pytorch文本分类(二):引入pytorch处理文本数据
pytorch文本数据处理
目录
- pytorch文本数据处理
- 1. Pytorch背景
- 2. 数据分割
- 3. 数据加载
- Dataset
- 代码分析
- 字典的用途
- 代码修改的目的
- Dataloader
- 4. 练习
原学习任务链接
相关数据链接:https://pan.baidu.com/s/1iwE3LdRv3uAkGGI2fF9BjA?pwd=ro0v
提取码:ro0v
–来自百度网盘超级会员V4的分享
1. Pytorch背景
Pytorch介绍
PyTorch是一个开源的Python机器学习库,应用于人工智能领域,如自然语言处理。它主要由Facebook的人工智能研究团队开发。
Pytroch 数据处理流程
Pytorch的数据处理流程主要是数据分割和数据加载这两部分,其中数据分割包含创建Dataset和DataLoader,循环DataLoader,将text, label加载到模型中进行训练。
2. 数据分割
随机将一个数据集分割成给定长度的不重叠的新数据集。可选择固定生成器以获得可复现的结果(效果同设置随机种子)。
torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)
参数介绍:
dataset (Dataset) :要分割的数据集。
lengths (Sequence) :要分割的长度。
generator (Generator) :用于随机排列的生成器。
import torch
from torch.utils.data import random_splitdataset = range(10) # range类型,可以通过for循环或者直接转换为list后打印出来。
train_dataset, test_dataset = random_split(dataset=dataset,lengths=[7, 3],generator=torch.Generator().manual_seed(0)) #分割测试和训练集
print(list(train_dataset))
print(list(test_dataset))
[4, 1, 7, 5, 3, 9, 0]
[8, 6, 2]C:\Users\chengyuanting\.conda\envs\pytorch_cpu\lib\site-packages\tqdm\auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.htmlfrom .autonotebook import tqdm as notebook_tqdm
’ generator=torch.Generator().manual_seed(0) '解析:
-
’ torch.Generator() ’ :这是一个PyTorch对象,提供了生成随机数的机制。PyTorch中使用生成器来管理各种随机数生成函数和操作的随机数生成状态,特别是那些涉及随机过程的随机数生成,如洗牌数据或初始化权重。使用生成器确保随机数的生成更容易控制和再现。
-
’ .manual_seed(0) ’ :在生成器对象上调用此方法以设置其种子。设置种子是编程中的一种常见做法,特别是在机器学习和数据科学中,以确保结果的可重复性。当您设置种子时,它将随机数生成器初始化为已知状态。在本例中,种子被设置为’ 0 '。因此,每次运行此代码时,生成器都会生成相同的随机数序列,这反过来意味着每次执行代码时,诸如变换或分割数据集之类的操作都会产生相同的结果。
在代码片段的上下文中,您将数据集拆分为训练集和测试集,“generator=torch.Generator().manual_seed(0)”用于确保拆分是可重复的。这意味着每次运行代码时,您都会得到相同的训练和测试子集,这在实验设置中通常是理想的,因为您希望在不同的运行中得到一致的结果。
3. 数据加载
Pytorch的数据加载主要依赖torch.utils.data.Dataset和torch.utils.data.DataLoader两个模块,可以完成傻瓜式加载。
Dataset
Pytorch中,任何基于索引读取数据(map-style: from keys to data samples)的类均需继承torch.utils.data.Dataset,该类为数据的读取定义了格式。我们可以通过torch.utils.data.Dataset源码得到该类的具体结构:
class Dataset(object): def __getitem__(self, index): raise NotImplementedError def __add__(self, other): return ConcatDataset([self, other])
数据示例:
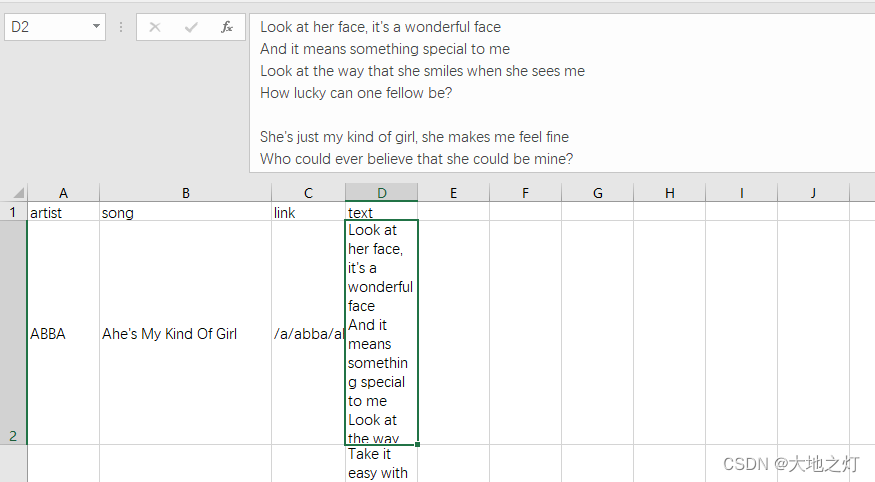
# 创建自定义的Dataset
import pandas as pd
import torch
from torch.utils.data import Dataset
