Python自动化测试系列[v1.0.0][多种数据驱动实现附源码]
前情提要
请确保已经熟练掌握元素定位的常用方法及基本支持,请参考Python自动化测试系列[v1.0.0][元素定位]
数据驱动测试是自动化测试中一种重要的设计模式,这种设计模式可以将测试数据和测试代码分开,实现数据与代码解耦,与此同时还能够实现一次任务中使用不同的数据来执行执行相同的测试脚本,因此它会使得我们的代码层次结构清晰,容易维护,并且大大降低了代码量
数据驱动是自动化测试中非常常见的一种设计模式,应用的场景非常多,无论是在Web自动化还是在接口自动化、单元测试,亦或是在数据分析应用领域的测试上都会得到非常广泛的使用,常见的比如Web自动化的登录功能、一些录入类的功能,再比如接口入参、单元测试的入参,甚至在数据类应用的大量数据输入及结果比较上
使用Excel存储测试输入数据
数据文件
假如我们有如下一组数据存储在Excel里
| 序号 | 检索词 | 期望结果 |
|---|---|---|
| 1 | 北京 | 北京 |
| 2 | 上海 | 上海 |
| 3 | 广州 | 广州 |
获取测试数据方法
通过python的openpyxl模块解析Excel文件,并获取数据
安装openpyxl
C:\Users\Administrator>pip install openpyxl
Collecting openpyxlDownloading openpyxl-3.0.3.tar.gz (172 kB)|████████████████████████████████| 172 kB 384 kB/s
Collecting jdcalUsing cached jdcal-1.4.1-py2.py3-none-any.whl (9.5 kB)
Collecting et_xmlfileUsing cached et_xmlfile-1.0.1.tar.gz (8.4 kB)
Installing collected packages: jdcal, et-xmlfile, openpyxlRunning setup.py install for et-xmlfile ... doneRunning setup.py install for openpyxl ... done
Successfully installed et-xmlfile-1.0.1 jdcal-1.4.1 openpyxl-3.0.3
方法封装
# encoding = utf-8
from openpyxl import load_workbookclass ParseExcel(object):def __init__(self, excelPath, sheetName):self.wb = load_workbook(excelPath)# self.sheet = self.lwb.get_sheet_by_name(sheetName)self.sheet = self.wb[sheetName]self.maxRowNum = self.sheet.max_rowdef getDatasFromSheet(self):dataList = []for line in list(self.sheet.rows)[1:]:tmpList = []tmpList.append(line[1].value)tmpList.append(line[2].value)dataList.append(tmpList)return dataListif __name__ == '__main__':excelPath = u'D:\\Programs\\Python\\PythonUnittest\\TestData\\测试数据.xlsx'sheetName = u'搜索数据表'pe = ParseExcel(excelPath, sheetName)for i in pe.getDatasFromSheet():print(i[0], i[1])
封装了getDatasFromSheet方法,该方法将解析Excel,并将数据存到List中去,后续的测试代码调用的实际上是从List里边获取数据
测试代码
# encoding = utf-8
from selenium import webdriver
import unittest
import time
import traceback
import ddt
import logging
from Util.ParseExcelUtil import ParseExcel
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level=logging.INFO,# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志的时间datefmt='%a, %d %b %Y %H:%M:%S',# 日志文件存放的目录及日志文件名filename='D:\\Programs\\Python\\PythonUnittest\\Reports\\TestResults.TestResults',# 打开日志的方式filemode='w'
)excelPath = u"D:\\Programs\\Python\\PythonUnittest\\TestData\\测试数据.xlsx"
sheetName = u"搜索数据表"
excel = ParseExcel(excelPath, sheetName)@ddt.ddt
class TestDataDrivenByExcel(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()@ddt.data( * excel.getDatasFromSheet())def test_dataDrivenByExcel(self, data):testData, expectData = tuple(data)url = "http://www.baidu.com"self.driver.get(url)self.driver.maximize_window()self.driver.implicitly_wait(10)try:self.driver.find_element_by_id("kw").send_keys(testData)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectData in self.driver.page_source)except NoSuchElementException as e:logging.error(u"查找的页面元素不存在,异常堆栈信息为:" + str(traceback.format_exc()))except AssertionError as e:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,失败" % (testData, expectData))except Exception as e:logging.error(u"未知错误,错误信息:" + str(traceback.format_exc()))else:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,通过" % (testData, expectData))def tearDown(self):self.driver.quit()
if __name__ == "__main__":unittest.main()
使用Parameterize模块组织数据集作为测试输入数据
安装PARAMETERIZE
C:\Users\Administrator>pip install parameterized
Collecting parameterizedDownloading https://files.pythonhosted.org/packages/a3/bf/6ef8239028beae8298e0806b4f79c2466b1b16ca5b85dc13d631c5ea92c4/parameterized-0.7.1-py2.py3-none-any.whl
Installing collected packages: parameterized
Successfully installed parameterized-0.7.1
测试代码
# -*- coding: utf-8 -*-
# @Time: 4/27/2019 1:52 PM
# @Author : Yang DaWei
# @Project : DataDrivenTest
# @FileName: Unittest_Parameterized.py
import unittest
from selenium import webdriver
import time
from parameterized import parameterized
from selenium.common.exceptions import NoSuchElementException # 引入NoSuchElementException异常类class LoginTest(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()self.url = "http://mail.163.com"self.driver.implicitly_wait(10)def user_login_163(self, username, password):driver = self.driverdriver.get(self.url)# 定义frame,他是页面中的iframe控件frame = self.driver.find_element_by_xpath("//*[@id='loginDiv']/iframe")time.sleep(1)try:self.driver.switch_to.frame(frame) # 切换进iframe控件self.driver.find_element_by_name("email").send_keys(username) # 输入用户名self.driver.find_element_by_name("password").send_keys(password) # 输入密码self.driver.find_element_by_id("dologin").click() # 点击登陆按钮except NoSuchElementException as e:# 将未找到页面元素的异常记录进日志raise eexcept Exception as e:raise e@parameterized.expand([('', "davieyang", "请输入帐号"),("davieyang", '', "请输入密码"),("error", "error", "帐号或密码错误"),])def test_login(self, username, password, assert_text):self.user_login_163(username, password)message = self.driver.find_element_by_id("nerror").textself.assertEqual(message, assert_text)def tearDown(self):self.driver.quit()if __name__ == '__main__':unittest.main(verbosity=2)使用JSON存储测试输入数据[List]
方式一
["北京||北京","上海||上海","广州||广州","深圳||深圳","香港||香港"
]
测试代码
