。(从反馈中学习)。让我解…...
IoT DC3 是一个基于 Spring Cloud 全开源物联网平台 linux docker部署傻瓜化步骤
如有不了解可先参考我的另一篇文章本地部署:IoT DC3 是一个基于 Spring Cloud 的开源的、分布式的物联网(IoT)平台本地部署步骤 如有不了解可先参考我的另一篇文章本地部署: 1 环境准备: JDK 8 以上 docker 安装好 下载docker-compose-dev.yml 文件 执行基础环境docker安装 …...
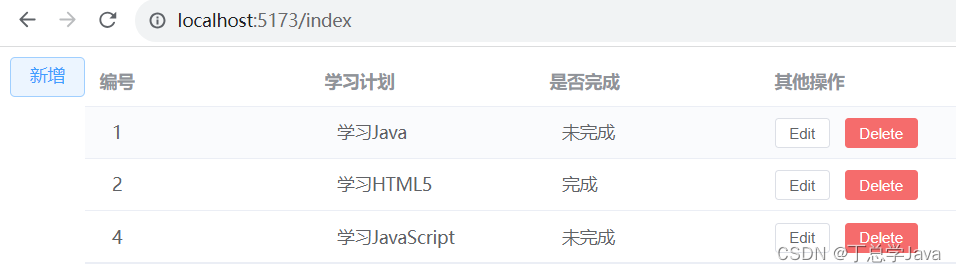
SSM项目实战-前端-在Index.vue中展示第一页数据
1、util/request.js import axios from "axios";let request axios.create({baseURL: "http://localhost:8080",timeout: 50000 });export default request 2、api/schedule.js import request from "../util/request.js";export let getSchedu…...

