MYSQl基础操作命令合集与详解
MySQL入门
先来个总结
SQL语言分类
- DDL(Data Definition Language) - 数据定义语言:
-
用于定义和管理数据库结构,包括创建、修改和删除数据库对象。
-
示例:
CREATE,ALTER,DROP等语句。
- DML(Data Manipulation Language) - 数据操纵语言:
-
用于操作数据库中的数据,包括插入、更新和删除数据。
-
示例:
INSERT,UPDATE,DELETE等语句。
- DQL(Data Query Language) - 数据查询语言:
-
用于从数据库中查询数据。
-
示例:
SELECT语句。
- TCL(Transaction Control Language) - 事务控制语言:
-
用于管理数据库中的事务,包括提交和回滚事务。
-
示例:
COMMIT,ROLLBACK等语句。
- DCL(Data Control Language) - 数据控制语言:
-
用于授权和权限管理。
-
示例:
GRANT,REVOKE等语句。
这些类别帮助组织 SQL 语言的不同方面和功能。DDL 主要关注数据库结构的定义,DML 关注数据的操作,DQL 关注数据的查询,TCL 关注事务管理,而 DCL 则关注数据库的安全性和权限控制。在实际使用中,通过结合这些语言元素,可以有效地管理和操作数据库。
DDL-操作数据库
查询:show databases;
创建数据库:create databases 数据库名称;
创建数据库(判断,如果不存在则创建):create database if not exists 数据库名称;
删除数据库:drop database 数据库名称;
删除数据库判断:drop database if exists 数据库名称;
使用数据库:use 数据库名称;
查看当前使用的数据库:select database();
DDL-操作表
查询当前数据库下所有表名称:show tables;
查询表结构:desc 表名称;
创建表:create table 表名 (字段名1 数据类型1,字段2 数据类型2...);
删除表:drop table 表名;
删除表时判断:drop table if exists 表名;
修改表名:alter table 表名 rename to 新表名;
添加一列:alter table 表名 add 列名 数据类型;
修改数据类型:alter table 表名 modify 列名 新数据类型;
修改列名和数据类型:alter table 表名 change 列名 新列名 新数据类型;
删除列:alter table 表名 drop 列名;
DML-添加数据
添加数据
给指定列添加数据:insert into 表名(列名1,列名2...) values (值1,值2,...);
给全部列添加数据:insetr into 表名 values (值1,值2,...);
批量添加数据:insert into 表名 (列名1,列名2,...) values(值1,值2,...),(值1,值2,...)...;
insert into 表名 values(值1,值2,...),(值1,值2,...),(值1,值2,...)...;
DML-修改数据
修改表数据:update 表名 set 列名1=值1,列名2=值2,... where 条件;
删除数据:delete from 表名 where 条件;
删除表内所有数据方法1:delete from 表名;
删除表内所有数据方法2:truncate table 表名;
DQL-基础查询
查询多个字段:select 字段列表 from 表名;select * from 表名;
去除重复记录:select distinct 字段列表 from 表名;
起别名:as as也可以省略
DQL-条件查询
语法:select 字段列表 from 表名 where 条件列表;
准确查询,模糊查询,区间匹配
条件:
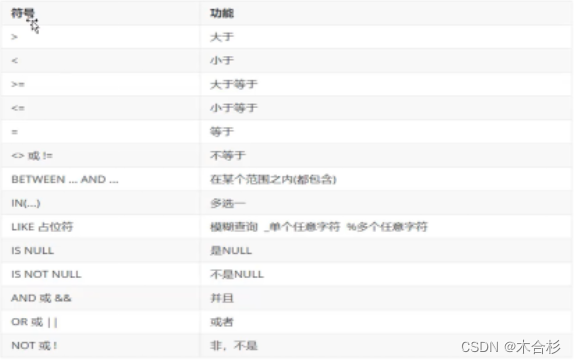
DQL-排序查询
普通排序查询:select 字段列表 from 表名 order by 排序字段名1 排序方法,排序字段名2 排序方法...;
排序方法:asc 升序排序(默认) desc 降序排序
tips:如果有多个排序条件,当前面的条件值一致时,才会根据第二条件进行排序
DQL-聚合函数查询
概念:将一列数据作为一个整体,进行纵向计算。
分类:

语法:select 聚合函数名(列名)from 表
null 值不参与所有聚合函数运算
DQL-对结果的二次处理
分组:select 字段列表 from 表名 where 分组前条件限定 group by 分组字段名 having 分组后条件过滤
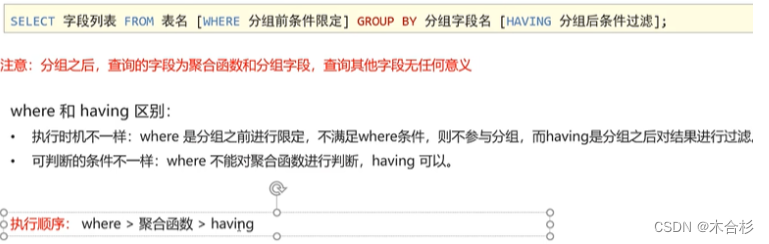
去重:select distinct 列名 from 表名;
截取:select 列名 from 表名 limit a, b;
多表查询
SELECTcolumn1, column2, ...
FROMtable1
JOINtable2 ON condition
[JOINtable3 ON condition]
WHEREcondition;
//其中:
column1, column2, ... 是你想要查询的列。
table1, table2, table3, ... 是要查询的表。
condition 是连接条件,它定义了如何将表关联起来。
具体的连接条件可以是各种形式,比如等值连接、不等值连接等,具体取决于你的需求。常见的JOIN类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN等。
克隆备份表
复制格式,复制表结构生成新的表create table 表名 like 被克隆的表名;
复制数据,将数据表的数据生成到新的表中 create table 表名 (select * from 被克隆的表名);
备份内容,将内容复制到结构一直的表中insert into 表名 select * from 被克隆的表名;
查看表的结构,索引等信息
show create table 表名\G;
这个命令中的 \G 是用来改变输出格式的,它会以更易读的方式显示结果,将结果每行一个字段,而不是标准的表格式输出。
接下来是详解
库命令:
1.查看已有的库:
show databases;
2.创建库:
create database 库名;
3.删除库:
drop database 库名;
表命令:
1.创建表:
create table 表名(列名 列类型 约束条件);
2.删除表:
drop table 表名
3.修改表:
1、修改表名:
alter table 旧名字 rename to 新名字;
2、添加一列:
alter table 表名 add column 新列名 新列类型 [约束条件];
3、如何修改一列:
修改一列的范围:列名、列类型、约束条件都能改。这似乎有点像替换。
alter table 表名 change 旧列名 新列名 新列类型 [约束条件];
4.删除一列:
alter table 表名 drop column 列名;
增 :
1、缺省插入:
insert into 表名(需要赋值的列) values (要插入的数据);
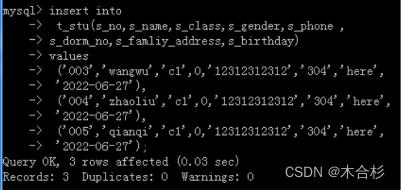
例:尝试在t_stu表中插入一行数据
insert into **关键字独占一行,且顶头**t_stu **语句参数独占一行,缩进一格**values(‘001’, ‘zhangsan’, ‘c1’, 0, ‘12312312312’,‘304’, ‘here’, ‘2022-06-27’);

