YOLOv8改进 | 2023检测头篇 | 利用AFPN改进检测头适配YOLOv8版(全网独家创新)
一、本文介绍
本文给大家带来的改进机制是利用今年新推出的AFPN(渐近特征金字塔网络)来优化检测头,AFPN的核心思想是通过引入一种渐近的特征融合策略,将底层、高层和顶层的特征逐渐整合到目标检测过程中。这种渐近融合方式有助于减小不同层次特征之间的语义差距,提高特征融合效果,使得检测模型能更好地适应不同层次的语义信息。本文在AFPN的结构基础上,为了适配YOLOv8改进AFPN结构,同时将AFPN融合到YOLOv8中(因为AFPN需要四个检测头,我们只有三个,下一篇文章我会出YOLOv8适配AFPN增加小目标检测头)实现暴力涨点。
推荐指数:⭐⭐⭐⭐
打星原因:为什么打四颗星是因为我觉得这个机制的计算量会上涨,这是扣分点,同时替换这个检测头刚开始前20个epochs的效果不好,随着轮次的增加涨幅才能体现出来,这也是扣分点,我给结构打分完全是客观的,并不是我推出的结构必须满分。
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
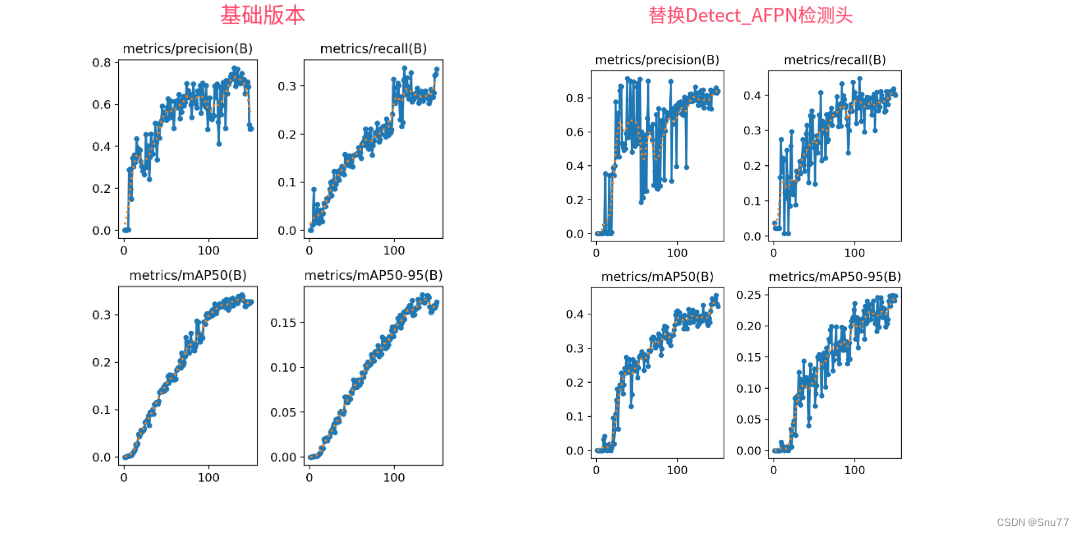
训练结果对比图->
这次试验我用的数据集大概有七八百张照片训练了150个epochs,虽然没有完全拟合但是效果有一定的涨点幅度,所以大家可以进行尝试毕竟不同的数据集上效果也可能差很多,同时我在后面给了多种yaml文件大家可以分别进行实验来检验效果。
目录
一、本文介绍
二、AFPN基本框架原理编辑
2.1 AFPN的基本原理
三、Detect_AFPN完整代码
四、手把手教你添加Detect_AFPN检测头
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
4.5 修改五
4.6 修改六
4.7 修改七
4.8 修改八
4.9 修改九
五、Detect_AFPN检测头的yaml文件
六、完美运行记录
七、本文总结
二、AFPN基本框架原理
论文地址:官方论文地址
代码地址:官方代码地址

