【Spark精讲】Spark内存管理
目录
前言
Java内存管理
Java运行时数据区
Java堆
新生代与老年代
永久代
元空间
垃圾回收机制
JVM GC的类型和策略
Minor GC
Major GC
分代GC
Full GC
Minor GC 和 Full GC区别
Executor内存管理
内存类型
堆内内存
堆外内存
内存管理模式
静态内存管理
统一内存管理
编辑
执行内存管理
多任务间内存分配
Shuffle 的内存占用
MemoryOverHead详解
任务内存调节
错误类型及调整方案
1. Executor OOM类错误 (错误代码 137、143等)
方式一:增加单个task的内存使用量
方式二:降低单个Task的内存消耗量
2. Beyond xxx memory, killed by yarn
情况1:不存在子进程
情况2:存在子进程
可用内存计算
常见问题
SparkSQL导致的JVM栈内存溢出
YARN-CLUSTER 模式的 JVM 栈内存溢出无法执行问题
频繁 GC 问题
JVM GC 导致的 shuffle 文件拉取失败
前言
Spark的Driver和Executor作为一个JVM进程,其内存管理是建立在JVM的内存管理之上的。
Java内存管理
Java运行时数据区
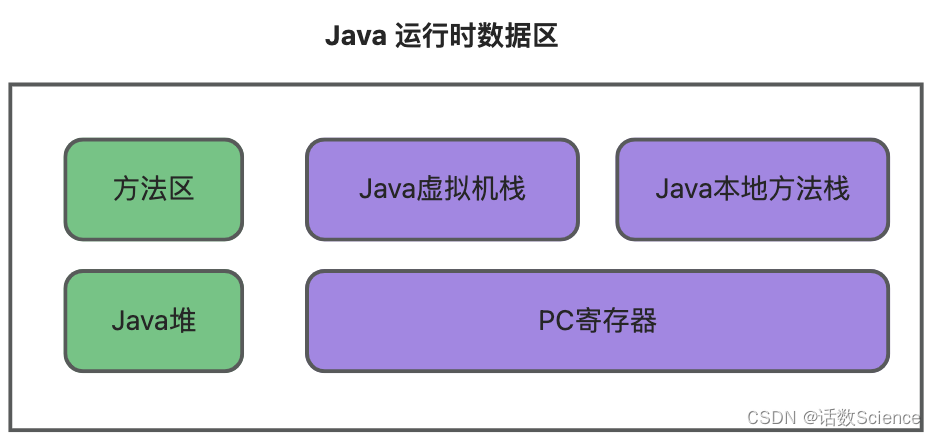
- 方法区:它用于存储每个类的结构信息,如运行时常量池、字段和方法数据、构造函数等内容。可共各个线程共享的内存区域;
- Java堆:所有类的实例和数组对象分配的内存区域,这个区域是所有线程共享的内存区域;
- PC寄存器:用于CPU运行多线程时,记录每个线程Java虚拟机正在执行的字节码指令的地址;
- Java虚拟机栈:每个线程都有自己私有的Java虚拟机栈。随线程创建而创建,随线程消失而销售。每个线程中,方法的调用都是通过Java虚拟机栈传递的。每个方法的调用都会生成对应的栈帧(Frame)压栈,方法执行结束时,对应的栈帧出栈,从而形成一些列的方法调用过程;
- 栈帧:是一种用来存储数据和部分过程结果的数据结构,同时栈帧也用来处理动态链接、方法返回值和异常的派发;
- 本地方法栈:用传统的栈来支持native方法的执行。创建线程时按线程分配。
Java堆
新生代与老年代
Java堆内存包含两部分:
- 新生代:包括Eden区,From Survivor区(S0),To Survivor区(S1),Eden:S0:S1 = 8:1:1
- 老年代:新生代 : 老年代 = 1 : 2,即年轻代占整个堆内存的1/3,老年代占2/3
通常对象在Eden区分配,经过一次新生代垃圾回收后,存活的对象被整理到S0或者S1,同时对象的年龄会加1,对象的年龄达到一定条件后,会进入老年代。

永久代
永久代是hotspot虚拟机,也就是我们使用的java虚拟机的特有的概念,他不属于堆内存,是方法区的一种实现,各大厂商对方法区有各自的实现。永久代存放jvm运行时,需要的类,包含java库的类和方法,在触发full gc的情况下,永久代也会被进行垃圾回收。永久代的内存溢出也就是 pergen space。
元空间
元空间是metaspace,在jdk1.8的时候,jvm移除了永久代的概念,元空间也是对java虚拟机的方法区的一种实现。元空间与永久代最大的区别在于,元空间不在虚拟机中,使用本地内存。通过配置如下参数可以更改元空间的大小。
-XX:MetaspaceSize:初始空间的大小。达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
永久代的回收会随着full gc进行移动,消耗性能。每种类型的垃圾回收都需要特殊处理元数据。将元数据剥离出来,简化了垃圾收集,提高了效率。
垃圾回收机制
垃圾回收(Garbage Collection,GC)针对的是Java堆和方法区。
Java堆和方法区两部分区域的生命周期是和整个Java应用程序相关联的,需要进行垃圾回收。而Java运行时数据区的其他部分如Java虚拟机栈,Java本地方法栈和PC寄存器是与每个线程的生命周期关联的,随线程创建与消亡,不需要进行垃圾回收。
判断一个对象是否回收的方法:可达性分析。找到一些列根对象,一般的根对象可以是Java虚拟机栈引用对象、方法区中静态属性和常量引用对象、本地方法栈引用对象等。以这一系列根对象为起点,向下搜索其引用的对象,当一个对象从根对象不可达时,则认为这个对象可以被回收了。
Java的引用共分为4种:强引用、软引用、弱引用、虚引用,引用关系强度依次减弱。
- 强引用:垃圾回收器不会回收。
- 软引用:发生内存溢出前,会把这类对象列入回收范围之内进行二次回收。回收后内存还是不足,则抛出内存溢出的异常。SoftReference。
- 弱引用:垃圾回收时,无论内存是否充足都会回收。WeakReference。
- 虚引用:不对垃圾回收产生影响。只是为了垃圾回收时,能够收到一个系统的通知。
垃圾回收算法:
- 引用计数法:缺点是无法处理循环引用,每次新增引用或清除引用时都要加减操作影响性能;
- 标记清除算法:分标记阶段和清除阶段。缺点是垃圾回收后会产生大量的内存碎片,影响内存分配效率;
- 标记压缩算法:在标记清除算法基础上,垃圾清理之后,将剩余存活的对象进行一次整理,统一移动到连续的内存空间中,虽然解决了内存不连续的问题,但是在压缩阶段会有额外的移动工作;
- 复制算法:分S0和S1两块内存区域,每次使用其中一个区域,当使用区域用完时,执行垃圾回收,将存活的对象复制到另外一个区域,然后将已使用的这块区域清空。优点是分配速度快,运行高效,缺点是内存浪费太严重。
- 分区算法:将整个堆空间划分成多个连续的更小的空间,每个空间独立分配独立回收。可以有效控制GC停顿时长;
- 分代思想:对象分两种一种存在生命周期较短的,一种生命周期较长的,相应的把内存划分为新生代存储生命周期较短的,老年代存储生命周期较长的。老年代适合用标记清除算法、标记压缩算法,新生代适合复制算法。新生代划分为eden、from、to三个区,from和to也称为幸存区(survive),分别为S0、S1。
垃圾回收器:
- 串行收集器:单线程运行,会暂停应用中其他线程直至回收完毕,可用于新生代和老年代;
- 并行收集器:多线程并行运行,分为ParNew(新生代)、ParallelGC(新生代)、ParallelOldGC(老年代);
- CMS收集器:CMS(并发标记清除),以获得最短垃圾回收时间为目标,减少系统停顿,一般应用在一些Web服务中。
- G1垃圾收集器:面向服务端应用,充分利用多核CPU的优势,缩短垃圾回收时用户线程停顿时长,回收过程与CMS类似,但可与用户线程同时执行。可用于整堆内存回收。
JVM GC的类型和策略
大家经常混淆的Minor GC、Major GC、Full GC,年轻代GC、老年代GC,之间有什么区别和联系。