class textDataset(Dataset):def __init__(self,csv_path): # Initialize file path or list of file names.super().__init__()self.install_data = pd.read_csv(csv_path, encoding='utf8', sep=',')def __len__(self):# You should change 0 to the total size of your dataset.return len(self.install_data)def __getitem__(self, idx):# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).# 2. Preprocess the data (e.g. torchvision.Transform).# 3. Return a data pair (e.g. image and label).#这里需要注意的是,第一步:read one data,是一个datainput_data = pd.DataFrame([])label = pd.DataFrame([])input_data = self.install_data.iloc[idx, 3]label = self.install_data.iloc[idx, 0]return label, input_data
#实例化
lyrics = textDataset('./data/songdata.csv')
label = []
label,text = lyrics[20:50]
print('label:',label[20],'\nlyrics: ',text[20]) #读取第20行的歌手label和歌词text
label: ABBA
lyrics: I'm down and I feel depressed
Sitting here just waiting
For next bus travelling
Downtown
It's a crying shame
Isn't it
The beautiful weather
If I could have my way
Well, I would not be working
On a day like this I know what I'd like to be
As free as a bumble bee
Take a sip from
Every flower
Free as a bumble bee
While away each lazy hour
What a good life
Lying laid back
Like an old railroad bum by the track
What a good life
Living outdoors
Lie in the grass and chew on a straw
针对以上通用代码,GPT提出的定制化建议:
您的代码通常结构良好,可以在PyTorch中定义自定义’ Dataset '类来处理CSV文件中的数据。但是,要使其正常工作,需要解决一些问题:
-
在’ getitem '中切片:PyTorch ’ Dataset ‘中的’ getitem ‘方法被设计用于处理单个项目访问,而不是切片(如’ lyrics[20:50] ‘)。如果你想访问一个范围的项,你应该遍历索引或修改’ getitem '方法来处理切片。
-
DataFrame初始化:在’ getitem ‘方法中,您将’ input_data ‘和’ label '初始化为空DataFrame,但随后您为它们分配一个来自Series的值。这是不必要的;您可以直接赋值。
-
返回张量:通常,PyTorch数据集以PyTorch张量的形式返回数据。如果你的’ input_data ‘和’ label '还不是张量,你可能需要在返回之前转换它们。
-
切片语法错误:在’ label, text = lyrics[20:50] ‘行中,您试图解压缩切片操作的结果,这将不会像当前’ getitem '定义所期望的那样工作。
这是你的代码调整后的版本(确实要比原版代码好哈哈哈):
class textDataset(Dataset):def __init__(self, csv_path): super().__init__()self.install_data = pd.read_csv(csv_path, encoding='utf8', sep=',')def __len__(self):return len(self.install_data)def __getitem__(self, idx):if torch.is_tensor(idx):idx = idx.tolist()input_data = self.install_data.iloc[idx, 3]label = self.install_data.iloc[idx, 0]# Convert to tensor if necessary, e.g.:# input_data = torch.tensor(input_data)# label = torch.tensor(label)return label, input_data# To access a range of items, you can do something like this:
lyrics = textDataset('./data/songdata.csv')
for i in range(20, 50):label, text = lyrics[i]print(f'label: {label}, lyrics: {text}')label: ABBA, lyrics: I'm down and I feel depressed
Sitting here just waiting
For next bus travelling
Downtown
It's a crying shame
Isn't it