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level=logging.INFO,# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志的时间datefmt='%a, %d %b %Y %H:%M:%S',# 日志文件存放的目录及日志文件名filename='F:\\DataDriven\\TestResults\TestResults.TestResults',# 打开日志的方式filemode='w'
)@ddt.ddt
class DataDrivenTestByDDTHTR(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome(executable_path="F:\\automation\\webdriver\\chromedriver.exe")# json文件所在路径@ddt.file_data("F:\\DataDriven\\testData\\test_data_list.json")def test_dataDrivenHTRByFile(self, value):url = "http://www.baidu.com"self.driver.get(url)self.driver.maximize_window()print(value)# 将从.json文件中读取出的数据用“||”分割成测试数据和期望的数据testdata, execptdata = tuple(value.strip().split("||"))# 设置隐式等待时间self.driver.implicitly_wait(10)try:self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)# 断言期望结果是否出现在页面中self.assertTrue(execptdata in self.driver.page_source)except NoSuchElementException as e:logging.error(u"查找的页面元素不存在,异常堆栈信息为:" + str(traceback.format_exc()))except AssertionError as e:logging.info(u"搜索 '%s',期望 '%s' ,失败" % (testdata, execptdata))except Exception as e:logging.error(u"未知错误,错误信息:" + str(traceback.format_exc()))else:logging.info(u"搜索 '%s',期望 '%s' ,通过" % (testdata, execptdata))def tearDown(self):self.driver.quit()if __name__ == '__main__':unittest.main()方式二
测试报告模板
# encoding = utf-8
"""
__title__ = 'DataDrivenTestByDDT use this template for generating testing report'
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
# encoding = utf-8
def htmlTemplate(trData):htmlStr = u'''<!DOCTYPE HTML><html><head><title>单元测试报告</title><style>body {width:80%;margin:40px auto;font-weight:bold;font-family: 'trebuchet MS', 'Lucida sans', SimSun;font-size:18px;color: #000;}table {* border-collapse:collapse;border-spacing:0;width:100%;}.tableStyle {/* border:solid #ggg 1px;*/border-style:outset;border-width:2px;/*border:2px;*/border-color:blue;}.tableStyle tr:hover {background: rgb(173.216.230);}.tableStyle td,.tableStyle th{border-left:solid 1px rgb(146,208,80);border-top:1px solid rgb(146,208,80);padding:15pxtext-align:center}.tableStyle th{padding:15px;background-color:rgb(146,208,80);/*表格标题栏设置渐变颜色*/background-image: -webkit -gradient(linear, left top, left bottom, from(#92D050), to(#A2D668))/*rgb(146,208,80)*/} </style></head><body><center><h1>测试报告</h1></center><br /><table class="tableStyle"><thead><tr><th>Search Words</th><th>Assert Words</th><th>Start Time</th><th>Waste Time(s)</th><th>Status</th></tr></thead>'''endStr = u'''</table></body></html>'''html = htmlStr + trData + endStrprint(html)with open("D:\\\Programs\\\Python\\\PythonUnittest\\\Reports\\testTemplate.html", "wb") as fp:fp.write(html.encode("gbk"))
测试脚本
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from DataDrivenTest.ReportTemplate import htmlTemplate
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level=logging.INFO,# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志的时间datefmt='%a, %d %b %Y %H:%M:%S',# 日志文件存放的目录及日志文件名filename='D:\\Programs\\Python\\PythonUnittest\\Reports\\TestResults.TestResults',# 打开日志的方式filemode='w'
)@ddt.ddt
class DataDrivenTestByDDT(unittest.TestCase):@classmethoddef setUpClass(cls):# 整个测试过程只调用一次DataDrivenTestByDDT.trStr = ""def setUp(self):self.driver = webdriver.Chrome(executable_path="D:\\Programs\\Python\\PythonUnittest\\BrowserDrivers\\chromedriver.exe")status = None # 用于存放测试结果状态,失败‘fail’,成功‘pass’flag = 0 # 数据驱动测试结果的标志,失败置0,成功置1@ddt.file_data("D:\\Programs\\Python\\PythonUnittest\\TestData\\test_data_list.json")def test_dataDrivenByFile(self, value):# 决定测试报告中状态单元格中内容的颜色flagDict = {0: 'red', 1: '#00AC4E'}url = "http://www.baidu.com"self.driver.get(url)self.driver.maximize_window()print(value)# 从.json文件中读取出的数据用“||”分割成测试数据和期望的数据testdata, execptdata = tuple(value.strip().split("||"))# 设置隐式等待时间self.driver.implicitly_wait(10)try:# 获取当前的时间戳,用于后面计算查询耗时用start = time.time()# 获取当前时间的字符串,表示测试开始时间startTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)# 断言期望结果是否出现在页面中self.assertTrue(execptdata in self.driver.page_source)except NoSuchElementException as e:logging.error(u"查找的页面元素不存在,异常堆栈信息为:"+ str(traceback.format_exc()))status = 'fail'flag = 0except AssertionError as e:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,失败" %(testdata, execptdata))status = 'fail'flag = 0except Exception as e:logging.error(u"未知错误,错误信息:" + str(traceback.format_exc()))status = 'fail'flag = 0else:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,通过" %(testdata, execptdata))status = 'pass'flag = 1# 计算耗时,从将测试数据输入到输入框中到断言期望结果之间所耗时wasteTime = time.time() - start - 3 # 减去强制等待3秒# 每一组数据测试结束后,都将其测试结果信息插入表格行的HTML代码中,并将这些行HTML代码拼接到变量trStr变量中,# 等所有测试数据都被测试结束后,传入htmlTemplate()函数中,生成完整测试报告的HTML代码DataDrivenTestByDDT.trStr += u'''<tr><td>%s</td><td>%s</td><td>%s</td><td>%.2f</td><td style = "color: %s">%s</td></tr><br/>''' % (testdata, execptdata, startTime, wasteTime, flagDict[flag], status)def tearDown(self):self.driver.quit()@classmethoddef tearDownClass(cls):# 写自定义的HTML测试报告,整个过程只被调用一次htmlTemplate(DataDrivenTestByDDT.trStr)if __name__ == '__main__':unittest.main()
生成日志
Fri, 07 Dec 2018 15:05:36 DataDrivenTestByDDT.py[line: 81] INFO 搜索 ‘北京’,期望 ‘北京’ ,通过
Fri, 07 Dec 2018 15:05:50 DataDrivenTestByDDT.py[line: 81] INFO 搜索 ‘上海’,期望 ‘上海’ ,通过
Fri, 07 Dec 2018 15:06:04 DataDrivenTestByDDT.py[line: 81] INFO 搜索 ‘广州’,期望 ‘广州’ ,通过