Minor GC
JVM堆内存被分为两部分:年轻代(Young Generation)和老年代(Old Generation)。

1.年轻代
年轻代是所有新对象产生的地方,当年轻代内存空间被用完时,就会触发垃圾回收,这个垃圾回收叫做Minor GC。
年轻代被分为3个部分——Enden区和两个Survivor区,年轻代空间的要点:
- 大多数新建的对象都位于Eden区。
- 当Eden区被对象填满时,就会执行Minor GC。并把所有存活下来的对象转移到其中一个survivor区。
- Minor GC同样会检查存活下来的对象,并把它们转移到另一个survivor区。这样在一段时间内,总会有一个空的survivor区。
- 经过多次GC周期后,仍然存活下来的对象会被转移到年老代内存空间。通常这是在年轻代有资格提升到年老代前通过设定年龄阈值来完成的。
2.年老代
年老代内存里包含了长期存活的对象和经过多次Minor GC后依然存活下来的对象,通常会在老年代内存被占满时进行垃圾回收。
Major GC
老年代的垃圾收集叫做Major GC,Major GC通常是跟full GC是等价的,收集整个GC堆。
Minor GC和Major GC其实就是年轻代GC和年老年GC的俗称。而在Hotspot VM具体实现的收集器:Serial GC, Parallel GC, CMS, G1 GC中,大致可以对应到某个Young GC和Old GC算法组合。
分代GC
针对HotSpot VM的实现,其实GC的准确分类可以分为:
- 分代GC
- Full GC
以及后续的G1的分区收集本质其实还是一个分代收集器,但是和之前的各类回收器不同,它同时兼顾年轻代和老年代。
分代GC并不收集整个GC堆的模式,而是只专注分代收集
- Young GC:只收集年轻代的GC
- Old GC:只收集年老代的GC(只有CMS的concurrent collection是这个模式)
- Mixed GC:收集整个young gen以及部分old gen的GC(只有G1有这个模式)
Full GC
Full GC定义是相对明确的,就是针对整个新生代、老生代、元空间(metaspace,java8以上版本取代perm gen)的全局范围的GC。
Minor GC 和 Full GC区别
新生代 GC(Minor GC):指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
老年代 GC(Major GC/Full GC):指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
Executor内存管理
内存类型
包含两种方式:堆内内存和堆外内存。一个 Executor 当中的所有 Task 是共享堆内内存的。一个 Worker 中的多个 Executor 中的多个 Task 是共享堆外内存的。

堆内内存
堆内内存大小,由 Spark 程序启动时的 --executor-memory 或 spark.executor.memory 参数配置。那 Spark 是如何管理堆内内存呢?Spark 对堆内内存的管理是一种逻辑上的“规划式”的管理,因为对象实例占用内存的申请和释放都由 JVM 完成的。
堆外内存
Spark1.6在堆内内存的基础上引入了堆外内存,进一步优化了Spark内存的使用率。其实如果你有过Java相关编程经历的话,相信对堆外内存的使用并不陌生。其底层调用基于C的JDK Unsafe类方法,通过指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等。
Spark在2.x之后,摒弃了之前版本的Tachyon,采用Java中常见的基于JDK Unsafe API来对堆外内存进行管理。此模式不在JVM中申请内存,直接操作系统内存,减少了JVM中内存空间切换的开销,降低了GC回收占用的消耗,实现对内存的精确管控。
堆外内存默认情况下是不开启的,需要在配置中将spark.memory.offHeap.enabled设为True,同时配置spark.memory.offHeap.size参数设置堆大小。对于堆外内存的划分,仅包含Execution(执行内存)和Storage(存储内存)两块区域,且被所有task线程任务共享。
spark.memory.offHeap.enabled=true # 开启堆外内存
spark.memory.offHeap.size =1073741824 # 分配堆外内存的大小,单位byte内存管理模式
在Spark1.6之前,Spark采用的是静态管理(Static Memory Manager)模式,Execution内存和Storage内存的分配占比全部是静态的,其值为系统预先设置的默认参数。
在Spark1.6后,为了考虑内存管理的动态灵活性,Spark的内存管理改为统一管理(Unified Memory Manager)模式,支持Storage和Execution内存动态占用。至于静态管理方式任然被保留,可通过spark.memory.useLegacyMode参数启用。
静态内存管理
在 Spark 最初采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置,其优点是实现机制简单,易理解;缺点是容易出现内存失衡的问题,即Storage、Execution一方内存过剩,一方内容不足,另外需要开发人员充分了解存储机制,调优不便。堆内内存的分配如图所示:

堆内内存空间整体被分为Storage(存储内存)、Execution(执行内存)、Other(其他内存)三部分,默认按照6:2:2的比率划分。其中Storage内存区域参数: spark.storage.memoryFraction(默认为0.6),Execution内存区域参数: spark.shuffle.memoryFraction(默认为0.2)。其中Other内存区域主要用来存储用户定义的数据结构、Spark内部元数据,占系统内存的20%。
堆外内存,由参数spark.memory.storageFraction(默认0.5)控制。

