【项目设计】高并发内存池 (四)[pagecache实现]
🎇C++学习历程:入门
- 博客主页:一起去看日落吗
- 持续分享博主的C++学习历程
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记,树🌿成长之前也要扎根,也要在漫长的时光🌞中沉淀养分。静下来想一想,哪有这么多的天赋异禀,那些让你羡慕的优秀的人也都曾默默地翻山越岭🐾。

🍁 🍃 🍂 🌿
目录
- 🍁1. pagecache
- 🍂1.1 pagecache整体设计
- 🍂1.2 pagecache中获取Span
- 🍁2. 申请内存过程联调
🍁1. pagecache
🍂1.1 pagecache整体设计
- page cache与central cache结构的相同之处
page cache与central cache一样,它们都是哈希桶的结构,并且page cache的每个哈希桶中里挂的也是一个个的span,这些span也是按照双链表的结构链接起来的。
- page cache与central cache结构的不同之处
首先,central cache的映射规则与thread cache保持一致,而page cache的映射规则与它们都不相同。page cache的哈希桶映射规则采用的是直接定址法,比如1号桶挂的都是1页的span,2号桶挂的都是2页的span,以此类推。
其次,central cache每个桶中的span被切成了一个个对应大小的对象,以供thread cache申请。而page cache当中的span是没有被进一步切小的,因为page cache服务的是central cache,当central cache没有span时,向page cache申请的是某一固定页数的span,而如何切分申请到的这个span就应该由central cache自己来决定。
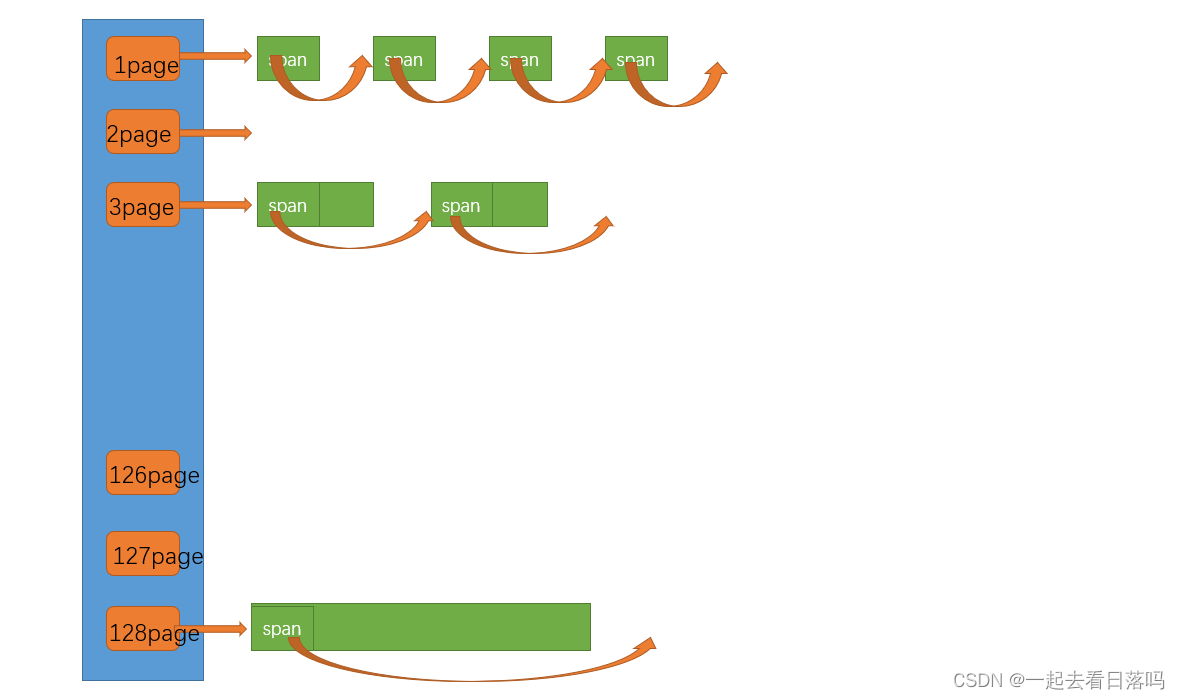
至于page cache当中究竟有多少个桶,这就要看你最大想挂几页的span了,这里我们就最大挂128页的span,为了让桶号与页号对应起来,我们可以将第0号桶空出来不用,因此我们需要将哈希桶的个数设置为129。
//page cache中哈希桶的个数
static const size_t NPAGES = 129;
为什么这里最大挂128页的span呢?因为线程申请单个对象最大是256KB,而128页可以被切成4个256KB的对象,因此是足够的。当然,如果你想在page cache中挂更大的span也是可以的,根据具体的需求进行设置就行了。
- 在page cache获取一个n页的span的过程
如果central cache要获取一个n页的span,那我们就可以在page cache的第n号桶中取出一个span返回给central cache即可,但如果第n号桶中没有span了,这时我们并不是直接转而向堆申请一个n页的span,而是要继续在后面的桶当中寻找span。
直接向堆申请以页为单位的内存时,我们应该尽量申请大块一点的内存块,因为此时申请到的内存是连续的,当线程需要内存时我们可以将其切小后分配给线程,而当线程将内存释放后我们又可以将其合并成大块的连续内存。如果我们向堆申请内存时是小块小块的申请的,那么我们申请到的内存就不一定是连续的了。
因此,当第n号桶中没有span时,我们可以继续找第n+1号桶,因为我们可以将n+1页的span切分成一个n页的span和一个1页的span,这时我们就可以将n页的span返回,而将切分后1页的span挂到1号桶中。但如果后面的桶当中都没有span,这时我们就只能向堆申请一个128页的内存块,并将其用一个span结构管理起来,然后将128页的span切分成n页的span和128-n页的span,其中n页的span返回给central cache,而128-n页的span就挂到第128-n号桶中。
也就是说,我们每次向堆申请的都是128页大小的内存块,central cache要的这些span实际都是由128页的span切分出来的。
- page cache的实现方式
当每个线程的thread cache没有内存时都会向central cache申请,此时多个线程的thread cache如果访问的不是central cache的同一个桶,那么这些线程是可以同时进行访问的。这时central cache的多个桶就可能同时向page cache申请内存的,所以page cache也是存在线程安全问题的,因此在访问page cache时也必须要加锁。
但是在page cache这里我们不能使用桶锁,因为当central cache向page cache申请内存时,page cache可能会将其他桶当中大页的span切小后再给central cache。此外,当central cache将某个span归还给page cache时,page cache也会尝试将该span与其他桶当中的span进行合并。