The beautiful weather
If I could have my way
Well, I would not be working
On a day like this I know what I'd like to be
As free as a bumble bee
Take a sip from
Every flower
Free as a bumble bee
While away each lazy hour
What a good life
Lying laid back
Like an old railroad bum by the track
What a good life
Living outdoors
Lie in the grass and chew on a strawlabel: ABBA, lyrics: Twinkle, Twinkle little star
How I wonder what you are
Like a diamond glitt'ring in the sky
Seems to me you shine your light
Down to me to say goodnight
Twinkle, Twinkle my old friend
Sleep is waiting round the bend
While you travel through the milky way
From afar
Twinkle, Twinkle, Twinkle little star. ...Knowing me, knowing you (ah-haa)
There is nothing we can do
Knowing me, knowing you (ah-haa)
We just have to face it, this time we're through
(This time we're through, this time we're through
This time we're through, we're really through)
Breaking up is never easy, i know but i have to go
(I have to go this time
I have to go, this time i know)
Knowing me, knowing you
It's the best i can do
import time
import torchtext
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iteratortokenizer = get_tokenizer('basic_english')
train_iter = lyricsdef yield_tokens(data_iter):# for _,text in data_iter:# yield tokenizer(text)for i in range(len(data_iter)): # 通过索引去遍历整个数据集_, text = data_iter[i]yield tokenizer(text)start = time.time()
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
cost = time.time() - start
print(f"Build vocab cost: {cost:.4f}")vocab.set_default_index(vocab["<unk>"])
print('The vocabulary "wonderful" is ', vocab['wonderful'])
print('The vocabulary "beautiful" is ', vocab['beautiful'])Build vocab cost: 9.8542
The vocabulary "wonderful" is 991
The vocabulary "beautiful" is 430
当然,我将逐句分析您的代码,并解释建立字典的用途,以及对代码的修改如何确保正确遍历数据集。
代码分析
-
导入模块和设置分词器:
import time import torchtext from torchtext.data.utils import get_tokenizer from torchtext.vocab import build_vocab_from_iteratortokenizer = get_tokenizer('basic_english')这段代码导入了必要的模块,并创建了一个用于英语的基本分词器。分词器的作用是将文本分割成单词或词素。
-
定义数据迭代器:
train_iter = lyrics这里将自定义的数据集
lyrics赋值给train_iter,意味着后续的操作将对这个数据集进行迭代。 -
定义生成单词的函数:
def yield_tokens(data_iter):for i in range(len(data_iter)): # Iterating through the dataset_, text = data_iter[i]yield tokenizer(text)这个函数遍历数据集
data_iter,对每个样本的文本部分应用分词器,并逐个产生单词。我在这里修改了遍历方式,使用索引来确保可以逐个访问数据集中的每个样本。 -
建立词汇表:
start = time.time() vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"]) cost = time.time() - start print(f"Build vocab cost: {cost:.4f}")这段代码使用从数据集中提取的单词建立词汇表,并记录所花费的时间。
specials=["<unk>"]表示在词汇表中添加一个特殊的未知单词标记<unk>。 -
设置未知单词的默认索引:
vocab.set_default_index(vocab["<unk>"])这行代码设定了对于词汇表中不存在的单词,默认返回
<unk>的索引。 -
获取特定单词的索引:
print('The vocabulary "wonderful" is ', vocab['wonderful']) print('The vocabulary "beautiful" is ', vocab['beautiful'])这里打印了单词 “wonderful” 和 “beautiful” 在词汇表中的索引。
字典的用途
建立字典(词汇表)在自然语言处理(NLP)中非常重要,主要用途包括:
-
单词到索引的映射:字典提供了一种将单词转换为数字索引的方式,这对于计算机处理文本数据是必要的。
-
统计和限制词汇:通过字典,可以控制模型学习的词汇范围,并且可以统计和分析数据集中单词的出现频率。
-
数据预处理:在训练神经网络模型时,通常需要将文本转换为数值形式,字典是实现这一转换的关键组件。
代码修改的目的
原始代码中,yield_tokens 函数直接遍历 data_iter,这在某些情况下可能会导致问题,因为标准的 PyTorch Dataset 类不支持直接通过 for 循环进行遍历。通过使用索引访问每个元素,可以确保无论 Dataset 的具体实现如何,代码都能正确地访问每个数据点。这种方法更加通用,可以适用于更广泛的 Dataset 实现。
Dataloader
torch.utils.data.DataLoader是实际的数据采样器/迭代器,以单/多进程迭代的方式在封装的Dataset上获取数据。具体地,迭代器DataLoader使用next()方法以不断获得数据。❗️需注意,DataLoader只读取tensor,故常需在Dataset中将源数据转化为tensor。常用模块如transforms等。
由torch.utils.data.DataLoader源码可以得到该类的参数如下,接下来简单介绍一下主要参数的用法:
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None) batch_size(Int):即一次训练所抓取的数据样本数量,它的大小影响训练速度和模型优化,也同样影响每一epoch训练模型次数。设置batch_size可以使得CPU或GPU不会内存爆炸,提高了训练的速度,其次是使得梯度下降的方向更加准确。
shuffle(Boolean):shuffle是深度学习中将训练模型的数据集进行打乱的操作。原始的数据,在样本均衡的情况下可能是按照某种顺序进行排列,如前半部分为a类数据,后半部分为b类数据。但经过打乱之后数据的排列就会拥有一定的随机性,在顺序读取的时候下一次得到的样本为任何一类型的数据的可能性相同。shuffle的好处是,在针对随机性敏感的数据集上,可以提升模型质量和提升预测表现。
num_workers(Int):用于数据加载的子进程数量。 0 表示数据将在主进程中加载。
# 使用Dataloader去加载数据集
from torch.utils.data import DataLoader
dataloader = DataLoader(train_iter, batch_size=8, shuffle=False)
print('The length of dataloader is ',len(dataloader))
The length of dataloader is 7207
4. 练习
- BATCH_SIZE = 64,而数据集的大小为120,问一个epoch要训练几个批次?
answer_1 = '2' #答案填在引号内
- 使用数据分割样例代码,按照80%的训练集和20%的测试集的比例来切割’/home/mw/input/geci_82079530/songdata.csv’中的英文语料后,问训练集和测试集的数量分别是多少?
length = len(lyrics)
len_train = int(0.8*length)
len_test = int(0.2*length)
answer_2 = f'{len_train}' #训练集的样本数量,答案填在引号内
answer_3 = f'{len_test}' #测试集的样本数量,答案填在引号内
相关文章:
pytorch文本分类(二):引入pytorch处理文本数据
pytorch文本数据处理 目录 pytorch文本数据处理1. Pytorch背景2. 数据分割3. 数据加载Dataset代码分析字典的用途代码修改的目的 Dataloader 4. 练习 原学习任务链接 相关数据链接:https://pan.baidu.com/s/1iwE3LdRv3uAkGGI2fF9BjA?pwdro0v 提取码:ro…...

Centos硬盘操作合集
一、硬盘命令说明 lsblk 列出系统上的所有磁盘列表 查看磁盘列表 参数意义 blkid 列出硬盘UUID [rootzs ~]# blkid /dev/sda1: UUID"77dcd110-dad6-45b8-97d4-fa592dc56d07" TYPE"xfs" /dev/sda2: UUID"oDT0oD-LCIJ-Xh7r-lBfd-axLD-DRiN-Twa…...
