26.Python 网络爬虫
目录
- 1.网络爬虫简介
- 2.使用urllib
- 3.使用request
- 4.使用BeautifulSoup
1.网络爬虫简介
网络爬虫是一种按照一定的规则,自动爬去万维网信息的程序或脚本。一般从某个网站某个网页开始,读取网页的内容,同时检索页面包含的有用链接地址,然后通过这些链接地址寻找下一个网页,再做相同的工作,一直循环下去,直到按照某种策略把互联网所有的网页都抓完为止。
网络爬虫的分类
网络爬虫大致有4种类型:通过网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。
- 通用网络爬虫:爬取的目标数据巨大,并且范围非常广,性能要求非常高。主要应用在大型搜索引擎中,有非常高的应用价值,或者应用于大型数据提供商。
- 聚焦网络爬虫:按照预先定义好的主题,有选择地进行网页爬取的一种爬虫。将爬取的目标网页定位在与主题相关的页面中,大大节省爬虫爬取时所需要的带宽资源和服务器资源。主要应用在对特定信息的爬取中为某一类特定的人群提供服务。
- 增量式网络爬虫:在爬取网页的时候,只爬取内容发生变化的网页或者新产生的网页,对于内容未变化的网页,则不会爬。增量式网络爬虫在一定的程度上能够保证爬取的页面尽可能是新页面。
- 深层网络爬虫:网页按存在方式可以分为表层页面和深层页面。表层页面指不需要提交表单,使用静态的链接就能够到达的静态页面;深层页面则隐藏在表单后面,不能通过静态链接直接获取,需要提交一定的关键词之后才能获取的页面。
网络爬虫的作用
1)搜索引擎:为用户提供相关且有效的内容,创建所有访问页面的快照以供后续处理。使用聚焦网络爬虫实现任何门户网站上的搜索引擎或搜索功能,有助于找到与搜索主题具有最高相关性的网页。
2)建立数据集:用于研究、业务和其他目的。
- 了解和分析网民对公司或组织的行为。
- 收集营销信息,并在短期内更好地做出营销决策。
- 从互联网收集信息,分析他们并进行学术研究。
- 收集数据,分析一个行业的长期发展趋势。
- 监控竞争对手的实时变化。
网络爬虫的工作流程
预先设定一个或若干个初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获取URL,进而访问并下载该页面。
当页面下载后,页面解析器去掉页面上的HTML标记并得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前网页上新的URL,推入URL队列,知道满足系统停止条件。
2.使用urllib
python2:urllib+urllib2
python3:urllib2+urllib3
urllib 是Python中请求URL连接的官方标准库,共有4个模块:
- urllib.request:主要负责构造和发起网络请求,定义了适用于各种复杂情况下打开URL的函数和类。
- urllib.error:异常处理。
- urllib.parse:解析各种数据格式。
- urllib.robotparser:解析robots.txt文件。
发起请求
'''
http.client.HTTPResponse = urllib.request.urlopen(url,data,timeout,cafile,capath,context)
cafile,capath 使用https时使用
http.client.HTTPResponse = urllib.request.urlopen(urllib.request.Request)
返回响应对象
'''
import urllib.request
baidu_url = 'http://www.baidu.com'
sina_url = 'http://www.sina.com'
r = urllib.request.urlopen(sina_url) # 发起请求,返回响应对象
h = r.read().decode('utf-8') # 读取数据并解码
print(h)
提交数据:使用data参数提交数据
import urllib.request
import urllib.parsebaidu_url = 'http://www.baidu.com'
sina_url = 'http://www.sina.com'
p = {'name':'Python','author':'admin'
}
d = bytes(urllib.parse.urlencode(p),encoding='utf8') # 进行编码,将字典转化为字符串再字节流
r = urllib.request.urlopen(sina_url,data=d,timeout=1) # 传入参数,发起请求,返回响应对象
h = r.read().decode('utf-8') # 读取数据并解码
print(h)
设置请求头:需要指定请求头
'''
urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
'''
# 浏览器,开发者工具,标头
# urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
import urllib.request
baidu_url = 'http://www.baidu.com'
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
req = urllib.request.Request(url=baidu_url,headers=headers)
r = urllib.request.urlopen(req)
h = r.read().decode('utf-8')
print(h)
使用代理:处理cookie等信息时。
'''
Handler
OpenerDirector
'''
import urllib.request
baidu_url = 'http://www.baidu.com'
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
# 通过第三方服务器寻找,具有实效性,可设置多个
proxy = urllib.request.ProxyHandler({'http':'125.71.212.17:9000','http':'113.71.212.17:9000'}