也就是说,在访问page cache时,我们可能需要访问page cache中的多个桶,如果page cache用桶锁就会出现大量频繁的加锁和解锁,导致程序的效率低下。因此我们在访问page cache时使用没有使用桶锁,而是用一个大锁将整个page cache给锁住。
而thread cache在访问central cache时,只需要访问central cache中对应的哈希桶就行了,因为central cache的每个哈希桶中的span都被切分成了对应大小,thread cache只需要根据自己所需对象的大小访问central cache中对应的哈希桶即可,不会访问其他哈希桶,因此central cache可以用桶锁。
此外,page cache在整个进程中也是只能存在一个的,因此我们也需要将其设置为单例模式
//单例模式
class PageCache
{
public://提供一个全局访问点static PageCache* GetInstance(){return &_sInst;}
private:SpanList _spanLists[NPAGES];std::mutex _pageMtx; //大锁
private:PageCache() //构造函数私有{}PageCache(const PageCache&) = delete; //防拷贝static PageCache _sInst;
};
当程序运行起来后我们就立马创建该对象即可。
PageCache PageCache::_sInst;
🍂1.2 pagecache中获取Span
- 获取一个非空的span
thread cache向central cache申请对象时,central cache需要先从对应的哈希桶中获取到一个非空的span,然后从这个非空的span中取出若干对象返回给thread cache。那central cache到底是如何从对应的哈希桶中,获取到一个非空的span的呢?
首先当然是先遍历central cache对应哈希桶当中的双链表,如果该双链表中有非空的span,那么直接将该span进行返回即可。为了方便遍历这个双链表,我们可以模拟迭代器的方式,给SpanList类提供Begin和End成员函数,分别用于获取双链表中的第一个span和最后一个span的下一个位置,也就是头结点。
//带头双向循环链表
class SpanList
{
public:Span* Begin(){return _head->_next;}Span* End(){return _head;}
private:Span* _head;
public:std::mutex _mtx; //桶锁
};
但如果遍历双链表后发现双链表中没有span,或该双链表中的span都为空,那么此时central cache就需要向page cache申请内存块了。
那具体是向page cache申请多大的内存块呢?我们可以根据具体所需对象的大小来决定,就像之前我们根据对象的大小计算出,thread cache一次向central cache申请对象的个数上限,现在我们是根据对象的大小计算出,central cache一次应该向page cache申请几页的内存块。
我们可以先根据对象的大小计算出,thread cache一次向central cache申请对象的个数上限,然后将这个上限值乘以单个对象的大小,就算出了具体需要多少字节,最后再将这个算出来的字节数转换为页数,如果转换后不够一页,那么我们就申请一页,否则转换出来是几页就申请几页。也就是说,central cache向page cache申请内存时,要求申请到的内存尽量能够满足thread cache向central cache申请时的上限。
//管理对齐和映射等关系
class SizeClass
{
public://central cache一次向page cache获取多少页static size_t NumMovePage(size_t size){size_t num = NumMoveSize(size); //计算出thread cache一次向central cache申请对象的个数上限size_t nPage = num*size; //num个size大小的对象所需的字节数nPage >>= PAGE_SHIFT; //将字节数转换为页数if (nPage == 0) //至少给一页nPage = 1;return nPage;}
};
代码中的PAGE_SHIFT代表页大小转换偏移,我们这里以页的大小为8K为例,PAGE_SHIFT的值就是13。
//页大小转换偏移,即一页定义为2^13,也就是8KB
static const size_t PAGE_SHIFT = 13;
需要注意的是,当central cache申请到若干页的span后,还需要将这个span切成一个个对应大小的对象挂到该span的自由链表当中。
