Kakfa详解(一)
kafka使用场景
- canal同步mysql
- elk日志系统
- 业务系统Topic
kafka基础概念
- Producer: 消息生产者,向kafka发送消息
- Consumer: 从kafka中拉取消息消费的客户端
- Consumer Group: 消费者组,消费者组是多个消费者的集合。消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费。
减少Group订阅Topic的数量,一个Group订阅的Topic最好不要超过5个,建议一个Group只订阅一个Topic
- Broker: 一台kafka服务器就是一个
Broker,一个集群由多个Broker组成 - Topic:主题,可以理解为队列,生产者和消费者都是面向
Topic - Partition:分区,为了实现扩展性。一个非常大的
Topic可以分布在多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)- 便于在集群中扩展
- 可以提高并发,以
Partition为单位进行读写,类似于多路
# 默认分区数 server.properties配置 num.partitions=1 - Replica:副本,为保证集群中某个节点发生故障,节点上的
Partition数据不丢失,kafka可以正常的工作,kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower# 默认副本数 server.properties配置 # 默认分区副本数不得超过kafka节点数(副本数如果一个节点放2份,就没意义了) default.replication.factor=3 - Leader:每个分区多个副本的主角色,生产者发送数据对象,以及消费者消费数据都是
Leader - Follower: 每个分区多个副本的从角色,实时的从
Leader同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。 - ISR:
in sync replica,基本保存同步的Replica列表,是副本与主副本保持同步的列表,默认是30s数据,如果从副本保持同步,那么重新选举leader的时候,会被选择。如果与主副本同步差距较大,会被移除,选举leader将不会被考虑。 - OSR:
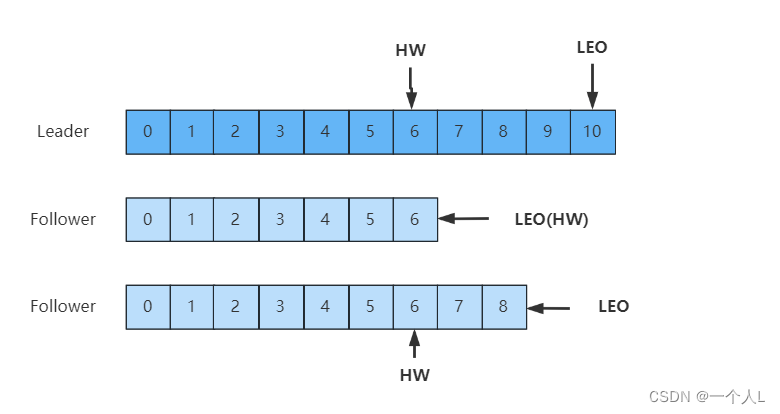
out of sync replica, 同步有延迟的follower列表 - LEO:
Log End Offset,每个副本最后一个offset - HW:
High Watermark,高水位,指消费者能见到的最大的offset,ISR队列中最小的LEO。
文件存储
主要是通过log和index等文件保存具体的消息文件
一个
topic对应多个partition
一个partition对应多个segment
一个segment对应log和index文件
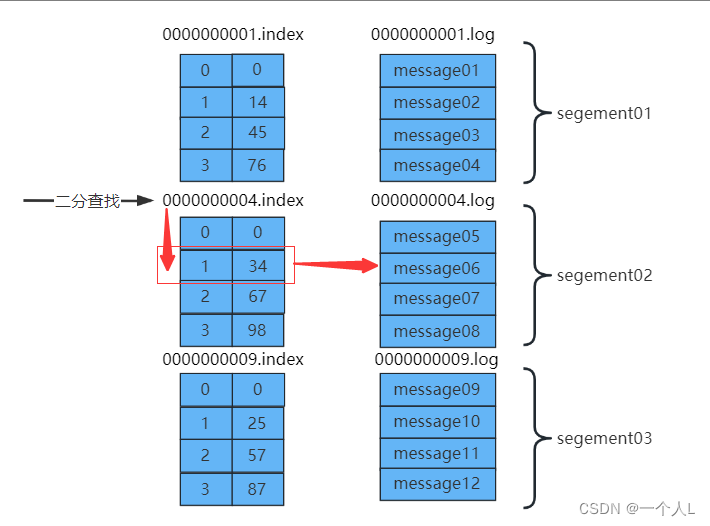
为了防止log文件过大导致定位效率低下,kafka的log文件以1G为一个分界点,当.log文件大小超过1G的时候,此时会创建一个新的.log文件,同时为了快速定位大文件中消息位置,kafka采取了分片和索引的机制来加速定位。
.index文件存储的消息的offset+真实的起始偏移量。.log中存放的是真实的数据。
数据定位步骤,查找offset=6的数据。
- 通过二分查找,定位
.index文件。offset=6(大于4,小于9),定位到第二个文件segement02 - 然后offset减去
segment02的起始偏移量(6-4=2),定位到之后总的偏移量 - 获取到总的偏移量之后,直接定位到
.log文件即可快速获得当前消息大小
生产者
发送消息分区策略
- 指明
partition(指明是指第几个分区)的情况下,直接将指明的值作为partition的值 - 没有指明
partition的情况下,但是存在值key,此时将key的hash值与topic的partition总数进行取余得到partition值 - 值与
partition均无的情况下,第一次调用时随机生成一个整数,后面每次调用在这个整数上自增,将这个值与topic可用的partition总数取余得到partition值,即round-robin算法。