2.1 AFPN的基本原理
AFPN的核心思想是通过引入一种渐近的特征融合策略,将底层、高层和顶层的特征逐渐整合到目标检测过程中。这种渐近融合方式有助于减小不同层次特征之间的语义差距,提高特征融合效果,使得检测模型能更好地适应不同层次的语义信息。
主要改进机制:
1. 底层特征融合: AFPN通过引入底层特征的逐步融合,首先融合底层特征,接着深层特征,最后整合顶层特征。这种层级融合的方式有助于更好地利用不同层次的语义信息,提高检测性能。
2. 自适应空间融合: 引入自适应空间融合机制(ASFF),在多级特征融合过程中引入变化的空间权重,加强关键级别的重要性,同时抑制来自不同对象的矛盾信息的影响。这有助于提高检测性能,尤其在处理矛盾信息时更为有效。
3. 底层特征对齐: AFPN采用渐近融合的思想,使得不同层次的特征在融合过程中逐渐接近,减小它们之间的语义差距。通过底层特征的逐步整合,提高了特征融合的效果,使得模型更能理解和利用不同层次的信息。
个人总结:AFPN的灵感就像是搭积木一样,它不是一下子把所有的积木都放到一起,而是逐步地将不同层次的积木慢慢整合在一起。这样一来,我们可以更好地理解和利用每一层次的积木,从而构建一个更牢固的目标检测系统。同时,引入了一种智能的机制,能够根据不同情况调整注意力,更好地处理矛盾信息。

