随机分词与tokenizer(BPE->BBPE->Wordpiece->Unigram->sentencepiece->bytepiece)
0 tokenizer综述
- 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。
- subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。
- 完整的分词流程包括:文本归一化,预切分,基于分词模型的切分,后处理。
- SentencePiece是一个分词工具,内置BEP等多种分词方法,基于Unicode编码并且将空格视为特殊的token。这是当前大模型的主流分词方案。
BPE:GPT, GPT-2, GPT-J, GPT-Neo, RoBERTa, BART, LLaMA, ChatGLM-6B, Baichuan
WordPiece:BERT, DistilBERT,MobileBERT
Unigram:AlBERT, T5, mBART, XLNet
中文分词&新词发现
1 基于subword的切分
基于词和字的切分都会存在一定的问题,直接应用的效果比较差。
基于词的切分,会造成:词表规模过大
一定会存在UNK,造成信息丢失
不能学习到词缀之间的关系,例如:dog与dogs,happy与unhappy基于字的切分,会造成:
每个token的信息密度低
序列过长,解码效率很低所以基于词和基于字的切分方式是两个极端,其优缺点也是互补的。而折中的subword就是一种相对平衡的方案。
基于subword的切分能很好平衡基于词切分和基于字切分的优缺点,也是目前主流最主流的切分方式。
subword的基本切分原则是:高频词依旧切分成完整的整词
低频词被切分成有意义的子词,例如 dogs => [dog, ##s]基于subword的切分可以实现:
词表规模适中,解码效率较高
不存在UNK,信息不丢失
能学习到词缀之间的关系基于subword的切分包括:BPE,WordPiece 和 Unigram 三种分词模型。
1.1 处理流程概述
- 归一化:最基础的文本清洗,包括删除多余的换行和空格,转小写,移除音调等。
HuggingFace tokenizer的实现: https://huggingface.co/docs/tokenizers/api/normalizers- 预分词:把句子切分成更小的“词”单元。可以基于空格或者标点进行切分。 不同的tokenizer的实现细节不一样。例如:
pre-tokenize:
[BERT]: [(‘Hello’, (0, 5)), (‘,’, (5, 6)), (‘how’, (7, 10)), (‘are’, (11, 14)), (‘you’, (16, 19)), (‘?’, (19, 20))]
[GPT2]: [(‘Hello’, (0, 5)), (‘,’, (5, 6)), (‘Ġhow’, (6, 10)), (‘Ġare’, (10, 14)), (‘Ġ’, (14, 15)), (‘Ġyou’, (15, 19)), (‘?’, (19, 20))]
[t5]: [(‘▁Hello,’, (0, 6)), (‘▁how’, (7, 10)), (‘▁are’, (11, 14)), (‘▁you?’, (16, 20))]
可以看到BERT的tokenizer就是直接基于空格和标点进行切分。
GPT2也是基于空格和标签,但是空格会保留成特殊字符“Ġ”。
T5则只基于空格进行切分,标点不会切分。并且空格会保留成特殊字符"▁",并且句子开头也会添加特殊字符"▁"。
预分词的实现: https://huggingface.co/docs/tokenizers/api/pre-tokenizers- 基于分词模型的切分:不同分词模型具体的切分方式。分词模型包括:BPE,WordPiece 和 Unigram 三种分词模型。
分词模型的实现: https://huggingface.co/docs/tokenizers/api/models- 后处理:后处理阶段会包括一些特殊的分词逻辑,例如添加sepcial token:[CLS],[SEP]等。
后处理的实现: https://huggingface.co/docs/tok
1.2 BPE
Byte-Pair Encoding(BPE)是最广泛采用的subword分词器。
训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
编码方法:将文本切分成字符,再应用训练阶段获得的合并规则
经典模型:GPT, GPT-2, RoBERTa, BART, LLaMA, ChatGLM等
因为BPE是从字符级别的小词表,逐步合并成大词表,所以需要先获得字符级别的小词表。
基于word2splits统计vocabs中相邻两个pair的词频pair2count
经过统计,当前频率最高的pair为: (‘Ġ’, ‘t’), 频率为7次。 将(‘Ġ’, ‘t’)合并成一个词并添加到词表中。同时在合并规则中添加(‘Ġ’, ‘t’)这条合并规则。
根据更新后的vocab重新对word2count进行切分。具体实现上,可以直接在旧的word2split上应用新的合并规则(‘Ġ’, ‘t’)
从而获得新的word2split
重复上述循环直到整个词表的大小达到预先设定的词表大小。
在推理阶段,给定一个句子,我们需要将其切分成一个token的序列。 具体实现上需要先对句子进行预分词并切分成字符级别的序列,然后根据合并规则进行合并。
BPE 的适用范围
BPE 一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。而中文的汉字一般不用 BPE 进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种。理论上分词效果更好,更好的区别语义。分字效率高、简洁,因为常用的字不过 3000 字,词表更加简短。
1.3 BBPE
2019年提出的Byte-level BPE (BBPE)算法是上面BPE算法的进一步升级。具体参见:Neural Machine Translation with Byte-Level Subwords。 核心思想是用byte来构建最基础的词表而不是字符。首先将文本按照UTF-8进行编码,每个字符在UTF-8的表示中占据1-4个byte。 在byte序列上再使用BPE算法,进行byte level的相邻合并。编码形式如下图所示:

