【100天精通Python】Day75:Python机器学习-第一个机器学习小项目_鸾尾花分类项目(上)
目录
1 机器学习中的Helloworld _鸾尾花分类项目
2 导入项目所需类库和鸾尾花数据集
2.1 导入类库
2.2 scikit-learn 库介绍
(1)主要特点:
(2)常见的子模块:
3 导入鸾尾花数据集
3.1 概述数据
3.2 数据维度
3.3 查看数据自身
3.4 统计描述数据
3.5 数据分类分布
4 数据可视化
4.1 单变量图表
4.2 多变量图表
1 机器学习中的Helloworld _鸾尾花分类项目
鸢尾花分类是机器学习领域中的一个经典示例,也是一个适用于入门级学习者的 "Hello World" 项目。这个项目使用鸢尾花数据集,其中包含了三个不同种类的鸢尾花:Setosa、Versicolor 和 Virginica。这三个亚属分别属于鸢尾属(Iris)中的不同物种。
2 导入项目所需类库和鸾尾花数据集
2.1 导入类库
# 导入鸢尾花数据集
from sklearn import datasets# 导入数据处理和分割工具
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 导入分类器模型
from sklearn.neighbors import KNeighborsClassifier# 导入性能评估指标
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 导入可视化工具
import matplotlib.pyplot as plt
import seaborn as sns
这段代码导入了以下类库和模块:
datasets:从 scikit-learn 中导入数据集。train_test_split:用于将数据集分割成训练集和测试集的模块。StandardScaler:用于数据标准化的模块,对特征进行缩放。KNeighborsClassifier:K近邻分类器,用于鸢尾花分类任务。accuracy_score、classification_report、confusion_matrix:用于评估分类器性能的模块。matplotlib.pyplot和seaborn:用于可视化数据和评估结果的模块。
请确保在运行这段代码之前已经安装了这些库,可以使用以下命令安装:
pip install scikit-learn matplotlib seaborn
导入这些类库后,你就可以在鸢尾花分类项目中使用它们进行数据处理、建模和评估。
2.2 scikit-learn 库介绍
scikit-learn 是一个用于机器学习的 Python 库,提供了丰富的工具和模型,用于数据挖掘和数据分析。它建立在 NumPy、SciPy 和 Matplotlib 基础之上,是机器学习领域中最受欢迎的库之一。
(1)主要特点:
简单而高效:
scikit-learn提供了简单且一致的接口,易于学习和使用。它支持多种机器学习任务,包括分类、回归、聚类、降维等。丰富的文档: 该库具有详细的文档,包括用户指南、教程和示例,使用户能够更好地理解和使用不同的算法和工具。
广泛的算法:
scikit-learn包含了许多经典和先进的机器学习算法,如支持向量机(SVM)、随机森林、K均值聚类等。数据预处理: 提供了丰富的数据预处理工具,包括数据标准化、特征选择、缺失值处理等。
模型评估: 支持模型性能评估的工具,包括交叉验证、网格搜索调参、性能度量等。
可扩展性: 允许用户通过创建自定义转换器和评估器来扩展功能,也支持集成其他库。
(2)常见的子模块:
datasets 模块: 包含一些常用的数据集,如鸢尾花数据集、手写数字数据集等。
model_selection 模块: 提供了用于交叉验证、超参数调优等的工具。
preprocessing 模块: 包含数据预处理的工具,如标准化、缩放、编码等。
metrics 模块: 包含模型评估的指标,如准确率、精确度、召回率等。
ensemble 模块: 包含集成学习方法,如随机森林、梯度提升树等。
neighbors 模块: 包含近邻算法,如 K 近邻分类器。
svm 模块: 包含支持向量机算法。
cluster 模块: 包含聚类算法,如 K 均值聚类、层次聚类等。
decomposition 模块: 包含降维算法,如主成分分析(PCA)等。
3 导入鸾尾花数据集
3.1 概述数据