Fri, 07 Dec 2018 15:06:18 DataDrivenTestByDDT.py[line: 81] INFO 搜索 ‘深圳’,期望 ‘深圳’ ,通过
Fri, 07 Dec 2018 15:06:32 DataDrivenTestByDDT.py[line: 81] INFO 搜索 ‘香港’,期望 ‘香港’ ,通过
HTML报告

使用JSON存储测试输入数据[字典]
除了在json文件中放置List类型的数据,还可以放置Dict类型的数据,在PO项目的TestData路径下新建一个文件,并命名为login.json,然后在文件中写入如下测试数据。
{"test_login_01": {"username":"","password":"davieyang","assert_text": "请输入帐号"},"test_login_02": {"username":"davieyang","password":"","assert_text": "请输入密码"},"test_login_03":{"username":"error","password":"error","assert_text": "帐号或密码错误"}
}
测试脚本
# -*- coding: utf-8 -*-
import unittest
from selenium import webdriver
from ddt import ddt, file_data
import time
# 引入NoSuchElementException异常类
from selenium.common.exceptions import NoSuchElementException
from Configuration import ConstantConfig
# 定义测试数据文件
login_json = ConstantConfig.jsondictdata@ddt
class TestLogin(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()self.url = "http://mail.163.com"self.driver.implicitly_wait(10)def user_login_163(self, username, password):driver = self.driverdriver.get(self.url)# 定义frame,他是页面中的iframe控件frame = self.driver.find_element_by_xpath("//*[@id='loginDiv']/iframe")time.sleep(1)try:self.driver.switch_to.frame(frame) # 切换进iframe控件self.driver.find_element_by_name("email").send_keys(username) # 输入用户名self.driver.find_element_by_name("password").send_keys(password) # 输入密码self.driver.find_element_by_id("dologin").click() # 点击登陆按钮except NoSuchElementException as e:# 将未找到页面元素的异常记录进日志raise eexcept Exception as e:raise e@file_data(login_json)def test_login(self, username, password, assert_text): # 定义测试方法self.user_login_163(username, password) # 调用登陆163的方法message = self.driver.find_element_by_id("nerror").text self.assertEqual(message, assert_text) # 断言def tearDown(self):self.driver.quit()
if __name__ == '__main__':unittest.main(verbosity=2)
使用MySQL存储测试输入数据
测试数据
# encoding = utf-8create_database = 'CREATE DATABASE IF NOT EXISTS davieyang DEFAULT CHARSET utf8 COLLATE utf8_general_ci;'
drop_table = 'DROP TABLE testdata;'
create_table = """CREATE TABLE testdata(ID int primary key not null auto_increment comment '主键',BOOKNAME varchar(40) unique not null comment '书名',AUTHOR varchar(30) not null comment '作者')engine = innodb character set utf8 comment '测试数据表';
"""
获取数据库测试数据方法
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
import pymysql
from TestData.SqlScripts import create_table
from TestData.SqlScripts import create_database
from TestData.SqlScripts import drop_tableclass MySQL(object):def __init__(self, host, port, dbName, username, password, charset):self.conn = pymysql.connect(host=host,port=port,db=dbName,user=username,password=password,charset=charset)self.cur = self.conn.cursor()def create(self):try:self.cur.execute(create_database)self.conn.select_db("davieyang")self.cur.execute(drop_table)self.cur.execute(create_table)'''cur.execute("drop database if exists davieyang") #如果davieyang数据库存在则删除 cur.execute("create database davieyang") #新创建一个数据库davieyang cur.execute("use davieyang") #选择davieyang这个数据库 # sql 中的内容为创建一个名为testdata的表 sql = """create table testdata(id BIGINT,name VARCHAR(20),age INT DEFAULT 1)""" #()中的参数可以自行设置 conn.execute("drop table if exists testdata") # 如果表存在则删除 conn.execute(sql)# 创建表 # 删除 # conn.execute("drop table testdata") conn.close()# 关闭游标连接 connect.close()# 关闭数据库服务器连接 释放内存 '''except pymysql.Error as e:raise eelse:self.cur.close()self.conn.commit()self.conn.close()print(u"创建数据库和表成功")def insertDatas(self):try:sql = "insert into testdata(bookname, author) values(%s, %s);"self.cur.executemany(sql, [('selenium xml DataDriven', 'davieyang'),('selenium excel DataDriven', 'davieyang'),('selenium ddt data list', 'davieyang')])except pymysql.Error as e:raise eelse:self.conn.commit()print(u"初始数据插入成功")self.cur.execute("select * from testData;")for i in self.cur.fetchall():print(i[1], i[2])self.cur.close()self.conn.close()def getDataFromDataBase(self):# 从数据库中获取数据# bookname作为搜索关键词,author作为期望结果self.cur.execute("select bookname, author from testdata;")# 从查询区域取回所有查询结果dataTuple = self.cur.fetchall()return dataTupledef closeDataBase(self):# 数据库清理self.cur.close()self.conn.commit()self.conn.close()if __name__ == "__main__":db = MySQL(host="localhost",port=3306,dbName="davieyang",username="root",password="root",charset="utf8")print(db.getDataFromDataBase())db.closeDataBase()测试脚本
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from Util.MysqlDBUtil import MySQL
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level=logging.INFO,# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志的时间datefmt='%a, %d %b %Y %H:%M:%S',# 日志文件存放的目录及日志文件名filename='F:\\DataDriven\\TestResults\TestResults.TestResults',# 打开日志的方式filemode='w'
)def getTestDatas():db = MySQL(host="localhost",port=3306,dbName="davieyang",username="root",password="root",charset="utf8")# 从数据库中获取测试数据testData = db.getDataFromDataBase()db.closeDataBase()return testData@ddt.ddt