如何找到一个span所管理的内存块呢?首先需要计算出该span的起始地址,我们可以用这个span的起始页号乘以一页的大小即可得到这个span的起始地址,然后用这个span的页数乘以一页的大小就可以得到这个span所管理的内存块的大小,用起始地址加上内存块的大小即可得到这块内存块的结束位置。
明确了这块内存的起始和结束位置后,我们就可以进行切分了。根据所需对象的大小,每次从大块内存切出一块固定大小的内存块尾插到span的自由链表中即可。
为什么是尾插呢?因为我们如果是将切好的对象尾插到自由链表,这些对象看起来是按照链式结构链接起来的,而实际它们在物理上是连续的,这时当我们把这些连续内存分配给某个线程使用时,可以提高该线程的CPU缓存利用率。
//获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& spanList, size_t size)
{//1、先在spanList中寻找非空的spanSpan* it = spanList.Begin();while (it != spanList.End()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}//2、spanList中没有非空的span,只能向page cache申请Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));//计算span的大块内存的起始地址和大块内存的大小(字节数)char* start = (char*)(span->_pageId << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;//把大块内存切成size大小的对象链接起来char* end = start + bytes;//先切一块下来去做尾,方便尾插span->_freeList = start;start += size;void* tail = span->_freeList;//尾插while (start < end){NextObj(tail) = start;tail = NextObj(tail);start += size;}NextObj(tail) = nullptr; //尾的指向置空//将切好的span头插到spanListspanList.PushFront(span);return span;
}
需要注意的是,当我们把span切好后,需要将这个切好的span挂到central cache的对应哈希桶中。因此SpanList类还需要提供一个接口,用于将一个span插入到该双链表中。这里我们选择的是头插,这样当central cache下一次从该双链表中获取非空span时,一来就能找到。
由于SpanList类之前实现了Insert和Begin函数,这里实现双链表头插就非常简单,直接在双链表的Begin位置进行Insert即可。
- 获取一个k页的span
当我们调用上述的GetOneSpan从central cache的某个哈希桶获取一个非空的span时,如果遍历哈希桶中的双链表后发现双链表中没有span,或该双链表中的span都为空,那么此时central cache就需要向page cache申请若干页的span了,下面我们就来说说如何从page cache获取一个k页的span。
因为page cache是直接按照页数进行映射的,因此我们要从page cache获取一个k页的span,就应该直接先去找page cache的第k号桶,如果第k号桶中有span,那我们直接头删一个span返回给central cache就行了。所以我们这里需要再给SpanList类添加对应的Empty和PopFront函数。
``cpp
//带头双向循环链表
class SpanList
{
public:void PushFront(Span* span){Insert(Begin(), span);}bool Empty(){return _head == _head->_next;}Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}private:Span* _head;
public:std::mutex _mtx; //桶锁
};
如果page cache的第k号桶中没有span,我们就应该继续找后面的桶,只要后面任意一个桶中有一个n页span,我们就可以将其切分成一个k页的span和一个n-k页的span,然后将切出来k页的span返回给central cache,再将n-k页的span挂到page cache的第n-k号桶即可。
但如果后面的桶中也都没有span,此时我们就需要向堆申请一个128页的span了,在向堆申请内存时,直接调用我们封装的SystemAlloc函数即可。