-
关于这里的插入,不同的数据类型在values后的括号中出现的形式是不一样的
-
数字:是直接出现的,不需要任何的修饰
-
字符串:字符串需要使用单引号进行包裹表示字符串的范围
-
时间:针对时间的赋值可以使用规范格式的字符串,
-
可用的格式 2022-06-27 2022 / 06 / 07 20220627
缺省插入并不是真的要少插入数据,它存在的目的和后续主要用法是用来标记value中出现的数据的顺序
在实际开发中,一张表不可能只交给一个程序员进行维护,你可能回去访问其他人或者其他系统中的表,当表的字段较多的时候你的value中数据的次序就很难把握了
2.批量插入:
insert into 表名 values (第一行数据), (第二行数据), …… ;
这只是MySQL中可以用的方式
3.中文插入
-
先设置的方式是输入命令 set names gbk
-
再
insert into t_stu(s_no, s_name)values(‘006’, ‘张三’);
-
直接插入是会报错的,windows系统默认字符集是gbk,终端(黑色的框体)是操作系统提供的,所以在终端中出现的中文字符集默认按照系统字符集就是gbk
-
数据库在安装的时候就将字符集设置为utf8,这样就是在用utf8去解析gbk的文字,这样就会导致乱码,在MySQL中就直接是报错。
-
那么在这里就需要通过sql命令将终端中接受的字符编码改成gbk的,让MySQL数据库知道要按照GBK的格式读取将要插入的数据,虽然读的数据是GBK的,保存在数据库中的还是utf8的。
-
设置的方式是输入命令 set names 字符集的名字
-
在这里使用的就是 set names gbk; 是同时管理输入和输出两个方向的字符集设置。
-
它的作用范围只在本次终端连接中,重新连接或者关掉重开都会使这个命令失效。
删:
1.删除所有数据:
delete from 表名;
#DELETE清空表后,返回的结果内有删除的记录条目; DELETE 工作时是一行一行的删除记录数据的;如果表中有自增长字段,使用DELETE FROM 删除 所有记录后,再次新添加的记录会从原来最大的记录ID后面继续自增写入记录。
truncate table 表名;
#TRUNCATE清空表后,没有返回被删除的条目: TRUNCATE 工作时是将表结构按原样重新建立, 因此在速度上TRUNCATE会比DELETE清空表快;使用TRUNCATE TABLE 清空表内数据后, ID会从1开始重新记录
2.where约束删除
delete from 表名 where 约束条件;
改:
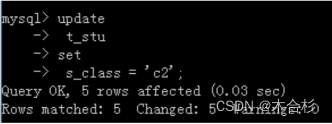
1.将整张表中这一列的值都替换为新值
update 表名 set 列名=新值;
updatet_stu
sets_class = ‘c2’;
2.只有符合where的判断的行才会受到影响
update 表名 set 列名=新值 where 约束条件;
updatet_stu
sets_class=’c1’
wheres_name = ‘lisi’;

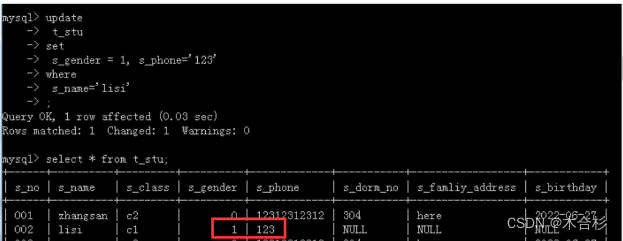
3.update语句每次可以修改不止一列的数据
例如:同时修改lisi的性别和手机号,将性别设为1 手机号设为123
updatet_stusets_gender = 1, s_phone=’123’
wheres_name=’lisi’
当出现多列要同时修改的时候,列与列之间用逗号隔开
查:
从一张指定的表中获取指定列的数据:select 需要被查的列 from 表名;
1.准确查询
准确查询使用 = 进行判断
where s_name=’李四’;
where s_no = ‘001’;
给出一个确定的值,必须和这个值完全一致才能通过
2.模糊查询
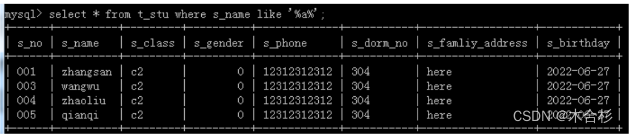
模糊查询使用关键字like替换了=like这里翻译成相似
需要搭配通配符:_表示一个任意字符 %表示0或多个任意字符
where s_name like ‘%a%’;//只要出现a即可,a的前后有没有内容,有什么内容都不重要select * from t_stu where s_name like ‘%a%’;
3.空值匹配
null在mysql是一个特殊的值,任何运算符只要有一侧是null结果就是null
针对null的判断mysql提供了专有关键字 is 和 is not
select * from t_stu where s_dorm_no is null;select * from t_stu where s_dorm_no is not null;