class DataDrivenByMySQL(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome(executable_path=r"F:\automation\webdriver\chromedriver.exe")@ddt.data(* getTestDatas())def test_dataDrivenByMySQL(self, data):# 对获得的数据进行解包testData, expectData =dataurl = "http://www.baidu.com"self.driver.get(url)self.driver.maximize_window()print(testData, expectData)self.driver.implicitly_wait(10)try:self.driver.find_element_by_id("kw").send_keys(testData)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectData in self.driver.page_source)except NoSuchElementException as e:logging.error(u"查找的页面元素不存在,异常堆栈信息为:" + str(traceback.format_exc()))except AssertionError as e:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,失败" % (testData, expectData))except Exception as e:logging.error(u"未知错误,错误信息:" + str(traceback.format_exc()))else:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,通过" % (testData, expectData))def tearDown(self):self.driver.quit()if __name__ == "__main__":unittest.main()
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level=logging.INFO,# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志的时间datefmt='%a, %d %b %Y %H:%M:%S',# 日志文件存放的目录及日志文件名filename='F:\\DataDriven\\TestResults\TestResults.TestResults',# 打开日志的方式filemode='w'
)@ddt.ddt
class DataDrivenDDT(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome(executable_path="F:\\automation\\webdriver\\chromedriver.exe")@ddt.data([u"阿里巴巴", u"腾讯"], [u"美团外卖", u"百度"], [u"饿了么", u"蚂蚁金服"])@ddt.unpackdef test_dataDrivenByDDT(self, testdata, expectdata):url = "http://www.baidu.com"self.driver.get(url)self.driver.implicitly_wait(30)try:self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectdata in self.driver.page_source)except NoSuchElementException as e:logging.error(u"查找的页面元素不存在,异常堆栈信息:" + str(traceback.format_exc()))except AssertionError as e:logging.info(u"搜索 '%s',期望 '%s' ,失败" % (testdata, expectdata))except Exception as e:logging.error(u"未知错误,错误信息:" + str(traceback.format_exc()))else:logging.info(u"搜索 '%s',期望 '%s' ,通过" % (testdata, expectdata))def tearDown(self):self.driver.quit()if __name__ == '__main__':unittest.main()
使用XML存储测试输入数据
<?xml version = "1.0" encoding = "utf-8"?>
<bookList type = "technology"><book><name>selenium xml datadriven</name><author>davieyang</author></book><book><name>selenium excel datadriven</name><author>davieyang</author></book><book><name>selenium ddt data list</name><author>davieyang</author></book>
</bookList>
解析XML方法
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
from xml.etree import ElementTreeclass ParseXML(object):def __init__(self, xmlPath):self.xmlPath = xmlPathdef getRoot(self):# 打开将要解析的XML文件tree = ElementTree.parse(self.xmlPath)# 获取XML文件的根节点对象,然后返回给调用者return tree.getroot()def findNodeByName(self, parentNode, nodeName):# 通过节点的名字获取节点对象nodes = parentNode.findall(nodeName)return nodesdef getNodeofChildText(self, node):# 获取节点node下所有子节点的节点名作为key,本节点作为value组成的字典对象childrenTextDict = {i.tag: i.text for i in list(node.iter())[1:]}# 上面代码等价于'''childrenTextDict = {}for i in list(node.iter())[1:]:fhildrenTextDict[i.tag] = i.text'''return childrenTextDictdef getDataFromXml(self):# 获取XML文档的根节点对象root = self.getRoot()# 获取根节点下所有名为book的节点对象books = self.findNodeByName(root, "book")dataList = []# 遍历获取到的所有book节点对象# 取得需要的测试数据for book in books:childrenText = self.getNodeofChildText(book)dataList.append(childrenText)return dataListif __name__ == "__main__":xml = ParseXML(r"F:\seleniumWithPython\TestData\TestData.xml")datas = xml.getDataFromXml()for i in datas:print(i["name"], i["author"])
测试脚本
# encoding = utf-8
"""
__title__ = ''
__author__ = 'davieyang'
__mtime__ = '2018/4/21'
"""
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from Util.ParseXMLUtil import ParseXML
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level=logging.INFO,# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志的时间datefmt='%a, %d %b %Y %H:%M:%S',# 日志文件存放的目录及日志文件名filename='D:\\Programs\\Python\\PythonUnittest\\Reports\\TestResults.TestResults',# 打开日志的方式filemode='w'
)# currentPath = os.path.dirname(os.path.abspath(__file__))
# dataFilePath = os.path.join(currentPath, "TestData.xml")
dataFilePath = "D:\\Programs\\Python\\PythonUnittest\\TestData\\TestData.xml"
print(dataFilePath)# 创建ParseXML类实例对象
xml = ParseXML(dataFilePath)@ddt.ddt
class DataDrivenTestByXML(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome(executable_path=r"F:\automation\webdriver\chromedriver.exe")@ddt.data(* xml.getDataFromXml())def test_dataDrivenByXML(self, data):testData, expectData = data["name"], data["author"]url = "http://www.baidu.com"self.driver.get(url)self.driver.maximize_window()self.driver.implicitly_wait(10)try:self.driver.find_element_by_id("kw").send_keys(testData)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectData in self.driver.page_source)except NoSuchElementException as e:logging.error(u"查找的页面元素不存在,异常堆栈信息为:" + str(traceback.format_exc()))except AssertionError as e:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,失败" % (testData, expectData))except Exception as e:logging.error(u"未知错误,错误信息:" + str(traceback.format_exc()))else:logging.info(u"搜索 ‘%s’,期望 ‘%s’ ,通过" % (testData, expectData))def tearDown(self):self.driver.quit()if __name__ == "__main__":unittest.main()相关文章:
Python自动化测试系列[v1.0.0][多种数据驱动实现附源码]
前情提要 请确保已经熟练掌握元素定位的常用方法及基本支持,请参考Python自动化测试系列[v1.0.0][元素定位] 数据驱动测试是自动化测试中一种重要的设计模式,这种设计模式可以将测试数据和测试代码分开,实现数据与代码解耦,与此同…...
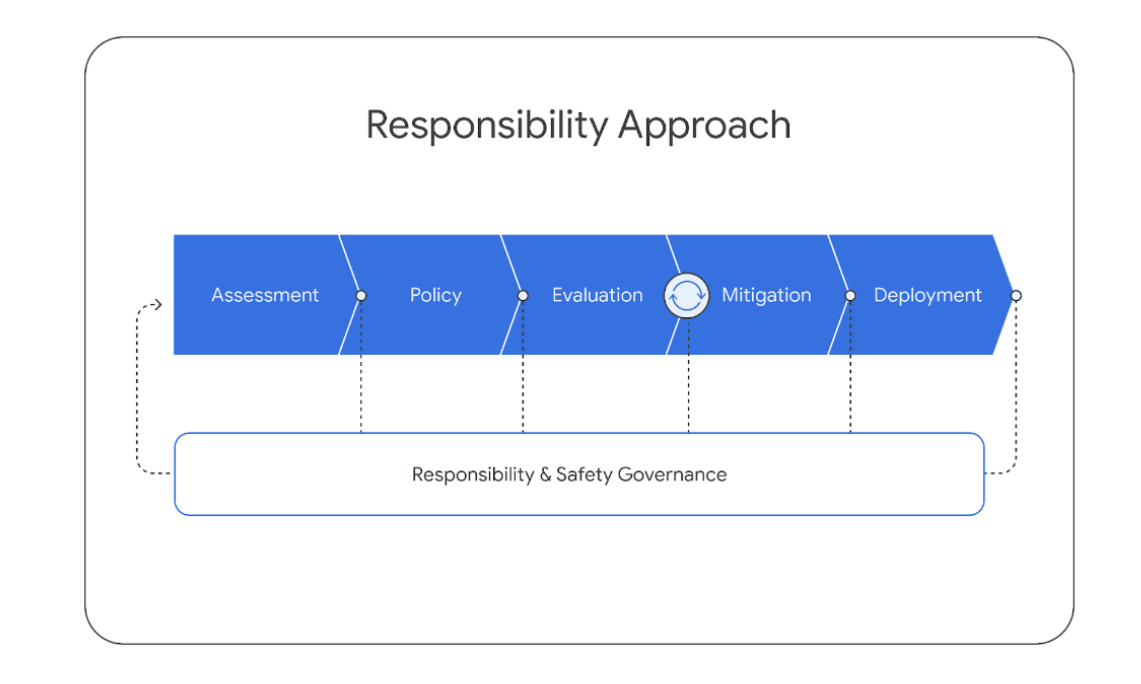
【论文笔记】Gemini: A Family of Highly Capable Multimodal Models——细看Gemini
Gemini 【一句话总结,对标GPT4,模型还是transformer的docoder部分,提出三个不同版本的Gemini模型,Ultra的最牛逼,Nano的可以用在手机上。】 谷歌提出了一个新系列多模态模型——Gemini家族模型,包括Ultra…...