需要注意的是,向堆申请内存后得到的是这块内存的起始地址,此时我们需要将该地址转换为页号。由于我们向堆申请内存时都是按页进行申请的,因此我们直接将该地址除以一页的大小即可得到对应的页号。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}//检查一下后面的桶里面有没有span,如果有可以将其进行切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan的头部切k页下来kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;//将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);//尽量避免代码重复,递归调用自己return NewSpan(k);
}
这里说明一下,当我们向堆申请到128页的span后,需要将其切分成k页的span和128-k页的span,但是为了尽量避免出现重复的代码,我们最好不要再编写对应的切分代码。我们可以先将申请到的128页的span挂到page cache对应的哈希桶中,然后再递归调用该函数就行了,此时在往后找span时就一定会在第128号桶中找到该span,然后进行切分。
这里其实有一个问题:当central cache向page cache申请内存时,central cache对应的哈希桶是处于加锁的状态的,那在访问page cache之前我们应不应该把central cache对应的桶锁解掉呢?
这里建议在访问page cache前,先把central cache对应的桶锁解掉。虽然此时central cache的这个桶当中是没有内存供其他thread cache申请的,但thread cache除了申请内存还会释放内存,如果在访问page cache前将central cache对应的桶锁解掉,那么此时当其他thread cache想要归还内存到central cache的这个桶时就不会被阻塞。
因此在调用NewSpan函数之前,我们需要先将central cache对应的桶锁解掉,然后再将page cache的大锁加上,当申请到k页的span后,我们需要将page cache的大锁解掉,但此时我们不需要立刻获取到central cache中对应的桶锁。因为central cache拿到k页的span后还会对其进行切分操作,因此我们可以在span切好后需要将其挂到central cache对应的桶上时,再获取对应的桶锁。
这里为了让代码清晰一点,只写出了加锁和解锁的逻辑,我们只需要将这些逻辑添加到之前实现的GetOneSpan函数的对应位置即可。
spanList._mtx.unlock(); //解桶锁
PageCache::GetInstance()->_pageMtx.lock(); //加大锁//从page cache申请k页的spanPageCache::GetInstance()->_pageMtx.unlock(); //解大锁//进行span的切分...spanList._mtx.lock(); //加桶锁//将span挂到central cache对应的哈希桶🍁2. 申请内存过程联调
- ConcurrentAlloc函数
在将thread cache、central cache以及page cache的申请流程写通了之后,我们就可以向外提供一个ConcurrentAlloc函数,用于申请内存块。每个线程第一次调用该函数时会通过TLS获取到自己专属的thread cache对象,然后每个线程就可以通过自己对应的thread cache申请对象了。
static void* ConcurrentAlloc(size_t size)
{//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}return pTLSThreadCache->Allocate(size);
}
里说一下编译时会出现的问题,在C++的algorithm头文件中有一个min函数,这是一个函数模板,而在Windows.h头文件中也有一个min,这是一个宏。由于调用函数模板时需要进行参数类型的推演,因此当我们调用min函数时,编译器会优先匹配Windows.h当中以宏的形式实现的min,此时当我们以std::min的形式调用min函数时就会产生报错,这就是没有用命名空间进行封装的坏处,这时我们只能选择将std::去掉,让编译器调用Windows.h当中的min。
相关文章:
【项目设计】高并发内存池 (四)[pagecache实现]
🎇C学习历程:入门 博客主页:一起去看日落吗持续分享博主的C学习历程博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记&…...