通过这种方式可以更好的处理跨语言和不常见字符的特殊问题(例如,颜文字),相比传统的BPE更节省词表空间(同等词表大小效果更好),每个token也能获得更充分的训练。
但是在解码阶段,一个byte序列可能解码后不是一个合法的字符序列,这里需要采用动态规划的算法进行解码,使其能解码出尽可能多的合法字符。具体算法如下: 假定f(k)表示字符序列B(1,k)最大能解码的合法字符数量,f(k)有最优的子结构:

1.4 WordPiece
WordPiece分词与BPE非常类似,只是在训练阶段合并pair的策略不是pair的频率而是互信息。
这里的动机是一个pair的频率很高,但是其中pair的一部分的频率更高,这时候不一定需要进行该pair的合并。 而如果一个pair的频率很高,并且这个pair的两个部分都是只出现在这个pair中,就说明这个pair很值得合并。
训练方法:从字符级的小词表出发,训练产生合并规则以及一个词表
编码方法:将文本切分成词,对每个词在词表中进行最大前向匹配
经典模型:BERT及其系列DistilBERT,MobileBERT等
在训练环节,给定语料,通过训练算法,生成最终的词表。 WordPiece算法也是从一个字符级别的词表为基础,逐步扩充成大词表。合并规则为选择相邻pair互信息最大的进行合并。
def _compute_pair2score(word2splits, word2count):"""计算每个pair的分数score=(freq_of_pair)/(freq_of_first_element×freq_of_second_element):return:"""vocab2count = defaultdict(int)pair2count = defaultdict(int)for word, word_count in word2count.items():splits = word2splits[word]if len(splits) == 1:vocab2count[splits[0]] += word_countcontinuefor i in range(len(splits) - 1):pair = (splits[i], splits[i + 1])vocab2count[splits[i]] += word_countpair2count[pair] += word_countvocab2count[splits[-1]] += word_countscores = {pair: freq / (vocab2count[pair[0]] * vocab2count[pair[1]])for pair, freq in pair2count.items()}return scores
1.5 Unigram
Unigram分词与BPE和WordPiece不同,是基于一个大词表逐步裁剪成一个小词表。
通过Unigram语言模型计算删除不同subword造成的损失来衡量subword的重要性,保留重要性较高的子词。
训练方法:从包含字符和全部子词的大词表出发,逐步裁剪出一个小词表,并且每个词都有自己的分数。
编码方法:将文本切分成词,对每个词基于Viterbi算法求解出最佳解码路径。
经典模型:AlBERT, T5, mBART, Big Bird, XLNet
在训练环节,目标是给定语料,通过训练算法,生成最终的词表,并且每个词有自己的概率值。 Unigram算法是从大词表为基础,逐步裁剪成小词表。裁剪规则是根据Unigram语言模型的打分依次裁剪重要度相对较低的词。
首先进行预切分处理。这里采用xlnet的预切分逻辑。具体会按照空格进行切分,标点不会切分。并且空格会保留成特殊字符"▁",句子开头也会添加特殊字符"▁"。
获得的pre_tokenized_corpus如下,每个单元分别为[word, (start_index, end_index)]
统计词表的全部子词和词频,取前300个词,构成最初的大词表。为了避免OOV,char级别的词均需要保留。
进一步统计每个子词的概率,并转换成Unigram里的loss贡献
基于每个子词的loss以及Viterbi算法就可以求解出,输入的一个词的最佳分词路径。即整体语言模型的loss最小。词的长度为N,解码的时间复杂度为O(N^2)。
尝试移除model中的一个子词,并计算移除后新的model在全部语料上的loss,从而获得这个子词的score,即删除这个子词使得loss新增的量。
为了提升迭代效率,批量删除前10%的结果,即让整体loss增量最小的前10%的词。(删除这些词对整体loss的影响不大。)