4.区间匹配
其实就是大于小于的范围
where age > 10; //大于,是不能包括10的
where age < 10; //小于,也是不包括10的
where age >= 10;
where age <= 10; //包括10的小于等于
同时实现大于小于,例如找出年龄在5~10岁之间的学生信息
where 5 <= age and age <= 10;
使用and这个逻辑运算符连接两个判断式的结果
mysql中的逻辑运算符
与 and
当and的两侧都是true的时候and返回true否则返回false
where 5 <= age and age <= 10;
年龄要大于5的同时也小于10
或 or
当or的两侧都是false的时候or返回false,否则返回true
where 5 <= age or age <= 10;
年龄大于5或者小于10都可以
非 not
原来是true变成false,原来是false变成true
枚举
列出所有需要的样本
例如找出年龄是5或10岁的学生信息
where age = 5 or age = 10;
where age in (5, 10);
()就是枚举范围,使用介词in连接到列上,括号中写枚举值,值和值之间用逗号隔开
请找出在2022年6月份出生的学生信息
select * from tstu where sbirthday between ‘2022-06-01’ and ‘2022-06-30’;
为什么日期可以比大小还可以形成区间?
这里要先理解计算机中是如何看待时间的,计算机并不是记录当前时间,而是记录现在这个时间点距离时间原点(1970年1月1日0时0分0秒)经过了多少毫秒数。
你可以认为6月1日小于6月2日,因为2日的时间点距离时间原点更远,毫秒数更大。
既然时间已经转化为了数字进行保存,数字之间比较大小形成区间也就好理解了。
对查询结果的二次处理
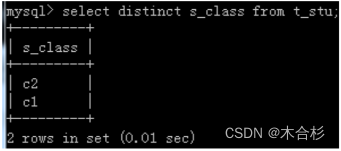
1.去重:select sclass from tstu;
关键字distinct进行去重:select distinct s_class from t_stu;

2.排序:order by
//希望根据生日对学生信息进行排序
select * from t_stu order by s_birthday;//默认顺序是正序(从小到大)
//可以在排序列的后面使用asc正序(从小到大)desc倒序(从大到小)
select * from t_stu order by s_birthday desc;
//tips:asc正序是默认值,可写可不写//请尝试根据学生的姓名进行排序,并尝试自行找出字符串排序的规律
//tips:当对字符串进行排序的时候,MySQL会进行逐位比较
//aa、ab 会先判断第一位上的a是否有顺序,如果是相同的,再判断下一位,根据ab的字母顺序进行排列
//aa会在aab之前,ab会在ba之前
3.截取:limit a, b;
limit a, b;
//从第a行开始截取,取b行数据limit 1, 3;
//从第1行开始截取,取3行数据,实际取值是(2,3,4)//a表示的行不会进入结果
//select * from t_stu limit 1, 3;

多表查询:
请按照给出的表名和列名,分配合适的数据类型创建这两表
t_user (u_id, u_name, u_grade, u_class);
t_score(s_id, u_id, s_subject, s_score);
create table t_user(
u_id int primary key,
u_name varchar(50),
u_grade int,
u_class int
);
insert into t_user values(1, '张三', 1, 1);
insert into t_user values(2, '李四', 1, 1);
insert into t_user values(3, '李世民', 2, 1);
insert into t_user values(4, '成吉思汗', 2, 2);
insert into t_user values(5, '李白', 2, 2);
insert into t_user values(6, '张飞', 3, 1);
insert into t_user values(7, '武则天', 3, 1);
create table t_score(
s_id int primary key,
u_id int,
s_subject varchar(50),
s_score int
);insert into t_score values(1, 1, '语文', 80);
insert into t_score values(2, 2, '数学', 90);
insert into t_score values(3, 3, '外语', 70);
insert into t_score values(4, 4, '外语', 95);
insert into t_score values(5, 5, '语文', 60);
insert into t_score values(6, 6, '数学', 30);
insert into t_score values(7, 7, '语文', 20);
insert into t_score values(8, 1, '数学', 50);请尝试查出每个人的语文分数(要求输出人名和成绩)名字在t_user表中,成绩在t_score表中,只查一张表是必然凑不齐要求的数据的,必须要同时查询多张表,并将表中的数据进行整合才能达到要求。
1、自然连接
-
在from关键字的后面,可以写不止一张表,需要多表查询的时候使用逗号隔开多张表
-
select * from t_user, t_score; -
在没有约束条件的情况下,直接连接的两张表查询结果是两张表内容的笛卡尔积
-
笛卡尔积:每张表中的每一行对应另一张的每一行。指从两个或多个表中获取所有可能的组合
-
当tuser有7行数据,tscore有8行数据的时候,查询结果就是7*8=56行结果,且这个结果是没有意义的,用户表和成绩表之间的关联应该放在u_id相等上,只有用户id相同才能表示这个成绩是这个用户考到的,直接逐行对应是没有逻辑的。
-
自然连接强调的是需要在where中使用判断式从笛卡尔积中筛选出符合要求的数据
selectu_name, s_score
fromt_user, t_score //将两张表同时写在from的后面
wheret_user.u_id = t_score.u_id; //再使用where从笛卡尔积中筛选数据


2、内连接
- 如何杜绝笛卡尔积的产生,直接查询表中的数据呢?需要使用连接,连接指的是将两张表在一定条件下整合成一张临时表,后续的查询操作不是直接查询数据表,而是这张整合后的临时表。
selectu_name, s_score
fromt_user inner join t_score on t_user.u_id = t_score.u_id;
A表 join B表 on 在某种条件下
在一般情况下,都认为内连接查询的效率是要高于自然连接的,因为它会先整合两张表中的数据从而杜绝笛卡尔积的产生,可以认为在刚才的例子中就没有出现那个56行的笛卡尔积的结果,而是直接出现了8行的最终结果(在连接产生的临时表中)
tips:inner这个关键字是可写可不写的。
3、外连接
- 外连接也是连接查询,外连接的重点是区分左右表,就分出了左外连接和右外连接。
selectu_name, s_score
fromt_user inner join t_score on t_user.u_id = t_score.u_id
wheres_subject = '语文';

在上面这个查询中会发现,由于部分学生没有语文成绩,所以在查询条件约束了考试科目的时候,这些学生由于uid = uid的判断式无法成立导致没有出现在最终的结果中。
外连接就可以将一侧的表设为主表,不管连接条件时怎样的,主表内容一定会完整显示。
t_user inner join t_score
//t_user表此刻在左侧,它就是左表
//t_score表在右侧,它就是右表
//如果使用左外连接,左表t_user就是主表,它的内容一定会完整的展示反之亦然。selectu_name, s_score
fromt_user left outer join t_score on t_user.u_id = t_score.u_id and s_subject = '语文';