生产者消息发送
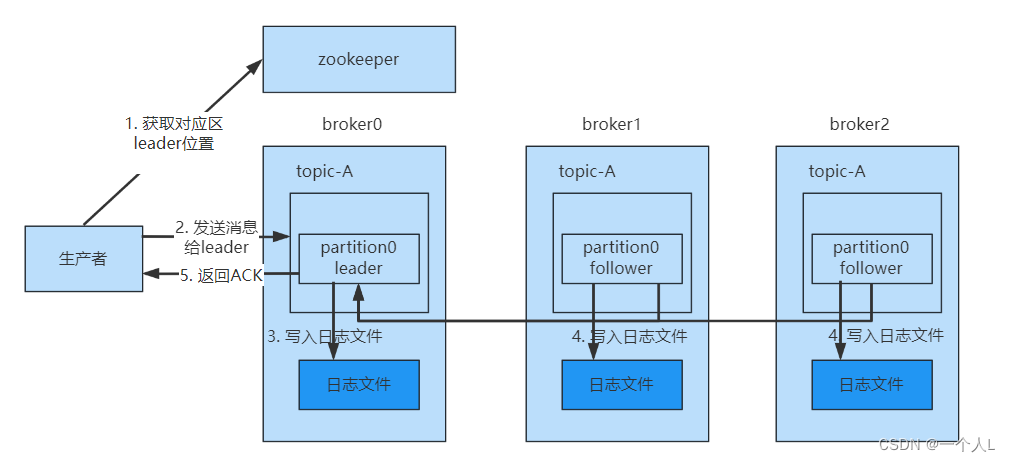
为保证producer发送的数据能够可靠的发送到指定的topic中,topic的每个partition收到producer发送的数据后,都需要向producer发送ackacknowledgement,如果producer收到ack就会进行下一轮的发送,否则重新发送数据。
发送ack时机
- 半数follower同步完成即发送ack,容错率低,延时低
- 全部follower同步完成完成发送ack,容错率高,延时高
kafka采用的是第二种,延迟对kafka影响比较小。
采用了第二种方案进行同步ack之后,如果leader收到数据,所有的follower开始同步数据,但有一个follower因为某种故障,迟迟不能够与leader进行同步,那么leader就要一直等待下去,直到它同步完成,才可以发送ack,此时需要如何解决这个问题呢?
leader中维护了一个ISR(in-sync replica set)同步副本集,即与leader保持同步的follower集合,当ISR中的follower完成数据的同步之后,给leader发送ack,如果follower长时间没有向leader同步数据,则该follower将从ISR中被踢出,该之间阈值由replica.lag.time.max.ms参数设定。当leader发生故障之后,会从ISR中选举出新的leader。
ack参数
0: producer不等待broker的ack,这一操作提供了最低的延迟,broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据1: producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将丢失数据。(只是leader落盘)-1(all): producer等待broker的ack,partition的leader和ISR的follower全部落盘成功才返回ack,但是如果在follower同步完成后,broker发送ack之前,如果leader发生故障,会造成数据重复。(这里的数据重复是因为没有收到,所以继续重发导致的数据重复)
高吞吐量,低延迟
- kafka会先写入
操作系统页缓存中,操作系统再决定将数据写回到磁盘上 - 磁盘顺序写,采用追加的方式写入消息
- 零拷贝
kafka消息发送,消息暂时暂存的,批量发送,RecordAccumulator.class是专门缓存kafka消息的。
spring:kafka:bootstrap-servers: 127.0.0.1:9200,127.0.0.1:9201,127.0.0.1:9202producer: # producer 生产者retries: 0 # 重试次数acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)batch-size: 16384 # 默认 批量大小 16KBbuffer-memory: 33554432 # 默认 生产端缓冲区大小 32MBkey-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
消费者
消费方式
消费者采用pull的方式来从broker中读取数据
push推的模式很难适应消费速率不同的消费者,因为消息发送率是由broker决定的,它的目标是尽可能以最快的速度传递消息,但是这样容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull方式则可以让consumer根据自己的消费处理能力以适当的速度消费消息。
消费流程
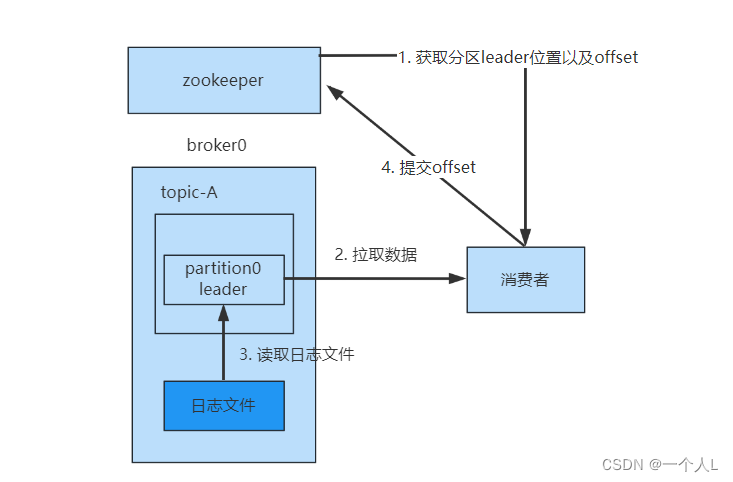
- 从zookeeper中获取leader的位置和offset的位置,kafka0.9版本之前,consumer默认将offset保存在zookeeper中,从0.9版本之后,consumer默认将offset保存在kafka一个内置的topic中,该topic为
__consumer_offsets - 拉取数据,直接从broker的
page cache拉取 - 如果
