011 数据结构_哈希
前言
本文将会向你介绍哈希概念,哈希方法,如何解决哈希冲突,以及闭散列与开散列的模拟实现
1. 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即 O( l o g 2 N log_2N log2N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一 一映射的关系,那么在查找时通过该函数可以很快找到该元素。 当向该结构中: 插入元素根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希方法,哈希方法中使用的转换函数称为哈希函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % size; size为存储元素底层空间总的大小。

2. 哈希方法
哈希方法:我们通常对关键码key进行转换来确定存储的位置,比如由字符串abc转换成一个整数作为存储的位置,这个转换的方法称为哈希方法,哈希方法中运用的函数叫做哈希函数
(1)直接定址法
ps:哈希方法是一个广义的概念,而哈希函数是哈希方法的一种具体实现。
1、直接定址法 值和位置关系唯一关系,每个值都有一个唯一位置,但是值很分散,直接定址会导致空间开很大,导致空间浪费
(此方法运用于关键字范围集中,量不大的情况,关键字和存储位置是一对一的关系,不存在哈希冲突)
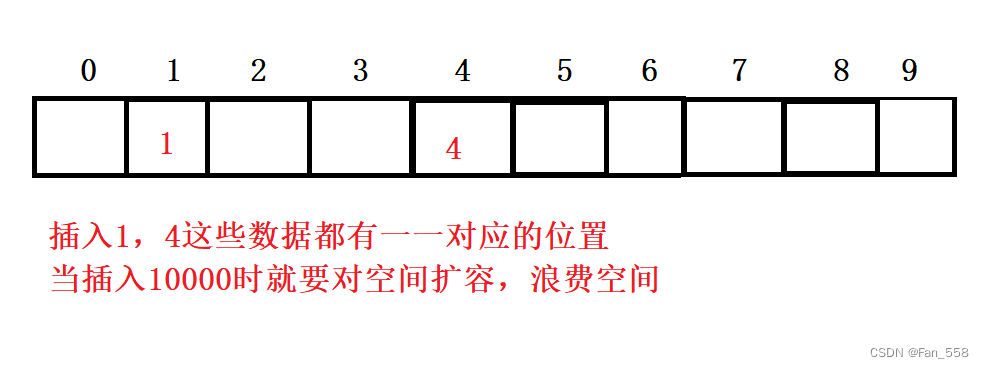
引入哈希冲突
哈希冲突概念:不同关键字通过相同的哈希函数计算出相同的哈希存储位置(不同的值映射到相同的位置上去),这种现象被称为哈希冲突或哈希碰撞,哈希冲突的发生与哈希函数的设计有关
(2)除留余数法
主要应用于关键字可以很分散,量可以很大,关键字和存储位置是多对一的关系的情况,但是存在哈希冲突
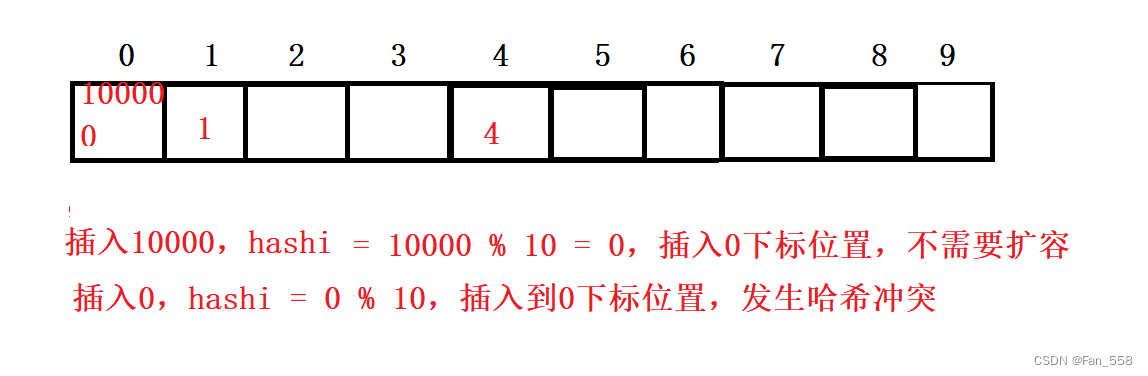
3. 解决哈希冲突
(1)闭散列
概念: 闭散列又称开放定址法,指当前位置被占用(哈希冲突),开放空间里按照某种规则,找一个没有被占用的位置存储
1、线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止 Hashi = hashi + i(i>=0)
2、二次探测
探测公式发生变化 hashi + i^2(i>=0)
(2)开散列
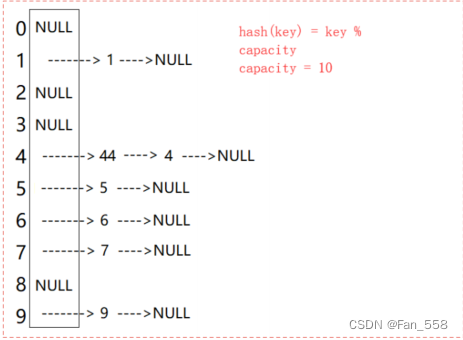
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
如图可观察到,val值为44的节点和节点val值为4的节点发生哈希冲突
开散列中每个桶中放大都是发生哈希冲突的元素
引入负载因子
负载因子:存储个数/空间的大小(注意这里的空间的大小是size而不是capacity)
由于在哈希表中,operator[]操作会根据已有的元素数量(即size())进行检查。因此,在计算负载因子时,要使用已有元素的个数除以哈希表的大小(即size())
size()函数返回的是当前哈希表中实际存储的元素数量,而capacity()函数返回的是哈希表的容量(即内部存储空间的大小)
负载因子:存储关键字个数/空间大小 负载因子太大,冲突可能会剧增,冲突增加,效率降低 负载因子太小,冲突降低,但是空间利用率就低了
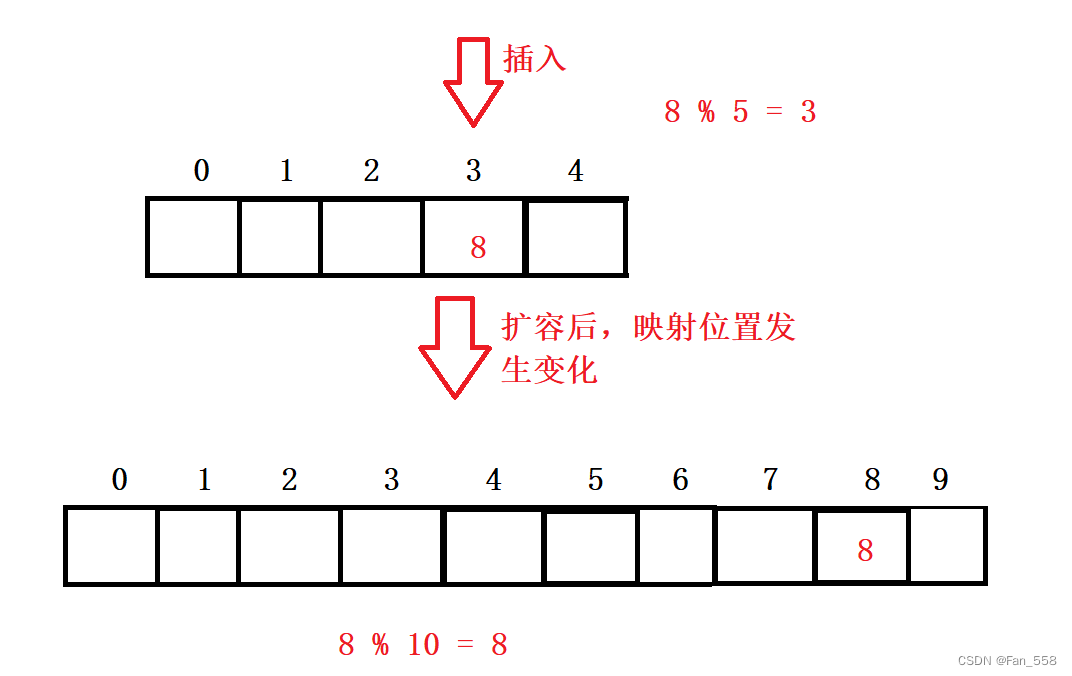
5. 哈希表扩容