深入理解mysql的explain命令
1 基础 全网最全 | MySQL EXPLAIN 完全解读 1.1 MySQL中EXPLAIN命令提供的字段包括: id:查询的标识符。select_type:查询的类型(如SIMPLE, PRIMARY, SUBQUERY等)。table:查询的是哪个表。partitions&…...
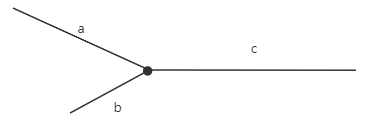
相交链表(LeetCode 160)
文章目录 1.问题描述2.难度等级3.热门指数4.解题思路方法一:暴力法方法二:哈希表方法三:双栈方法四:双指针:记录链表长度方法五:双指针:互换遍历 5.实现示例参考文献 1.问题描述 给两个单链表的…...
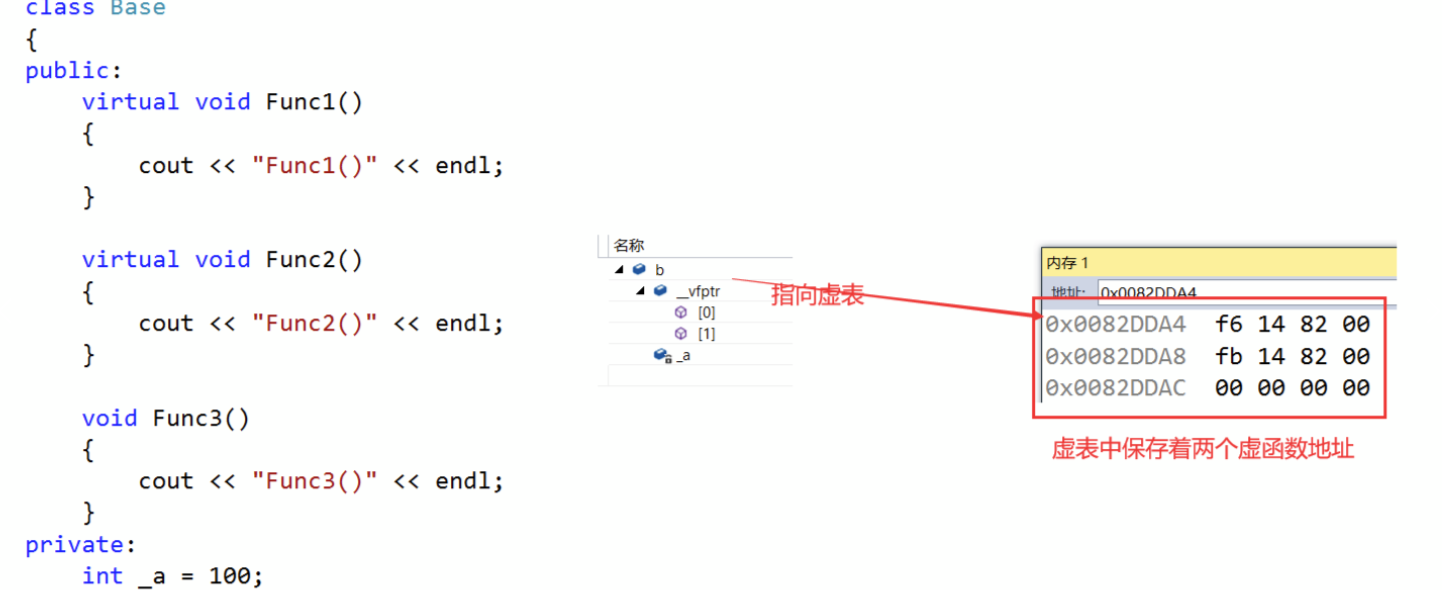
C++多态(详解)
一、多态的概念 1.1、多态的概念 多态:多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。 举个例子:比如买票这个行为,当普通人买票时,是全价买票;学生买票时&am…...
06、基于内容的过滤算法Tensorflow实现
06、基于内容的过滤算法Tensorflow实现 开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。全部工程可从最上方链接下载。 05、基于梯度下降的协同过滤算法中已经介绍了协同过滤算法的基本实现方法,但是这种方法仅…...
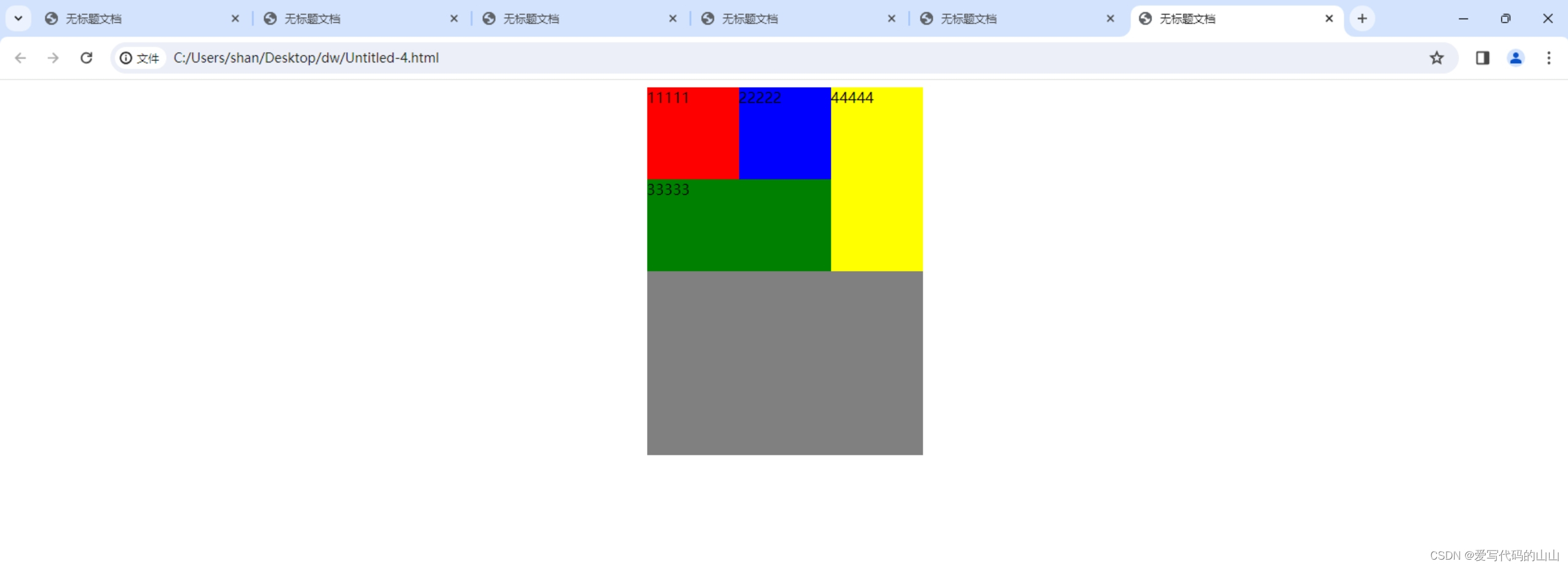