鸢尾花数据集是由统计学家和生物学家Ronald A. Fisher于1936年创建的,用于展示多变量统计方法。该数据集包含了三个不同种类的鸢尾花(Setosa、Versicolor 和 Virginica)的测量数据。
导入数据集
from sklearn import datasets# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target
你可以在 UCI Machine Learning Repository 网站上找到鸢尾花数据集的信息和下载链接:Iris Data Set![]() https://archive.ics.uci.edu/ml/datasets/iris然后,你可以下载数据集并使用适当的工具进行导入和处理。
https://archive.ics.uci.edu/ml/datasets/iris然后,你可以下载数据集并使用适当的工具进行导入和处理。
3.2 数据维度
查看数据维度
from sklearn import datasets
import pandas as pd# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 创建数据框
df = pd.DataFrame(data=X, columns=iris.feature_names)
df['target'] = y# 查看数据集的维度
print(f"数据集维度:{df.shape}")

数据集的特征包括:
- 萼片长度(Sepal Length)
- 萼片宽度(Sepal Width)
- 花瓣长度(Petal Length)
- 花瓣宽度(Petal Width)
每个特征都以厘米为单位进行测量。
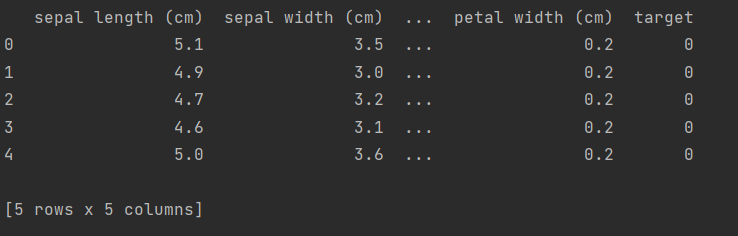
3.3 查看数据自身
首先,让我们看一下数据集的一些样本和它们的标签:
from sklearn import datasets
import pandas as pdiris = datasets.load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target# 打印数据集的前几行
print(df.head())
输出:
3.4 统计描述数据
我们可以使用 pandas 库的 describe() 方法获取关于数据的统计描述信息:
from sklearn import datasets
import pandas as pdiris = datasets.load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target# 打印数据集的前几行
print(df.head())
# 统计描述
print(df.describe())
输出:

3.5 数据分类分布
查看鸢尾花数据集中每个类别的分布:
from sklearn import datasets
import pandas as pdimport matplotlib.pyplot as plt
import seaborn as snsiris = datasets.load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target# # 打印数据集的前几行
# print(df.head())
# # 统计描述
# print(df.describe())# 绘制数据集中每个类别的计数分布
sns.countplot(x='target', data=df)
plt.title('Class Distribution in Iris Dataset')
plt.show() 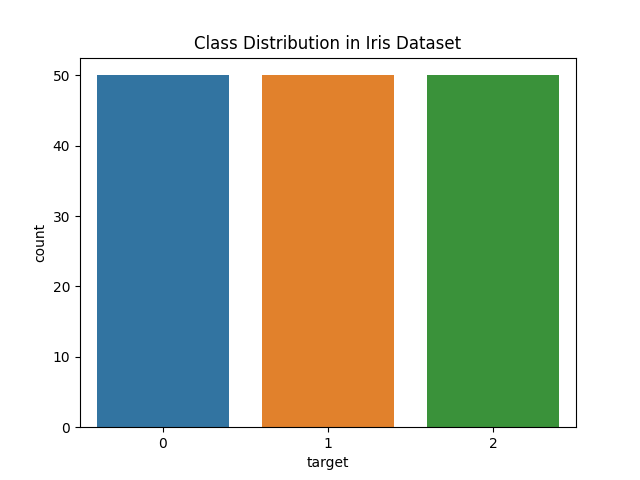
以上步骤可以让你更好地了解鸢尾花数据集,包括特征的维度、样本的分布情况等。这些信息对于进行机器学习任务之前的数据探索和理解非常重要。
4 数据可视化
通过对数据集的审查,对数据有一个基本的了解。接下来将通过图标来进一步查看数据特征的分布情况和数据不同特征之间的相互关系。
使用单变量图表可以更好地理解每一个特征属性。
多变量图表用于理解不同特征属性之间的关系。
4.1 单变量图表
from sklearn import datasets
import pandas as pd# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 创建数据框