这种查询后,左表中的内容完整的显示了(结果中有完整的7个user),如果有无法对应的右表中的内容用null进行占位(表示没有对应值)
再来个练习
请找出英语考试没有分数的学生的姓名
selectu_name
fromt_user left outer join t_score on t_user.u_id = t_score.u_id and s_subject = '外语'
wheres_score is null;
4、子查询
-
将多条语句写在一个语句中同步执行。
-
例如:请查出二年级二班的学生的成绩
-
分析一下:查询的条件年级和班级都是在tuser这张表中的,成绩是在tscore表中的。
-
能否将这题中的查询分成两个部分
-
1、根据班级和年级查出学生的编号
-
select uid from tuser where ugrade = 2 and uclass = 2;
-
2、根据这些编号查出对应的成绩
-
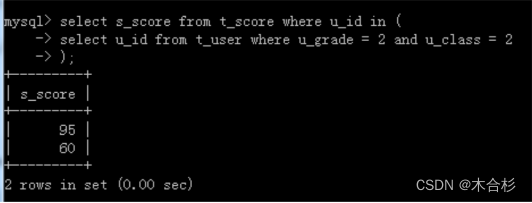
select sscore from tscore where u_id in (4, 5);
-
第二部的查询条件 4,5这两个值就是第一步的查询的结果,那能否直接将第一步查询的语句写在这个括号中代表4,5这两个值呢?
select s_score from t_score where u_id in (select u_id from t_user where u_grade = 2 and u_class = 2
);
子查询实际上就是将一次查询的结果当做下一次查询的组成部分,这个组成部分可以是多表查询中的一张表也可以是where约束条件中的判断依据
tips:子查询是上面所有多表查询中效率最低的一种,在编码中要尽量回避,但是不是不能用,当sql的逻辑过于复杂用一条语句实在难以实现的时候可以用子查询进行逻辑的简化(将一道复杂的逻辑分解为多个简单的逻辑,分别用sql实现然后组装起来形成一个子查询)
对于sql的优化,其中有一点就是将子查询进行了再次组成一个其他类型的多表查询。
例、统计每个部门年龄最大的员工的姓名
selecte_name
fromt_emp, (select e_dept_id, max(e_age) maxagefromt_empgroup bye_dept_id) twheret_emp. e_dept_id = t. e_dept_id andt_emp.e_age = t. maxage;
让我把这个查询解析一下:
- 主查询:
-
选择了表
t_emp中的e_name列。 -
没有直接指定表的来源,而是在查询中使用了表别名
t_emp。
- 子查询:
-
内部查询了表
t_emp,按照e_dept_id进行分组,并找出每个部门中年龄最大的员工。 -
使用了聚合函数
MAX(e_age)找到每个部门的最大年龄。 -
选取了
e_dept_id和每个部门的最大年龄,这两列作为结果集。
- 连接条件:
-
在主查询中,使用了表别名
t_emp和子查询t。 -
t_emp.e_dept_id = t.e_dept_id确保主查询中的部门ID与子查询中的部门ID相匹配。 -
t_emp.e_age = t.maxage确保主查询中的员工年龄与子查询中的最大年龄相匹配。
综合起来,这个查询的目的是从 t_emp 表中选取每个部门中年龄最大的员工,并返回这些员工的姓名(e_name)。
tips:1、子查询除了可以作为查询条件还可以作为临时表充当查询的数据来源
2、表和列都可以在查询中起别名,方式是用空格加上别名
mysql中的函数
函数在mysql中有两个大的类型
1、单行函数
一般是对查询结果进行后处理
例如:获取当前时间
select now();

2、聚合函数
单行函数是对一个值进行处理,聚合函数是将一组值进行统一的计算最后返回一个值。
max :取最大值
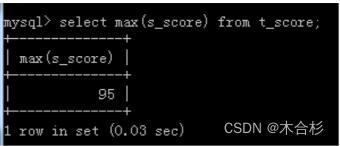
select max(sscore) from tscore;
本来t_score表中有多个成绩的值,使用max表示仅取最大值这一列的值经过计算之后只会留下最大的那一个。
min:取最小值
avg:取平均值
count 计数
sum 总和
来点练习
1、找出最大值
select max(s_score) from t_score;2、找出最大值对应的u_id
select u_id from t_score where s_score = 最大值;3、找出u_id对应的u_name
select u_name from t_user where u_id = 上一步查出来的
select u_name from t_user where u_id = (select u_id from t_score where s_score = (select max(s_score) from t_score)
);尝试整合一下多个子查询,将代码转为
1、查出最大值
select max(s_score) from t_score;2、根据成绩找人名字
自然连接版
selectu_name
fromt_user, t_score
wheret_user.u_id = t_score.u_id ands_score = (select max(s_score) from t_score);内连接版
selectu_name
fromt_user inner join t_score on t_user.u_id = t_score.u_id
wheres_score = (select max(s_score) from t_score);左外连接版
selectu_name
fromt_user left outer join t_score on t_user.u_id = t_score.u_id
wheres_score = (select max(s_score) from t_score);
1、统计平均分
select avg(s_score) from t_score;2、统计每个学科的平均分
select s_subject ,avg(s_score) from t_score group by s_subject;3、统计每个年级的平均分
selectu_grade, avg(s_score)
fromt_user, t_score
wheret_user.u_id = t_score.u_id
group byu_grade;tips:分组查询是特殊的一种查询,它查出的数据不是表中直接存在的数据,而是分组后再次经过分组函数统计的数据tips:当使用分组查询的时候select的后面只能出现被分组的列和聚合函数以下面的代码为例
selects_id, u_grade, avg(s_score)
fromt_user, t_score
wheret_user.u_id = t_score.u_id
group byu_grade;u_grade是分组的依据,就是被分组的列,每一行的查询结果都是根据它的值分出来的一个组,所以u_grade的值和查询结果中的行是一一对应的,聚合函数是在这一组的基础上进行计算得到分组组内的计算结果,所以这个结果也是和当前组一一对应的。s_id就不是,它和这一组没有任何关系,每个年级有多个考试结果,他们都有自己的s_id不存在一个一一对应的关系,这个值和计算出来的集合函数的返回值也没有数值上的关系。所以s_id在这里不管查出了什么数据都是“巧合”。巧合就是错误
分组查询
group by
:分组查询是特殊的一种查询,它查出的数据不是表中直接存在的数据,而是分组后再次经过分组函数统计的数据
:当使用分组查询的时候select的后面只能出现被分组的列和聚合函数
相关文章:
MYSQl基础操作命令合集与详解
MySQL入门 先来个总结 SQL语言分类 DDL(Data Definition Language) - 数据定义语言: 用于定义和管理数据库结构,包括创建、修改和删除数据库对象。 示例:CREATE, ALTER, DROP等语句。 DML(Data Manipulation Lan…...