扩容的核心是先开辟新空间,然后遍历旧空间的数据,按照hashi = hashi % Newsize重新建立映射,然后将旧空间的数据拷贝到新空间去,最后交换新旧哈希表,本质上我们还是要对旧哈希表进行扩容,因此最后要swap交换两表
6. 哈希表插入
三种状态EMPTY、EXIST、DELETE
EMPTY,表示该位置为空。
EXIST,表示该位置被占用了。
DELETE,表示该位置被删除了。
删除状态存在的含义
或许你会有疑问:删除为什么不能直接设为空状态,而是将被删除的状态设置为DELETE

7. 闭散列模拟实现
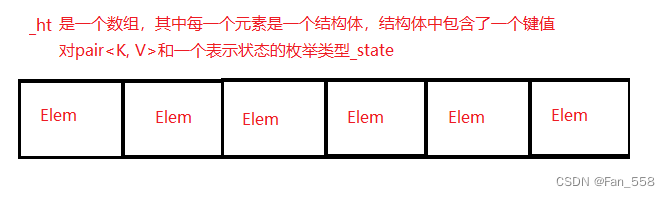
数据结构
struct Elem
{pair<K, V> _val;State _state = EMPTY;
};
vector<Elem<K, V>> _ht;
闭散列插入
闭散列的插入步骤是:判断是否存在,判断是否需要扩容(结合负载因子),遍历旧空间拷贝数据
关于闭散列的模拟实现,核心步骤在上文都有讲,这里就不再多作赘述,具体可看下面的代码与注释
namespace Close_Hash
{template<class T>struct HashFunc{size_t operator()(const T& key){return (size_t)key;}};//因为字符串做键值非常常见,库里面也特化了一份//BKDR算法,这里不会展开来讲template<>struct HashFunc<string>{size_t operator()(const string& key){size_t hashi = 0;for (auto ch : key){hashi = hashi * 31 + ch;}return hashi;}};enum State { EMPTY,EXIST,DELETE};template <class K, class V>struct Elem{pair<K, V> _val;State _state = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:HashTable(size_t capacity = 3): _ht(capacity),_size(0), _totalSize(0){for (size_t i = 0; i < capacity; ++i)_ht[i]._state = EMPTY;}// 插入bool Insert(const pair<K, V>& val){Hash hf;_size = _ht.size();//已有if (Find(val.first)){return false;}else{//扩容,负载因子==0.6if ((double)_totalSize / _size >= 0.6){//开辟新空间size_t newsize = _size * 2;HashTable<K, V, Hash> NewHt;NewHt._ht.resize(newsize);//遍历旧空间for (int i = 0; i < _size; i++){if (_ht[i]._state == EXIST){NewHt.Insert(_ht[i]._val);}}NewHt._ht.swap(_ht);}size_t hashi = hf(val.first) % _size;//不为空,向后查找while (_ht[hashi]._state == EXIST){hashi++;//如果超出数组长度hashi %= _size;}//为空,插入_ht[hashi]._val.first = val.first;_ht[hashi]._val.second = val.second;_ht[hashi]._state = EXIST;++_totalSize;return true;}}// 查找Elem<K, V>* Find(const K& key){Hash hf;//线性探测size_t hashi = hf(key) % _ht.size();while (_ht[hashi]._state != EMPTY){ if (_ht[hashi]._state == EXIST && _ht[hashi]._val.first == key){return &_ht[hashi];}hashi++;//超出数组长度hashi %= _ht.size();}//没有找到areturn nullptr;}// 删除bool Erase(const K& key){Elem<K, V>* ret = Find(key);//不为空就说明找到if (ret){ret->_state = DELETE;--_totalSize;return true;}else return false;}private:size_t HashFunc(const K& key){return key % _ht.capacity();}void CheckCapacity();private:vector<Elem<K, V>> _ht;size_t _size;size_t _totalSize; // 哈希表中的所有元素:有效和已删除, 扩容时候要用到};
}
测试
void Print(){for (int i = 0; i < _ht.size(); i++){if (_ht[i]._state == EXIST){//printf("[%d]->%d\n", i, _tables[i]._kv.first);cout << "[" << i << "]->" << _ht[i]._val.first << ":" << _ht[i]._val.second << endl;}else if (_ht[i]._state == EMPTY){printf("[%d]->\n", i);}else{printf("[%d]->D\n", i);}}void TestHT1()
{Close_Hash::HashTable<int, int> ht;int a[] = { 4,14,24,34,5,7,1 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Print();ht.Insert(make_pair(3, 3));ht.Insert(make_pair(3, 3));ht.Insert(make_pair(-3, -3));ht.Print();cout << endl;ht.Erase(3);;ht.Print();if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Insert(make_pair(23, 3));ht.Insert(make_pair(3, 3));if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Print();
}8. 开散列模拟实现
数据结构