df = pd.DataFrame(data=X, columns=iris.feature_names)
df['target'] = y# 查看数据集的维度
print(f"数据集维度:{df.shape}")import matplotlib.pyplot as plt
import seaborn as sns# 设置图形样式
sns.set(style="whitegrid")# 创建单变量图表
plt.figure(figsize=(12, 6))# 绘制花萼长度的直方图
plt.subplot(2, 2, 1)
sns.histplot(df['sepal length (cm)'], kde=True, color='skyblue')
plt.title('Distribution of Sepal Length')# 绘制花萼宽度的直方图
plt.subplot(2, 2, 2)
sns.histplot(df['sepal width (cm)'], kde=True, color='salmon')
plt.title('Distribution of Sepal Width')# 绘制花瓣长度的直方图
plt.subplot(2, 2, 3)
sns.histplot(df['petal length (cm)'], kde=True, color='green')
plt.title('Distribution of Petal Length')# 绘制花瓣宽度的直方图
plt.subplot(2, 2, 4)
sns.histplot(df['petal width (cm)'], kde=True, color='orange')
plt.title('Distribution of Petal Width')plt.tight_layout()
plt.show()
4.2 多变量图表
from sklearn import datasets
import pandas as pd# 导入鸢尾花数据集
iris = datasets.load_iris()# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 创建数据框
df = pd.DataFrame(data=X, columns=iris.feature_names)
df['target'] = y# 查看数据集的维度
print(f"数据集维度:{df.shape}")import matplotlib.pyplot as plt
import seaborn as sns# 设置图形样式
sns.set(style="whitegrid")# 创建多变量图表
plt.figure(figsize=(12, 6))# 绘制花萼长度和宽度的散点图
plt.subplot(1, 2, 1)
sns.scatterplot(x='sepal length (cm)', y='sepal width (cm)', hue='target', data=df, palette='viridis')
plt.title('Scatter Plot of Sepal Length vs. Sepal Width')# 绘制花瓣长度和宽度的散点图
plt.subplot(1, 2, 2)
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='target', data=df, palette='viridis')
plt.title('Scatter Plot of Petal Length vs. Petal Width')plt.tight_layout()
plt.show()
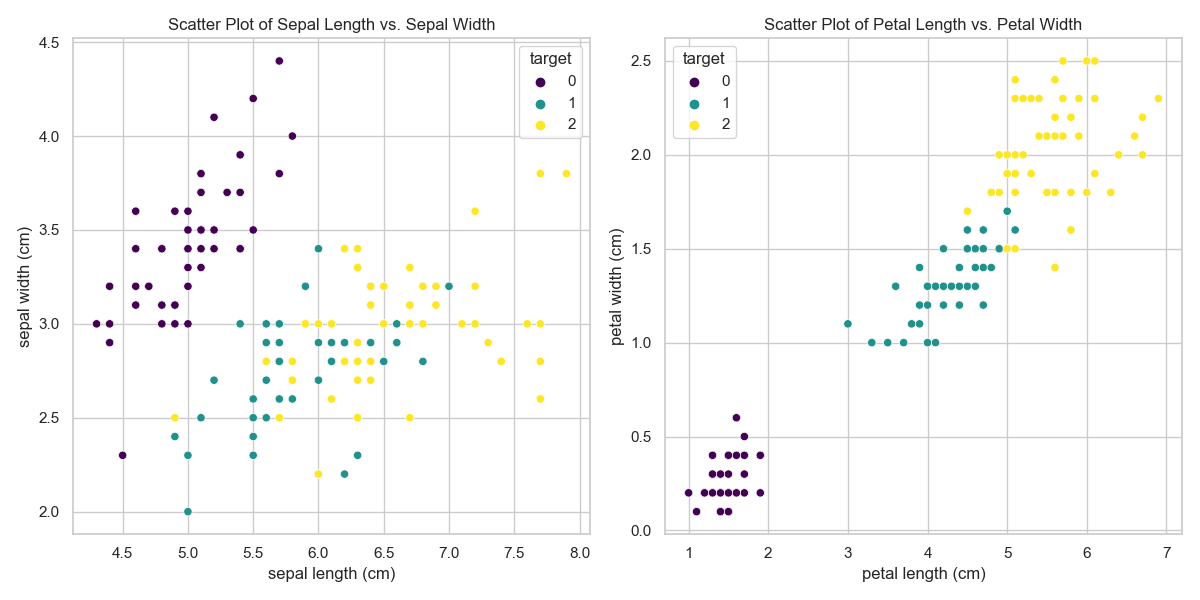
这些代码使用了
seaborn库,通过直方图展示了花萼和花瓣的长度和宽度的分布情况,并使用散点图展示了花萼长度和宽度以及花瓣长度和宽度之间的关系。这些可视化图表可以帮助你更好地了解数据集的特征和类别之间的差异。
相关文章:
【100天精通Python】Day75:Python机器学习-第一个机器学习小项目_鸾尾花分类项目(上)
目录 1 机器学习中的Helloworld _鸾尾花分类项目 2 导入项目所需类库和鸾尾花数据集 2.1 导入类库 2.2 scikit-learn 库介绍 (1)主要特点: (2)常见的子模块: 3 导入鸾尾花数据集 3.1 概述数据 3.…...