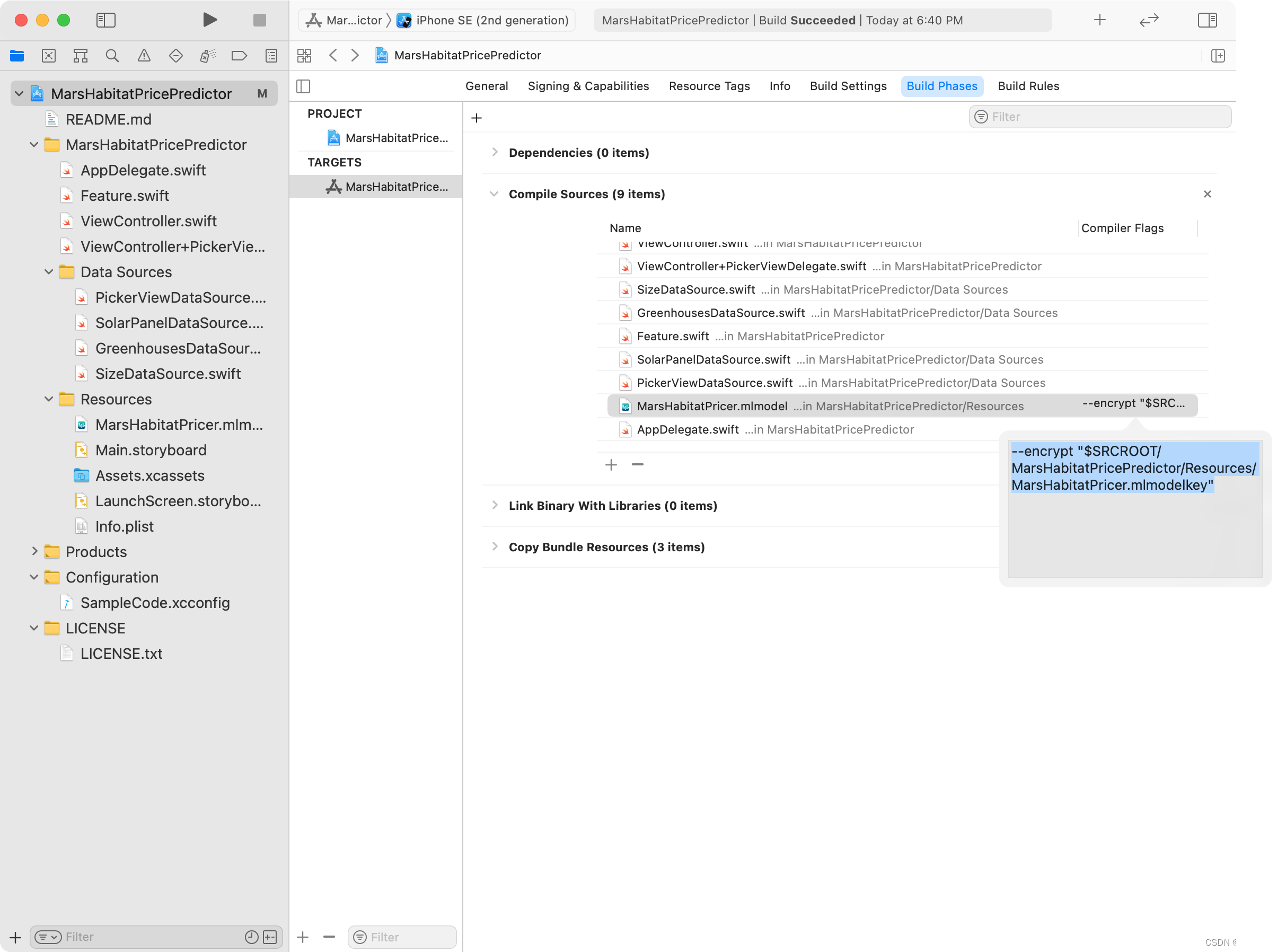
iOS加密CoreML模型
生成模型加密密钥 必须在Xcode的Preferences的Accounts页面登录Apple ID,才能在Xcode中生成模型加密密钥。 在Xcode中打开模型,单击Utilities选项卡,然后单击“Create Encryption Key”按钮。 从下拉菜单中选择当前App的Personal Team&…...
Springboot自定义start首发预告
Springboot自定义start首发预告 基于Springboot的自定义start , 减少项目建设重复工作, 如 依赖 , 出入参包装 , 日志打印 , mybatis基本配置等等等. 优点 模块化 可插拔 易于维护和升级 定制化 社区支持(后期支持) 发布时间 预告: 2023-12-10 预计发布: 2024-1-1 , 元旦首…...
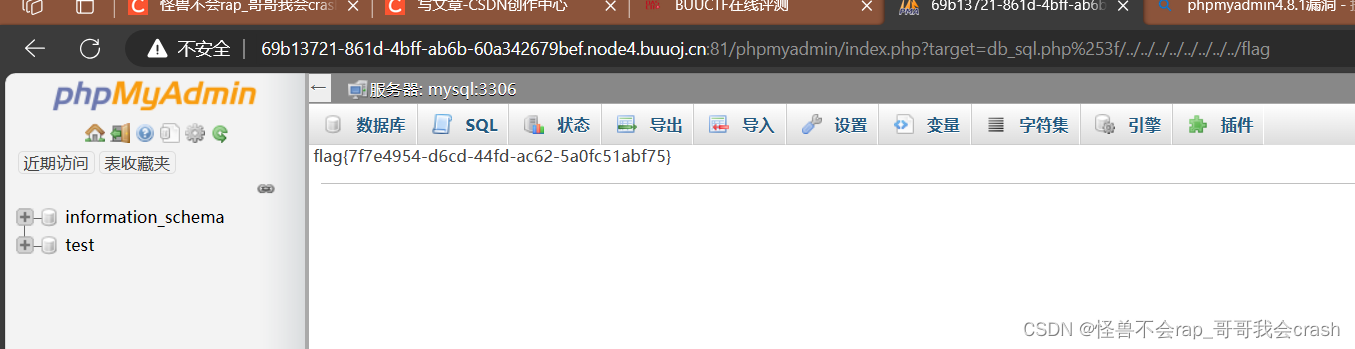
[GWCTF 2019]我有一个数据库1
提示 信息收集phpmyadmin的版本漏洞 这里看起来不像是加密应该是编码错误 这里访问robots.txt 直接把phpinfo.php放出来了 这里能看到它所有的信息 这里并没有能找到可控点 用dirsearch扫了一遍 ####注意扫描buuctf的题需要控制扫描速度,每一秒只能扫10个多一个都…...