【Flink名称解释一】什么是cataLog
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。 数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持久化的&#x…...

ES如何提高准确率之【term-centric】
提高准确率的方法有很多,但是要在提高准确率的同时保证召回率往往比较困难,本文只介绍一种比较常见的情况。 问题场景 我们经常搜索内容,往往不止针对某个字段进行搜索,比如:标题、内容,往往都是一起搜索…...

DDD落地:爱奇艺打赏服务,如何DDD架构?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 谈谈你的DDD落地经验? 谈谈你对DDD的理解&#x…...

基于JavaWeb+SSM+Vue居住证申报系统小程序的设计和实现
基于JavaWebSSMVue居住证申报系统小程序的设计和实现 源码获取入口KaiTi 报告Lun文目录前言主要技术系统设计功能截图订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码获取入口 KaiTi 报告 1.1题目背景 随着时代的发展,人口流动越来越频繁࿰…...

环境安全之配置管理及配置安全设置指导
一、前言 IT运维过程中,配置的变更和管理是一件非常重要且必要的事,除了一般宏观层面的配置管理,还有应用配置参数的配置优化,本文手机整理常用应用组件配置项配置,尤其安全层面,以提供安全加固指导实践。…...

【C#】Microsoft C# 视频学习总结
一、文档链接 C# 文档 - 入门、教程、参考。| Microsoft Learn 二、基础学习 1、输出语法 Console.WriteLine() using System; namespace HelloWorldApplication {class HelloWorld{static void Main(string[] args){Console.WriteLine("Hello World!");}} }Hel…...
【已解决-实操篇】SaTokenException: 非Web上下文无法获取Request问题解决-实操篇
在上一篇《【理论篇】SaTokenException: 非Web上下文无法获取Request问题解决 -理论篇》中,凯哥(公众号:凯哥Java)介绍了了产生这个问题的源码在哪里,以及怎么解决的方案。没有给出实际操作步骤。 本文,凯哥就通过threadLocal方案…...