gitlab高级功能之容器镜像仓库
今天给大家介绍一个gitlab的高级功能 - Container Registry,该功能可以实现docker镜像的仓库功能,将gitlab上的代码仓的代码通过docker构建后并推入到容器仓库中,好处就是无需再额外部署一套docker仓库。 文章目录 1. 参考文档2. Container R…...
)
线程的使用(二)
新增实现方式之实现Callable接口 特点 1、可以有返回值。 2、方法可以抛异常。 3、支持泛型的返回值。 4、需借助FutureTask类,比如获取返回值。 步骤 1、创建一个实现Callable接口的实现类。 2、重写call方法, 将此线程需执行的操作声明在call&…...
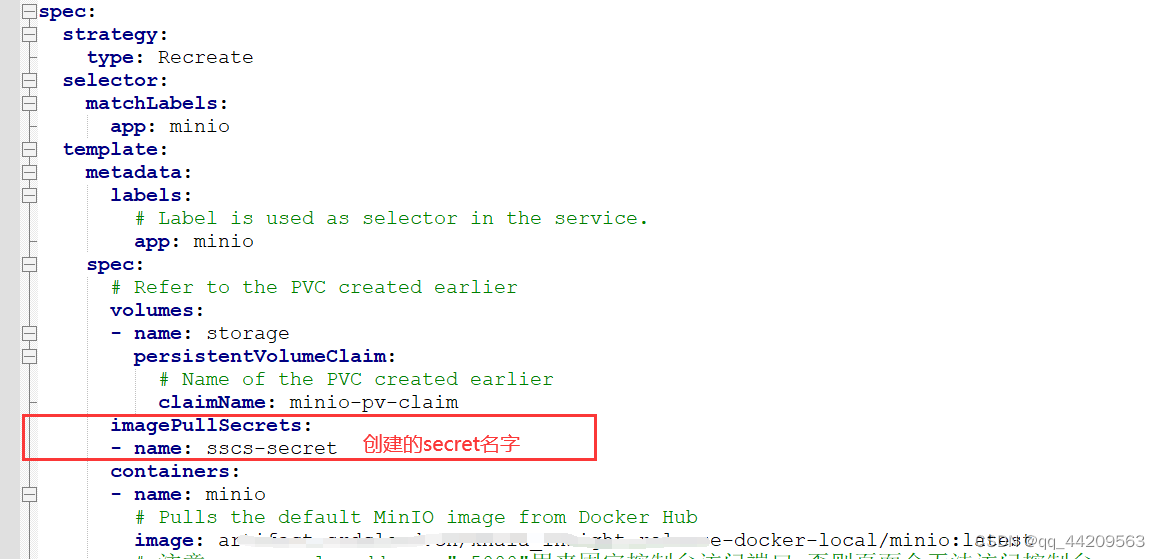
k8s之镜像拉取时使用secret
k8s之secret使用 一、说明二、secret使用2.1 secret类型2.2 创建secret2.3 配置secret 一、说明 从公司搭建的网站镜像仓库,使用k8s部署服务时拉取镜像失败,显示未授权: 需要在拉取镜像时添加认证信息. 关于secret信息,参考: https://www.…...

mysql面试题——MVCC
一:什么是MVCC? 多版本并发控制,更好的方式去处理读-写冲突,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。 二:…...