统一内存管理
为了解决(Static Memory Manager)静态内存管理的内存失衡等问题,Spark在1.6之后使用了一种新的内存管理模式—Unified Memory Manager(统一内存管理)。在新模式下,移除了旧模式下的Executor内存静态占比分配,启用了内存动态占比机制,并将Storage和Execution划分为统一共享内存区域。
堆内内存整体划分为Usable Memory(可用内存)和Reversed Memory(预留内存)两大部分。其中预留内存作为OOM等异常情况的内存使用区域,默认被分配300M的空间。可用内存可进一步分为(Unified Memory)统一内存和Other内存其他两部分,默认占比为6:4。
- Storage Memory 存储内存,用于存放广播数据及RDD缓存数据。
- Execution Memory 执行内存,用于缓存执行Shuffle过程中产生的中间数据。
- Other Memory 其他内存,用于存放用户自定义的数据结构或Spark内部元数据。
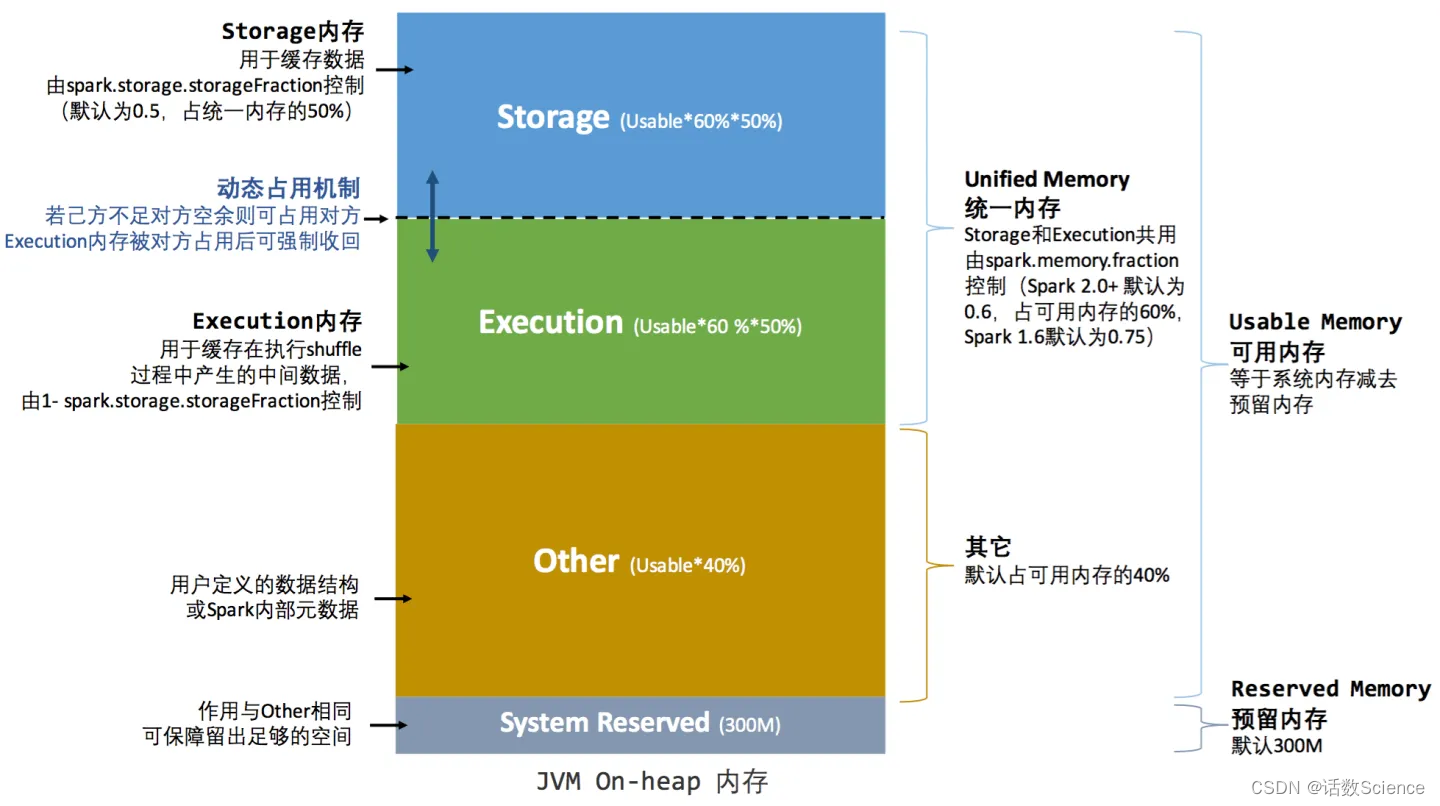
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同如下图所示(以统一内存管理机制为例),所有运行中的并发任务共享存储内存和执行内存。 动态占用机制示意图:
动态占用机制示意图: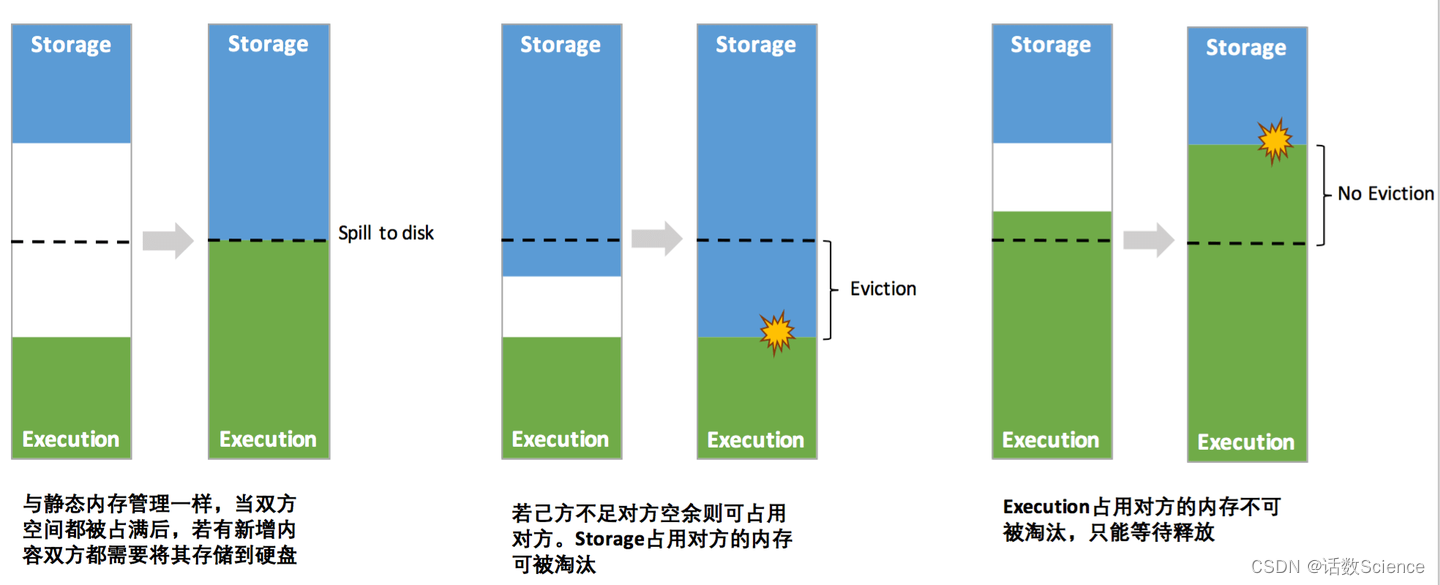
执行内存管理
多任务间内存分配
Executor 内运行的任务同样共享执行内存,Spark 用一个 HashMap 结构保存了任务到内存耗费的映射。每个任务可占用的执行内存大小的范围为 1/2N ~ 1/N,其中 N 为当前 Executor 内正在运行的任务的个数。每个任务在启动之时,要向 MemoryManager 请求申请最少为 1/2N 的执行内存,如果不能被满足要求则该任务被阻塞,直到有其他任务释放了足够的执行内存,该任务才可以被唤醒。
Shuffle 的内存占用
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程,我们来看 Shuffle 的 Write 和 Read 两阶段对执行内存的使用:
Shuffle Write
- 若在 map 端选择普通的排序方式,会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
- 若在 map 端选择 Tungsten 的排序方式,则采用 ShuffleExternalSorter 直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
Shuffle Read
在对 reduce 端的数据进行聚合时,要将数据交给 Aggregator 处理,在内存中存储数据时占用堆内执行空间。
如果需要进行最终结果排序,则要将再次将数据交给 ExternalSorter 处理,占用堆内执行空间。
在 ExternalSorter 和 Aggregator 中,Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从 MemoryManager(BlockManager里的MemoryStore里的memoryManager) 申请到新的执行内存时,Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Shuffle Write 阶段中用到的 Tungsten 是 Databricks 公司提出的对 Spark 优化内存和 CPU 使用的计划,解决了一些 JVM 在性能上的限制和弊端。Spark 会根据 Shuffle 的情况来自动选择是否采用 Tungsten 排序。Tungsten 采用的页式内存管理机制建立在 MemoryManager 之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个 MemoryBlock 来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。堆内的 MemoryBlock 是以 long 型数组的形式分配的内存,其 obj 的值为是这个数组的对象引用,offset 是 long 型数组的在 JVM 中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;堆外的 MemoryBlock 是直接申请到的内存块,其 obj 为 null,offset 是这个内存块在系统内存中的 64 位绝对地址。Spark 用 MemoryBlock 巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个 Task 申请到的内存页。
Tungsten 页式管理下的所有内存用 64 位的逻辑地址表示,由页号和页内偏移量组成:
- 页号:占 13 位,唯一标识一个内存页,Spark 在申请内存页之前要先申请空闲页号。
- 页内偏移量:占 51 位,是在使用内存页存储数据时,数据在页内的偏移地址。
有了统一的寻址方式,Spark 可以用 64 位逻辑地址的指针定位到堆内或堆外的内存,整个 Shuffle Write 排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和 CPU 使用效率带来了明显的提升。
Spark 的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark 用一个 LinkedHashMap 来集中管理所有的 Block,Block 由需要缓存的 RDD 的 Partition 转化而成;而对于执行内存,Spark 用 AppendOnlyMap 来存储 Shuffle 过程中的数据,在 Tungsten 排序中甚至抽象成为页式内存管理,开辟了全新的 JVM 内存管理机制。
MemoryOverHead详解
看过官方文档,我们知到spark.executor(driver).memoryOverhead 主要就是保证Yarn/K8s模式下 Executor 运行时的稳定性。
那么spark.memory.offHeap.size和spark.executor.memoryOverhead两个参数都是控制堆外内存大小,那到底有什么区别那?
在3.0之前的版本spark.memory.offHeap.size此参数包含于spark.executor.memoryOverhead内,也就是spark.memory.offHeap.size的参数值应小于spark.executor.memoryOverhead的参数。而到了3.0之后两块内存互相独立了,不再是包含关系。
总结如下(spark 2.X):
- spark.memory.offHeap.size 真正作用于spark executor的堆外内存
- spark.executor.memoryOverhead 作用于yarn,用来保证稳定性