上面上AFPN的网络结构,可以看出从Backbone中提取出特征之后,将特征输入到AFPN中进行处理,然后它可以获得不同层级的特征进行融合,这也是它的主要思想质疑,同时将结果输入到检测头中进行预测。
(需要注意的是本文砍掉了最下面那一条线适应YOLOv8因为我们是三个检测头,下一篇文章我会出增加小目标检测头的然后四个头的yolov8改进,从而适应AFPN的结构)。
三、Detect_AFPN完整代码
这里代码是我对于2023年新提出的AFPN进行了修改然后适配YOLOv8的整体结构提出的检测头,本来该结构是四个检测头部分,但是我去除掉了一个从而适配yolov8,当然在我也在出一篇文章里会用到四头的(增加辅助训练头,针对小目标检测)讲解(要不然一个博客放不下 这么多代码)。
import math
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules import DFL
from ultralytics.nn.modules.conv import Conv
from ultralytics.utils.tal import dist2bbox, make_anchors__all__ =['Detect_AFPN']def BasicConv(filter_in, filter_out, kernel_size, stride=1, pad=None):if not pad:pad = (kernel_size - 1) // 2 if kernel_size else 0else:pad = padreturn nn.Sequential(OrderedDict([("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=stride, padding=pad, bias=False)),("bn", nn.BatchNorm2d(filter_out)),("relu", nn.ReLU(inplace=True)),]))class BasicBlock(nn.Module):expansion = 1def __init__(self, filter_in, filter_out):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(filter_in, filter_out, 3, padding=1)self.bn1 = nn.BatchNorm2d(filter_out, momentum=0.1)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(filter_out, filter_out, 3, padding=1)self.bn2 = nn.BatchNorm2d(filter_out, momentum=0.1)def forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out += residualout = self.relu(out)return outclass Upsample(nn.Module):def __init__(self, in_channels, out_channels, scale_factor=2):super(Upsample, self).__init__()self.upsample = nn.Sequential(BasicConv(in_channels, out_channels, 1),nn.Upsample(scale_factor=scale_factor, mode='bilinear'))def forward(self, x):x = self.upsample(x)return xclass Downsample_x2(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample_x2, self).__init__()self.downsample = nn.Sequential(BasicConv(in_channels, out_channels, 2, 2, 0))def forward(self, x, ):x = self.downsample(x)return xclass Downsample_x4(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample_x4, self).__init__()self.downsample = nn.Sequential(BasicConv(in_channels, out_channels, 4, 4, 0))def forward(self, x, ):x = self.downsample(x)return xclass Downsample_x8(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample_x8, self).__init__()self.downsample = nn.Sequential(BasicConv(in_channels, out_channels, 8, 8, 0))def forward(self, x, ):x = self.downsample(x)return xclass ASFF_2(nn.Module):def __init__(self, inter_dim=512):super(ASFF_2, self).__init__()self.inter_dim = inter_dimcompress_c = 8self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)def forward(self, input1, input2):level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced)return outclass ASFF_3(nn.Module):def __init__(self, inter_dim=512):super(ASFF_3, self).__init__()self.inter_dim = inter_dimcompress_c = 8self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_3 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)def forward(self, input1, input2, input3):level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)level_3_weight_v = self.weight_level_3(input3)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v, level_3_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :] + \input3 * levels_weight[:, 2:, :, :]out = self.conv(fused_out_reduced)return outclass ASFF_4(nn.Module):def __init__(self, inter_dim=512):super(ASFF_4, self).__init__()self.inter_dim = inter_dimcompress_c = 8self.weight_level_0 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)def forward(self, input0, input1, input2):level_0_weight_v = self.weight_level_0(input0)level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = input0 * levels_weight[:, 0:1, :, :] + \input1 * levels_weight[:, 1:2, :, :] + \input2 * levels_weight[:, 2:3, :, :]out = self.conv(fused_out_reduced)return outclass BlockBody(nn.Module):def __init__(self, channels=[64, 128, 256, 512]):super(BlockBody, self).__init__()self.blocks_scalezero1 = nn.Sequential(BasicConv(channels[0], channels[0], 1),)self.blocks_scaleone1 = nn.Sequential(BasicConv(channels[1], channels[1], 1),)self.blocks_scaletwo1 = nn.Sequential(BasicConv(channels[2], channels[2], 1),)self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])self.asff_scaleone1 = ASFF_2(inter_dim=channels[1])self.blocks_scalezero2 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone2 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)self.downsample_scalezero2_2 = Downsample_x2(channels[0], channels[1])self.downsample_scalezero2_4 = Downsample_x4(channels[0], channels[2])self.downsample_scaleone2_2 = Downsample_x2(channels[1], channels[2])self.upsample_scaleone2_2 = Upsample(channels[1], channels[0], scale_factor=2)self.upsample_scaletwo2_2 = Upsample(channels[2], channels[1], scale_factor=2)self.upsample_scaletwo2_4 = Upsample(channels[2], channels[0], scale_factor=4)self.asff_scalezero2 = ASFF_3(inter_dim=channels[0])self.asff_scaleone2 = ASFF_3(inter_dim=channels[1])self.asff_scaletwo2 = ASFF_3(inter_dim=channels[2])self.blocks_scalezero3 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone3 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)self.blocks_scaletwo3 = nn.Sequential(BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),)self.downsample_scalezero3_2 = Downsample_x2(channels[0], channels[1])self.downsample_scalezero3_4 = Downsample_x4(channels[0], channels[2])self.upsample_scaleone3_2 = Upsample(channels[1], channels[0], scale_factor=2)self.downsample_scaleone3_2 = Downsample_x2(channels[1], channels[2])self.upsample_scaletwo3_4 = Upsample(channels[2], channels[0], scale_factor=4)self.upsample_scaletwo3_2 = Upsample(channels[2], channels[1], scale_factor=2)self.asff_scalezero3 = ASFF_4(inter_dim=channels[0])self.asff_scaleone3 = ASFF_4(inter_dim=channels[1])self.asff_scaletwo3 = ASFF_4(inter_dim=channels[2])self.blocks_scalezero4 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone4 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)self.blocks_scaletwo4 = nn.Sequential(BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),)def forward(self, x):x0, x1, x2 = xx0 = self.blocks_scalezero1(x0)x1 = self.blocks_scaleone1(x1)x2 = self.blocks_scaletwo1(x2)scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))scaleone = self.asff_scaleone1(self.downsample_scalezero1_2(x0), x1)x0 = self.blocks_scalezero2(scalezero)x1 = self.blocks_scaleone2(scaleone)scalezero = self.asff_scalezero2(x0, self.upsample_scaleone2_2(x1), self.upsample_scaletwo2_4(x2))scaleone = self.asff_scaleone2(self.downsample_scalezero2_2(x0), x1, self.upsample_scaletwo2_2(x2))scaletwo = self.asff_scaletwo2(self.downsample_scalezero2_4(x0), self.downsample_scaleone2_2(x1), x2)x0 = self.blocks_scalezero3(scalezero)x1 = self.blocks_scaleone3(scaleone)x2 = self.blocks_scaletwo3(scaletwo)scalezero = self.asff_scalezero3(x0, self.upsample_scaleone3_2(x1), self.upsample_scaletwo3_4(x2))scaleone = self.asff_scaleone3(self.downsample_scalezero3_2(x0), x1, self.upsample_scaletwo3_2(x2))scaletwo = self.asff_scaletwo3(self.downsample_scalezero3_4(x0), self.downsample_scaleone3_2(x1), x2)scalezero = self.blocks_scalezero4(scalezero)scaleone = self.blocks_scaleone4(scaleone)scaletwo = self.blocks_scaletwo4(scaletwo)return scalezero, scaleone, scaletwoclass AFPN(nn.Module):def __init__(self,in_channels=[256, 512, 1024, 2048],out_channels=128):super(AFPN, self).__init__()self.fp16_enabled = Falseself.conv0 = BasicConv(in_channels[0], in_channels[0] // 8, 1)self.conv1 = BasicConv(in_channels[1], in_channels[1] // 8, 1)self.conv2 = BasicConv(in_channels[2], in_channels[2] // 8, 1)# self.conv3 = BasicConv(in_channels[3], in_channels[3] // 8, 1)self.body = nn.Sequential(BlockBody([in_channels[0] // 8, in_channels[1] // 8, in_channels[2] // 8]))self.conv00 = BasicConv(in_channels[0] // 8, out_channels, 1)self.conv11 = BasicConv(in_channels[1] // 8, out_channels, 1)self.conv22 = BasicConv(in_channels[2] // 8, out_channels, 1)# self.conv33 = BasicConv(in_channels[3] // 8, out_channels, 1)# init weightfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.xavier_normal_(m.weight, gain=0.02)elif isinstance(m, nn.BatchNorm2d):torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)def forward(self, x):x0, x1, x2 = xx0 = self.conv0(x0)x1 = self.conv1(x1)x2 = self.conv2(x2)# x3 = self.conv3(x3)out0, out1, out2 = self.body([x0, x1, x2])out0 = self.conv00(out0)out1 = self.conv11(out1)out2 = self.conv22(out2)return out0, out1, out2class Detect_AFPN(nn.Module):"""YOLOv8 Detect head for detection models."""dynamic = False # force grid reconstructionexport = False # export modeshape = Noneanchors = torch.empty(0) # initstrides = torch.empty(0) # initdef __init__(self, nc=80, channel=256, ch=()):"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""super().__init__()self.nc = nc # number of classesself.nl = len(ch) # number of detection layersself.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)self.no = nc + self.reg_max * 4 # number of outputs per anchorself.stride = torch.zeros(self.nl) # strides computed during buildc2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channelsself.cv2 = nn.ModuleList(nn.Sequential(Conv(channel, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)self.cv3 = nn.ModuleList(nn.Sequential(Conv(channel, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()self.AFPN = AFPN(ch, channel)def forward(self, x):"""Concatenates and returns predicted bounding boxes and class probabilities."""x = list(self.AFPN(x))shape = x[0].shape # BCHWfor i in range(self.nl):x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)if self.training:return xelif self.dynamic or self.shape != shape:self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shapex_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV opsbox = x_cat[:, :self.reg_max * 4]cls = x_cat[:, self.reg_max * 4:]else:box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.stridesif self.export and self.format in ('tflite', 'edgetpu'):# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695img_h = shape[2] * self.stride[0]img_w = shape[3] * self.stride[0]img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)dbox /= img_sizey = torch.cat((dbox, cls.sigmoid()), 1)return y if self.export else (y, x)def bias_init(self):"""Initialize Detect() biases, WARNING: requires stride availability."""m = self # self.model[-1] # Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequencyfor a, b, s in zip(m.cv2, m.cv3, m.stride): # froma[-1].bias.data[:] = 1.0 # boxb[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
四、手把手教你添加Detect_AFPN检测头
这里教大家添加检测头,检测头的添加相对于其它机制来说比较复杂一点,修改的地方比较多。
具体更多细节可以看我的添加教程博客,下面的教程也是完美运行的,看那个都行具体大家选择。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
4.1 修改一
首先我们将上面的代码复制粘贴到'ultralytics/nn/modules' 目录下新建一个py文件复制粘贴进去,具体名字自己来定,我这里起名为AFPN.py。