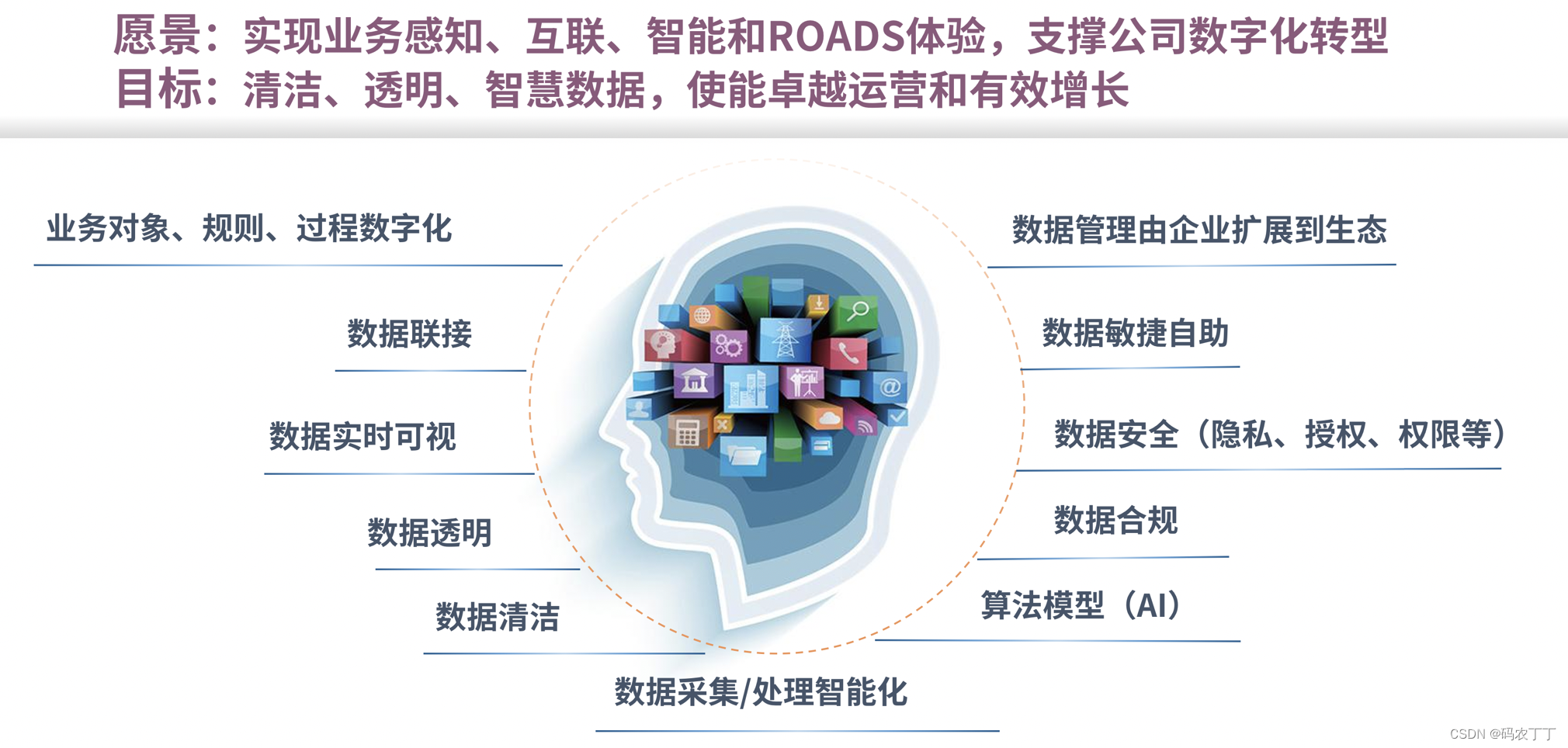
【华为数据之道学习笔记】1-2华为数字化转型与数据治理
传统企业通过制造先进的机器来提升生产效率,但是未来,如何结构性地提升服务和运营效率,如何用更低的成本获取更好的产品,成了时代性的问题。数字化转型归根结底就是要解决企业的两大问题:成本和效率,并围绕…...