由 yarn.scheduler.maximum-allocation-mb 指定 NodeManager 上container可申请的最大内存,提交任务时,如果 spark.executor.memoryOverhead 和 Executor Memory 所占的内存之和大于分配的内存之和,那就会造成 Executor 提交失败;运行过程中超过上限阈值,进程会被杀掉。
JVM OffHeap内存:大小由”spark.yarn.executor.memoryOverhead”参数指定,主要用于JVM自身,字符串, NIO Buffer等开销。
如上图所示,Yarn集群管理模式中,Spark 以Executor Container的形式在NodeManager中运行,其可使用的内存上限由“yarn.scheduler.maximum-allocation-mb” 指定, ---我们可以称其为MonitorMemory。
如前所述,Executor的内存由Heap内存和设定的Off-heap内存组成。
- Heap: 由“spark.executor.memory” 指定, 以下称为ExecutorMemory
- Off-heap: 由 “spark.yarn.executor.memoryOverhead” 指定, 以下称为MemoryOverhead
因此, 对现有Yarn集群,存在:
ExecutorMemory + MemoryOverhead <= MonitorMemory
若应用提交之时,指定的 ExecutorMemory与MemoryOverhead 之和大于 MonitorMemory,则会导致Executor申请失败;若运行过程中,实际使用内存超过上限阈值,Executor进程会被Yarn终止掉(kill)。
Executor 中,MemoryOverhead内存主要是创建Java Object时的额外开销,Native方法调用,线程栈, NIO Buffer等开销(Driect Buffer)。此部分为用户代码及Spark 不可操作的内存,不足时可通过调整参数解决, 无需过多关注。 具体需要调整的场景参见下面参数调节部分。
任务内存调节
Executor中可同时运行的任务数由Executor分配的CPU的核数N 和每个任务需要的CPU核心数C决定。其中:
- N = spark.executor.cores
- C = spark.task.cpus
Executor的最大任务并行度可表示为TP = N / C, 其中,C值与应用类型有关,大部分应用使用默认值1即可,因此,影响Executor中最大任务并行度的主要因素是N。
依据Task的内存使用特征,前文所述的Executor内存模型可以简单抽象为下图所示模型:

其中,Executor 向yarn申请的总内存可表示为: M = M1 + M2
错误类型及调整方案
1. Executor OOM类错误 (错误代码 137、143等)
该类错误一般是由于Heap(M2)已达上限,Task需要更多的内存,而又得不到足够的内存而导致。因此,解决方案要从增加每个Task的内存使用量,满足任务需求 或 降低单个Task的内存消耗量,从而使现有内存可以满足任务运行需求两个角度出发。因此:
方式一:增加单个task的内存使用量
- 增加最大Heap值, 即上图中M2 的值,使每个Task可使用内存增加。
- 降低Executor的可用Core的数量 N , 使Executor中同时运行的任务数减少,在总资源不变的情况下,使每个Task获得的内存相对增加。
方式二:降低单个Task的内存消耗量
降低单个Task的内存消耗量可从配制方式和调整应用逻辑两个层面进行优化:
- 配制方式:
减少每个Task处理的数据量,可降低Task的内存开销,在Spark中,每个partition对应一个处理任务Task。因此,在数据总量一定的前提下,可以通过增加partition数量的方式来减少每个Task处理的数据量,从而降低Task的内存开销。针对不同的Spark应用类型,存在不同的partition调整参数如下:
- P = spark.default.parallism (非SQL应用)
- P = spark.sql.shuffle.partition (SQL 应用)
- P = mapred.reduce.tasks (HiveOnSpark)
通过增加P的值,可在一定程度上使Task现有内存满足任务运行
注: 当调整一个参数不能解决问题时,上述方案应进行协同调整
---备注:若应用shuffle阶段 spill严重,则可以通过调整“spark.shuffle.spill.numElementsForceSpillThreshold”的值,来限制spill使用的内存大小,比如设置(2000000),该值太大不足以解决OOM问题,若太小,则spill会太频繁,影响集群性能,因此,要依据负载类型进行合理伸缩(此处,可设法引入动态伸缩机制,待后续处理)。
- 调整应用逻辑:
Executor OOM 一般发生Shuffle阶段,该阶段需求计算内存较大,且应用逻辑对内存需求有较大影响,下面举例就行说明:
- groupByKey 转换为 reduceByKey
一般情况下,groupByKey能实现的功能使用reduceByKey均可实现,而ReduceByKey存在Map端的合并,可以有效减少传输带宽占用及Reduce端内存消耗。