玩转qsort——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容还是我们的深度剖析指针呀,上篇博客我们学习了回调函数这个知识点,但是没有写完,因为:小雅兰觉得qsort值得单独写出来!!!好啦,就…...
【干货】又是一年跳槽季!Nginx 10道核心面试题及解析
Nginx是一款轻量级的高性能Web服务器和反向代理服务器,由俄罗斯的Igor Sysoev开发。它具有占用资源少、高并发、稳定性高等优点,被广泛应用于互联网领域。在Nginx的面试过程中,面试官通常会提出一些核心问题,本文将介绍一些常见的…...

【线程安全的HashMap有哪些,CurrentHashMap底层是怎么实现线程安全的】
在 Java 中,线程安全的 HashMap 通常有以下几种实现: Collections.synchronizedMap 方法:该方法可以将 HashMap 转换为线程安全的 Map。 Hashtable 类:Hashtable 是一种线程安全的集合类,它与 HashMap 类似࿰…...

C语言-结构体【详解】
一、 结构体的基础知识 结构是一些值的集合,这些值称为成员变量结构的每个成员可以是不同类型的变量 (1)结构体的声明 写法一: 注: 括号后边的分号不能忘结构体末尾可以不创建变量,在主函数中再创建 struc…...

浏览器输入url到页面渲染完成经历了哪些步骤
一、URL解析 这一步比较容易理解,在浏览器地址栏输入url后,浏览器会判断这个url的合法性 ,以及是否有可用缓存,如果判断是 url 则进行域名解析,如果不是 url ,则直接使用搜索引擎搜索 二、域名解析 输入…...
大数据技术之Hadoop(Yarn)
第1章Yarn资源调度器思考:1)如何管理集群资源?2)如何给任务合理分配资源?Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等…...

5.建造者模式
目录 简介 四个角色 应用场景 实现步骤 和工厂模式的区别 简介 建造者模式也叫生成器模式,是一种对象构建模式;它可以把复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象;…...

数据库基础-数据库基本概念(1-1)
你好,欢迎来到数据库基础系列专栏,欢迎留言互动哦~ 目录一、数据库基础1. 数据库基本概念1.1 数据库1.2 什么是数据库管理软件1.3 表1.4 行1.5 列和数据类型1.6 主键1.7 什么是 SQL一、数据库基础 1. 数据库基本概念 1.1 数据库 数据库是一个以某种有…...

学习笔记-架构的演进之服务容错策略-服务发现-3月day01
文章目录前言服务容错容错策略附前言 “容错性设计”(Design for Failure)是微服务的一个核心原则。 使用微服务架构,拆分出的服务越来越多,也逐渐导致以下问题: 某一个服务的崩溃,会导致所有用到这个服务…...
采编式AIGC视频生产流程编排实践
作者 | 百度人工智能创作团队 导读 本文从业务出发,系统介绍了采编式 TTV的实现逻辑和实现路径。结合业务拆解,实现了一个轻量级服务编排引擎,有效实现业务诉求、高效支持业务扩展。 全文6451字,预计阅读时间17分钟。 01 背景 近…...

Leetcode23. 合并k个升序链表
一、题目描述: 给你一个链表数组,每个链表都已经按升序排列。 请你将所有链表合并到一个升序链表中,返回合并后的链表。 示例 1: 输入:lists [[1,4,5],[1,3,4],[2,6]]输出:[1,1,2,3,4,4,5,6]解释&#…...

从用户出发,互联网产品策划方法论
【一】从用户到需求 产品经理需要具备两个非常重要的技能,一个叫策划,一个叫感知用户。 我们在分析问题的时候往往会说“这么做,我认为用户会怎么怎么样”、“用户会认为这样很不爽”,当我们这样说时,很有可能是把自己当成了用户,用某些特定的情感或记忆代表了用户。 当我…...