page cache数据不全,就会从磁盘中拉取,并发送 - 消费完成后,可以手动提交offset,也可以自动提交offset
零拷贝
…
分区分配策略
线上的服务都是多个消费者服务一起消费的,一个topic包含多个partition,分区和消费者存在一个分配的策略,默认采用的是Range范围分配策略。
计算公式
n = 分区数/消费者数
m = 分区数%消费者数
前m个消费者,消费n+1个,剩下的消费n个
8个分区(p1 - p8),3个消费者(c1 - c3)
c1 分配 p1 p2 p3
c2 分配 p4 p5 p6
c3 分配 p7 p8
配置参数
spring:kafka:consumer: # consumer消费者group-id: test-group # 默认的消费组IDenable-auto-commit: true # 是否自动提交offsetauto-commit-interval: 1000 # 提交offset延时(接收到消息后多久提交offset)# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常auto-offset-reset: latestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializermax-poll-records: 500 #一次拉取最大数据 500条
offset提交
默认是自动提交,enable.auto.commit=true
手动提交offset的方法有两种:
- commitSync:同步提交,失败后会自动重试
- commitAsync: 异步提交,失败后不会自动重试
重复消费
产生的原因
- 生产者重复提交
- rebalance引起的重复消费
超过一定时间(max.poll.interval.ms设置的值,默认5分钟)未进行poll拉取消息,则会导致客户端主动离开队列,而引发rebalance,提交offset失败。其他消费者会从没有提交的位置消费,从而导致重复消费。
解决方案
- 提高消费速度
- 增加消费者
- 多线程处理
- 异步消费
- 调整消费处理时间
- 幂等处理
- 消费者设置幂等校验
- 开启kafka幂等配置,生产者开启幂等配置,将消息生成md5,然后保存到redis中,处理新消息的时候先校验。这个尽量不要开启,消耗性能
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
批量消费配置
@Configuration
@Slf4j
public class KafkaConsumerConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;@Value("${spring.kafka.consumer.group-id}")private String consumerGroupId;@Value("${spring.kafka.consumer.auto-offset-reset}")private String autoOffsetReset;public Map<String, Object> consumerFactory() {Map<String, Object> props = new HashMap<>(16);props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 120000);props.put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, 180000);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);return props;}@Beanpublic KafkaListenerContainerFactory<?