html/css中用float实现的盒子案例
运行效果: 代码部分: <!doctype html> <html> <head> <meta charset"utf-8"> <title>无标题文档</title> <style type"text/css">.father{width:300px; height:400px; background:gray;…...
simulink中 Data store memory、write和read模块及案例介绍
目录 1.Data store memory模块 2.data store write模块 3.data store read模块 4.仿真分析 4.1简单使用三个模块 4.2 模块间的调用顺序剖析 1.Data store memory模块 向右拖拉得到Data store read模块,向左拉得到Data write模块 理解:可视为定义变量…...
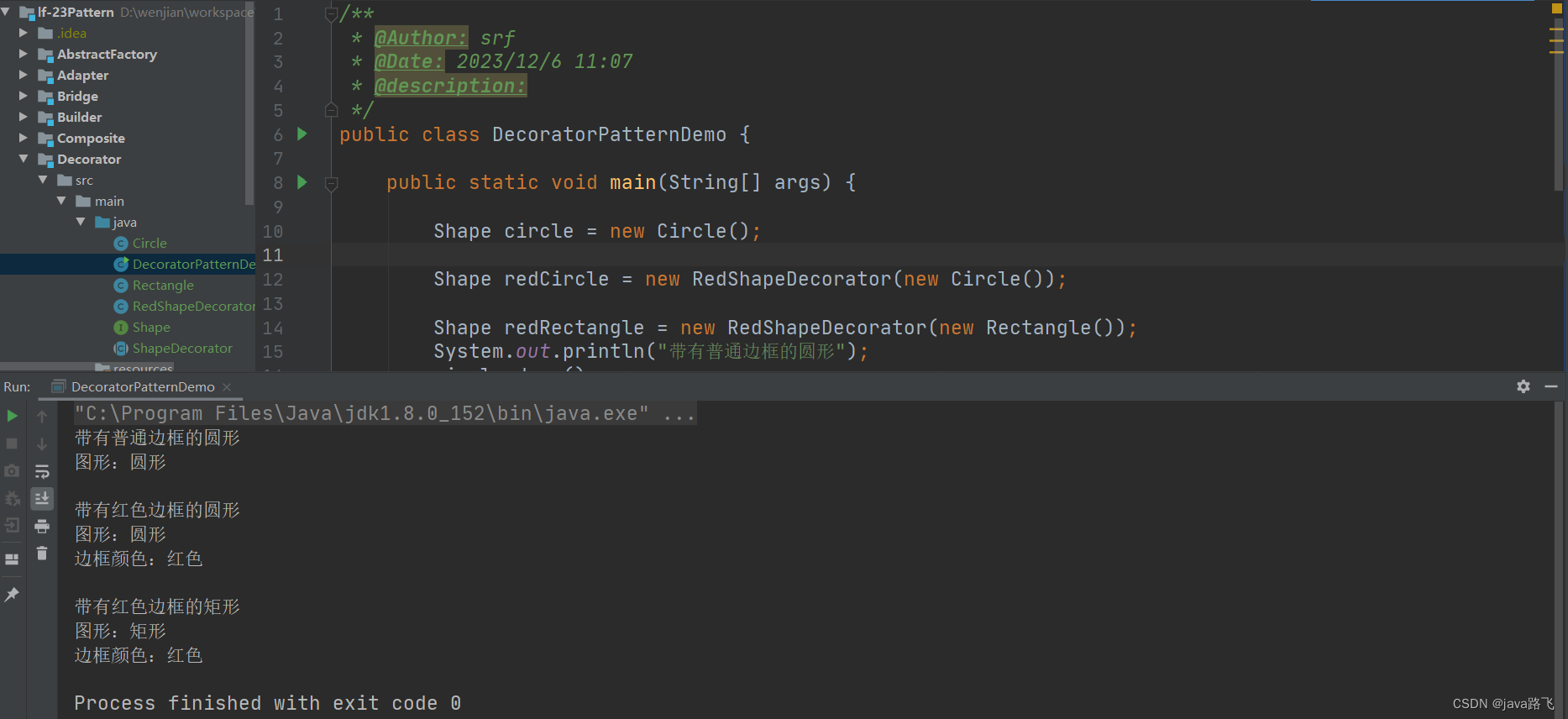
java设计模式学习之【装饰器模式】
文章目录 引言装饰器模式简介定义与用途实现方式 使用场景优势与劣势装饰器模式在Spring中的应用画图示例代码地址 引言 在日常生活中,我们常常对基本事物添加额外的装饰以增强其功能或美观。例如,给手机加一个保护壳来提升其防护能力,或者在…...
Ubuntu宝塔面板本地部署Emlog个人博客网站并远程访问【内网穿透】
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