获得新的词表后,重新计算每个词的概率,获得新的模型。并重复以上步骤,直到裁剪到词表大小符合要求。
初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
针对当前词表,用EM算法求解每个子词在语料上的概率。
对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
重复步骤2到4,直到词表大小减少到设定范围。
可以看出,ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
1.6 SentencePiece
SentencePiece是Google出的一个分词工具:
内置BPE,Unigram,char和word的分词方法无需预分词,以unicode方式直接编码整个句子,空格会被特殊编码为▁
相比传统实现进行优化,分词速度速度更快
当前主流的大模型都是基于sentencepiece实现,例如ChatGLM的tokenizer。
byte回退
当SentencePiece在训练BPE的时开启–byte_fallback, 在效果上类似BBPE,遇到UNK会继续按照byte进行进一步的切分。参见:https://github.com/google/sentencepiece/issues/621 具体实现上是将<0x00> … <0xFF>这256个token添加到词表中。
分析ChatGLM的模型,可以发现ChatGLM就是开启了–byte_fallback
同样的方法,可以验证LLaMA, ChatGLM-6B, Baichuan这些大模型都是基于sentencepiece实现的BPE的分词算法,并且采用byte回退。
参考链接:https://zhuanlan.zhihu.com/p/651430181
1.7 bytepiece
一个理想的Tokenizer应该是怎样的,这样才能判断最终是否达到了预期。照笔者看来,Tokenizer至少应该具备如下基本特性:
1、无损重构:分词结果应该可以无损还原为输入;
2、高压缩率:词表大小相同时,同一批数据的tokens数应该尽可能少;
3、语言无关:基于统计,训练和分词过程都不应引入语言特性;
4、数据驱动:可以直接基于原始语料进行无监督训练;
5、训练友好:能够在合理的时间和配置上完成训练过程。
最后,还有一些加分项,比如分词速度快、代码易读、方便二次拓展等,这些满足自然最好,但笔者认为可以不列入基本特性里边。
对于笔者来说,SentencePiece最大的槽点就是“无损重构”和“训练友好”。
首先,SentencePiece默认会进行NFKC normalization,这会导致“全角逗号转半角逗号”等不可逆变化,所以默认情况下它连“无损重构”都不满足,所以很长时间里它都不在笔者的候选名单中,直到后来发现,在训练时添加参数–normalization_rule_name=identity就可以让它不做任何转换。所以SentencePiece算是支持无损重构,只不过要特别设置。
至于训练方面,就更让人抓狂了。SentencePiece支持BPE和Unigram两种主流算法,Unigram训练速度尚可,但压缩率会稍低一些,BPE的压缩率更高,但是训练速度要比Unigram慢上一个数量级!而且不管是BPE还是Unigram,训练过程都极费内存。总而言之,用较大的语料去训练一个SentencePiece模型真不是一种好的体验。
1.7.1 byte-based
我们知道,Python3的默认字符串类型是Unicode,如果以Unicode为基本单位,我们称之为Char-based。Char-based很直观方便,汉字表现为长度为1的单个字符,但不同语言的Char实在太多,即便只是覆盖单字都需要消耗非常大的vocab_size,更不用说引入Word。所以BytePiece跟主流的Tokenizer一样,以Byte为基本单位。
回到Byte之后,很多问题都“豁然开朗”了。因为不同的单Byte只有256个,所以只要词表里包含了这256个单Byte,那么就可以杜绝OOV(Out of Vocabulary),这是它显而易见的好处。
此外,我们知道汉字的平均信息熵要比英文字母的平均信息熵要大,如果我们选择Char-based,那么虽然每个Char表面看起来长度都是1,但“内在”的颗粒度不一样,这会导致统计结果有所偏置。相比之下,每个Byte的信息熵则更加均匀【比如,大部分汉字的UTF-8编码对应3个Byte,而汉字的平均信息熵正好是英文字母(对应一个Byte)的2~3倍左右】,因此用Byte的统计结果会更加无偏,这将会使得模型更加“语言无关”。