论文润色机构哪个好 快码论文
大家好,今天来聊聊论文润色机构哪个好,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧,可以借助此类工具: 标题:论文润色机构哪个好――专业、高效、可靠的学术支持 一…...
Idea执行bat使用maven打包springboot项目成docker镜像并push到Harbor
如果执行以下命令失败,先把mvn的-q参数去掉,让错误输出到控制台。 《idea配置优化、Maven配置镜像、并行构建加速打包、解决maven打包时偶尔几个文件没权限的问题》下面的使用company-repo私有仓库和阿里云镜像仓库同时使用的配置参考。 bat echo off …...
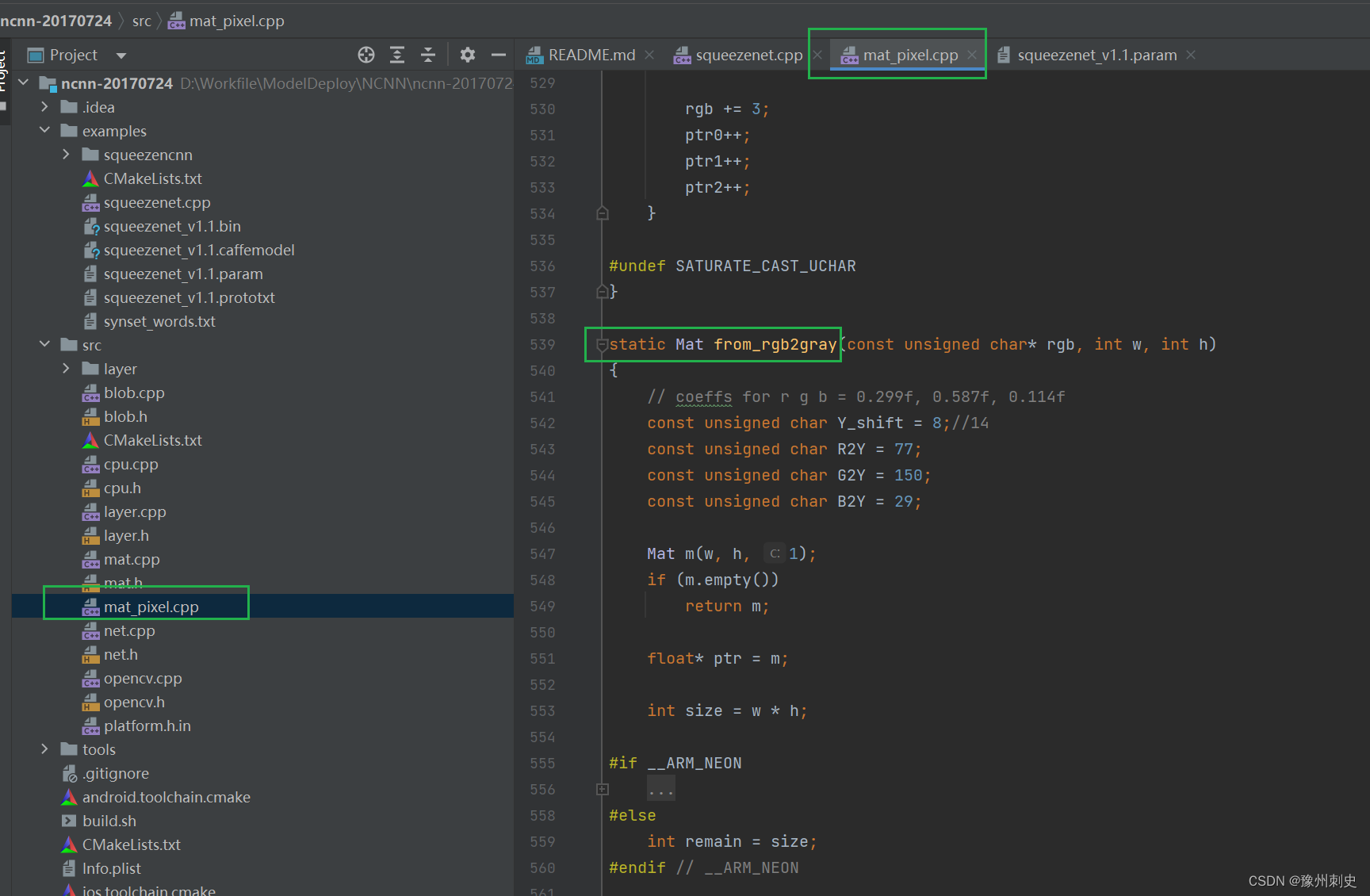
NCNN 源码学习【三】:数据处理
一、Topic:数据处理 这次我们来一段NCNN应用代码中,除了推理外最重要的一部分代码,数据处理: ncnn::Mat in ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR, bgr.cols, bgr.rows, 227, 227);const float mean_v…...
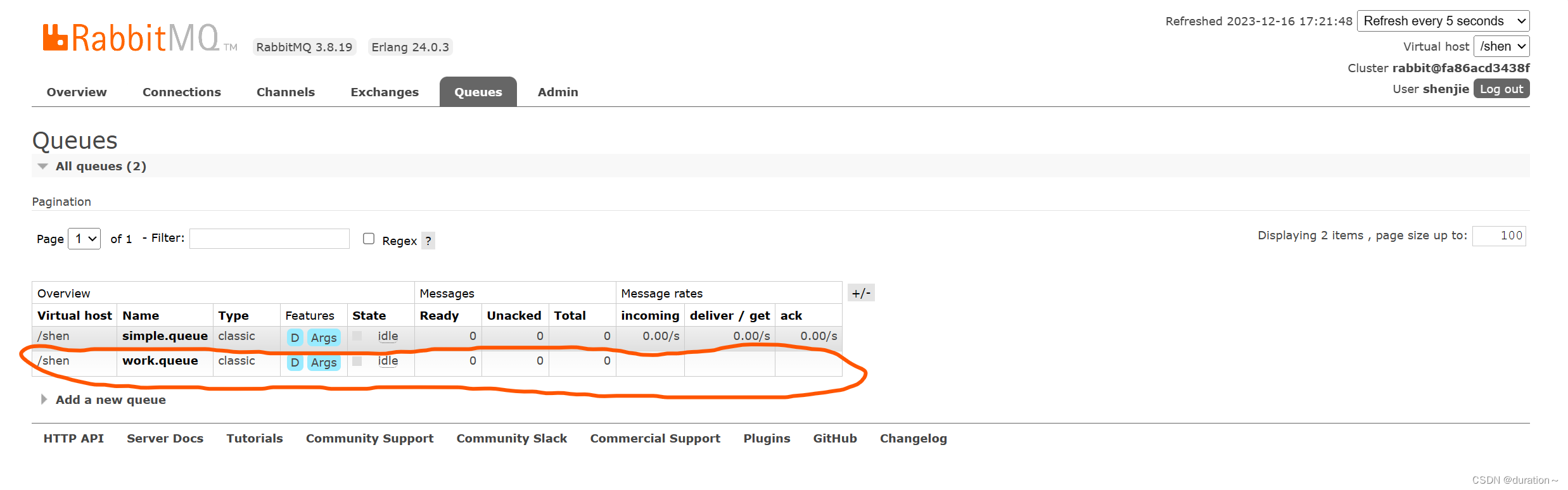
RabbitMq基本使用
目录 SpringAMQP1.准备Demo工程2.快速入门1.1.消息发送1.2.消息接收1.3.测试 3.WorkQueues模型3.1.消息发送3.2.消息接收3.3.测试3.4.能者多劳3.5.总结 SpringAMQP 将来我们开发业务功能的时候,肯定不会在控制台收发消息,而是应该基于编程的方式。由于R…...
windows wsl2 ubuntu上部署 redroid云手机
Redroid WSL2部署文档 下载wsl内核源码 #文档注明 5.15和5.10 版本内核可以部署成功,这里我当前最新的发布版本 #下载wsl 源码 wget --progressbar:force --output-documentlinux-msft-wsl-5.15.133.1.tar.gz https://codeload.github.com/microsoft/WSL2-Linux-Ker…...