> containerFactory() {ConcurrentKafkaListenerContainerFactory<String, String>factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerFactory()));// 消费者组中线程数量factory.setConcurrency(3);// 当使用批量监听器时需要设置为truefactory.setBatchListener(true);// 拉取超时时间factory.getContainerProperties().setPollTimeout(3000);// 重试次数RetryingBatchErrorHandler errorHandler = new RetryingBatchErrorHandler(new FixedBackOff(500L, 3L), null);factory.setBatchErrorHandler(errorHandler);return factory;}
}
@KafkaListener(topics = "aloneness-topic02",properties = {"max.poll.records=20"},containerFactory = "containerFactory")
public void listen02(List<String> list) {log.info("处理批量消息:{}", JSON.toJSONString(list));List<Message> messages = JSON.parseArray(JSON.toJSONString(list), Message.class);System.out.println(messages);
}
如果未配置重试次数,也消费代码中出现异常,会一直重试,一直消费异常
手动创建Topic
kafka版本大于2.2
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic als-test-topic02
--zookeeper localhost:2181指定zookeeper集群--partitions指定分区数--replication-factor指定分区副本数
重新分配分区副本
声明需要分配的Topic
topic-generate.json
{"topics": [{"topic": "aloneness-topic"}],"version": 1
}
通过 --topics-to-move-json-file 参数,生成分区分配策略 --generate
kafka-reassign-partitions.bat --zookeeper localhost:2181 --topics-to-move-json-file topic-generate.json --broker-list "0,1,2" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"aloneness-topic","partition":0,"replicas":[0],"log_dirs":["any"]}]}Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"aloneness-topic","partition":0,"replicas":[1],"log_dirs":["any"]}]}
通过 --reassignment-json-file 参数,执行分区分配策略 --execute
kafka-reassign-partitions.bat --zookeeper localhost:2181 --reassignment-json-file partition-replica-reassignment.json --execute
相关文章:
Kakfa详解(一)
kafka使用场景 canal同步mysqlelk日志系统业务系统Topic kafka基础概念 Producer: 消息生产者,向kafka发送消息Consumer: 从kafka中拉取消息消费的客户端Consumer Group: 消费者组,消费者组是多个消费者的集合。消费者组之间互不影响,所有…...
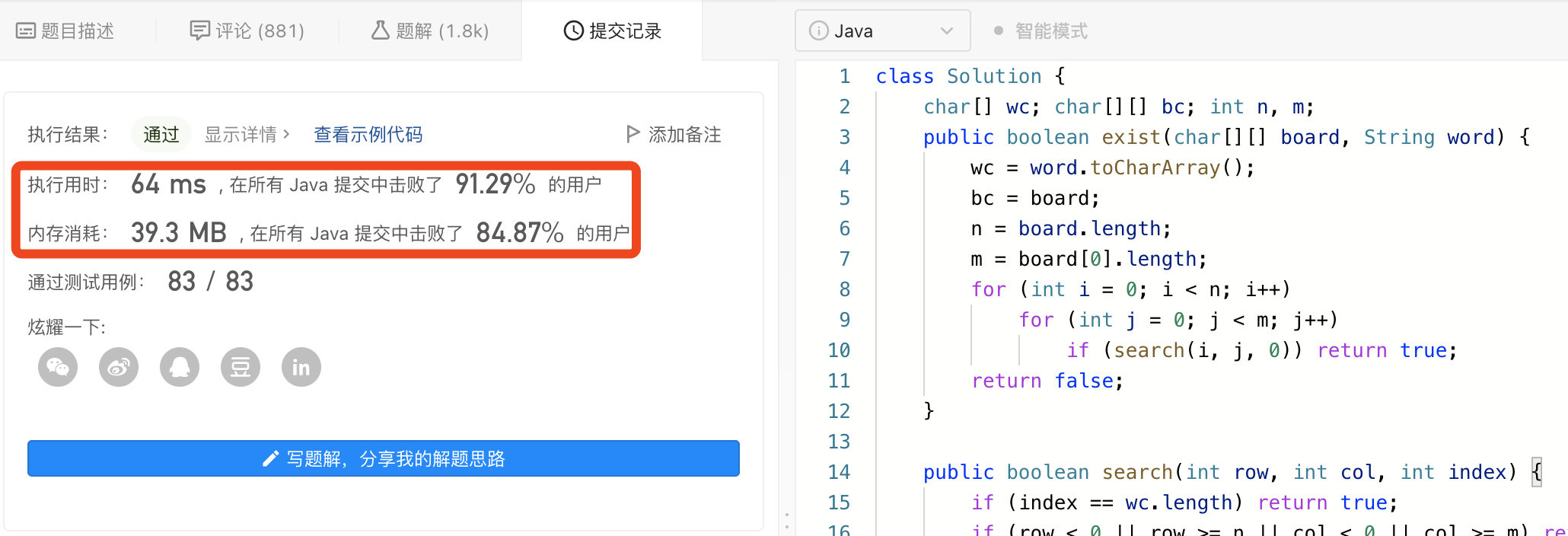
图解LeetCode——剑指 Offer 12. 矩阵中的路径
一、题目 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。 单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相…...