选择合适的算子
- data skew 预处理
Data Skew是指任务间处理的数据量存大较大的差异。
如左图所示,key 为010的数据较多,当发生shuffle时,010所在分区存在大量数据,不仅拖慢Job执行(Job的执行时间由最后完成的任务决定)。 而且导致010对应Task内存消耗过多,可能导致OOM. 而右图,经过预处理(加盐,此处仅为举例说明问题,解决方法不限于此)可以有效减少Data Skew导致 的问题
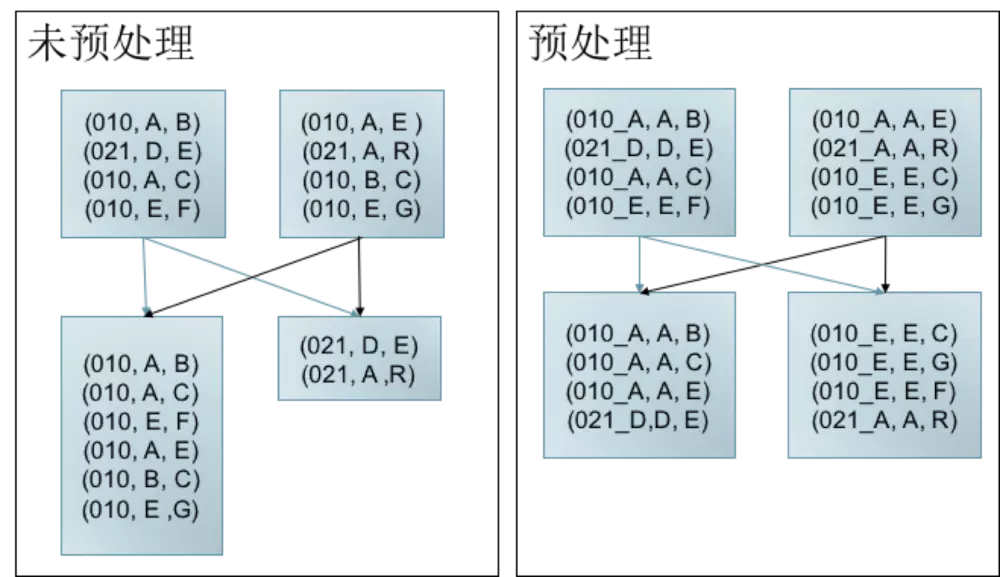
Data Skew预处理
---注:上述举例仅为说明调整应用逻辑可以在一定程序上解决OOM问题,解决方法不限于上述举例
2. Beyond xxx memory, killed by yarn
出现该问题原因是由于实际使用内存上限超过申请的内存上限而被Yarn终止掉了, 首先说明Yarn中Container内存监控机制:
- Container进程的内存使用量:以Container进程为根的进程树中所有进程的内存使用总量。
- Container被杀死的判断依据:进程树总内存(物理内存或虚拟内存)使用量超过向Yarn申请的内存上限值,则认为该Container使用内存超量,可以被“杀死”。
因此,对该异常的分析要从是否存在子进程两个角度出发。
情况1:不存在子进程
根据Container进程杀死的条件可知,在不存在子进程时,出现killed by yarn问题是于由Executor(JVM)进程自身内存超过向Yarn申请的内存总量M 所致。由于未出现第1节所述的OOM异常(如果是Executor OOM,则会先抛Executor OOM异常,而不会抛出killed by yarn异常),因此可判定其为 M1(Overhead)不足, 依据Yarn内存使用情况有如下两种方案:
- 如果,M未达到Yarn单个Container允许的上限时,可仅增加M1 ,从而增加M;如果,M达到Yarn单个Container允许的上限时,增加 M1, 降低 M2.
操作方法:在提交脚本中添加 --conf spark.yarn.executor.memoryOverhead=3072(或更大的值,比如4096等) --conf spark.executor.memory = 10g 或 更小的值,注意二者之各要小于Container监控内存量,否则伸请资源将被yarn拒绝。
- 减少可用的Core的数量 N, 使并行任务数减少,从而减少Overhead开销
操作方法:在提交脚本中添加 --executor-cores=3 <比原来小的值> 或 --conf spark.executor.cores=3 <比原来小的值>
情况2:存在子进程
Spark 应用中Container以Executor(JVM进程)的形式存在,因此根进程为Executor对应的进程, 而Spark 应用向Yarn申请的总资源M = M1 + M2 , 都是以Executor(JVM)进程(非进程树)可用资源的名义申请的。申请的资源并非一次性全量分配给JVM使用,而是先为JVM分配初始值,随后内存不足时再按比率不断进行扩容,直致达到Container监控的最大内存使用量M 。当Executor中启动了子进程(调用shell等)时,子进程占用的内存(记为 S) 就被加入Container进程树,此时就会影响Executor实际可使用内存资源(Executor进程实际可使用资源为:M - S),然而启动JVM时设置的可用最大资源为M, 且JVM进程并不会感知Container中留给自己的使用量已被子进程占用,因此,当JVM使用量达到 M - S,还会继续开辟内存空间,这就会导致Executor进程树使用的总内存量大于M 而被Yarn 杀死。
典形场景有:PySpark(Spark已做内存限制,一般不会占用过大内存)、自定义Shell调用。其解决方案:
PySpark场景:
- 如果,M未达到Yarn单个Container允许的上限时,可仅增加M1 ,从而增加M;如果,M达到Yarn单个Container允许的上限时,增加 M1, 降低 M2;
- 减少可用的Core的数量 N, 使并行任务数减少,从而减少Overhead开销
自定义Shell 场景:(OverHead不足为假象)
- 调整子进程可用内存量,(通过单机测试,内存控制在Container监控内存以内,且为Spark保留内存等留有空间)。方法同上。
可用内存计算
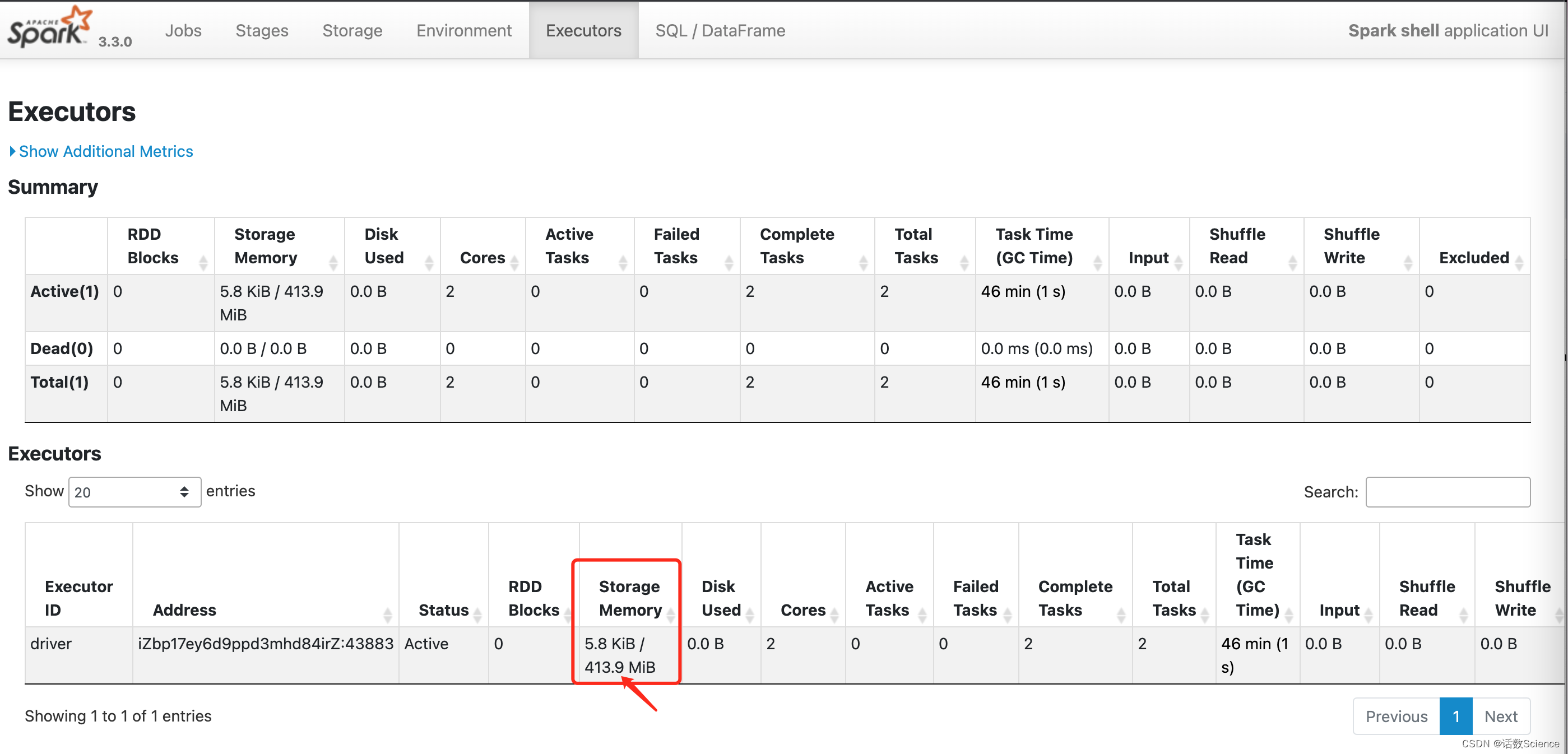
参考:Spark内存管理计算详述-CSDN博客
常见问题
SparkSQL导致的JVM栈内存溢出
当 SparkSQL 的 sql 语句有成百上千的 or 关键字时,就可能会出现Driver端的JVM栈内存溢出。
JVM 栈内存溢出基本上就是由于调用的方法层级过多,产生了大量的,非常深的,超 出了 JVM 栈深度限制的递归。(我们猜测 SparkSQL 有大量 or 语句的时候,在解析 SQL 时, 例如转换为语法树或者进行执行计划的生成的时候,对于 or 的处理是递归,or 非常多时,会发生大量的递归)。此时,建议将一条 sql 语句拆分为多条 sql 语句来执行,每条 sql 语句尽量保证 100 个以内的子句。根据实际的生产环境试验,一条 sql 语句的 or 关键字控制在 100 个以内,通 常不会导致 JVM 栈内存溢出。