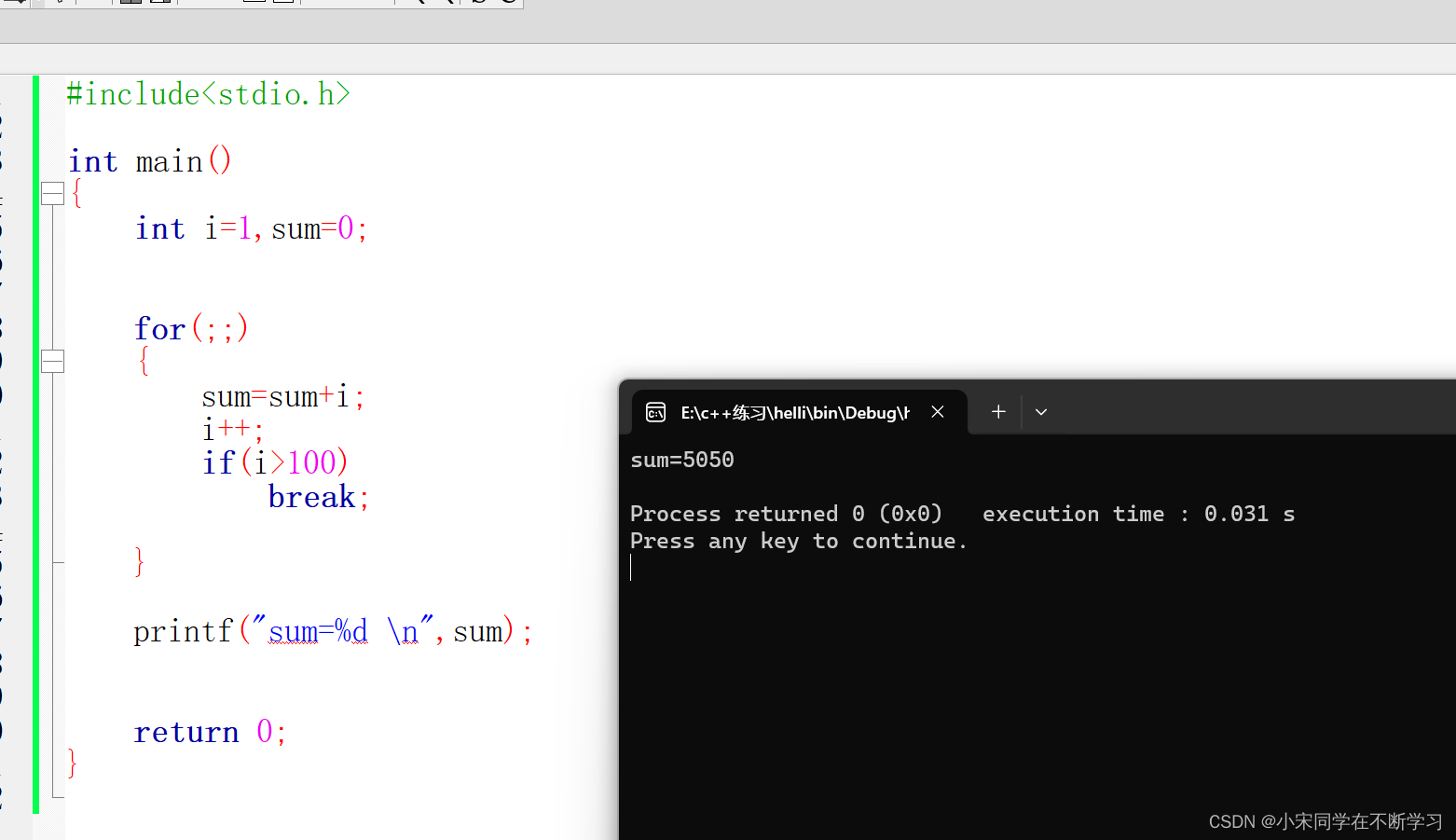
三大循环语句
goto 我们看代码去感受goto的循环,那么goto循环最经常搭配的就是loop,那么就像如下代码 这个代码中loop:就是个标志,然后程序正常向下运行,goto loop;就会让她回到loop,然后在运行到goto loop…...