4.2 修改二
我们新建完上面的文件之后,找到如下的文件'ultralytics/nn/tasks.py'。这里需要修改的地方有点多,总共有7处,但都很简单。首先我们在该文件的头部导入我们AFPN文件中的检测头。

4.3 修改三
找到如下的代码进行将检测头添加进去,这里给大家推荐个快速搜索的方法用ctrl+f然后搜索Detect然后就能快速查找了。

4.4 修改四
同理将我们的检测头添加到如下的代码里。

4.5 修改五
同理

4.6 修改六
同理

4.7 修改七
同理

4.8 修改八
这里有一些不一样,我们需要加一行代码
else:return 'detect'为啥呢不一样,因为这里的m在代码执行过程中会将你的代码自动转换为小写,所以直接else方便一点,以后出现一些其它分割或者其它的教程的时候在提供其它的修改教程。

4.9 修改九
这里也有一些不一样,需要自己手动添加一个括号,提醒一下大家不要直接添加,和我下面保持一致。

五、Detect_AFPN检测头的yaml文件
这个代码的yaml文件和正常的对比也需要修改一下,如下->
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect_AFPN, [nc, 256]] # Detect(P3, P4, P5)
六、完美运行记录
最后提供一下完美运行的图片。

七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

相关文章:
YOLOv8改进 | 2023检测头篇 | 利用AFPN改进检测头适配YOLOv8版(全网独家创新)
一、本文介绍 本文给大家带来的改进机制是利用今年新推出的AFPN(渐近特征金字塔网络)来优化检测头,AFPN的核心思想是通过引入一种渐近的特征融合策略,将底层、高层和顶层的特征逐渐整合到目标检测过程中。这种渐近融合方式有助于…...

测试经理的职责是什么?
测试经理的职责是什么? 从项目启动到项目结束的管理 测试计划 获得客户对交付产品的认可 批准中间可交付内容并向客户发布补丁 记录工作内容以便绩效考评或其他计费 问题管理 团队管理 向测试协调员或SQA提交每周状态报告 参加每周回顾会议 每周发布所有测试项目的…...
LinuxBasicsForHackers笔记 -- BASH 脚本
你的第一个脚本:“你好,黑客崛起!” 首先,您需要告诉操作系统您要为脚本使用哪个解释器。 为此,请输入 shebang,它是井号和感叹号的组合,如下所示:#! 然后,在 shebang …...
定时任务特辑 | Quartz、xxl-job、elastic-job、Cron四个定时任务框架对比,和Spring Boot集成实战
专栏集锦,大佬们可以收藏以备不时之需: Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9 Python 专栏:http://t.csdnimg.cn/hMwPR Redis 专栏:http://t.csdnimg.cn/Qq0Xc TensorFlow 专栏:http://t.csdni…...

【面试经典150 | 二叉树】对称二叉树
文章目录 写在前面Tag题目来源解题思路方法一:递归方法二:迭代 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为主,并附带一些对于本题涉及到的…...

使用Git进行版本控制
参考:《Python编程从入门到实践》 前言1、安装、配置 Git1.1 在Linux系统中安装Git1.2 在OS X系统中安装Git1.3 在Windows系统中安装Git1.4 配置Git 2、创建项目3、忽略文件4、初始化仓库5、检查状态6、将文件加入到仓库中7、执行提交8、查看提交历史 前言 版本控制…...

专业课145+总分440+东南大学920考研专业基础综合信号与系统数字电路经验分享
个人情况简介 今年考研440,专业课145,数一140,期间一年努力辛苦付出,就不多表了,考研之路虽然艰难,付出很多,当收获的时候,都是值得,考研还是非常公平,希望大…...

Leetcode每日一题
https://leetcode.cn/problems/binary-tree-preorder-traversal/ 这道题目需要我们自行进行创建一个数组,题目也给出我们需要自己malloc一个数组来存放,这样能达到我们遍历的效果,我们来看看他的接口函数给的是什么。 可以看到的是这个接口函…...