particles在vue3中的基本使用
第三方库地址 particles.vue3 - npm 1.安装插件 npm i particles.vue3 npm i tsparticles2.在main.js中引入 import Particles from particles.vue3 app.use(Particles) // 配置相关的文件常用 api particles.number.value>粒子的数量particles.number.density粒子的稀密…...
04 Android基础--RelativeLayout
04 Android基础--RelativeLayout什么是RelativeLayout?RelativeLayout的常见用法:什么是RelativeLayout? 相对布局(RelativeLayout)是一种根据父容器和兄弟控件作为参照来确定控件位置的布局方式。 根据父容器定位 在相…...

python基础命令
1.现在包的安装路径 #pip show 包名 2.pip讲解 相信对于大多数熟悉Python的人来说,一定都听说并且使用过pip这个工具,但是对它的了解可能还不一定是非常的透彻,今天小编就来为大家介绍10个使用pip的小技巧,相信对大家以后管理和…...
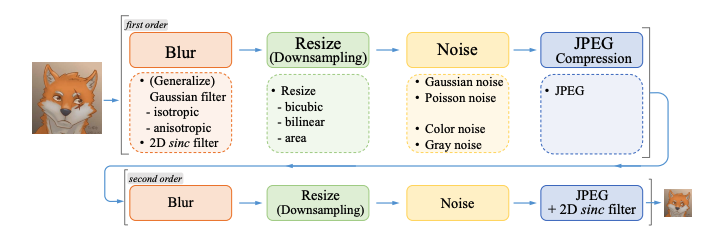
用 Real-ESRGAN 拯救座机画质,自制高清版动漫资源
内容一览:Real-ESRGAN 是 ESRGAN 升级之作,主要有三点创新:提出高阶退化过程模拟实际图像退化,使用光谱归一化 U-Net 鉴别器增加鉴别器的能力,以及使用纯合成数据进行训练。 关键词:Real-ESRGAN 超分辨率 视…...
)
数据结构预备知识(模板)
模板 功能上类比C的重载函数,可以使用一种通用的形式,去代替诸多数据类型,使得使用同一种函数的时候,可以实现对于不同数据类型的相同操作。增强类和函数的可重用性。 使用模板函数为函数或类声明一个一般的模式,使得…...
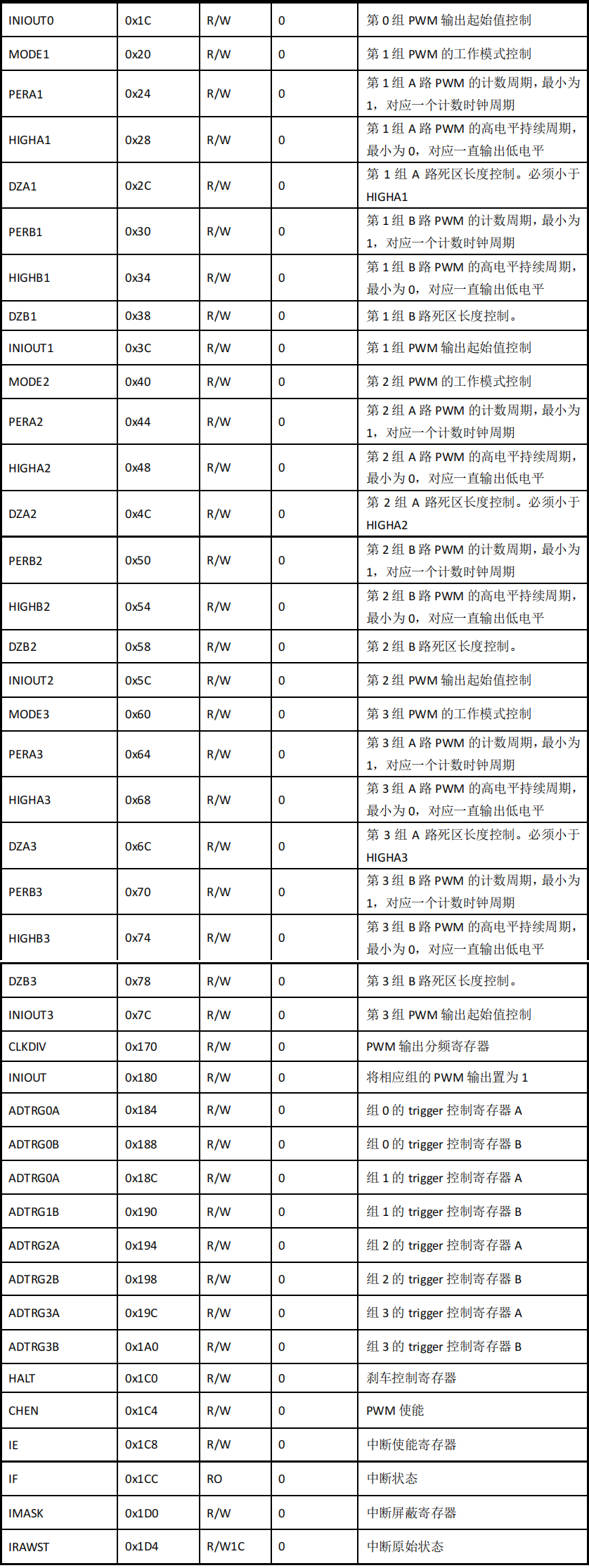
SWM181按键控制双通道PWM固定占空比输出
SWM181按键控制双通道PWM固定占空比输出📌SDK固件包:https://www.synwit.cn/kuhanshu_amp_licheng/ 🌼开发板如下图: ✨注意新手谨慎选择作为入门单片机学习。目前只有一个简易的数据手册和SDK包,又没有参考手册&am…...