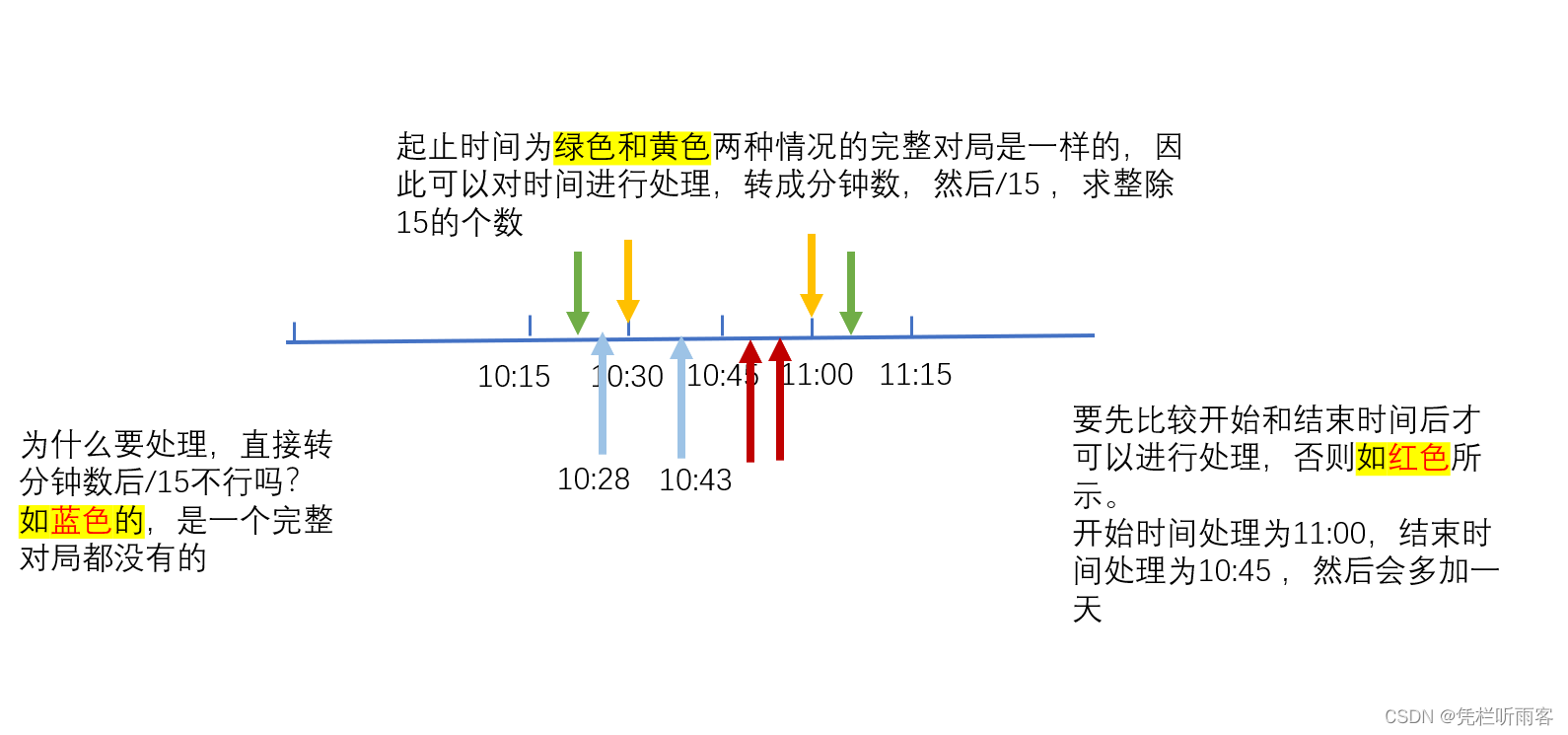
【LeetCode每日一题】1904. 你完成的完整对局数
给你两个字符串 startTime 和 finishTime ,均符合 "HH:MM" 格式,分别表示你 进入 和 退出 游戏的确切时间,请计算在整个游戏会话期间,你完成的 完整对局的对局数 。 如果 finishTime 早于 startTime ,这表示…...
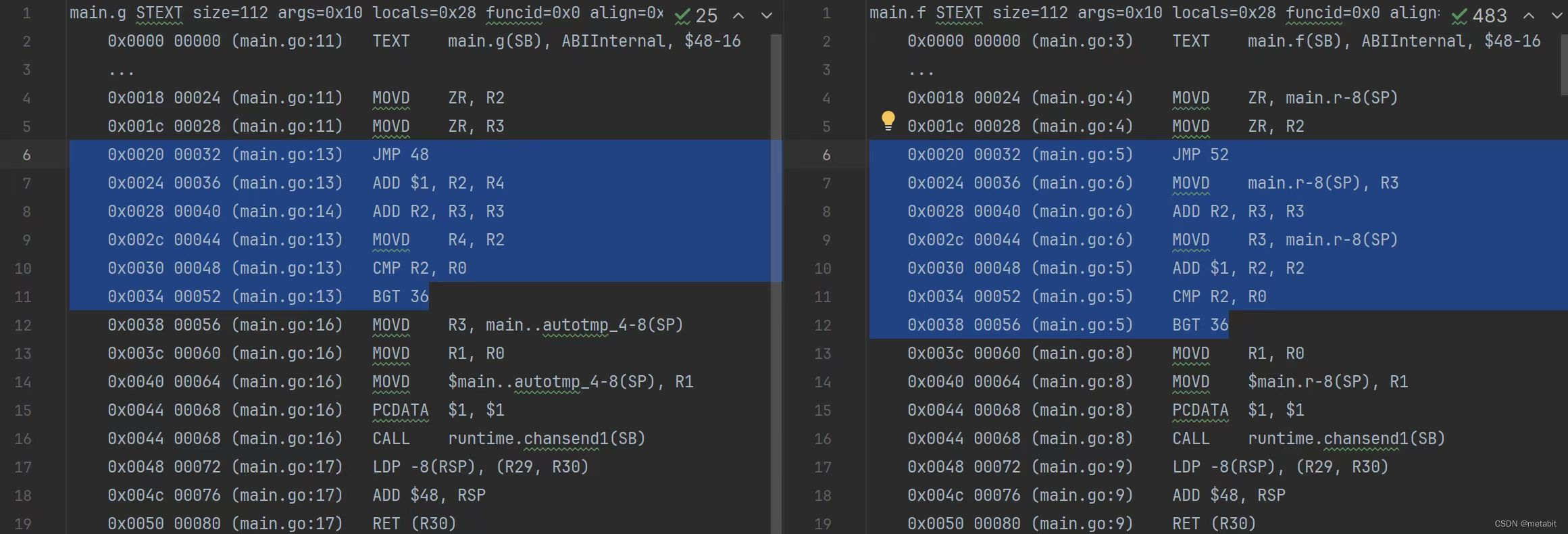
+0和不+0的性能差异
前几日,有群友转发了某位技术大佬的weibo。并在群里询问如下两个函数哪个执行的速度比较快(weibo内容)。 func g(n int, ch chan<- int) {r : 0for i : 0; i < n; i {r i}ch <- r 0 }func f(n int, ch chan<- int) {r : 0for …...