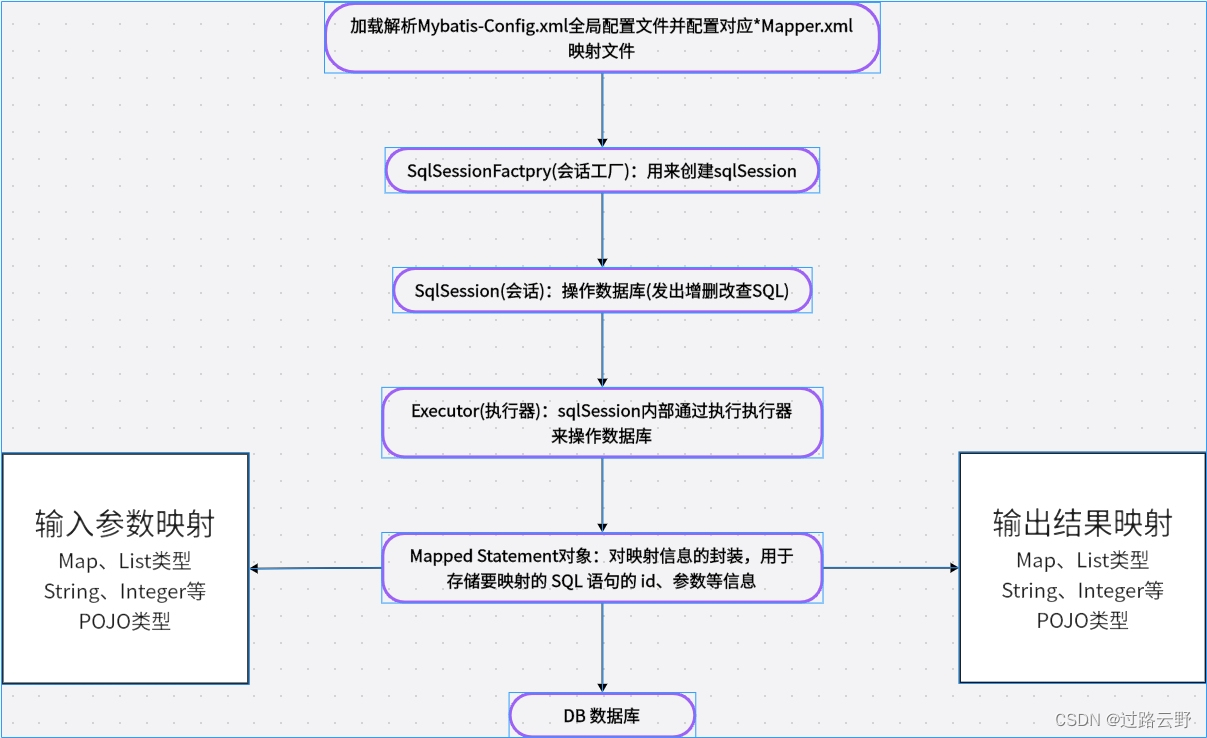
Mybatis详解
MyBatis是什么 MyBatis是一个持久层框架,用于简化数据库操作的开发。它通过将SQL语句和Java方法进行映射,实现了数据库操作的解耦和简化。以下是MyBatis的优点和缺点: 优点: 1. 灵活性:MyBatis允许开发人员编写原生的…...

spring cloud alibaba RocketMQ 最佳实践
目录 概述使用准备工作引入依赖创建Topic代码应用启动消息接收再扩展一个 结束 概述 github 文档地址 rocket mq example RocketMQ 版本为 5.1.4 使用 准备工作 阅读此文需要事先准备 RocketMQ ,如有疑问,请移步 RocketMQ 服务搭建 引入依赖 此处…...

php使用OpenCV实现从照片中截取身份证区域照片
<?php // 获取上传的文件 $file $_FILES[file]; // 获取文件的临时名称 $tmp_name $file[tmp_name]; // 获取文件的类型 $type $file[type]; // 获取文件的大小 $size $file[size]; // 获取文件的错误信息 $error $file[error]; // 检查文件是否上传成功 if ($er…...

抖音ip地址切换会看不到视频吗
随着社交媒体平台的快速发展,抖音已经成为了许多人分享生活点滴、展示才艺的热门平台。然而,有时候使用抖音时会遇到一些问题,比如IP地址切换后无法观看视频。那么,为什么会出现这种情况呢?让我们分析一下。 首先&…...
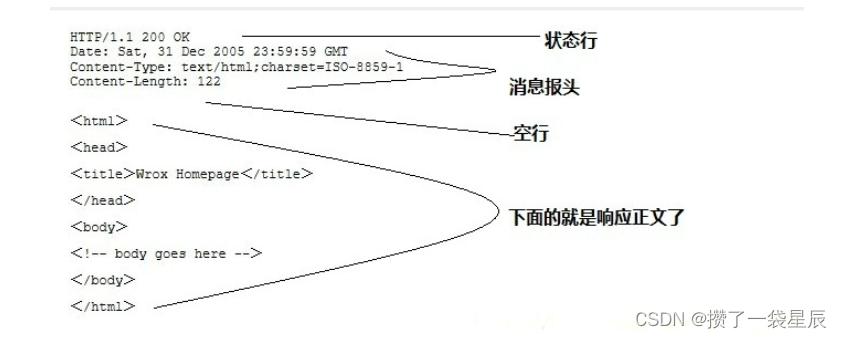
有关爬虫http/https的请求与响应
简介 HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。 HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTT…...