YARN-CLUSTER 模式的 JVM 栈内存溢出无法执行问题
当 Spark 作业中包含 SparkSQL 的内容时,可能会碰到 YARN-client 模式下可以运行,但是 YARN-cluster 模式下无法提交运行(报出 OOM 错误)的情况。
YARN-client 模式下,Driver 是运行在本地机器上的,Spark 使用的 JVM 的 PermGen 的 配置,是本地机器上的 spark-class 文件,JVM 永久代的大小是 128MB,这个是没有问题的, 但是在 YARN-cluster 模式下,Driver 运行在 YARN 集群的某个节点上,使用的是没有经过配置的默认设置,PermGen 永久代大小为 82MB。
SparkSQL 的内部要进行很复杂的 SQL 的语义解析、语法树转换等等,非常复杂,如果 sql 语句本身就非常复杂,那么很有可能会导致性能的损耗和内存的占用,特别是对 PermGen 的占用会比较大。
所以,此时如果 PermGen 的占用好过了 82MB,但是又小于 128MB,就会出现 YARN- client 模式下可以运行,YARN-cluster 模式下无法运行的情况。
解决上述问题的方法时增加 PermGen 的容量,需要在 spark-submit 脚本中对相关参数 进行设置,设置方法如代码清单所示。
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"通过上述方法就设置了 Driver 永久代的大小,默认为 128MB,最大 256MB,这样就可以避免上面所说的问题。
频繁 GC 问题
1、打印 GC 详情
统计一下 GC 启动的频率和 GC 使用的总时间,在 spark-submit 提交的时候设置参数
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps"如果出现了多次Full GC,首先考虑的是可能配置的Executor内存较低,这个时候需要增加 Executor Memory 来调节。
2、如果一个任务结束前,Full GC 执行多次,说明老年代空间被占满了,那么有可能是没有分配足够的内存。
1.调整 executor 的内存,配置参数 executor-memory
2.调整老年代所占比例:配置-XX:NewRatio 的比例值
3.降低 spark.memory.storageFraction 减少用于缓存的空间3、如果有太多 Minor GC,但是 Full GC 不多,可以给 Eden 分配更多的内存。
1.比如 Eden 代的内存需求量为 E,可以设置 Young 代的内存为-Xmn=4/3*E,设置该值也会导致 Survivor 区域扩张
2.调整 Eden 在年轻代所占的比例,配置-XX:SurvivorRatio 的比例值4、调整垃圾回收器,通常使用 G1GC,即配置-XX:+UseG1GC。当 Executor 的堆空间比较大时,可以提升 G1 region size(-XX:G1HeapRegionSize),在提交参数指定:
--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC -XX:G1HeapRegionSize=16M -XX:+PrintGCDetails -XX:+PrintGCTimeStampsJVM GC 导致的 shuffle 文件拉取失败
在Spark作业中,有时会出现shuffle file not found的错误,这是非常常见的一个报错,有时出现这种错误以后,选择重新执行一遍,就不再报出这种错误。
出现上述问题可能的原因是 Shuffle 操作中,后面 stage 的 task 想要去上一个 stage 的 task 所在的 Executor 拉取数据,结果对方正在执行 GC,执行 GC 会导致 Executor 内所有的工作现场全部停止,比如 BlockManager、基于 netty 的网络通信等,这就会导致后面的 task拉取数据拉取了半天都没有拉取到,就会报出shuffle file not found的错误,而第二次再次执行就不会再出现这种错误。
可以通过调整 reduce 端拉取数据重试次数和 reduce 端拉取数据时间间隔这两个参数来对 Shuffle 性能进行调整,增大参数值,使得 reduce 端拉取数据的重试次数增加,并且每次失败后等待的时间间隔加长。
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "60")
.set("spark.shuffle.io.retryWait", "60s")相关文章:
【Spark精讲】Spark内存管理
目录 前言 Java内存管理 Java运行时数据区 Java堆 新生代与老年代 永久代 元空间 垃圾回收机制 JVM GC的类型和策略 Minor GC Major GC 分代GC Full GC Minor GC 和 Full GC区别 Executor内存管理 内存类型 堆内内存 堆外内存 内存管理模式 静态内存管理 …...