美颜技术讲解:视频美颜SDK的开发与集成
如今,美颜技术的应用愈发成为吸引用户的一项重要功能。本文将深入探讨视频美颜SDK的开发与集成,揭示其背后的技术原理和实现步骤。 一、美颜技术的背后 美颜技术并非仅仅是简单的滤镜效果,而是一项涉及复杂图像处理和算法的技术。在视频美颜…...

期末数组函数加强练习
前言:由于时间问题,部分题解取自网友,但都是做过的好题。 对于有些用c实现的题目,可以转化成c实现,cin看成c的读入,可以用scanf,输出cout看作printf,endl即换行符 开胃菜ÿ…...
如何下载B站视频?我来教你B站视频下载方法
如何下载B站视频?B站作为一个巨大的宝藏库,日常可以拿它作为娱乐工具,刷一些有趣新奇的短视频。也可以把它作为一款成长学习工具,具有丰富的公开课、纪录片内容。 对于较短的视频来说,花费几分钟时间看一下就结束了&am…...

AcWing 3709:单链表节点交换 ← 四川大学考研机试题
【题目来源】 https://www.acwing.com/problem/content/3712/【题目描述】 输入一个单链表,依次交换前2个数,第3、4个数,第5、6个数,…,以此类推,直到操作完整个链表。 如果链表长度是奇数,则最…...
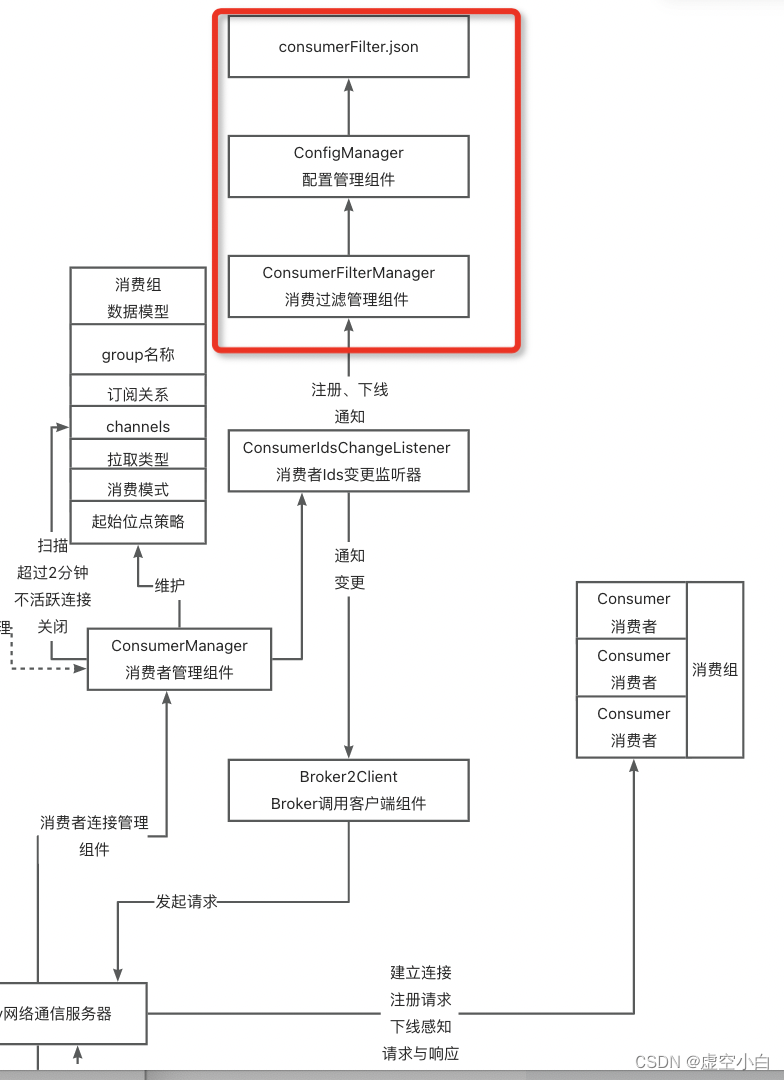
RocketMQ源码 Broker-ConsumerFilterManager 消费者数据过滤管理组件源码分析
前言 ConsumerFilterManager 继承了ConfigManager配置管理组件,拥有将内存数据持久化到磁盘文件consumerFilter.json的能力。它主要负责,对在消费者拉取消息时,进行消息数据过滤,且只针对使用表达式过滤的消费者有效。 源码版本&…...

数据挖掘-07-航空公司客户价值分析(包括数据和代码)
文章目录 0. 数据代码下载1. 背景与挖掘目标2. 导入相关库,加载数据2.1客户基本信息分布a. 绘制会员性别比例饼图b. 绘制会员各级别人数条形图c. 绘制年龄分布图 2.2 客户乘机信息分布分析a. 绘制客户飞行次数箱线图b. 绘制客户总飞行公里数箱线图 2.3 客户积分信息…...

浏览器 css 默认的字体图表
以下是一些常见的浏览器(PC端)中网站 CSS 默认字体及其对应的字体系列(font family): 浏览器默认字体字体系列(font family)ChromeArial, sans-serif“Arial”, “Helvetica Neue”, Helvetica…...

JAVA:注册表窗口的实现
目录 题目要求: 思路大意: 窗体的实现: 窗口A: 窗口B: 窗体之间的构思: 关键代码的实现: 窗口A: 封装列表: 窗口B: 题目要求: 使用…...

Liunx Centos 防火墙操作
liunx centos 防火墙 查看防火墙状态 systemctl status firewalld查看已经开放的端口 firewall-cmd --list-ports添加端口3306 firewall-cmd --zonepublic --add-port3306/tcp --permanent重启防火墙 firewall-cmd --reload数据库开放账号可以外网登陆 mysql -u root -p …...

VirtualBox 和 Vagrant 快速安装 Centos7 报错
VirtualBox 和 Vagrant 快速安装 Centos7 报错 今天尝试用 VirtualBox 和 Vagrant 快速安装 Centos7,BUG 多多! 1)下载 6.1.26 版本 VirtualBox,Windows11 不兼容???什么鬼? 解决…...

使用Python进行数学四则运算
当我们讨论到Python中的计算问题时,我们必然涉及到加法运算符()、减法运算符(-)、乘法运算符(*)以及除法运算符(/)这四大常见的算术运算。下面,我将为您展示如…...