struct HashNode{HashNode* _next;pair<K, V> _val;HashNode(const pair<K, V>& val):_next(nullptr),_val(val){}};typedef HashNode<K, V> Node;vector<Node*> _ht;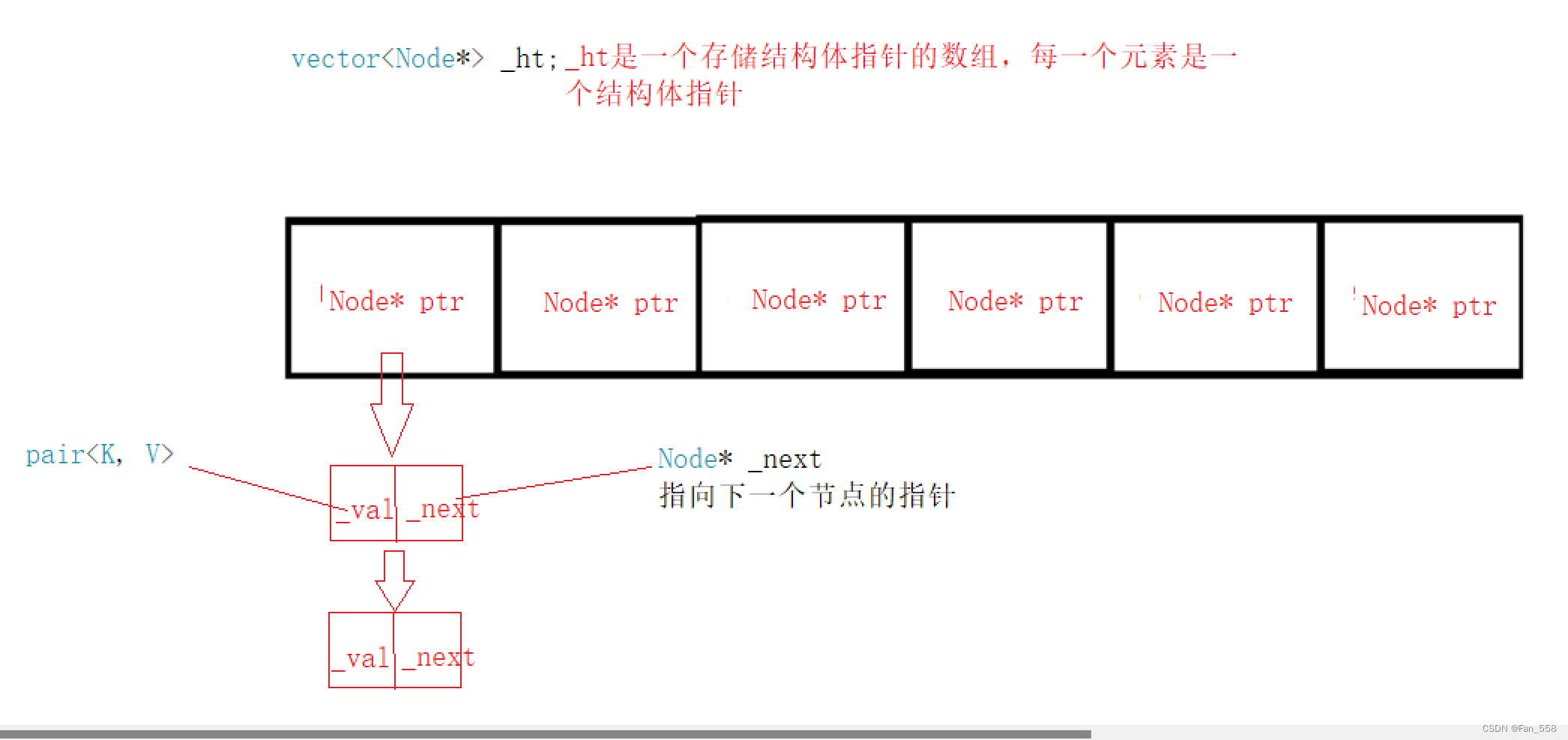
开散列插入
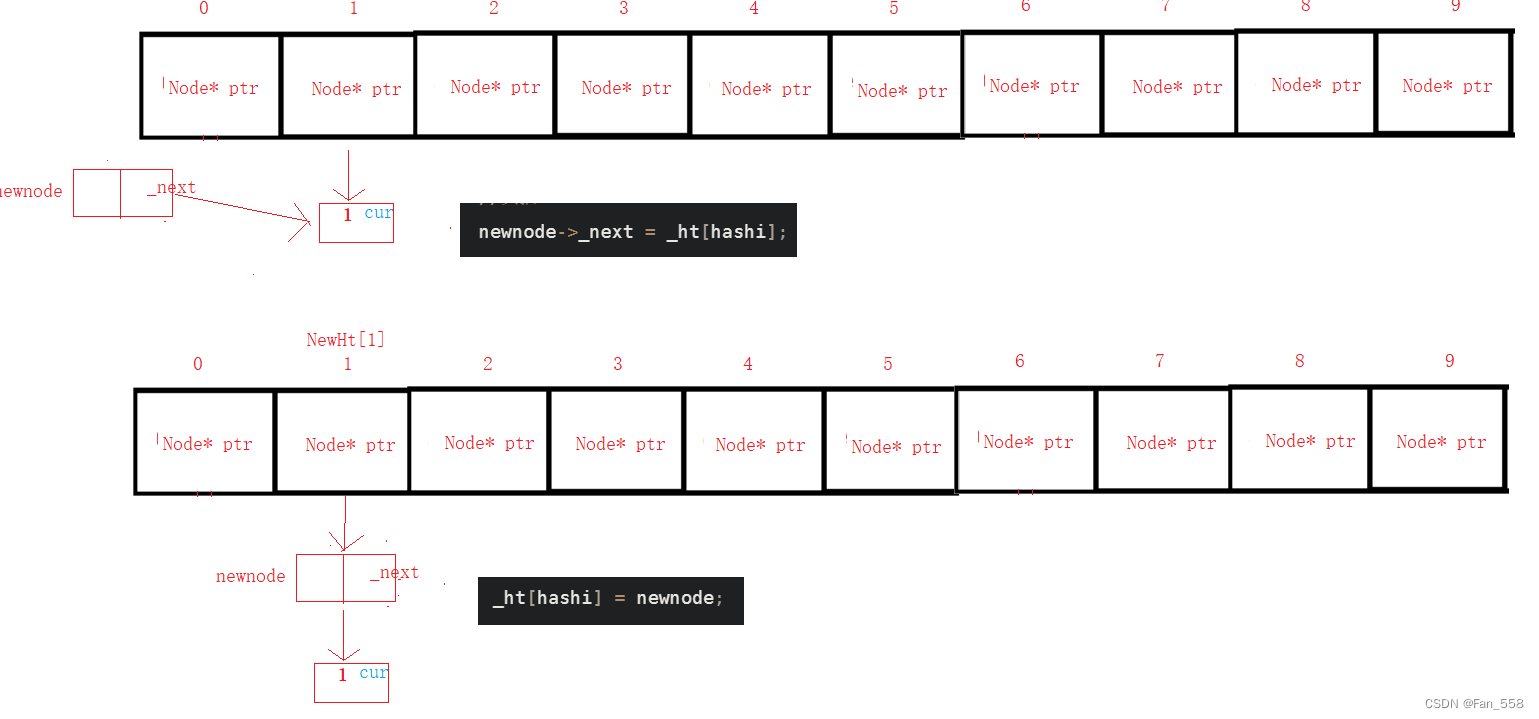
插入的主要逻辑是:先查找是否存在,判断是否需要扩容(依据平衡因子),开辟新空间然后遍历旧空间,将旧空间的数据拷贝到新空间上(需要根据新的映射关系,待会会细讲),最后插入节点
bool Insert(const pair<K, V>& val)
{Hash hf;//已有if (Find(val.first)){return false;}//扩容,负载因子==1if (_totalSize == _ht.size()){//开辟新空间size_t newsize = _ht.size() * 2;vector<Node*> NewHt;NewHt.resize(newsize);//遍历旧空间for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){//保存下一个结构体指针Node* next = cur->_next;size_t hashi = hf(cur->_val.first) % NewHt.size();//将新空间上hashi位置处的哈希桶链接到需要处理的当前节点cur->_next = NewHt[hashi];NewHt[hashi] = cur;//处理旧空间上哈希桶的下一个节点cur = next;}//防止出现悬空指针的问题_ht[i] = nullptr;} _ht.swap(NewHt);}//插入节点size_t hashi = hf(val.first) % _ht.size();Node* newnode = new Node(val);//头插newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_totalSize;return true;
}
以下是遍历旧空间,拷贝数据的图解
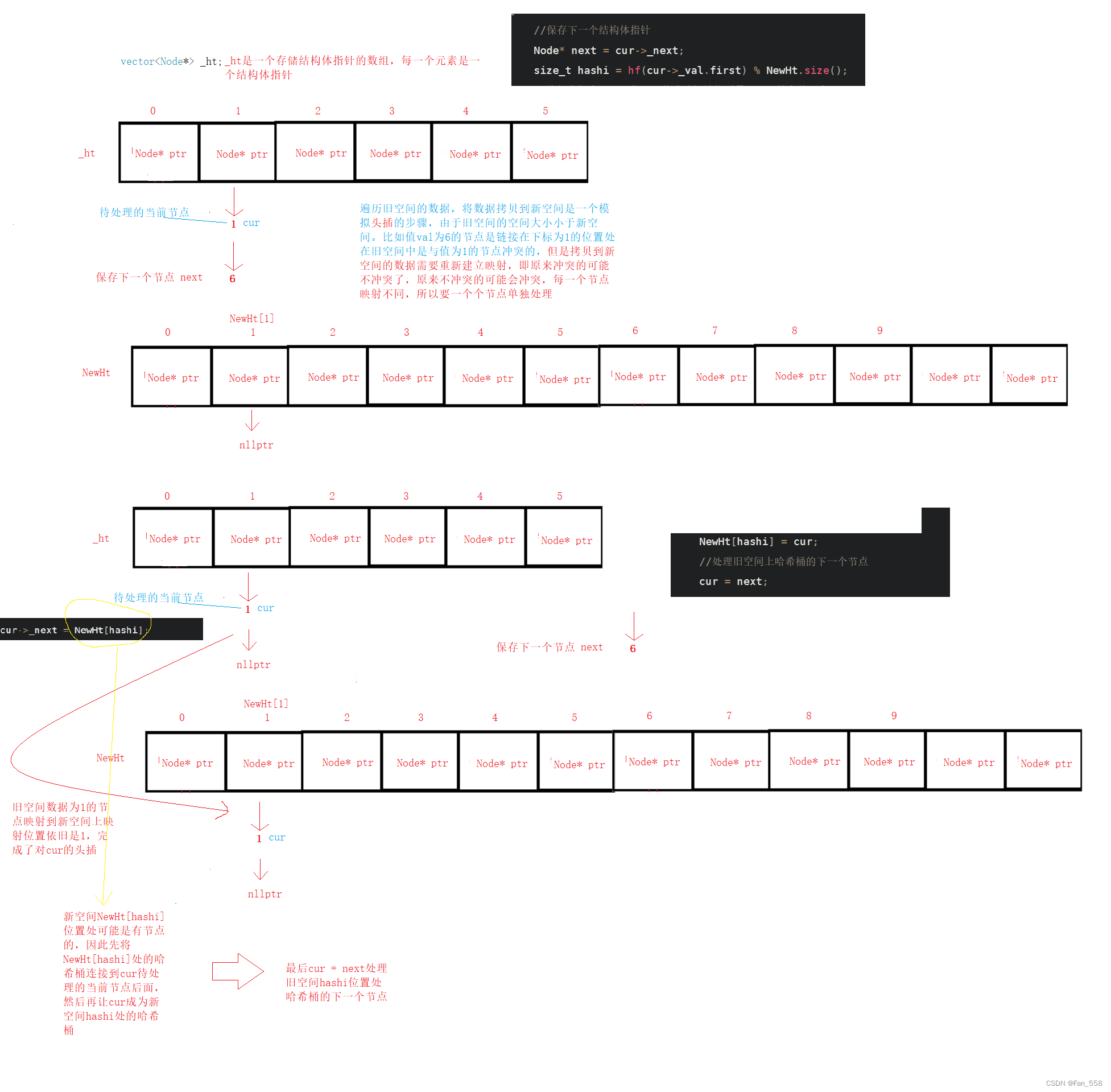
插入过程图解
全部代码
namespace Open_Hash
{template<class T>struct HashFunc{size_t operator()(const T& key){if (key >= 0){return (size_t)key;}else{return abs(key);}}};//字符串哈希算法这里不展开讲,采用的是BKDR算法template<>struct HashFunc<string>{size_t operator()(const string& key){size_t hashi = 0;for (auto ch : key){hashi = hashi * 31 + ch;}return hashi;}};template <class K, class V>struct HashNode{HashNode* _next;pair<K, V> _val;HashNode(const pair<K, V>& val):_next(nullptr),_val(val){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public: HashTable(){_ht.resize(10);}~HashTable(){for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}//将当前哈希桶置空_ht[i] = nullptr;}}typedef HashNode<K, V> Node;// 插入bool Insert(const pair<K, V>& val){Hash hf;//已有if (Find(val.first)){return false;}//扩容,负载因子==1if (_totalSize == _ht.size()){//开辟新空间size_t newsize = _ht.size() * 2;vector<Node*> NewHt;NewHt.resize(newsize);//遍历旧空间for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){//保存下一个结构体指针Node* next = cur->_next;size_t hashi = hf(cur->_val.first) % NewHt.size();//将新空间上hashi位置处的哈希桶链接到需要处理的当前节点cur->_next = NewHt[hashi];NewHt[hashi] = cur;//处理旧空间上哈希桶的下一个节点cur = next;}//防止出现悬空指针的问题_ht[i] = nullptr;}_ht.swap(NewHt);}//插入节点size_t hashi = hf(val.first) % _ht.size();Node* newnode = new Node(val);//头插newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_totalSize;return true;}//查找Node* Find(const K& key){Hash hf;//线性探测size_t hashi = hf(key) % _ht.size();Node* cur = _ht[hashi];//遍历对应hashi位置处的哈希桶while (cur){if (cur->_val.first == key){return cur;}cur = cur->_next;}//没有找到return nullptr;}// 删除bool Erase(const K& key){Hash hf;Node* ret = Find(key);size_t hashi = hf(key) % _ht.size();//不为空就说明找到if (ret){Node* cur = _ht[hashi];Node* prev = nullptr;//遍历当前哈希桶while (cur){if (cur->_val.first == key){//判断是头删还是中间位置处的删除if (prev == nullptr){_ht[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}}//未找到return false;}private:vector<Node*> _ht;Node* _next = nullptr;size_t _totalSize = 0; // 哈希表中的所有元素:有效和已删除, 扩容时候要用到};
}
测试