USB连接器
USB连接器 电子元器件百科 文章目录 USB连接器前言一、USB连接器是什么二、USB连接器的类别三、USB连接器的应用实例四、USB连接器的作用原理总结前言 USB连接器的使用广泛,几乎所有现代电子设备都具备USB接口,使得设备之间的数据传输和充电变得简单和便捷。 一、USB连接器是…...
软件工程之需求分析
一、对需求的基本认识 1.需求分析简介 (1)什么是需求 用户需求:由用户提出。原始的用户需求通常是不能直接做成产品的,需要对其进行分析提炼,最终形成产品需求。 产品需求:产品经理针对用户需求提出的解决方案。 (2)为什么要…...
URL提示不安全
当用户访问一个没有经过SSL证书加密的网站(即使用HTTP而不是HTTPS协议),或者SSL证书存在问题时,浏览器URL会显示不安全提示。这些提示旨在保护用户免受潜在的恶意活动,并提醒他们谨慎对待这些不安全的网站。那么该如何…...

JavaBean是什么
详情请参考JavaBean规范:https://www.oracle.com/java/technologies/javase/javabeans-spec.html JavaBean是可重用的软件组件,是一个java类,方法名称符合一定的规范,这样使用方使用起来方便,例如框架和工具可以根据规…...

202309-2
http://118.190.20.162/view.page?gpidT174 题目分析: 这道题读完题后感觉像是考察前缀和,这里回顾下什么是前缀和:https://blog.csdn.net/weixin_45629285/article/details/111146240 我们利用前缀和算法,就可以在O(nm)的时…...
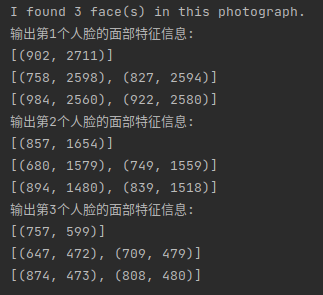
数字图像处理(实践篇)二十 人脸特征提取
目录 1 安装face_recognition 2 涉及的函数 3 实践 使用face_recognition进行人脸特征提取. 1 安装face_recognition pip install face_recognition 或者 pip --default-timeout100 install face_recognition -i http://pypi.douban.com/simple --trusted-host pypi.dou…...