pygame函数命令
pygame.mixer.music.load() —— 载入一个音乐文件用于播放 pygame.mixer.music.play() —— 开始播放音乐流 pygame.mixer.music.rewind() —— 重新开始播放音乐 pygame.mixer.music.stop() —— 结束音乐播放 pygame.mixer.music.pause() —— 暂停音乐播放 pygame.mixer.mu…...

异步循环
业务 : 批量处理照片 , 批量拆建 , 裁剪一张照片需要异步执行等待 , 并且是批量 所以需要用到异步循环 裁剪图片异步代码 : 异步循环 循环可以是 普通 for 、 for of 、 for in 不能使用forEach ,这里推荐 for…...

Vue表单提交与数据存储
学习内容来源:视频p5 书接目录对页面重新命名选择组件后端对接测试接口设置接口前端调用对页面重新命名 将之前的 Page1 Page2 进行重新命名,使其具有实际意义 Page1 → BookManage ; Page2 → AddBook 并且 /router/index.js 中配置页面信息…...
以及业务网关(后端服务网关)设计思路(二))
API网关(接入层之上业务层之上)以及业务网关(后端服务网关)设计思路(二)
文章目录 流量网关业务网关常见网关对比1. OpenResty2. KongKong解决了什么问题Kong的优点以及性能Kong架构3. Zuul1.0过滤器IncomingEndpointOutgoing过滤器类型Zuul 1.0 请求生命周期4. Zuul2.0Zuul 与 Zuul 2 性能对比5. Spring Cloud GatewaySpring Cloud Gateway 底层使用…...