在Byte-based方面,BytePiece比SentencePiece更彻底,SentencePiece是先以Char-based进行处理,然后遇到OOV再以Byte-based处理,BytePiece则是在一开始就将文本通过text.encode()转为Bytes,然后才进行后续操作,相比之下更加纯粹。
1.7.2 分词算法
基于词典进行分词的算法无非就那几种,比如最大匹配、最短路径、最大概率路径等,
跟jieba等中文分词工具一样,BytePiece选择的是最大概率路径分词,也称“一元文法模型”,即Unigram。
选择Unigram有三方面的考虑:
第一,Unigram的最大概率换言之就是最大似然,而LLM的训练目标也是最大似然,两者更加一致;
第二,从压缩的角度看,最大概率实际上就是最短编码长度(也叫最小描述长度),是压缩率最大化的体现,这也跟“压缩就是智能”的信仰一致;
第三,Unigram求最优分词方案可以通过Viterbi算法在线性复杂度内完成,这是理论最优的复杂度了。
当然,既然有“一元文法模型”,自然也有更复杂的“二元文法模型”、“三元文法模型”等,但它们的复杂度增加远大于它能带来的收益,所以我们通常不考虑这些高阶模型。
1.7.3 训练算法
Tokenizer的训练本质上就是以往的“新词发现”,而笔者之前也提了好几种新词发现算法。现在看来,跟Unigram分词算法最契合、最有潜力的,应该是《基于语言模型的无监督分词》,
BytePiece的训练就是基于它实现的,这里称之为Byte-based N-gram Language Model(BNLM)。
具体来说,对于Unigram分词,如果一个长度为l的字节串c1,c2,…,cl,最优分词结果为w1,w2,…,wm,那么概率乘积p(w1)p(w2)…p(wm)应该是所有切分中最大的。
设w1,w2,⋯,wm的长度分别为l1,l2,⋯,lm,那么根据条件分解公式
∏i=1mp(wi)=∏i=1m∏j=Li−1+1j=Li−1+lip(cj|cLi−1+1,⋯,cj−1) (1)
这里Li=l1+l2+⋯+li。只考虑n-gram模型,将j>Li−1+n的p(cj|cLi−1+1,⋯,cj−1)统一用p(cj|cj−n+1,⋯,cj−1)近似,
那么Unigram分词就转化为一个字(节)标注问题,而Tokenizer的训练则转化为n-gram语言模型的训练(推荐n=6),可以直接无监督完成。
(注意:n=6只是说BytePiece的统计信息最多到6-gram,但并非最大只能生成长度为6的piece,因为大于6的n-gram条件概率我们会用6-gram的近似,所以它是可以做到任意阶的,即理论上可以生成任意长度piece。)
1.7.4 代码实现&效果
Github:https://github.com/bojone/bytepiece
代码很简单,单文件,里边就Trainer和Tokenizer两个类,分别对应分词两部分。分词借助pyahocorasick来构建AC自动机来稍微提了一下速,能凑合用,但还是会比SentencePiece慢不少,毕竟速度方面纯Python跟C++确实没法比。
训练则分为四个主要步骤:
1、n-gram计数;
2、n-gram剪枝;
3、预分词;
4、预分词结果剪枝。
其中1、3、4都是计算密集型,并且都是可并行的,所以编写了相应的多进程实现。在开足够多的进程(笔者开了64进程,每个进程的使用率基本上都是满的)下,训练速度能媲美SentencePiece的Unigram训练速度。
这里特别要提一下结果剪枝方面。剪枝最基本的依据自然是频数和vocab_size,但这还不够,因为有时候会出现p(w1)p(w2)>p(w1∘w2)(w1∘w2指两个词拼接)且w1,w2,w1∘w2三个词都在词表中,这种情况下w1∘w2这个词永远不会切分出来,所以将它放在词表中是纯粹浪费空间的,因此剪枝过程也包含了这类结果的排除。
首先做个小规模的测试,从悟道之前开源的数据集里边随机采样10万条作为训练集(导出来的文件大概330MB),然后另外采样1千作为测试集,训练一个vocab_size=50k的词表,结果对比如下:
接下来进行一个更大规模的测试。从中英比例大致为3:5的混合语料库中,抽取出10万条样本训练vocab_size=100k的Tokenizer。这个语料库的文本都比较长,所以这时候10万条导出来的文件已经13GB了,测试集包含两部分,一部分是同样的语料库中采样出1000条(即同源),另一部分是刚才采样出来的1000条悟道数据集(代表不同源)。结果如下:

相关文章:

随机分词与tokenizer(BPE->BBPE->Wordpiece->Unigram->sentencepiece->bytepiece)
0 tokenizer综述 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。完…...
成都工业学院Web技术基础(WEB)实验四:CSS3布局应用
写在前面 1、基于2022级计算机大类实验指导书 2、代码仅提供参考,前端变化比较大,按照要求,只能做到像,不能做到一模一样 3、图片和文字仅为示例,需要自行替换 4、如果代码不满足你的要求,请寻求其他的…...

TikTok科技趋势:平台如何引领数字社交革命?
TikTok作为一款颠覆性的短视频应用,不仅改变了用户的娱乐方式,更在数字社交领域引领了一场革命。本文将深入探讨TikTok在科技趋势方面的引领作用,分析其在数字社交革命中的关键角色,以及通过技术创新如何不断满足用户需求…...
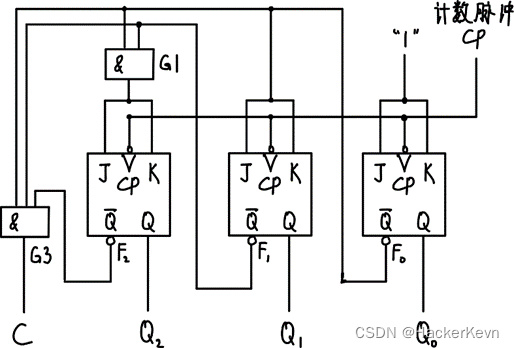
【上海大学数字逻辑实验报告】六、时序电路
一、 实验目的 掌握同步二进制计数器和移位寄存器的原理。学会用分立元件构成2位同步二进制加计数器。学会在Quartus II上设计单向移位寄存器。学会在Quartus II上设计环形计数器。 二、 实验原理 同步计数器是指计数器中的各触发器的时钟脉冲输入端连接在一起,接…...