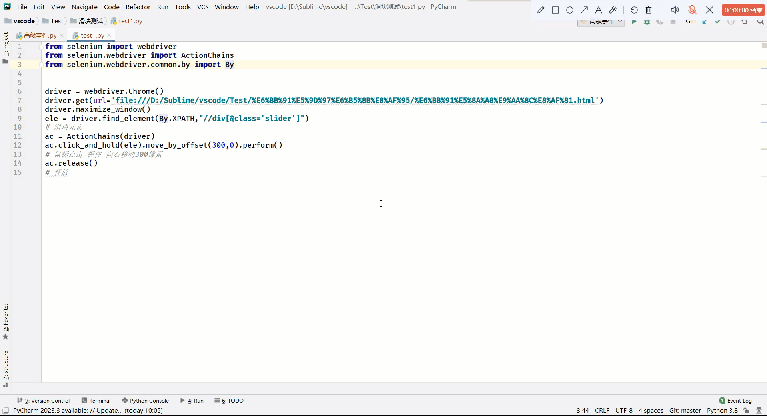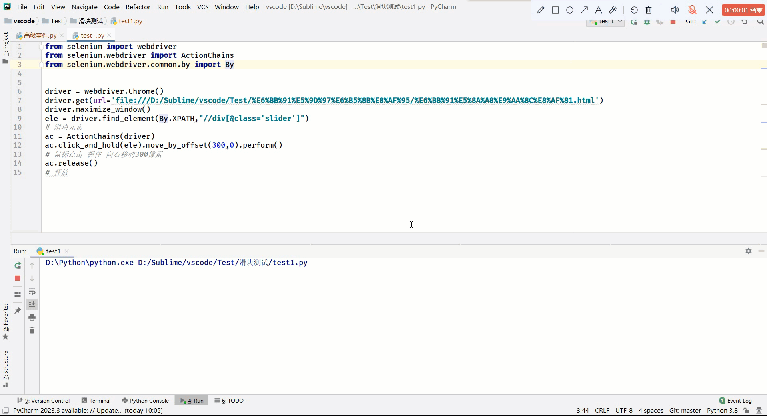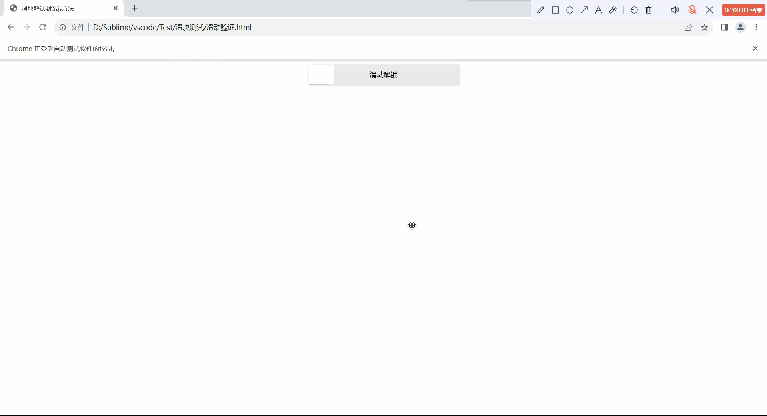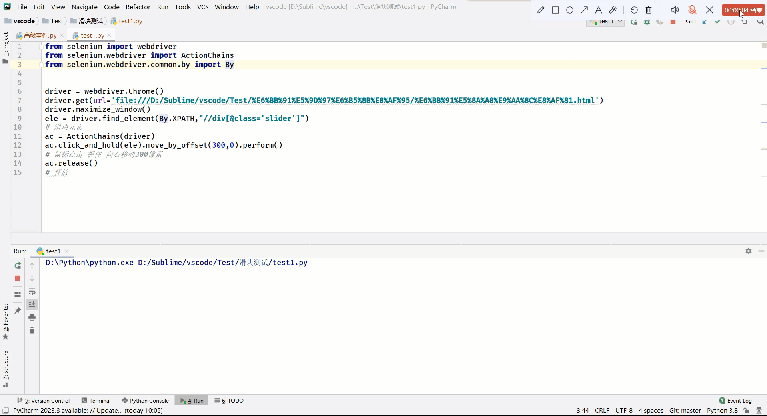
Python自动化:selenium常用方法总结
使用的Python版本为3.8,selenium版本为4.15.2 Python自动化:selenium常用方法总结 1. 三种等待方式2. 浏览器操作3. 8种查找元素的方法4. 高级事件 1. 三种等待方式 强制等待 使用模块time下的sleep()实现等待效果隐式等待 使用driver.implicitly_wait()方法&#…...
『开源资讯』JimuReport积木报表 v1.6.6 版本发布—免费报表工具
项目介绍 一款免费的数据可视化报表,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! Web 版报表设计器,类似于excel操作风格,通过拖拽完成报…...

每天五分钟计算机视觉:使用1*1卷积层来改变输入层的通道数量
本文重点 在卷积神经网络中有很多重要的卷积核,比如1*1的卷积核,3*3的卷积核,本文将讲解1*1的卷积核的使用,它在卷积神经网络中具有重要的地位。由于1*1的卷积核使用了最小的窗口,那么1*1的卷积核就失去了卷积层可以识…...

Java (JDK 21) 调用 OpenCV (4.8.0)
Java 调用 OpenCV 一.OpenCV 下载和安装二.创建 Java Maven 项目三.其他测试 一.OpenCV 下载和安装 Open CV 官网 可以下载编译好的包,也可以下载源码自行编译 双击安装 opencv-4.8.0-windows.exe 默认为当前目录 安装即解压缩 根据系统位数选择 将 x64 目录下 op…...