C语言实现Hoare版快速排序(递归版)
Hoare版 快速排序是由Hoare发明的,所以我们先来讲创始人的想法。我们直接切入主题,Hoare版快速排序的思想是将一个值设定为key,这个值不一定是第一个,如果你选其它的值作为你的key,那么你的思路也就要转换一下…...

git 避免输入用户名 密码 二进制/文本 文件冲突解决
核心概念介绍 工作区是你当前正在进行编辑和修改的文件夹,可见的。 暂存区位于.git/index(git add放入)。 代码库(工作树)位于.git(git commit将暂存区中的更改作为一个提交保存到代码库中,并清空暂存区) 避免输入用户 密码: 方式一: ht…...

[OpenWrt]RAX3000一根线实现上网和看IPTV
背景: 1.我家电信宽带IPTV 2.入户光猫,桥接模式 3.光猫划分vlan,将上网信号IPTV信号,通过lan口(问客服要光猫超级管理员密码,具体教程需要自行查阅,关键是要设置iptv在客户侧的vlan id&#…...
最新50万字312道Java经典面试题52道场景题总结(附答案PDF)
最近有很多粉丝问我,有什么方法能够快速提升自己,通过阿里、腾讯、字节跳动、京东等互联网大厂的面试,我觉得短时间提升自己最快的手段就是背面试题;花了3个月的时间将市面上所有的面试题整理总结成了一份50万字的300道Java高频面…...

html.parser --- 简单的 HTML 和 XHTML 解析器
源代码: Lib/html/parser.py 这个模块定义了一个 HTMLParser 类,为 HTML(超文本标记语言)和 XHTML 文本文件解析提供基础。 class html.parser.HTMLParser(*, convert_charrefsTrue) 创建一个能解析无效标记的解析器实例。 如果…...

赵传和源代码就是设计-UMLChina建模知识竞赛第4赛季第23轮
参考潘加宇在《软件方法》和UMLChina公众号文章中发表的内容作答。在本文下留言回答。 只要最先答对前3题,即可获得本轮优胜。第4题为附加题,对错不影响优胜者的判定,影响的是优胜者的得分。 所有题目的回答必须放在同一条消息中࿰…...
Leaflet.Graticule源码分析以及经纬度汉化展示
目录 前言 一、源码分析 1、类图设计 2、时序调用 3、调用说明 二、经纬度汉化 1、改造前 2、汉化 3、改造效果 总结 前言 在之前的博客基于Leaflet的Webgis经纬网格生成实践中,已经深入介绍了Leaflet.Graticule的实际使用方法和进行了简单的源码分析。认…...
html 中vue3 的setup里调用element plus的弹窗 提示
引入Elementplus之后,在setup()方法外面导入ElMessageBox const {ElMessageBox} ElementPlus 源码 : <!DOCTYPE html> <html> <head><meta charset"UTF-8"><!-- import Vue before Elemen…...
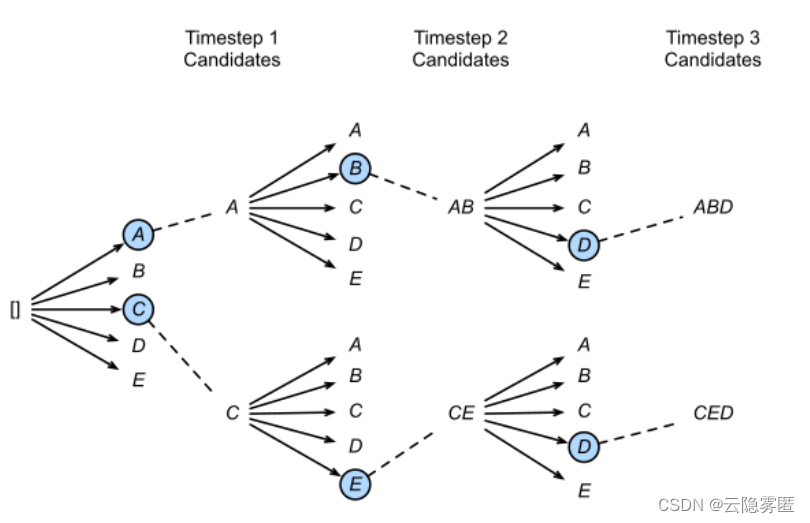
对话系统之解码策略(Top-k Top-p Temperature)
一、案例分析 在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,…...
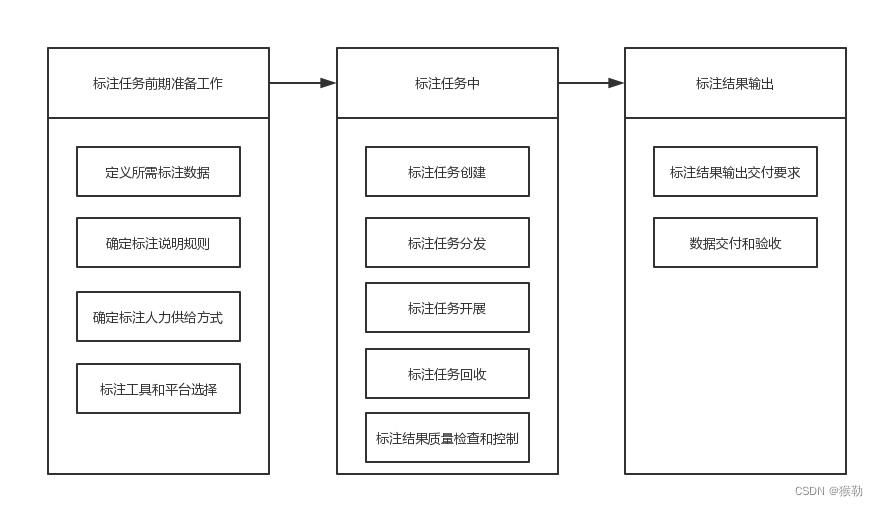
《面向机器学习的数据标注规程》摘录
说明:本文使用的标准是2019年的团体标准,最新的国家标准已在2023年发布。 3 术语和定义 3.2 标签 label 标识数据的特征、类别和属性等。 3.4 数据标注员 data labeler 对待标注数据进行整理、纠错、标记和批注等操作的工作人员。 【批注】按照定义…...