docker版zerotier-planet服务端搭建
1:ZeroTier 介绍2:为什么要自建PLANET 服务器3:开始安装 3.1:准备条件 3.1.1 安装git3.1.2 安装docker3.1.3 启动docker3.2:下载项目源码3.3:执行安装脚本3.4 下载 planet 文件3.5 新建网络 3.5.1 创建网络4.客户端配置 4.1 Windows 配置 4.2 加入网络4.2 Linux 客户端4.…...
【Spring教程28】Spring框架实战:从零开始学习SpringMVC 之 请求与请求参数详解
目录 1 设置请求映射路径1.1 环境准备 1.2 问题分析1.3 设置映射路径 2 请求参数2.1 环境准备2.2 参数传递2.2.1 GET发送单个参数2.2.2 GET发送多个参数2.2.3 GET请求中文乱码2.2.4 POST发送参数2.2.5 POST请求中文乱码 欢迎大家回到《Java教程之Spring30天快速入门》ÿ…...
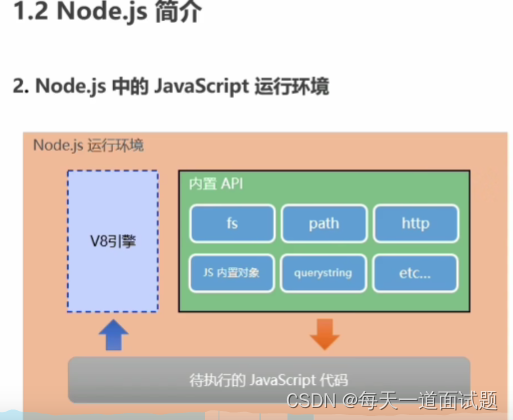
node.js和浏览器之间的区别
node.js是什么 Node.js是一种基于Chrome V8引擎的JavaScript运行环境,可以在服务器端运行JavaScript代码 Node.js 在浏览器之外运行 V8 JavaScript 引擎。 这使得 Node.js 非常高效。 浏览器如何运行js代码 nodejs运行环境 在浏览器中,大部分时间你所…...

【python并发任务的几种方式】
文章目录 1 Process:2 Thread:3 ThreadPoolExecutor:4 各种方式的优缺点:5 线程与进程的结束方式5.1 线程结束的几种方式5.2 进程的结束方式 6 应用场景效率对比 在Python中,有几种方法可以处理并行执行任务。其中,Process、Thread和ThreadPo…...