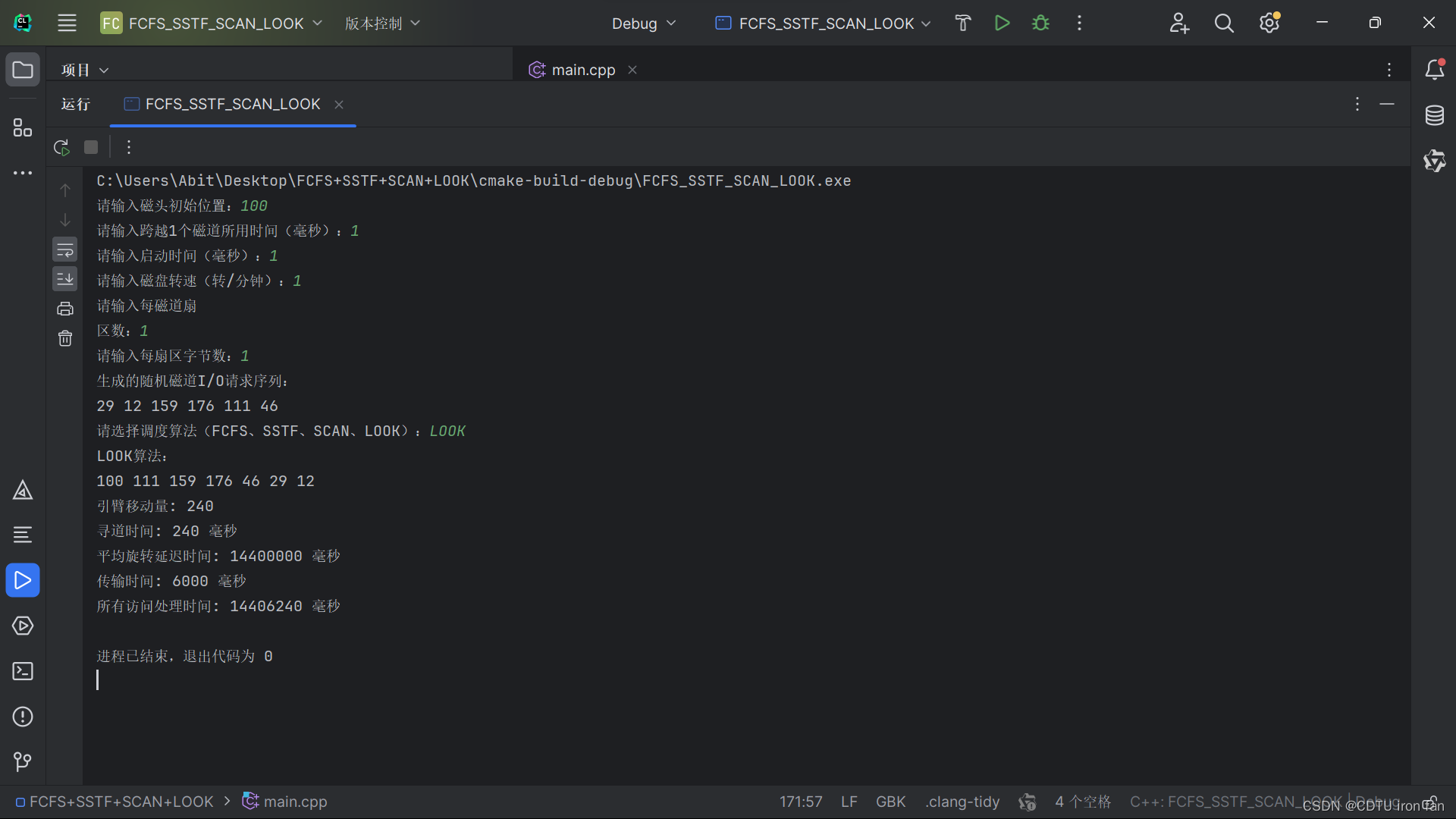
成都工业学院2021级操作系统专周课程设计FCFS,SSTF,SCAN,LOOK算法的实现
运行环境 操作系统:Windows 11 家庭版 运行软件:CLion 2023.2.2 源代码文件 #include <iostream> #include <vector> #include <algorithm> #include <random> using namespace std;// 生成随机数 int generateRandomNumber…...
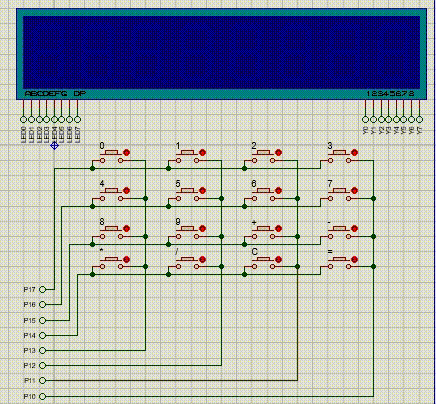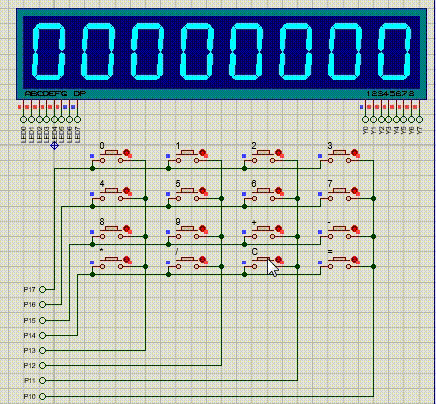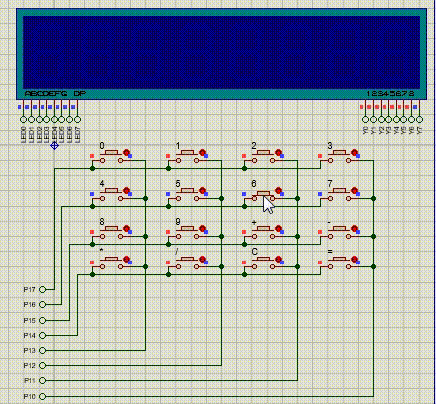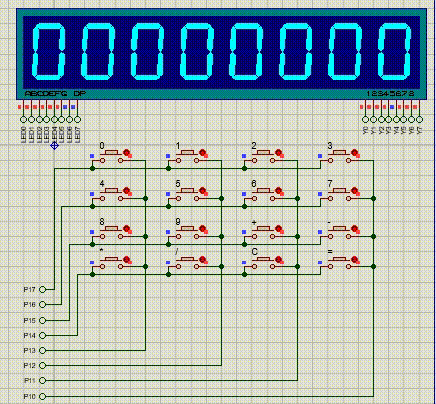
【51单片机系列】矩阵按键扩展实验
本文对矩阵按键的一个扩展,利用矩阵按键和动态数码管设计一个简易计算器。代码参考:https://blog.csdn.net/weixin_47060099/article/details/106664393 实现功能:使用矩阵按键,实现一个简易计算器,将计算数据及计算结…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...