//打印void Print1(){for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];cout << "[" << i << "]:";//哈希桶不为空while(cur){cout << "(" << cur->_val.first << "," << cur->_val.second << ")" << "->";cur = cur->_next;}cout << endl;}cout << endl;}void Print2(){for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];//哈希桶不为空while (cur){cout << cur->_val.first << ":"<< cur->_val.second << " ";cur = cur->_next;}}cout << endl;}
//测试void TestHT1(){HashTable<int, int> ht;int a[] = { 4,14,24,34,5,7,1 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(3, 3));ht.Insert(make_pair(3, 3));ht.Insert(make_pair(-3, -3));ht.Print1();ht.Erase(3);ht.Print1();if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Insert(make_pair(3, 3));ht.Insert(make_pair(23, 3));//ht.Insert(make_pair(-9, -9));ht.Insert(make_pair(-1, -1));ht.Print1();}void TestHT2(){string arr[] = { "香蕉", "甜瓜","苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };//HashTable<string, int, HashFuncString> ht;HashTable<string, int> ht;for (auto& e : arr){//auto ret = ht.Find(e);HashNode<string, int>* ret = ht.Find(e);if (ret){ret->_val.second++;}else{ht.Insert(make_pair(e, 1));}}ht.Print2();ht.Insert(make_pair("apple", 1));ht.Insert(make_pair("sort", 1));ht.Insert(make_pair("abc", 1));ht.Insert(make_pair("acb", 1));ht.Insert(make_pair("aad", 1));ht.Print2();}void Some(){const size_t N = 100;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比较大时,重复值比较多v.push_back(rand()%100+i); // 重复值相对少//v.push_back(i); // 没有重复,有序}HashTable<int, int> ht;for (auto e : v){ht.Insert(make_pair(e, e));}ht.Print1();}
小结
今日的分享就到这里啦,后续将会向你带来位图与布隆过滤器的知识,如果本文存在疏漏或错误的地方还请您能够指出,另外如果你存在疑问,也可以评论留言哦!