微服务01
笔记: day03-微服务01 - 飞书云文档 (feishu.cn) 数据库连接不上? 要在虚拟机启动MySQL容器。docker start mysql 服务治理 服务提供者:暴露服务接口,供其他服务调用 服务消费者:调用其他服务提供的接口 注册中心&…...
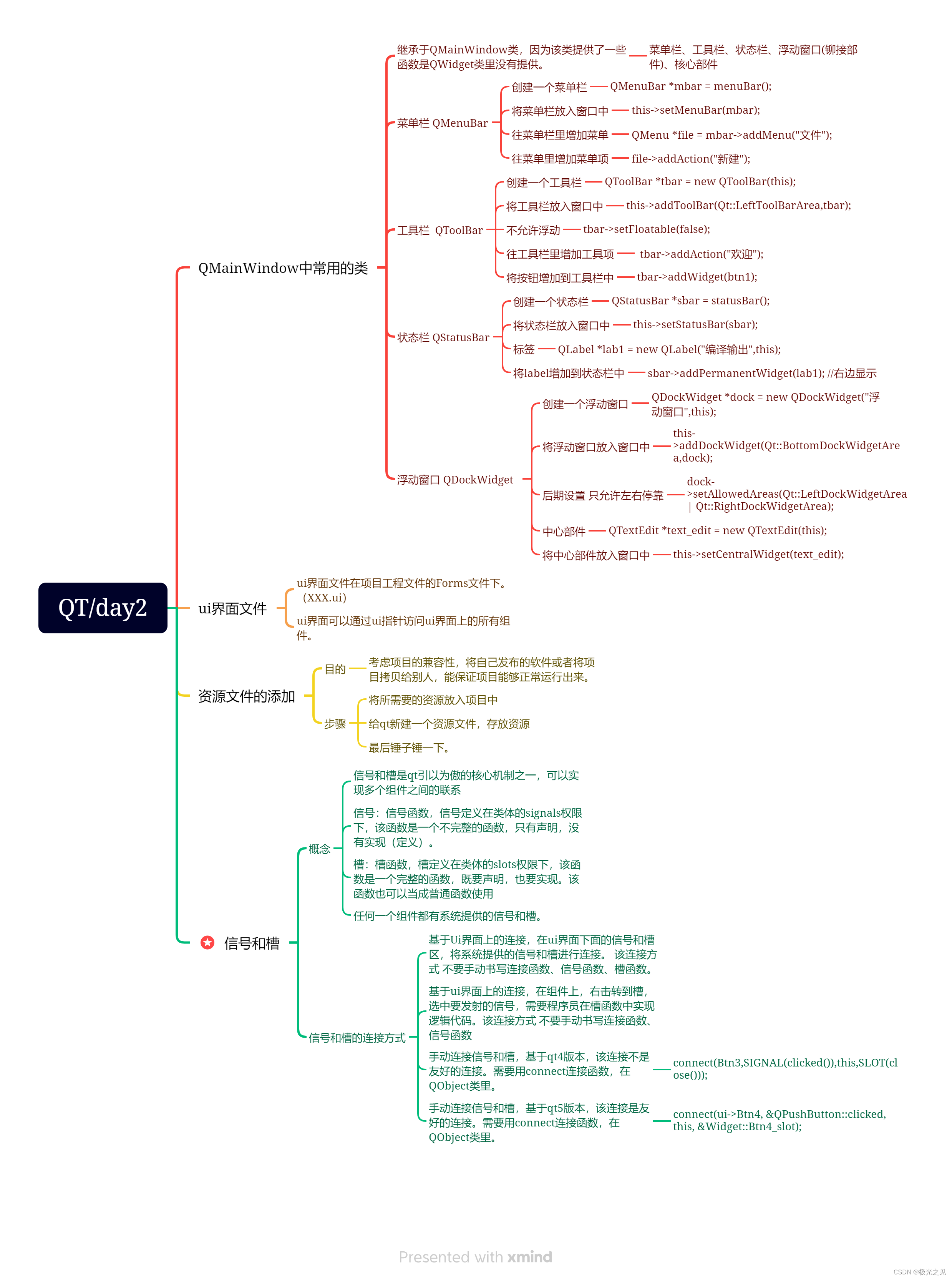
作业12.8
1. 使用手动连接,将登录框中的取消按钮使用qt4版本的连接到自定义的槽函数中,在自定义的槽函数中调用关闭函数。将登录按钮使用qt5版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin",密码是…...