创维电视机 | 用当贝播放器解决创维电视机不能播放MKV视频的问题
小故事在下面,感兴趣可以看看,开头我就直接放解决方案 创维电视虽然是基于Android开发的,可以安装apk软件,但是基本不能用,一定要选择适配电视的视频播放器,或者使用本文中提供的创维版当贝播放器。 原软…...
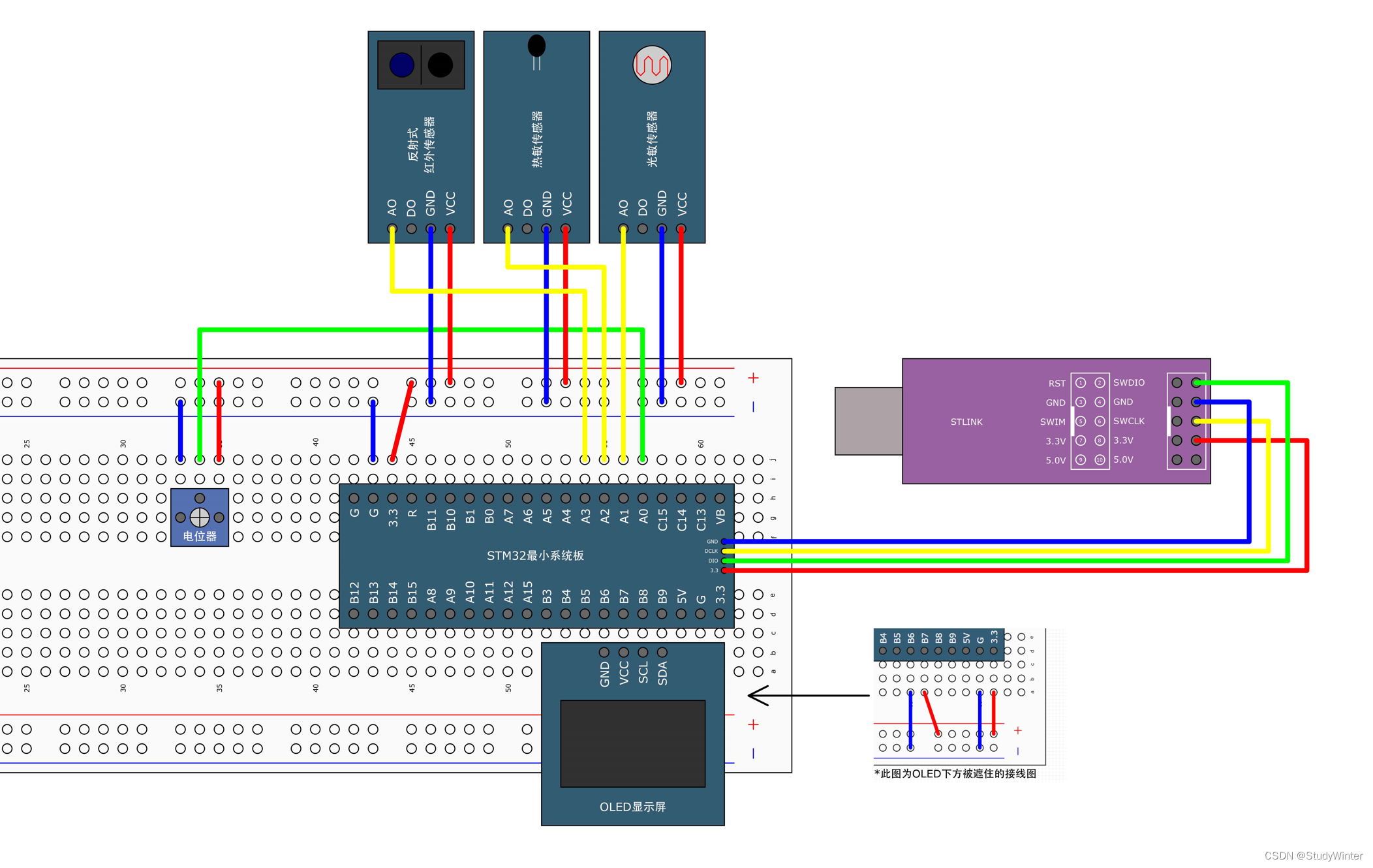
【STM32】DMA直接存储器存取
1 DMA简介 DMA(Direct Memory Access)直接存储器存取 可以直接访问STM32的存储器的,包括运行SRAM、程序存储器Flash和寄存器等等 DMA可以提供外设寄存器和存储器或者存储器和存储器之间的高速数据传输,无须CPU干预,节…...
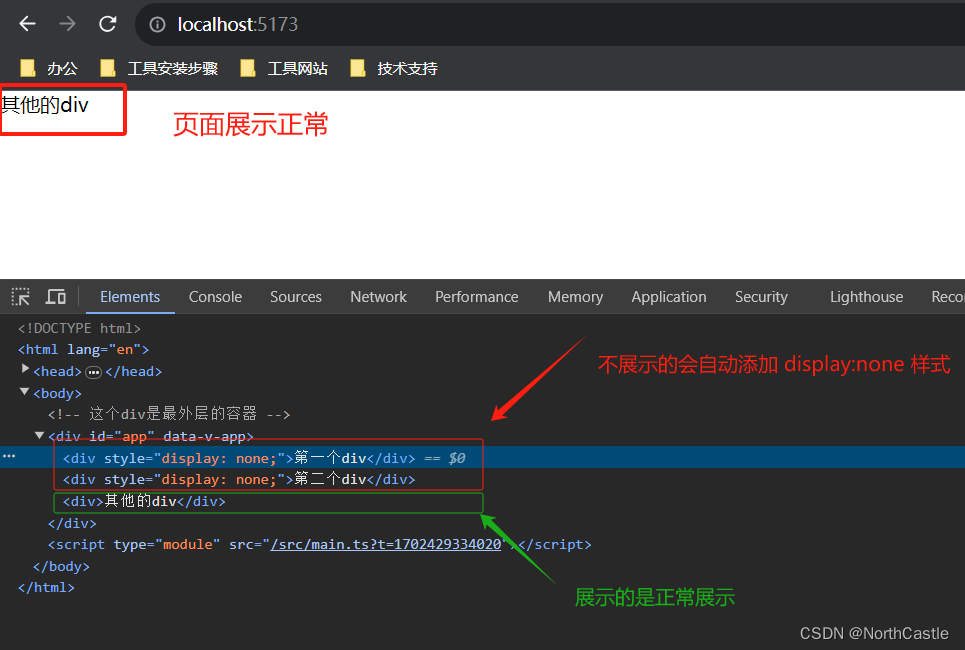
Vue3-09-条件渲染-v-show 的基本使用
v-show 的作用 v-show 可以根据条件表达式的值【展示】或【隐藏】html 元素。v-show 的特点 v-show 的实现方式是 控制 dom 元素的 css的 display的属性, 因此,无论该元素是否展示,该元素都会正常渲染在页面上, 当v-show 的 条件…...
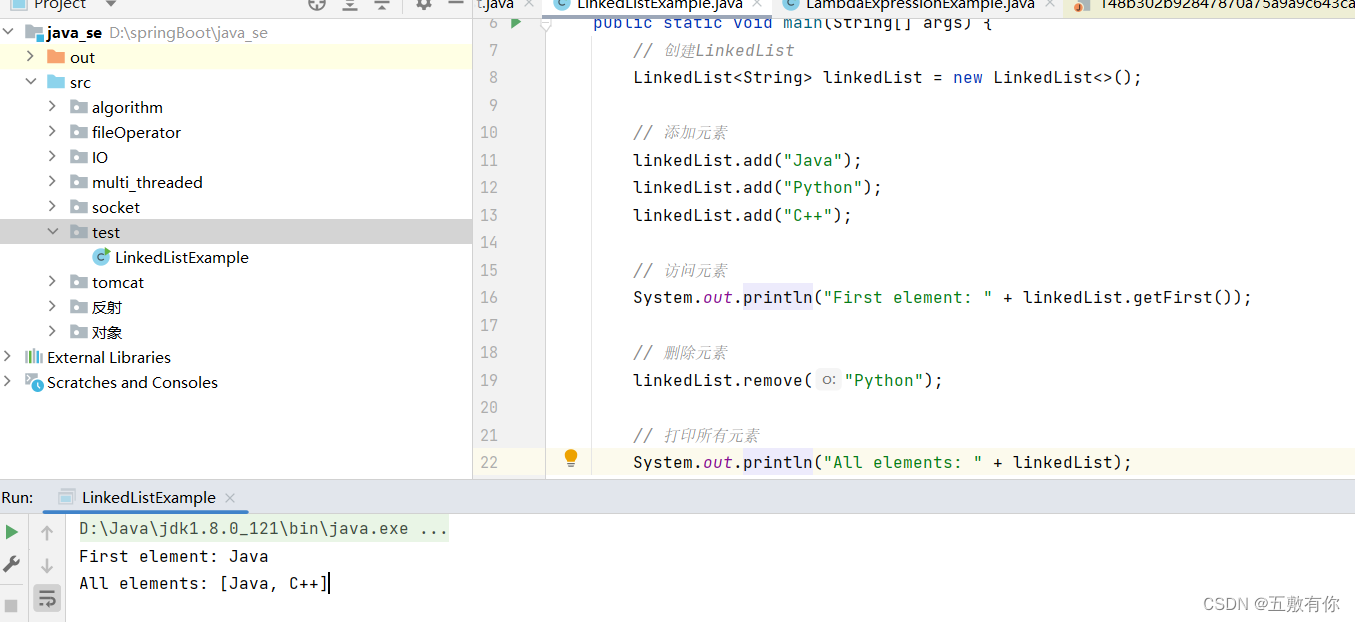
ArrayList与LinkLIst
ArrayList 在Java中,ArrayList是java.util包中的一个类,它实现了List接口,是一个动态数组,可以根据需要自动增长或缩小。下面是ArrayList的一些基本特性以及其底层原理的简要讲解: ArrayList基本特性: 动…...
)
位运算(、|、^、~、>>、<<)
分类 编程技术 1.位运算概述 从现代计算机中所有的数据二进制的形式存储在设备中。即 0、1 两种状态,计算机对二进制数据进行的运算(、-、*、/)都是叫位运算,即将符号位共同参与运算的运算。 口说无凭,举一个简单的例子来看下 CPU 是如何进…...
Centos7部署SVN
文章目录 (1)SVN概述(2)SVN与Samba共享(3)安装SVN(4)SVN搭建实例(5)pc连接svn服务器(6)svn图标所代表含义 (1)…...