有些笑话,外行人根本看不懂,只有程序员看了会狂笑不止
我一直都觉得我们写代码的程序员与众不同,就连笑话都跟别人不一样。 如果让外行人来看我们一些我们觉得好笑的东西,他们根本不知道笑点在哪里。 不信你来瞧瞧,但凡有看不懂的地方,说明你的道行还不够深。 1.大多数人开始学编程时…...

企业电子招投标采购系统——功能模块功能描述
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外…...

Presto 在美图的实践
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用…...

Molecule:使用Jetpack Compose构建StateFlow流
Molecule:使用Jetpack Compose构建StateFlow流 看下面的jetpack compose片段: Composable fun MessageCard(message: Message) {Column {Text(text message.author)Text(text message.body)} }这段代码最有趣的部分是它实际上是reactive。其反应性为 通过Composa…...
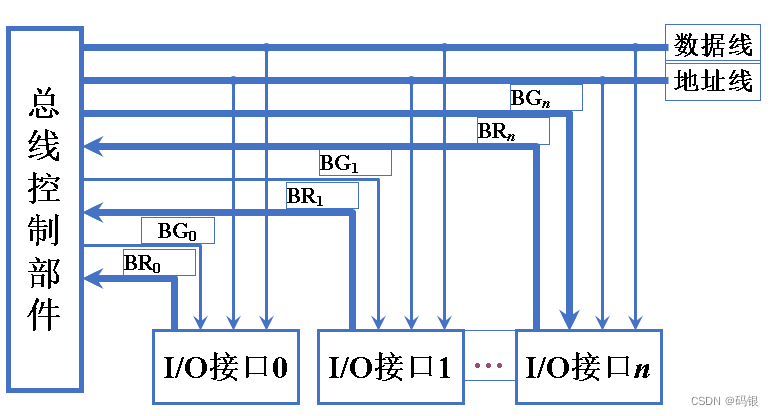
计算机组成原理(2.2)--系统总线
目录 一、总线结构 1.单总线结构 1.1单总线结构框图 编辑1.2单总线性能下降的原因 2.多总线结构 2.1双总线结构 2.2三总线结构 2.3四总线结构 编辑 二、总线结构举例 1. 传统微型机总线结构 2. VL-BUS局部总线结构 3. PCI 总线结构 4. 多层 PCI 总线结构 …...

如何使用dlinject将一个代码库实时注入到Linux进程中
关于dlinject dlinject是一款针对Linux进程安全的注入测试工具,在该工具的帮助下,广大研究人员可以在不使用ptrace的情况下,轻松向正在运行的Linux进程中注入一个共享代码库(比如说任意代码)。之所以开发该工具&#…...
Docker安装Cassandra数据库,在SpringBoot中连接Cassandra
简介 Apache Cassandra是一个高度可扩展的高性能分布式数据库,旨在处理许多商用服务器上的大量数据,提供高可用性而没有单点故障。它是NoSQL数据库的一种。首先让我们了解一下NoSQL数据库的作用。 NoSQL 数据库 NoSQL数据库(有时称为“Not …...
)
Linux常用命令总结(建议收藏)
Linux常用命令总结(建议收藏) 这里收集了一些常用命令以便需要时查看,欢迎作补充。(这里的提到操作都默认以CentOS系统为基础) 文件管理 目录操作 切换目录 cd 查看目录 ls -l 列出文件详细信息 或者直接ll-a 列出当前目录下所有文件及…...