简述IO流的使用以及使用时需要注意的事项
Hi i,m JinXiang ⭐ 前言 ⭐ 本篇文章主要介绍介绍IO流的使用以及使用时需要注意的事项以及部分理论知识 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主收将持续更新学习记录获,友友们有任何问题可…...
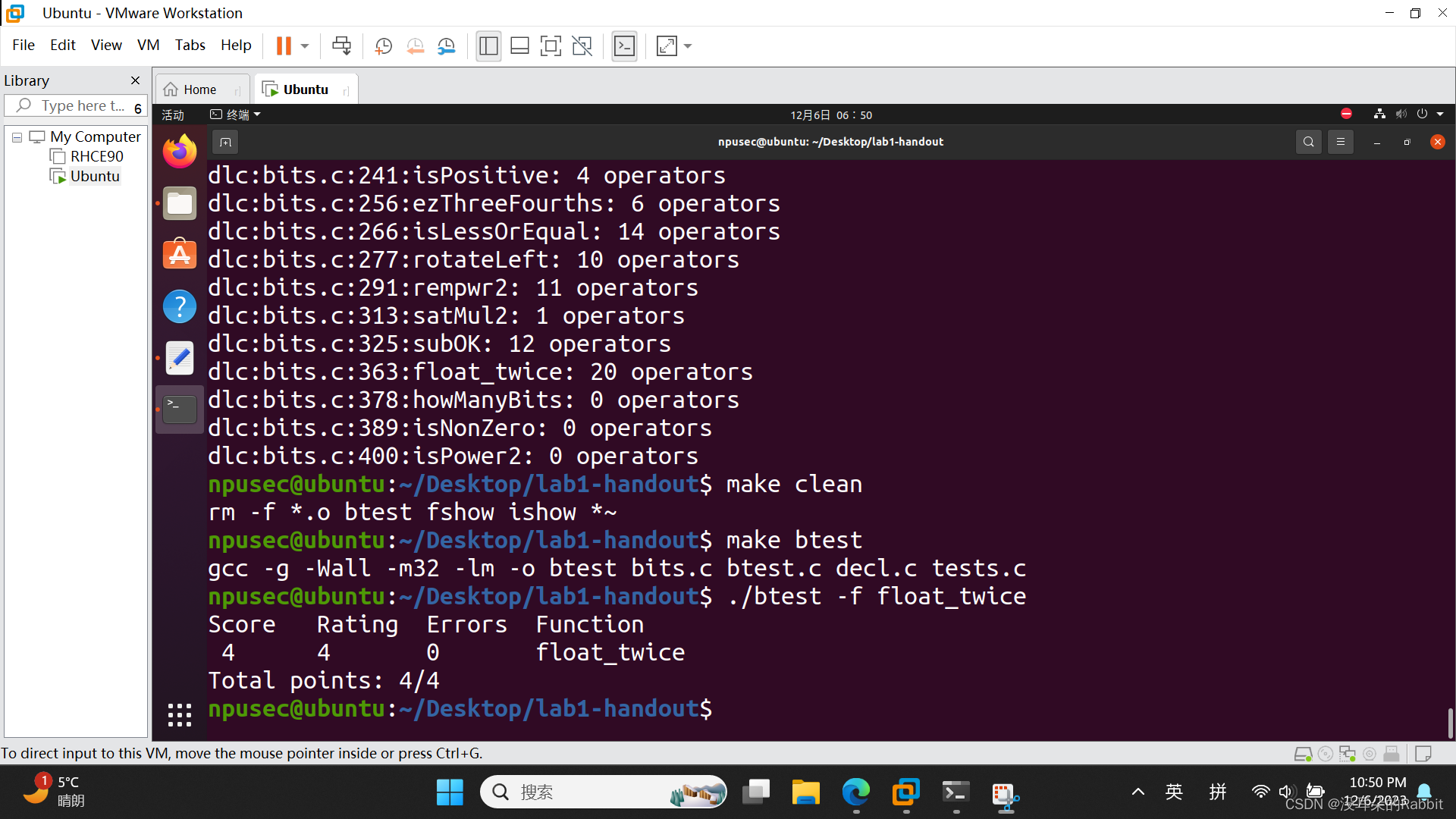
西工大计算机学院计算机系统基础实验一(函数编写11~14)
稳住心态不要慌,如果考试周冲突的话,可以直接复制这篇博客和上一篇博客西工大计算机学院计算机系统基础实验一(函数编写1~10)-CSDN博客最后的代码,然后直接提交,等熬过考试周之后回过头再慢慢做也可以。 第…...
Spring 声明式事务
Spring 声明式事务 1.Spring 事务管理概述1.1 事务管理的重要性1.2 Spring事务管理的两种方式1.2.1 编程式事务管理1.2.2 声明式事务管理 1.3 为什么选择声明式事务管理 2. 声明式事务管理2.1 基本用法2.2 常用属性2.2.1 propagation(传播行为)2.2.2 iso…...