)
opener = urllib.request.build_opener(proxy) # 创建代理
urllib.request.install_opener(opener) # 安装代理
req = urllib.request.Request(url=baidu_url,headers=headers)
r = urllib.request.urlopen(req)
h = r.read().decode('utf-8')
print(h)
认证登录:需要先登入才能访问浏览页面。
- 创建一个账号密码管理对象。
- 添加账号和密码。
- 获取一个handler对象。
- 获取opener对象。
- 使用open()函数发起请求。
import urllib.request
url = 'http://cnblogs.com/xtznb'
user = 'user'
password = 'password'
pwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 创建一个账号密码管理对象
pwdmgr.add_password(None,url,user,password) # 添加账号和密码
auth_handler = urllib.request.HTTPBasicAuthHandler(pwdmgr) # 获取一个handler对象
opener = urllib.request.build_opener(auth_handler) # 获取opener对象
response = opener.open(url) # 使用open()函数发起请求
print(response.read().decode('utf-8'))
设置Cookies:页面每次需要生成验证,可以使用Cookies自动登入。
- 实例化Cookies对象。
- 构建一个handler对象。
- 使用opener对象的open()发起请求。
import urllib.request
import http.cookiejar
url = 'http://tieba.baidu.com'
file = 'cookie.txt'
cookie = http.cookiejar.CookieJar() # 实例化Cookies对象
handler = urllib.request.HTTPCookieProcessor(cookie) # 构建一个handler对象
opener = urllib.request.build_opener(handler)
response = opener.open(url) # 使用opener对象的open()发起请求
f = open(file,'a') # 追加模式写入
for i in cookie: # 迭代写入信息f.write(i.name + '=' + i.value + '\n')
f.close() # 关闭文件
3.使用request
requests模块是在urllib3模块基础上进行了高度封装,使用更方便,网络请求也变得更加简洁和人性化。在爬取数据时,urllib爬取数据之后直接断开连接,而requests爬取数据之后可以继续复用socket,并没有断开连接。
发起GET请求
使用requests模块的get()方法可以发送GET请求。
'''
response = get(url,params=None,**kwargs)
url:请求的URL地址
params:字典或字节序列,作为参数增加到URL中
**kwargs:控制访问的参数
'''
import requests
r = requests.get('http://www.baidu.com')
print(r.url) # http://www.baidu.com/
print(r.cookies) # <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
r.encoding = 'utf-8'
print(r.encoding) # utf-8
print(r.text) # 网页源代码
print(r.content) # 二进制字节流
print(r.headers) # 文件头
print(r.status_code) # 状态码
# 手工附加
r = requests.get('http://www.baidu.com/?key=val')
# 使用params关键字参数
payload1 = {'key1':'value1','key2':'value2'}
r = requests.get('http://www.baidu.com',params=payload1)
payload2 = {'key1':'value1','key2':['value2','value3']}
r = requests.get('http://www.baidu.com',params=payload2)
# 请求头形式
headers = {'Content-Type':'text/html; charset=utf-8','User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
r = requests.get('http://www.baidu.com',headers=headers)
# 设置代理
headers = {'Content-Type':'text/html; charset=utf-8','User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
p = {'http':'120.25.253.234.0000'
}
r = requests.get('http://www.baidu.com',headers=headers,proxies=p)
也可以使用timeout参数设置延时时间,使用verify参数设置整数验证,使用cookies参数传递cookie信息等。
发送POST请求
HTTP协议规定POST提交的数据必须放在消息主题中,但协议并没有规定数据必须使用什么编码方式,具体的编码方式有3种:
- form表单形式:application/x-www-form-urlencoded
- JSON字符串提交数据:application/json
- 上传文件:multipart/form-data
发送POST请求,可以使用post()方法,也返回一个Response对象。
示例1:form形式发送POST请求。
import requests
payload = {'key1':'value1','key2':'value2'}
r = requests.post('http://httpbin.org/post',params=payload)
print(r.text)
'''输出
{"args": {"key1": "value1", "key2": "value2"}, "data": "", "files": {}, "form": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "0", "Host": "httpbin.org", "User-Agent": "python-requests/2.27.1", "X-Amzn-Trace-Id": "Root=1-656f516d-18cccab474d121d705eb3ad9"}, "json": null, "origin": "218.104.29.129", "url": "http://httpbin.org/post?key1=value1&key2=value2"
}
'''
示例2:JSON格式发送POST请求。
import requests
import json
payload = {'key1':'value1','key2':'value2'}
r = requests.post('http://httpbin.org/post',data=json.dumps(payload))
print(r.text)
'''
{"args": {}, "data": "{\"key1\": \"value1\", \"key2\": \"value2\"}", "files": {}, "form": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "36", "Host": "httpbin.org", "User-Agent": "python-requests/2.27.1", "X-Amzn-Trace-Id": "Root=1-656f5282-3f08151e1fbbeec54501ed80"}, "json": {"key1": "value1", "key2": "value2"}, "origin": "218.104.29.129", "url": "http://httpbin.org/post"
}
'''
示例3:上传文件发送POST请求。
# 新建文本文件report.txt,输入一行Hello world
import requests
files = {'file':open('report.txt','rb')}
r = requests.post('http://httpbin.org/post',files=files)
print(r.text)
'''
{"args": {}, "data": "", "files": {"file": "Hello world"}, "form": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "157", "Content-Type": "multipart/form-data; boundary=44a0c52d3705bdc2a8a6ffa85ccc00bc", "Host": "httpbin.org", "User-Agent": "python-requests/2.27.1", "X-Amzn-Trace-Id": "Root=1-656f538f-5c062ec1599c4fbe082aa840"}, "json": null, "origin": "218.104.29.129", "url": "http://httpbin.org/post"
}
'''
requests 不仅提供了GET和POST请求方式,还提供了其他请求方式:put、delete、head、options。
GET主要用于从指定的资源请求数据,而POST主要用于向指定的资源提交要被处理的数据。
4.使用BeautifulSoup
使用requests模块仅能抓去一些网页源码,但是如何对源码进行筛选、过滤,精确找到需要的数据,就要用到BeautifulSoup。它是一个可以从HTML或XML文件中提取数据的Python库。
BeautifulSoup支持Python标准库种的HTML解析器,还支持一些第三方的解析器,如果不安装,则python默认的解析器,lxml解析器就更加强大,速度更快,推荐使用lxml解析器。
解析器字符串
html.parser:BeautifulSoup(html,'html.parser')默认执行速度一般,容错能力强。lxml:BeautifulSoup(html,'lxml')速度快文档容错能力强。xml:BeautifulSoup(html,'xml')速度快,主要针对XML文档。html5lib:BeautifulSoup(html,'html5lib')最好的容错性,主要针对HTML5文档。
BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码。
环境配置
'''
pip install beautifulsoup4
# 需要调用HTML解析器,安装如下
pip install html5lib
pip install lxml
'''
示例3:
# 新建test.html,输入以下内容
<!DOCTYPE html>
<html>
<head><meta charset="utf-8"><title>Hello,world</title>
</head>
<body>
<div class="book"><span><!--这里是注释的部分--></span><a href="https://www.baidu.com">百度一下,你就知道</a><p class="a">这是一个示例</p>