Vue中this.$nextTick的执行时机
一、Vue中this.$nextTick的执行时机,整体可分为两种情况: 第一种:下一次 Dom 更新之后执行(即等待DOM更新结束之后,执行nextTick的延迟回调函数); 第二种:页面挂载后 (m…...
配置实践与电源管理详解)
【CP AUTOSAR】Pwm(PWMDriver)配置实践与电源管理详解
1. PWM驱动基础与AUTOSAR架构解析 第一次接触AUTOSAR的PWM驱动时,我被各种专业术语搞得晕头转向。后来在实际项目中摸爬滚打才发现,理解PWM在AUTOSAR架构中的定位非常重要。PWM驱动属于MCAL(微控制器抽象层)的组成部分,…...

实测有效:ERNIE-4.5-0.3B镜像部署,Chainlit界面聊天体验分享
实测有效:ERNIE-4.5-0.3B镜像部署,Chainlit界面聊天体验分享 1. 开箱即用的ERNIE-4.5体验 最近在测试各种开源大语言模型时,发现百度ERNIE-4.5系列中的0.3B版本特别适合快速部署和体验。这个轻量级模型虽然参数规模不大,但在文本…...

【硬件】络石SR系列协作机械臂:商用场景下的高性价比之选
1. 为什么商用场景需要协作机械臂? 最近两年,我走访了超过50家中小型制造企业,发现一个共同痛点:人工成本越来越高,但传统工业机器人又太"笨重"。要么需要专门的围栏隔离,要么编程复杂到必须请工…...
)
MySQL安装(LINUX RHEL9.3系统)
前置准备: 1. 卸载系统自带的 MariaDB(避免冲突) MySQL 和 MariaDB 会端口 / 文件冲突,先检查并卸载: 2. 关闭防火墙 (避免权限拦截) yum在线安装(推荐): …...

Winget包管理器故障排查与系统优化指南
Winget包管理器故障排查与系统优化指南 【免费下载链接】winget-install Install winget tool using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2022. 项目地址: https://gitcode.com/gh_mirrors/wi/winget-install 引言 …...

从“技术驱动”到“业务驱动”:衡石如何帮助企业构建业务导向的数据文化
在企业数字化转型的浪潮中,一个令人深思的现象反复出现:某公司投入数千万元建设了数据中台,采购了最先进的BI工具,组建了专业的数据团队,但一年后复盘发现,一线业务人员依然在用Excel做报表,会议…...

OpenClaw技能开发入门:为GLM-4.7-Flash扩展自定义文件转换器
OpenClaw技能开发入门:为GLM-4.7-Flash扩展自定义文件转换器 1. 为什么需要自定义技能 去年我在整理技术文档时,经常需要将PDF格式的论文和报告转换成Markdown格式。手动操作不仅耗时,还容易出错。当我发现OpenClaw可以通过技能扩展实现自动…...

OpenLRC:3步实现音频转精准字幕,让多语言内容创作效率提升300%
OpenLRC:3步实现音频转精准字幕,让多语言内容创作效率提升300% 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频…...

TCN-GRU这个组合模型算是把时间序列预测的两个经典结构玩出了花——时间卷积负责抓局部特征,GRU来捕捉时序依赖关系。咱直接上代码看看核心部分怎么搭的
TCN-GRU基于时间卷积网络-门控循环单元的多变量回归组合预测模型 Matlab语言 可直接运行 1.多输入单输出,模型属于个人提出,非常新颖,但不保证精度,组合方式如图2网络结构所示。 GRU也可以换成LSTM或BiLSTM,Matlab版本…...

简单三步:用Fish Speech 1.5实现语音评测功能
简单三步:用Fish Speech 1.5实现语音评测功能 1. 准备工作与环境部署 1.1 了解Fish Speech 1.5 Fish Speech 1.5是由Fish Audio开源的新一代文本转语音(TTS)模型,基于LLaMA架构与VQGAN声码器。它不仅能实现高质量的语音合成,还能通过其内置…...