通达OA inc/package/down.php接口存在未授权访问漏洞
声明 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 一. 产品简介 通达OA(Office Anywhere网络智能办公系统&am…...

数据库原理: 笛卡儿积
笛卡儿积(Cartesian Product)是集合论中的一个概念,也在数据库中的查询操作中经常使用。笛卡儿积是指两个集合(或更多集合)之间所有可能的组合。如果有两个集合A和B,它们的笛卡儿积记作A B,表示…...
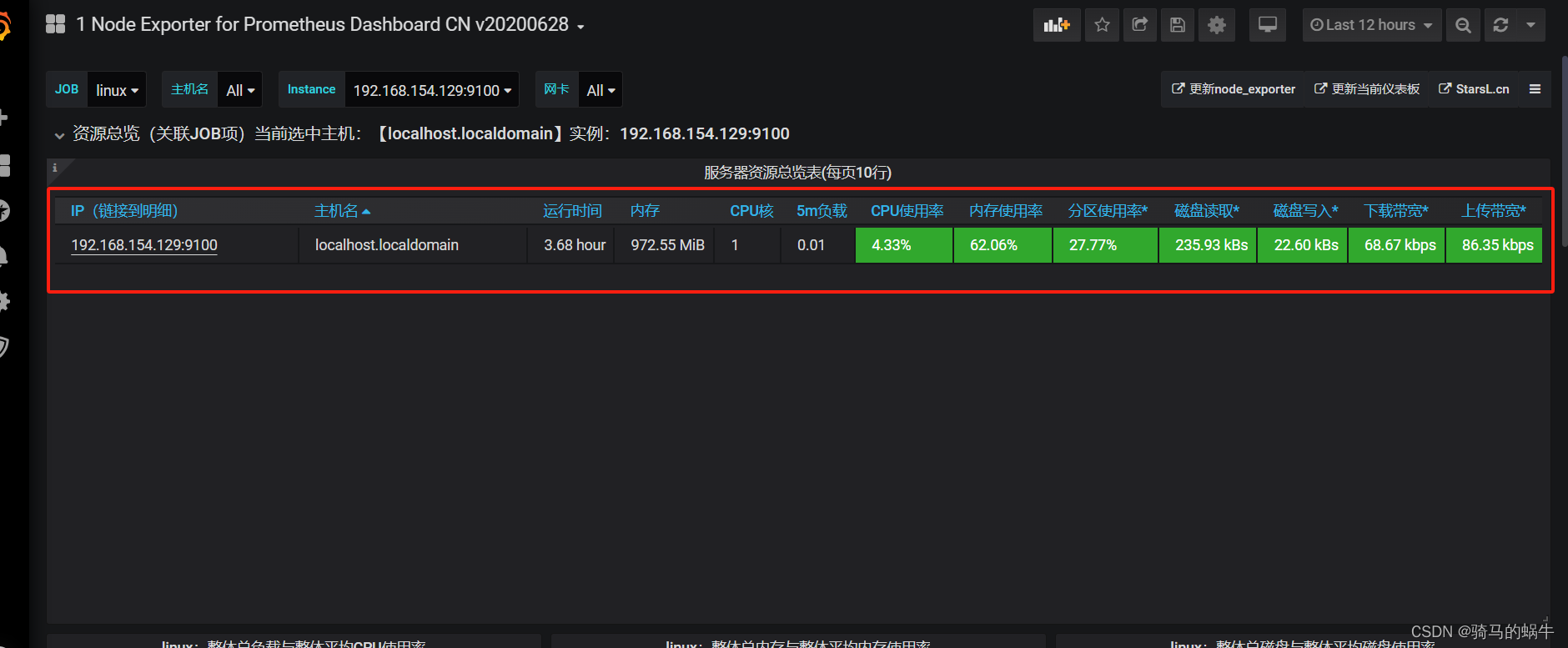
docker安装配置prometheus+node_export+grafana
简介 Prometheus是一套开源的监控预警时间序列数据库的组合,Prometheus本身不具备收集监控数据功能,通过获取不同的export收集的数据,存储到时序数据库中。Grafana是一个跨平台的开源的分析和可视化工具,将采集过来的数据实现可视…...