</div>
</body>
</html># 新建py文件
from bs4 import BeautifulSoup
f = open('paichong/test.html','r',encoding='utf-8') # 打开文件
html = f.read()
f.close()
soup = BeautifulSoup(html,'html5lib') # 指定html5lib解析器
print(type(soup))
节点对象
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,对象归纳为:Tag、NavigableString、BeautifulSoup、Comment。
- Tag:标签
- NavigableString:标签包裹的文本
- BeautifulSoup:解析网页所得到的对象
- Comment:注释或者特殊字符串。
from bs4 import BeautifulSoup
f = open('paichong/test.html','r',encoding='utf-8') # 打开文件
html = f.read()
f.close()
soup = BeautifulSoup(html,'html5lib') # 指定html5lib解析器
print(type(soup))
tag = soup.p # 读取p标签
print(tag.name) # 读取p标签名称
print(tag["class"]) # 属性值
print(tag.get_text()) # 文本
文档遍历
遍历节点属性如下:
- contents:获取所有字节点,包含NavigableString对象,返回的是一个列表。
- children:获取所有子节点,返回的是一个迭代器。
- descendants:获取所有子孙节点,返回的是一个迭代器。
- string:获取直接包含的文本。
- strings:获取全部包含的文本,返回一个可迭代对象。
- parent:获取上一层父节点。
- parents:获取父辈节点,返回一个可迭代对象。
- next_sibling:获取当前节点的下一个兄弟节点。
- next_siblings:获取当前节点的下方所有兄弟节点。
- previous_sibling:获取当前节点的上一个兄弟节点。
- previous_siblings:获取当前节点的上方所有兄弟节点。
from bs4 import BeautifulSoup
f = open('paichong/test.html','r',encoding='utf-8') # 打开文件
html = f.read()
f.close()
soup = BeautifulSoup(html,'html5lib') # 指定html5lib解析器
tags = soup.head.children # 获取head的所有子节点
print(tags)
for tag in tags:print(tag)
文档搜索
- find_all(name[,name1,…]):name为标签名称,直接标签字符串过滤。
- find_all(attires = {‘属性名称’:‘属性值’}): 搜索属性。
- find_all(name,text=”文本内容“) :搜索文本
- find_all(name,recursive=False):限制查找范围。
- find_all(re.compile(”b”)):正则表达式。
a = soup.find_all('a',text='百度一下,你就知道')
a = soup.find_all(re.compile('a'))
print(a)
CSS选择器
select() 方法传入字符串参数。详细见:http://www.w3.org/TR/CSS2/selector.html。
from bs4 import BeautifulSoup
import re
f = open('paichong/test.html','r',encoding='utf-8') # 打开文件
html = f.read()
f.close()
soup = BeautifulSoup(html,'html5lib') # 指定html5lib解析器
tags = soup.select(".a")
print(tags) # [<p class="a">这是一个示例</p>]
相关文章:

26.Python 网络爬虫
目录 1.网络爬虫简介2.使用urllib3.使用request4.使用BeautifulSoup 1.网络爬虫简介 网络爬虫是一种按照一定的规则,自动爬去万维网信息的程序或脚本。一般从某个网站某个网页开始,读取网页的内容,同时检索页面包含的有用链接地址࿰…...

Spring Boot 在启动之前还做了哪些准备工作?
目录 一:初始化资源加载器 二:校验主要源 三:设置主要源 四:推断 Web 应用类型<...
)
SQL语句常用语法(开发场景中)
一、SQL语句常用小场景 1.查询某个表信息,表中某些字段为数据字典需要进行转义 SELECTt.ID,CASEWHEN t.DINING_TYPE 1 THEN早餐WHEN t.DINING_TYPE 2 THEN午餐WHEN t.DINING_TYPE 3 THEN晚餐END AS diningTypeStr from student t 2.联表查询语法 select si.*…...

HarmonyOS应用开发者认证:开启全新的智能设备开发之旅
随着科技的不断发展,人工智能、物联网等技术逐渐渗透到我们的日常生活中。在这个智能化的时代,华为推出了一款全新的操作系统——HarmonyOS,旨在为各种智能设备提供统一的操作系统,实现设备之间的无缝连接和协同工作。作为开发者&…...

Python 模板引擎 Jinja2 的安装和使用
目录 一、概述 二、安装 Jinja2 三、使用 Jinja2 四、Jinja2的强大功能和优点 五、总结 一、概述 Jinja2 是 Python 中广泛使用的一种模板引擎,它具有灵活的语法、强大的控制结构、方便的 API,以及高效的渲染速度。通过使用 Jinja2,开发…...