已解决error: (-215:Assertion failed) inv_scale_x > 0 in function ‘cv::resize‘
需求背景 欲使用opencv的resize函数将图像沿着纵轴放大一倍,即原来的图像大小为(384, 512), 现在需要将图像放大为(768, 512)。 源码 import cv2 import numpy as np# 生成初始图像 img np.zeros((384, 512), dtypenp.uint8) img[172:212, 32:-32] 255 H, W …...

Android View.inflate 和 LayoutInflater.from(this).inflate 的区别
前言 两个都是布局加载器,而View.inflate是对 LayoutInflater.from(context).inflate的封装,功能相同,案例使用了dataBinding。 View.inflate(context, layoutResId, root) LayoutInflater.from(context).inflate(layoutResId, root, fals…...
etcd 与 Consul 的一致性读对比
本文分享和对比了 etcd 和 Consul 这两个存储的一致性读的实现。 作者:戴岳兵,爱可生研发中心工程师,负责项目的需求开发与维护工作。 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 本…...
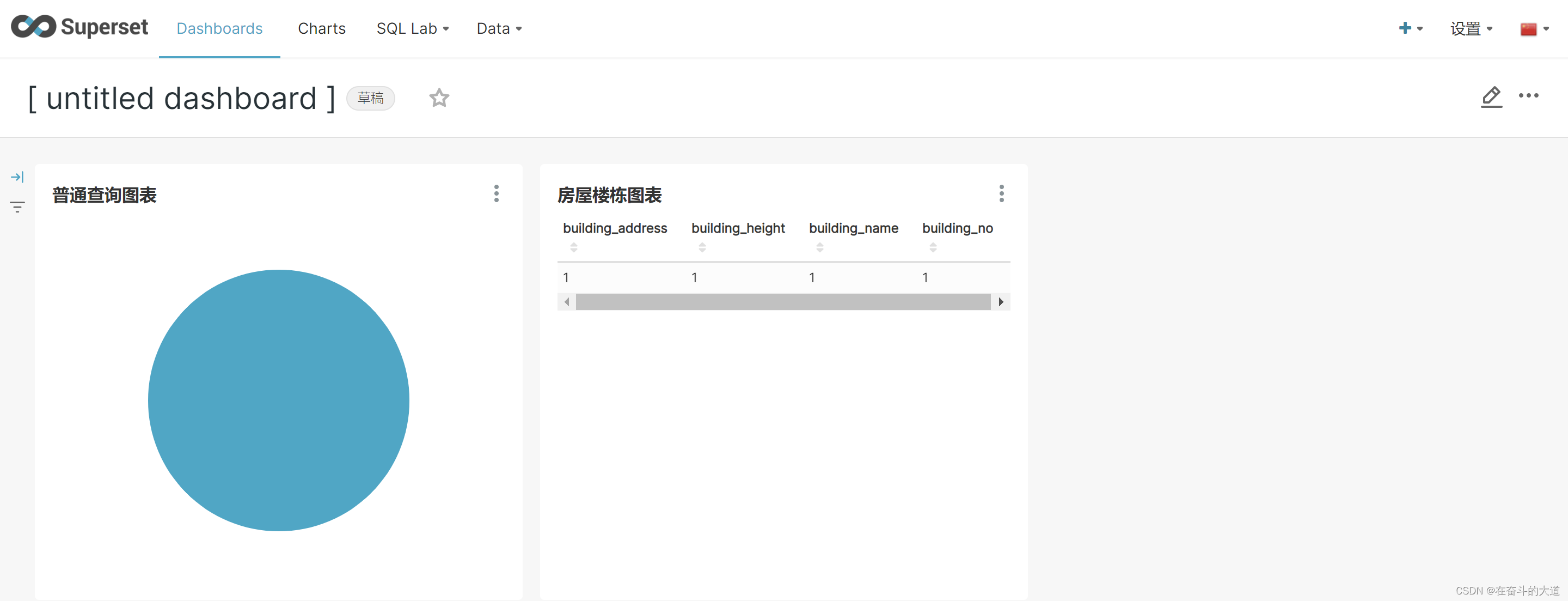
Docker 安装Apache Superset 并实现汉化和快速入门
什么是Apache Superset Apache Superset是一个现代化的企业级商业智能Web应用程序。Apache Superset 支持用户的各种数据类型可视化和数据分析,支持简单图饼图到复杂的地理空间图表。Apache Superset 是一个轻量级、简单化、直观化、可配置的BI 框架。 Docker 安…...