STM32 E18-D80NK红外检测
本文代码使用 HAL 库。 文章目录前言一、E18-D80NK 红外传感器:1. E18-D80NK 的介绍2. 电器特性二、红外检测小实验代码讲解三、实验现象总结前言 这篇文章介绍 如何使用 STM32 控制 E18-D80NK 进行红外检测。 一、E18-D80NK 红外传感器: 1. E18-D80N…...

Linux常用命令--进程和计划任务管理
一、程序和进程的关系 1、程序 ①保存在硬盘、光盘等介质中的可执行代码和数据 ②静态保存的代码 2、进程 ①在cpu及内存中运行及进程代码 ②动态执行的代码 ③父(fork)、子进程,每个程序可以创建一个或多个进程 父进程和子进程的区别&am…...

Unity TextMeshPro
Unity TextMeshPro 简介 TextMeshPro(也简称为TMP)号称是Unity的终极文本解决方案,它是Unity 的 UI 文本和旧版文本网格体的完美替代品。 功能强大且易于使用,使用高级文本渲染技术以及一组自定义着色器;提供实质性的视觉质量改进,同时在文本样式和纹理方面为用户提供令人…...
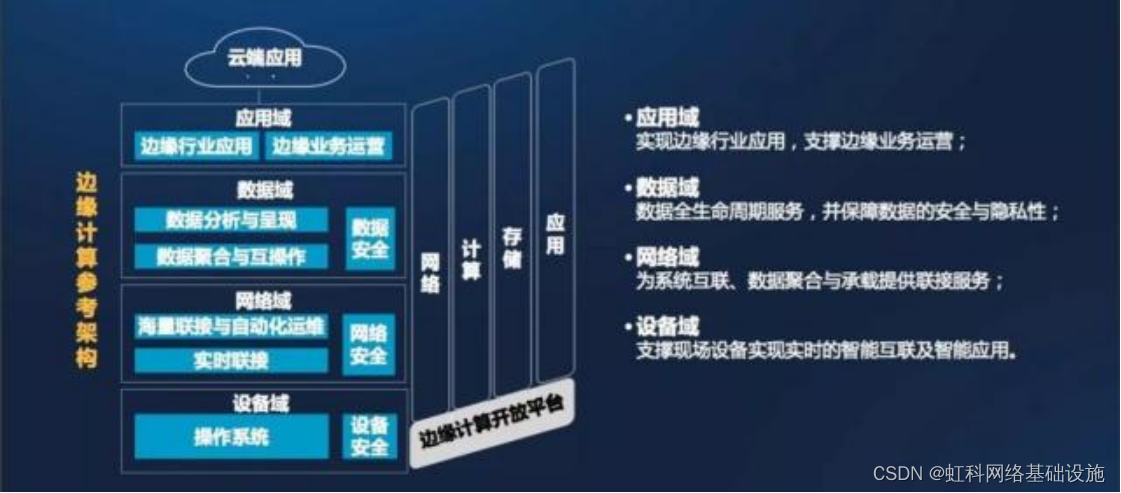
虹科分享| 浅谈HK-Edgility边缘计算平台
上周,我们推出了虹科新品HK-Edgility边缘计算平台以及uCPE解决方案。本篇文章我们再来谈一谈到底什么是边缘计算?为什么需要边缘计算?边缘计算和云计算有什么关系?HK-Edgility边缘计算平台将为您带来什么?一、边缘计算…...

React Router v6详解
旧版本React Router使用方式 BrowserRouter:通过 history 库,传递 history 对象,location 对象Switch:匹配唯一的路由 Route,展示正确的路由组件Route:视图承载容器,控制渲染 UI 组件 新版本R…...

帮助100w人成功入职的软件测试面试常见问题以及答案
测试面试题怎么来设计测试方案根据测试需求(包括功能需求和非功能性需求),识别测试要点,识别测试环境要求,安排测试轮次,根据项目计划和开发计划做整体的测试安排。被测试的特性:通过对需求规格…...

tensorflow2.4--2.回归问题分析
文章目录前言流程案例操作前言 流程 回归问题预测连续值,在某个区间内变动. 常见的线性回归问题模型是yaxb,然而现实世界由于大量的数据偏差以及复杂度,同时还有大量的噪声,往往达不到如此的精确解,实际解决问题时需要考虑噪声的存在 对于噪声,往往我们已经假设了它符合高斯…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...