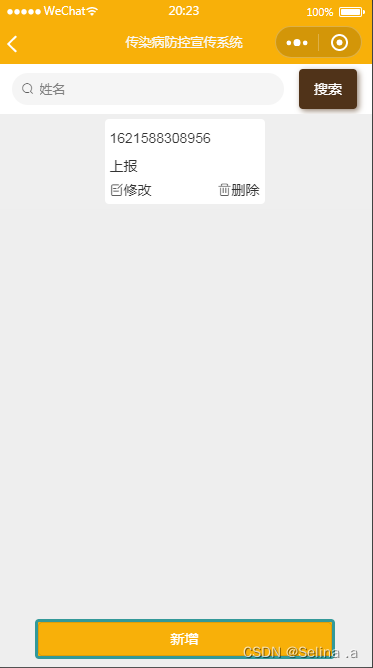
案例063:基于微信小程序的传染病防控宣传系统
文末获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder …...

53. Protocol buffer 的Go使用
文章目录 一、介绍二、安装三、protoc3语法1、 protoc3 与 protoc2区别2、proto3生成go代码包Message内嵌Message字段单一标量字段单一message字段可重复字段slicemap字段枚举 一、介绍 Protobuf是Google旗下的一款平台无关,语言无关,可扩展的序列化结构…...

如何访问内部网络做内网穿透
项目:https://github.com/ehang-io/nps 有个公网服务器,搭建服务端。 然后客户端使用: -server是服务端的访问方式。-vkey是秘钥。 ./npc -server192.227.19.12:8024 -vkeyoies8gq3wml -typetcp然后在服务端配置TCP隧道即可。...
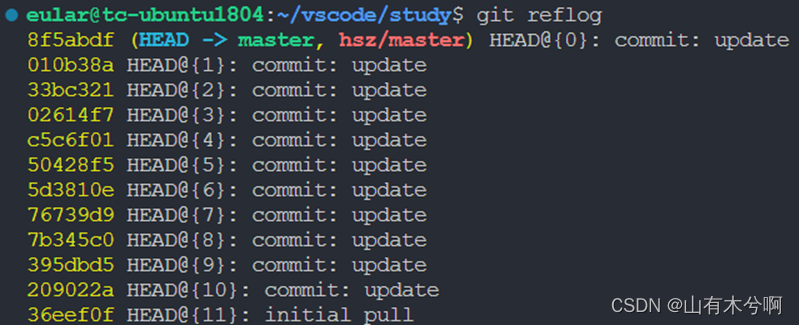
git常用命令总结
生成公钥并在github添加公钥 ssh-keygen -t rsa -C **********测试是否可用 ssh -T gitgithub.com本地初始化 git init添加远程库 格式:git remote add [shortname] [url] git remote add origin gitgithub.com:TonyBeen/eular.git拉取指定仓库的代码 git pull orig…...

Apollo新版本Beta技术沙龙
有幸参加Apollo开发者社区于12月2日举办的Apollo新版本(8.0)的技术沙龙会,地址在首钢园百度Apollo Park。由于去的比较早,先参观了一下这面的一些产品,还有专门的讲解,主要讲了一下百度无人驾驶的发展历程和历代产品。我对下面几个…...