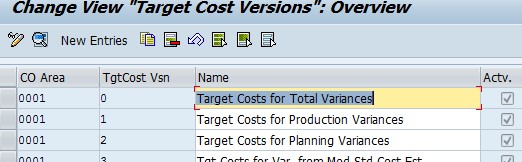
差异计算基础知识 - 了解期末业务操作、WIP 和差异
原文地址:Basics of variance calculation-Understanding Period End activities, WIP and Variances | SAP Blogs 大家好, 这是我在成本核算方面的第六份文件,旨在解释期末的差异计算和相关活动。 我将引导您完成期末活动和差异计算。在本文…...
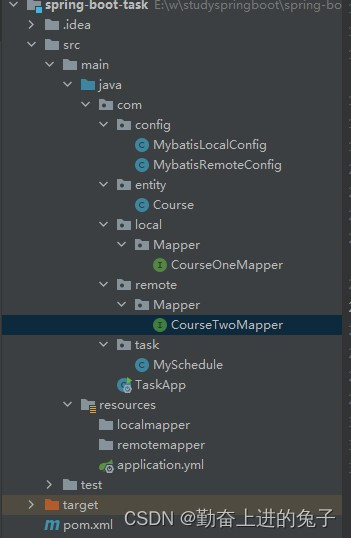
spring boot定时器实现定时同步数据
文章目录 目录 文章目录 前言 一、依赖和目录结构 二、使用步骤 2.1 两个数据源的不同引用配置 2.2 对应的mapper 2.3 定时任务处理 总结 前言 一、依赖和目录结构 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifa…...

第一百九十六回 通过蓝牙发送数据的细节
文章目录 1. 概念介绍2. 实现方法3. 代码与效果3.1 示例代码3.2 运行效果4. 经验总结我们在上一章回中介绍了"分享三个使用TextField的细节"沉浸式状态样相关的内容,本章回中将介绍SliverList组件.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 通过蓝牙设备…...

26.Python 网络爬虫
目录 1.网络爬虫简介2.使用urllib3.使用request4.使用BeautifulSoup 1.网络爬虫简介 网络爬虫是一种按照一定的规则,自动爬去万维网信息的程序或脚本。一般从某个网站某个网页开始,读取网页的内容,同时检索页面包含的有用链接地址࿰…...

Spring Boot 在启动之前还做了哪些准备工作?
目录 一:初始化资源加载器 二:校验主要源 三:设置主要源 四:推断 Web 应用类型<...
)
SQL语句常用语法(开发场景中)
一、SQL语句常用小场景 1.查询某个表信息,表中某些字段为数据字典需要进行转义 SELECTt.ID,CASEWHEN t.DINING_TYPE 1 THEN早餐WHEN t.DINING_TYPE 2 THEN午餐WHEN t.DINING_TYPE 3 THEN晚餐END AS diningTypeStr from student t 2.联表查询语法 select si.*…...

HarmonyOS应用开发者认证:开启全新的智能设备开发之旅
随着科技的不断发展,人工智能、物联网等技术逐渐渗透到我们的日常生活中。在这个智能化的时代,华为推出了一款全新的操作系统——HarmonyOS,旨在为各种智能设备提供统一的操作系统,实现设备之间的无缝连接和协同工作。作为开发者&…...

Python 模板引擎 Jinja2 的安装和使用
目录 一、概述 二、安装 Jinja2 三、使用 Jinja2 四、Jinja2的强大功能和优点 五、总结 一、概述 Jinja2 是 Python 中广泛使用的一种模板引擎,它具有灵活的语法、强大的控制结构、方便的 API,以及高效的渲染速度。通过使用 Jinja2,开发…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...