VGG(pytorch)
VGG:达到了传统串型结构深度的极限 学习VGG原理要了解CNN感受野的基础知识 model.py import torch.nn as nn import torch# official pretrain weights model_urls {vgg11: https://download.pytorch.org/models/vgg11-bbd30ac9.pth,vgg13: https://download.pytorch.org/mo…...

celery/schedules.py源码精读
BaseSchedule类 基础调度类,它定义了一些调度任务的基本属性和方法。以下是该类的主要部分的解释: __init__(self, nowfun: Callable | None None, app: Celery | None None):初始化方法,接受两个可选参数,nowfun表…...
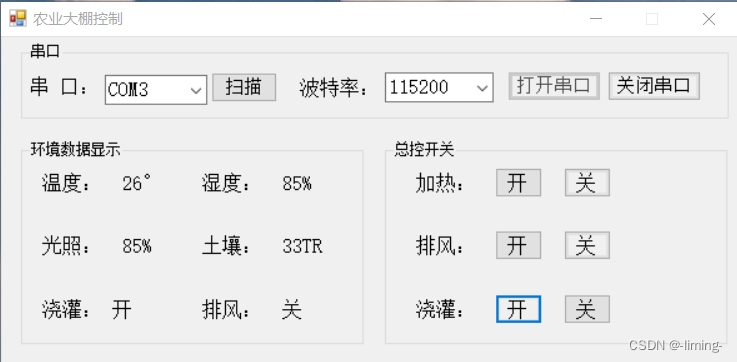
单片机上位机(串口通讯C#)
一、简介 用C#编写了几个单片机上位机模板。可定制!!! 二、效果图...

初识Flask
摆上中文版官方文档网站:https://flask.github.net.cn/quickstart.html 开启实验之路~~~~~~~~~~~~~ from flask import Flaskapp Flask(__name__) # 使用修饰器告诉flask触发函数的URL,绑定URL,后面的函数用于返回用户在浏览器上看到的内容…...

JeecgBoot jmreport/queryFieldBySql RCE漏洞复现
0x01 产品简介 Jeecg Boot(或者称为 Jeecg-Boot)是一款基于代码生成器的开源企业级快速开发平台,专注于开发后台管理系统、企业信息管理系统(MIS)等应用。它提供了一系列工具和模板,帮助开发者快速构建和部署现代化的 Web 应用程序。 0x02 漏洞概述 Jeecg Boot jmrepo…...
机器学习---模型评估
1、混淆矩阵 对以上混淆矩阵的解释: P:样本数据中的正例数。 N:样本数据中的负例数。 Y:通过模型预测出来的正例数。 N:通过模型预测出来的负例数。 True Positives:真阳性,表示实际是正样本预测成正样…...
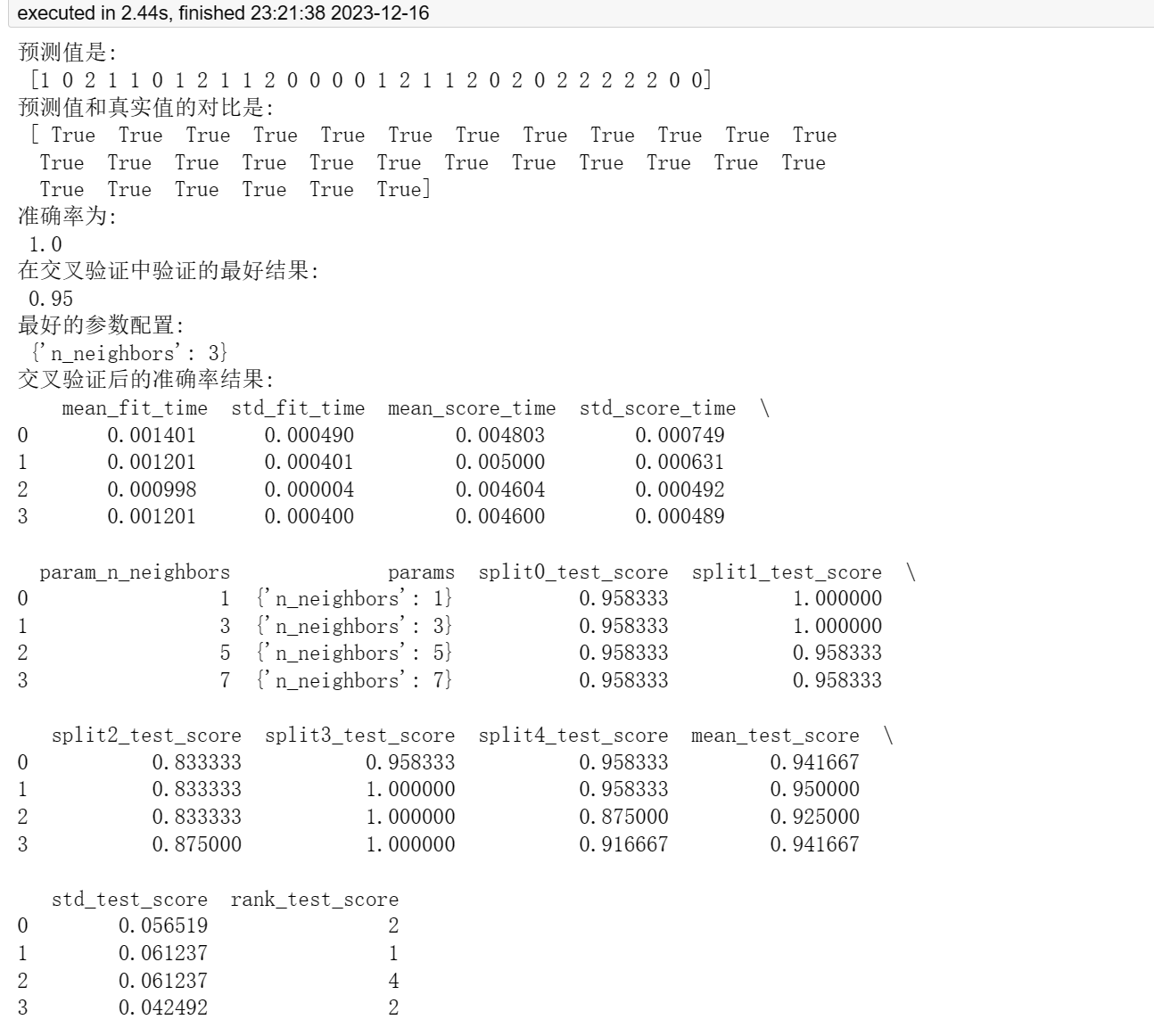
【机器学习】应用KNN实现鸢尾花种类预测
目录 前言 一、K最近邻(KNN)介绍 二、鸢尾花数据集介绍 三、鸢尾花数据集可视化 四、鸢尾花数据分析 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Fil…...

ACL和NAT
目录 一.ACL 1.概念 2.原理 3.应用 4.种类 5.通配符 1.命令 2.区别 3.例题 4.应用原则 6.实验 1.实验目的 2.实验拓扑 3.实验步骤 7.实验拓展 1.实验目的 2.实验步骤 3.测试 二.NAT 1.基本理论 2.作用 3.分类 静态nat 动态nat NATPT NAT Sever Easy-IP…...

MX6ULL学习笔记(十二)Linux 自带的 LED 灯
前言 前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动,Linux 内 核已经集成了。Linux 内核的 LED 灯驱动采用 platform 框架,因此我们只需要按照要求在设备 树文件中添加相应的 LED 节点即可,本章我们就来学…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...