相关文章:
011 数据结构_哈希
前言 本文将会向你介绍哈希概念,哈希方法,如何解决哈希冲突,以及闭散列与开散列的模拟实现 1. 哈希概念 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经…...
案例025:基于微信小程序的移动学习平台的设计与实现
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...
写实3D游戏模型纹理贴图设置
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 当谈到游戏角色的3D模型风格时,有几种不同的风格: …...

如何基于Akamai IoT边缘平台打造一个无服务器的位置分享应用
与地理位置有关的应用相信大家都很熟悉了,无论是IM软件里的位置共享或是电商、外卖应用中的配送地址匹配,我们几乎每天都在使用类似的功能与服务。不过你有没有想过,如何在自己开发的应用中嵌入类似的功能? 本文Akamai将为大家提…...

【开源】基于JAVA的木马文件检测系统
项目编号: S 041 ,文末获取源码。 \color{red}{项目编号:S041,文末获取源码。} 项目编号:S041,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 木马分类模块2.3 木…...
KaiOS 运营商相关文件operator_variant_manager.js代码功能和调试
gaia/apps/system/js/operator_variant_manager.js at master mozilla-b2g/gaia GitHub js文件接口功能 No 接口/常量 功能 1 OperatorVariantManager var OperatorVariantManager function(core) 2 OperatorVariantManager.IMPORTS OperatorVariantManager.I…...
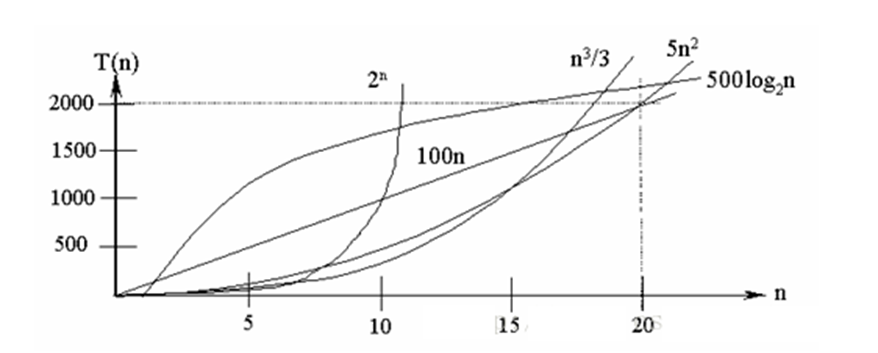
【数据结构(六)】排序算法介绍和算法的复杂度计算(1)
文章目录 1. 排序算法的介绍1.1. 排序的分类 2. 算法的时间复杂度2.1. 度量一个程序(算法)执行时间的两种方法2.2. 时间频度2.2.1. 忽略常数项2.2.2. 忽略低次项2.2.2. 忽略系数 2.3. 时间复杂度2.4. 常见的时间复杂度2.5. 平均时间复杂度和最坏时间复杂度 3. 算法的空间复杂度…...

带有 RaspiCam 的 Raspberry Pi 监控和延时摄影摄像机
一、说明 一段时间以来,我一直想构建一个运动激活且具有延时功能的树莓派相机,但从未真正找到我喜欢的案例。我在thingiverse上找到了这个适合树莓派和相机的好案例。它是为特定的鱼眼相机设计的,但从模型来看,我拥有的廉价中国鱼…...
Apache Doris 在某工商信息商业查询平台的湖仓一体建设实践
作者|某工商信息商业查询平台 高级数据研发工程师 李昂 信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。对于行业相关企业来说,数据收集、加工、分析能力的重要性不言而喻。以某工商信息…...

【尘缘送书第六期】2023年度学习:AIGC、AGI、GhatGPT、人工智能大模型实现必读书单
【文末送书】今天推荐几本AIGC、AGI、GhatGPT、人工智能大模型领域优质书籍。 目录 前言1 《ChatGPT 驱动软件开发》2 《ChatGPT原理与实战》3 《神经网络与深度学习》4 《AIGC重塑教育》5 《通用人工智能》6 文末送书 前言 2023年是人工智能大语言模型大爆发的一年࿰…...
我的 CSDN 三周年创作纪念日:2020-12-12
本人大叔一枚,自1992年接触电脑,持续了30年的业余电脑发烧爱好者,2022年CSDN博客之星Top58,阿里云社区“乘风者计划”专家博主。自某不知名财校毕业后进入国有大行工作至今,先后任职于某分行信息科技部、电子银行部、金…...

什么是css初始化
什么是css初始化 CSS初始化是指重设浏览器的样式。 因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。 每次新开发网站或新网页时候通过初始化CSS样式的属性,为我们将用…...

谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!
文章目录 谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!前言重磅!Mixtral MoE 8x7B!!!Mixtral是啥模型介绍模型结构长啥样?表现如何?可…...