git 常用的使用方法
1.查看分支 $ git branch #查看本地分支 $ git branch -r #查看远程分支 $ git branch -a #查看所有分支 $ git branch -vv #查看本地分支及追踪的分支 2.创建分支 方法1 $ git branch 分支名 #创建本地分支 #将本地分支push,就创建了远程分支方法2 #创建本地分…...
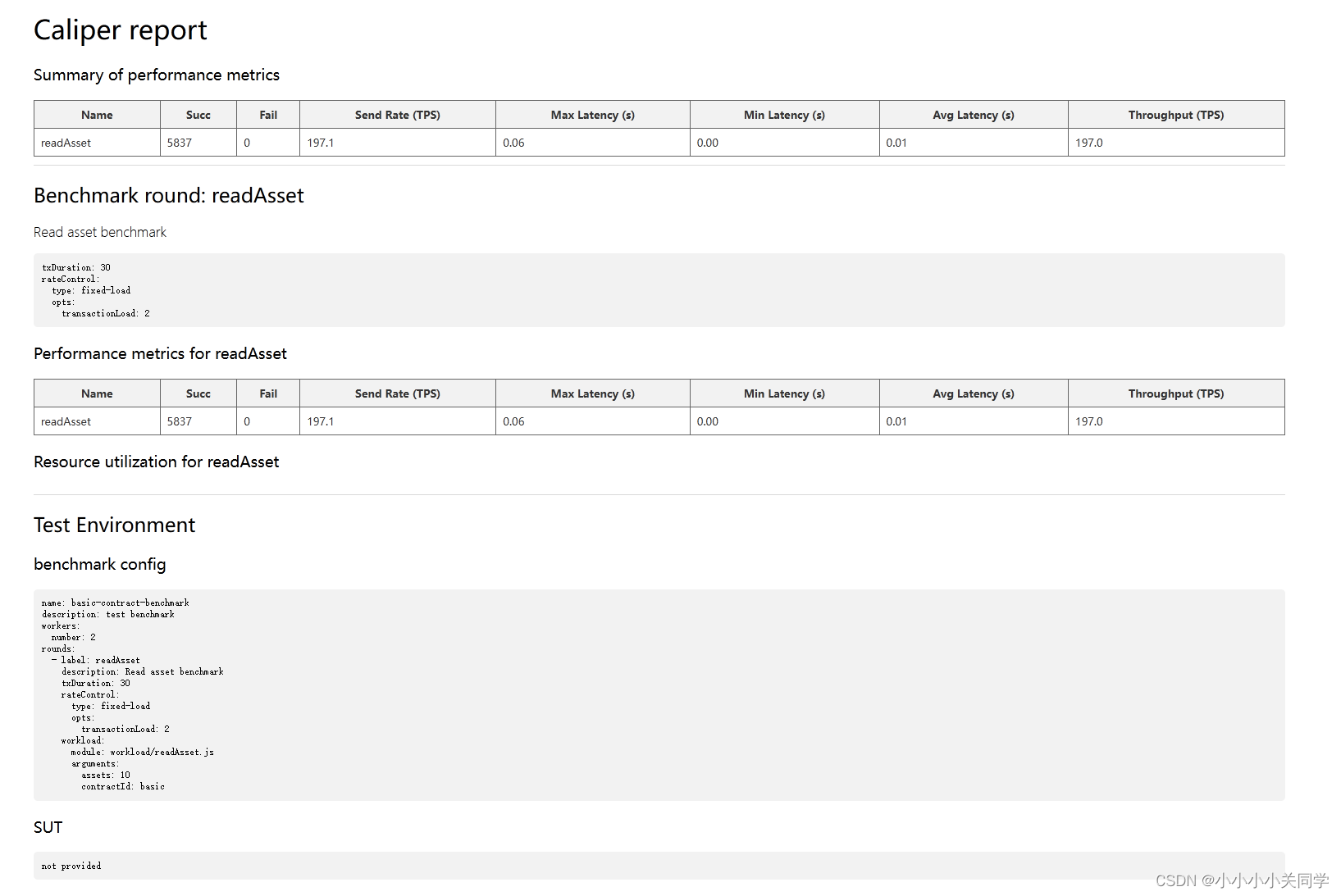
使用Caliper对Fabric地basic链码进行性能测试
如果你需要对fabric网络中地合约进行吞吐量、延迟等性能进行评估,可以使用Caliper来实现,会返回给你一份网页版的直观测试报告。下面是对test-network网络地basic链码地测试过程。 目录 1. 建立caliper-workspace文件夹2. 安装npm等3. calipe安装4. 创建…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...