【JavaScript】JS——Map数据类型
【JavaScript】JS——Map数据类型 什么是Map?特性Map与Object的比较 map的创建map的属性map相关方法map的遍历 什么是Map? 存储键值对的对象。 能够记住键的原始插入顺序任何值(对象或原始值)都可以作为键或值。 特性 Map中的一个键只能出现一次&am…...
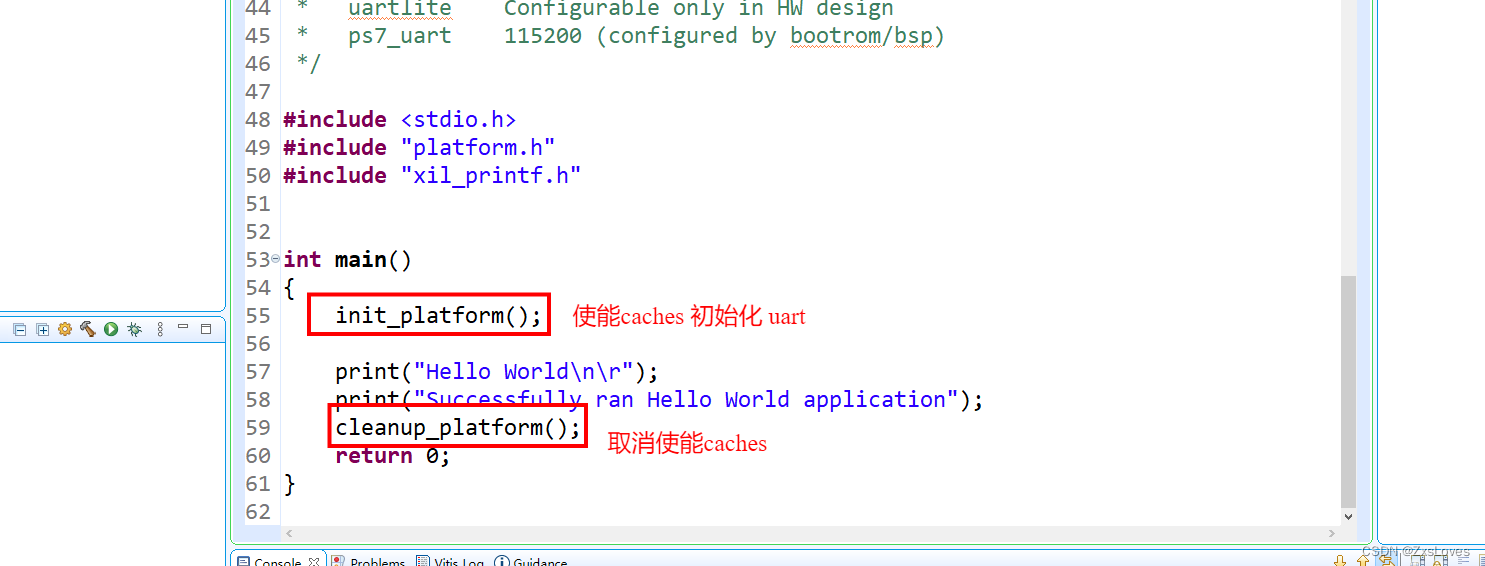
【【FPGA的 MicroBlaze 的 介绍与使用 】】
FPGA的 MicroBlaze 的 介绍与使用 可编程片上系统(SOPC)的设计 在进行系统设计时,倘若系统非常复杂,采用传统 FPGA 单独用 Verilog/VHDL 语言进行开发的方式,工作量无疑是巨大的,这时调用 MicroBlaze 软核…...