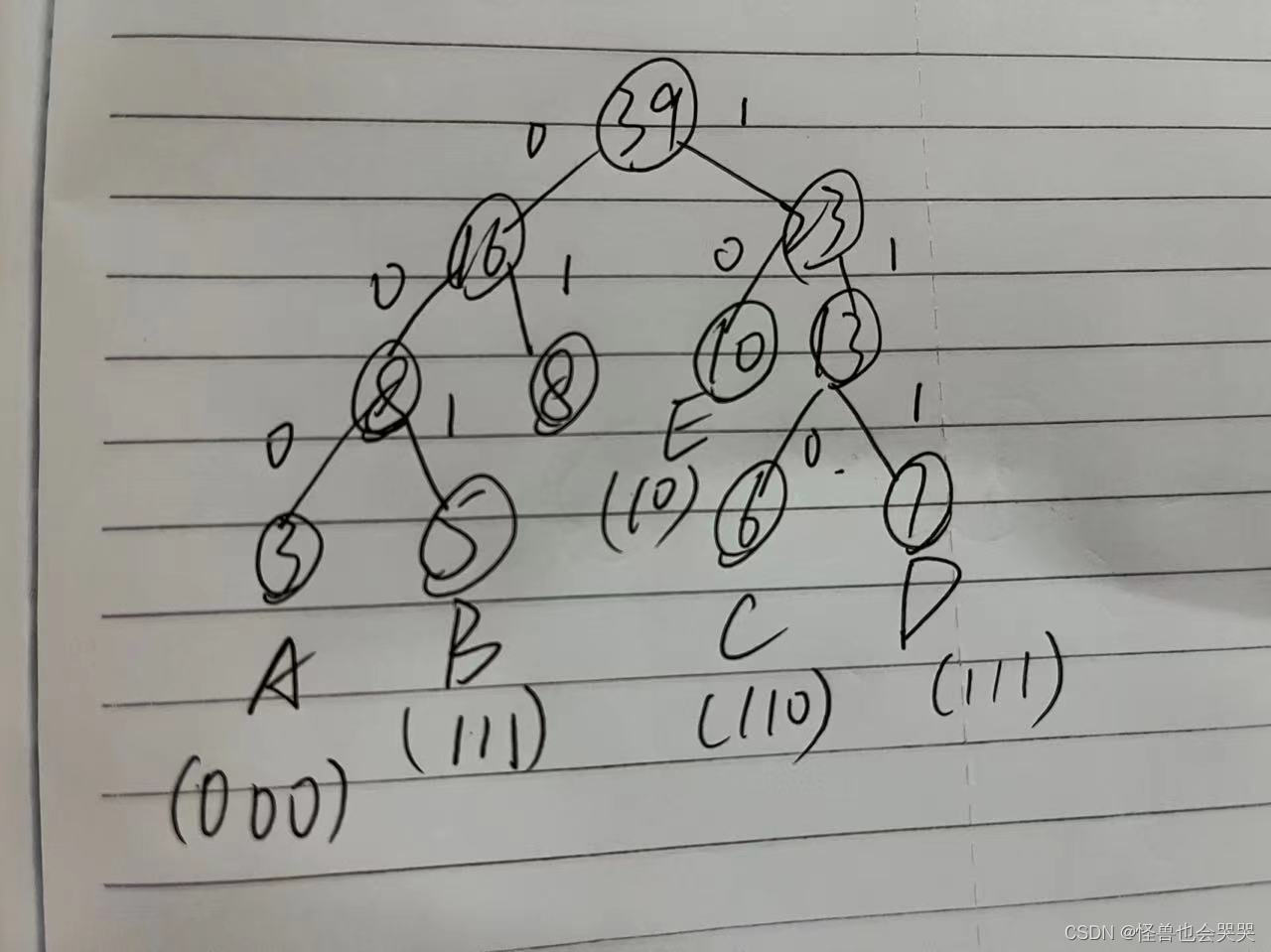
数据结构第二次作业——递归、树、图【考点罗列//错题正解//题目解析】
目录 一、选择题 ——递归—— 1.【单选题】 ——递归的相关知识点 2.【单选题】——递归的应用 3.【单选题】——递归的实现结构 4.【单选题】——递归的执行与实现 5.【单选题】 ——递归算法 ——树—— 6.【单选题】 ——树的结构 *7.【单选题】——树的知识点 …...

Redis--12--Redis分布式锁的实现
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Redis分布式锁最简单的实现如何避免死锁?锁被别人释放怎么办?锁过期时间不好评估怎么办?--看门狗分布式锁加入看门狗 redissonRe…...

MongoDB简介与安装
目录 1. MongoDB简介 2. 安装MongoDB 3. 基本命令行操作 4. Java代码实践 MongoDB是一种NoSQL数据库,以其灵活的文档存储模型和高度可扩展性而闻名。这篇文章将简单介绍一下MongoDB的基本概念,包括其特点和优势,并提供安装MongoDB的步骤。…...