Linux升级nginx版本
处于漏洞修复目的服务器所用nginx是1.16.0版本扫出来存在安全隐患,需要我们升级到1.17.7以上。 一般nginx默认在 /usr/local/ 目录,这里我的nginx是自定义的路径安装在 /app/weblogic/nginx 。 1.查看生产环境nginx版本 cd /app/weblogic/nginx/sbin/…...
人工智能|网络爬虫——用Python爬取电影数据并可视化分析
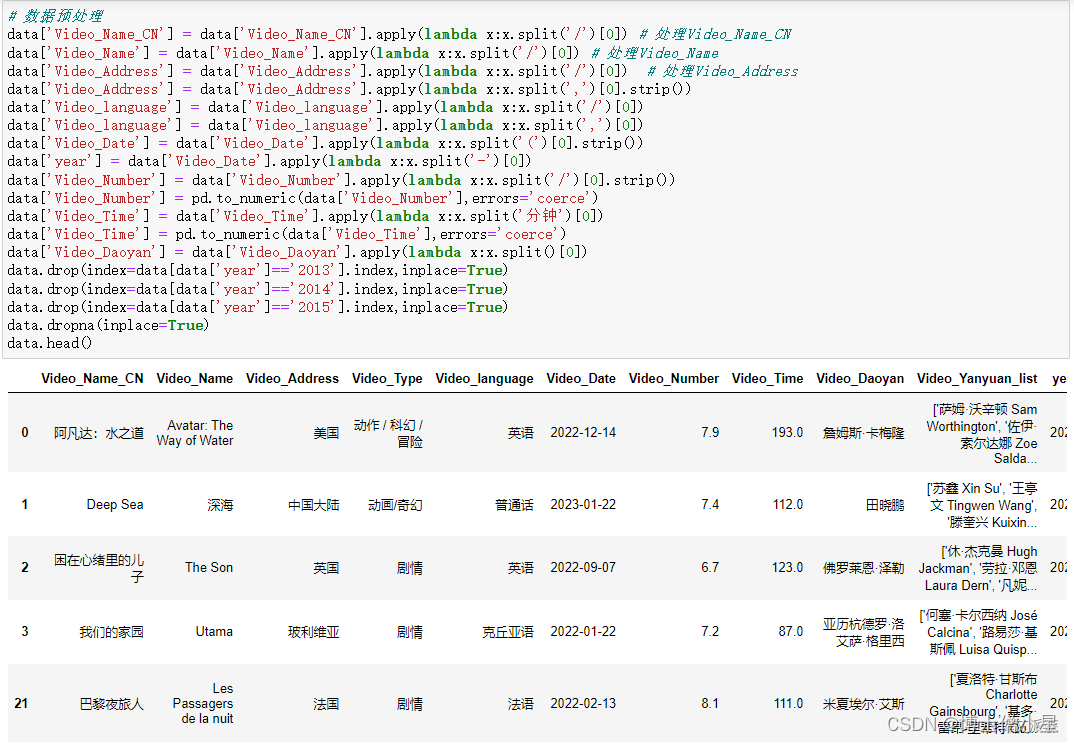
一、获取数据 1.技术工具 IDE编辑器:vscode 发送请求:requests 解析工具:xpath def Get_Detail(Details_Url):Detail_Url Base_Url Details_UrlOne_Detail requests.get(urlDetail_Url, headersHeaders)One_Detail_Html One_Detail.cont…...

mac苹果笔记本电脑如何强力删除卸载app软件?
苹果电脑怎样删除app?不是把app移到废纸篓就行了吗,十分简单呢! 其实不然,因为在Mac电脑上,删除应用程序只是删除了应用程序的主要组件。大多数时候,系统会有一个相当长的目录,包含所有与应用程…...

net6中使用MongoDB
目录 一、MongoDB是什么? 二、使用步骤 1.安装驱动 2.设置连接字符串、配置类 3.建立实体类 4.服务层 5.在Program添加服务 6.在Controller注入服务 总结 一、MongoDB是什么? MongoDB 是一个开源的、可扩展的、跨平台的、面向文档的非关系型数据库&…...

vue中yarn install超时问题
囚笼中的网络固然可以稳定局势,不让猴子们得以随时醒悟!给你吃的你就好好吃,不要有其他的翻然醒悟的时刻。无论如何,愚蠢的活着也是一种幸福,听着那些耐心寻味的统计幸福指数,我们不由的幸福的一批。。 最…...

vue3 引入 markdown编辑器
参考文档 安装依赖 pnpm install mavon-editor // "mavon-editor": "3.0.1",markdown 编辑器 <mavon-editor></mavon-editor>新增文本 <mavon-editor ref"editorRef" v-model"articleModel.text" codeStyle"…...

算法----K 和数对的最大数目
题目 给你一个整数数组 nums 和一个整数 k 。 每一步操作中,你需要从数组中选出和为 k 的两个整数,并将它们移出数组。 返回你可以对数组执行的最大操作数。 示例 1: 输入:nums [1,2,3,4], k 5 输出:2 解释&…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...