PyQt pdf格式保存
参考文章 pyqt5:利用QFileDialog从本地选择图片\文本文档显示到label、保存图片\label文本到本地(附代码)_pyqt5中qfiledialog.getopenfileurl-CSDN博客 txt文件的打开与保存 def openTextFile(self): # 选择文本文件上传fd,fp QFileDialog.getOpen…...

Java开发者福音:SpringBoot集成RexUniNLU,5分钟搞定零样本意图识别
Java开发者福音:SpringBoot集成RexUniNLU,5分钟搞定零样本意图识别 1. 为什么Java开发者需要关注RexUniNLU 在开发智能客服系统时,我们经常遇到这样的问题:用户会用各种不同的表达方式询问同一件事。"快递怎么还没到"…...

Hogan.js数据绑定终极指南:5个简单步骤实现动态内容渲染
Hogan.js数据绑定终极指南:5个简单步骤实现动态内容渲染 【免费下载链接】hogan.js A compiler for the Mustache templating language 项目地址: https://gitcode.com/gh_mirrors/ho/hogan.js Hogan.js是一个专为Mustache模板语言设计的编译器,由…...

WeKnora知识沉淀方法论:构建企业数字资产的完整流程
WeKnora知识沉淀方法论:构建企业数字资产的完整流程 1. 引言 在信息爆炸的时代,企业每天产生大量文档、报告、邮件等知识资产,但这些宝贵资源往往散落在各个角落,难以有效利用。传统的关键词搜索已经无法满足企业对知识管理的需…...

Chord在科研视频处理中的应用:实验过程帧级语义标注与行为时序建模
Chord在科研视频处理中的应用:实验过程帧级语义标注与行为时序建模 1. 引言:科研视频分析的挑战与机遇 在科学研究领域,特别是生物学、心理学、医学和工程学等学科中,实验过程视频记录已成为不可或缺的研究手段。研究人员通过视…...

5分钟搞定OpenClaw+Kimi-VL-A3B-Thinking:星图GPU镜像一键体验
5分钟搞定OpenClawKimi-VL-A3B-Thinking:星图GPU镜像一键体验 1. 为什么选择云端沙盒体验OpenClaw 作为一个长期折腾本地AI部署的技术爱好者,我深刻理解配置环境的痛苦。上周尝试在MacBook Pro上手动部署OpenClaw时,光是解决Node.js版本冲突…...

Django UI扩展全攻略:打造炫酷管理界面,【面试】Kafka / RabbitMQ / ActiveMQ。
Django第三方扩展UI详解:打造现代化管理界面和用户界面 核心UI扩展库介绍 Django-admin-interface 提供高度可定制的管理后台界面,支持主题切换、颜色自定义和模块拖拽布局。无需修改Django原生代码即可实现视觉升级,适合快速构建品牌化管理系…...

麦科奥特冲刺港股:年亏损1.85亿 估值26亿
雷递网 雷建平 4月5日陕西麦科奥特医药科技股份有限公司(简称“麦科奥特”)日前更新招股书,准备在港交所上市。麦科奥特2025年9月26日完成2.36亿元,投后估值为26.36亿元。年亏损1.85亿麦科奥特成立于2007年,是一家平台…...

Ostrakon-VL-8B图文对话实战:上传厨房照片→提问卫生问题→获取结构化反馈
Ostrakon-VL-8B图文对话实战:上传厨房照片→提问卫生问题→获取结构化反馈 想象一下,你是一家连锁餐厅的卫生督导员,每周要巡查几十家门店的厨房。传统方式是什么?拿着检查表,挨个角落拍照,回到办公室再整…...

OpenClaw邮件处理方案:Qwen2.5-VL-7B自动分类与回复
OpenClaw邮件处理方案:Qwen2.5-VL-7B自动分类与回复 1. 为什么需要邮件自动化助手 每天早晨打开邮箱时,面对堆积如山的未读邮件总让人心生畏惧。作为技术从业者,我的收件箱里混杂着技术订阅、会议邀请、账单通知和各种推广信息,…...
)
保姆级教程:用QGroundControl地面站V4.2.0连接Gazebo模拟无人机(附避坑指南)
从零到一:QGroundControl地面站与Gazebo无人机仿真全流程实战 无人机仿真技术已经成为开发者快速验证算法、学生入门飞控系统的首选方案。相比真机测试,仿真环境不仅成本低廉,还能避免硬件损坏风险。本文将手把手带你完成QGroundControl地面站…...