【效率跃迁】STM32CubeMX:图形化配置如何重塑嵌入式开发流程
1. 从查手册到点鼠标:STM32CubeMX如何颠覆传统开发模式 十年前我第一次接触STM32开发时,光是搭建开发环境就花了整整三天。记得当时为了配置一个USART外设,需要反复翻阅1000多页的参考手册,核对寄存器地址、计算波特率分频值、确认…...

GOM传奇引擎外网架设避坑指南:常见问题与解决方案
GOM传奇引擎外网架设避坑指南:常见问题与解决方案 1. 外网架设前的关键准备工作 很多开发者在开始GOM引擎外网架设时,常常因为基础环境配置不当导致后续问题频发。这里分享几个容易被忽视但至关重要的准备环节: 硬件与网络环境检查清单&#…...

cv_unet_image-colorization实战教程:从环境搭建到批量处理黑白照片
cv_unet_image-colorization实战教程:从环境搭建到批量处理黑白照片 1. 引言 你有没有翻看过家里的老相册?那些黑白照片记录着珍贵的回忆,但总让人觉得少了点什么。色彩能让记忆更加鲜活,让历史重现光彩。今天,我要带…...

调试排错 - 线程Dump分析
Thread Dump介绍 什么是Thread Dump Thread Dump是非常有用的诊断Java应用问题的工具。每一个Java虚拟机都有及时生成所有线程在某一点状态的thread-dump的能力,虽然各个 Java虚拟机打印的thread dump略有不同,但是 大多都提供了当前活动线程的快照&…...

AgentCPM研报助手应用指南:如何用它高效完成课题研究与论文写作
AgentCPM研报助手应用指南:如何用它高效完成课题研究与论文写作 1. 为什么选择本地研报生成工具? 在学术研究和商业分析领域,撰写深度报告是每个研究者必须面对的任务。传统流程通常包括: 收集和阅读大量文献资料整理数据并构建…...

WuliArt Qwen-Image Turbo实际作品展示:雨滴在霓虹灯表面的物理反射模拟
WuliArt Qwen-Image Turbo实际作品展示:雨滴在霓虹灯表面的物理反射模拟 1. 项目概述 WuliArt Qwen-Image Turbo是一款专为个人GPU环境设计的轻量级文本生成图像系统。这个项目基于阿里通义千问的Qwen-Image-2512文生图底座,并深度融合了Wuli-Art专属的…...

Qwen3-ASR-1.7B部署教程:CentOS+Tesla T4环境下FP16推理稳定性验证
Qwen3-ASR-1.7B部署教程:CentOSTesla T4环境下FP16推理稳定性验证 想找一个既准确又能在自己电脑上安全运行的语音转文字工具?今天要聊的Qwen3-ASR-1.7B可能就是你要找的答案。它不像那些需要把音频上传到别人服务器的在线工具,而是完全在你…...

SER5 Pro迷你主机折腾记:ESXi 6.7+OpenWRT+群晖NAS三合一保姆级教程
SER5 Pro迷你主机全能实验室:从硬件解析到三系统无缝整合实战 零刻SER5 Pro这款AMD Ryzen 7 5800H加持的迷你主机,正在重新定义家庭实验室的性价比边界。当大多数用户还在为选择单一功能设备犹豫时,我们已经可以用这台巴掌大的机器同时承载虚…...
)
MobileNet实战:深度可分离卷积在移动端的高效应用(附PyTorch代码)
MobileNet实战:深度可分离卷积在移动端的高效应用(附PyTorch代码) 当你在手机上使用人脸解锁或实时滤镜时,有没有想过这些AI功能如何在资源有限的移动设备上流畅运行?答案就藏在深度可分离卷积这项关键技术中。与标准卷…...

FancyZones:重新定义Windows多屏效率的窗口智能管理革命
FancyZones:重新定义Windows多屏效率的窗口智能管理革命 【免费下载链接】PowerToys Windows 系统实用工具,用于最大化生产力。 项目地址: https://gitcode.com/GitHub_Trending/po/PowerToys 在当今数字化工作环境中,窗口管理已成为影…...