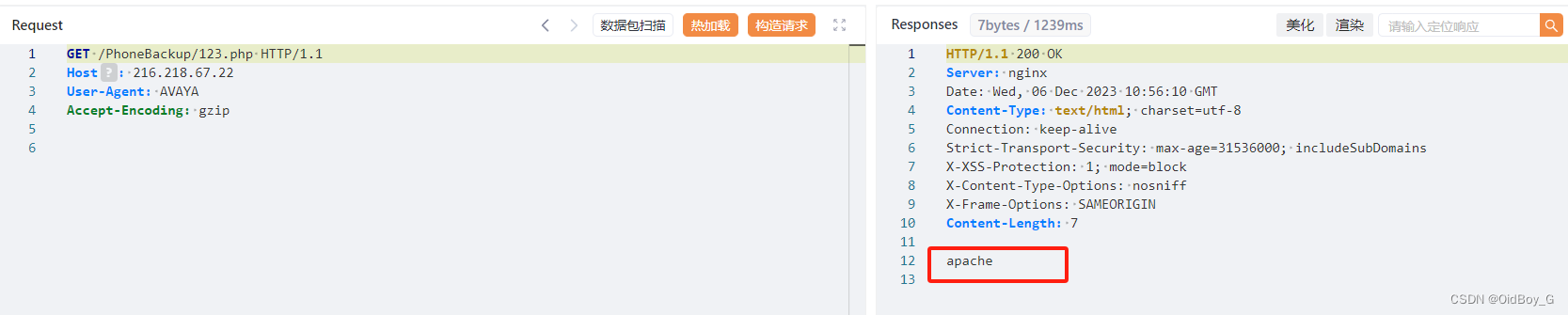
Avaya Aura Device Services 任意文件上传漏洞复现
0x01 产品简介 Avaya Aura Device Services是美国Avaya公司的一个应用软件。提供一个管理 Avaya 端点功能。 0x02 漏洞概述 Avaya Aura Device Services 系统PhoneBackup接口处存在任意文件上传漏洞,攻击者可绕过验证上传任意文件获取服务器权限。 0x03 影响范围…...
C#注册表技术及操作
目录 一、注册表基础 1.Registry和RegistryKey类 (1)Registry类 (2)RegistryKey类 二、在C#中操作注册表 1.读取注册表中的信息 (1)OpenSubKey()方法 (2)GetSubKeyNames()…...
js/jQuery常见操作 之各种语法例子(包括jQuery中常见的与索引相关的选择器)
js/jQuery常见操作 之各种语法例子(包括jQuery中常见的与索引相关的选择器) 1. 操作table常见的1.1 动态给table添加title(指定td)1.1.1 给td动态添加title(含:获取tr的第几个td)1.1.2 动态加工…...
C语言数组(下)
我希望各位可以在思考之后去看本期练习,并且在观看之后独立编写一遍,以加深理解,巩固知识点。 练习一:编写代码,演⽰多个字符从两端移动,向中间汇聚 我们依旧先上代码 //编写代码,演⽰多个字…...

pytorch学习5-最大池化层的使用
系列文章目录 pytorch学习1-数据加载以及Tensorboard可视化工具pytorch学习2-Transforms主要方法使用pytorch学习3-torchvisin和Dataloader的使用pytorch学习4-简易卷积实现pytorch学习5-最大池化层的使用pytorch学习6-非线性变换(ReLU和sigmoid)pytorc…...

在python中安装库,会有conda安装,也会有pip安装,conda与pip的区别是什么?
文章目录 一、Conda是什么?二、pip是什么?三、pip与conda的区别:总结 一、Conda是什么? Conda是一个开源的包管理系统,它是Anaconda公司为Python和其他编程语言开发的。它主要用于数据科学和机器学习领域,…...
算法-贪心思想
贪心的思想非常不好解释,而且越使用权威的语言解释越难懂。而且做题的时候根据自己的理解可能直接做出来,但是非要解释一下怎么使用的贪心的话,就懵圈了。一般来说,贪心的题目没有固定的套路,一题一样,不过…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...