模块二——滑动窗口:438.找到字符串中所有字母异位词
文章目录 题目描述算法原理滑动窗口哈希表 代码实现 题目描述 题目链接:438.找到字符串中所有字母异位词 算法原理 滑动窗口哈希表 因为字符串p的异位词的⻓度⼀定与字符串p 的⻓度相同,所以我们可以在字符串s 中构造⼀个⻓度为与字符串p的⻓度相同…...

排序算法(二)-冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序
排序算法(二) 前面介绍了排序算法的时间复杂度和空间复杂数据结构与算法—排序算法(一)时间复杂度和空间复杂度介绍-CSDN博客,这次介绍各种排序算法——冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序。 文章目录 排…...
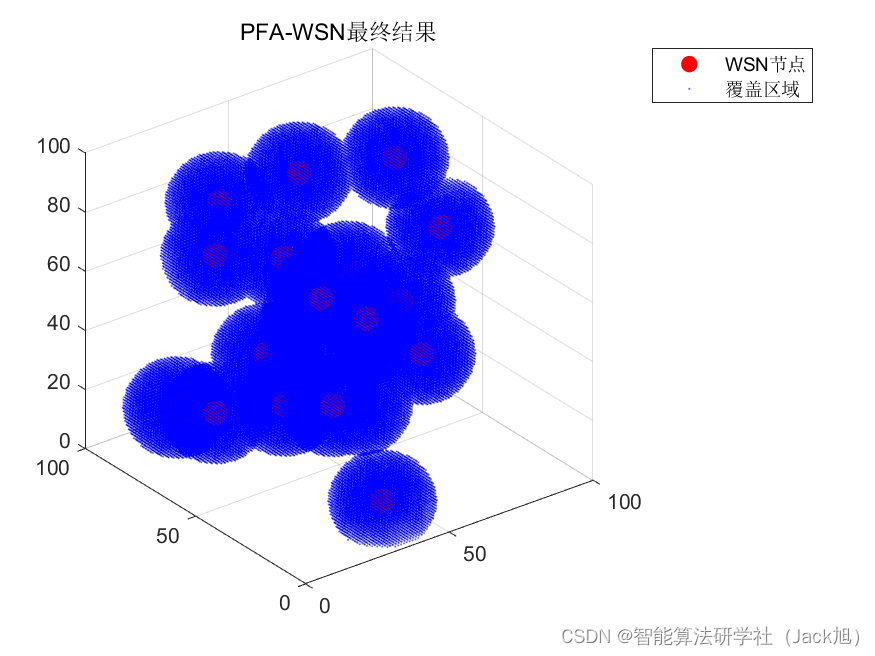
智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.探路者算法4.实验参数设定5.算法结果6.参考文…...

高效排队,紧急响应:RabbitMQ Priority Queue全面指南【RabbitMQ 九】
欢迎来到我的博客,代码的世界里,每一行都是一个故事 高效排队,紧急响应:RabbitMQ Priority Queue全面指南 引言前言第一:初识RabbitMQ Priority Queue插件插件的背景和目的:为什么需要消息优先级࿱…...

Java中使用EasyExcel写excel文件
1、公式 package com.web.report.handler;import com.alibaba.excel.context.WriteContext; import com.alibaba.excel.metadata.csv.CsvCellStyle; import com.alibaba.excel.metadata.data.WriteCellData; import com.alibaba.excel.write.handler.CellWriteHandler; import…...
【C语言程序设计】函数程序设计
目录 前言 一、程序阅读 二、程序设计 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 📣如需转载&#…...
GDPU 数据结构 天码行空14
实验十四 查找算法的实现 一、【实验目的】 1、掌握顺序排序,二叉排序树的基本概念 2、掌握顺序排序,二叉排序树的基本算法(查找算法、插入算法、删除算法) 3、理解并掌握二叉排序数查找的平均查找长度。 二、【实验内容】 …...