使用ROS模板基于ECS和RDS创建WordPress环境
本文教程介绍如何使用ROS模板基于ECS和RDS(Relational Database Service)创建WordPress环境。 前提条件 如果您是首次使用ROS,必须先开通ROS服务。ROS服务免费,开通服务不会产生任何费用。 背景信息 WordPress是使用PHP语言开…...
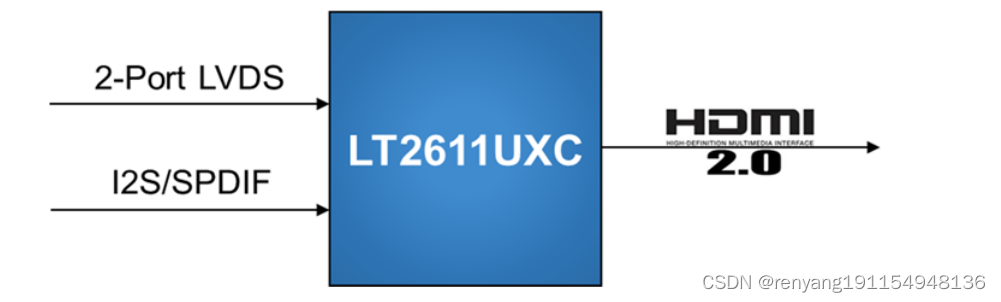
龙迅LT2611UXC 双PORT LVDS转HDMI(2.0)+音频
描述: LT2611UXC是一个高性能的LVDS到HDMI2.0的转换器,用于STB,DVD应用程序。 LVDS输入可配置为单端口或双端口,有1个高速时钟通道,3~4个高速数据通道,最大运行1.2Gbps/通道,可支持高达9.6Gbp…...
)
websocket和SSE通信示例(无需安装任何插件)
websocket和SSE通信示例(无需安装任何插件) 源码示例(两种方案任意切换) data(){return {heartBeatInterval:5000,// 心跳间隔时间,单位为毫秒webSocket:null,heartBeatTimer:null,} }, mounted() {// this.initWebS…...
计算机网络(三)
(十一)路由算法 A、路由算法分类 动态路由和静态路由 静态路由:人工配制,路由信息更新慢,优先级高。这种在实际网络中要投入成本大,准确但是可行性弱。 动态路由:路由更新快,自动…...

HttpURLConnection OOM问题记录
使用HttpURLConnection 上传大文件,会出现内存溢出问题: 观察HttpURLConnection 源码: Overridepublic synchronized OutputStream getOutputStream() throws IOException {connecting true;SocketPermission p URLtoSocketPermission(th…...

WT588F02B单片机语音芯片在磁疗仪中的应用介绍
随着健康意识的普及和科技的发展,磁疗仪作为一种常见的理疗设备,受到了广大用户的关注。为了提升用户体验和操作便捷性,唯创知音WT588F02B单片机语音芯片被成功应用于磁疗仪中。这一结合将为磁疗仪带来智能化的语音交互功能,为用户…...
深度学习——第5章 神经网络基础知识
第5章 神经网络基础知识 目录 5.1 由逻辑回归出发 5.2 损失函数 5.3 梯度下降 5.4 计算图 5.5总结 在第1课《深度学习概述》中,我们介绍了神经网络的基本结构,了解了神经网络的基本单元组成是神经元。如何构建神经网络,如何训练、优化神…...

微信网页授权步骤说明
总览 引导用户进入授权页面同意授权,获取code通过code换取网页授权access_token(与基础支持中的access_token不同)如果需要,开发者可以刷新网页授权access_token,避免过期(一般不需要)通过网页…...

linux bash shell变量操作符 —— 筑梦之路
1. 变量子串 ${var} 返回变量var的内容,单独使用时有没有{}一样,混合多个变量和常量时,用{}界定变量名 ${#var} 返回变量var内容的长度 ${var:offset} 从变量var中的偏移量offset开始截取到字符串结尾的子字符串,offset从0开始 ${…...

2.61【Python生成器与迭代器】
Python迭代器与生成器 迭代器 什么是迭代器 首先迭代是指python中访问元素的一种方式,迭代器是一个可以记住遍历位置的对象,因此不会像列表那样一次性全部生成,而是可以等到用的时候才生成,因此节省了大量的内存资源 可迭代对…...

devecho stuido npm 失败
使用华为推荐的设置npm 代理方式仍然无效。还是得使用npm 命令去设置代理。地址参考: npm设置和取消代理的方法_npm查看代理-CSDN博客 最后使用自己的代理加载成功,使用华为推荐的代理不成功,不清楚什么原因。 华为推荐的环境配置如下&…...

postgreSql逻辑复制常用语句汇总和说明
简单说明 postgreSql逻辑复制的原理这里不再赘述,度娘一下即可。这里只是对常用的语句做一些汇总和说明,以便日后查找时方便。 逻辑复制的概念 逻辑复制整体上采用的是一个发布订阅的模型,订阅者可以订阅一个或者多个发布者, 发…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...