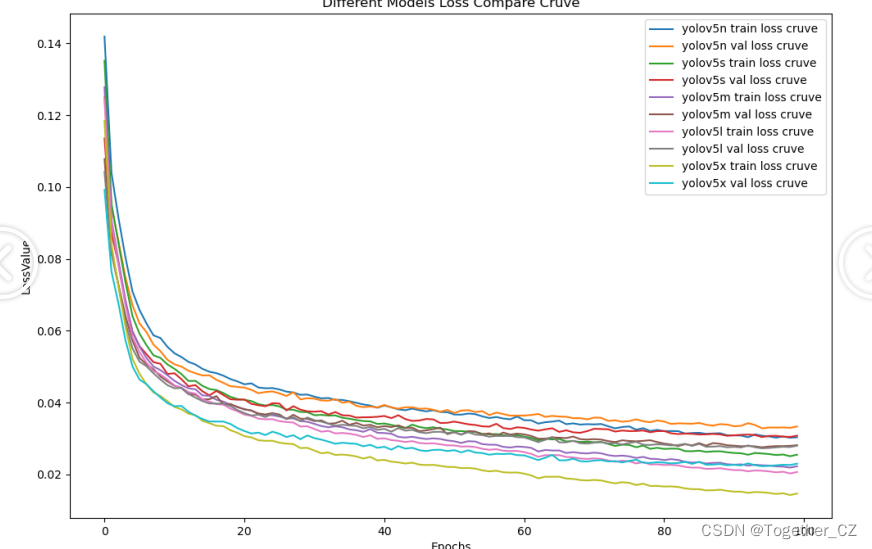
科技提升安全,基于YOLOv5系列模型【n/s/m/l/x】开发构建商超扶梯场景下行人安全行为姿态检测识别系统
在商超等人流量较为密集的场景下经常会报道出现一些行人在扶梯上摔倒、受伤等问题,随着AI技术的快速发展与不断普及,越来越多的商超、地铁等场景开始加装专用的安全检测预警系统,核心工作原理即使AI模型与摄像头图像视频流的实时计算…...
【网络安全】网络防护之旅 - 对称密码加密算法的实现
🌈个人主页:Sarapines Programmer🔥 系列专栏:《网络安全之道 | 数字征程》⏰墨香寄清辞:千里传信如电光,密码奥妙似仙方。 挑战黑暗剑拔弩张,网络战场誓守长。 目录 😈1. 初识网络安…...

鸿蒙arkTs Toast抽取 及使用
Toast抽取,创建一个Utils import promptAction from ohos.promptAction; import display from ohos.display; export function ToastUtils(msg:string){try {promptAction.showToast({message: msg,duration: 1500,bottom:450});} catch (error) {console.error(sh…...

网络安全渗透测试的相关理论和工具
网络安全 一、引言二、网络安全渗透测试的概念1、黑盒测试2、白盒测试3、灰盒测试 三、网络安全渗透测试的执行标准1、前期与客户的交流阶段1.1 渗透测试的目标网络1.2 进行渗透测试所使用的方法1.3 进行渗透测试所需要的条件1.4 渗透测试过程中的限制条件1.5 渗透测试的工期1.…...

C 语言 xml 库的使用
在C语言中,可以使用多种库来处理XML文件,其中最常用的是libxml2库。libxml2是一个用于解析XML和HTML文档的C语言库,它提供了许多功能,包括解析XML文档、创建XML文档、验证XML文档等等。下面是一个简单的示例,演示读取l…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
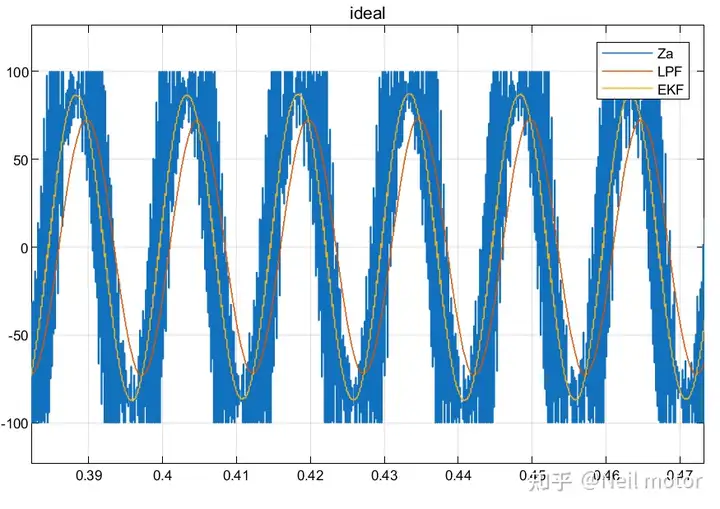
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...